JavaSe知识点
JavaSE笔记
Java学习路线图如下
- 首先要学习Java SE,掌握Java语言本身、Java核心开发技术以及Java标准库的使用;
- 如果继续学习Java EE,那么Spring框架、数据库开发、分布式架构就是需要学习的;
- 如果要学习大数据开发,那么Hadoop、Spark、Flink这些大数据平台就是需要学习的,他们都基于Java或Scala开发;
- 如果想要学习移动开发,那么就深入Android平台,掌握Android App开发。
一、面向对象基础
不同版本的Java

-
Java SE:标准版,包含标准的JVM和标准库
-
Java EE:企业版,在SE的基础上加上了大量的API和库
主要针对:web应用、数据库、消息服务等
-
Java ME:针对嵌入式设备的"瘦身版",SE 标准库无法在ME上使用,ME的虚拟机也是"瘦身版".
类路径和jar包
-
classpath的介绍:
classpath是jvm用到的一个环境变量,它用来指示JVM如何搜索class。
classpath就是一组目录的集合,它设置的搜索路径与操作系统有关。 -
classpath的设定方法:
1.在系统环境变量中设置classpath环境变量。
2.在启动JVM时设置classpath变量。
(JVM默认的classpath为当前目录)
3.JVM不依赖classpath加载核心库 -
jar包的介绍:
如果项目中包含多个.class文件,散落在各层目录中,可以将目录打一个包,变成一个文件。
jar包的作用就是如此。 -
jar包的概念:
1.jar包实际上就是一个zip格式的压缩文件,而jar包相当于目录。
2.如果要执行一个jar包的class,就可以把jar包放到classpath中。
3.JVM会自动在hello.jar文件里去搜索某个类。 -
创建jar包:
- 在资源管理器中,找到正确的目录,点击右键压缩文件夹,将.zip文件改为.jar文件即可。
(注意:jar包里的第一层目录,不能是bin) - 可以配置/META-INF/MANIFEST.MF纯文本文件,可以指定Main-Class和其他信息。
- 3.jar包还可以包含其他jar包,需要在MANIFEST.MF文件里配置classpath。
- 在资源管理器中,找到正确的目录,点击右键压缩文件夹,将.zip文件改为.jar文件即可。
数据类型
-
整数类型:byte,short,int,long
-
浮点数类型:float,double
-
字符类型:char
-
布尔类型:boolean
Java是高精度强类型语言
整型表示范围
1B byte: -128 ~ 127
2B short: -32768 ~ 32767
4B int: -2147483648 ~ 2147483647
8B long: -9223372036854775808 ~ 9223372036854775807
备注:Java中整型默认使用int进行计算
var关键字
这个时候,如果想省略变量类型,可以使用var关键字:
var sb = new StringBuilder();
备注:
类型转换
//数据类型精度表:byte-short-(char)int-long-float-double
//1 自动类型转换情况1: 高精度变量=低精度数据
//2 自动类型转换情况2: byte/short/char变量=int常量值
//3 强制类型转换: 低精度变量=(低精度变量类型)高精度数据
//4 多类型运算结: 运算后结果的数据类型取决于精度最高的数据
不规则数组
/*
在java中,多维数组可以理解为,数组的元素是一个数组
所以可以使用下列方式声明不等宽的二维数组
*/
int[][] a = new int[N][];//初始化二维数组时可以只写行数,而不写列数
int[0] = new int[M];
...;
int[N-1] = enw int[K];
流程控制
输入和输出
-
Scanner
一个可以解析基本类型和字符串的简单文本扫描器
Scanner in = new Scanner(System.in);备注:System.in系统输入指的是通过键盘录入数据
输入待解决问题:
- Scanner调用Scanner中的hasNextInt()判断获取的输入是否为整型?
-
System.out.printf
把数据显示成我们期望的格式,就需要使用格式化输出的功能。
public class Main { public static void main(String[] args) { double d = 3.1415926; System.out.printf("%.2f\n", d); // 显示两位小数3.14 System.out.printf("%.4f\n", d); // 显示4位小数3.1416 System.out.printf("%Ns\n",s);//显示N长度的字符串,长度不够截取;长度不足,左对齐;加负号,右对齐。 } }备注:printf中似乎不可用字符串拼接。
思考:
- 输出指定格式时不可使用字符串拼接?
分支和循环
-
switch
只适用于穷举法;不使用于范围判断
- switch表达式的数据类型仅限于:int+String+enum
- break的作用是 跳出switch结构
- 没有碰到break语句前,会一直执行分支的语句
-
for
一般用于指定次数的循环。常用于遍历数组。
for(int i=0;i<n;i++){ 循环指定语句="" }="" ~~~=""> 备注: -
while
一般用于位置次数的循环,常用于逻辑判断结束循环。
while(条件语句){ //循环指定语句 } while((n--)>0){}//循环n次 while((--n)>0){}//循环n-1次备注:
-
break为跳出当前循环。
-
continue为跳过本次循环,进入下一次循环,循环体中,continue后面部分的内容就不执行了。
顺序排序&冒泡排序
/*冒泡排序
思想:每次选出无序元素中的最值,排到无序元素序列的队尾,
实现:已经排到队尾的元素为有序元素,后续可以不用遍历,第i次遍历a.length-i-1次。
*/
for(int i=0;i<arr.length-1;i++){ 共arr.length-1行="" for(int="" j="0;j<arr.length-i-1;j++){//让arr[j]作为前面的元素" arr[j+1]是后面的元素="" if(arr[j]<arr[j+1]){="" int="" k="arr[j];arr[j]=arr[j+1];arr[j+1]=k;" }="" *顺序排序="" 思想:每次取当前位置的元素与后续所有元素比较,选出最值放入当前位置。="" 实现:从i+1开始遍历,a.length-1结束。="" *="" i="0;i<arr.length-1;i++){//共arr.length-1行" arr[j]作为当前元素后面的元素="" if(arr[j]<arr[i]){="" ~~~="" ###="" 插入排序="" ~~~java="" **="" 思想:从前往后遍历数组,但是从后向前进行比较="" 实现:将第i各元素,倒着和前面的元素比较和挪移,最后放入。="" public="" static="" void="" sort(int[]="" a){="" for="" (int="" <="" a.length;="" i++)="" {="" temp="a[i];//保存当前元素" j;="" (j="i-1;">= 0; j--) {
if (a[i] < a[j]) {
a[j+1] = a[j];//将元素向后挪移
}}
a[j+1] = temp;//将元素插入
}}
递归
概念:方法自己调用自己
注意事项:
- 方法递归必须有出口;
- 斐波那契数列
1 1 2 3 5 8 ...
public static void main(String[] arg){
for(int i=0;i<10;i++){
System.out.print(Shu(i)+" ");
}System.out.println();
}
public static int Shu(int n){
if(n <= 2){
return 1;
}else{
return Shu(n-2) + Shu(n-1);
}
}
权限修饰符
修饰符:让被修饰者具有一些本来不具有的特征的关键字
修饰符分类:范围修饰符 静态修饰符 常量修饰符 同步修饰符
- 范围修饰符
| 名称 | 本类 | 本包 | 子类 | 非包 | 范围总结 |
|---|---|---|---|---|---|
| public | √ | √ | √ | √ | 整个项目 |
| protected | √ | √ | √ | × | 本包及其他包子类 |
| 默认范围 | √ | √ | × | × | 本包 |
| private | √ | × | × | × | 本类 |
注:由该类创建出的对象,在该类中可以直接获取类中的私有属性。
-
final
- 修饰字段值:常量,一旦赋值不可更改、没有默认初始值。
- 修饰方法:不可被重写。
- 修饰类:类不可被继承。
- 修饰引用变量,表示引用不可变,但是引用的内容可变。
- 被final修饰的方法,JVM会尝试将其内联,以提高运行效率。
- 被final修饰的常量,会在编译阶段会存入常量池。
从Java 8+开始,只要局部变量事实不变,那么final关键字可以省略
-
static(静态)
- 特点:
- 使用静态修饰的成员不会随对象变化。
- 修饰的成员属于类,所有对象共享使用。
- 静态方法:
- 可以不用实例化,直接调用方法。
- 可以访问静态成员,不可以访问非静态成员。
- 静态方法中不能使用this关键字。
- 静态代码块
- 当第一次用到本类时,静态代码块执行唯一的一次。
- 一般用于类中静态成员的初始值。
- 修饰类(静态类):
- 全局唯一,任何一次的修改都是全局的影响。
- 只加载一次,优先于非静态。????
- 生命周期属于类级别,从JVM加载开始到JVM御载结束。
- 特点:
-
abstract(抽象)
-
修饰对象:类、方法
-
修饰效果:
-
抽象方法不能有方法体
-
抽象方法的类必须是抽象类
-
抽象类不能创建对象 但是可以定义引用
-
子类继承抽象类 必须实现所有抽象方法
或者 定义为抽象类
-
-
方法
方法是一个实现特定功能的代码块,又名函数。
方法的作用:代码的复用
方法的本质:就是一个功能
参数传递
/*
当调用方法传递参数时,根据传递类型不同,会产生不同的效果,为了方便理解,
可以将参数传递等效为代码操作。
*/
public void method(int a);//等效代码:int a = N;
//当a发生改变时,不会影响到N的值。
public void method(int[] arry);//等效代码:int[] arry = Arry[];
//因为arry和Arry指向同一片地址,所以对地址的数据进行修改时,会影响到双方。
public void method(String str){
str = new String();
}
/*
当在方法中调用了new操作时,会将传递的参数引用地址覆盖,
所以不会影响到原地址值。
*/
- 不定参数(JDK1.8的新特性)
public void method(int... a);
public void method(double d,int... a);
/*
1.使用(类型... 名称)传递不确定个数的某一类型变量。
2.参数接收后,会自动封装为一个数组。
3.当多个类型参数并列时,将此格式放在最后
*/
返回值
1. return的作用:1 把方法的返回值返回给调用者 2 结束方法
方法重载
-
特点
1 必须是同一个类
2 方法名必须相同
3 方法参数列表必须不同:
参数个数不同,参数类型不同,参数顺序不同 -
使用场景
几个功能一致,只是参数列表不同;
功能基本一致,满足不同参数列表的需求;
面向对象思想
类和对象
类可以看做是对象的模板,通过类这个模板,可以创建出无数个对象。
类中拥有的字段值和方法,对象都可以访问。
-
类中包括的内容:
-
成员变量——实例化对象可以使用,类不可使用。
-
成员方法——实例化对象调用,类不可调用。
-
静态字段——类可以调用,无序实例化。
-
静态方法——类可以调用,无需实例化对象。
如果一个方法没有涉及实例,尽量成静态方法
-
内部类
-
代码块
- 构造代码块:一般用于给对象的实例变量初始化
- 静态代码块:只有在类加载时执行一次,一般用于给类变量初始化
-
-
成员变量和局部变量
- 概念解释:
- 相同之处:
- 不同之处:
- 作用域不同:前者在对象中,后者在方法中。
- 默认值:前者有默认值,后者需显式赋值。
- 修饰符:
- 前者:范围修饰 静态修饰 final修饰
- 后者: final修饰
-
构造方法/构造器
- 构造方法没有返回值,不用void标识
- 构造方法不能被对象调用
对象创建
-
加载类;
为类创建静态区域,用来记载类的静态成员
执行静态代码块、为静态变量赋值等操作。 -
定义引用;
-
创建对象:new调用构造器:
-
内存中划分区域,创建对象。
-
调用父类构造器,将父类的实例成员加载进子类对象的内存中。
1.构造方法不能加载进对象内存中;
2.创建对象时只加载普通方法的方法声明,不加载方法体:调用时才加载 -
执行调用的父类构造器中的语句。
-
调用子类构造器,将子类的实例成员加载进子类对象内存中。
-
隐藏子类对象从父类继承但被重新定义的成员。
-
执行子类构造器中的语句。
-
-
让引用指向此对象
抽象类
使用abstract关键字修饰的类
- 抽象类有构造方法,不是用来创建本类对象,是用来帮助创建子类对象的。
- 抽象类中可以没有抽象方法。
接口
使用Interface关键字声明,与class同级
-
概念:内部全是抽象方法的抽象类
接口和类不是同一种形态
-
作用:
- 增加程序的扩展性
- 提高代码的复用性
- 降低模块之间的耦合度
-
特点:
- 成员变量默认修饰符:public static final
- 没有构造方法,不能创建对象,但是可以引用对象
- 支持多继承,不影响继承直接父类
-
使用:implements关键字
封装
-
作用:
- 使外部代码可控制的访问内部的代码。
- 解耦:外部调用不需要知道内部的实现,只提供内部所需的数据等。
-
实现:
使用范围修饰符限制成员的可见性,设置外部访问的方法接口。
一般使用private关键字,限制只能本类访问
继承
-
特点
-
重名问题(向上转型)
-
变量重名
- 直接通过子类对象访问成员变量:
等号左边是谁,就优先用谁,没有则向上找。 - 间接通过成员方法访问成员变量:
该方法属于谁,就优先用谁,没有则向上找。
- 直接通过子类对象访问成员变量:
-
方法重名
-
创建的对象是谁,就优先用谁,如果没有则向上找
局部变量:直接用变量名称
本类变量:this.变量名称
父类变量:super.变量名称
-
-
super- 子类构造方法会默认使用
super()调用父类无参构造(隐式) - 若父类没有无参构造,则需要显式调用有参构造
super(参数列表)
- 子类构造方法会默认使用
-
-
方法重写
使用new创建的是哪个对象,实际执行时,就调用哪个对象的方法。
(多态)- 子类方法的返回值必须小于等于父类方法的返回值范围
- 子类方法的权限必须大于等于父类方法的权限修饰符
多态
-
概念:相同类型的对象,调用同一方法(参数列表也相同,区别方法重载),在实际运行时,可能会执行出不同的结果。
-
实现:
- 前提前提条件是继承、重写、向上转型
-
特点:多态特点
-
应用:
- 参数列表类型:传递子类
- 成员变量类型:赋值子类
- 返回值类型:返回子类
- 数组元素类型:存入多种子类对象
-
向上转型
定义父类引用指向创建的子类对象。
特点:除了重写的方法,其他的和父类对象完全一致
参考:重名问题
-
向下转型
使用InstanceOf判断转型是否可以成功
工具类
学习类:
1 此类作用
2 此类常用的方法
3 此类相关的面试题和练习
Math类
static double pow(n1,n2);//返回n1的n2次方
static E max(E n1,E n2);//返回最大值
static double PI = 精度范围内的圆周率;//Math.PI
static double E = 比任何其他值都更接近 e(即自然对数的底数)的 double 值。;
//求近似值
static double ceil(double num);//向上取整
static double floor(double num);//向下取整
static double long round(double num);//四舍五入
//求次方
static double cbrt(double a);//开三次方
static double sqrt(double a);//开二次方
System类
static void gc() :启动垃圾回收器
static void exit(int status) :虚拟机退出:参数为0正常退出 非0异常退出
static long currentTimeMillis() :获取当前时间的毫秒值:参照历元(1970/1/1 0:0:0)
Arrays类
static void sort(T[] a,Comparator<!--? super T--> c);//按比较器c对数组a进行排序
static void sort(数组);//按照默认升序(从小到大)对数组的元素进行排序
//自定义类型需要实现Comparable或这Comparator接口
static <t> List<t> asList(T... a); //由参数数组获取一个集合
static String toString(booleanp[] a); //获取参数数组的字符串
static String deepToString(Object[] a); //打印二维数组
static void fill(booleanp[] a,boolean val); //使用val填充数组a
Objects类
static boolean equals(Object a,Object b);
/*一般用来比较引用类型变量
1.如果参数彼此相等,则返回true,否则返回false。
2.如果两个参数都为null,则返回true。
3.如果第一个参数不为null,则通过使用此方法的第二个参数调用第一个参数的equals方法来确定相等性。否则,返回false。*/
static int hash(Object... values);
/*用来计算多个对象关联的哈希值*/
Collections类
public static <t extends="" comparable<?="" super="" t="">>
void sort(List<t> list);
/*
1.列表中的所有元素必须实现Comparable接口,
1.该方法是对传入list直接进行排序,而不是返回一个新的有序list
*/
static void fill(List list,T obj); //使用参数对象obj替换list中的所有元素
static T max(Collection coll); //获取最大的元素
static T min(COllection coll); //获取最小的元素
static T max(Collection coll,Comparator comp); //按指定比较器 获取最大的元素
static T min(Collection coll,Comparator comp); //按指定比较器 获取最小元素
static void reverse(List<!--?--> list); //反转集合
static void shuffle(List<!--?--> list); //随机洗牌
static void sort(List<t> list); //排序
static void sort(List<t> list,Comparator<!--? super T--> c);//按参数比较器 排序
static void swap(List<!--?--> list,int i,int j);//下标i和下标j处的元素互换位置
备注:区别Collection和Collections
常用类
String类
-
字符串的特点
- 字符串的内容永不可变
- 正是因为字符串不可改变,所以字符串是可以共享使用的
- 字符串效果上相当于是cahr[]字符数组,但是底层原理是byte[]字节数组
-
字符串常用创建方式:

public String();//"" public String(char[] array);//根据字符数组创建字符串 public String(byte[] array);//根据字节数组创建对应字符串- java1.7后,增加了字符串常量池,用于存放不使用new关键字创建的String,池中的字符串可以被多个字符串变量“指向”。
- 使用new关键字创建的字符串不在字符串常量池中,会在额外创建一个新的字符串,即使两个字符串内容相同。
-
String的常用方法
public int length();//获取字符串中含有的字符个数 public String concat(String str);//将当前字符串拼接成为新字符串,并返回 public char charAt(int index);//获取指定索引位置的单个字符(索引从0开始) //查找参数字符串在本字符串当中首次出现的索引位置,如果没有返回-1值 public int indexOf(String str); public int lastIndexOf(String str);//查找最后一次出现的位置 public boolean contains(CharSequence s);//判断是否包含指定的子串 int compareTo(String anotherString);//比较字符串大小,大则正数,相等0,小则负数 int compareToIgnoreCase(String str);//忽略大小写 /*字符串截取*/ public String substring(int index); public String substring(int begin,int end); public CharSequence subSequence(int begin,int end); //[begin,end),包含左,不包含右边 public byte[] getBytes();//返回字符串底层的字节数组 public byte[] getBytes(String charsetName);//使用指定编码集 public char[] toCharArray();//返回字符数组 public String replace(CharSequence oldString,CharSequence newString); //将字符串中的对应字段替换为新的字段,并返回替换完后的新的字符串。 //可以替换多次出现的字段 public String[] split(String regex);//按照参数的规则将字符串切割成为若干部分 /* 字符串切割: 如果开头或者中间是连续多个“刀”,会形成多个空字符串 但如以多个连续“刀”结尾不会形成空字符串 */注:regex是一个正则表达式,使用特殊符号时,需要加上转义字符
例:"\.",表示使用.来切割字符串 -
String的版本特性
从Java 13开始,字符串可以用"""..."""表示多行字符串(Text Blocks)了。
public class Main {
public static void main(String[] args) {
String s = """
SELECT * FROM
users
WHERE id > 100
ORDER BY name DESC
""";
System.out.println(s);
}}
备注:String为引用类型
Object类

- equals
public boolean equals(Object obj);//
euqals方法编写的规则
- 自反性(Reflexive):对于非
null的x来说,x.equals(x)必须返回true;- 对称性(Symmetric):对于非
null的x和y来说,如果x.equals(y)为true,则y.equals(x)也必须为true;- 传递性(Transitive):对于非
null的x、y和z来说,如果x.equals(y)为true,y.equals(z)也为true,那么x.equals(z)也必须为true;- 一致性(Consistent):对于非
null的x和y来说,只要x和y状态不变,则x.equals(y)总是一致地返回true或者false;- 对
null的比较:即x.equals(null)永远返回false。
- hashCode
public int hashCode();//返回一个hash值,每次运行可能不一样
备注:
枚举类
enum定义的类型就是class
- 特点:
- 定义的enum类型总是继承自java.lang.Enum,且无法被继承;
- 只能定义出enum的实例,而无法通过new操作符创建enum的实例;
- 定义的每个实例都是引用类型的唯一实例;
- 可以将enum类型用于switch语句。
public class T1 {
public static void main(String[] args) {
System.out.println(
Month.JAN.name()+":"//输出实例名称
+Month.JAN.dayValue+":"//输出实例的属性
+Month.JAN.ordinal());//输出实例的序号0~n,会随顺序改变
//输出结果 JAN:31:0
}}
enum Month{
JAN(31),FEB(28);//枚举类实例
//实例的属性,一般声明为final类型
public final int dayValue;
//私有构造方法,外部不可调用
private Month(int dayValue) {
this.dayValue = dayValue;
}}
包装类
| 基本类型 | byte | short | int * | long | double | float | char* | boolean |
|---|---|---|---|---|---|---|---|---|
| 包装类型 | Byte | Short | Integer | Long | Double | Float | Character | Boolean |
-
包装类解决的问题:包装类对象、字符串、基本数据类型常量之间的相互转换
-
从JDK 1.5+开始,支持自动装箱、自动拆箱。
自动装箱:基本类型-->包装类型
自动拆箱:包装类型-->基本类型
-
类型最值
包装类.MAX_VALUES;//获取类型最大值 包装类.MIN_VALUES;//获取类型最小值 //具体操作如下: int Max = Integer.MAX_VALUES; int Min = Integer.MIN_VALUES; -
Integer
//构造方法 public Integer(int value);//基本数据转包装 public Integer(String s);//字符串转包装,异常NumberFormatException //普通方法 String toString();//包装转字符串 //静态方法 static int parseInt(String s,*int radix);//可以指定进制,也可以不指定 /*parse方法为大多数包装类的类型转换方法*/ static valueOf(int value);//基本数据转包装,[-128,127]指向常量池 static valueOf(String s);//字符串转包装 static valueOf(String s, int radix);//使用指定的进制radix解析字符串s static String toBinaryString(int i);//2进制字符串 static String toHexString(int i);//16进制字符串 static String toOctalString(int i);//8进制字符串 static String toString(int i,*int radix);//指定进制的字符串 -
character
//Character中的特有方法 一般用于判断 static boolean isDigit(char ch);//判断是否是数字字符 static boolean isLetter(char ch);//判断是否是(字母/汉字) static boolean isLetterOrDigit(char ch);//判断是否是上述两者 static boolean isLowerCase(char c);//判断是否是小写字母 static boolean isUpperCase(char c);//判断是否是小写字母 static char toLowerCase(char c);//获取参数字符小写 static char toUpperCaser(char c);//获取参数字符大写
进阶类
内部类
概念:定义在类内部的类
好处:
- 内部类的继承关系不受外部类影响;
- 成员内部类可以无条件访问外部类的所有属性;
-
成员内部类
特点: 1. 可以无条件的访问外部类的属性和方法; 2. 但是外部类想要访问内部类,必须要创建一个内部类对象,然后通过对象访问内部类; 内部类想要创建对象,必须实例化一个外部类对象; 3. 不能包含静态属性或方法; 访问权限: private:仅外部类可访问; protected:同包下或继承类可访问; default:同包下可访问; public:所有类可访问; 用法: 1. 创建内部类 内部类寄身于外部类,创建内部类对象就必须先创建外部类对象; 外部类名.内部类名 name = 外部对象.new 内部类(参数列表); 2. 内部类调用外部类 若同名,则 外部类名.this.属性/方法名 调用外部类的成员; -
局部内部类
特点: 1. 局部类和局部变量类似,不能使用范围权限修饰符和 static; 2. 作用域仅限于方法内部; 3. 不能包含静态属性或方法; 4. 只能访问所属方法的final变量; 和声生命期有关 用法: 1. 在作用域中基本随意使用; -
匿名内部类(最常用,Lambda表达式有关)
特点: 1. 没有构造方法; 2. 只能访问外部类的final变量; 3. 只能使用唯一一次,一般用于创建对象,或传参; 使用: 1. 在方法参数处直接使用new创建类; 接口名称 name = new 接口名称{方法体}; -
静态内部类
特点: 1. 只能调用外部类的静态属性或方法; 2. 不依赖外部类,可以不用外部类对象实例创建对象; 使用:
StringBuffer类
String:字符串常量,字符序列不能更改
StringBuffered和StringBuilder:字符串缓冲区,字符序列可以更改
相同之处:都可描述字符串
不同之处:String,自付出啊常量 字符串对象一旦床架 字符序列不能更改
StringBuffer和StringBuilder,都是字符串缓冲区,字符串长度和字符序列都可以更改
StringBuffer和StringBuilder都是字符串缓冲区 API兼容(方法完全相同)
版本不同:StringBuilder 1.5 StringBuffer 1.0
是否同步:StringBuilder线程不同步,只支持单线程,线程不安全效率高
StringBuffer线程同步,支持多线程,线程安全,效率低
以StringBuffer为例:
//构造方法:
StringBuffer()://创建一个初始序列为空的字符串缓冲区对象
StringBuffer(String str)://创建一个与初始字符串相同序列的字符串缓冲区对象
//普通方法(特有方法):
StringBuffer append(Object obj)://把参数对象对应的字符串添加到末尾
StringBuffer delete(int start,int end)://删除start到end-1处的字符
StringBuffer deleteCharAt(int index)://删除index下标处的字符
StringBuffer insert(int offset,Object obj)://把obj对应的字符串插入到offset下标处
StringBuffer replace(int start,int end,String str)://使用str替换start到end-1位置处的子串
StringBuffer reverse()://字符串倒序排列
void setCharAt(int index,char ch)://设置index下标处的字符为ch
String toString()://获取当前字符串缓冲区相同序列的字符串对象
-
Random类
- 用来创建伪随机数。根据指定的初始种子,产生的随机数列是完全一样的。
- 如果不给定种子,就使用系统当前时间戳作为种子,因此每次运行时,得到的伪随机数列就不同。
-
SecureRandom类
//创建线程安全的随机数。 SecureRandom sr = new SecureRandom(); System.out.println(sr.nextInt(100));SecureRandom无法指定种子,它使用RNG(random number generator)算法。
二、异常
注意事项
//概念:用于描述程序运行出现非正常情况的一组类a
//throws和throw的区别
//相同之处
都是异常处理的关键字
//不同之处
1 位置不同:throws用在方法声明上 throw用在方体中
2 后面跟的内容不同:throws后面跟多个异常类型 throw后面跟一个异常
3 作用不同:throws 用在方法声明上 来表示当前方法可能产生哪些异常
一旦产生这些异常 异常会被封装为对象 抛给调用者
throw 用在方法体中 表示程序出现指定的异常
异常实例
ClassCastException : 向下转型时:容易出现的异常;
NullPointerException : 空指针异常;
StringIndexOutOfBoundsException : 字符串下标越界异常;
ArrayIndexOutOfBoundsException : 数组下标越界异常;
IndexOutOfBoundsException : 集合下标越界异常;
ArithmeticException : 算术逻辑异常;
ParseException : 字符串格式转换异常;
ClassCastException : 类型转换异常;
NumberFormatException : 数据输入格式异常;
UnsupportedEncodingException : 编码集名称异常;
ConcurrentModificationException : 并发修改异常;
异常体系

-
Throwable是异常体系的根,他有两个体系:
-
Error:严重的错误,通过java代码逻辑不能处理的严重错误。
-
Exception:则是运行时的错误,它可以被捕获并处理。
-
-
Exception两大分支:
- RuntimeException,以及他的子类:
运行时异常,未检查异常。
出现频率高,编译器不检查,默认抛出,可以不用处理。 - 非RuntimeException(包括IOException等等):非运行时异常
已检查异常,编译时异常。
出现频率低,编译器检查,在代码中必须显示处理。
- RuntimeException,以及他的子类:
-
异常体系特点
- 异常类都必须直接或间接的继承Throwable类
- 子类都是以父类名字为后缀
- 异常的子类 常用方法都继承与Throwable类
区别是类名和异常原因
-
Throwable常用方法
//构造方法 Throwable();//构造一个将 null 作为其详细消息的新 throwable。 Throwable(String message);//构造带指定详细消息的新 throwable。 Throwable(String messagem,Throwable throwable);//创建详细信息和原因的异常 //普通方法 String getMessage();//获取详细信息 void printStackTrace(); Throwable getCause(); String toString();//返回异常类型:详细信息
异常处理
-
抛出异常
//抛出机制 在方法声明上加throw PareException 作用 1 当前方法可能出现异常:ParseException 2 如果当前方法出现异常ParseException 异常对象被抛给方法的调用者 去处理 -
捕获异常
try{ ... }catch(Exception e){ ... }finally{ ... } 1. 若 try 代码块出现异常 try中的其他代码块不再执行 而是执行对应的catch代码块; 2. 捕获父类异常的 catch 代码块 必须放在捕获子类异常 catch 代码块的后面; 3. 如果在 try 或者 catch 代码块中 停止虚拟机 finally 代码块将不再执行; 重点: 关于 return 的理解:return执行分为两步,返回值,结束方法; return 一旦被调用后,就会将值返回,执行完finally语句后再结束方法;
自定义异常
根据项目需求 定义jre中没有的异常
注意事项:1 异常类必须直接或者间接继承Throwable
2 异常类之间的区别:异常类名+异常原因(通过构造方法的参数列表)
日志打印异常
使用日志的目的是为了更好的记录程序运行中的信息,包括但不限于:
程序的执行步骤、程序触发的异常等信息,使用日志可以将以上信息以规范的格式进行输出,便于阅读查看,同时,省去了部分代码的设计。
Commons Logging的使用
Commons Logging的特色是,它可以挂接不同的日志系统,并通过配置文件指定挂接的日志系统。
Commons Logging定义了6个日志级别:
FATAL
ERROR
WARNING
INFO
DEBUG
TRACE
使用步骤:
- Commons Logging自动搜索并使用Log4j,其次使用JDK Logging。
- 通过LogFactory获取Log类的实例
- 使用Log实例的方法打日志
Log log = LogFactory.getLog(Main.class);
log.info("start...");
log.warn("end.");
配置步骤:
1.引入commonlog的jar包,将其添加到JVM的classpath路径中。
2.包名为commons-logging-1.2.jar。
3.若使用命令行执行引入第三方jar包的.class文件,必须指定classpath,命令格式如下:
java -cp .:commons-logging-1.2.jar Main
注:使用
log.error(String, Throwable)打印异常。
Log4j的使用
-
组件化设计架构:

- Appender设置日志的输出路径(控制台、文件、数据库等)
- Filter设置过滤器,过滤日志
- Layout设置日志信息的格式,可以使用配置文件进行设置
-
配置Log4j日志框架
1.下载jar包,导入如下三个jar包:
- log4j-api-2.x.jar
- log4j-core-2.x.jar
- log4j-jcl-2.x.jar
2.可以和Commons Logging一起使用。
最佳实践
在开发阶段,始终使用Commons Logging接口来写入日志,并且开发阶段无需引入Log4j。如果需要把日志写入文件, 只需要把正确的配置文件和Log4j相关的jar包放入
classpath,就可以自动把日志切换成使用Log4j写入,无需修改任何代码。
六、日期与时间
日期类型转换

Date类
此类作为日期类对象,其中大部分的方法已经过时,但是,可以使用Date类来实例化日期,用作对日期的封装。
完全按照美国人对时间的描述而创建的类:与很多其他民族描述时间的算法都不一致
缺点:
- 它不能转换时区
- 很难对日期和时间进行加减
//构造方法
Date();//默认系统当前时间的对象
Date(long date);//使用时间戳创建时间对象
//普通方法
long getTime();//返回当前时间对象的时间戳(毫秒数)
boolean after(Date when);//判断日期是否在日期之后
boolean before(Date when);//判断日期是否在日期之前
Calendar类
此类作为Date类的上位替代,算是"国际化"的Date类;
类设计思想:为了满足国际化 提供所有时间参数 使用者自提。与Date相比,主要多了一个可以做简单的日期和时间运算的功能
缺点:
不能直接使用SimpleDateformat格式化时间,需要转换成Date类型
public abstract class Calendar
extends Object
implements Serializable, Cloneable, Comparable<calendar>;
/*Calendar类;
* 1.该类为抽象类,不能直接调用其构造方法字节实例化对象
* 可以借助静态方法getInstance()获取其子类对象。
* 2.static Calendar getInstance():获取子类对象
*/
Calendar c1 = Calendar.getInstance();//获取日历类实例对象
/*方法
* 1.和Date相同的比较方法。
* 2.设置和获取指定的时间参数:通过静态的成员变量来表示所有的时间参数 */
* int get(int field);
* void set(int field,int value);
// 3.设置年月日:
* void set(int year,int month,int date);
* void set(int year,int month,int date,int hour,int minute);
// 4.指定时间参数添加值
* void add(int field,int amount);
// 5.日历和日期之间的转换
* void setTime(Date date);//把当前日历对象的时间设置为参数日期对象定义的时间
* Date getTime();//获取当前日历对象的相同时间对应的日期对象
// 注:日期与日历之间的转换重要方法*
*
// 6.日历与毫秒值之间的转换
* long getTimeInMillis();//获取时间戳
* void setTimeInMillis(long time);
// 7.清除设置时间
* void clear();
* //将此 Calendar的所有日历字段值和时间值(从历元至现在的毫秒偏移量)设置成未定义。
*
日期格式化
- SimpleDateFormat:日期格式化
使用方式:
1. 创建实例,调用format()方法返回格式化的字符串;
2. 日期的格式只能使用构造方法传入,一经生成不可更改,除非创建新的实例;
//构造方法
1.SimpleDateFormat();//使用语言环境默认的日期格式;
2.SimpleDateFormat(String pattern)//使用给定的日期格式;
//格式例子:"yyyy-MM-dd HH:mm:ss"
3.SimpleDateFormat(String pattern,Locale locale);
//使用给定格式和语言习惯;
//普通成员方法
1. String format(Date date);//将日期按照内部格式化为字符串
//注:此方法为日期对象转换为字符串格式
2. Date parse(String source);//将符合内部日期格式的字符串转换为日期对象
/*注:1)此方法为字符串转化为日期对象的方法
2)此方法可能抛出异常ParseException*/
3. String toPattern();//返回当前日期格式化字符串;
三、泛型*
- jdk1.5后的新特性
作用:为容器的元素规范类型,
把容器元素类型也定义为变量,
使用时由调用者来指定具体类型。
四、集合
注意事项
- 使用foreach遍历集合时,不能对集合元素进行删减;
添加会报错:ConcurrentModificationException;
删除则不成功;
集合体系

使用集合的优势
-
集合支持泛型,可以限制一个集合中只能放入同一种数据类型的元素。
-
使用迭代器访问集合,无需知道集合内部的存储方式。(封装性好)
-
本质上是容器,装任意个数引用类型数据的容器
-
集合元素没有默认值
-
集合的元素只能是引用数据类型
遍历集合
- 可以使会用foreach循环
- 可以使用Iterator迭代器
Collection接口

//添加
boolean add(E e);
boolean addAll(Collection<!--? extends E--> c);
//删除
boolean remove(Object o);
boolean removeAll(Collection<!--?--> c);//删除包含在c中的所有元素
//判断
boolean contains(Object o);//判断o是否存在
boolean containsAll(Collection<!--?--> c);//
boolean isEmpty();//判断是否为空
//获取
Iterator<e> iterator();//获取集合迭代器
boolean hasNext();//是否有下一个元素
Object next();//将"指针"指向下一个元素,并返回
int size();//获取元素的个数
Object[] toArray();//转换为Object数组
List子接口
- List内部按照放入元素的先后顺序存放
- List允许添加null,查找元素时
- 需要为放入的元素实现equals方法
常用实现类:ArrayList、LinkList
-
遍历集合
方法一:可以使用foreach循环遍历,底层调用Iterator迭代器; 方法二:可以使用Interator迭代遍历集合; -
//实际使用中可能会碰到比较对象为null的问题,所以借助Objects.equals() public boolean equals(Object o) { if (o instanceof Person) { Person p = (Person) o; return Objects.equals(this.name, p.name) && this.age == p.age; } return false; } -
常用方法
-
add(添加元素)
//添加元素 public boolean add(E item);//将指定项目添加到列表末尾 public boolean add(E item,int index);//添加元素到index位置。 /*若index<0 || index>size则将元素插到队尾*/ //删除元素 public E remove(int position);//删除列表中指定位置的元素 public E remove(E item);//删除指定元素,并返回被删除元素,若无则返回null public void removeAll(Collections<e> c);//删除集合内的所有元素 /* 1.若position小于0或大于size,抛出数组越界异常 2.该方法会调用E的equals方法,所以自定义对象需要实现eqauals方法*/ //修改元素 E set(int index, E element);//修改指定下标处的元素,返回旧值 * 获取: E get(int index);//获取指定位置的元素 int size();//返回集合中的元素个数 int indexOf(Object o);//获取元素第一次出现的下标,若元素不存在返回-1 * 判断: boolean contains(Object o);//判断列表中是否存在该元素 /*1.会调用传入对象的equals,方法判断是否相等*/ -
of(返回一个ImmutableCollections类型的集合)
@SafeVarargs static <e> List<e> of(E... elements); List<string> list = List.of("1","2","3");List.of返回的是一个ImmutableCollections集合实现了 实现Iterable接口
-
-
数组与集合转换
* toArray(转换为数组): <t> T[] toArray(T[] a);//将集合中的元素复制到指定数组,并返回 T[] array = list.toArray(T[]::new);//简化写法 //JDK11前 Arrys.asList(T...);//T...的意思是多个T类型的参数,也可以是数组 /* 1.该方法将数组与List链表链接起来:当更新其中一个时,另一个自动更新 2.不支持add()、remove()、clear()等方法 3.返回的List的长度是不可变得 总结:如果你的List只是用来遍历,就用Arrays.asList()。 */ //JDK11后 List.of(T...);//返回的是一个只读List /* 对只读List调用add()、remove()方法会抛出UnsupportedOperationException。 */ -
ArrayList和LinkedList的区别
| ArrayList | LinkedList | |
|---|---|---|
| 获取指定元素 | 速度很快 | 需要从头开始查找元素 |
| 添加元素到末尾 | 速度很快 | 速度很快 |
| 在指定位置添加/删除 | 需要移动元素 | 不需要移动元素 |
| 内存占用 | 少 | 较大 |
- 底层实现不同:ArrayList底层是可变长度数组实现的,LinkedList底层是链表
- ArrayList元素在内存中是连续空间 而LinkedList的元素内存空间可以不连续,可以实现内容的有效利用
- ArrayList查询和修改效率高,但增删效率低,LinkedList增删效率高,但查询和修改效率低
ArrayList
//Arraylist类的声明
public class ArrayList<e> extends AbstractList<e>
implements List<e>, RandomAccess, Cloneable, java.io.Serializable
LinkList
LinkeList是List的实现类,底层是链表
使用和Arraylist基本相同 都可以根据下标操作元素,但是提供了更多的对头和尾的操作
//Linklis类的声明
public class LinkedList<e>
extends AbstractSequentialList<e>
implements List<e>, Deque<e>, Cloneable, java.io.Serializable;
void addFirst(E e):在头部添加元素
void addLast(E e):在尾部添加元素
E getFirst():获取头部的第一个元素
E getLast():获取尾部的最后一个元素
E pollFirst():移除并返回头部的第一个元素,如果链表为空,返回null
E pollLast():移除并返回尾部的最后一个元素,如果链表为空,则返回null
E removeFirst():移除并返回头部的第一个元素,如果链表为空,抛异常NoSuchElementException
E removeLast():移除并返回尾部的最后一个元素,如果链表为空抛异常NoSuchElementException
备注:底层使用链表实现
Set子接口
-
内部默认无序且不可重复的集合
-
如果只需要存储不重复的key,可以使用
Set常用实现类:HashSet、TreeSet
-
使用Set
放入
Set的元素和Map的key类似,都要正确实现equals()和hashCode()方法,否则该元素无法正确地放入Set。
Set不重复原理
调用set.add(obj1)时 怎么保证元素唯一?
- 先调用obj1的hashCode方法 获取其hashCode值
- 如果此hashCode值 与set中其他所有元素比较是唯一的
直接添加成功- 如果此hashCode值 与set中其他所有元素中的n个元素
hashCode值相同- 调用obj1的equals方法与这n个相同hashCode值的元素
分别做比较- 只用当调用的n次equals方法都返回false 才允许添加
只要有一个返回true 则添加失败
注:可以使用hashCode先排除明显不同的对象,
再使用equals方法详细判断。
Set接口常用方法
//构造方法
TreeSet(Collection<!--? extends E--> c);//创建有序子类TreeSet
public boolean add(E e);//将元素添加进Set<e>
public boolean remove(Object e);//将元素从Set<e>删除
public boolean contains(Object e);//判断是否包含元素
Set的常用实现类
Set接口并不保证有序,而SortedSet接口则保证元素是有序的:HashSet是无序的,因为它实现了Set接口,并没有实现SortedSet接口;TreeSet是有序的,因为它实现了SortedSet接口。

-
HashSet
最常用的
Set实现类是HashSet,实际上,HashSet仅仅是对HashMap的一个简单封装public class HashSet<e> implements Set<e> { // 持有一个HashMap: private HashMap<e, object=""> map = new HashMap<>(); // 放入HashMap的value: private static final Object PRESENT = new Object(); public boolean add(E e) { return map.put(e, PRESENT) == null; } public boolean contains(Object o) { return map.containsKey(o); } public boolean remove(Object o) { return map.remove(o) == PRESENT; } } -
TreeSet
TreeSet:不重复 元素按自然顺序排序 方法:继承于Collection 特有方法: E first():获取第一个元素 E last():获取最后一个元素 E floor(E e):获取小于等于参数的最大元素,若不存在这样的元素,则返回null E ceiling(E e):获取大于等于参数的最小元素,如果不存在这样的元素,则返回null E higher(E e):获取大于参数的最小元素,如果不存在这样的元素,则返回null E lower(E e):获取小于参数的最大元素,如果不存在这样的元素,则则返回null E pollFirst():移除并返回第一个元素 E pollLast():移除并返回最后一个元素重点:
使用
TreeSet和使用TreeMap的要求一样,添加的元素必须正确实现Comparable接口,如果没有实现Comparable接口,那么创建TreeSet时必须传入一个Comparator对象。保证一个类具有可比较性:
-
让类实现Comparable
接口,实现public int compareTo(E e) 方法 -
为创建一个比较器类,实现Comparator
,实现public int compare(E o1,E o2) 注意:在使用TreeSet时需要关联一个比较器对象:new TreeSet<>(new Comparator());
-
Map接口
Map存储的是key-value的映射关系,并且,它不保证顺序- 作用就是能高效通过
key快速查找value(元素) - 放入相同的key,会进行覆盖
常用方法
//添加
V put(K key,V value);
//1.若key不存在,返回null
//2.若key存在,返回被删除的旧的value
//获取
V get(Object Key);//返回key对应的value,没有返回null
Set<k> keySet();//返回Key的Set集合
Set<map.entry<k,v>> entrySet();//返回键值映射关系表
//该集合是由Map的支持,两者修改后会相互影响
//判断
boolean containsKey(K key);//只是查询是否存在key值
//查询key值是否存在,需要实现equals
注意事项
-
作为
key的对象必须正确覆写equals()方法,相等的两个key实例调用equals()必须返回true; -
作为
key的对象还必须正确覆写hashCode()方法,且hashCode()方法要严格遵循以下规范:- 如果两个对象相等,则两个对象的
hashCode()必须相等; - 如果两个对象不相等,则两个对象的
hashCode()尽量不要相等。
即对应两个实例
a和b:- 如果
a和b相等,那么a.equals(b)一定为true,则a.hashCode()必须等于b.hashCode(); - 如果
a和b不相等,那么a.equals(b)一定为false,则a.hashCode()和b.hashCode()尽量不要相等。
- 如果两个对象相等,则两个对象的
-
HashMap
- 键和值都可以为null,但是treeMap都不可为null。
-
TreeMap
/* 注意到Comparator接口要求实现一个比较方法,它负责比较传入的两个元素a和b, 如果a<b,则返回负数,通常是-1,如果a==b,则返回0,如果a>b,则返回正数,通常是1。 TreeMap内部根据比较结果对Key进行排序 */ Map<person, integer=""> map = new TreeMap<>(new Comparator<person>() { public int compare(Person p1, Person p2) { return p1.name.compareTo(p2.name); } });有序Map
- HashMap内部存储使用hash函数设置索引,其顺序不可预测。
- 还有一种
Map,它在内部会对Key进行排序,这种Map就是SortedMap。
-
EnumMap
//节省空间Map Map<dayofweek, string=""> map = new EnumMap<>(DayOfWeek.class);如果作为key的对象是
enum类型,那么,还可以使用Java集合库提供的一种EnumMap,它在内部以一个非常紧凑的数组存储value,并且根据enum类型的key直接定位到内部数组的索引,并不需要计算hashCode(),不但效率最高,而且没有额外的空间浪费。 -
SortedMap
SortedMap是接口,它的实现类是TreeMap。SortedMap保证遍历时以Key的顺序来进行排序。TreeMap不使用equals()和hashCode()。- 使用
TreeMap时,放入的Key必须实现Comparable接口
如果作为Key的class没有实现Comparable接口,那么,必须在创建TreeMap时同时指定一个自定义排序算法
Iterator接口
编译器把for each循环使用Iterator遍历集合,这种通过Iterator对象遍历集合的模式称为迭代器
-
使用迭代器的好处:
-
对任何集合都采用同一种访问模型;
-
调用者对集合内部结构一无所知;
-
集合类返回的
Iterator对象知道如何迭代。-
调用方总是以统一的方式遍历各种集合类型,而不必关系它们内部的存储结构
-
Java的集合类都可以使用
for each循环,List、Set和Queue会迭代每个元素,Map会迭代每个key
-
-
-
Iterator对象是集合对象的内部类,它自己知道如何高效遍历内部的数据集合
改写Iterator
-
集合类实现
Iterable接口,该接口要求返回一个Iterator对象; -
用
Iterator对象迭代集合内部数据。class ReverseList<t> implements Iterable<t> { ...; @Override public Iterator<t> iterator(){} //Iterator内部类,返回一个iterator类用于遍历该集合 class ReverseIterator implements Iterator<t> {} }-
Java提供了标准的迭代器模型,即集合类实现
java.util.Iterable接口,返回java.util.Iterator实例。 -
调用方则完全按
for each循环编写代码,根本不需要知道集合内部的存储逻辑和遍历逻辑
-
使用Iterator
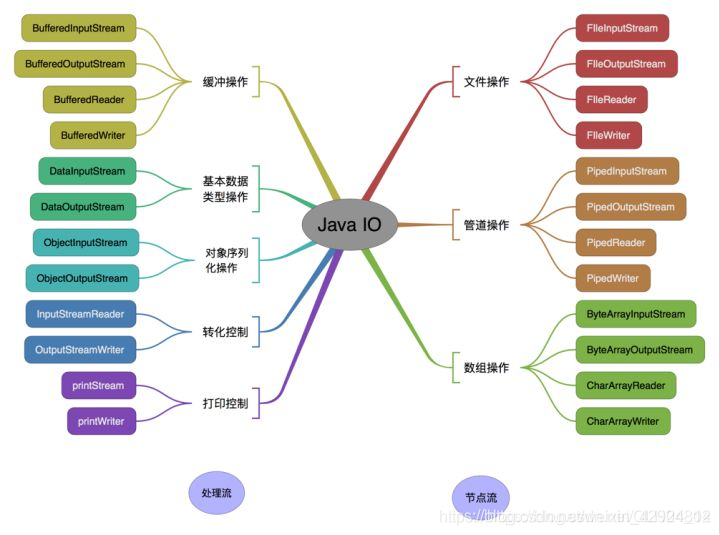
五、IO流
-
字符集
在进行文件输出时,尤其是文本流,需要设置字符集,例如:utf-8
当两者的字符集不匹配时,会发生乱码 -
序列化
将对象从内存输出到外存时,需要将对象序列列化,否则会报错。
序列化的目的是为了输出和输入的数据一致而设置的”秘钥“。
File类
//Java中提供的用于文件操作的实体类 java.IO.File;
--文件地址分隔符--
static String separator://File.separator
--构造方法--
File(String parent,String child);//可用于文件的复制或者剪切
File(String pathname);
--普通方法--
// 获取文件名字
String getAbsolutePath() :获取绝对路径;
String getPath() :获取创建对象时 构造方法的参数;
String getName() :获取文件/文件夹名字 不带父目录;
// 判断
boolean exists() :判断是否存在;
Boolean isDirectory() :判断是否为目录 文件必须存在;
boolean isFile() :判断是否为文件 文件必须存在;
// 创建
boolean createNewFile() :只能创建文件/不能创建文件夹,存在返回false
boolean mkdir() :只能创建一层目录,存在返回fasle
boolean mkdirs() :可以创建多层目录;
//删除
void deleteOnExit():程序结束前删除;//文件夹需要是空的
boolean delete():删除文件/文件夹,但删除文件夹时,文件必须是空的
// 获取
int length() :获取文件字节数 不能获取文件夹
File getParentFile() :获取直接父目录
String getParent() :获取直接父目录的路径
File[] listFiles() :获取当前目录下的所有直接子文件/子文件夹
// 重命名
boolean renameTo(File dest) :文件重命名,重名则返回false
流的分类
-
按方向分类(输入流/输出流)
输入:从程序外部调入到程序内部,称为InputStream/Reader
输出:从程序内部调出到程序外部,称为OutputStream/Writer -
按基本单位分类(字节流/字符流)
字节流:操作的基本单位是字节,后缀为Stream
字符流:操作的基本单位是字符对应的字节集合,后缀为Reader/Writer -
按关联对象分类(节点流/处理流)
节点流:从一个特定的地方(节点)读写数据。如FileReader
装饰流/过滤流:对一个已存在的流进行功能加强/增加,
(相当于一种流的代理类)如:InputStream
字节流
abstract class InputStream:字节输入流的顶层父类
abstract class OutputStream:字节输出流的顶层父类
子类FileInputStream/子类FileOutputStream
--输入流--
//构造方法
FileInputStream(File file);
FileInputStream(String name);
普通方法
int read();//一次一个字节 文件末尾返回-1
int read(byte[] b);//读取全部的字节数组 文件末尾-1 返回值是本次读到的有效字节数
int read(byte[] b, int off, int len);//读一个字节数组的一部分
void close();//关闭流
--输出流--
构造方法: 若目标文件不存在,则自动创建文件;若目标文件存在,则覆写目标文件;
FileOutputStream(File file);
FileOutputStream(String name);
FileOutputStream(File file,boolean append);// 实现文件的续写
FileOutputStream(String name,boolean append);
普通方法
void write(int b); // 一次写一个字节
void write(byte[] b); // 一次写出一个字节数组
void write(byte[] b, int off, int len);// 一次写出一个字节数组的一部分
字符流
字符流:每次操作的最小单位是一个字符对应的字节数组
顶层父类:Reader + Writer
子类:FileReader + FileWriter
字符输入流
构造方法:
FileReader(File file)
FileReader(String fileName)
普通方法:
int read() :一次写一个字符
int read(char[] cbuf):一次写一个字符数组
int read(char[] cbuf,int off, int len):一次写一个字符数组的一部分
void close():关闭流 释放资源
字符输出流
构造方法:若文件不存在,则创建文件;若无法创建,则抛出异常IOException
FileWriter(File file)
FileWriter(File file, boolean append)
FileWriter(String fileName)
FileWriter(String fileName, boolean append)
普通方法:
void write(char[] cbuf, int off, int len)
void write(char[] cbuf)
void write(int c)
void close():关闭流 释放资源
void write(String str, int off, int len)
void write(String str)
String getEncoding():获取字符编码集
转换流
转换路:把字节流转换为字符流
实现类:InputStreamReader/OutputStreamWriter
公共方法:String getEncoding();//获取编码集
//输出流:
构造方法:
OutputStreamWriter(OutpurSteam out, String charsetName);
// 不加字符集,使用默认字符集
普通方法:和FileWriter完全相同
//输入流:
构造方法:
InputStreamReader(InputStream in, String charsetName);
// 和输出流的相似
普通方法:和FileReader完全相同
高效流
//高效流:过滤流的一种 作用:增加节点流的传输效率
//实现类:
BufferedInputStream/BufferedOutputStream
BufferedReader/BufferedWriter
//关键字:
流的名字中带有 Buffered 字样的,皆为高效流;
//构造方法:
该流为修饰流,所以在创建时,需要传入其他(节点)流作为关联;
例:BufferedInputStream(InputStream in);
//使用方法:
被此流修饰过后,除了在传输效率上有所提高外,
使用上和修饰前使用方式基本相同相同,个别功能会有所增加。
BufferedReader特有方法:String readLine();//支持逐行读,到达末尾,返回null
BufferedWriter特有方法:void newLine();//写一个换行符
打印输出流
PrintWriter打印流
特点1:既可以是节点流,也可以是过滤流
PrintWriter(File file)
PrintWriter(OutputStream out)
特点2:可以保证数据的原始状态
void print(49); 等价于print(49+"");
特点3:当创建对象时指定自动刷新 调用println是可以实现自动刷新
序列化流
/*序列化相关的类:把内存中对象的信息持久保存到硬盘中,
把硬盘的信息重构成内存中的的对象
对象在内存中是字节,所以是字节流。*/
ObjectInputStream:反序列化,把硬盘中的信息读到内存中 重构成对象
ObjectOutputStream:序列化流,把内存中对象的信息持久化保存到硬盘上
// ObjectOutputStream的方法:
ObjectOutputStream(OutputStream out) :构造方法关联一个字节流
void writeObject(Object obj) :把一个对象的信息写到目的文件中
// ObjectInputStream的方法:
ObjectInputStream(InputStream in) :构造方法关联一个字节流
Object readObject() :一次读一个对象的信息 并重构对象
// 注意事项:
1 序列化流和反序列化流 操作的兑现必须实现接口Serializable
2 ObjectInputSteam的readObjec()方法读到文件末尾会抛出EOFException。
3 Serializable接口会给当前类分配一个唯一的编号,用于保证序列化和反序列化使用的同一个接口
4 序列化流不支持续写
// UUID:通用唯一识别码
随机一个32为的16进制的整型变量
六、线程
//概念:
在电脑中,一个程序可以看做一个进程,线程可以看做是进程的缩小版,
进程是运行的工厂,线程就是工厂的流水线;
//多线程/并发:
同一个进程中有多个线程在同时执行,程序中需要多个代码块同时执行--需要多线程。
//多线程执行原理:
cpu在时间轮片内在多个线程之间随机切换。
- 垃圾回收机制
1. jvm会不定时的启动垃圾回收器对象
垃圾回收器对象会根据创建的对象是否存在更多引用
来判断对象是否是垃圾
2. 如果是垃圾就调用此对象的finalize方法,来销毁对象释放内存
3. 程序员通过调用System.gc()方法来运行垃圾回收器对象
来干涉垃圾回收机制
4. 垃圾回收有一个单独的线程 和main线程不是同一个线程
线程的创建方式
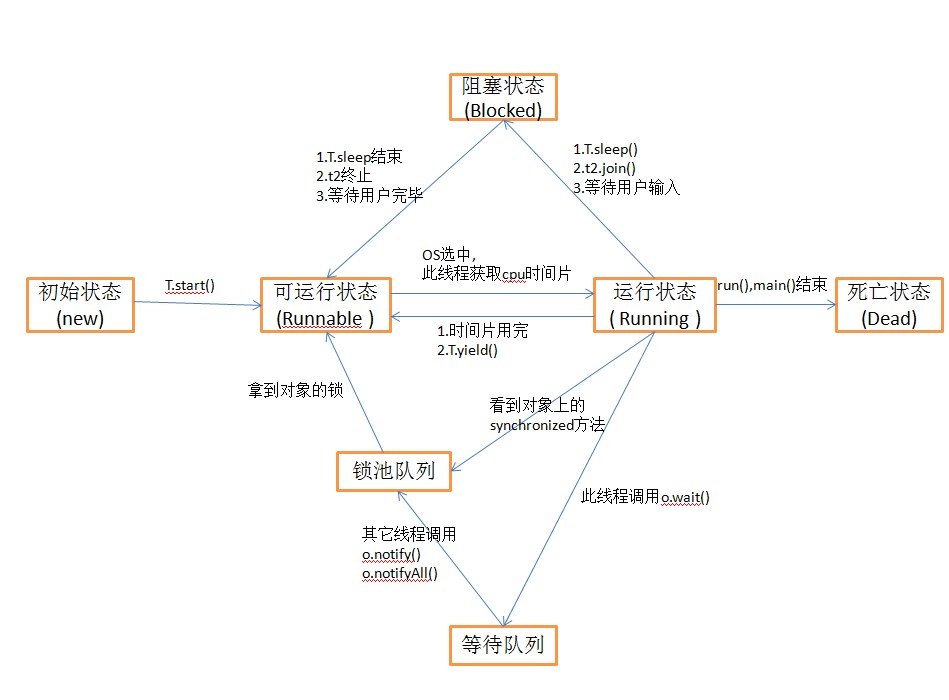
-
继承Thread类,重写run方法
-
实现Runnable接口, 实现run方法
JDK1.5 以后新增了以下两种创建方式
-
实现Callable接口
- Future.get()方法的理解
-
使用线程池创建线程
Thread
* Thread:线程类
* 构造方法:
* Thread()
Thread(Runnable target)
Thread(Runnable target, String name)
Thread(String name)
* 普通方法:
* static Thread currentThread() :获取当前线程对象
* String getName() :获取线程对象的名字
* void setName(String name) :设置线程对象的名字
* void join() :线程等待
* void run() :执行线程任务
* static void sleep(long millis) :线程休眠
* void start() :启动线程
线程任务:线程中关联的代码块
创建线程的方式1:继承Thread类 重写run方法
1)将类声明为 Thread 的子类。
2)该子类应重写 Thread 类的 run 方法。
3)接下来可以分配实例
4)并启动该子类的实例
Runnable
Runnable是一个接口,其中包括了线程的核心方法run()
如果只是想使用run方法,则无需创建线程子类。
作用:
1.使用Runable实现run方法可以实现更好的封装。
2.使用接口实现更加易于扩展
创建线程的方式2:继承Runnable接口 实现run方法
1)创建一个类实现Runnable接口
2)实现run方法:封装的线程任务
3)创建实现类的对象
4)创建Thread对象 并通过构造方法参数列表来关联实现类
5)开启线程
Thread t = new Thread(new Runnable(){},String name);
//使用Thread的构造方法创建线程
Callable
Callable接口和Runnable接口类似,
就像是用于封装线程的执行任务的类。
区别:
1. Runnable接口重写run方法,没有返回值,不能抛出异常,
Callable接口的call方法,有返回值(使用了泛型),可以抛出异常。
2. Runnable可以直接作为构造参数,用于创建线程,而Callable不可以。
Callable的使用,需要FutureTask实现类,用于接收运算结果。
FutureTask类实现类Runnable接口,可以将其作为Runnable类型的参数
传递给Thread的构造方法,用于创建新的线程。
使用步骤:
//1 继承Callable接口,实现call方法
class MyCall implements Callable {
@override
public String call() throws Exception{
retrun ;
}
}
//2 实例化实现类,用于创建FutureTask实例
FutureTask<string> ft = new FutureTask(new MyCall());
//3 实例化线程,将FutureTask线程绑定到线程中开始执行
Thread t1 = new Thread(ft);
/*
Callable的使用类似于将一个函数,交给另一个线程执行,
主线程继续执行别的函数,当Callable的线程将执行结果返回后,
加入到主线程中继续执行,
相当于执行的时间大于等于执行时间最长的函数,
在未调用get方法获取call的返回值时,程序可以继续执行
get方法是阻塞方法。
若call所在线程执行完毕,则可以直接获取到值,不会影响到主线进度;
若call所在线程未执行完毕,则会在get方法处阻塞,直到获取到call的返回值;
*/
线程池
方式4:线程池:线程提供了一个线程队列,队列中保存着所有等待状态的线程,
避免了创建与销毁额外开销,提高了响应速度。
具体步骤:
//1 创建Runnable的实现类 通过Executors创建线程池对象,
通过池对象的submit方法来启动一个线程
//2 创建线程池对象,并制定线程个数
ExecutorsService threadPool = Executors.newFixedThreadPool(10);
//3 创建实现类对象
MyImp04 imp = new MyImp04();
//5 通过线程池对象的submit方法,提交线程任务,提交的次数就是运行的线程个数
for(int i=0;i<5;i++){
threadPool.submit(imp);
}
//6 关闭池对象
threadPool.shutdown();
线程安全问题
多个线程同时操作一个共享数据时,当一个线程在使用数据时,另一个线程对数据进行了修改
导致与所期望的执行结果不同。
//造成问题的条件:
1.多线程 2.有共享数据 3.多个语句操作共享数据
//造成问题的原因:
1.线程的执行顺序无法预测
//解决问题的方法:(线程)
1.使用synchronized关键字,为执行代码块上锁,
使得同一时刻,共享数据只能被单个线程访问。
线程同步
- synchronized
//用法:将共享数据作为锁,来为指定代码块上锁
//作用:只有持有锁(对象),才可以执行内部的代码块,相当于访问权限限制
例子:
synchronized(Obj 锁对象){
锁内代码块;
}//结尾处,可以看做释放锁
通过上述方法,可以将所内代码块变为原子操作,即不可分割执行的代码。
要么,不执行;要么,一口气执行完。
- 同步方法
//当一个方法的方法体要求同步时,可以定义该方法为同步方法
public synchronized void method(){
方法体;
}
//同步方法的锁是当前对象,即this
- wait和notify
/*
* 面试题:wait和sleep的区别
wait和notify都是锁对象的方法
Object类的方法: void wait() 当前线程等待
Object类的方法: void notify() 随机唤醒一个当前对象作为锁对象 并且处于等待状态的线程
Object类的方法: void notifyAll() 唤醒所有当前对象作为锁对象 并且处于等待状态的线程
*/
wait和sleep的区别
//相同之处:
两者都会使线程进入阻塞状态。
//wait方法:
1. wait是Object方法的方法,
2. 只能在同步代码块使用,
3. 失去时间片的获取权限,
4. 会释放同步代码块的锁,
5. 只能被其他人唤醒,不能被自己唤醒
//sleep方法:
1. sleep是Thread的方法,
2. 必须指定时间参数,
3. 不会失去时间片获取权限,
4. 时间到期后会自动唤醒。
//jion方法:
1. 会使当前线程进入阻塞,直到jion调用的线程完成为止。
2. 不会释放锁
sleep的实际含义是该代码需要的执行时间,
也就是说等效于执行该时间长度的代码块,
会占用使用时间片的时间。
sleep(100);//一段需要执行100毫秒的代码块
死锁*
死锁是多线程编程中常见的一种问题,该问题的出现是由线程执行的不确定性造成的。
线程可以看做进程的子进程,在执行期间的顺序不可预测,也就是抢占式线程,
谁抢到时间片就执行谁,其中充满了不确定性。
死锁的实例:
-
死锁现象1
//使用jion产生的死锁现象 原理:两个线程中,相互调用对方线程的jion方法,互相等待对方执行结束,产生死锁。 //使用synchronized关键字,对代码块上锁,实现线程同步 原理:执行代码块需要的资源不唯一,需要对多个资源进行上锁,但是一次拿不完, 多个线程抢到部分资源,但是因为资源不全,无法执行后续代码,但是不释放资源, 相互等待对方释放资源,从而进入无限等待的状态。 造成原因:持有抢占? 示例1: //jion实现死锁
七、网络编程
概念
实现网络中,不同电脑之间的数据传输
-
Ip地址(Internet Protocol Address)是指互联网络协议地址
-
IPV4:4个1个byte的十进制数字
-
IPV6:8个2个byte的16进制数字
它为互联网上的每一个网络和每一台主机分配一个逻辑地址,一次来屏蔽物理地址的差异。
一个字符串用于唯一标识互联网上主机 -
127.0.0.1/localhost 表示本地主机
-
-
域名:ip地址不易于记忆 通过一段字符串来和ip地址一一对应
-
域名服务器:DNS 解析域名与ip的对应关系
-
PORT:端口 逻辑端口 电脑上安装的所有软件都会分配一个唯一的编号
0-65535 实现互联网数据传输
注意10000以下的端口 不要使用 默认被操作系统的软件使用
Socket分类
-
TCP:Transmission Control Protocol
可控的、端对端的、字节流传输协议
类似于:打固定电话 -
UDP:User Datagram Protocol 用户数据报协议
不可靠的、无需链接的、报文流传输协议
类似于:发电报
套接字TCP
tcp的两端:客户端和服务器端
主动接电话的——服务器端
主动打电话的——客户端
主要涉及的类:ServiceSocket、Socket
import java.net.ServerSocket;
import java.net.Socket;//属于net包需要添加引用
ServerSocket:服务器套接字
构造方法:ServerSocket(int port) :开启服务并指定端口
普通方法:Socket accept() :等到和获取客户端连接
void close() :关闭服务
Socket:套接字/传输通道
构造方法:Socket(String host,int port) 创建连接 并制定服务器端的ip和port
普通方法:InputStream getInputStream() :获取输入流
OutputStream getOutputStream() :获取输出流
void close() :关闭socket
InetAddress getInetAddtess() 获取自己的ip
InetAddrss getLocalAddress() 获取对方的ip
int getLocalPort() 获取自己的端口
int fetPort() 获取对方的端口
ServerSocket使用步骤:
//1 开启服务:创建一个ServerSocket并开启一个端口
ServerSocket server = new ServerSocket(10086);
//2 等待客户端的连接
Socket socket=server.accept();//阻塞方法
//3 获取socket的输入流和输出流 用于接受和发送信息
InputStream in=socket.getInputStream();
OutputStream out=socket.getOutputStream();
//4 接收和发送信息
...可自由发挥部分...
前后都是固定步骤,记住即可,该部分为核心逻辑,
可以理解为前后都是声明,该部分为方法体
//5 关闭服务
server.close();
Socket使用步骤:
//1 创建socket 指定服务器端的ip和port
Socket socket = new Socket("192.168.118.133",10086);
//2 获取输入流和输出流
InputStream in = socket.getInputStream();
OutputStream out = socket.getOutputStream();
//3 发送和接收数据
...同ServerSocket内容基本相同...
注:发送和接收顺序相反
//关闭客户端
socket.close();
使用时,注意一般先开启ServerSocket再开启Socket
//存在问题:
服务端和客户端都会陷入阻塞状态,原因是客户端的read()方法引起的。
客户端的本地输入流bis.read(b))一直阻塞,读取不到-1,其网络输出流也就输出不了-1;这样服务端的网络输入流也就读不到-1,进入阻塞,一直死循环等待结束标记。
//解决办法:
客户端上传完文件,给服务器写一个结束标记。使用socket.shotdownOutput()方法,
但方面断开流,就可以使得服务端可以接收到-1.
//特别注意:
使用该方法断开连接后,客户端仍可以接收数据,服务端仍可以发送数据。
//client端核心代码
while((n=bin.read(arr))!=-1){
out.write(arr, 0, n);
}
//关闭socket的输出流
socket.shutdownOutput();
套接字UDP
UDP:报文流传输协议,传输时使用的是字节流
主要类:DatagramPacket+DatagramSocket
InetAddress;//该类为java封装的ip地址类,可以使用该类的静态方法获取ip地址
static InetAddress getByName(String host);//已知主机名获取ip地址
DatagramPacket;//对发送和接收的信息的封装
构造方法:
DatagramPacket(byte[] buf,int offset,int length);//用于接收的报文
DatagramPacket(byte[] buf,int offset,int length,InetAddress address,int port);//用于发送的报文
普通方法:
InetAddress getAddress():获取对方的ip
int getPort() :获取对方的ip
byte[] getData();//获取包含数据的字节数组
int getLength();
/*获取数据的长度,当没有接收数据时,获取的是设置的长度,
当接收数据后,获取的是接受数据的长度,当接收数据大于设置的容器时,
会丢失超出长度的部分*/
void setPort(int iport) //设置要将此数据报发往的远程主机上的端口号。
void setSocketAddress(SocketAddress address)
//设置要将此数据报发往的远程主机的 SocketAddress(通常为 IP 地址 + 端口号)。
DatagramSocket:报文流的套接字
构造方法:
DatagramSocket(int port) ://指定开启的打开,并绑定到本机上
DatagramSocket(int port, InetAddress laddr):
//创建数据报套接字,将其绑定到指定的本地地址
普通方法
void receive(DatagramPacket p) ://接收报文对象
void send(DatagramPacket p) ://发送报文
void close() ://关闭套接字
InetAddress getLocalAddress() ://获取本地的ip
int getLocalPort() ://获取本地的port
//使用步骤:
发送方:
//1 创建datagramsocket
DatagramSocket socket=new DatagramSocket(10086);
//2 创建一个datagrampacket,用于封装发送信息
DatagramPacket packet=new DatagramPacket(arr, arr.length,
InetAddress.getByName("127.0.0.1"), 10010);
//3 发送信息
socket.send(packet);
//4 关闭socket
socket.close();
接收方:
//1 创建socket
DatagramSocket scoket=new DatagramSocket(10010);
//2 创建一个空的datagramepacket用于接受信息
DatagramPacket packet=new DatagramPacket(new byte[1024], 1024);
//3 接受信息
scoket.receive(packet);
//4 解析信息
String message=new String(packet.getData(),0,packet.getLength());
//5 关闭socket
scoket.close();
概括使用步骤:
首先关键步骤在第2步:
1. 发送方在该步骤可以将需要发送的信息进行处理,装入DatagramPacket对象中;
该对象中除了发送的信息外,还要包括目标的ip地址和端口号
使用 send(DatagramPacket packet) 方法将对象发送出去。
2. 接收方同样需要创建一个DatagramPacket的对象作为容器,用来接收数据;
但是因为不知道接收数据的实际大小,容器可能装不下,猜测会发生错误!
- 注意事项
1. DatagramPacket packet=new DatagramPacket(byte[] buf, int length);
DatagramPacket的getLenth()的方法返回数据的长度,
若是没有使用receive()接收过数据,则返回构造方法时传入的长度参数length;
若是使用receive()接收过数据,则返回接收到的数组的实际长度。
2. UDP的信息发送和接收是没有建立稳定连接的,所以单方面发送和单方面接收信息时,
可能会出现速度不同,即发送方已经发完了,但是接收方还在等待,
----归结为线程的不同步问题。
八、设计模式
创建型模式
对象实例化的模式,创建型模式用于解耦对象的实例化过程。
结构性模式
把类或对象结合在一起形成一个更大的结构。
行为型模式
类和对象如何交互,及划分责任和算法。
三、反射*
四、注解*
八、正则表达式
十、函数式编程
</dayofweek,></person,></b,则返回负数,通常是-1,如果a==b,则返回0,如果a></map.entry<k,v></e,></arr.length-1;i++){></n;i++){>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号