异步索引
异步索引
create index XXX on database.tablename(col1, col2) include(col3, col4) async
hbase org.apache.phoenix.mapreduce.index.IndexTool \
--schema 库名 --data-table 表名 --index-table 索引表名 \
--output-path hdfs路径指向一个文件件即可
库名、表名、索引表名尽量都不要小写
这里一定要注意,异步索引比较繁琐,需要执行两步命令,后台会启动一个Mapreduce分布式任务向索引表插入数据,如果你的表数据很小完全没有必要用异步索引,启动Mapreduce任务的时间就赶上了小表索引创建时间,切记勿乱用!!!
create index XXX on database.tablename(col1, col2) include(col3, col4) async
hbase org.apache.phoenix.mapreduce.index.IndexTool \
--schema 库名 --data-table 表名 --index-table 索引表名 \
--output-path hdfs路径指向一个文件件即可
hbase org.apache.phoenix.mapreduce.index.IndexTool \
--schema 'dws' --data-table 'dws'.'dwd_energy_platforms' --index-table 'dws'.IDX_BDH_ENERGY2_HID \
--output-path IDX_BDH_ENERGY2_HID
hbase org.apache.phoenix.mapreduce.index.IndexTool \
--schema 'dws' --data-table 'dwd_energy_platforms' --index-table IDX_BDH_ENERGY2_HID \
--output-path ASYNC_IDX_HFILES
hbase org.apache.phoenix.mapreduce.index.IndexTool \
--schema 'dws' --data-table 'dws'.'dwd_energy_platforms' --index-table 'dws'.IDX_BDH_ENERGY2_HID \
--output-path ASYNC_IDX_HFILES
hbase org.apache.phoenix.mapreduce.index.IndexTool \
--schema 'dws' --data-table 'dws'.'dwd_energy_platforms' --index-table IDX_BDH_ENERGY2_HID \
--output-path ASYNC_IDX_HFILES
./hbase org.apache.phoenix.mapreduce.index.IndexTool --schema default --data-table DWR_NT_ORDER_DETAIL --index-table INDEX_DWR_NT_ORDER_DETAIL_ORDER_NO4 --output-path ASYNC_IDX_HFILES
备注:异步创建索引时,如果有新数据写入,会出现索引表数据丢失现象,创建完成后,数据正常写入不会丢失,所以,创建完成后可能需要往索引表补数据!
1.在phoenix中创建视图:
create view "six" ("pk" varchar primary key,"one"."one" varchar,"one"."two" varchar) as select * from "six";
2.在phoenix中创建异步索引:
create index "six_one_one_index" on "six" ("one"."one") async;
3.退出phoenix,在hbase中执行异步创建索引的操作:
hbase org.apache.phoenix.mapreduce.index.IndexTool --data-table six_one --index-table six_one_one_index --output-path /data/export
在执行这个步骤的时候出去,因为phoenix大小写的原因。这里只会去查找SIX_ONE表和SIX_ONE_ONE_INDEX表,并不会去查找six_one和six_one_one_index表。
解决:只在大写的表中创建异步索引:
步骤如下:
create view six_one ("pk" varchar primary key,"one"."one" varchar,"one"."two" varchar) as select * from "six";
创建一个大写的表SIX_ONE;
create index six_one_index on six_one ("cf"."eagle_si") async;
创建异步索引;
hbase org.apache.phoenix.mapreduce.index.IndexTool --data-table six_one --index-table six_one_index --output-path /data/export
执行语句去往index表中添加数据。
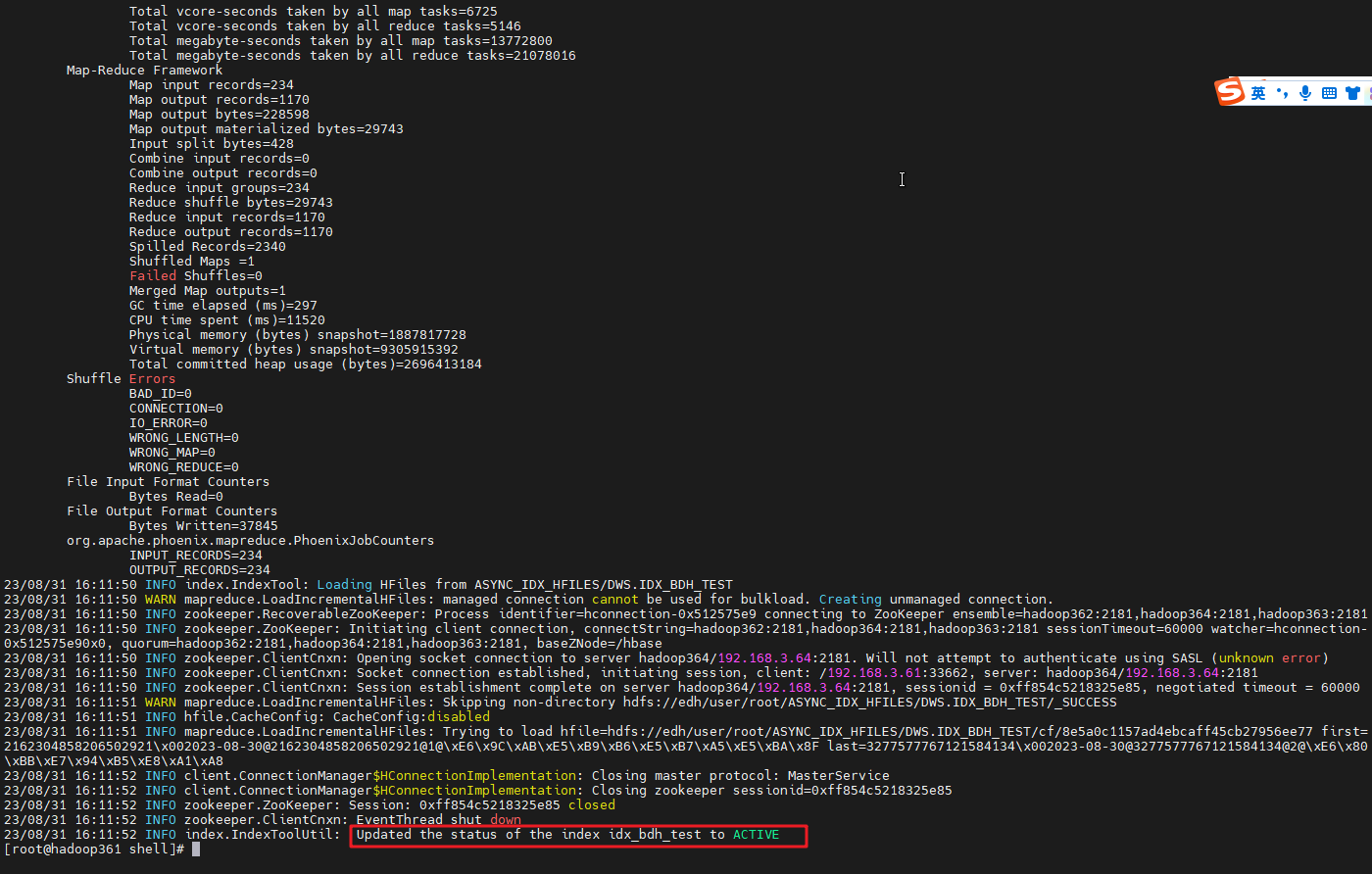
create index idx_bdh_test on dws.test2("cf"."producer_id") include("cf"."class_order","cf"."active_power"
,"cf"."dev_group"
,"cf"."htime"
) async;
hbase org.apache.phoenix.mapreduce.index.IndexTool \
--schema dws --data-table test2 --index-table idx_bdh_test \
--output-path ASYNC_IDX_HFILES
hdfs://edh/user/root/ASYNC_IDX_HFILES/DWS.IDX_BDH_TEST/_SUCCESS

参考资料
https://www.cnblogs.com/mxxct/p/13965189.html
https://blog.51cto.com/u_15080019/2654036

 浙公网安备 33010602011771号
浙公网安备 33010602011771号