Hadoop 简介
1、特性扩展性、容错性、可靠性
2、hadoop主要有一个分布式文件系统和一个分布式计算框架组成
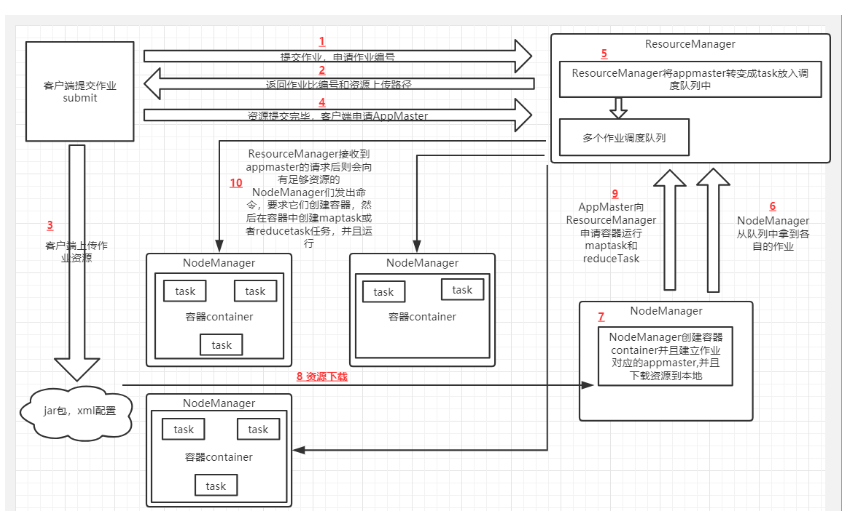
MapReduce:一个分布式计算框架
输入时key value对,输出为key value对输出到磁盘。MapReduce 框架对自动地对相同key值的数据进行聚合,key值相同的键值对会统一交给一个reduce函数处理。
3、mapreduce:
采集,计算,存储
主要用于一次性计算,不适用于迭代计算,迭代计算的结果都需要存到磁盘
4、shuffle:map方法之后,reduce方法之前。
collect:环形缓存区 (100m - 200)
spill:溢写到磁盘,在溢写之前进行分区和排序(快排) (80% - 90%)
merge:将溢写到磁盘的文件进行归并排序 (默认一次归并10个)
reduce端拉取数据,并进行归并排序。存入内存,或溢出。(默认拉取5个)
写入到reduce方法中。之前可以进行一次分组排序
组成:
job tracker:调度任务
task tracker
迭代:遍历输入数据,将数据分析为key-value对 InputFormat
数据切分、为mapper提供数据
映射:讲key-value对映射成另外一写key-value对 (过滤分发) Mapper
分组:根据key值进行分组 (shuffle) partitionor (数据分区,sort,局部聚合,缓存,归并排序)
规约:以组为单位进行规约(计算并归并) reduce
迭代:讲最红产生的key-value值保存到文件中 writeFormat
4、HDFS:一个高容错的分布式文件系统。
架构:master/slaves
镜像文件和编辑日志:
(1)Fsimage文件:HDFS文件系统元数据的一个永久性的检查点,包含着集群所有文件的元数据信息。
(2)Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到edits文件中。
读取文件:client发送文件请求给namenode,如果文件不存在,返回错误信息,否侧,返回文件所对应block所在的datanode的位置。client与对应的datanode进行socket连接并获取数据
写文件:client发送写请求到namenode,如果文件存在,返回错误,否则,返回一些可用的datanade。client将文件分为多块,并行存储到不同的datanode节点上(管道备份)。存完发送消息给namenode。
参数调优:namenode和datanode之间心跳通讯问题。配置成20log(集群个数)
优化:小文件
(1)Hadoop Archives :Hadoop归档文件,归档文件中包含元数据信息和小文件内容
(2)Sequence file和CombineFileInputFormat
(1)(2)将多个小文件放到一个整体里面,对外是一个文件,减小存储空间
(3)JVM重用:
(4)通过CombineFileInputFormat类将多个文件分别打包到一个split中,每个mapper处理一个split, 提高并发处理效率,减少maptask个数
5、二次排序:
在对key排序的情况下,对value也进行排序
自定义组合key:改变key 将key改变成(key-value的组合形式) 构造组合键
自己定义分区函数,分组比较器,和排序比较器
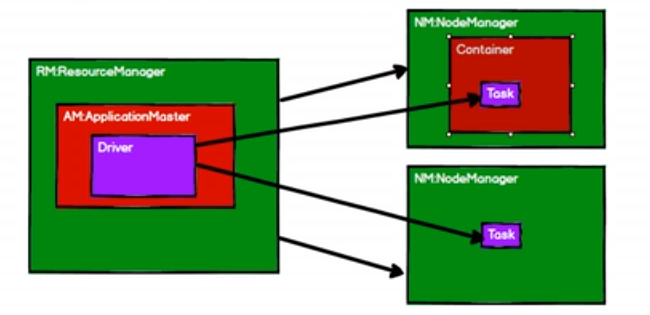
6、yarn
调度:
FIFO:单队列,前进先出,同时只有一个任务在执行。
容器调度器(默认):多队列 (并发度不是很高)
公平调度:多队列,一个队列可以有多个job同时运行 (并发度高)
zookeeper:
如果发现别人的 ZXID比自己大,也就是数据比自己新,那么就重新发起投票,投票给目前已知最大的 ZXID所属节点。半数以上的投票才能选出leader。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号