操作系统面试内容
第一部分 内存管理
一、虚拟内存
- 概念:基于局部性原理,在程序装入时,可以将程序的一部分装入内存,而将其余部分留在外存,就可以启动程序执行。在程序执行过程中,当所访问的信息不在内存时,由操作系统将所需要的部分调入内存,然后继续执行程序。另一方面,操作系统将内存中暂时不使用的内容换出到外存上,从而腾出空间存放将要调入内存的信息。这样,系统好像为用户提供了一个比实际内存大得多的存储器,称为虚拟存储器。
- 局部性原理:
- 时间局部性:如果执行了程序中的某条指令,那么不久后这条指令很有可能再次被执行;如果某个数据被访问过,不就之后该数据很有可能再次被访问。(因为程序中存在大量的循环)
- 空间局部性:一旦程序访问了某个存户单元,在不久之后,其附近的存储单元也很有可能被访问。(因为很多数据在内存中都是连续存放的)。
- 特性:
- 多次性:无需再作业运行时一次性全部装入内存,而是允许被多次调入内存。
- 对换性:在作业运行时无需一直常驻内存,而是允许在作业运行过程中,将作业换入、换出
- 虚拟性:从逻辑上扩充了内存的容量,使用户看到的内存容量,远大于实际容量。
二、实现方法
1. 请求分页存储管理
-
概念:请求分页系统建立在基本分页系统基础之上,为了支持虚拟存储器功能而增加了请求调页功能和页面置换功能。
-
页表机制:操作系统需要知道每个页面是否已经调入内存;如果还没调入,那么也需要知道该页面在外存中存放的位置;操作系统需要通过某些指标来决定到底换出哪个页面;请求分页系统中的页表项,增加的四个字段说明如下:
- 状态位P:用于指示该页是否已调入内存,供程序访问时参考。
- 访问字段A:用于记录本页在一段时间内被访问的次数,或记录本页最近己有多长时间未被访问,供置换算法换出页面时参考。
- 修改位M:标识该页在调入内存后是否被修改过。
- 外存地址:用于指出该页在外存上的地址,通常是物理块号,供调入该页时参考。
-
缺页中断机构:在请求分页系统中,每当所要访问的页面不在内存时,便产生一个缺页中断,请求操作系统将所缺的页调入内存。
- 此时应将缺页的进程阻塞(调页完成唤醒),如果内存中有空闲块,则分配一个块,将要调入的页装入该块,并修改页表中相应页表项
- 若此时内存中没有空闲块,则要淘汰某页(若被淘汰页在内存期间被修改过,则要将其写回外存)。
-
地址变换机构:请求分页系统中的地址变换机构,是在分页系统地址变换机构的基础上,为实现虚拟内存,又增加了某些功能而形成的。
- 在进行地址变换时,先检索快表:若找到要访问的页,便修改页表项中的访问位(写指令则还须重置修改位),然后利用页表项中给出的物理块号和页内地址形成物理地址。
- 若未找到该页的页表项,应到内存中去查找页表,再对比页表项中的状态位P,看该页是否已调入内存,未调入则产生缺页中断,请求从外存把该页调入内存。
-
页面置换算法:
- 最佳置换算法(OPT):每次选择淘汰的页面将是以后用不使用,或者最长时间内不被访问的页面,这样可以保证较低的缺页率。该算法无法实现。
- 先进先出(FIFO)页面置换算法:优先淘汰最早进入内存的页面,亦即在内存中驻留时间最久的页面。该算法实现简单,只需把调入内存的页面根据先后次序链接成队列,设置一个指针总指向最早的页面。但该算法与进程实际运行时的规律不适应,因为在进程中,有的页面经常被访问。
- 最近最久未使用(LRU)置换算法:选择最近最长时间未访问过的页面予以淘汰,它认为过去一段时间内未访问过的页面,在最近的将来可能也不会被访问。该算法为每个页面设置一个访问字段,来记录页面自上次被访问以来所经历的时间,淘汰页面时选择现有页面中值最大的予以淘汰。
- 时钟(CLOCK)置换算法
- 改进型的时钟置换算法
-
页面分配策略:
- 驻留集大小:给特定的进程分配多大的主存空间
- 固定分配局部置换。它为每个进程分配一定数目的物理块,在整个运行期间都不改变。若进程在运行中发生缺页,则只能从该进程在内存中的页面中选出一页换出,然后再调入需要的页面。实现这种策略难以确定为每个进程应分配的物理块数目:太少会频繁出现缺页中断,太多又会使CPU和其他资源利用率下降。
- 可变分配全局置换。这是最易于实现的物理块分配和置换策略,为系统中的每个进程分配一定数目的物理块,操作系统自身也保持一个空闲物理块队列。当某进程发生缺页时,系统从空闲物理块队列中取出一个物理块分配给该进程,并将欲调入的页装入其中。
- 可变分配局部置换。它为每个进程分配一定数目的物理块,当某进程发生缺页时,只允许从该进程在内存的页面中选出一页换出,这样就不会影响其他进程的运行。如果进程在运行中频繁地缺页,系统再为该进程分配若干物理块,直至该进程缺页率趋于适当程度; 反之,若进程在运行中缺页率特别低,则可适当减少分配给该进程的物理块。
- 调入页面的时机:
- 预调页策略。根据局部性原理,一次调入若干个相邻的页可能会比一次调入一页更高效。但如果调入的一批页面中大多数都未被访问,则又是低效的。所以就需要釆用以预测为基础的预调页策略,将预计在不久之后便会被访问的页面预先调入内存。但目前预调页的成功率仅约50%。故这种策略主要用于进程的首次调入时,由程序员指出应该先调入哪些页。
- 请求调页策略。进程在运行中需要访问的页面不在内存而提出请求,由系统将所需页面调入内存。由这种策略调入的页一定会被访问,且这种策略比较易于实现,故在目前的虚拟存储器中大多釆用此策略。它的缺点在于每次只调入一页,调入调出页面数多时会花费过多的I/O开销。
- 从何处调入页面:
- 系统拥有足够的对换区空间:可以全部从对换区调入所需页面,以提髙调页速度。为此,在进程运行前,需将与该进程有关的文件从文件区复制到对换区。
- 系统缺少足够的对换区空间:凡不会被修改的文件都直接从文件区调入;而当换出这些页面时,由于它们未被修改而不必再将它们换出。但对于那些可能被修改的部分,在将它们换出时须调到对换区,以后需要时再从对换区调入。
- UNIX方式:与进程有关的文件都放在文件区,故未运行过的页面,都应从文件区调入。曾经运行过但又被换出的页面,由于是被放在对换区,因此下次调入时应从对换区调入。进程请求的共享页面若被其他进程调入内存,则无需再从对换区调入。
- 驻留集大小:给特定的进程分配多大的主存空间
-
页面抖动(颠簸):刚刚换出的页面马上又要换入主存,刚刚换入的页面马上就要换出主存,这种频繁的页面调度行为称为抖动,或颠簸。如果一个进程在换页上用的时间多于执行时间,那么这个进程就在颠簸。
-
工作集 (驻留集):工作集(或驻留集)是指在某段时间间隔内,进程要访问的页面集合。经常被使用的页面需要在工作集中,而长期不被使用的页面要从工作集中被丢弃。为了防止系统出现抖动现象,需要选择合适的工作集大小。
2. 请求分段存储管理
3.请求段页式存储管理
参考链接:
- https://blog.csdn.net/yongchaocsdn/article/details/78533097?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_baidulandingword~default-0.pc_relevant_default&spm=1001.2101.3001.4242.1&utm_relevant_index=3
第二部分 进程与线程
一、基础知识
-
进程:
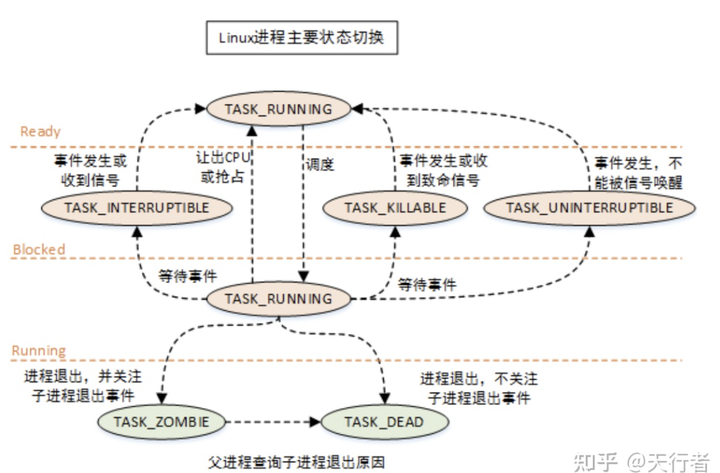
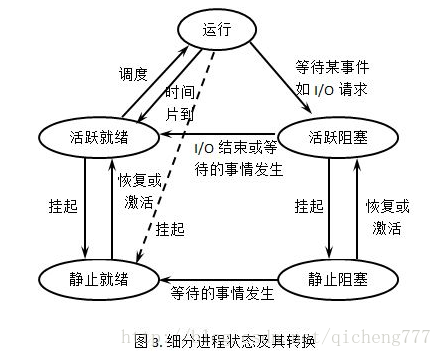
- 进程状态:运⾏状态(Runing)、就绪状态(Ready)、阻塞状态(Blocked)、创建状态(new)、结束状态(Exit)、挂起状态(阻塞挂起状态、就绪挂起状态)
-
进程分类:
- CPU密集型和I/O密集型:计算密集型任务的特点是要进行大量的计算,消耗CPU资源;IO密集型,涉及到网络、磁盘IO的任务都是IO密集型任务,CPU消耗很少,任务的大部分时间都在等待IO操作完成
- 交互进程、批处理进程和实时进程
-
进程创建方式:
- clone()、fork() 及 vfork() 系统调用:轻量级进程是由名为 clone() 的函数创建的;传统的fork() 系统调用在Linux中使用 clone() 实现的;vfork() 系统调用在Linux中也是用 clone 实现的
- 进程创建方式:系统初始化(init);正在运行的程序执行了创建进程的系统调用(比如 fork);用户请求创建一个新进程;初始化一个批处理工作
- 写时复制:如果有多个呼叫者(callers)同时要求相同资源,他们会共同取得相同的指标指向相同的资源,直到某个呼叫者(caller)尝试修改资源时,系统才会真正复制一个副本(private copy)给该呼叫者,以避免被修改的资源被直接察觉到
-
进程终结方式:正常退出;错误退出;严重错误;被其他进程杀死
-
孤儿进程:一个父进程退出,而它的一个或多个子进程还在运行,将被init进程(进程号为1)所收养
-
僵尸进程:一个进程使用fork创建子进程,如果子进程退出,而父进程并没有调用wait()或waitpid()获取子进程的状态信息,那么子进程的进程描述符仍然保存在系统中。
-
孤儿进程和僵尸进程的危害:
- 孤儿进程不会有什么危害。
- 如果进程不调用wait() / waitpid()的话, 那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵尸进程,将因为没有可用的进程号而导致系统不能产生新的进程.。
-
PCB:进程存在的唯⼀标识
- 包含信息:进程描述信息、进程控制和管理信息、资源分配清单、CPU 相关信息
- 如何组织:通过链表的⽅式进⾏组织,把具有相同状态的进程链在⼀起,组成各种队列
-
进程和线程
- 进程和线程的定义:
- 进程的定义:进程是对运行时程序的封装,是操作系统进行资源调度和分配的的基本单位。
- 线程的定义:线程是进程中活动的对象,是进程的子任务,是CPU调度和分派的基本单位。每个线程都拥有一个独立的程序计数器、进程栈和一组进程寄存器。
- 进程和线程的区别
- 线程的粒度小于进程
- 进程是资源拥有的基本单位,线程是独立调度与独立运行的基本单位
- 线程切换的开销远远小于进程
- 进程在执行过程中拥有独立的内存单元,而多个线程共享进程的内存
- 进程是资源分配的最小单位,线程是CPU调度的最小单位
- 通信:线程通信较进程通信简单
- 进程和线程持有的资源
- 进程:可执行程序的代码段、打开的文件、挂起的信号、内核内部数据、处理器状态、一个或多个内存地址空间、一个或多个执行线程、存放全局变量的数据段
- 线程:程序计数器、寄存器、进程栈
- 进程和线程的定义:
-
进程的上下⽂切换
- 方式:把交换的信息保存在进程的 PCB,当要运⾏另外⼀个进程的时候,我们需要从这个进程的 PCB 取出上下⽂,然后恢复到 CPU 中,这使得这个进程可以继续执⾏
- 进程上下文切换场景:
- 在CPU上运行进程的时间片耗尽,便会被操作系统挂起,调度器选择其他进程执行。
- 在CPU上运行进程被更高优先级的进程抢占。
- 在CPU上运行进程需要等待某种设备资源时。
- 当进程通过睡眠函数 sleep 这样的⽅法将⾃⼰主动挂起时
- 在CPU上运行进程的时间片尚未耗尽时,发生硬件中断,CPU中断当前执行的进程,转而去调用对应的中断处理程序处理中断。
- 切换流程
- 保存进程P1的状态到进程控制块PCB1中。
- 移动进程P1到相应的队列,如就绪队列(ready queue)或者 设备队列(device queue)。
- 在内存中检索进程P2的上下文并将其加载到CPU寄存器中恢复。
- 更新进程的虚拟内存和用户栈。
- 跳转到程序计数器所指向的位置,以恢复该进程。
-
线程的实现:
- 线程分类:用户级;核心级
- ⽤户线程(User Thread):在⽤户空间实现的线程,不是由内核管理的线程,是由⽤户态的线程库来完成线程的管理;
- 内核线程(Kernel Thread):在内核中实现的线程,是由内核管理的线程;
- 轻量级进程(LightWeight Process):在内核中来⽀持⽤户线程;
- ⽤户线程和内核线程的对应关系:多对⼀、⼀对⼀、多对多
-
调度
-
调度时机;在进程的⽣命周期中,当进程从⼀个运⾏状态到另外⼀状态变化的时候,其实会触发⼀次调度。
-
调度原则:CPU 利⽤率、系统的吞吐率、进程的周转时间、就绪队列中进程的等待时间、响应时间
-
调度算法:
-
先来先服务调度算法:每次从就绪队列选择最先进⼊队列的进程,⼀直运⾏,直到进程退出或被阻塞,才会继续从队列中选择第⼀个进程接着运⾏
-
最短作业优先调度算法:优先选择运⾏时间最短的进程来运⾏,这有助于提⾼系统的吞吐量。
-
⾼响应⽐优先调度算法:每次进⾏进程调度时,先计算「响应⽐优先级」,然后把「响应⽐优先级」最⾼的进程投⼊运⾏

-
时间⽚轮转调度算法:每个进程被分配⼀个时间段,称为时间⽚(Quantum),即允许该进程在该时间段中运⾏。
-
最⾼优先级调度算法:从就绪队列中选择最⾼优先级的进程进⾏运⾏
-
多级反馈队列调度算法:
- 设置了多个队列,赋予每个队列不同的优先级,每个队列优先级从⾼到低,同时优先级越⾼时间⽚越短;
- 新的进程会被放⼊到第⼀级队列的末尾,按先来先服务的原则排队等待被调度,如果在第⼀级队列规定的时间⽚没运⾏完成,则将其转⼊到第⼆级队列的末尾,以此类推,直⾄完成;
- 当较⾼优先级的队列为空,才调度较低优先级的队列中的进程运⾏。如果进程运⾏时,有新进程进⼊较⾼优先级的队列,则停⽌当前运⾏的进程并将其移⼊到原队列末尾,接着让较⾼优先级的进程运⾏;
-
-
-
进程、线程和协程区别
-
协程:协程是一种用户态的轻量级线程,协程的调度完全由用户控制。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
-
协程多与线程进行比较
-
一个线程可以有多个协程,一个进程也可以单独拥有多个协程。
-
线程进程都是同步机制,而协程则是异步
-
协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态(协程在子程序内部是可中断的,然后转而执行别的子程序,在适当的时候再返回来接着执行。)
-
-
协程优点:
- 极高的执行效率:因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显;
- 不需要多线程的锁机制:因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
-
二、进程间通信
-
进程通信目的
- 数据传输:一个进程需要将它的数据发送给另一个进程。
- 共享数据:多个进程想要操作共享数据,一个进程共享数据。
- 共享资源:多个进程之间共享同样的资源。
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有缺陷和异常,并能够及时知道其状态改变。
-
进程通信方式
- 管道/匿名管道 (PIPE):实质是一个内核缓冲区,进程以先进先出的方式从缓冲区存取数据,管道一端的进程顺序的将数据写入缓冲区,另一端的进程则顺序的读出数据。
- 特点
- 管道是半双工的,数据只能向一个方向流动。
- 只能用于父子进程或者兄弟进程之间(具有亲缘关系的进程;
- 单独构成一种独立的文件系统。
- 数据的读出和写入:写入的内容每次都添加在管道缓冲区的末尾,并且每次都是从缓冲区的头部读出数据。
- 局限:
- 只支持单向数据流;
- 只能用于具有亲缘关系的进程之间;
- 没有名字;
- 管道的缓冲区是有限的
- 管道所传送的是无格式字节流,这就要求管道的读出方和写入方必须事先约定好数据的格式。
- 有名管道 (FIFO):有名管道不同于匿名管道之处在于它提供了一个路径名与之关联,以有名管道的文件形式存在于文件系统中(克服血缘进程通信)
- 特点
- 管道/匿名管道 (PIPE):实质是一个内核缓冲区,进程以先进先出的方式从缓冲区存取数据,管道一端的进程顺序的将数据写入缓冲区,另一端的进程则顺序的读出数据。
- 信号(Signal)
- 来源:硬件来源:用户按键输入Ctrl+C退出、硬件异常如无效的存储访问等。软件终止:终止进程信号、其他进程调用kill函数、软件异常产生信号
- 处理过程
- 信号被某个进程产生,设置传递的对象,传递给操作系统;
- OS选择性的发送给接收者(判断是否阻塞)
- 目的进程接收到此信号,执行中断,完成后恢复
- 消息(Message)队列:存放在内核中的消息链表
- 共享内存(share memory):共享内存的机制,就是拿出⼀块虚拟地址空间来,映射到相同的物理内存中
- 信号量(semaphore):是一个计数器,用于多进程对共享数据的访问,信号量的意图在于进程间同步。
- 套接字(Socket):不同平台上进程通信
-
线程通信方式
- 锁机制:包括互斥锁/量(mutex)、读写锁(reader-writer lock)、自旋锁(spin lock)、条件变量(condition)互斥锁/量(mutex):提供了以排他方式防止数据结构被并发修改的方法。
- 信号量机制(Semaphore)无名线程信号量
- 信号机制(Signal):类似进程间的信号处理
- 屏障(barrier):屏障允许每个线程等待,直到所有的合作线程都达到某一点,然后从该点继续执行。
三、多线程同步
- 互斥:保证⼀个线程在临界区执⾏时,其他线程应该被阻⽌进⼊临界区
- 同步:并发进程/线程在⼀些关键点上可能需要互相等待与互通消息,这种相互制约的等待与互通信息称为进程/线程同步。
- 互斥与同步的实现和使⽤:
- 锁 :加锁、解锁操作;
- 信号量 :P、V 操作;
- 进程同步方式
- 进程同步与互斥的软件实现方法
- 单标志法
- 进程同步与互斥的软件实现方法
- 线程同步方式
- 经典同步问题:
- 哲学家就餐问题
- 读者-写者问题
四、死锁
- 死锁条件:互斥条件;持有并等待条件;不可剥夺条件;环路等待条件;
- 利⽤⼯具排查死锁问题:
- 避免死锁:资源有序分配法,来破环环路等待条件。
五、悲观锁和乐观锁
第三部分 调度算法
一、内存⻚⾯置换算法
-
最佳⻚⾯置换算法:置换在「未来」最⻓时间不访问的⻚⾯。
-
先进先出置换算法(FIFO):选择在内存驻留时间很⻓的⻚⾯进⾏中置换
-
最近最久未使⽤的置换算法(LRU):选择最⻓时间没有被访问的⻚⾯进⾏置换
- 实现原理:使用LinkedHashMap实现,LinkedHashMap底层就是用的HashMap加双链表实现的,而且本身已经实现了按照访问顺序的存储。此外,LinkedHashMap中本身就实现了一个方法removeEldestEntry用于判断是否需要移除最不常读取的数,方法默认是直接返回false,不会移除元素,所以需要重写该方法。即当缓存满后就移除最不常用的数。
public class LRU<K,V> { private static final float hashLoadFactory = 0.75f; private LinkedHashMap<K,V> map; private int cacheSize; public LRU(int cacheSize) { this.cacheSize = cacheSize; int capacity = (int)Math.ceil(cacheSize / hashLoadFactory) + 1; map = new LinkedHashMap<K,V>(capacity, hashLoadFactory, true){ private static final long serialVersionUID = 1; @Override protected boolean removeEldestEntry(Map.Entry eldest) { return size() > LRU.this.cacheSize; } }; } public synchronized V get(K key) { return map.get(key); } public synchronized void put(K key, V value) { map.put(key, value); } public synchronized void clear() { map.clear(); } public synchronized int usedSize() { return map.size(); } public void print() { for (Map.Entry<K, V> entry : map.entrySet()) { System.out.print(entry.getValue() + "--"); } System.out.println(); } }- 优缺点:当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
-
时钟⻚⾯置换算法:
-
最不常⽤(LFU)算法:当发⽣缺⻚中断时,选择「访问次数」最少的那个⻚⾯,并将其淘汰。
二、磁盘调度算法
- 先来先服务算法:先到来的请求,先被服务。如果⼤量进程竞争使⽤磁盘,请求访问的磁道可能会很分散,那先来先服务算法在性能上就会显得很差,因为寻道时间过⻓。
- 最短寻道时间优先算法:优先选择从当前磁头位置所需寻道时间最短的请求,但这个算法可能存在某些请求的饥饿
- 扫描算法算法:磁头在⼀个⽅向上移动,访问所有未完成的请求,直到磁头到达该⽅向上的最后的磁道,才调换⽅向。不会产⽣饥饿现象,但是存在这样的问题,中间部分的磁道会⽐较占便宜,中间部分相⽐其他部分响应的频率会⽐较多,也就是说每个磁道的响应频率存在差异。
- 循环扫描算法:只有磁头朝某个特定⽅向移动时,才处理磁道访问请求,⽽返回时直接快速移动⾄最靠边缘的磁道,并且返回中途不处理任何请求。
- LOOK 算法:磁头在每个⽅向上仅仅移动到最远的请求位置,然后⽴即反向移动,⽽不需要移动到磁盘的最始端或最末端,反向移动的途中会响应请求。
- C-LOOK 算法:磁头在每个⽅向上仅仅移动到最远的请求位置,然后⽴即反向移动,⽽不需要移动到磁盘的最始端或最末端,反向移动的途中不会响应请求。
第四部分 文件系统
一、文件存储
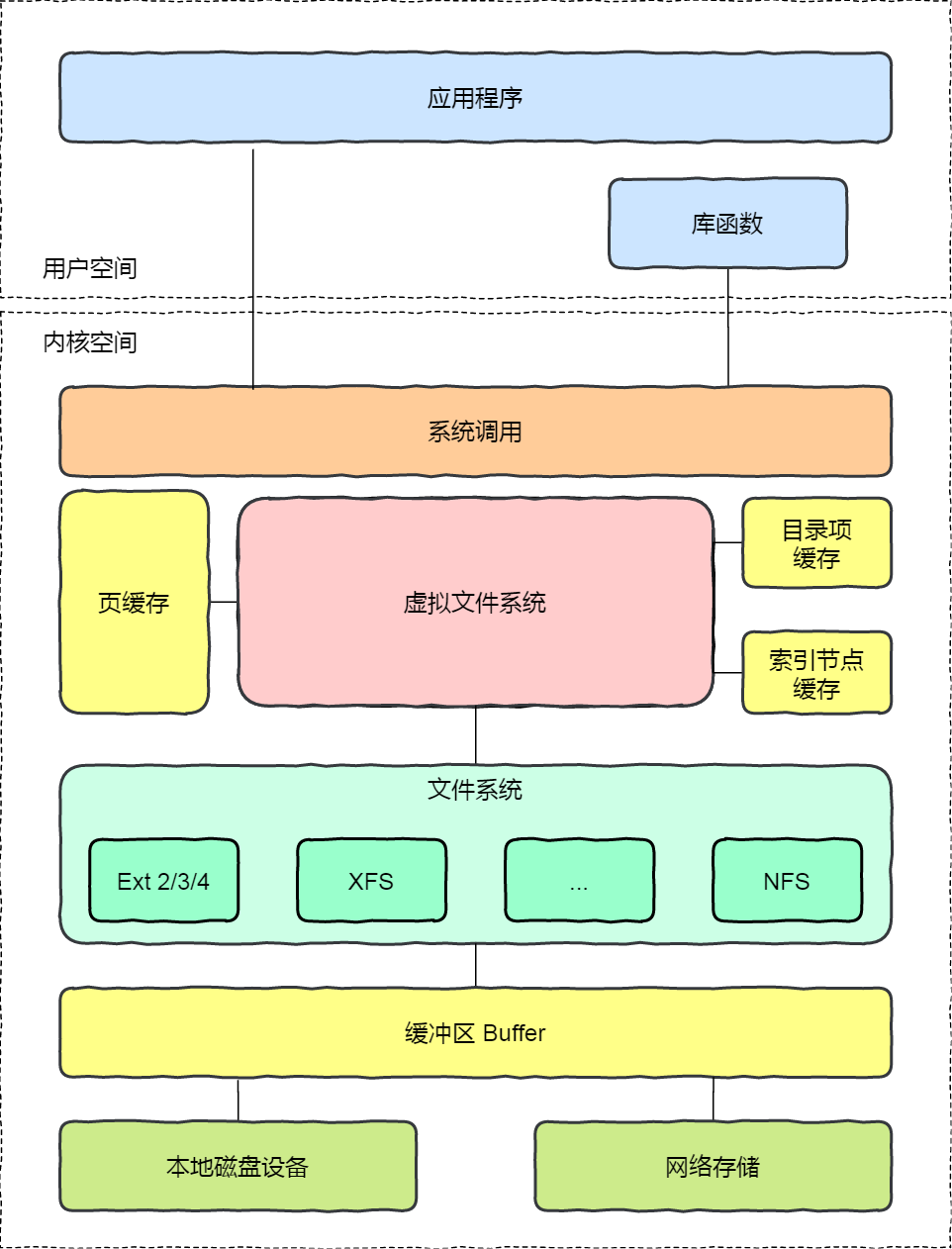
- Linux ⽂件系统组成:为每个⽂件分配两个数据结构:索引节点(index node)和⽬录项(directory entry),主要⽤来记录⽂件的元信息和⽬录层次结构。
- 虚拟⽂件系统:⽂件系统的种类众多,⽽操作系统希望对⽤户提供⼀个统⼀的接⼝,于是在⽤户层与⽂件系统层引⼊了中间层,这个中间层就称为虚拟⽂件系统(Virtual File System , VFS)。
- ⽂件的存储:
- 连续空间存放⽅式:
- ⽂件存放在磁盘「连续的」物理空间中。这种模式下,⽂件的数据都是紧密相连,读写效率很⾼,因为⼀次磁盘寻道就可以读出整个⽂件。
- ⽂件头⾥需要指定「起始块的位置」和「⻓度」
- 有「磁盘空间碎⽚」和「⽂件⻓度不易扩展」的缺陷。
- ⾮连续空间存放⽅式
- 链表⽅式:链表的⽅式存放是离散的,不⽤连续的,可以消除磁盘碎⽚,提⾼磁盘空间的利⽤率,同时⽂件的⻓度可以动态扩展。
- 隐式链表:⽂件头要包含「第⼀块」和「最后⼀块」的位置,并且每个数据块⾥⾯留出⼀个指针空间,⽤来存放下⼀个数据块的位置。缺点在于⽆法直接访问数据块,只能通过指针顺序访问⽂件,以及数据块指针消耗了⼀定的存储空间,稳定性较差。
- 显式链接:把⽤于链接⽂件各数据块的指针,显式地存放在内存的⼀张链接表中,该表在整个磁盘仅设置⼀张,每个表项中存放链接指针,指向下⼀个数据块号。提⾼了检索速度,⽽且⼤⼤减少了访问磁盘的次数。但也正是整个表都存放在内存中的关系,主要的缺点是不适⽤于⼤磁盘。
- 索引⽅式:为每个⽂件创建⼀个「索引数据块」,⾥⾯存放的是指向⽂件数据块的指针列表,另外,⽂件头需要包含指向「索引数据块」的指针
- 优点在于:⽂件的创建、增⼤、缩⼩很⽅便;不会有碎⽚的问题;⽀持顺序读写和随机读写;
- 缺陷之⼀就是存储索引带来的开销
- 链表 + 索引:在索引数据块留出⼀个存放下⼀个索引数据块的指针,当⼀个索引数据块的索引信息⽤完了,就可以通过指针的⽅式,找到下⼀个索引数据块的信息
- 多级索引块:通过⼀个索引块来存放多个索引数据块
- 链表⽅式:链表的⽅式存放是离散的,不⽤连续的,可以消除磁盘碎⽚,提⾼磁盘空间的利⽤率,同时⽂件的⻓度可以动态扩展。
- Unix ⽂件的实现⽅式:混合索引方式,根据⽂件的⼤⼩,包含一级、二级等索引
- 连续空间存放⽅式:
- 空闲空间管理
- 空闲表法:为所有空闲空间建⽴⼀张表,表内容包括空闲区的第⼀个块号和该空闲区的块个数,注意,这个⽅式是连续分配的。
- 空闲链表法:使⽤「链表」的⽅式来管理空闲空间,每⼀个空闲块⾥有⼀个指针指向下⼀个空闲块。当创建⽂件需要⼀块或⼏块时,就从链头上依次取下⼀块或⼏块。反之,当回收空间时,把这些空闲块依次接到链头上。
- 位图法:利⽤⼆进制的⼀位来表示磁盘中⼀个盘块的使⽤情况,磁盘上所有的盘块都有⼀个⼆进制位与之对应。
- ⽬录的存储:
- 普通⽂件的块⾥⾯保存的是⽂件数据,⽽⽬录⽂件的块⾥⾯保存的是⽬录⾥⾯⼀项⼀项的⽂件信息。
- 软链接和硬链接:
- 硬链接:多个⽬录项中的「索引节点」指向⼀个⽂件,也就是指向同⼀个 inode,硬链接是不可⽤于跨⽂件系统的,只有删除⽂件的所有硬链接以及源⽂件时,系统才会彻底删除该⽂件。
- 软链接:相当于重新创建⼀个⽂件,这个⽂件有独⽴的 inode,但是这个⽂件的内容是另外⼀个⽂件的路径,软链接是可以跨⽂件系统的,甚⾄⽬标⽂件被删除了,链接⽂件还是在的,只不过指向的⽂件找不到了⽽已。
- 硬链接和软链接有什么区别?
二、文件I/O
- 缓冲与⾮缓冲 I/O
- 缓冲 I/O,利⽤的是标准库的缓存实现⽂件的加速访问,⽽标准库再通过系统调⽤访问⽂件。
- ⾮缓冲 I/O,直接通过系统调⽤访问⽂件,不经过标准库缓存。
- 直接与⾮直接 I/O
- 直接 I/O,不会发⽣内核缓存和⽤户程序之间数据复制,⽽是直接经过⽂件系统访问磁盘。
- ⾮直接 I/O,读操作时,数据从内核缓存中拷⻉给⽤户程序,写操作时,数据从⽤户程序拷⻉给内核缓存,再由内核决定什么时候写⼊数据到磁盘。
- 阻塞与⾮阻塞 I/O VS 同步与异步 I/O
- 阻塞与⾮阻塞 I/O:当⽤户程序执⾏ read ,线程会被阻塞,⼀直等到内核数据准备好,并把数据从内核缓冲区拷⻉到应⽤程序的缓冲区中,当拷⻉过程完成, read 才会返回。阻塞等待的是「内核数据准备好」和「数据从内核态拷⻉到⽤户态」这两个过程。
- ⾮阻塞的 read 请求在数据未准备好的情况下⽴即返回,可以继续往下执⾏,此时应⽤程序不断轮询内核,直到数据准备好,内核将数据拷⻉到应⽤程序缓冲区, read 调⽤才可以获取到结果。
- ⽆论是阻塞 I/O、⾮阻塞 I/O,还是基于⾮阻塞 I/O 的多路复⽤都是同步调⽤。因为它们在 read 调⽤时,内核将数据从内核空间拷⻉到应⽤程序空间,过程都是需要等待的,也就是说这个过程是同步的,如果内核实现的拷⻉效率不⾼,read 调⽤就会在这个同步过程中等待⽐较⻓的时间。⽽真正的异步 I/O 是「内核数据准备好」和「数据从内核态拷⻉到⽤户态」这两个过程都不⽤等待。
第五部分 面试题
- 堆和栈的区别,堆怎么存储的,在操作系统里堆和栈怎么体现,堆和栈里面分别存放什么信息?
- 操作系统怎么处理中断的?怎么判断是哪种类型的中断?
- 操作系统执行一个程序的过程?
- 一个进程占有哪些资源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号