
SSD网络笔记
针对不同大小的目标检测,传统的做法是先将图像转换成不同大小,然后分别检测,最后将结果综合起来,而SSD算法则利用不同卷积层的feature map进行综合也能达到同样的效果。
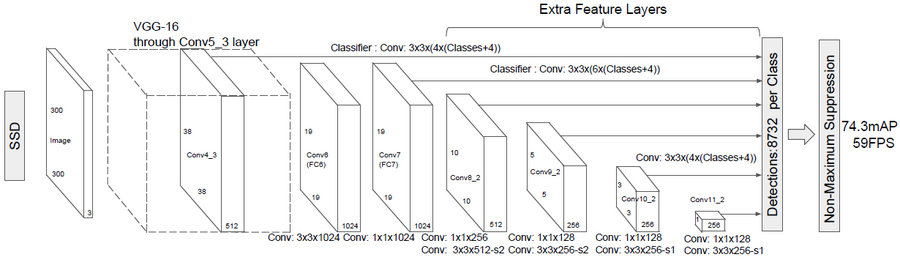

对于不同的卷积层,会把图像分割成不一样的feature map,对于每一个feature map cell都有一系列default box,假设每个feature map cell有k个default box,对于每个default box都需要预测c个类别score和4个offset,那么如果有一个feature map的大小是m*n,也就是有m*n个feature map cell,那么这个feature map就一共有(c+4)*k*m*n个输出,其中score表示预测框是某种类别的得分,offset是预测框针对实际物体的偏移。



关于这里的feature map,你最开始的理解是错误的,你最开始理解为,对于640*640的输入图像(你的华为相机项目里面输入图像是640*640),我们在第一层是把640*640分成了159*159个小格子,每个小格子是4*4,然后在这159*159个小格子上面分别生成默认框,但是实际上不是的,实际上是我们在经过第一次处理把原始的640*640的输入图像提取成159*159的大小,然后针对159*159大小的图像,我们会有159*159个中心点,然后在每个中心点上生成默认框。然后我们再经过第二次处理把特征图提取成了79*79的大小,然后再79*79个中心点上去生成默认框,也就是说我们的输入图像是越来越小的,并不是你之前理解的图像一直是640*640然后分别分成159*159 79*79.
那么default box的scale(大小)和aspect ratio(横纵比)要怎么确定呢,假设我们用m个feature maps做预测,那么对于每个feature map而言,其default box的scale是按以下公式计算的额。


关于默认框的大小,论文里面计算的时候,Smin默认值是0.2,Smax默认值是0.9(这里的0.2 0.9在实际使用的时候是可以修改的,不一定非取0.2 0.9),第一个特征图不参与这个公式的计算,直接用输入图像的大小*0.1,论文中默认的大小是300*300的,所以第一个标准框的大小就是300*0.1=30,然后从第二个特征图开始用这个公式计算,K是1到m,m就是有几个特征图,但是我们华为相机项目里面用到的并不是根据公式计算出来的,而是算法同事给的经验值。
SSD中的softmax层
神经网络的最后一层往往是全连接层+softmax(分类网络)
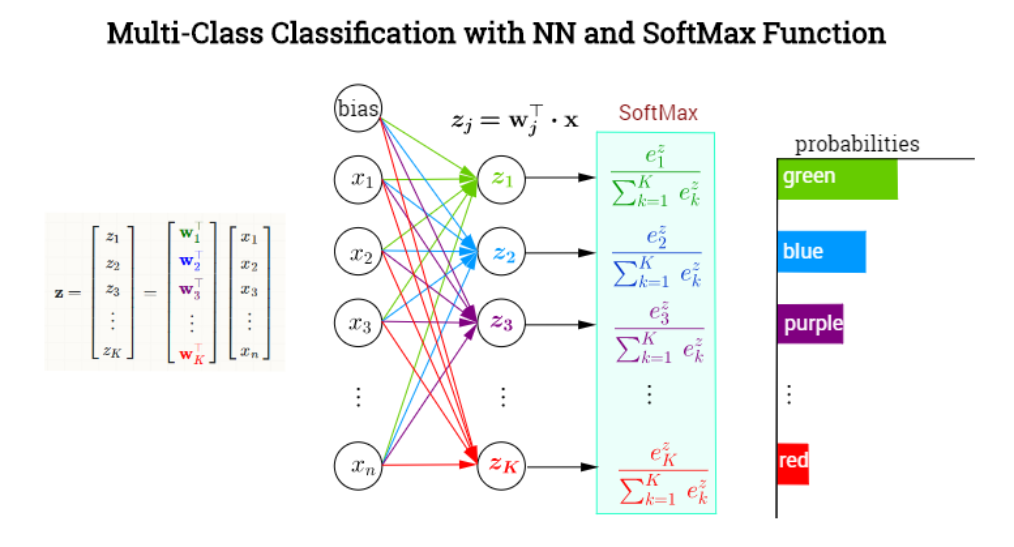


detection out layer:SSD网络的最后一层,用于整合预选框,预选框偏移以及得分三项结果,最终输出满足条件的目标检测框,目标的label和得分。
作者:cumtchw
出处:http://www.cnblogs.com/cumtchw/
我的博客就是我的学习笔记,学习过程中看到好的博客也会转载过来,若有侵权,与我联系,我会及时删除。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号