一款好用的js敏感信息收集脚本分享
0x00 作用:
用于输入网址后获取该页面所有的js脚本,根据自定义的关键字匹配对应的value,实现js信息收集的便利性与灵活性。
0x01 环境:
python3
0x02 脚本:
import requests import re import time import random from urllib.parse import urljoin, urlparse from bs4 import BeautifulSoup from openpyxl import Workbook from openpyxl.styles import Font, PatternFill class JSAnalyzerPro: def __init__(self): self.session = requests.Session() self.headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ' 'AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/120.0.0.0 Safari/537.36', 'Accept-Encoding': 'gzip, deflate' } self.visited = set() self.domain = "" self.keywords = [] self.max_depth = 2 self.results = [] def configure(self, target_url, keywords): """配置参数并验证有效性""" try: # 自动补全URL协议 if not target_url.startswith(('http://', 'https://')): target_url = f'https://{target_url}' parsed = urlparse(target_url) self.domain = parsed.netloc # 关键字处理(自动纠错+去重) self.keywords = list({k.strip().lower().replace('secert', 'secret') for k in keywords.split(',')}) # 验证目标可达性 test_res = self.session.head(target_url, timeout=10) test_res.raise_for_status() print(f"[系统检测] 成功连接到目标网站: {target_url}") except Exception as e: raise ConnectionError(f"配置失败: {str(e)}") def safe_extract(self, content): """增强型键值提取(带调试输出)""" try: pattern = r''' (["']?)\b({})\b(["']?) # 键 \s*[:=]\s* # 分隔符 (["']?)(.*?)(["']?) # 值 (?=\s*[,;}}\n]) # 终止符 '''.format('|'.join(map(re.escape, self.keywords))) matches = re.findall( pattern, content, flags=re.IGNORECASE | re.VERBOSE | re.DOTALL ) processed = [] for q1, key, q2, q3, value, q4 in matches: clean_key = key.strip('\'"') clean_value = value.strip('\'"') if clean_key.lower() in self.keywords: print(f"[数据提取] 发现匹配: {clean_key} = {clean_value[:30]}...") # 调试输出 processed.append((clean_key, clean_value)) return processed except Exception as e: print(f"[警告] 正则解析异常: {str(e)}") return [] def crawl_js(self, url, depth=0): """带调试日志的递归爬取""" if depth > self.max_depth or url in self.visited: return print(f"\n[深度 {depth}] 分析: {url}") self.visited.add(url) try: # 请求参数优化 time.sleep(random.uniform(1.5, 3.0)) # 更长的随机延迟 verify_ssl = False # 临时关闭SSL验证 if url.startswith('http'): response = self.session.get( url, timeout=20, verify=verify_ssl, allow_redirects=True ) response.encoding = 'utf-8' # 强制UTF-8编码 content = response.text print(f"[网络请求] 成功获取内容,长度: {len(content)}字节") else: content = url # 执行提取 matches = self.safe_extract(content) for key, value in matches: self.results.append({ 'source': url, 'keyword': key, 'value': value, 'depth': depth }) # 深度控制 if depth < self.max_depth: print(f"[深度控制] 进入第{depth + 1}层分析...") soup = BeautifulSoup(content, 'html.parser') if depth == 0 else None for js_url in self.find_js_links(content, soup, url): self.crawl_js(js_url, depth + 1) except Exception as e: print(f"[严重错误] 处理 {url} 失败: {str(e)}") def find_js_links(self, content, soup, base_url): """改进的链接发现方法""" links = set() # 从HTML标签解析 if soup: for tag in soup.find_all(['script', 'link']): src = None if tag.name == 'script' and tag.has_attr('src'): src = tag['src'] elif tag.name == 'link' and 'script' in tag.get('as', ''): src = tag.get('href', '') if src: absolute_url = urljoin(base_url, src.split('?')[0]) if self.is_valid_url(absolute_url): links.add(absolute_url) # 从JS代码解析 patterns = [ r'\.src\s*=\s*["\'](.*?)["\']', r'load\(["\'](.*?)["\']\)', r'fetch\(["\'](.*?)["\']\)' ] for pattern in patterns: for match in re.finditer(pattern, content, re.IGNORECASE): absolute_url = urljoin(base_url, match.group(1)) if self.is_valid_url(absolute_url): links.add(absolute_url) print(f"[链接发现] 找到{len(links)}个新链接") return [link for link in links if link not in self.visited] def is_valid_url(self, url): """增强型URL验证""" parsed = urlparse(url) # 允许相对路径和同域名资源 return not parsed.netloc or parsed.netloc == self.domain def generate_report(self): """带验证的报告生成""" if not self.results: print("[警告] 未发现任何匹配数据,不生成空报告") return try: wb = Workbook() ws = wb.active ws.title = "安全扫描报告" # 标题行 headers = ["来源URL", "关键词", "提取值", "数据深度", "风险等级"] ws.append(headers) # 设置标题样式 header_fill = PatternFill(start_color="2F5496", fill_type="solid") for col in ws.iter_cols(min_row=1, max_row=1): for cell in col: cell.font = Font(bold=True, color="FFFFFF") cell.fill = header_fill # 填充数据 risk_keywords = {'password', 'secret', 'key', 'token'} for item in self.results: risk = "高危" if item['keyword'].lower() in risk_keywords else "中危" ws.append([ item['source'], item['keyword'], item['value'], item['depth'], risk ]) # 自动调整列宽 for col in ws.columns: max_len = max(len(str(cell.value)) for cell in col) adjusted_width = (max_len + 2) * 1.2 ws.column_dimensions[col[0].column_letter].width = adjusted_width # 生成文件名 domain_clean = self.domain.replace('.', '_').replace(':', '') filename = f"security_report_{domain_clean}_{int(time.time())}.xlsx" # 保存前验证 if len(ws['A']) > 1: # 确保有数据行 wb.save(filename) print(f"[报告生成] 成功保存到: {filename}") else: print("[警告] 检测到空数据表,取消保存操作") except Exception as e: print(f"[严重错误] 生成报告失败: {str(e)}") raise if __name__ == "__main__": analyzer = JSAnalyzerPro() try: target = input("请输入目标URL: ").strip() keys = input("请输入要提取的关键字(多个用逗号分隔): ").strip() analyzer.configure(target, keys) analyzer.crawl_js(target) analyzer.generate_report() print(f"[系统通知] 扫描完成,共发现 {len(analyzer.results)} 条敏感信息") except Exception as e: print(f"[致命错误] 程序运行失败: {str(e)}") print("故障排查建议:") print("1. 检查网络连接和代理设置") print("2. 尝试降低最大爬取深度(修改 max_depth)") print("3. 安装最新依赖:pip install --upgrade requests beautifulsoup4 openpyxl")
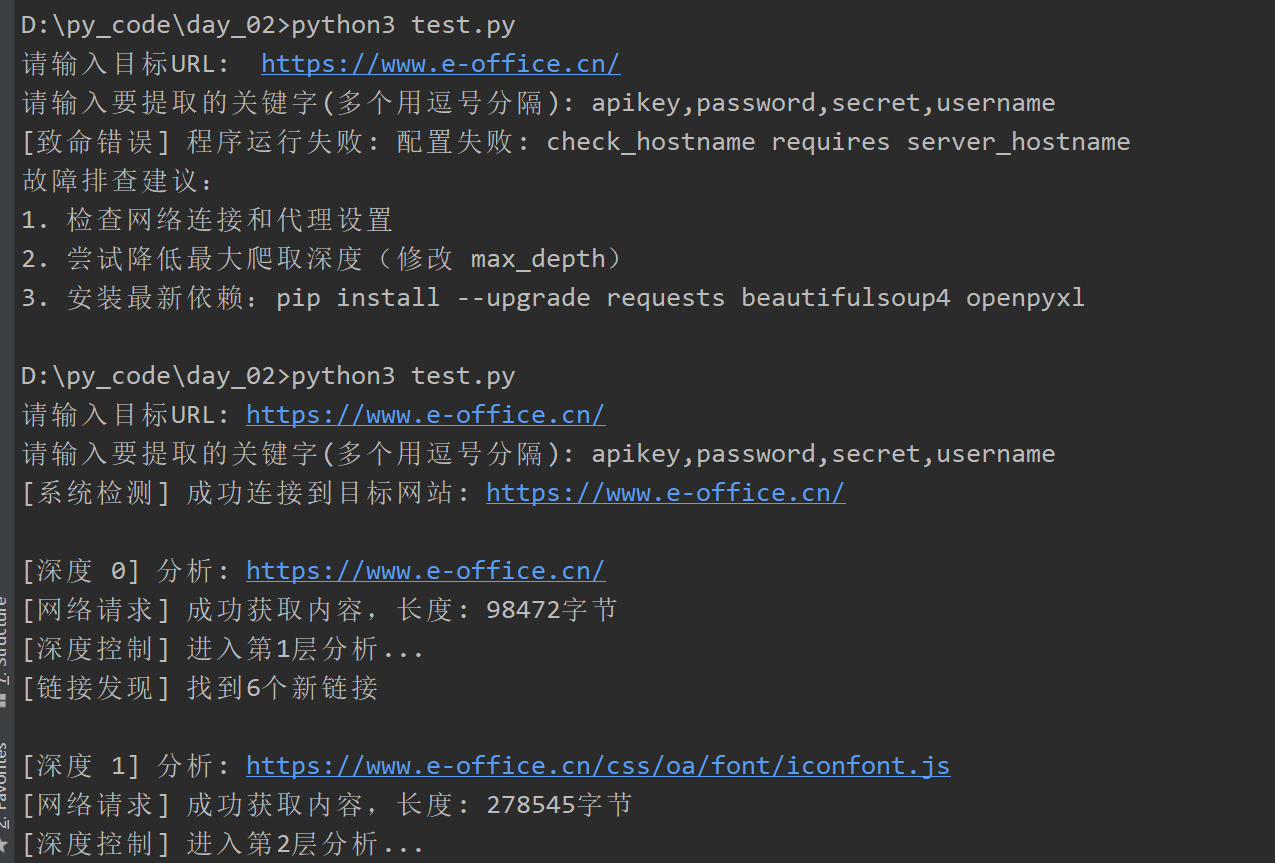
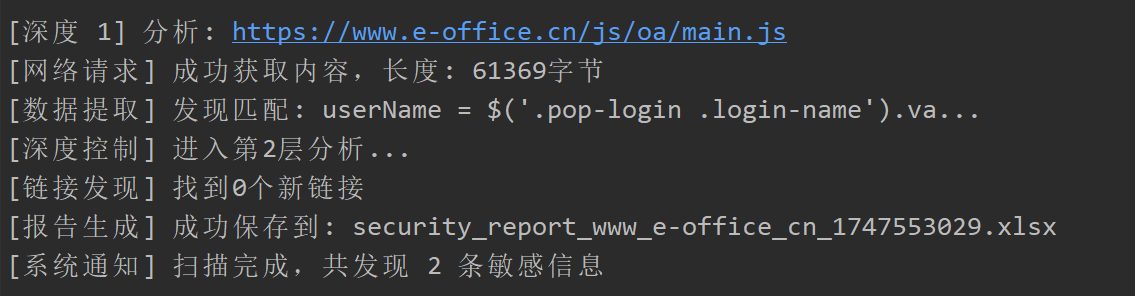
0x03 效果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号