pytorch学习
pytorch 学习
感谢B站up主我是土堆的课程,完结撒花!!!
对pytorch的基本结构有了了解,更学会了高效地查阅官方文档!!!
数据导入
- Dataset
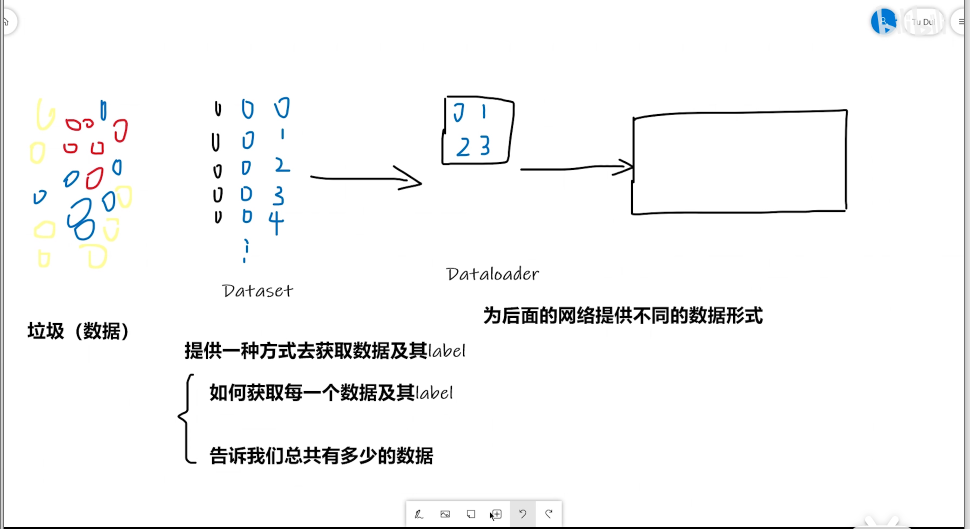
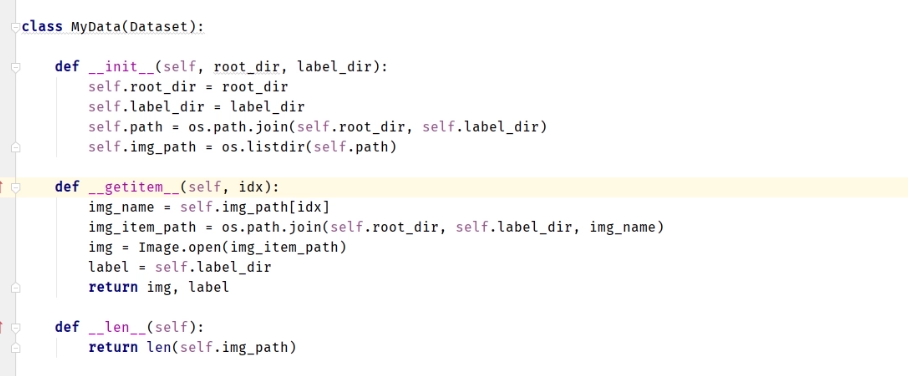
将dataset和sampler组合,提供了一种遍历dataset的方法
import torchvision
# 准备的测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter("dataloader")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
print()
# print(imgs.shape)
# print(targets)
writer.add_images("Epoch: {}".format(epoch), imgs, step)
step = step + 1
writer.close()
遍历了两次, step是156 (从0开始编码 \(156 \times 64 = 9984\))不够10000是因为drop_last=True
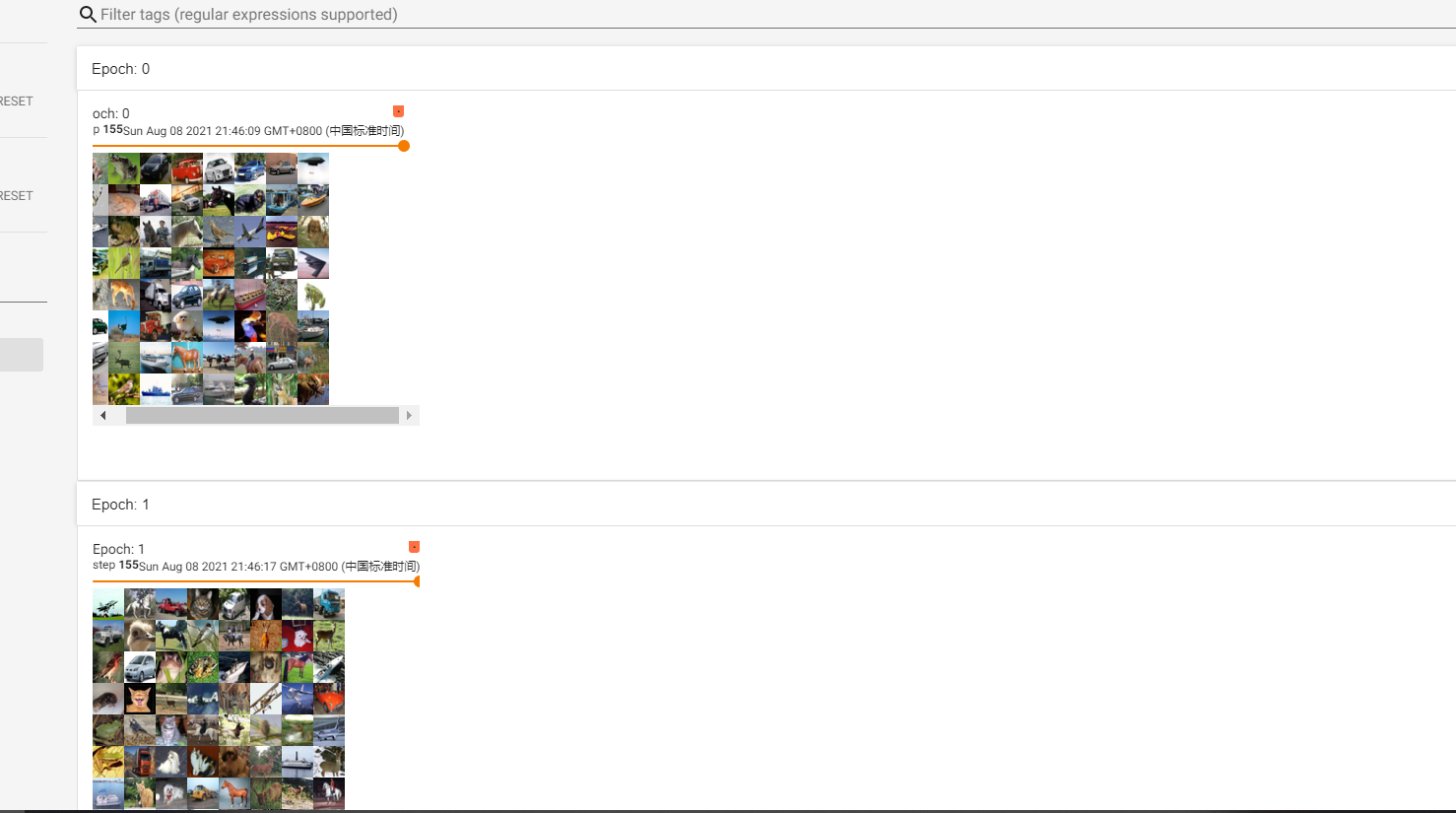
Tensorboard使用
- add_scale
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
for i in range(100):
# writer.add_image()
writer.add_scalar("y= x", i, i)
writer.close()

运行结束后:

打开logs文件:

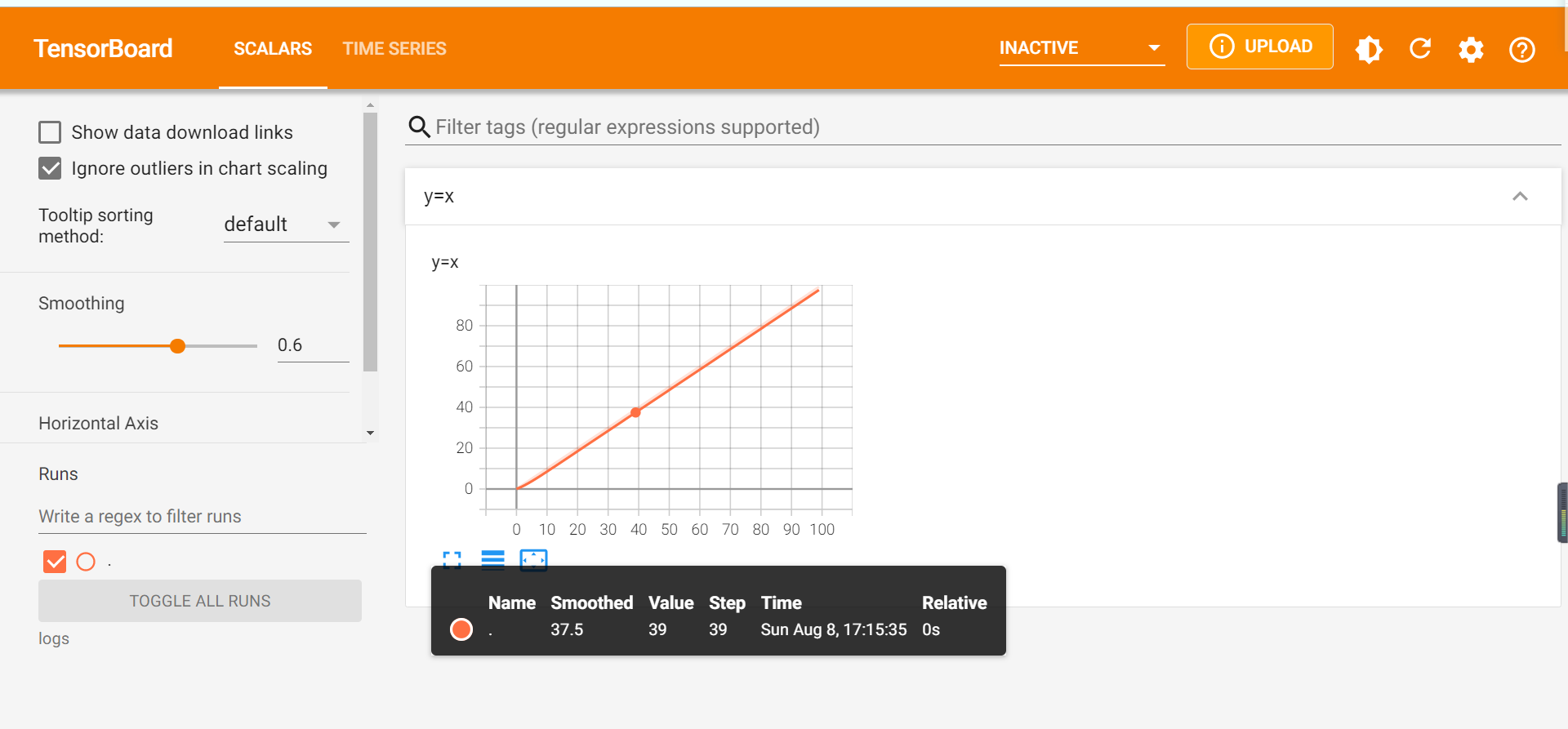
- add_image
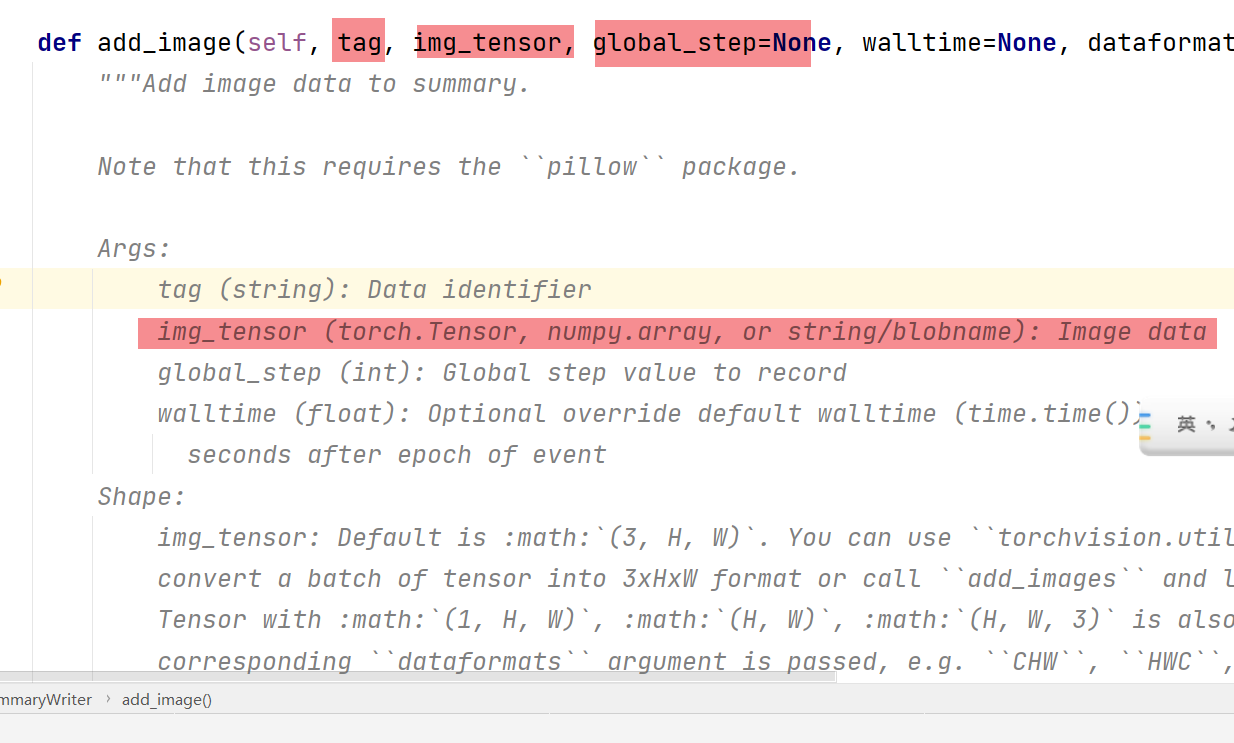
运行示例:
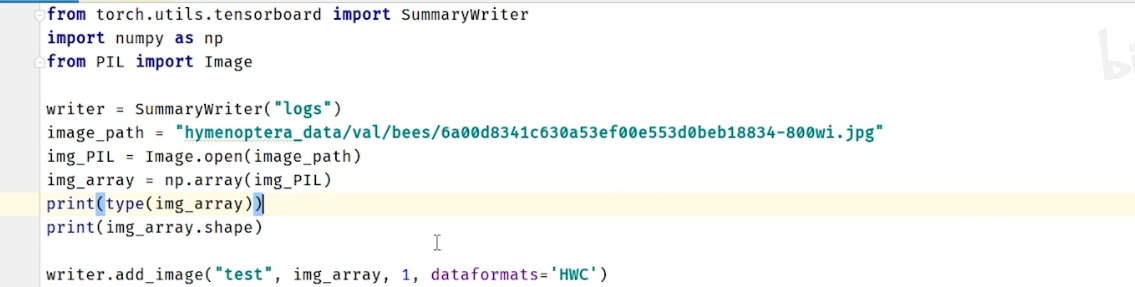
image_array默认是 (C, H, W), 如果是(H,W,C)需要加代码中的参数
运行示例:
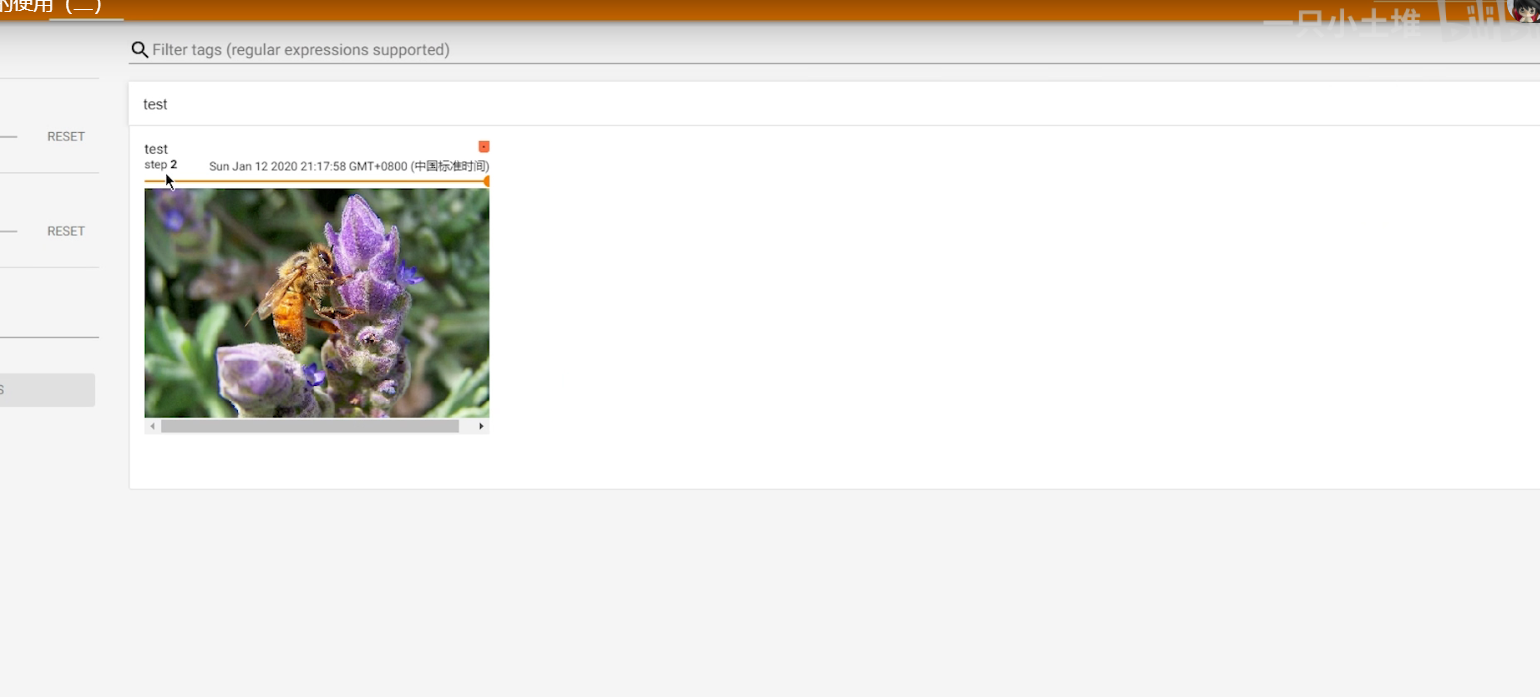
transforms的使用
transform.py
- ToTensor()
是transform.py下的一个类,功能是把type为PIL,nparray的图片转化为tensor数据类型
from torchvision import transforms
from PIL import Image
img = Image.open("hymenoptera_data/train/ants/5650366_e22b7e1065.jpg")
# 一个转换器
val_totensor = transforms.ToTensor()
# 给转换器填入参数
img = val_totensor(img)
print(img)

- Compose()
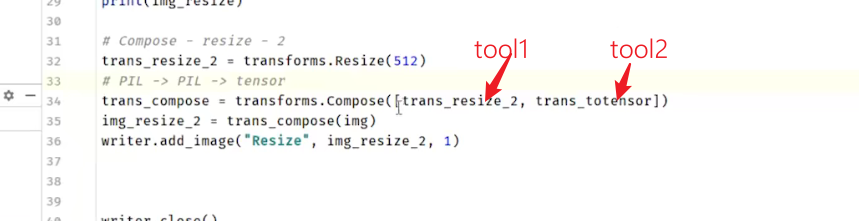
img 先送到 tool1, tool1返回的结果送给tool2
-
ToPILImage()
-
Normalize
class Normalize(torch.nn.Module): """Normalize a tensor image with mean and standard deviation. This transform does not support PIL Image. Given mean: ``(mean[1],...,mean[n])`` and std: ``(std[1],..,std[n])`` for ``n`` channels, this transform will normalize each channel of the input ``torch.*Tensor`` i.e., ``output[channel] = (input[channel] - mean[channel]) / std[channel]`` .. note:: This transform acts out of place, i.e., it does not mutate the input tensor. Args: mean (sequence): Sequence of means for each channel. std (sequence): Sequence of standard deviations for each channel. inplace(bool,optional): Bool to make this operation in-place. """ def __init__(self, mean, std, inplace=False): super().__init__() self.mean = mean self.std = std self.inplace = inplace def forward(self, tensor: Tensor) -> Tensor: """ Args: tensor (Tensor): Tensor image to be normalized. Returns: Tensor: Normalized Tensor image. """ return F.normalize(tensor, self.mean, self.std, self.inplace) def __repr__(self): return self.__class__.__name__ + '(mean={0}, std={1})'.format(self.mean, self.std)使用示例:
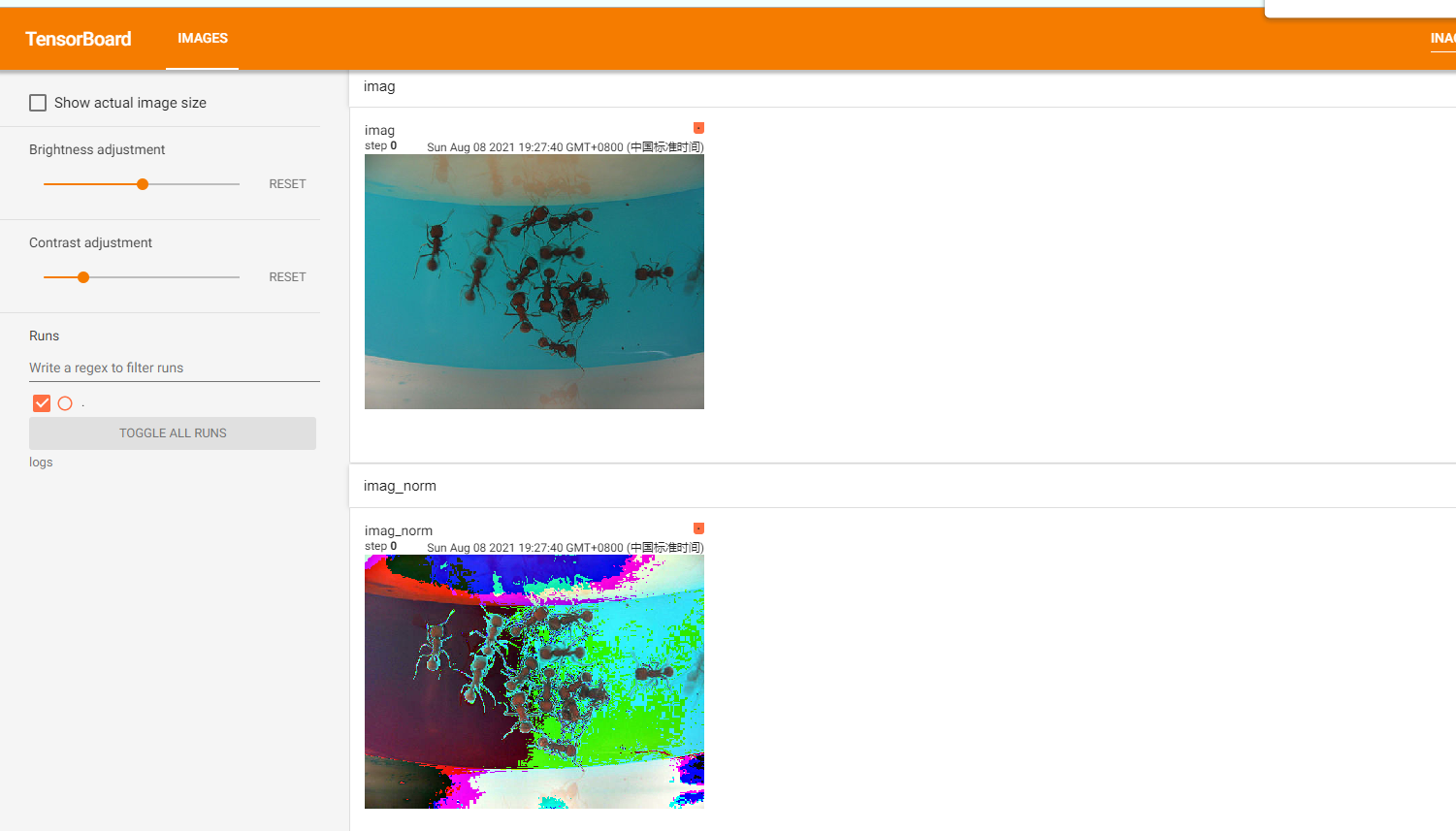
from torchvision import transforms from torch.utils.tensorboard import SummaryWriter from PIL import Image img = Image.open("hymenoptera_data/train/ants/5650366_e22b7e1065.jpg") writer = SummaryWriter("logs") val_totensor = transforms.ToTensor() img = val_totensor(img) writer.add_image("imag", img) # 填入三个通道上的均值 平方差 val_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) imag_norm = val_norm(img) writer.add_image("imag_norm", imag_norm) writer.close()
-
Resize()
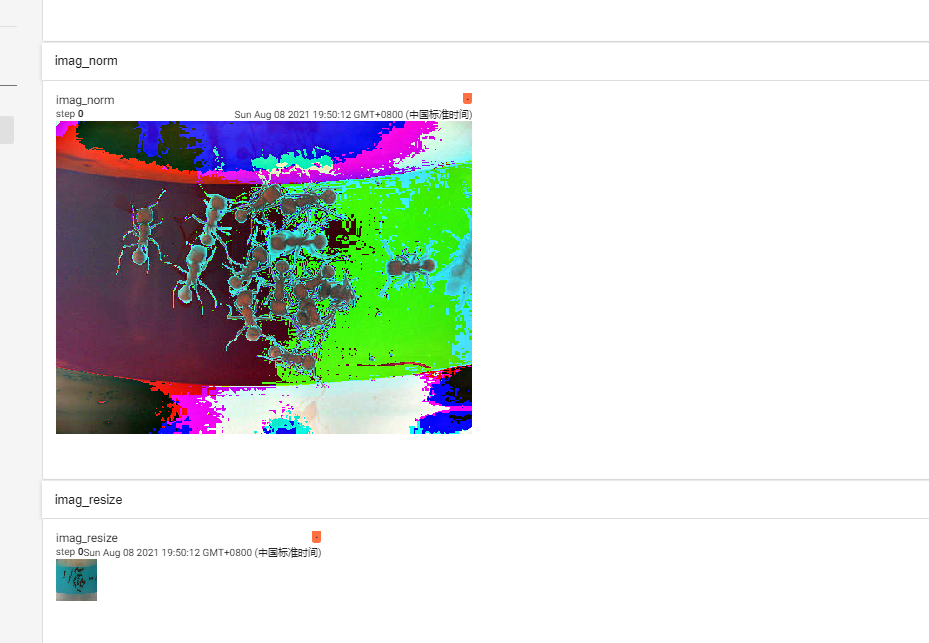
from torchvision import transforms from torch.utils.tensorboard import SummaryWriter from PIL import Image img = Image.open("hymenoptera_data/train/ants/5650366_e22b7e1065.jpg") writer = SummaryWriter("logs") val_totensor = transforms.ToTensor() img_tensor = val_totensor(img) writer.add_image("imag", img_tensor) # 填入三个通道上的均值 平方差 norm_tool = transforms.Normalize([5, 5, 5], [0.5, 0.5, 0.5]) imag_norm = norm_tool(img_tensor) writer.add_image("imag_norm", imag_norm) '''size (sequence or int): Desired output size. If size is a sequence like (h, w), output size will be matched to this. If size is an int, smaller edge of the image will be matched to this number. i.e, if height > width, then image will be rescaled to (size * height / width, size).''' # resize print(img_tensor.size) resize_tool = transforms.Resize((50, 50)) img_resize = resize_tool(img_tensor) writer.add_image("imag_resize", img_resize) print(type(img_resize)) print(img_tensor.size) writer.close()
- RandomCrop()
关于如何使用pytorch的官方数据集
import torchvision
from torch.utils.tensorboard import SummaryWriter
# 可以添加更多的操作 比如裁剪
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
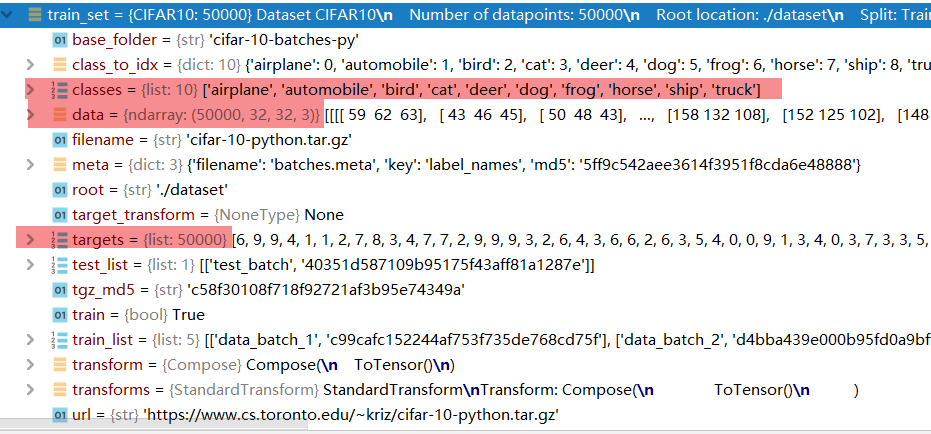
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
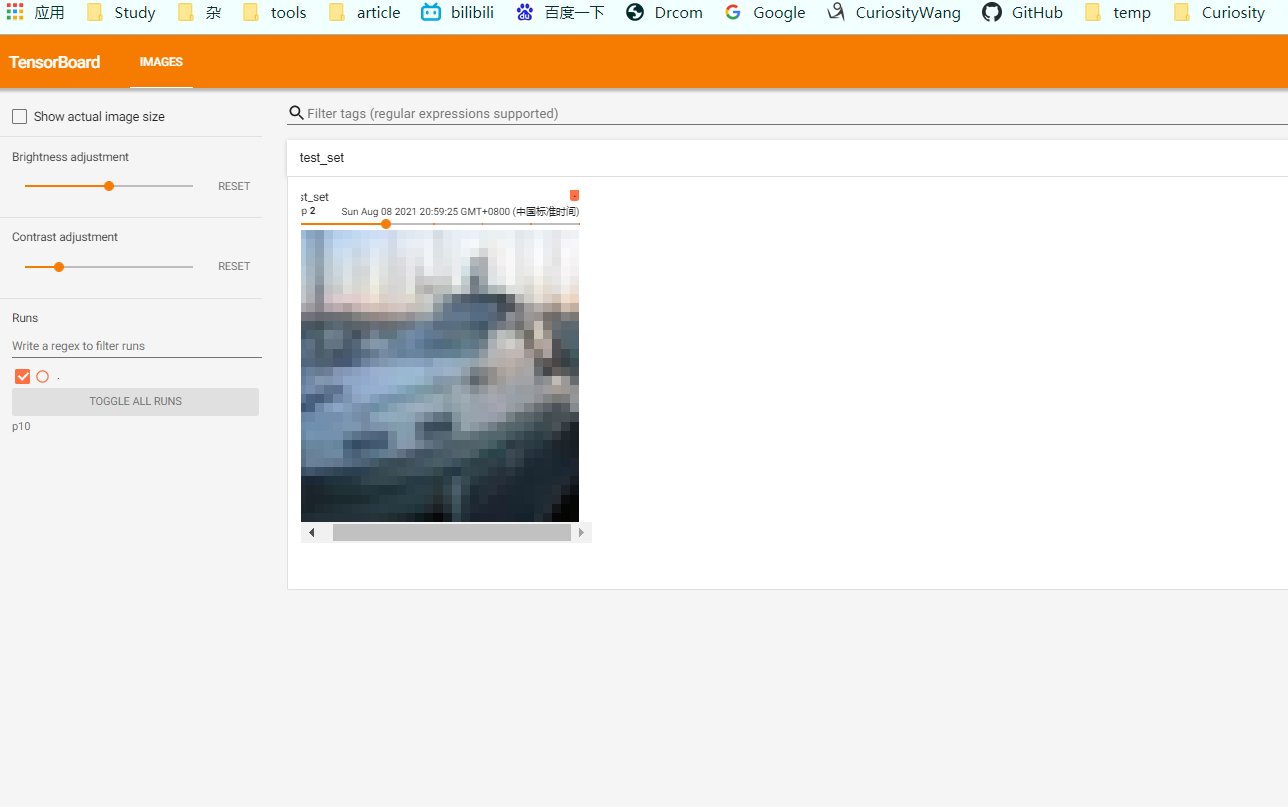
writer = SummaryWriter("p10")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
print(i)
writer.close()
train_set的结构,有点像json
网络搭建
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
基本结构使用
import torch
import torch.nn.functional as F
# With square kernels and equal stride
filters = torch.randn(8, 4, 3, 3)
inputs = torch.randn(1, 4, 5, 5)
output = F.conv2d(inputs, filters, padding=1)
print(output.shape)

- 卷积层
简单神经网络
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64, shuffle=True, drop_last=False)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 定义了一个卷积层
self.conv1 = Conv2d(out_channels=6, in_channels=3, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
tudui = Tudui()
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, targets = data # torch.Size([64, 3, 32, 32])
# 将 imgs 送入神经网络
output = tudui(imgs) # torch.Size([64, 6, 30, 30])
writer.add_images("input", imgs, step)
output = torch.reshape(output, (-1, 3, 30, 30)) # writer 不能显示 6 通道图片
writer.add_images("output", output, step)
print(step)
step = step + 1
writer.close()
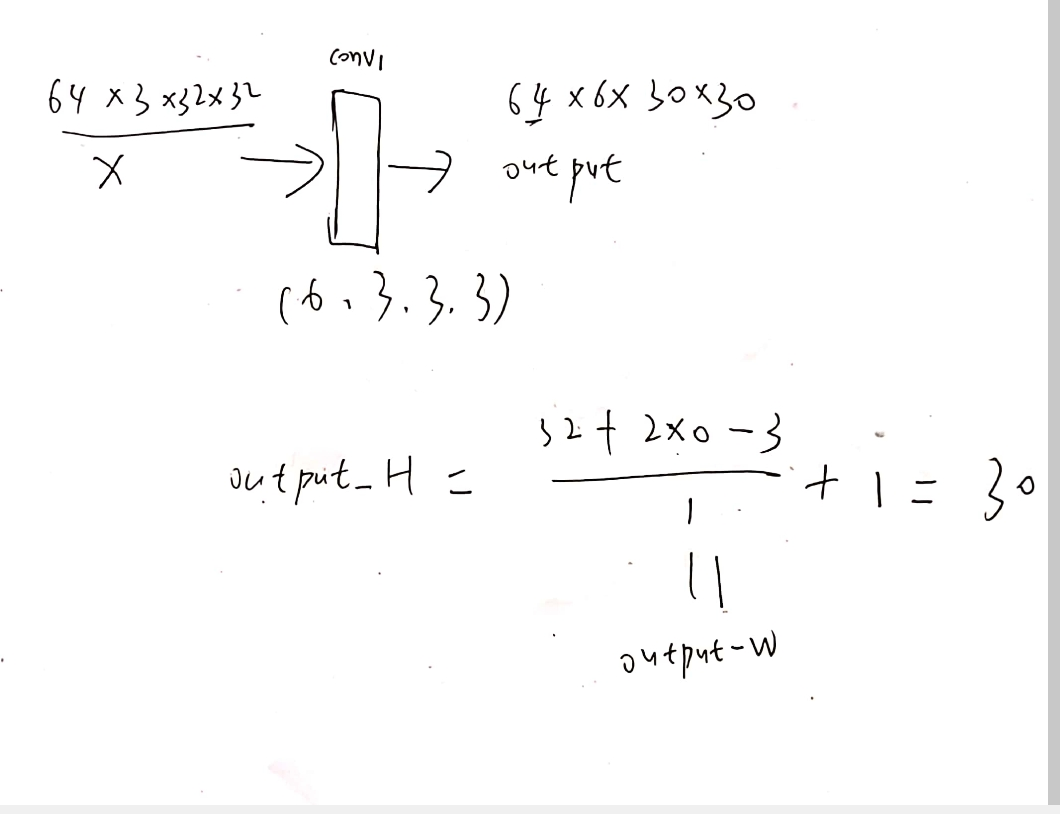
-
池化层

import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
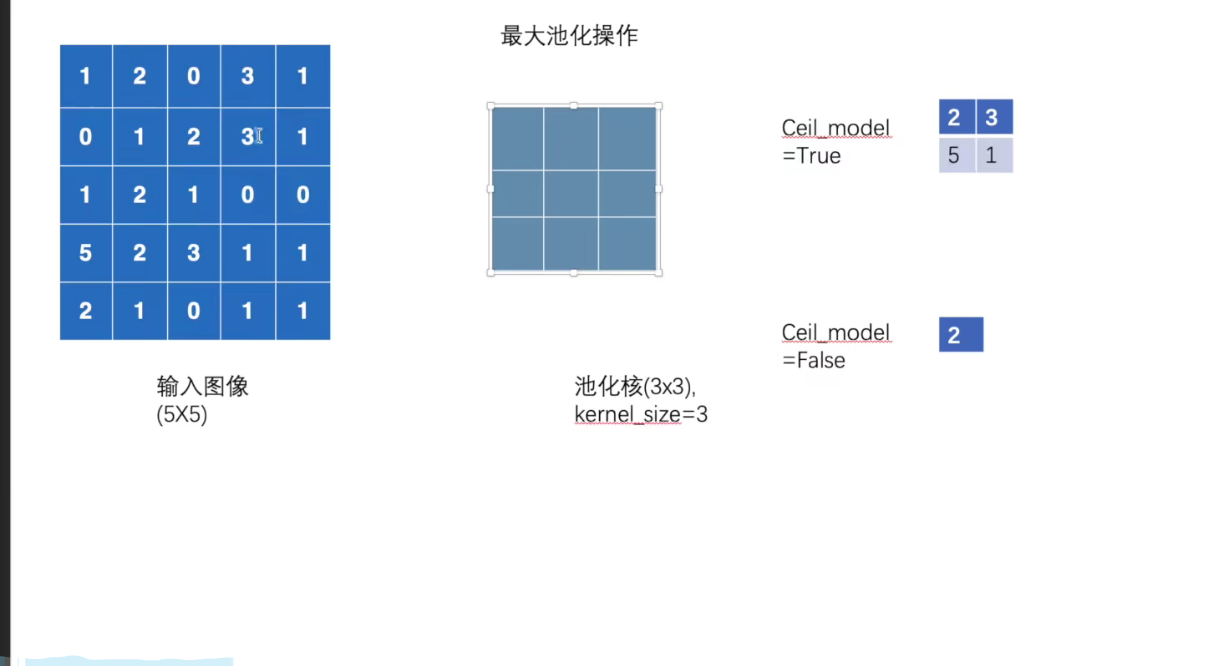
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, input):
output = self.maxpool1(input)
return output
maxpool = Tudui()
writer = SummaryWriter("../logs_maxpool")
step = 0
for data in dataloader:
imgs, targets = data # torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
output = maxpool(imgs) # torch.Size([64, 3, 10, 10])
print(output.shape)
writer.add_images("output", output, step)
step = step + 1
writer.close()
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
- 其他层 drop_out BN RNN and so on

练习神经网络搭建
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
tudui = Tudui()
print(tudui)
## 进行网络的初步测试
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
# 计算图
writer = SummaryWriter("logs")
writer.add_graph(tudui, input)
writer.close()
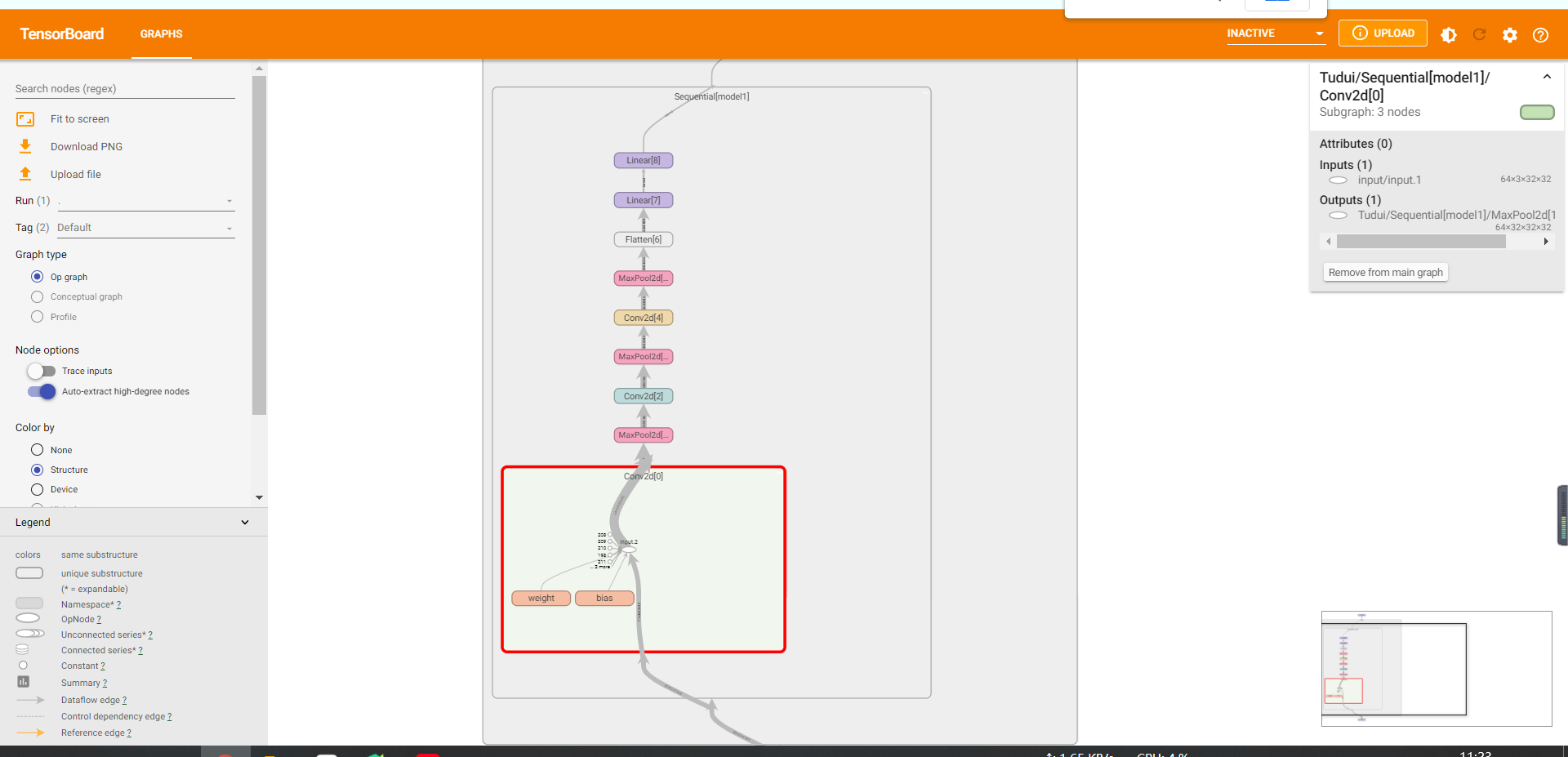
损失函数和梯度

示例:
import torch
import torch.nn.functional as F
from torch import nn
loss = nn.CrossEntropyLoss()
input = torch.randn(3, 5, requires_grad=True)
print("input", input)
target = torch.empty(3, dtype=torch.long).random_(4)
print("target", target)
result_loss = loss(input, target)
print(result_loss )

优化器
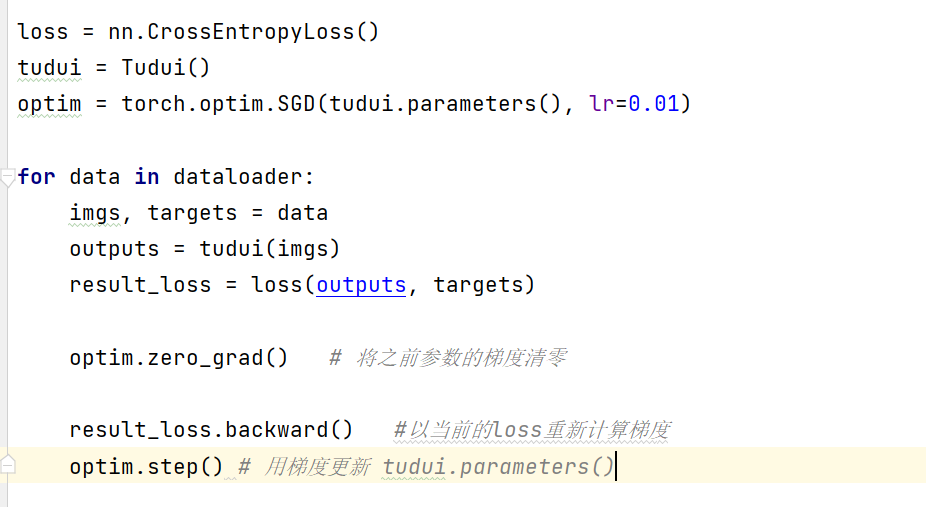
torchvision.models使用
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader
if __name__ == '__main__':
# pretrained=True 加载 实现训练好的参数
vgg16_pretrained = torchvision.models.vgg16(pretrained=True)
vgg16_unpretrained = torchvision.models.vgg16(pretrained=False)
print(vgg16_pretrained)
C:\Users\Curiosity\anaconda3\envs\cs231n\python.exe C:/python_codes/learn_pytorch/VGG/vgg16.py
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
Process finished with exit code 0
打印之后我们可以看到VGG16的网络结构
可以发现最后一层 out_features = 1000 也就是 分类是1000
那如果我想用它求分类是10的数据集怎么办?
vgg16_pretrained.classifier.add_module("add_linear", nn.Linear(1000, 10))
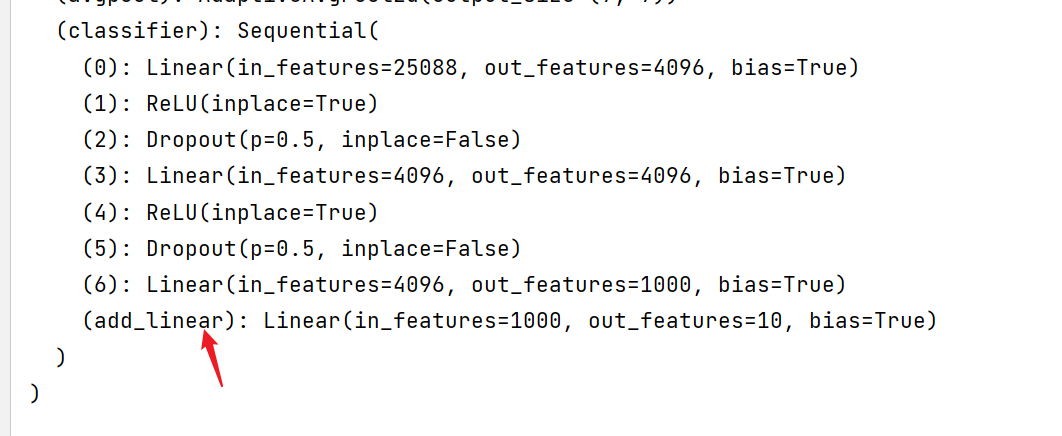
修改某一层:
vgg16_pretrained.features[5] = nn.Linear(1000, 10)
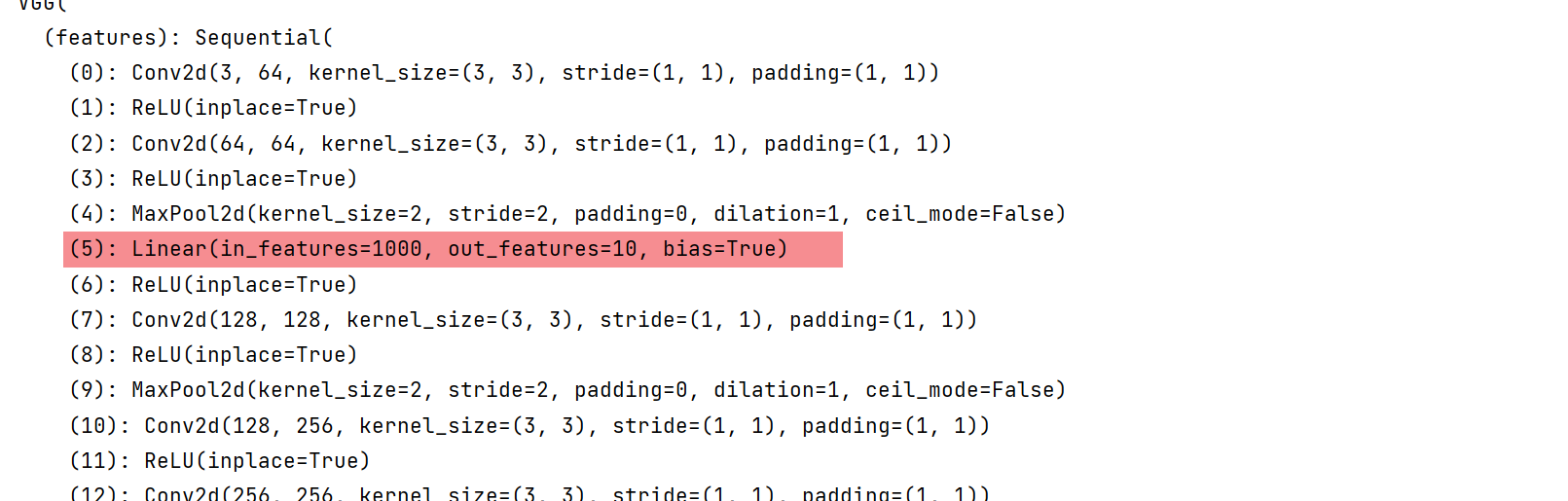
当然此处的修改会导致模型无法使用
模型的保存,导入
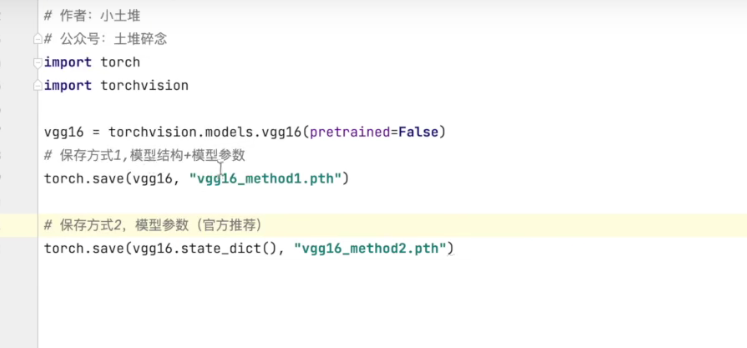

注:方法一在使用的时候,如果该文件中(包括导入的文件)找不到对应的类,则需要重新定义该类.
比如我在a.py保存了一个 module AAA, 想要在b.py使用时,需要先在b中定义 Class AAA.
利用GPU进行训练
method1

将以上数据结构做如下处理:
- 网络模型

- 损失函数

-
数据

method2(更常用)
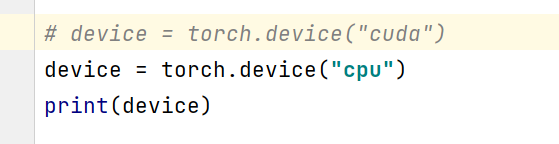
**更优雅的写法 **
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
-
修改数据



Google colab 与 我的 Windows GPU CPU速度对比
此结构:
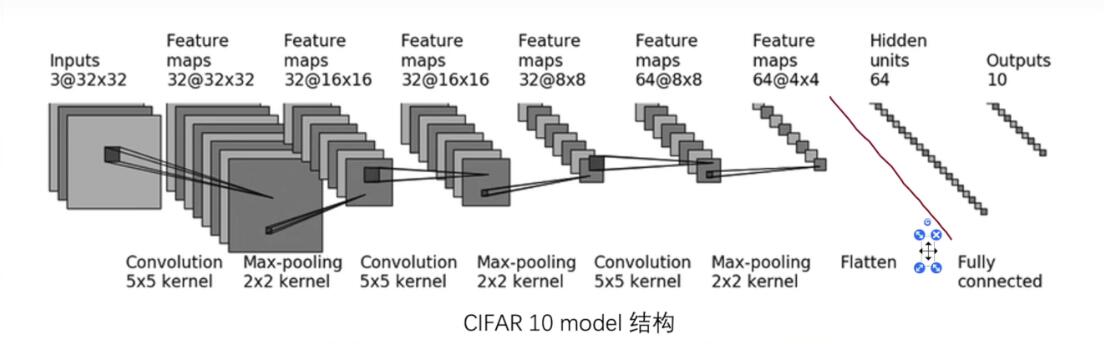
数据量:

运行代码看这一节的附录,按理来说可以计算出这些数据量在整个网络一共有多少次矩阵的相乘....
速度对比:

- 我的电脑显卡数据 GTX1050ti 显存4GB
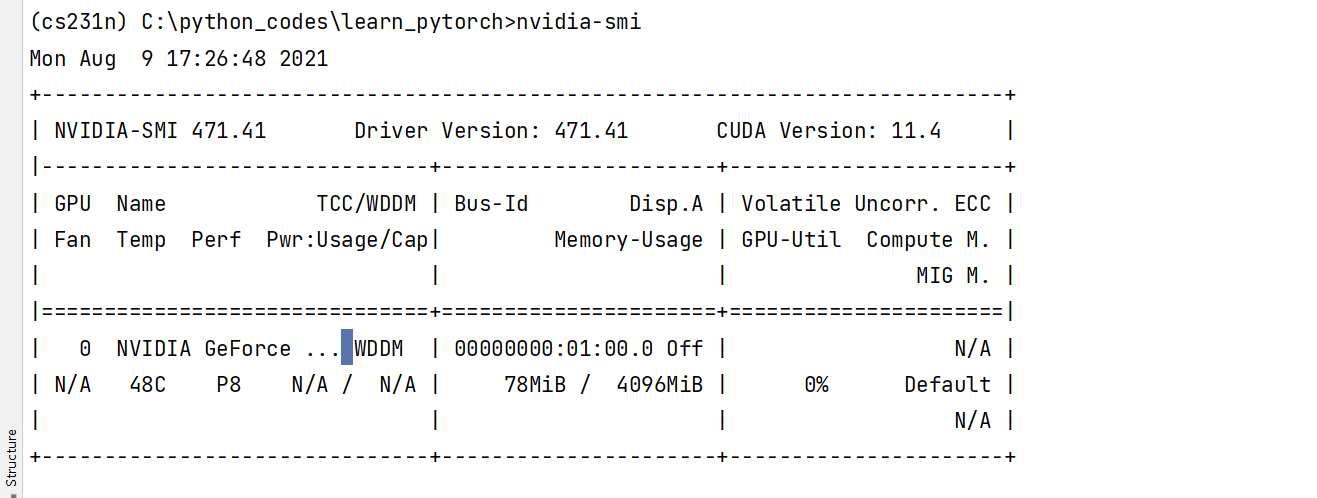
- Google colab显卡数据 特斯拉T4 显存16GB
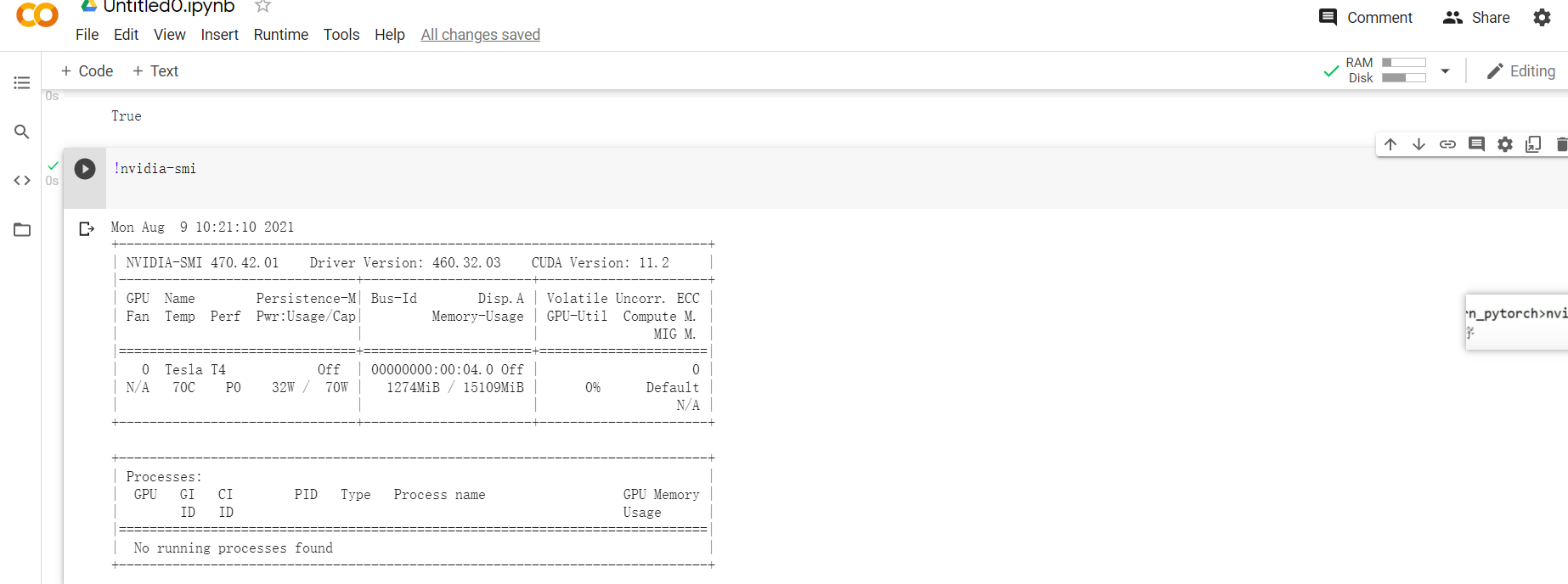
附录代码:(测试GPU CPU速度)
import time
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader
# 搭建神经网络
class Cir(nn.Module):
def __init__(self):
super(Cir, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# device = torch.device("cuda")
device = torch.device("cpu")
print(device)
train_data = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# 训练集 测试集大小
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
Cir_module = Cir()
Cir_module.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
Cir_module.to(device)
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(Cir_module.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 1
# 添加tensorboard
writer = SummaryWriter("/logs")
start = time.time()
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i+1))
# 训练步骤开始
Cir_module.train()
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = Cir_module(imgs)
loss = loss_fn(outputs, targets)
# 梯度更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
end = time.time()
print(end - start)
本文来自博客园,作者:CuriosityWang,转载请注明原文链接:https://www.cnblogs.com/curiositywang/p/15120891.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号