数据结构:第七章学习小结
这一章我们学习了线性表、树表、散列表的查找。下图是我对本章所学知识的大致总结。
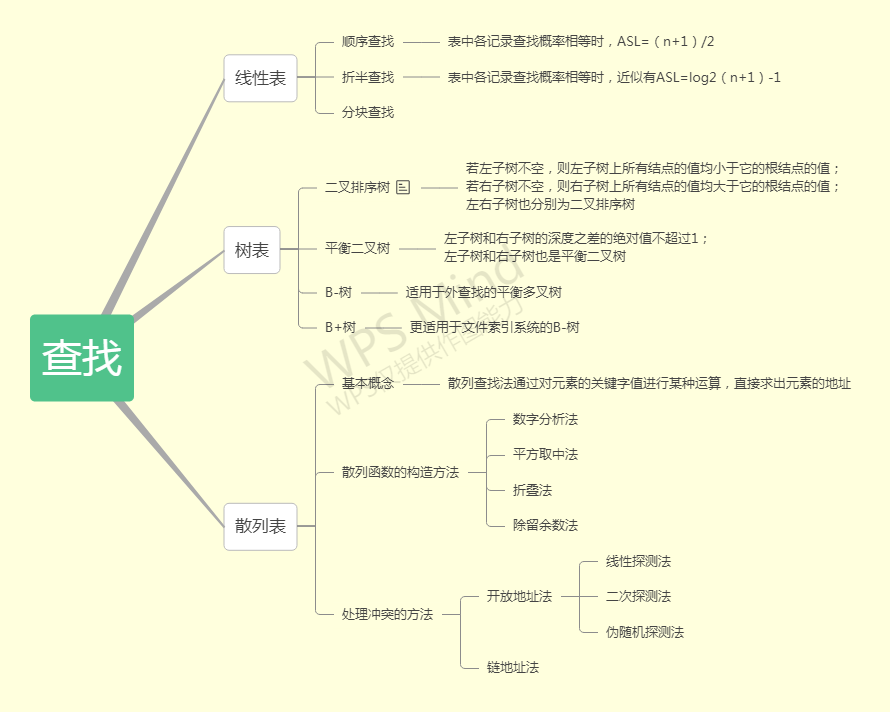
这一章的知识点非常多且极易记混淆,所以对我而言还是很有难度的。
首先在学习线性表的查找时,重点就是二分查找法。其中要注意两点:1.low<=high而不是low<high; 2.high=mid-1而不是high=mid
学习散列表的查找时,重点就是处理冲突的方法。
作业思考:
1.在做实践一:二分查找变形时,我的思维还是受到了一定的局限,太过于依赖书上提供的代码,导致自己思考问题不够透彻,打出的代码也复杂难懂,且有多处冗余。在跟同学交流后,才学习到了更好的做法:
int Search_Bin(SSTable ST,int key) { int low=0,high=ST.length-1,mid; if(key<ST.R[low]) return 0;//如果key小于有序表中第0位,那么0就是自左向右大于key的一个数的下标 if(key>ST.R[high]) return -1; while(low<=high) { mid = (low+high)/2; if(key<=ST.R[mid]) high = mid - 1; else low = mid + 1; } return low; }
2.在作业题中,有关召回率和准确率的题目也让我感到困惑,好在找到了这篇博客 https://www.cnblogs.com/huanglifeng/p/8350395.html
召回率(Recall Rate,也叫查全率)是检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率;精度是检索出的相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率。召回率(Recall)和精度(Precise)是广泛用于信息检索和统计学分类领域的两个度量值,用来评价结果的质量。
3.在代码题Hashing中,我参考了这篇博客:https://blog.csdn.net/qq_38975493/article/details/90370475?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522159322718219195265942279%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=159322718219195265942279&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_v2~rank_v25-10-90370475.pc_search_back_js3&utm_term=7-1Hashing
虽然他的分析不是非常详细,也没有注释,但是代码非常清晰
#include<stdio.h> #include<math.h> #include<stdlib.h> struct Hash{ int Size; int *Num; }H; int InsertHash(int X){ int Realkey; int key=X%H.Size; int k=0; while(k<=H.Size){ Realkey=(key+pow(k*1.0,2.0)); Realkey=Realkey%H.Size; if(!H.Num[Realkey]){ H.Num[Realkey]=X; break; } k++; } if(k>H.Size) Realkey=-1; return Realkey; } int IsPrime(int M){ int i; for(i=2;i<=sqrt(M);i++){ if(M%i==0) return 0; } return 1; } int main(){ int i; int M,N; scanf("%d%d",&M,&N); i=M; while(!IsPrime(i)) i++; if(i==1) i++; H.Size=i; H.Num=(int*)malloc(H.Size*sizeof(int)); for(i=0;i<H.Size;i++) H.Num[i]=0; int X,Position[N]; for(i=0;i<N;i++){ scanf("%d",&X); Position[i]=InsertHash(X); } // printf("H.size=%d\n",H.Size); for(i=0;i<N;i++){ if(Position[i]!=-1) printf("%d",Position[i]); else printf("-"); if(i<N-1) printf(" "); else printf("\n"); } return 0; }
但是我觉得在处理冲突时可以不用pow函数,毕竟k是int型变量,转换为double型变量也不是非常妥当;
题目难点在于处理冲突部分,易错点在于1不属于质数,需要特别注意。
学习心得:查找这一章的内容有我们熟悉的顺序查找和二分查找,也有我们闻所未闻的B-、B+树和哈希表,虽然整体是一个从简到难的学习过程,但难的部分我还是没能够掌握好,在做思维导图回顾整篇内容时,我也明显感觉到了知识点的陌生,这一点还是要怪我看书看少了,所以接下来不仅是本章内容还有全面复习,我都需要回到课本,结合以往作业,对所学知识进行汇总。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号