基础-SQL
基本类型:
char(n):固定长度的字符串
varchar(n):可变长字符串,用户指定最大长度
int:整数类型
smallint:
numeric(p,d):定点数,精度由用户指定。有p位数字,d为小数点后的位数
real:浮点数
double precision:双精度浮点数
float(n):精度至少为n的浮点数。
创建数据库:create database test;
创建表:
use test; CREATE TABLE `department` ( `dept_name` varchar(20) NOT NULL AUTO_INCREMENT, `building` varchar(15) DEFAULT NULL, `budget` decimal(12,2) DEFAULT NULL, PRIMARY KEY (`dept_name`) //完整性约束 ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT Charset=utf8mb4 COLLATE=.....;
create table course( course_id varchar(7), title varchar(50), dept_name varchar(20), credits numeric(2,0), primary key (course_id), foreign key (dept_name) references department(dept_name) //外键
);
select:
select dept from instructor;
like: %(匹配任意子字符串) _(匹配任意一个字符) /(转义符号) upper(将字符串转为大写) lower (转为小写)
order by:默认自然升序 desc(降序) asc(升序)
where 字句:
salary between 90 and 100 <==> salary <= 100 and salary >= 90
元组:where(instructor.ID, dept_name) = (teaches.ID, 'Biology')
空值:null
算术运算:任意一输入为空,则为空
比较运算:unknown (eg. 1 < null)
布尔运算:and or not
is null:判断是否为空
is unknown:判断是否为unknown
集合运算 + select distinct: 重复元组都被去除 (null值是相同的)
聚集函数:除了count(*) 都忽略到null
集合运算:union, intersect, except
union: 并集 union all(保留重复的)
intersect:交集 intersect all(保留重复的)
except:差 except all (保留重复的)
聚集函数:以集合为输入,返回单个值的函数
avg,min,max,sum,count
eg. select avg(salary)from instructor where dept_name = 'Comp.Sci';
分组聚集:作用到一组元组集上 group by,此时select语句中只能是group by字句中出现的属性或被聚集的属性。
eg: select dept_name, avg(salary) from instructor group by dept_name;
having 字句:对分组限定条件 eg. select dept_name, avg(salary) as avg_salary from instructor group by dept_name having avg(salary) > 42000;
嵌套子查询:
in (select ...) not in (select...)
> some () = some() <= some()
> all() < all() = all()
exists:查询子查询的结果是否存在元组
unique:查询子查询的结构是否有重复的元组
with:定义临时关系
标量子查询:
select dept_name, (select count(*) from instructor where department.dept_name = instructor.dept_name) as num_isntructors from department;
删除:delete from r where P;
插入:insert into course values ('CS-437', 'database', 'Comp. Sci', 4);
insert into course (course_id, title, dept_name,credits) values ('CS-437', 'database', 'Comp. Sci', 4);
更新:update instructor set salary = salary * 1.05 where salary < (select avg(salary) from instructor;
case: case where pred1 then result1 where pred2 then result2 else result0 end
update instructor set salary = case where salary <= 10000 then salary * 1.05 else salary * 1.03 end
自然连接:连接属性上取值相同的元组对 (字段名相同的值相同)
from department natural join course; <==> from department join course using (dept_name) <==> from department join course on (department.dept_name = course.dept_name)
链接表:数据库做查询是形成的中间表
内连接:返回链接表中符合链接条件和查询条件的数据行
外连接:除了返回链接表中符合连接条件和查询条件的数据行,还返回其它的一些数据行。左外链接,右外连接,全外连接。
左外连接:返回内连接结果+左表中不符合连接条件和查询条件的数据行。
全外连接:左外连接并右外连接。
department natural left out join course
department left outer join course on (department.dept = course.dept_name)
连接类型:
inner join
left outer join
right outer join
full outer join
连接条件:
natural
on <predicate>
using(A1, A2, ..., An)
视图定义:create view v as <query expression>
视图物化:将视图存到数据库中
完整性约束:保证授权用户对数据库所做的修改不会破坏数据的一致性。
not null
unique: unique (A1, A2,...)
check: eg., check ( semester in ('fall', 'winter','spring','Summer')
参照完整性: foreign key (dept_name) references department(dept_name) 关系中给定属性集上的取值一定在另一关系的特定属性集的取值中出现。
延迟完整性约束:事物中对完整性约束的违反,部分数据库允许在事物结束之后再检查完整性约束
INITIALLY DEFERRED:检查被推迟到事务提交前执行 INITIALLY IMMEDIATE:检查在每个语句后立即被执行
断言: create assertion <assertion-name> check (predicate)
日期和时间类型:
date:年月日
time:包括小时、分和秒
timestamp:data和time的组合
字符串必须符合正确的格式和顺序
默认值:default
创建索引:create index studentId_index on student (ID)
大对象:cblob (字符数的大对象数据类型) bclob(二进制数据的大对象数据类型)
权限的授予与收回:select, insert, update,delete 权限
grant <权限列表 >
on <关系名或视图名>
to <用户/角色列表>
eg.:grant select on department to Amit,Satoshi
revoke <权限列表》
on <关系名或视图名>
from <用户/角色列表> (默认连级收回, 加restrict申明防止连级收回)
角色转移:grant select on department to Amit with grant option
触发器:
create trigger timeslot_check1 after insert on section
referencing new row as nrow
for each row
when( nrow.time_slot_id ....)
begin
rollback
end;
高级聚集特性:
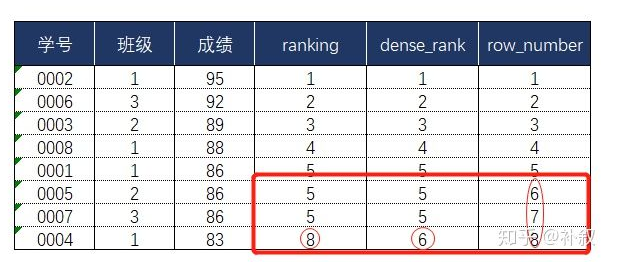
排名:select ID, rank() over (partition by ... order by (GPA) desc) as s_rank from student_grades dense_rank() row_number()
聚合函数,如sum,avg,count,max,min等。
窗口:rows 3 preceding rows unbounded preceding rows between 3 preceding and 2 following 对于一定范围内的元组计算聚集函数
eg.: select year, avg(num_credits) over (order by year rows 3 preceding) as avg_credits from ...
声明和调用SQL函数和过程:
create function dept_count(dept_name varchar(20))
returns integer
begin
declare d_count Integer;
select count(*) into d_count
from instructor'
where instructor.dept_name = dept_name
return d_count;
end
一、SQL SELECT语句的执行顺序:
1.from子句组装来自不同数据源的数据;
2.where子句基于指定的条件对记录行进行筛选;
3.group by子句将数据划分为多个分组;
4.使用聚集函数进行计算;
5.使用having子句筛选分组;
6.计算所有的表达式;
7.使用order by对结果集进行排序;
8.select 集合输出
找出每个部门工资最高的员工
找出每个部门获得前三高工资的所有员工
窗口函数:
SELECT *,rank() OVER (PARTITION BY 班级 ORDER BY 成绩 DESC) AS ranking FROM 班级表;
窗口函数的位置可以放置以下两种函数:
1>专用窗口函数,包括row_number();rank();dense_rank()等。
2 >聚合函数,如sum,avg,count,max,min等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号