

注:本文已于2025.10.26 发表于知乎和公众号
1. 简介
前序的两篇笔记,先系统总结所有 SGLang 分布式集群模式,然后介绍 TP 集群处理请求的完整流程。本文将对 PP 集群做介绍,重点讲解流水线调度、分布式通信组以及通信量推导。PP 模式将模型中的多个层拆分到不同的 GPU 上,集群可以承载更大的模型,和 TP 模式相比,它可以降低通信量、提高计算效率,进而有机会提升整体吞吐。
2. 进程视角架构图
以 PP2 * TPN 为例:
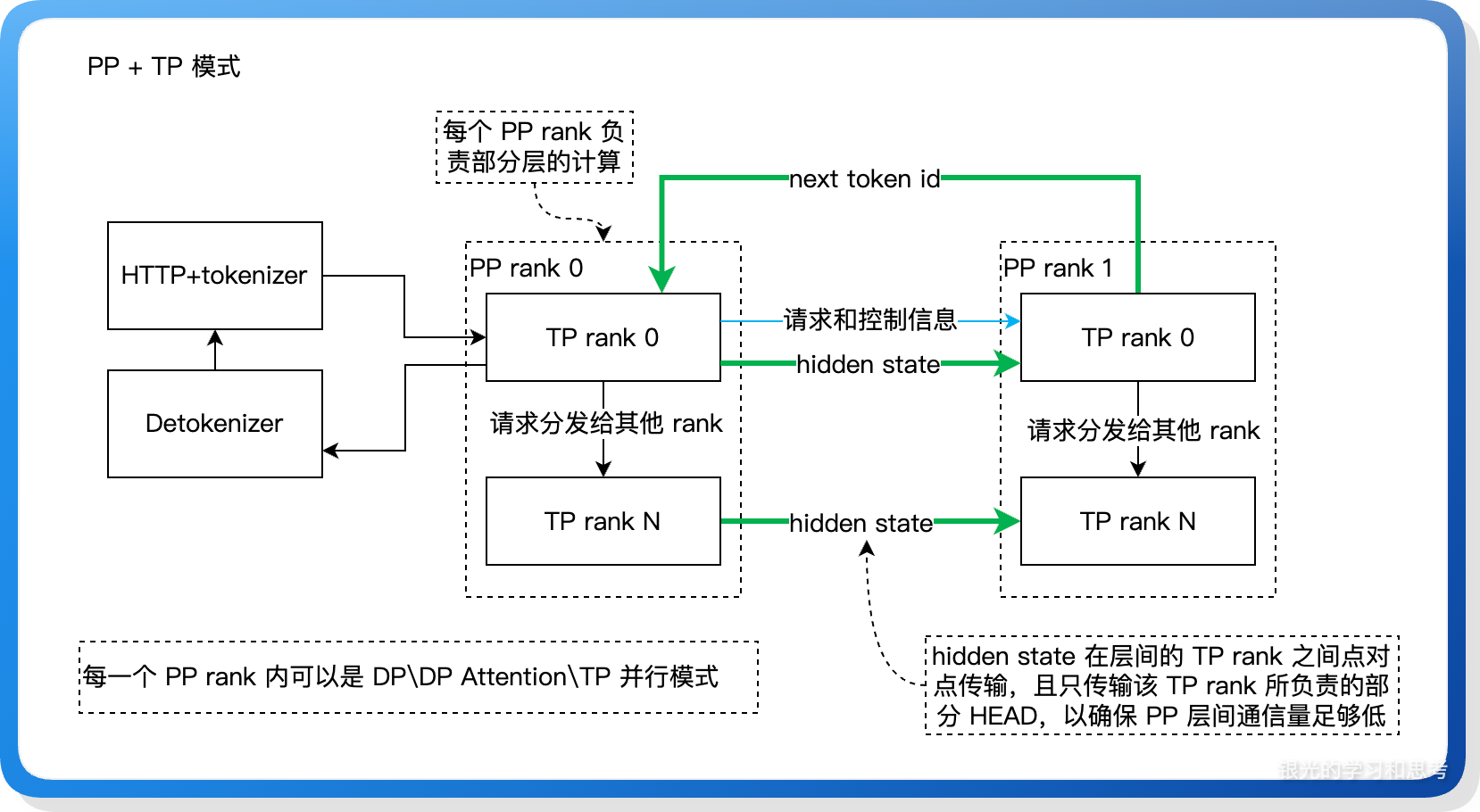
如上图所示,涉及三类进程:
- HTTP + tokenizer 组成服务入口进程,负责提供 HTTP 接口,以及将输入 prompt 转为 token id。
- Detokenizer 负责将模型生成的 token id 转回文本。
- 所有 TP rank 组成的集群负责模型推理计算。TP rank 分为两组,PP rank 0 和 PP rank 1,每个 PP rank 下的 TP rank 单独编序号。注:TP rank 的实际承载进程是 Scheduler 进程,为方便描述以 TP rank 进程代替。
进程之间主要有三类通信:
- PP rank 0 下的 TP rank 0 负责整个 TP rank 集群和外部的通信,包括:接收来自 tokenizer 的输入、收集计算结果发给 detokenizer 进程。
- 不同 PP rank 的 TP rank 0 之间传递请求和控制信息。
- PP 层间所有 TP rank 点对点传输 hidden state,每个 TP rank 只传输自己负责的部分分片数据。hidden state 只传输部分分片,而不是完整的 hidden state,这尽量的减少 PP rank 间的通信量,后续 PP rank 内再通过 all_gather 收集完整的 hidden state。这个设计将 hidden state 传输拆分为两步,第一步是 PP rank 之间,第二步是 PP rank 内的 TP rank 之间,相比在所有的 TP rank 上一次性将 hidden state 传输到位,这个设计可以减少 PP rank 之间的通信量,当 PP rank 处于不同的网络节点下时,可以大幅度降低跨节点通信量,整体通信耗时更短(代码细节见:
send_tensor_dict和recv_tensor_dict函数)。
3. 启动命令举例
3.1. 单机模式
python3 -m sglang.launch_server --model-path xxx --port 30000 --tp 2 --pp 4
参数说明:
- --tp,指定一个 PP rank 下的 TP size 数
- --pp,指定整个集群的 PP rank 数
3.2. 多机模式
多机模式的启动命令需要加上多机通信需要的 IP:Port、总节点数、本节点在多节点中的序号:
- --dist-init-addr [ip:port],用于指明多机通信的首节点 IP 和 起始端口
- --nnodes [总节点数],用于指明总共有多少台机器组成一个 TP 集群
- --node-rank [本节点号],用于指明本节点在所有节点中的序号
# 两个节点,每个节点有 8 个 GPU 组成 PP4*TP4 集群 # 节点 0 12.123.123.123 NCCL_SOCKET_IFNAME=bond1 python3 -m sglang.launch_server --model-path xxx --dist-init-addr 12.123.123.123:20000 --nnodes 2 --node-rank 0 --tp 4 --pp 4 --port 30000 # 节点 1 其他 IP NCCL_SOCKET_IFNAME=bond1 python3 -m sglang.launch_server --model-path xxx --dist-init-addr 12.123.123.123:20000 --nnodes 2 --node-rank 1 --tp 4 --pp 4 --port 30000
其中 NCCL_SOCKET_IFNAME 用于 RDMA 通信前建立连接,bond1 绑定的是本机对外通信的 IP,这部分信息可以通过 ip addr show | grep bond 查看。如果使用了其他 bond,会导致启动失败。另外,也有文档提到,如果遇到启动失败,可以试下设置环境变量 export NCCL_IB_GID_INDEX=3
4. PP 模式的限制
- pp_size * tp_size 必须能被节点数整除。
- 模型层数必须大于 pp_size。
- 不能和多个功能同时使用: overlap、投机采样、mixed chunk(prefill 和 decode 混合执行)。
因大多数模型的层数都有几十层,所以 PP 模式在并行度上的限制比较少。
5. 进程启动的核心过程
下面的章节开始介绍 SGLang PP 模式代码实现,本章先介绍进程启动时的处理。
5.1. 流程图
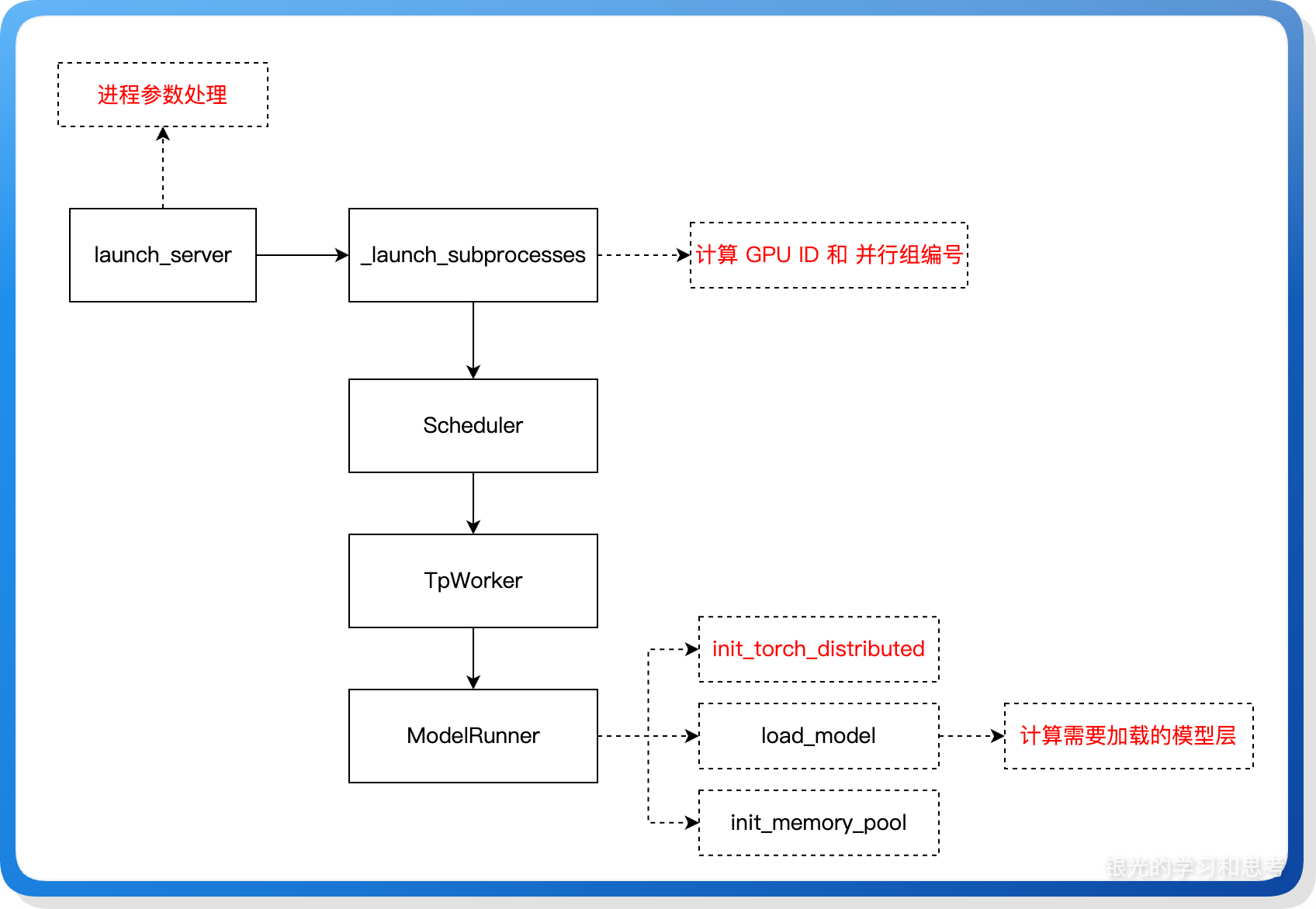
上图展示 PP 模式进程启动时处理的关键阶段,下面对这些关键阶段做讲解。
5.2. 计算 GPU ID 编号和并行组编号
5.2.1. 原理和概念
(1)编号(rank)的作用
通常一个节点有多张 GPU 卡,由 HTTP 进程负责做 GPU ID 编号、并行组编号,然后再启动 GPU 进程(即 Scheduler 进程),每个编号唯一标识一个 GPU 计算进程,后续的模型加载、模型计算、张量通信都基于编号。
(2)GPU ID 编号
GPU ID 是本地 GPU 号,可以通过进程参数指定起始 GPU ID、GPU ID 的增长步长。譬如:GPU ID base 为 0,步长为 2,本机的总 GPU 个数为 4,那么本机的 GPU ID 列表是:[0, 2, 4, 8],这些 GPU ID 代表了一张张的 GPU 卡,创建张量或者通信组时,我们通过 GPU ID 告诉 pytorch API 或者 CUDA API 使用哪些 GPU 硬件。
(3)并行组编号
在加载模型权重、建立通信组时,我们怎么知道某个 GPU 要加载哪部分权重,某几个 GPU 需要建立通信组呢?这和分布式集群的并行组织有关,我们根据集群的并行组织,为每个 GPU 生成一个并行组编号,然后根据 GPU 的并行组编码确认该 GPU 需要存储哪部分张量,需要和哪些 GPU 建立通信。
一张 GPU 卡在每一个并行维度下都有对应编号,当前系统支持 TP、PP 两类并行,我们可以把某个 GPU 的并行组编号描述为 [tp_rank, pp_rank],譬如:[4, 0] 表示某个 GPU 是第 0 PP 分组的第 4 个 TP rank。
5.2.2. 代码实现
在 engine.py 的 _launch_subprocesses 函数里实现 GPU ID 编号、并行组(PP rank、TP rank)编号,然后用这些编号启动 scheduler 进程。计算方式较为复杂,思路总结如下:
(1)先求得当前节点所负责的 PP rank 区间;
(2)再求得当前节点一个 PP rank 内的 TP rank 编码区间;
(3)基于 PP rank、TP rank 计算出 GPU ID;
(4)整体上分为两层,第一层遍历 PP rank,第二层遍历 TP rank;
开源代码注解:
# 计算一个 PP rank 下的 tp group 分布在多少个节点上 nnodes_per_tp_group = max(server_args.nnodes // server_args.pp_size, 1) # 计算一个节点上有多少个同属于一个 PP rank 的 tp rank tp_size_per_node = server_args.tp_size // nnodes_per_tp_group # 计算本节点在本 PP rank 下的 tp rank 区间 tp_rank_range = range( tp_size_per_node * (server_args.node_rank % nnodes_per_tp_group), tp_size_per_node * (server_args.node_rank % nnodes_per_tp_group + 1), ) # 计算一个节点下有多少个 PP rank pp_size_per_node = max(server_args.pp_size // server_args.nnodes, 1) # 计算本节点的 PP rank 区间 pp_rank_range = range( pp_size_per_node * (server_args.node_rank // nnodes_per_tp_group), pp_size_per_node * (server_args.node_rank // nnodes_per_tp_group + 1), ) for pp_rank in pp_rank_range: for tp_rank in tp_rank_range: reader, writer = mp.Pipe(duplex=False) GPU_id = ( server_args.base_GPU_id + ((pp_rank % pp_size_per_node) * tp_size_per_node) + (tp_rank % tp_size_per_node) * server_args.GPU_id_step )
这个代码实现思路是 PP + TP 的原理直译,看似简单,实际上很复杂。复杂点体现在:如何计算当前节点所在的 PP rank 区间、如何计算本节点所在的 PP rank 下的 TP rank 区间。这两计算时,需要考虑两种情况:一个节点有多个 PP rank,或者是一个节点只有部分 PP rank,这导致计算代码非常复杂。除了复杂之外,可扩展性也不好,如果新增一种并行,譬如新增“序列并行”,这里的实现就需要大改动。
我们可以重新梳理思路,并做泛化设计:
(1)整个集群的 GPU 数为 N 个并行维度的乘积,又已知节点数,可以求得单个节点的 GPU 总数,然后再基于总数、起点 GPU ID、GPU ID 步长计算本节点需要处理的所有 GPU ID。
(2)已知 GPU ID,求它的并行组编号,即是求一个函数:输入 GPU ID 和 并行组的维度,输出它的并行组编号。
(3)GPU ID 和并行组编号的关系很像“数字进位”,GPU ID 相当于一个十进制数字,并行组编号相当一个 N 位数字。
按这个思路实现并行组编码,更容易理解,也有更好的扩展性。但也需要注意,这种思路要求新增的并行维度必须是符合分段设计,进而利用“数字进位”的思想处理。在前面介绍所有 SGLang 集群模式时,我们也知道有一些集群是不符合分段设计的,譬如: DP Attention 模式、EP 模式,这些并行的 tp_size 和其它的并行维度是包含关系,而不是乘积关系。
5.3. 初始化分布式通信组
5.3.1. 理论基础
(1)通信组的种类
SGLang 建立的通信组可以分为两类,一类是整个集群所有 GPU 建立的基础通信组,即世界组,整个集群只有一个;另一类是各种并行策略按需建立的通信组,这类通信组有很多,也较为复杂。
(2)通信组的 ID 是全局逻辑 ID
通信组里代表每一个 GPU 的 ID 既不是本地 GPU ID,也不是并行组编号 ID,而是全集群编号的逻辑 ID,这个逻辑 ID 和并行组编号有关系,公式:rank = self.pp_rank * self.tp_size + self.tp_rank。
(3)并行策略通信组的设计
通信组的设计和并行策略强相关,总结如下:
- TP 通信组,需要同步数据的多个 TP rank 组成一个 tp group 通信组,有 world_size / tp_size 个通信组。
- PP 通信组,不同 PP rank 之间相同位置的 TP rank 组成一个 PP group,一个 PP rank 下有多少个 TP rank,就有多少个 PP 通信组。
(4)必要的名词说明
通信组和计算组很容易混淆,这里特别做说明:
- TP group,特指为了支持 TP rank 之间做张量同步而组成一个通信组的 TP rank 集合,同时 TP group 也是并行计算小组。
- PP group,特指为了支持 PP rank 之间的张量同步而组成的一个通信组的 TP rank 集合。
- PP rank,流水线并行 worker,一个 PP rank 代表一个 TP group。
举例:TP4 * PP2:
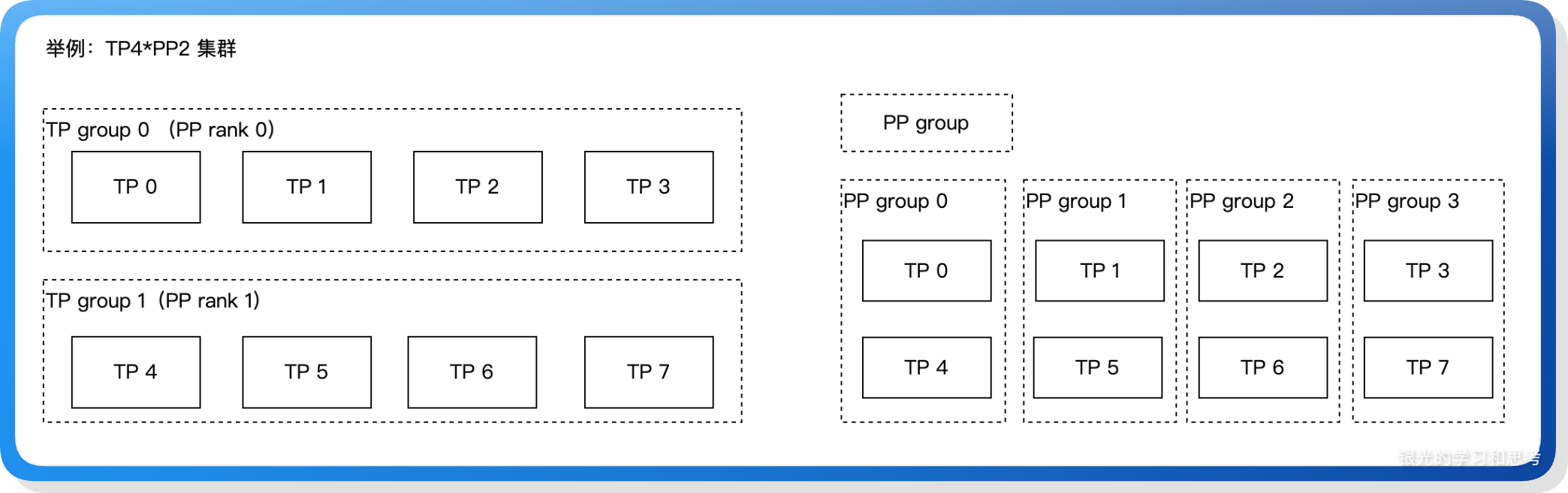
上述例子里,TP group 会建立通信组,用来完成张量并行计算。PP group 则是多个 PP rank 之间相同位置的 TP rank 建立通信组,用来完成上下阶段之间的 hidden state 传递通信。
5.3.2. 代码实现
(1)torch 世界组初始化
在 ModelRunner.init_torch_distributed 函数里执行 init_distributed_environment,使用全局 rank 执行初始化,所有的 GPU 进程组成一个世界通信组。
(2)局部通信组
在 ModelRunner.init_torch_distributed 函数里执行 initialize_model_parallel,使用 tp_size、pp_size、moe_size 初始化 4 类通信组。
- TP,建立 world_size / tp_size 个通信组,每个通信组有 tp_size 个元素;
- MoE EP,在每一个 tp_size 小组下,建立 moe_ep 通信组:全局的 TP group(有 tp_size 个元素的 TP 组)拆分为 ep_size 个 ep local tp group,所有 ep local tp group 的相同位置建立通信组。也就是有 moe_local_tp_size 个通信组,这些通信组用来做两次 all_to_all 通信,传递 token hidden state。
- MoE TP,在每一个 tp_size 小组下,为每一个 ep local tp group 建立通信组,用于 ep rank 内部的张量并行计算通信。
- PP,建立 world_size / pp_size 个通信组,每个通信组有 PP size 个元素,这 PP size 个 TP rank 会串行的流水线执行,这也是取名为 PP 的原因。注:PP 的点对点通信和 MoE EP 类似。
注:每个进程都会执行 initialize_model_parallel,计算各个通信组的组成,然后在一个并行维度上加入一个通信组。
5.4. 计算需要加载的模型层
代码实现在 sglang/python/sglang/srt/distributed/utils.py 的 get_pp_indices 函数里,提供两种实现
(1)定制分层,可以自定义分层规则,让不同的 PP 按需处理部分层。分层的规则配置在 SGLANG_PP_LAYER_PARTITION 环境变量,用逗号分隔,譬如:[2, 8],表示模型总共有 10 层,PP rank 0 处理前面 2 层,PP rank 1 处理后面 8 层。
(2)均衡分层,层数按 PP size 均分,无法整除的余数放在最后一个 PP rank。
从这两种实现来看,PP size 的限制仅在于:每个 PP rank 最少需要处理一层,这个限制很宽松。
6. 请求执行的关键过程
在TP 模式浅析文章中已系统介绍从 prompt 输入到 output token 输出的完整流程,因此本章节省略对全流程的介绍,只重点介绍 PP 模式特有的调度。
6.1. 流水线调度理论基础
在介绍 PP 模式的请求处理之前,我们先了解下流水线调度的理论知识,在了解这些知识之后,可以更好的理解代码实现。
6.1.1. 流水线执行的基础流程
假设有 4 个 PP rank,对应到 Stage 0~3,T1~T4 四个时刻处理的请求如下:
| 时刻 | Stage 0 处理 | Stage 1 处理 | Stage 2 处理 | Stage 3 处理 |
|---|---|---|---|---|
| T1 | Batch A | - | - | - |
| T2 | Batch B | Batch A | - | - |
| T3 | Batch C | Batch B | Batch A | - |
| T4 | Batch D | Batch C | Batch B | Batch A |
我们可以看到 Batch A 从 T1 时刻到 T4 时刻是从 Stage 0 流转到 Stage 3,这是流水线最基本的过程。
6.1.2. 流水线结果回传
大模型推理的流水线因为有需要反复执行的 decode 阶段,使得它和普通的流水线有一些差异:需要做流水线结果的回传。 先看看大模型推理的执行流程,突出反复 decode 和 KV Cache,将用来解释为什么我们需要流水线结果回传。
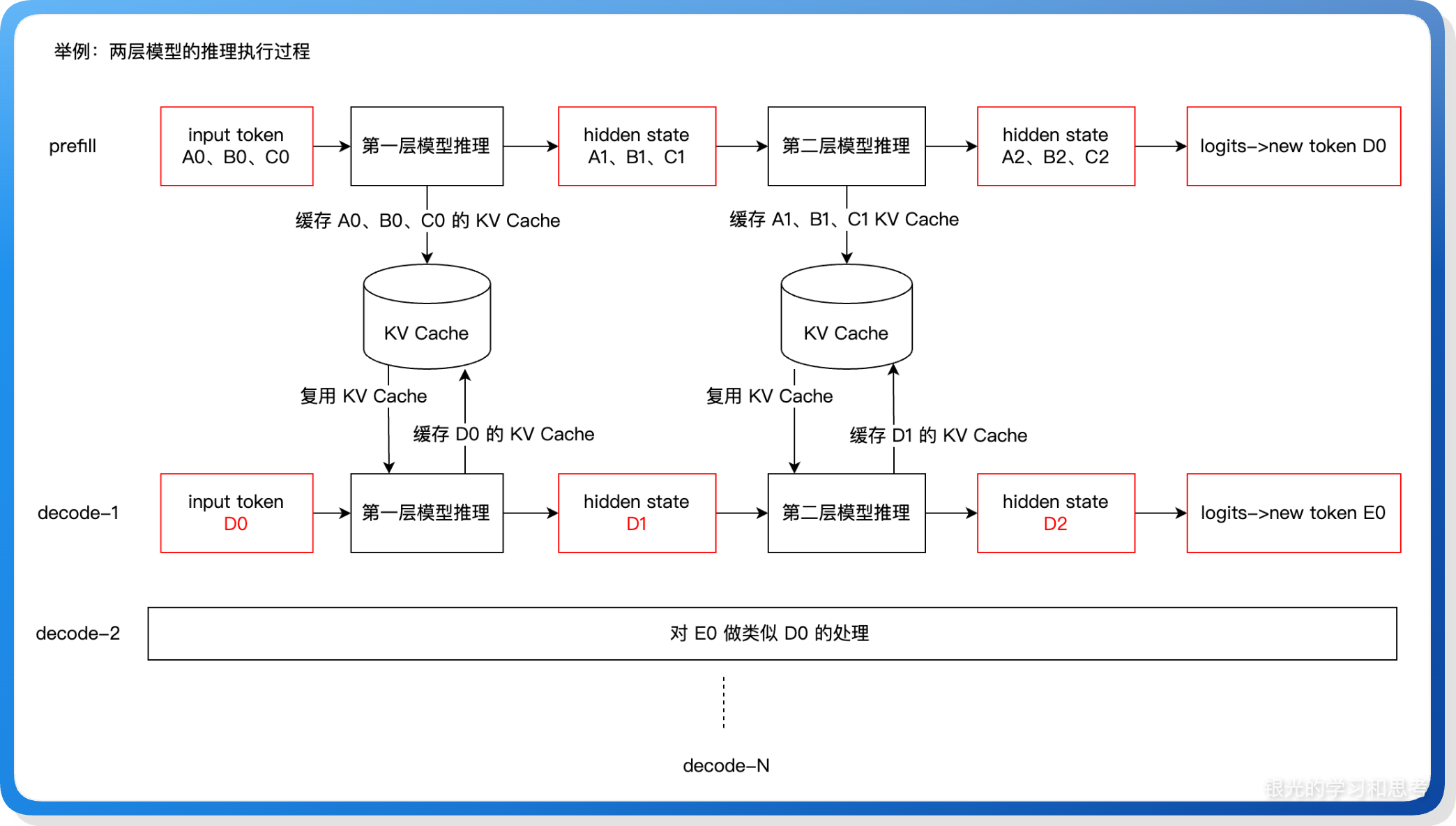
上图展示大模型推理的 prefill 和 decode 阶段对 KV Cache 的应用。我们把 prefill、decode-1、decode-2 等推理过程称为一轮推理,一轮推理包括多个模型层的处理。我们把第一层模型推理放在 PP rank 0,第二层模型推理放在 PP rank 1。对于一个请求,流水线在执行 PP rank 0 上的第一层模型的同时,还需要将本层的 KV Cache 存储到缓存中,用于下一轮推理,这些缓存信息在这个请求的推理全部执行完成之后需要清理。除了 KV Cache 之外,还有请求本身的销毁也需要考虑清理:因为一个请求需要反复的执行,所以请求会被保存下来,直到确认推理完成才做销毁。基于这些原因,大模型推理的流水线需要加上推理信号回传,在最后一个 PP rank 执行完成后,需要将请求的状态信息回传给其他 PP rank,这个“状态信息”当前用的是新生成的 token id(next token id),各个层可以基于 next token id 判断当前请求是否结束。
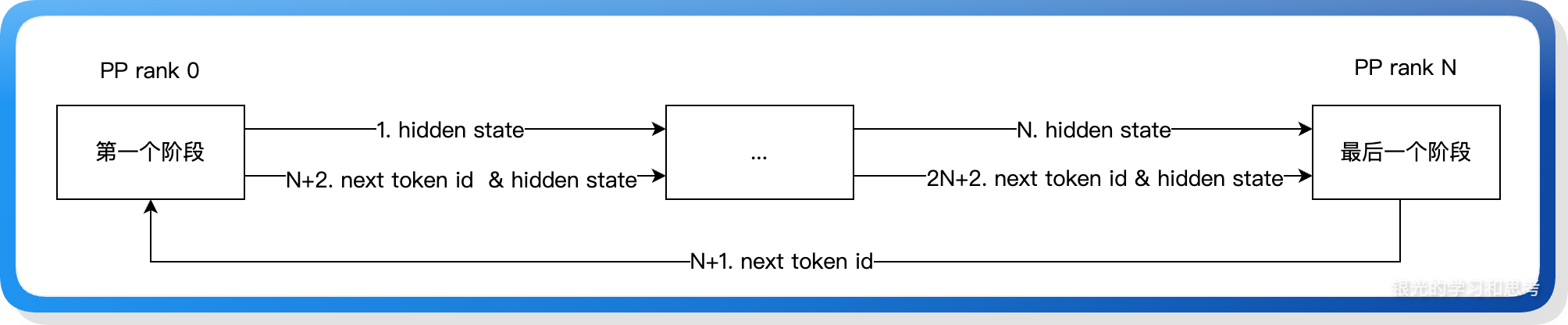
上图展示 next token id 的生成和回传,从最后一个 PP rank 产出,然后从 PP rank 0 开始传遍流水线的各个 stage,直到下一个 next token id 产出。这里我们可能会有疑问:既然各个 PP rank 都需要 next token id,为什么不是 PP rank N 直接广播给所有的 PP rank,而是要用流水线逐级在 PP rank 之间传递?
可以从两方面解释:1、首先是不需要,当 next token id 不是最后一个 token id 时,广播没有收益,此时只有 PP rank 0 需要 next token id 用来执行流水线,只有在生成最后一个 token 时,才可以用来让其他 PP rank 更早的结束请求,但平均只是早了 pp_size / 2 个流水线周期而已,价值比较小;2、然后是广播的耗时代价比点对点传播高,并且广播通信会导致整个 PP 集群有通信热点,所有的 PP rank 都需要和 PP rank N 有通信,不能让通信局部化,会带来通信瓶颈,進而影响耗时。
6.1.3. 连续批处理
在上述 decode 特色的基础上衍生出来“连续批处理”功能。decode 不是算力密集型的,如果只是执行少数请求,它不能充分利用 GPU,而“连续批处理”可以让处于不同 decode 阶段的请求随时汇集到一起执行,提升了 GPU 利用率。
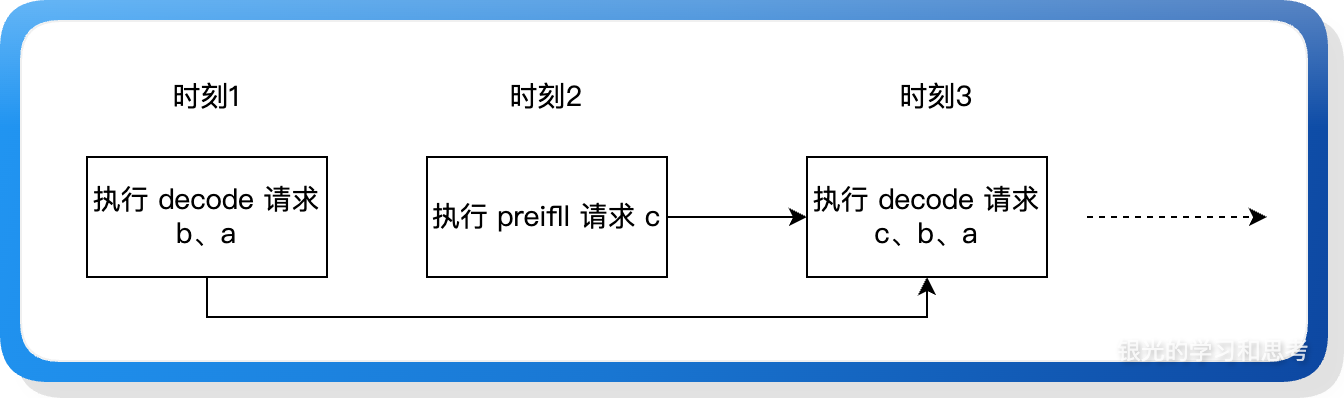
如上图所示,老的 decode 请求和新的 decode 请求可以合并到一个批次里执行,从而提高 decode 时的 GPU 使用率。连续批处理功能也需要融入到流水线执行过程中,因为流水线的特点:代表一个请求的 hidden state/token id 在多个 PP rank 之间流转,因此那些可以合并为一个批次的请求必须正好同时到达某个 PP rank,这需要在实现代码时加上筛选功能。前述的连续批处理示意图相当于 PP size 为 1 的场景。
6.2. 流水线调度的代码实现
下面来介绍 SGLang 的代码实现,初看觉得很复杂,我们从关键功能点、关键变量出发来理解代码实现,然后再思考这么设计的合理性。
6.2.1. 关键功能点
首先,我们来分析生成一个 token 的执行过程,如下:
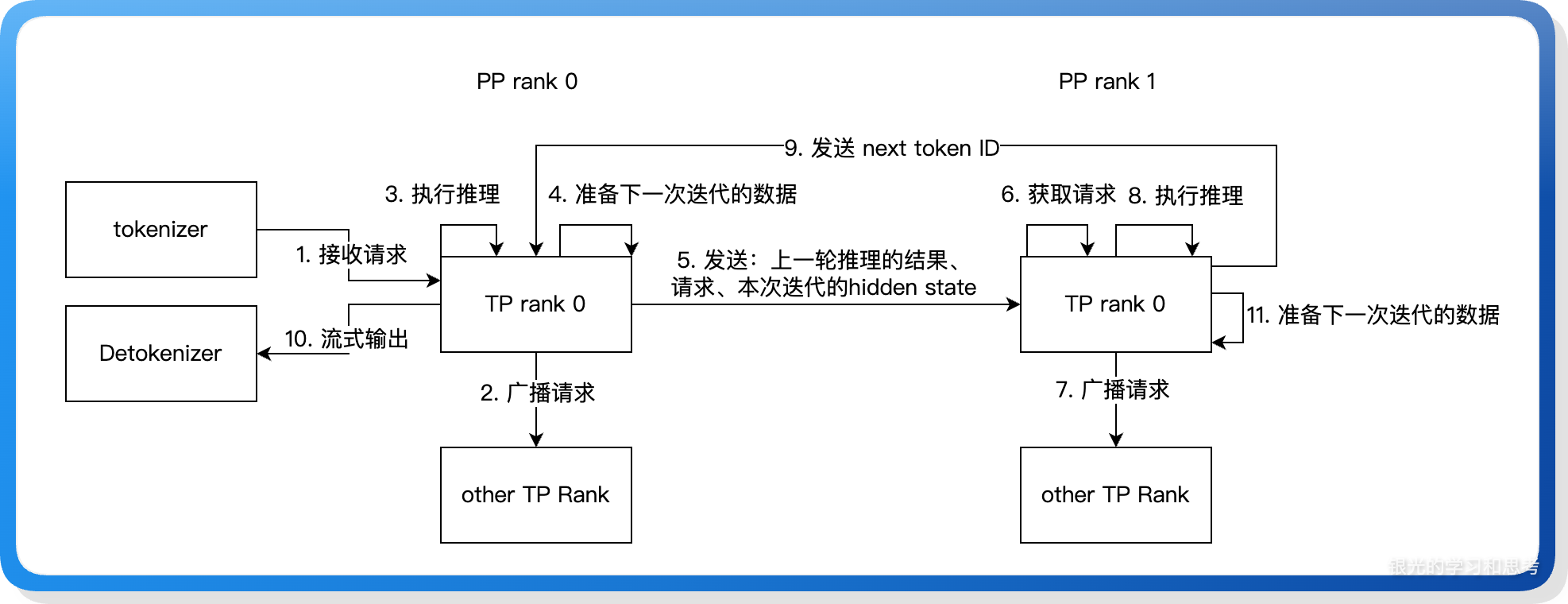
如上图所示,PP rank 0 下的 TP rank 0 收到请求后,首先将请求广播给同属一个 PP rank 的 TP rank,然后执行本 PP rank 下的推理,在最后将请求、hidden state 传给下一个 PP rank。下面介绍一些关键点:
(1)这里第 4 步准备下一次迭代的数据,是指接收上一个 PP rank 的推理结果为下一步推理做数据准备,所有的 PP rank 都设计为:先做本 PP rank 都推理,然后接收上一个 PP rank 的结果,这样所有的 PP rank 才能没有空隙的衔接起来。
(2)PP rank 0 从 tokenizer 非阻塞的获取请求,而其他 PP rank 会阻塞的通过 P2P 接口接收请求,当没有新请求时,PP rank N-1 也会发送空请求给 PP rank N,确保 PP rank N 可以执行 decode。此时,接收请求不仅仅是接收请求,也是让下一个 PP rank 继续往下执行的信号通知。
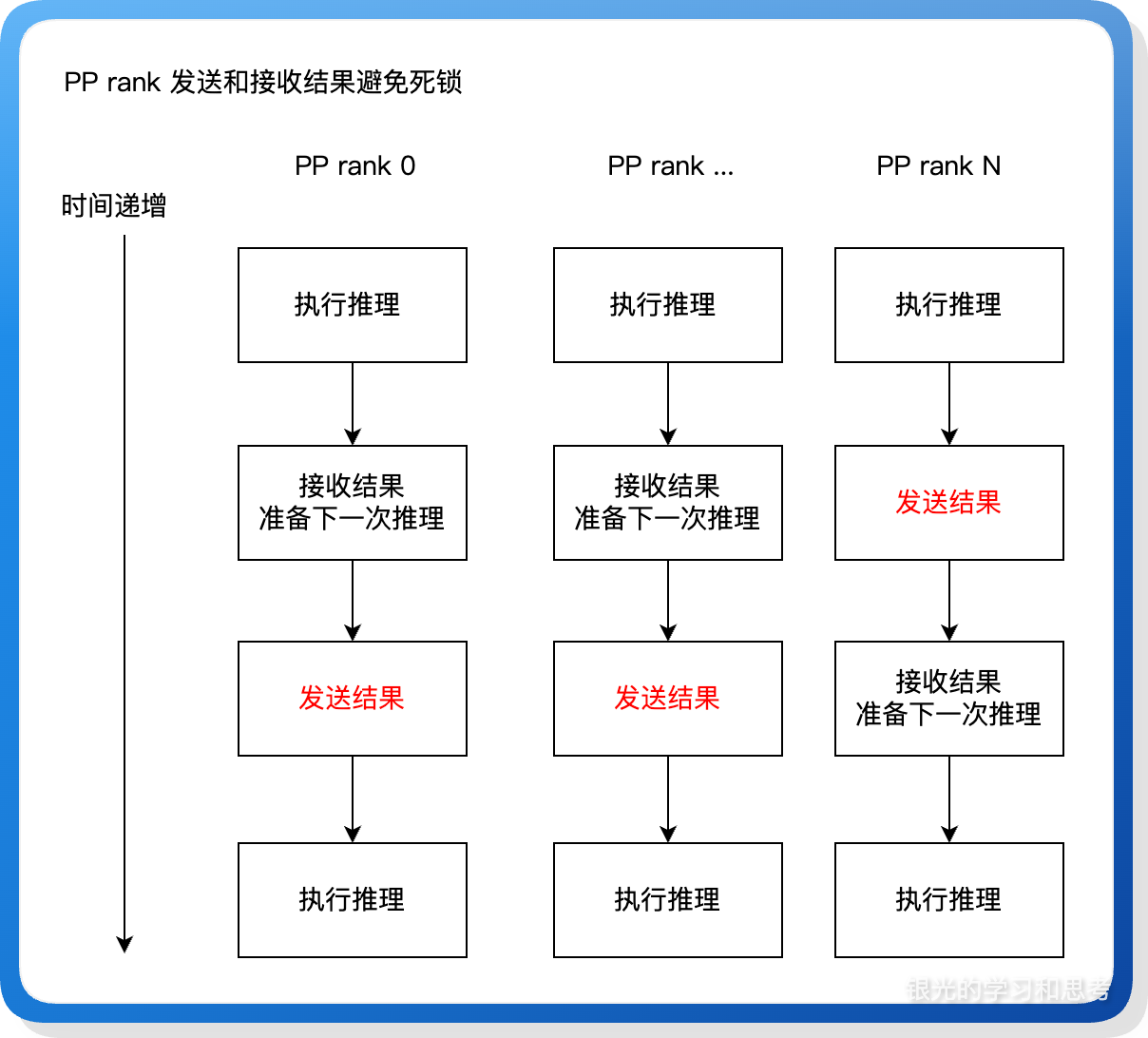
(3)多个 PP rank 之间的 <发送-接收> 通过让最后一个 PP rank 先发送后接收来确保整个流水线不会死锁。
6.2.2. 关键变量设计
为了实现连续批处理,引入了三个关键变量:正在执行的请求(mbs)、上一轮执行的请求(last_mbs)、正在持续执行 decode 请求(也叫持久化的请求,running_mbs),mbs 是微批次 microbatch 的缩写。在代码执行时,mbs 通过循环迭代实时获取到将要执行的请求,last_mbs 备份上一轮循环时的 mbs 请求,last_mbs 会合并进 running_batch,然后进入到 running_mbs。这三个变量都是数组,它们的的关联如下图:
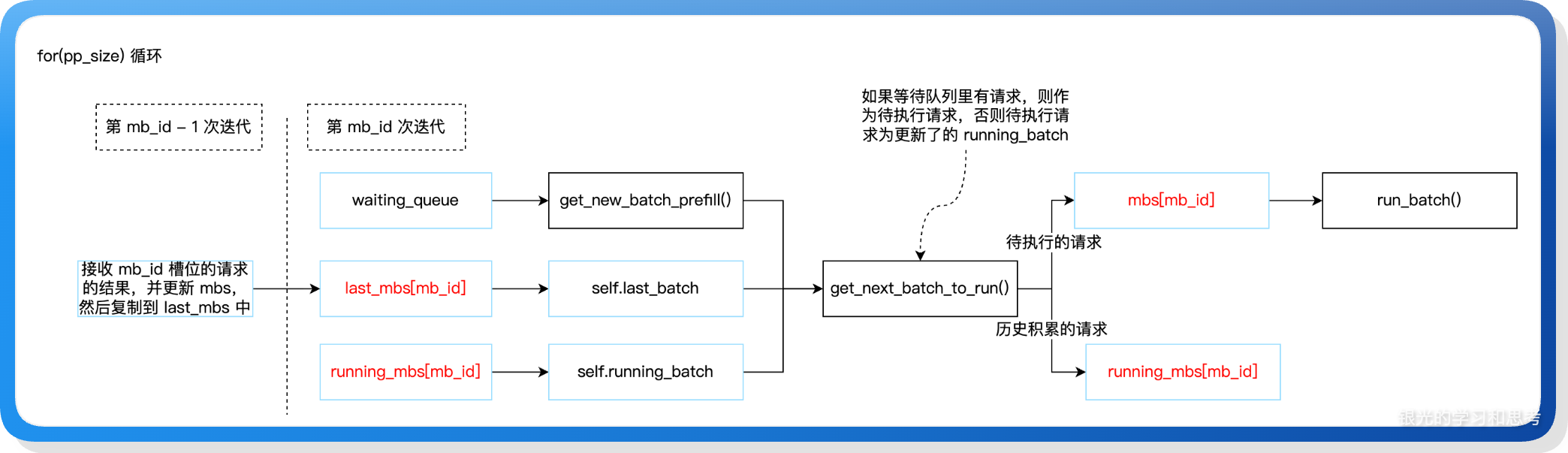
这里的设计可以分为两层:
(1)为了实现连续批处理,设计了:当前微批次、上轮微批次、持久化微批次 3 个变量;
(2)为了和流水线配合,将上述 3 个变量设计为数组,并且数组的长度为 PP size,将请求固定到数组的某个槽位里,然后循环的对数组槽位做请求填充和请求处理,基于槽位来精细控制不同 PP rank 之间的通信,以及实现同一个槽位历史轮次的 decode 请求合并(也就是连续批处理)。数组 PP size 个元素正好是执行完所有模型层需要经过的阶段,这是有意设计的。
6.2.3. 理想态的思考
理解 SGLang 实现流水线调度的核心在于理解 3 个关键数组变量,这个设计看起来很巧妙,理解起来也比较绕,很自然的我们会想到一个常见的原则:“简单才是最好的”,那么这里是否有优化空间?
(1)当前的 3 个变量是否可以合并为两个?本质上这些变量只有两个用途:当前处理的请求和需要反复执行的请求,也许可以通过调整执行顺序,把当前微批次和上轮微批次这两个变量合并为一个。
(2)用数组来实现流水线块的连续批处理是否是最佳的?
举例:PP size = 2, 模型层数 = 2 时,以当前的实现,在 PP rank 0 的时刻 4 只能执行 b 请求的 decode,而此时 a 请求也已经可以执行,并且应该更早的执行,但却因为请求分组,使得它要等到下一轮循环才能执行。案例如下图:
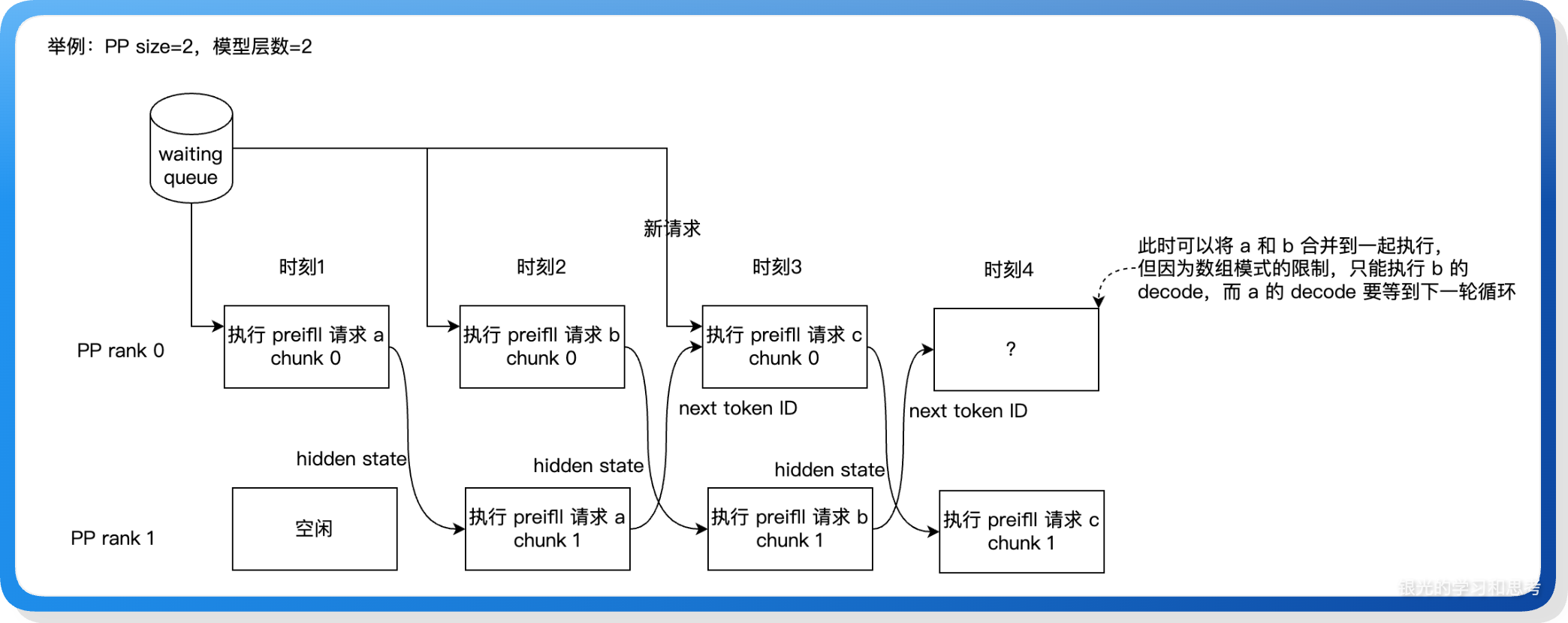
因为分组模式限制了不同分组的请求一定不能合并执行,否则会导致不同 PP rank 间的分组通信错乱,同时分组设计也导致了上一节介绍的:非 PP rank 0 需要阻塞的接收请求,同时每个 PP rank 在没有新请求的情况下也需要向下一个 PP rank 发送空请求,以便作为信号通知,这是一个很冗余的设计。从理想态考虑,分组模式会导致可以执行的请求无法及时执行,也增加了非必要的通信,所以它不是最佳的实现,也许可以把分组去掉,通过词典来标记不同的请求及其可执行状态,实现更自由的执行流程,从而提升性能。
(3)再审视 PP rank 之间传递请求的操作,这里有冗余,实际上只有第一个 PP rank 需要输入 token id,其他 PP rank 只需要请求里的参数,譬如:输出序列长度、结束字符等。
(4)代码的不对称性:粗看 event_loop_pp 里的代码时,会很困惑:为什么非 last PP rank 有两次 send_tensor_dict,但却只有一次 recv_tensor_dict?因为在 event_loop_pp 里只有接收 next token id 的代码,而接收 hidden state 的代码放在了 tp_worker.py 里。这种不对称实现的代码,给阅读理解增加障碍。
7. GPU 通信量理论分析
通信量优化是 PP 模式的一大特色,本章将对通信量的优化效果、为什么能优化做理论分析。
GPU 间的通信包括三部分:1、上一轮输出的 next token id;2、原始请求;3、hidden state。next token id 只有几个字节,原始请求每个 TP rank 只会收一次,所以这两忽略不计,只分析 hidden state 通信量,PP 模式发送 hidden state 时会分为两步,先点对点发送 1/tp_size 的 hidden state,再由接收侧 all-gather 汇集完整的 hidden state。
假设已知条件:
- 假设模型有 64 层,有 8 张 GPU 卡,集群为 PP2TP4,请求序列长度为 10,对比 TP8 的通信量。
- all-reduce 内部的实现需要一次 reduce-scatter 和一次 all-gather,一次 reduce-scatter 或者 all-gather 通信需要发出和接收共 2 * (P-1)/P 份数据,举例:TP8,all-reduce 总共通信量为 7/2 份数据。
- PP 模式下,首尾 PP rank 的通信量比中间 PP rank 通信量少,首 PP rank 不需要接收 hidden state,尾 PP rank 不需要发 hidden state,为了简化,我们都当作中间 PP rank(需要收发 hidden state)来算通信量。
7.1. 单卡通信量分析
(1)PP2TP4,单卡通信量
- PP rank 之间:非首尾 PP rank 下的单个 TP rank 需要收发 hidden state。接收时,先点对点接收 1/4 的 hidden state,然后再通过 all_gather 收集到完整的 hidden state,all_gather 通信量为 2 * 3 / 4 hidden state。发送时,点对点发送 1/4 的 hidden state。10 个 token 的总通信量:10 *(1/4 + 2 * 3/4 + 1/4) = 20 hidden state。
- local TP rank 之间:模型每一层有两次 all reduce,一次 all-reduce 通信量为 2 * 2 * 3/4 = 3 hidden state,每个 PP rank 负责 64/2=32 层。10 个 token 的总通信量:10 * 32 * 2 * 3 = 1920 hidden state。
- 汇总:20 + 1920 = 1940 hidden state
(2)TP8,单卡通信量
- 每一层有两次 all reduce,一次 all-reduce 通信量为 7/2 hidden state,64 层。通信量:10 * 64 * 2 * 7/2 = 4480 hidden state。
(3)总结
| 配置 | PP rank 间通信 | TP rank 间通信 | 总通信量 | 相对 TP8 |
|---|---|---|---|---|
| PP2TP4 | 20 hidden state | 1920 hidden state | 1940 hidden state | 43% |
| TP8 | 0 hidden state | 4480 hidden state | 4480 hidden state | 100% |
PP2TP4 的通信量相比 TP8 下降一半以上。另外,通信耗时也和网络拓扑、通信次数有关系,在 10k 左右的 token 序列下,实测得到这样的影响面结论:网络拓扑 > 通信量 > 通信次数。
网络拓扑的影响最大,它包括:同机 VS 跨机通信,少卡 VS 多卡通信等场景,譬如:跨机通信通常比同机通信慢,8 卡同机的 all-gather 通信比 4 卡同机的 all-gather 慢。
7.2. 为什么 PP2TP4 相比 TP8 的单卡通信量会成倍减少
PP2TP4 模式单个卡承载的模型层数减少,但单个卡承载的注意力计算和 FFN 计算的 HEAD 数变多,这其实是“跷跷板”,层数少了、权重张量矩阵变大,因而一个卡需要加载的总的模型权重不变。我们再观察计算 all-reduce 通信量的公式:序列长度 * 模型层数 * 2 * 一次 all-reduce 的通信量。可以看到关键因子:序列长度、模型层数、一次 all-reduce 的通信量。当层数减少而张量矩阵变大时,通信量只会跟随模型层数而下降,不会因为张量矩阵变大而变大。
进一步分析,为什么权重张量矩阵变大不会导致通信量增加?
(1)无论是 attention 还是 FFN 的 all-reduce,参与通信的都是完整的 hidden state,和 HEAD 个数没有关系。
(2)某个 TP 在做完 qkv 计算后,还会做一次输出投影,这个投影会将最后一维的 HEAD 抹掉,变成一个完整形状的 hidden state。计算过程如下:
- qkv 计算:[seq_len, part_head_dim] * [part_head_dim, seq_len] * [seq_len, part_head_dim] = [seq_len, part_head_dim]
- 投影计算 [seq_len, part_head_dim] * [part_head_dim, hidden_state_dim] = [seq_len, hidden_state_dim]
(3)因此,对于一个 token 来说,无论 HEAD 数是 1/4,还是 1/8,参与 all-reduce 通信的张量形状都是一样的,所以 PP2TP4 这种 HEAD 数多而层数少的设计,可以减少 all-reduce 的通信量。
这里也抽象出一个一般性结论:GQA、MHA 结构的模型,使用 TP 模式时,无论参与注意力计算的权重张量有多大(即无论 tp size 是多少),最后做通信的张量都是 hidden state 维。基于这个一般性结论,我们在做计算的按层切、按 token 数切分、按权重张量切时,如果为了降低卡间的通信量,应该选择让一个卡计算更多的 HEAD 数,更少的模型层,更少的 token。
8. PP 和 TP 的适用场景对比
(1)理论分析
理论上,相同 GPU 卡数时,PP 模式相比 TP 模式有以下优势:
- 通信耗时下降。首先是单卡通信量更低;然后通过 PP 模式,也有机会降低跨机通信,让更多的通信发生在同机的 NVLink 下,而不是跨机的 RoCE。
- 计算效率可能更高。权重张量拆分得更粗,整体计算耗时可能会更低,譬如从 16 卡变成两组 8 卡,矩阵形状可能更适合 GPU 硬件设计,整体有可能算得更快。
但实测效果却没有更好,上述的这些优势没有转化为吞吐提升或者耗时下降。
(2)实际情况
实际上耗时和吞吐(一秒处理的请求)都可能变差。
- PP 模式通常会有更高的 TTFT 和 TPOT 耗时,对于单个请求来说,原本用 N 个卡做一次推理,现在只能用 N/2 个卡做推理。
- 吞吐也会变差,这是因为存在“流水线气泡”,GPU 算力有更大的浪费。
- 另外,PP 模式无法使用 overlap、投机采样等优化,也会影响到耗时和吞吐。
(3)业务应用
对耗时要求比较高的业务通常更倾向于使用 TP 模式,模式简单且 TTFT、TPOT 的耗时较低。而 PP 模式也有自身的优势:按层切分的限制比按张量切分少,可以支持超大模型、可以减少网络带宽消耗、通过精细的配置可以提升整体吞吐(虽然单个请求的耗时增加了)。
9. 参考文档
在本文的总结过程中,除了查看源代码,也使用 deepwiki 和其他 AI 工具辅助理解。
本文地址:https://www.cnblogs.com/cswuyg/p/19319162
知乎:https://zhuanlan.zhihu.com/p/1965709884877149831
公众号:https://mp.weixin.qq.com/s/HrFY_uz4U5GFRNo0U2E40A

 浙公网安备 33010602011771号
浙公网安备 33010602011771号