
各种卷积类型Convolution
从最开始的卷积层,发展至今,卷积已不再是当初的卷积,而是一个研究方向。在反卷积这篇博客中,介绍了一些常见的卷积的关系,本篇博客就是要梳理这些有趣的卷积结构。
阅读本篇博客之前,建议将这篇博客结合在一起阅读,想必会有更深的理解。另外,不管是什么类型的卷积,我们都把它理解成一种运算操作。
- Group convolution
Group convolution是最早应用在2012年Alexnet的双GPU架构模型中,相当于把channel这一维度均分到两个GPU,进行分组卷积。如图所示:
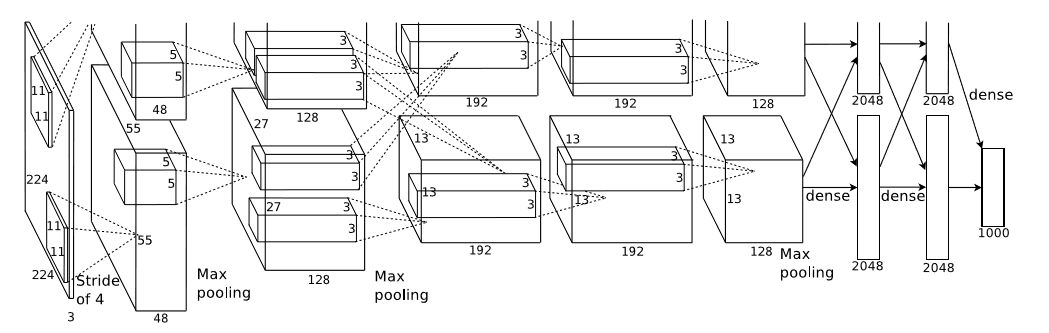
这篇论文是:ImageNet Classification with Deep Convolutional Neural Networks。由图可见,上下两个并行的网络结构只有在部分层中才有信息交互,而且网络结构一模一样,这就是Group convolution最早的应用,但是在caffe中经常使用的单机多GPU并行训练和上述问题存在本质区别,因为Group convolution是指将channel维度细分成多个group,然后再分组进行Convolution,而多GPU的训练只是一个数据并行分组的方式,其中minibatch和batch之间的关系就是batch=minibatch*GPU_num,这并不存在对channel的分组。
总之,Group convolution是一种卷积操作,想要切分channel,然后分组卷积,运算上没有什么特别的地方。
2.Pointwise convolution
点积,就是卷积核大小是1*1的,那为啥起名点积呢?就是因为这和向量中的点积运算很类似,举个例子,一张3通道的feature map,卷积核大小是1*1*3,那它的运算其实就是:Σ卷积核*单通道feature map。
总之,Pointwise convolution是一种卷积操作,而且是一种特殊的卷积运算,代表着卷积核的大小是1*1。
3.Separable convolution
可分离卷积,这种思路其实就是起了个高深的名字,也很常见。也是想在channel维度上改变经典的卷积运算,咋办呢?经典的卷积核都是k*k*channel大小的,其中channel是上一层的输出即本层的输入,这不太好,我们想任意指定一个channel,作为卷积核的大小,这样并不影响输入输出的特征图的长宽尺寸,仅仅改变了channel这一维度。这就变得很有意思了,同Group convolution不一样的是,可分离卷积可增加channel维度,而并没有依赖GPU。
举个例子,对于经典的卷积运算,如果说所需的参数量为256*3*3*256=589824。而对于可分离卷积,假设我们指定的卷积核是3*3*4,那首先是256*3*3*4=9216,接下来我们得到了4*256=1024个通道数,但是呢?这并没有完成,因为还需要下一个过程将channel重新压缩回256,接着有1024*1*1*256=262144,整个过程就是9216+262144=271360,看看,589824是271360的两倍多。虽然,这在很多框架上也许未能比较出效果的显著差异,那是多方面的原因。
值得一提的是,上面举的例子可以认为是Separable convolution 和Pointwise convolution结合在一起,事实上就是配套使用的。
最早的Separable convolution来源于论文:Simplifying ConvNets for Fast Learning,作者用的是k*1和1*k的卷积核,起名为可分离卷积,而本处的可分离卷积来源于另一篇论文:Xception: Deep Learning with Depthwise Separable Convolutions。
总之,Separable convolution是一种卷积操作,而且是一种特殊的卷积运算,代表着卷积核的channel维度可以自己任意选取。
4.Depthwise convolution
深度卷积,这名字又开始很高深了,其实它的意思就是拓展Separable convolution而来,我们可以让卷积核的channel维度等于1啊,这样就是深度卷积,意为在每一个channel上做卷积。值得注意的是,往往Separable convolution和Depthwise convolution是统称为Depthwise convolution。假设卷积核的shape是[filter_height, filter_width, in_channels, channel_multiplier],区别仅在于channel_multiplier,由于参考同一篇论文,此处将其统一。
这样说来,前面的例子中其实就是Depthwise separable convolution = Depthwise convolution + Pointwise convolution,这就是深度可分离卷积的真正内涵。这也就是以下论文的工作:Xception: Deep Learning with Depthwise Separable Convolutions
总之,Depthwise convolution是一种卷积操作,和Separable convolution一样,表示对channel维度进行卷积的一种方式。
5.Dilated convolution
空洞卷积是解决pixel-wise输出模型的一种常用的卷积方式。一种普遍的认识是,pooling下采样操作导致的信息丢失是不可逆的,通常的分类识别模型,只需要预测每一类的概率,所以我们不需要考虑pooling会导致损失图像细节信息的问题,但是做像素级的预测时(譬如语义分割),就要考虑到这个问题了。那么空洞卷积可以用下图来说明:
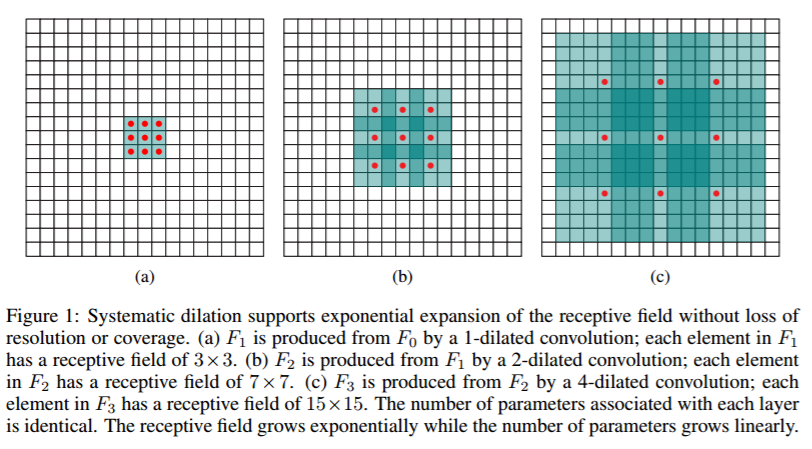
也就是以下论文:Multi-scale context aggregation by dilated convolutions
总之,空洞卷积是卷积运算的一种方式,在于增大了感受野却不丢失语义信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号