Python正则表达式
Python正则表达式
参考学习资料:https://www.bilibili.com/video/BV144411A7L4
正则表达式的基本介绍
1.正则表达式是一种标准的匹配方式,可以用简单的字符去言简意赅的体现程序对匹配的需求,例如大小写、是否为空白字符等待,学会正则匹配可以在过滤危险语句的过程中,有效的产生应有的作用。
正则表达式的本质是使用一种规则,去匹配字符串,并且进行检索、替换等处理。
之前的文章里我学习过PHP的正则匹配,与PHP不同的是,Python通过re模块来提供对正则表达式的支持,过程如下:
①:首先将正则表达式的字符串形式编译为Pattern实例。
什么是Pattern实例呢,通缩来说就是匹配的正则表达式,例如如果要匹配名称中含有dogs的字符串,那么它的pattern实例就是re.compile('dog')
②:使用Pattern实例处理文本并且获得匹配结果
③:使用实例获得信息,进行其他操作
import re pattern =re.compile('hello!') match=pattern.match('hello woworldrld!') print(match.group()) #显示结果是hello
注意,如果我们将re.compile里的内容转换为:
pattern = re.compile('woworldrld!')
就会出现报错,报错信息为:
AttributeError: 'NoneType' object has no attribute 'group'
这是因为match函数的匹配问题,match函数只能从头开始匹配,而不能从中间匹配,在没有匹配到元素后又调用了group函数,就会报错。而将match函数替换成research函数就不会出现上述的情况。
以上实际操作一共有两步:先通过编译设置pattern,再通过pattern的内置函数(match、replace..eg)进行匹配
但是也可以将以上步骤进行简化合并:
word=re.findall('world','helloworld') print(word)
正则表达式匹配元素:
| 一般字符 | 作用 | 匹配使用 |
|---|---|---|
| . | 匹配任意换行符'\n'以外的字符,在DOALL1模式中也能匹配换行符 | a.c=abc |
| \ | 转义字符,使得最后一个字符改变原来的意思,如果字符串有字符需要匹配,则可以使用*或者[] | a.c=a\.c |
| [...] | 字符集,对应位置可以是字符集中的任何字符,也可以使用^(异或)运算符去排除其他字符,所有特殊字符在字符集中都失去原有的特殊含义 | a[bc]d=ab |
预定义字符集
| 字符 | 含义 | 样例 | 匹配 |
|---|---|---|---|
| \d | 数字:[0-9] | a\dc | a1c |
| \D | 非数字:^[0-9] | a\Dc | abc |
| \s | 非空字符 | a\sc | a c |
| \S | 非空白字符 [ ^\s} | a\Sc | abc |
| \w | 单词字符[A-Za-z0-9] | a\wc | abc |
| \W | 非单词字符[ ^\w] | a\Wc | a c |
数量词
| 字符 | 含义 | 样例 | 匹配 |
|---|---|---|---|
| * | 匹配前一个字符0次或无限次 | abc* | abcccc|ab |
| + | 匹配前一个字符1次或无限次 | abc+ | abcccc|abc |
| ? | 匹配前一个字符0次或1次 | abc? | ab|abc |
| {m} | 匹配前一个字符m次 | ab{2}c | abbc |
| {m,n} | 匹配前要给字符m到次 | ab{1,2}c | abc|abbc |
逻辑、分组
| 字符 | 含义 | 样例 | 匹配 |
|---|---|---|---|
| | | 代表左右表达式任意匹配一个,但是是先左后右匹配,一旦左边匹配的是正确的,则跳过右边表达式的匹配 | abc|efg | abc、efg |
| (...) | 被括起来的表达式子将作为分组,从表达式左边开始没遇到一个分组的左括号,编号+1,分组表达式将作为一个整体 | (abc){2} | abcabc |
贪婪模式与非贪婪模式:
贪婪模式:尽可能多的匹配---->(.*)
非贪婪模式:尽可能少的匹配---->(.*?)
案例:
匹配B站发布python教程第一页的UP主名称:
import re html=''' 网页源代码 ''' title=re.findall(r'up-name">(.*?)</a',html) #避免重复使用set将title原本的列表形式转换为集合形式 title=set(title) for i in title: print(i)
#根据网页源代码特性,我们发现up主的姓名在"up-name">之后,</a之前,使用非贪婪模式即可匹配出来,但是用贪婪模式就会匹配到很多无关信息,直到最后一个</a
结果演示: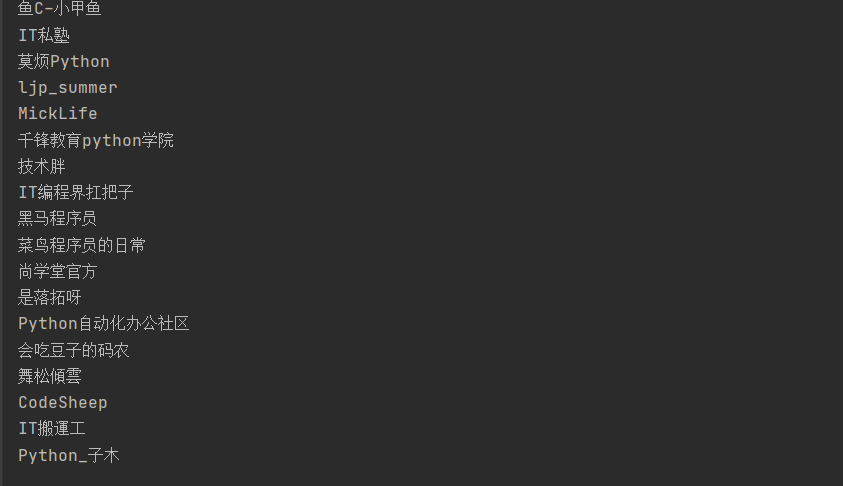

 浙公网安备 33010602011771号
浙公网安备 33010602011771号