ImageNet Classfication with Deep Convolutional Neural Network 论文复现笔记
 AlexNet的学习
AlexNet的学习
ImageNet Classfication with Deep Convolutional Neural Network 论文复现笔记
论文结构
-
Abstract
介绍背景及提出AlexNet模型,获得ILSVRC-2012冠军
-
Introduction
研究的成功得益于大量数据及高性能GPU;介绍本论文主要贡献
-
The Dataset
ILSVRC数据集简介;图片预处理细节
-
The Architecture
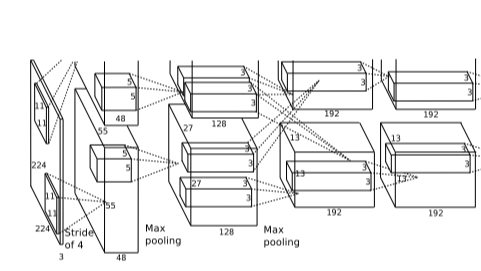
AlexNet网络结构及其内部细节:ReLu、GPU、LRN、Overlapping Pooling
-
Reduce Overfiting
防止过拟合技术,数据增强和dropout
-
Details of learing
实验参数设置:超参调整,权重初始化
-
Results
AlexNet比赛指标,成绩及其详细设置
-
Quanlitative Evalutions
实验探究,分析卷积核模型,模型输出合理性,高级特征的相似性
-
Discussion
强调网络结构之间的强关联,提出进一步研究方向
AlexNet Architecture
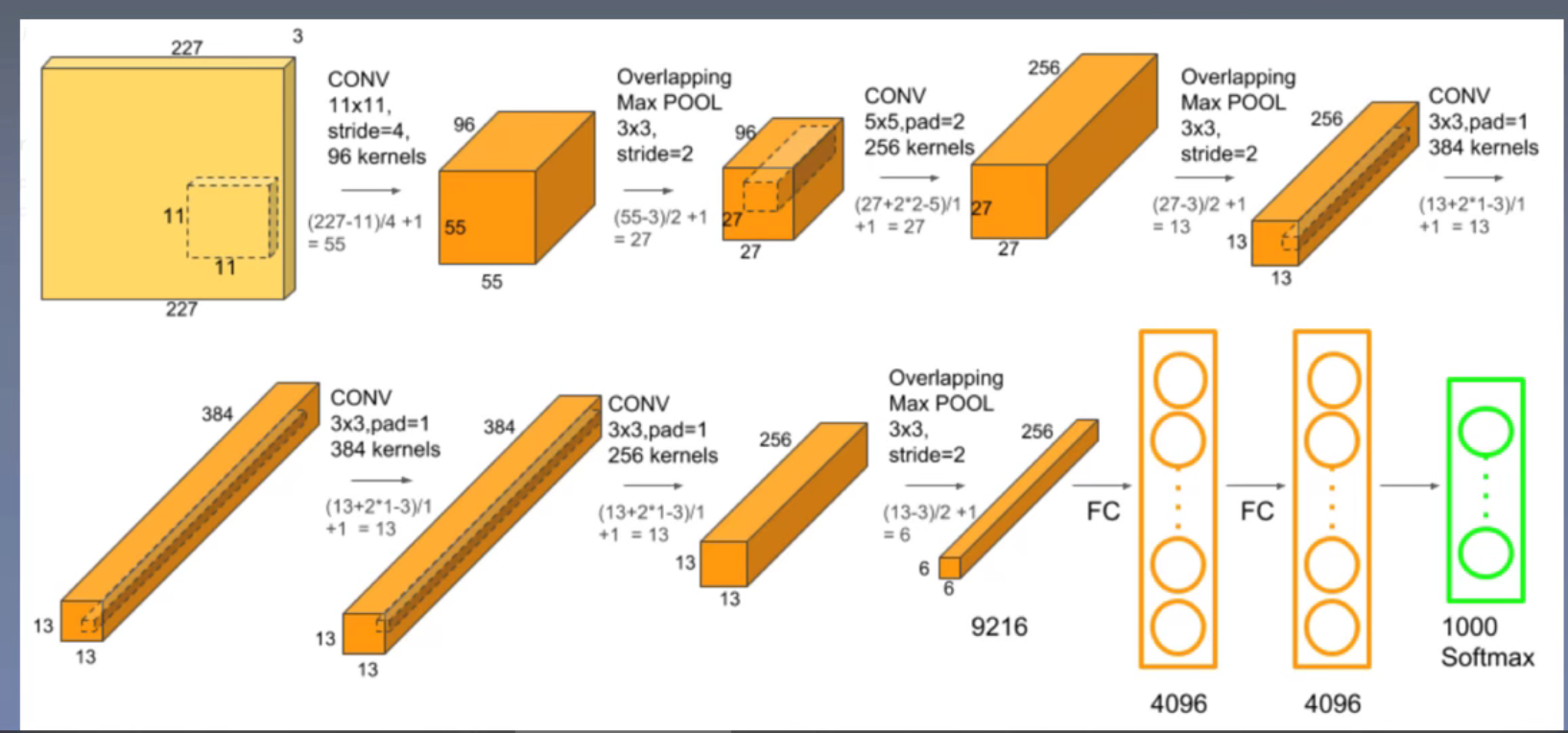
参数数量:
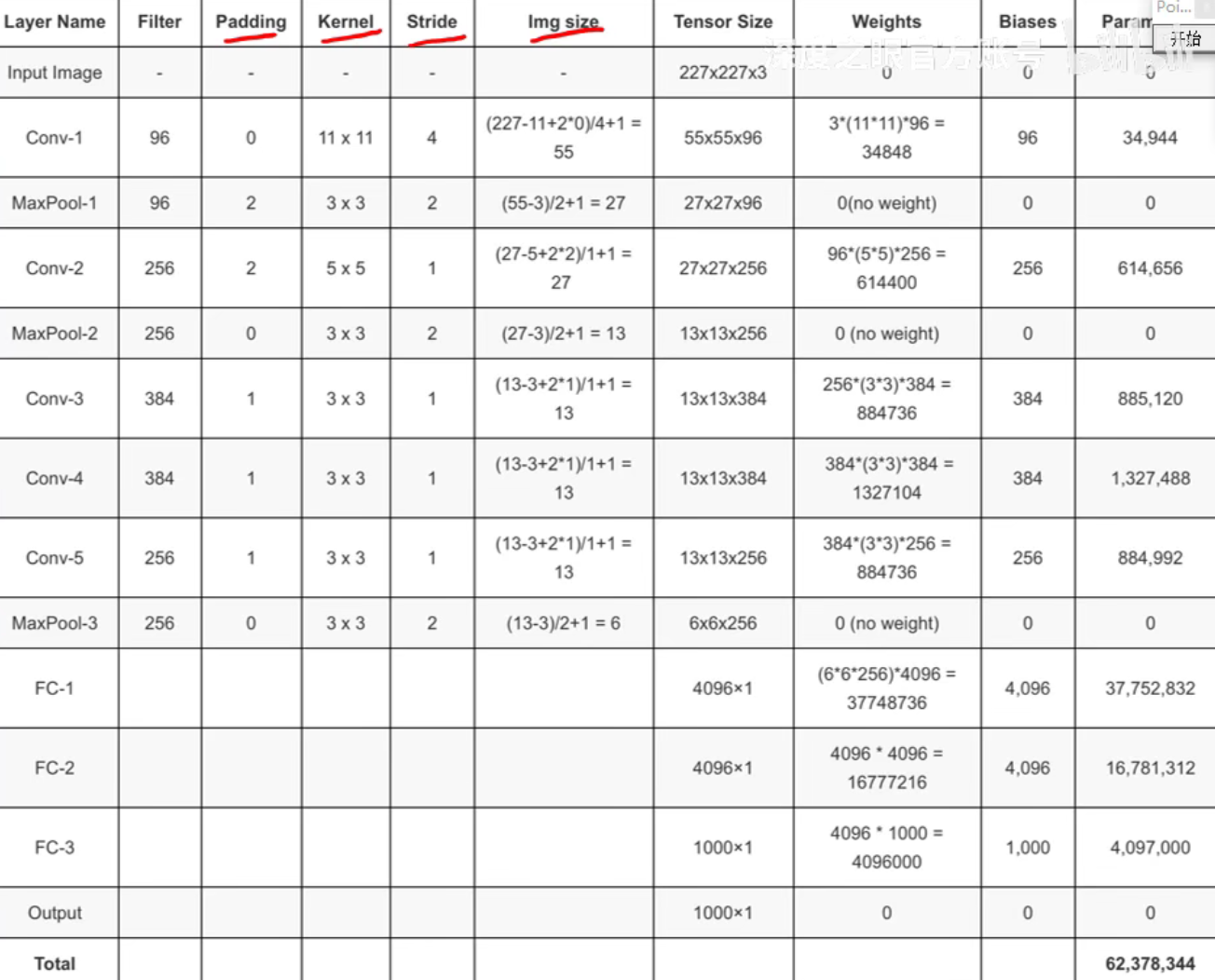
可以发现 FC-1层的参数量大致是整个网络一半的参数量.
模型结构中的相关技术
- ReLu
在 ReLU 激活函数未提出之前,神经网络的激活函数主要为 Sigmoid 函数和 Tanh 函数。
这里两个函数的表达式如下:
两个函数的导数是:
函数图像:
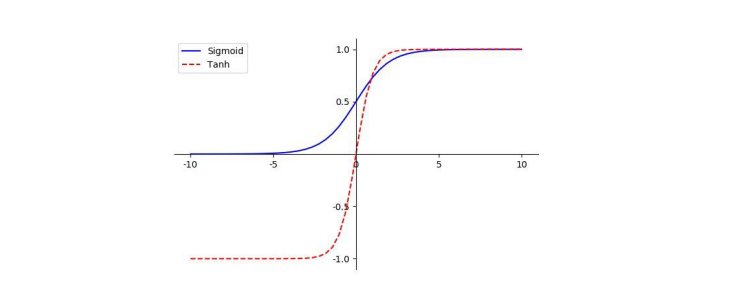
当\(x->\infty\)时,函数区域平缓,导数趋向于0,因此 Sigmoid和 Tanh 函数都是饱和函数,容易在训练后期出现梯度消失。
在 AlexNet 论文当中,提出了利用非饱和非线性的 ReLU 函数作为激活函数。ReLU 函数的函数表达式及其导数如下:
函数图像:
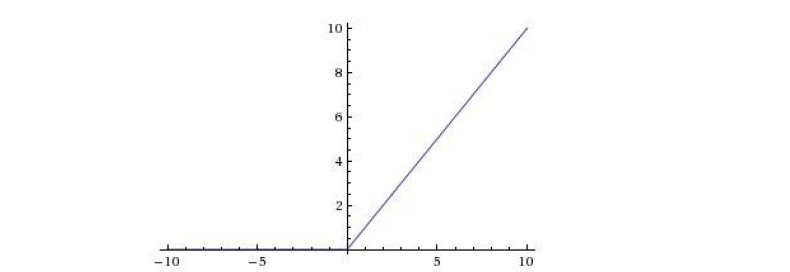
在一个四层的卷积神经网络上(训练数据是CIFAR-10),使用ReLu和使用Tanh达到25%的训练数据错误率所需的Epoch数
- 多GPU进行训练
限于当时没有算力更强大的GPU( 2 个 NVIDIA GTX 580 GPU 内存3GB),因此作者采用了双GPU并行训练的技术,将一半内核(或神经元)放在每个 GPU 上,GPU只在某些层中进行通信。此处具体的技术细节如果以后要用到,再去进行学习。
- LRN 局部响应归一化
这是受到了神经科学的启发,所研究出的技术。

LRN在AlexNet的第一层和第二层之后,但其实现在已经有了更好用的BatchNormalization,在这里介绍一下LRN的实现方法:

就是通道方向上的元素,会受到相邻通道方向上元素的“抑制”,图中的j方向就是通道方向,x,y是固定的。
最后LRN减少了Top-1 and Top-5 error rate分别是1.4%,1.2%。
-
重叠池化
摘选自原论文:

避免过拟合的相关技术
- 数据增强
AlexNet使用的数据增强技术一直沿用至今。
-
第一种数据增强的形式包括生成平移图像和水平翻转图像。做法就是从 \(256 \times 256\) 的原始图像中提取随机的\(224\times 224\) 大小的块(以及它们的水平翻转),这使得我们的训练集增大了 2048 倍(\((256-224)^2\times2=2048\))。尽管产生的这些训练样本显然是高度相互依赖的,但有效地减轻了过拟合(论文中没提效果)。在测试时,网络通过提取 5 个\(224 \times 224\)的块(四个边角块和一个中心块)以及它们的水平翻转(因此共十个块)做预测,然后网络的 softmax 层对这十个块的预测值做平均。
-
第二种数据增强的形式包括改变训练图像的 RGB 通道的强度。采用了PCA,貌似相当复杂。
- Dropout
dropout 它将每一个隐藏神经元的输出以 0.5 概率设为 0。以这种方式被“踢出”的神经元不会参加前向传递,也不会加入反向传播。因此每次有输入时,神经网络采样一个不同的结构,但是所有这些结构都共享权值。这个技术降低了神经元之间复杂的联合适应性,因为一个神经元不是依赖于另一个特定的神经元的存在的。因此迫使要学到在连接其他神经元的多个不同随机子集的时候更鲁棒性的特征。在测试时,本文使用所有的神经元,但对其输出都乘以了 0.5。
相关的点
知识点
-
top five error

-
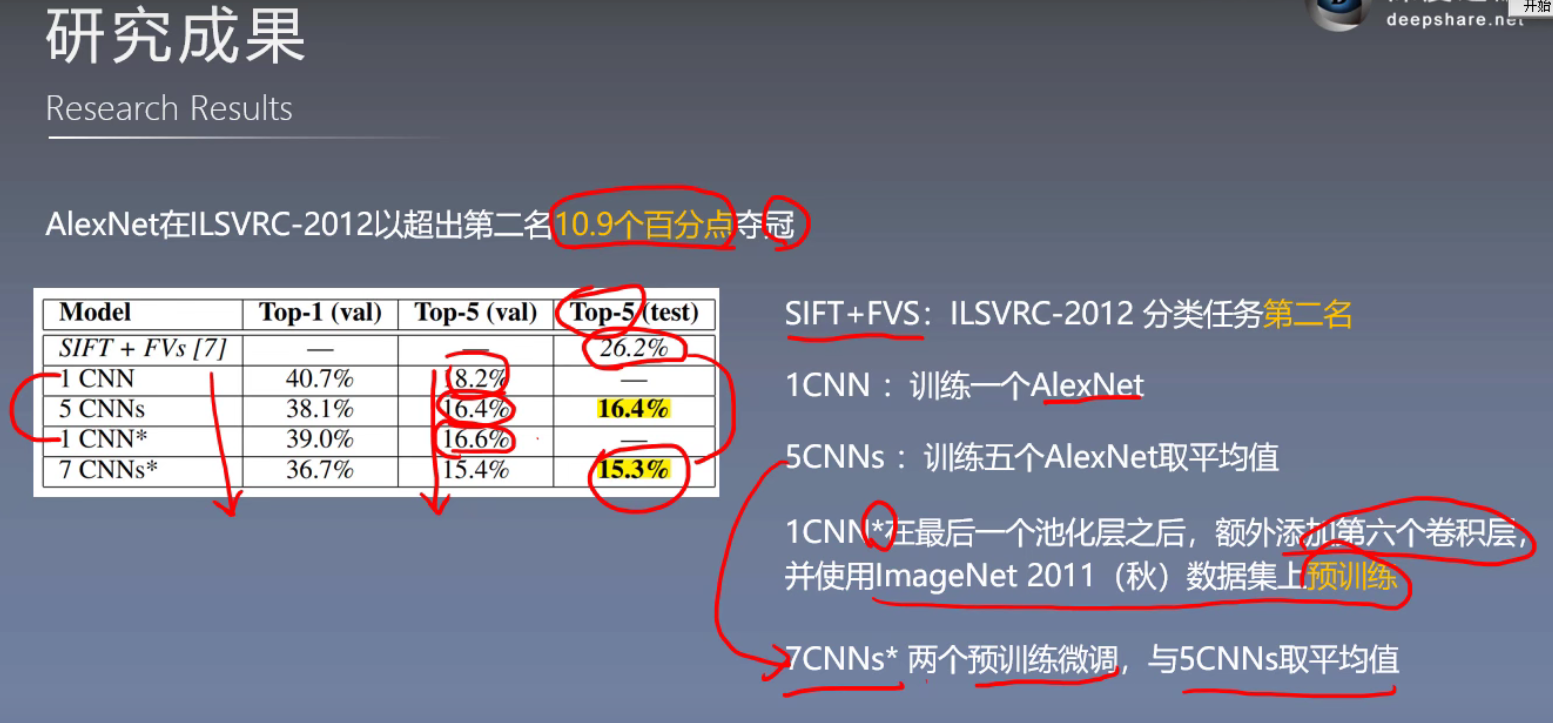
研究成果

启发点


代码复现
文件结构说明
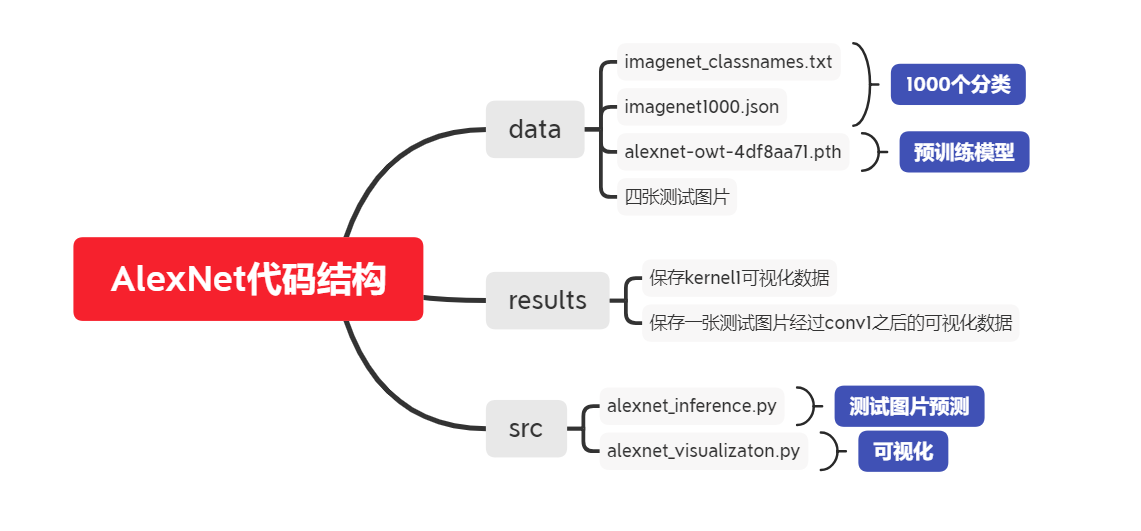
笔记
由于笔记本的算力限制,我去下载了AlexNet的预训练模型(由于模型大于100M,文件中未包含,读者可去官网下载)
测试部分
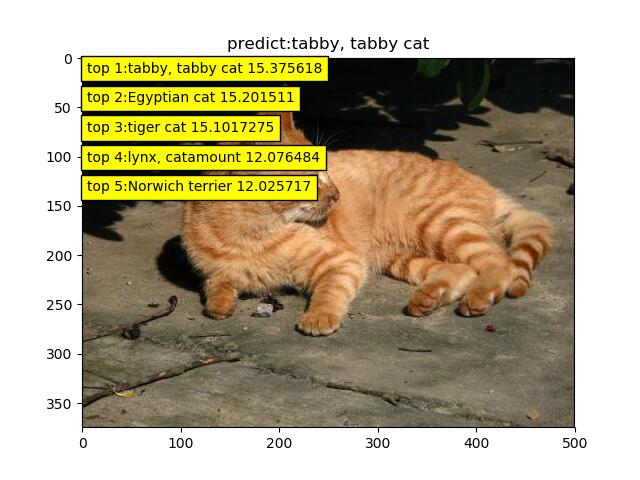
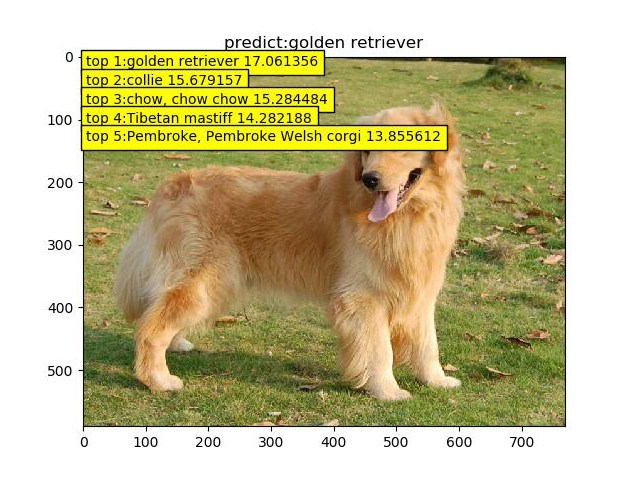
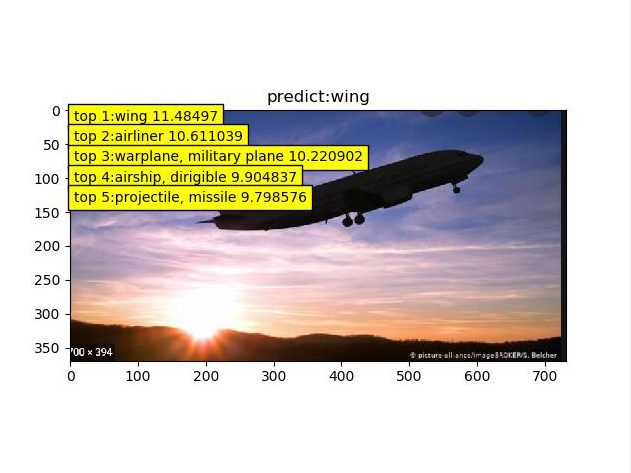
我找了四张图片对AlexNet进行测试(类别后面的数字代表概率)
 |
 |
|---|---|
 |
 |
可以看到模型的运行还不错,但是第三张图片把这个阴影的飞机识别成了wing.为此我去观察了,原数据集中的wing图片
Kernel可视化
由于第一个conv层的kernel size是 \(64 \times 3 \times 11\times 11\)因此具有可视化的潜质(其它层的kernel size都太小了)

大概可以知道刚开始学习的主要是图片的一些基础的纹理和色彩特征.
然后以4张图片为例,查看卷积后的图片变成了什么样子.
| 输入size \(3 \times 224\times 224\) | 输出size \(64 \times 55\times 55\) | |
|---|---|---|
 |
conv1 |  |
 |
conv1 |  |
 |
conv1 |  |
 |
conv1 |  |
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/15170233.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号