
JAVA重要知识点
为什么 Java 中只有值传递?
开始之前,我们先来搞懂下面这两个概念:
- 形参&实参
- 值传递&引用传递
形参&实参
方法的定义可能会用到 参数(有参的方法),参数在程序语言中分为:
- 实参(实际参数) :用于传递给函数/方法的参数,必须有确定的值。
- 形参(形式参数) :用于定义函数/方法,接收实参,不需要有确定的值。
String hello = "Hello!";
// hello 为实参
sayHello(hello);
// str 为形参
void sayHello(String str) {
System.out.println(str);
}
值传递&引用传递
程序设计语言将实参传递给方法(或函数)的方式分为两种:
- 值传递 :方法接收的是实参值的拷贝,会创建副本。
- 引用传递 :方法接收的直接是实参所引用的对象在堆中的地址,不会创建副本,对形参的修改将影响到实参。
很多程序设计语言(比如 C++、 Pascal )提供了两种参数传递的方式,不过,在 Java 中只有值传递。
为什么 Java 只有值传递?
为什么说 Java 只有值传递呢? 不需要太多废话,我通过 3 个例子来给大家证明。
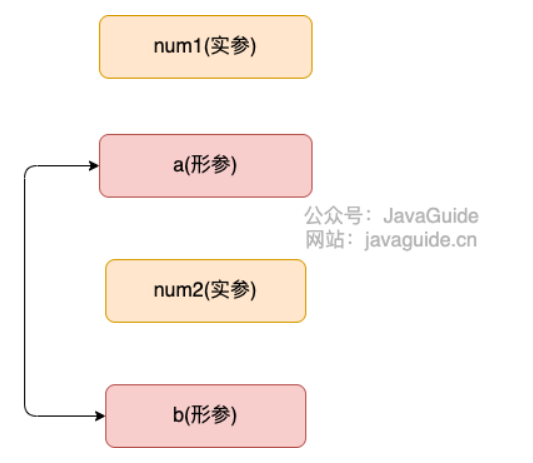
案例1:传递基本类型参数
代码:
public static void main(String[] args) {
int num1 = 10;
int num2 = 20;
swap(num1, num2);
System.out.println("num1 = " + num1);
System.out.println("num2 = " + num2);
}
public static void swap(int a, int b) {
int temp = a;
a = b;
b = temp;
System.out.println("a = " + a);
System.out.println("b = " + b);
}
输出:
a = 20
b = 10
num1 = 10
num2 = 20
解析:
在 swap() 方法中,a、b 的值进行交换,并不会影响到 num1、num2。因为,a、b 的值,只是从 num1、num2 的复制过来的。也就是说,a、b 相当于 num1、num2 的副本,副本的内容无论怎么修改,都不会影响到原件本身。
通过上面例子,我们已经知道了一个方法不能修改一个基本数据类型的参数,而对象引用作为参数就不一样,请看案例2。
案例2:传递引用类型参数1
代码:
public static void main(String[] args) {
int[] arr = { 1, 2, 3, 4, 5 };
System.out.println(arr[0]);
change(arr);
System.out.println(arr[0]);
}
public static void change(int[] array) {
// 将数组的第一个元素变为0
array[0] = 0;
}
输出:
1
0
解析:
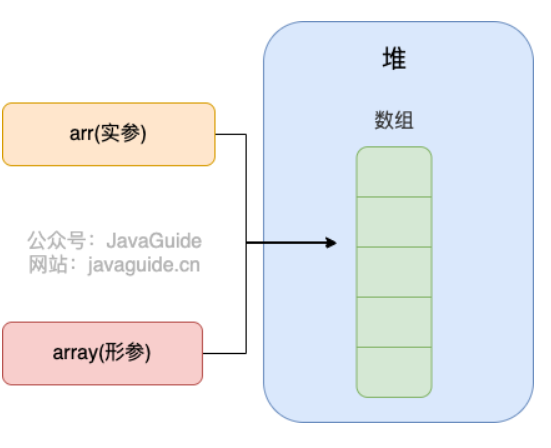
看了这个案例很多人肯定觉得 Java 对引用类型的参数采用的是引用传递。
实际上,并不是的,这里传递的还是值,不过,这个值是实参的地址罢了!
也就是说 change 方法的参数拷贝的是 arr (实参)的地址,因此,它和 arr 指向的是同一个数组对象。这也就说明了为什么方法内部对形参的修改会影响到实参。
为了更强有力地反驳 Java 对引用类型的参数采用的不是引用传递,我们再来看下面这个案例!
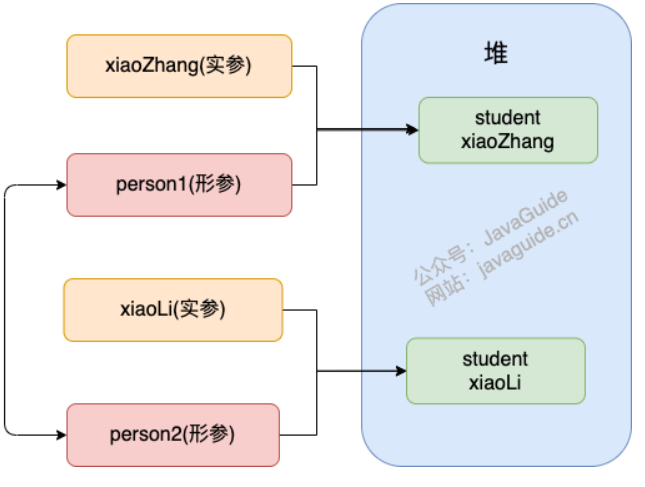
案例3 :传递引用类型参数2
public class Person {
private String name;
// 省略构造函数、Getter&Setter方法
}
public static void main(String[] args) {
Person xiaoZhang = new Person("小张");
Person xiaoLi = new Person("小李");
swap(xiaoZhang, xiaoLi);
System.out.println("xiaoZhang:" + xiaoZhang.getName());
System.out.println("xiaoLi:" + xiaoLi.getName());
}
public static void swap(Person person1, Person person2) {
Person temp = person1;
person1 = person2;
person2 = temp;
System.out.println("person1:" + person1.getName());
System.out.println("person2:" + person2.getName());
}
输出:
person1:小李
person2:小张
xiaoZhang:小张
xiaoLi:小李
怎么回事???两个引用类型的形参互换并没有影响实参啊!
swap 方法的参数 person1 和 person2 只是拷贝的实参 xiaoZhang 和 xiaoLi 的地址。因此, person1 和 person2 的互换只是拷贝的两个地址的互换罢了,并不会影响到实参 xiaoZhang 和 xiaoLi 。
那如果调用对象的方法进行改变的话,就会发生改变,比如将swap改成:
public static void swap(Person person1, Person person2) {
String name1 = person1.getName();
String name2 = person2.getName();
person1.setName(name2);
person2.setName(name1);
}
主程序中:
@Test
void Test3(){
Person xiaoZhang = new Person("小张");
Person xiaoLi = new Person("小李");
System.out.println("修改前");
System.out.println("person1:" + xiaoZhang.getName());
System.out.println("person2:" + xiaoLi.getName());
swap(xiaoZhang,xiaoLi);
System.out.println("修改后");
System.out.println("person1:" + xiaoZhang.getName());
System.out.println("person2:" + xiaoLi.getName());
}
结果为
修改前
person1:小张
person2:小李
修改后
person1:小李
person2:小张
可以发现里面的属性被修改了。
总结
Java 中将实参传递给方法(或函数)的方式是 值传递 :
- 如果参数是基本类型的话,很简单,传递的就是基本类型的字面量值的拷贝,会创建副本。
- 如果参数是引用类型,传递的就是实参所引用的对象在堆中地址值的拷贝,同样也会创建副本。
Java序列化详解
什么是序列化?什么是反序列化?
如果我们需要持久化 Java 对象比如将 Java 对象保存在文件中,或者在网络传输 Java 对象,这些场景都需要用到序列化。
简单来说:
- 序列化: 将数据结构或对象转换成二进制字节流的过程
- 反序列化:将在序列化过程中所生成的二进制字节流的过程转换成数据结构或者对象的过程
对于 Java 这种面向对象编程语言来说,我们序列化的都是对象(Object)也就是实例化后的类(Class),但是在 C++这种半面向对象的语言中,struct(结构体)定义的是数据结构类型,而 class 对应的是对象类型。
维基百科是如是介绍序列化的:
序列化(serialization)在计算机科学的数据处理中,是指将数据结构或对象状态转换成可取用格式(例如存成文件,存于缓冲,或经由网络中发送),以留待后续在相同或另一台计算机环境中,能恢复原先状态的过程。依照序列化格式重新获取字节的结果时,可以利用它来产生与原始对象相同语义的副本。对于许多对象,像是使用大量引用的复杂对象,这种序列化重建的过程并不容易。面向对象中的对象序列化,并不概括之前原始对象所关系的函数。这种过程也称为对象编组(marshalling)。从一系列字节提取数据结构的反向操作,是反序列化(也称为解编组、deserialization、unmarshalling)。
综上:序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。
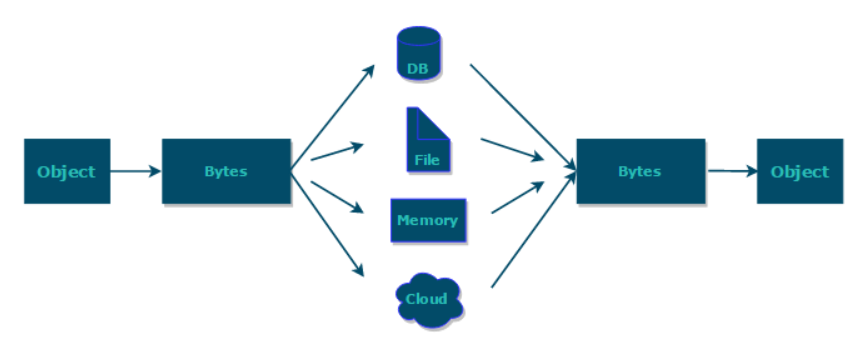
实际开发中有哪些用到序列化和反序列化的场景?
- 对象在进行网络传输(比如远程方法调用 RPC 的时候)(啥是远程方法调用RPC?)之前需要先被序列化,接收到序列化的对象之后需要再进行反序列化;
- 将对象存储到文件中的时候需要进行序列化,将对象从文件中读取出来需要进行反序列化。
- 将对象存储到缓存数据库(如 Redis)时需要用到序列化,将对象从缓存数据库中读取出来需要反序列化。
序列化协议对应于 TCP/IP 4 层模型的哪一层?
我们知道网络通信的双方必须要采用和遵守相同的协议。TCP/IP 四层模型是下面这样的,序列化协议属于哪一层呢?
- 应用层
- 传输层
- 网络层
- 网络接口层
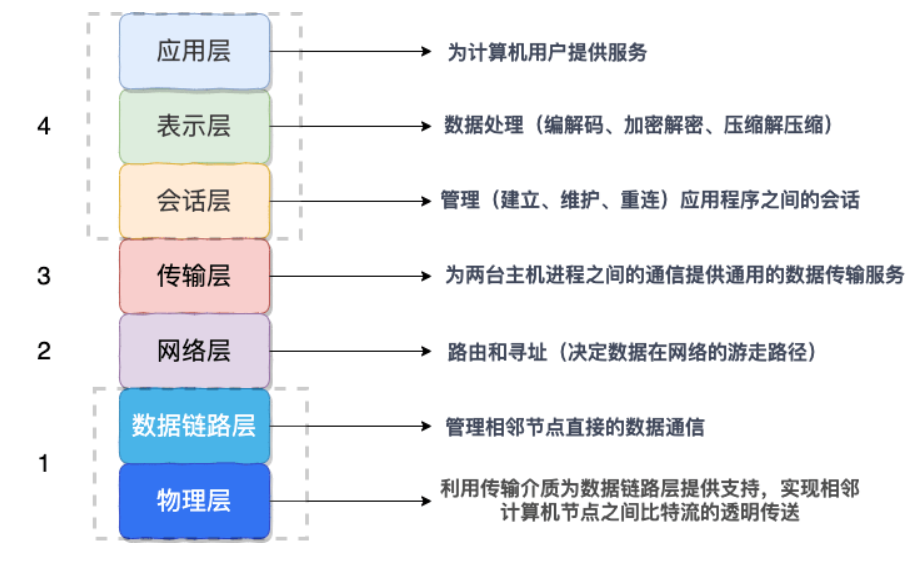
如上图所示,OSI 七层协议模型中,表示层做的事情主要就是对应用层的用户数据进行处理转换为二进制流。反过来的话,就是将二进制流转换成应用层的用户数据。这不就对应的是序列化和反序列化么?
因为,OSI 七层协议模型中的应用层、表示层和会话层对应的都是 TCP/IP 四层模型中的应用层,所以序列化协议属于 TCP/IP 协议应用层的一部分。
常见序列化协议对比
JDK 自带的序列化方式一般不会用 ,因为序列化效率低并且部分版本有安全漏洞。(为啥效率低?安全漏洞又是啥?)比较常用的序列化协议有 hessian、kyro、protostuff。
下面提到的都是基于二进制的序列化协议,像 JSON 和 XML 这种属于文本类序列化方式。虽然 JSON 和 XML 可读性比较好,但是性能较差,一般不会选择。
JDK 自带的序列化方式
JDK 自带的序列化,只需实现 java.io.Serializable接口即可。比如下面的Student类
@NoArgsConstructor
@AllArgsConstructor
@Getter
@Builder
@ToString
public class Student implements Serializable {
private static final long serialVersionUID = 1905122041950251207L;
private String name;
private transient Integer age;
private String address;
}
private transient Integer age中的transient表示不会序列化该属性,当对象被序列化时该属性age不会被序列化,反序列化时,该属性是以默认值赋值。比如下面反序列化时,age的值为空。
public class SerializeOperation {
/**
* 序列化对象,并使用了try-with-resources
* @param student
* @param path
* @throws IOException
*/
public static void serializeToFile(Student student, String path) throws IOException {
Student s = new Student("小明",16,"翻斗花园");
try(FileOutputStream fileOut = new FileOutputStream(path);
ObjectOutputStream out = new ObjectOutputStream(fileOut);) {
out.writeObject(s);
}catch (Exception e){
e.printStackTrace();
}
}
/**
* 反序列化对象
* @param path
*/
public static void deserializationFromFile(String path){
try(FileInputStream fileIn = new FileInputStream(path);
ObjectInputStream in = new ObjectInputStream(fileIn);){
Student s = (Student) in.readObject();
System.out.println(s.getAddress());
System.out.println(s.getAge());
System.out.println(s.getName());
}catch (Exception e){
e.printStackTrace();
}
}
}
上面使用了try-with-resources可以自动关闭任何实现 java.lang.AutoCloseable或者 java.io.Closeable 的对象。这样我们就不用在finally再关闭了。
主程序:
public class mainPractice {
public static void main(String[] args) throws IOException {
Student toBeSerializedObject = new Student("小明",16,"翻斗花园!");
StringBuffer path = new StringBuffer("E:");
path.append(File.separator).append("test").append(File.separator).append("student.ser");
SerializeOperation.serializeToFile(toBeSerializedObject, path.toString());
SerializeOperation.deserializationFromFile(path.toString());
}
}
打印的结果:
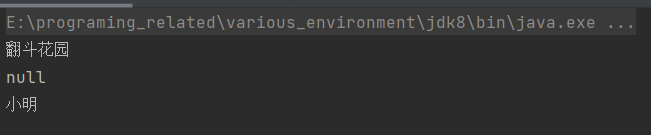
如果初始化的序列化id和反序列化的id不一致,就会报错:

JDK序列化的缺陷
我们在用过的RPC(远程方法调用)通信框架中,很少会发现使用JDK提供的序列化,主要是因为JDK默认的序列化存在着如下一些缺陷:
1. 无法跨语言
现在很多系统的复杂度很高,采用多种语言来编码,而Java序列化目前只支持Java语言实现的框架,其它语言大部分都没有使用Java的序列化框架,也没有实现Java序列化这套协议,因此,如果两个基于不同语言编写的应用程序之间通信,使用Java序列化,则无法实现两个应用服务之间传输对象的序列化和反序列化。 像JSON序列化的话就可以跨语言,因为JSON这种数据格式是通用的。
2. 易被攻击
Java官网安全编码指导方针里有说明,“对于不信任数据的反序列化,从本质上来说是危险的,应该避免“。可见Java序列化并不是安全的。
我们知道对象是通过在 ObjectInputStream 上调用 readObject() 方法进行反序列化的,这个方法其实是一个神奇的构造器,它可以将类路径上几乎所有实现了 Serializable 接口的对象都实例化。这也就意味着,在反序列化字节流的过程中,该方法可以执行任意类型的代码,这是非常危险的。
对于需要长时间进行反序列化的对象,不需要执行任何代码,也可以发起一次攻击。攻击者可以创建循环对象链,然后将序列化后的对象传输到程序中反序列化,这种情况会导致 hashCode 方法被调用次数呈次方爆发式增长, 从而引发栈溢出异常。例如下面这个案例就可以很好地说明。
Set root = new HashSet();
Set s1 = root;
Set s2 = new HashSet();
for (int i = 0; i < 100; i++) {
Set t1 = new HashSet();
Set t2 = new HashSet();
t1.add("test"); //使t2不等于t1
s1.add(t1);
s1.add(t2);
s2.add(t1);
s2.add(t2);
s1 = t1;
s2 = t2;
}
如何解决这个漏洞?
很多序列化协议都制定了一套数据结构来保存和获取对象。例如,JSON 序列化、ProtocolBuf 等,它们只支持一些基本类型和数组数据类型,这样可以避免反序列化创建一些不确定的实例。虽然它们的设计简单,但足以满足当前大部分系统的数据传输需求。我们也可以通过反序列化对象白名单来控制反序列化对象,可以重写 resolveClass 方法,并在该方法中校验对象名字。代码如下所示:
@Override
protected Class resolveClass(ObjectStreamClass desc) throws IOException,ClassNotFoundException {
if (!desc.getName().equals(Bicycle.class.getName())) {
throw new InvalidClassException(
"Unauthorized deserialization attempt", desc.getName());
}
return super.resolveClass(desc);
}
3. 序列化后的流太大
序列化后的二进制流大小能体现序列化的性能。序列化后的二进制数组越大,占用的存储空间就越多,存储硬件的成本就越高。如果我们是进行网络传输,则占用的带宽就更多,这时就会影响到系统的吞吐量。
Java 序列化中使用了 ObjectOutputStream 来实现对象转二进制编码,那么这种序列化机制实现的二进制编码完成的二进制数组大小,相比于 NIO 中的 ByteBuffer 实现的二进制编码完成的数组大小,要大上几倍。
4. 序列化性能太差
Java 序列化中的编码耗时要比 ByteBuffer 长很多。
Kryo
Kryo 是一个高性能的序列化/反序列化工具,由于其变长存储特性并使用了字节码生成机制,拥有较高的运行速度和较小的字节码体积。
另外,Kryo 已经是一种非常成熟的序列化实现了,已经在 Twitter、Groupon、Yahoo 以及多个著名开源项目(如 Hive、Storm)中广泛的使用。刚刚序列化和反序列化Student的案例在Kryo上使用如下:
public class KryoSerializerOperation {
public static void serializeToFile(Object toBeSerializedObject, String path){
Kryo kryo = new Kryo();
kryo.register(toBeSerializedObject.getClass());
try (Output output = new Output(new FileOutputStream(path));){
kryo.writeObject(output, toBeSerializedObject);
}catch (Exception e){
e.printStackTrace();
}
}
public static void deSerializeFromFile(Class toBeSerializedObject, String path){
Kryo kryo = new Kryo();
kryo.register(toBeSerializedObject);
try (Input input = new Input(new FileInputStream(path));){
Student s = (Student) kryo.readObject(input, toBeSerializedObject);
System.out.println(s);
}catch (Exception e){
e.printStackTrace();
}
}
}
主程序:
public class mainPractice {
public static void main(String[] args) {
KryoSerializerOperation.serializeToFile(ConstantUsedBySerialization.student
,ConstantUsedBySerialization.path);
KryoSerializerOperation.deSerializeFromFile(ConstantUsedBySerialization.student.getClass()
,ConstantUsedBySerialization.path);
}
}
其中的常量类为:
public class ConstantUsedBySerialization {
public static Student student = new Student("小明",16,"翻斗花园");
public static String path = "E:"+ File.separator+"test"+File.separator+"student.ser";
}
Protobuf
Protobuf 出自于 Google,性能还比较优秀,也支持多种语言,同时还是跨平台的。就是在使用中过于繁琐,因为你需要自己定义 IDL 文件和生成对应的序列化代码。这样虽然不然灵活,但是,另一方面导致 protobuf 没有序列化漏洞的风险。
Protobuf 包含序列化格式的定义、各种语言的库以及一个 IDL 编译器。正常情况下你需要定义 proto 文件,然后使用 IDL 编译器编译成你需要的语言
一个简单的 proto 文件如下:
// protobuf的版本
syntax = "proto3";
// SearchRequest会被编译成不同的编程语言的相应对象,比如Java中的class、Go中的struct
message Person {
//string类型字段
string name = 1;
// int 类型字段
int32 age = 2;
}
总结
Kryo 是专门针对 Java 语言序列化方式并且性能非常好,如果你的应用是专门针对 Java 语言的话可以考虑使用,并且 Dubbo 官网的一篇文章中提到说推荐使用 Kryo 作为生产环境的序列化方式。(文章地址:[rest 协议 | Apache Dubbo](https://dubbo.apache.org/zh/docs/v2.7/user/references/protocol/rest/))
Java 反射机制详解
何为反射?
如果说大家研究过框架的底层原理或者咱们自己写过框架的话,一定对反射这个概念不陌生。
反射之所以被称为框架的灵魂,主要是因为它赋予了我们在运行时分析类以及执行类中方法的能力。通过反射你可以获取任意一个类的所有属性和方法,你还可以调用这些方法和属性。
反射的应用场景了解么?
像咱们平时大部分时候都是在写业务代码,很少会接触到直接使用反射机制的场景。
但是,这并不代表反射没有用。相反,正是因为反射,你才能这么轻松地使用各种框架。像 Spring/Spring Boot、MyBatis 等等框架中都大量使用了反射机制。
这些框架中也大量使用了动态代理,而动态代理的实现也依赖反射。
比如下面是通过 JDK 实现动态代理的示例代码,其中就使用了反射类 Method 来调用指定的方法。
public class DebugInvocationHandler implements InvocationHandler {
/**
* 代理类中的真实对象
*/
private final Object target;
public DebugInvocationHandler(Object target) {
this.target = target;
}
public Object invoke(Object proxy, Method method, Object[] args) throws InvocationTargetException, IllegalAccessException {
System.out.println("before method " + method.getName());
Object result = method.invoke(target, args);
System.out.println("after method " + method.getName());
return result;
}
}
另外,像 Java 中的一大利器 注解 的实现也用到了反射。
为什么你使用 Spring 的时候 ,一个@Component注解就声明了一个类为 Spring Bean 呢?为什么你通过一个 @Value注解就读取到配置文件中的值呢?究竟是怎么起作用的呢?
这些都是因为你可以基于反射分析类,然后获取到类/属性/方法/方法的参数上的注解。你获取到注解之后,就可以做进一步的处理。
谈谈反射机制的优缺点
优点 : 可以让咱们的代码更加灵活、为各种框架提供开箱即用的功能提供了便利
缺点 :让我们在运行时有了分析操作类的能力,这同样也增加了安全问题。比如可以无视泛型参数的安全检查(泛型参数的安全检查发生在编译时)(如何无视?)。另外,反射的性能也要稍差点,不过,对于框架来说实际是影响不大的。
反射实战
获取 Class 对象的四种方式
如果我们动态获取到这些信息,我们需要依靠 Class 对象。Class 类对象将一个类的方法、变量等信息告诉运行的程序。Java 提供了四种方式获取 Class 对象:
1. 知道具体类的情况下可以使用:
Class alunbarClass = TargetObject.class;
但是我们一般是不知道具体类的,基本都是通过遍历包下面的类来获取 Class 对象,通过此方式获取 Class 对象不会进行初始化
2. 通过 Class.forName()传入类的全路径获取:
Class alunbarClass1 = Class.forName("cn.javaguide.TargetObject");
3. 通过对象实例instance.getClass()获取:
TargetObject o = new TargetObject();
Class alunbarClass2 = o.getClass();
4.通过类加载器xxxClassLoader.loadClass()传入类路径获取:
ClassLoader.getSystemClassLoader().loadClass("cn.javaguide.TargetObject");
通过类加载器获取 Class 对象不会进行初始化,意味着不进行包括初始化等一系列步骤,静态代码块和静态对象不会得到执行
反射的一些基本操作
- 创建一个我们要使用反射操作的类
TargetObject。
package reflect;
public class TargetObject {
private String value;
public TargetObject() {
value = "JavaGuide";
}
public void publicMethod(String s) {
System.out.println("I love " + s);
}
private void privateMethod() {
System.out.println("value is " + value);
}
}
2.使用反射操作这个类的方法以及参数
public class mainPractice {
public static void main(String[] args) throws ClassNotFoundException, InstantiationException, IllegalAccessException, NoSuchMethodException, InvocationTargetException {
/**
* 获取 TargetObject 类的 Class 对象并且创建 TargetObject 类实例
*/
Class<?> targetClass = Class.forName("reflect.TargetObject");
TargetObject targetObject = (TargetObject) targetClass.newInstance();
/**
* 获取 TargetObject 类中定义的所有方法
*/
Method[] declaredMethods = targetClass.getDeclaredMethods();
for (Method method : declaredMethods) {
System.out.println("方法名字:"+method.getName());
System.out.println("返回值类型:"+method.getReturnType());
System.out.println("该方法的参数个数"+method.getParameterCount());
System.out.println("方法的参数的类型依次为:");
for (Class<?> parameterType : method.getParameterTypes()) {
System.out.println(parameterType.getName());
}
}
/**
* 获取指定方法publicMethod并调用,传入参数JavaGuide
*/
Method publicMethod = targetClass.getDeclaredMethod("publicMethod",String.class);
publicMethod.invoke(targetObject, "JavaGuide");
/**
* 调用 private 方法
*/
Method privateMethod = targetClass.getDeclaredMethod("privateMethod");
//为了调用private方法我们取消安全检查
privateMethod.setAccessible(true);
privateMethod.invoke(targetObject);
}
}
可以看到Class类的对象有很多get方法,可以获取类似于注解,方法,构造器之类的。
获得方法之后,还可以获得方法的返回值、参数等等...
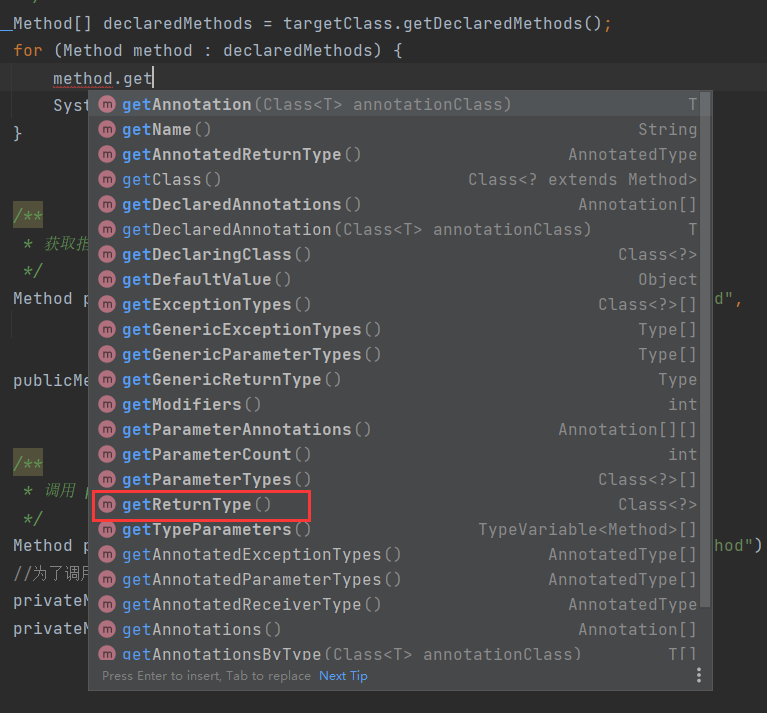
输出为:可以看到当privateMethod没有参数时,参数类型输出就位空。
方法名字:publicMethod
返回值类型:void
该方法的参数个数1
方法的参数的类型依次为:
java.lang.String
方法名字:privateMethod
返回值类型:void
该方法的参数个数0
方法的参数的类型依次为:
I love JavaGuide
value is JavaGuide
Java Socket详解
Java 代理模式详解
1. 代理模式
代理模式是一种比较好理解的设计模式。简单来说就是 我们使用代理对象来代替对真实对象(real object)的访问,这样就可以在不修改原目标对象的前提下,提供额外的功能操作,扩展目标对象的功能。
代理模式的主要作用是扩展目标对象的功能,比如说在目标对象的某个方法执行前后你可以增加一些自定义的操作。
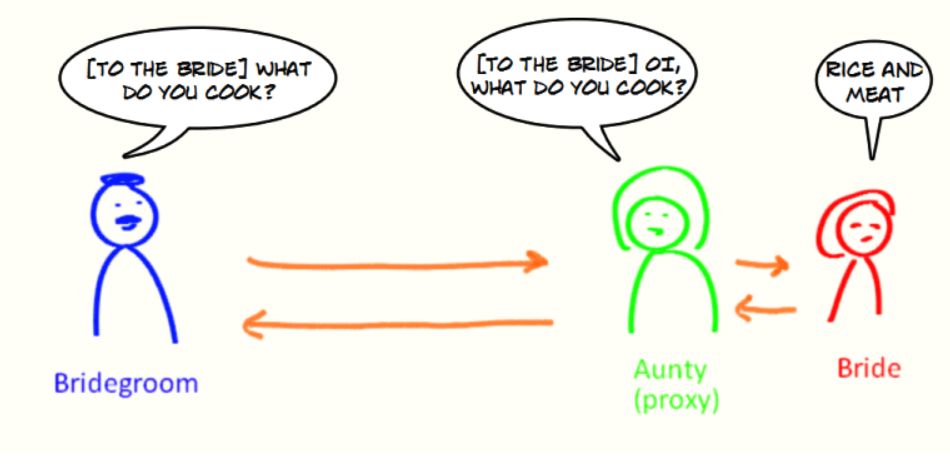
举个例子:新娘找来了自己的姨妈来代替自己处理新郎的提问,新娘收到的提问都是经过姨妈处理过滤之后的。姨妈在这里就可以看作是代理你的代理对象,代理的行为(方法)是接收和回复新郎的提问。
代理模式有静态代理和动态代理两种实现方式,我们 先来看一下静态代理模式的实现。
2. 静态代理
静态代理中,我们对目标对象的每个方法的增强都是手动完成的(*后面会具体演示代码*),非常不灵活(*比如接口一旦新增加方法,目标对象和代理对象都要进行修改*)且麻烦(*需要对每个目标类都单独写一个代理类*)。 实际应用场景非常非常少,日常开发几乎看不到使用静态代理的场景。
上面我们是从实现和应用角度来说的静态代理,从 JVM 层面来说, 静态代理在编译时就将接口、实现类、代理类这些都变成了一个个实际的 class 文件。
静态代理实现步骤:
- 定义一个接口及其实现类;
- 创建一个代理类同样实现这个接口
- 将目标对象注入进代理类,然后在代理类的对应方法调用目标类中的对应方法。这样的话,我们就可以通过代理类屏蔽对目标对象的访问,并且可以在目标方法执行前后做一些自己想做的事情。
下面通过代码展示!
1.定义发送短信的接口
public interface SmsService {
String send(String message);
}
2.实现发送短信的接口
public class SmsServiceImpl implements SmsService {
public String send(String message) {
System.out.println("send message:" + message);
return message;
}
}
3.创建代理类并同样实现发送短信的接口
public class SmsProxy implements SmsService {
private final SmsService smsService;
public SmsProxy(SmsService smsService) {
this.smsService = smsService;
}
@Override
public String send(String message) {
//调用方法之前,我们可以添加自己的操作
System.out.println("before method send()");
smsService.send(message);
//调用方法之后,我们同样可以添加自己的操作
System.out.println("after method send()");
return null;
}
}
4.实际使用
public class Main {
public static void main(String[] args) {
SmsService smsService = new SmsServiceImpl();
SmsProxy smsProxy = new SmsProxy(smsService);
smsProxy.send("java");
}
}
运行上述代码之后,控制台打印出:
before method send()
send message:java
after method send()
可以输出结果看出,我们已经增加了 SmsServiceImpl 的send()方法。因为本来的SmsServiceImpl 的send()方法就只输出send message:java,现在加上了两行分别是:before method send()和after method send(),这就代表着我们可以在调用方法之前做一些操作,调用之后也做一些操作。
3. 动态代理
相比于静态代理来说,动态代理更加灵活。我们不需要针对每个目标类都单独创建一个代理类,并且也不需要我们必须实现接口,我们可以直接代理实现类( CGLIB 动态代理机制)。
从 JVM 角度来说,动态代理是在运行时动态生成类字节码,并加载到 JVM 中的。
说到动态代理,Spring AOP、RPC 框架应该是两个不得不提的,它们的实现都依赖了动态代理。
动态代理在我们日常开发中使用的相对较少,但是在框架中的几乎是必用的一门技术。学会了动态代理之后,对于我们理解和学习各种框架的原理也非常有帮助。
就 Java 来说,动态代理的实现方式有很多种,比如 JDK 动态代理、CGLIB 动态代理等等。
3.1. JDK 动态代理机制
3.1.1. 介绍
在 Java 动态代理机制中 InvocationHandler 接口和 Proxy 类是核心。Proxy 类中使用频率最高的方法是:newProxyInstance() ,这个方法主要用来生成一个代理对象。
<?>代表任意java类型,只有在不关心数据的具体类型下才使用通配符表示
public static Object newProxyInstance(ClassLoader loader,Class<?>[] interfaces,InvocationHandler h)throws IllegalArgumentException
{
......
}
这个方法一共有 3 个参数:
- loader :类加载器,用于加载代理对象。
- interfaces : 被代理类实现的一些接口;
- h : 实现了
InvocationHandler接口的对象;
要实现动态代理的话,还必须需要实现InvocationHandler 来自定义处理逻辑。 当我们的动态代理对象调用一个方法时,这个方法的调用就会被转发到实现InvocationHandler 接口类的 invoke 方法来调用。
public interface InvocationHandler {
/**
* 当你使用代理对象调用方法的时候实际会调用到这个方法
*/
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable;
}
invoke() 方法有下面三个参数:
- proxy :动态生成的代理类
- method : 与代理类对象调用的方法相对应
- args : 当前 method 方法的参数
也就是说:你通过Proxy 类的 newProxyInstance() 创建的代理对象在调用方法的时候,实际会调用到实现InvocationHandler 接口的类的 invoke()方法。 你可以在 invoke() 方法中自定义处理逻辑,比如在方法执行前后做什么事情。
3.1.2. JDK 动态代理类使用步骤
- 定义一个接口及其实现类;
- 自定义
InvocationHandler并重写invoke方法,在invoke方法中我们会调用原生方法(被代理类的方法)并自定义一些处理逻辑; - 通过
Proxy.newProxyInstance(ClassLoader loader,Class<?>[] interfaces,InvocationHandler h)方法创建代理对象;
3.1.3. 代码示例
1.定义发送短信的接口
public interface SmsService {
String send(String message);
}
2.实现发送短信的接口
public class SmsServiceImpl implements SmsService {
@Override
public String send(String message) {
System.out.println("real Object sends message:" + message);
return message;
}
}
3.定义一个 JDK 动态代理类
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
public class DebugInvocationHandler implements InvocationHandler {
/**
* 代理类中的真实对象
*/
private final Object target;
public DebugInvocationHandler(Object target) {
this.target = target;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//调用方法之前,我们可以添加自己的操作
System.out.println("before method " + method.getName());
Object result = method.invoke(target, args);//method表示是哪个方法进行调用,target表示对哪个对象调用,args表示调用时传入的参数
//调用方法之后,我们同样可以添加自己的操作
System.out.println("after method " + method.getName());
return result;
}
}
invoke() 方法: 当我们的动态代理对象调用原生方法的时候,最终实际上调用到的是 invoke() 方法,然后 invoke() 方法代替我们去调用了被代理对象的原生方法。
4.获取代理对象的工厂类
public class JdkProxyFactory {
public static Object getProxy(Object target) {
return Proxy.newProxyInstance(
target.getClass().getClassLoader(), // 目标类的类加载
target.getClass().getInterfaces(), // 代理需要实现的接口,可指定多个,这里也是和CGLIB不同的地方,需要通过接口来
new DebugInvocationHandler(target) // 代理对象对应的自定义 InvocationHandler,
// 通过传入不同的实现了InvocationHandler的handler对象,可以实现对不同的代理对象进行不同的处理
);
}
}
getProxy() :主要通过Proxy.newProxyInstance()方法获取某个类的代理对象
5.实际使用
SmsService smsService = (SmsService) JdkProxyFactory.getProxy(new SmsServiceImpl());
smsService.send("java");
运行上述代码之后,控制台打印出:
before method send
real Object sends message:javajava
after method send
注意点:实际使用时,只能用接口来接受经过代理的类,比如下面这种写法就会报错,即用实现类来接受Object:
public static void main(String[] args) {
SmsServiceImpl smsService = (SmsServiceImpl) JdkProxyFactory.getProxy(new SmsServiceImpl());
smsService.send("javajava");
}

所以JDK的代理实现中Proxy.newProxyInstance( target.getClass().getClassLoader(),target.getClass().getInterfaces(), new DebugInvocationHandler(target))的getInterfaces就是关键,JDK动态代理只能增强接口里的方法,因为需要从接口中获得有哪些方法。
3.2CGLIB 动态代理机制
3.2.1. 介绍
JDK 动态代理有一个最致命的问题是其只能代理实现了接口的类。为了解决这个问题,我们可以用 CGLIB 动态代理机制来避免。
CGLIB(Code Generation Library)是一个基于ASM的字节码生成库,它允许我们在运行时对字节码进行修改和动态生成。CGLIB 通过继承方式实现代理。很多知名的开源框架都使用到了CGLIB, 例如 Spring 中的 AOP 模块中:如果目标对象实现了接口,则默认采用 JDK 动态代理,否则采用 CGLIB 动态代理。
在 CGLIB 动态代理机制中 MethodInterceptor 接口和 Enhancer 类是核心。
你需要自定义 MethodInterceptor 并重写 intercept 方法,intercept 用于拦截增强被代理类的方法。
public interface MethodInterceptor
extends Callback{
// 拦截被代理类中的方法
public Object intercept(Object obj, java.lang.reflect.Method method, Object[] args,MethodProxy proxy) throws Throwable;
}
- obj : 动态生成的代理对象
- method : 被拦截的方法(需要增强的方法)
- args : 方法入参
- proxy : 用于调用原始方法
你可以通过 Enhancer类来动态获取被代理类,当代理类调用方法的时候,实际调用的是 MethodInterceptor 中的 intercept 方法。
3.2.2. CGLIB 动态代理类使用步骤
- 定义一个类;
- 自定义
MethodInterceptor并重写intercept方法,intercept用于拦截增强被代理类的方法,和 JDK 动态代理中的invoke方法类似; - 通过
Enhancer类的create()创建代理类
3.2.3. 代码示例
不同于 JDK 动态代理不需要额外的依赖。CGLIB(Code Generation Library) 实际是属于一个开源项目,如果你要使用它的话,需要手动添加相关依赖。
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>3.3.0</version>
</dependency>
1.实现一个使用阿里云发送短信的类
public class AliSmsService {
public String send(String message) {
System.out.println("REAL send message:" + message);
return message;
}
}
2.自定义 MethodInterceptor(方法拦截器)
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
import java.lang.reflect.Method;
public class DebugMethodInterceptor implements MethodInterceptor {
/**
* @param o 代理对象(增强的对象)
* @param method 被拦截的方法(需要增强的方法)
* @param args 方法入参
* @param methodProxy 用于调用原始方法
*/
@Override
public Object intercept(Object o, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
//调用方法之前,我们可以添加自己的操作
System.out.println("before method " + method.getName());
Object object = methodProxy.invokeSuper(o, args);
//调用方法之后,我们同样可以添加自己的操作
System.out.println("after method " + method.getName());
return object;
}
}
3.获取代理类
public class CglibProxyFactory {
public static Object getProxy(Class<?> clazz) {
Enhancer enhancer = new Enhancer();// 创建动态代理增强类
enhancer.setClassLoader(clazz.getClassLoader());// 设置类加载器
enhancer.setSuperclass(clazz);// 设置被代理类
enhancer.setCallback(new DebugMethodInterceptor());// 设置方法拦截器,可以自定义传入
return enhancer.create();// 创建代理类
}
}
4.实际使用
AliSmsService aliSmsService = (AliSmsService) CglibProxyFactory.getProxy(AliSmsService.class);
aliSmsService.send("javajava");
输出为:
before method send
REAL send message:javajava
after method send
如果想用在另一个类上,那么直接如法炮制即可:
public class OtherService {
public String callPhone(String phoneNumber){
System.out.println("正在拨打电话,号码为"+phoneNumber);
return phoneNumber;
}
}
接着用同样的方法动态代理OtherService类
OtherService otherService = (OtherService) CglibProxyFactory.getProxy(OtherService.class);
otherService.callPhone("12344");
输出为:
before method callPhone
正在拨打电话,号码为12344
after method callPhone
3.3. JDK 动态代理和 CGLIB 动态代理对比
- JDK 动态代理只能代理实现了接口的类或者直接代理接口,而 CGLIB 可以代理未实现任何接口的类。 另外, CGLIB 动态代理是通过生成一个被代理类的子类来拦截被代理类的方法调用,因此不能代理声明为 final 类型的类和方法。
- 就二者的效率来说,大部分情况都是 JDK 动态代理更优秀,随着 JDK 版本的升级,这个优势更加明显。
4. 静态代理和动态代理的对比
- 灵活性 :动态代理更加灵活,不需要必须实现接口,可以直接代理实现类,并且可以不需要针对每个目标类都创建一个代理类。另外,静态代理中,接口一旦新增加方法,目标对象和代理对象都要进行修改,这是非常麻烦的!
- JVM 层面 :静态代理在编译时就将接口、实现类、代理类这些都变成了一个个实际的 class 文件。而动态代理是在运行时动态生成类字节码,并加载到 JVM 中的。
5. 总结
这篇文章中主要介绍了代理模式的两种实现:静态代理以及动态代理。涵盖了静态代理和动态代理实战、静态代理和动态代理的区别、JDK 动态代理和 Cglib 动态代理区别等内容。
泛型和通配符
参考了Java 泛型中的通配符 - 雨点的名字 - 博客园 (cnblogs.com),感谢雨点的名字!转自公众号: 后端元宇宙
泛型
Java泛型是JDK5中引入的一个新特性,泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。
泛型擦除
Java的泛型基本上都是在编译器这个层次上实现的,在生成的字节码中是不包含泛型中的类型信息的,使用泛型的时候加上类型参数,在编译器编译的时候会去掉,这个过程成为类型擦除。看下面代码
public class GenericErase {
public static void main(String[] args) {
ArrayList<String> list1 = new ArrayList<>();
ArrayList<Integer> list2 = new ArrayList<>();
System.out.println(list1.getClass() == list2.getClass());//true
}
}
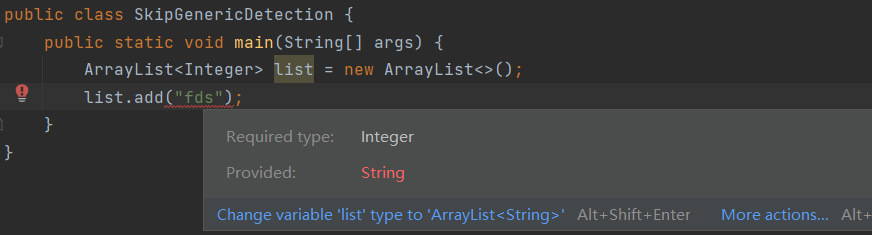
可以看到ArrayList<Integer>和ArrayList<String>的原始类型是相同,在编译成字节码文件后都会变成List,JVM看到的只有List,看不到泛型信息,这就是泛型的类型擦除。所以我们可以利用反射机制,跳过泛型检测添加不同类型的元素。
如果我们在运行之前给指定了泛型(Integer)的list添加String类型的元素,不仅IDE会报错,而且编译器检查代码的时候也会报错。
跳过泛型检测
在看下面这段代码,使用反射机制跳过泛型检测:
public class SkipGenericDetection {
public static void main(String[] args) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException {
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.getClass().getMethod("add",Object.class).invoke(list,"haha");
System.out.println(list.get(0));
System.out.println(list.get(1));
}
}
输出:
1
haha
可以看到通过反射进行add操作,ArrayList<Integer>竟然可以存储字符串,这是因为在反射就是在运行期调用的add方法,在运行期泛型信息已经被擦除。
既然存在类型擦除,那么Java是如何保证在ArrayList<Integer>添加字符串会报错呢?Java编译器是通过先检查代码中泛型的类型,然后再进行类型擦除,再进行编译。
通配符
- ? 用于在泛型的使用,即为通配符。
- 通配符是用来解决泛型无法协变的问题的,协变指的就是如果 Student 是 Person 的子类,那么List 也应该是 List 的子类。但是泛型是不支持。
我们在泛型中使用通配符经常看到T、F、U、E,K,V其实这些并没有啥区别,我们可以选 A-Z 之间的任何一个字母都可以,并不会影响程序的正常运行。
只不过大家心照不宣的在命名上有些约定:
- T (Type) 具体的Java类
- E (Element)在集合中使用,因为集合中存放的是元素
- K V (key value) 分别代表java键值中的Key Value
- N (Number)数值类型
- ? 表示不确定的 Java 类型
上界通配符 < ? extends E>
语法:<? extends E>
举例:<? extends Animal> 可以传入的实参类型是Animal或者Animal的子类。主要用于接收的时候用。
两大原则
add:除了null之外,不允许加入任何元素!get:可以获取元素,可以通过E或者Object接受元素!因为不管存入什么数据类型都是E的子类型
代码:
public static void method(List<? extends Animal> lists){
Animal animal = lists.get(0);//正确 因为传入的一定是Animal的子类
Object object = lists.get(1);//正确 当然也可以用Object类接收,因为Object是顶层父类
? t = lists.get(2);//错误 不能用?接收
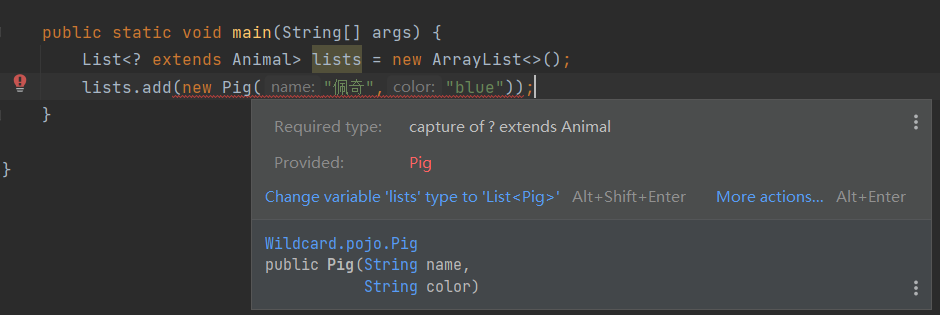
lists.add(new Animal());// 错误
lists.add(new Dog());//错误
lists.add(object);//错误
lists.add(null);//正确 除了null之外,不允许加入任何元素!
}
add加入子类对象也会报错:
但是上界通配符作为接受时的参数时,会很有用,只要list中的泛型是Animal的子类的时候,就可以作为参数传入。
public class mainPractice {
public static void getList(List<? extends Animal> lists){
Animal animal = lists.get(0);
System.out.println(animal.getName());
}
public static void main(String[] args) {
List<Pig> lists = new ArrayList<>();
lists.add(new Pig("佩奇","blue"));
mainPractice.getList(lists);//打印出 佩奇
List<Dog> list2 = new ArrayList<>();
list2.add(new Dog("汪汪队","red"));
mainPractice.getList(list2);//打印出 汪汪队
}
}
下界通配符 < ? super E>
语法: <? super E>
举例 :<? super Dog> 可以传入的实参的类型是Dog或者Dog的父类类型
两大原则
-
add:允许添加E和E的子类元素! -
get:可以获取元素,但传入的类型可能是E到Object之间的任何类型,也就无法确定接收到数据类型,所以返回只能使用Object引用来接受!如果需要自己的类型则需要强制类型转换。
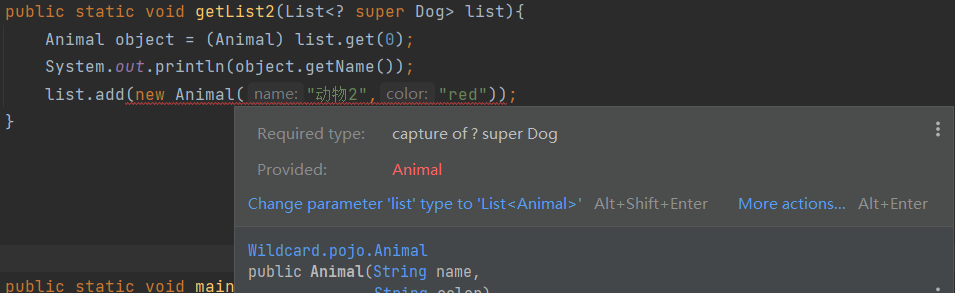
add的时候只能允许添加E和E的子类元素,是因为,万一泛型是E的某个父类A,E的子类也是A的子类,所以添加E和E的子类肯定不会报错。但是如果泛型就是E,这个时候E的父类A的其他子类B不一定是E的子类(肯定不是),所以会报错。比如下面的,虽然泛型是Dog的父类,但是传入Animal会超出Dog这个下界,如果这个Animal是一个Pig,而泛型是Dog,那么就会报错了。
这样添加时肯定没错的,Hashiqi是Dog的子类,添加Dog和Hashiqi肯定没问题。
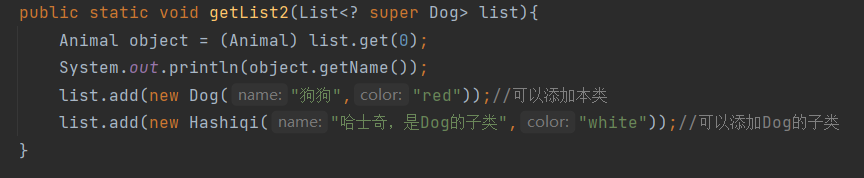
public static void main(String[] args) {
List<Animal> list = new ArrayList<>();//Animal是Dog的父类类型
list.add(new Pig("佩奇","blue"));
mainPractice.getList2(list);
}
什么是PECS原则?
PECS原则:生产者(Producer)使用extends,消费者(Consumer)使用super。
原则
-
如果想要获取,而不需要写值则使用" ? extends T "作为数据结构泛型。
-
如果想要写值,而不需要取值则使用" ? super T "作为数据结构泛型。
实例程序:
public class PESC {
ArrayList<? extends Animal> exdentAnimal;
ArrayList<? super Animal> superAnimal;
Dog dog = new Dog("小黑", "黑色");
private void test() {
Animal a1 = exdentAnimal.get(0);//正确,因为exdentAnimal里面的元素最大不会超过Animal
Animal a2 = superAnimal.get(0);//错误,需要用强制类型转换。
exdentAnimal.add(dog);//错误
superAnimal.add(dog);//正确
}
}
实例程序二:
Collections集合工具类有个copy方法,我们可以看下源码,就是PECS原则。因为只需要从源list中读元素,所以用上界通配符,只需要对dest写元素,所以用下界通配符。
public static <T> void copy(List<? super T> dest, List<? extends T> src) {
int srcSize = src.size();
if (srcSize > dest.size())
throw new IndexOutOfBoundsException("Source does not fit in dest");
if (srcSize < COPY_THRESHOLD ||
(src instanceof RandomAccess && dest instanceof RandomAccess)) {
for (int i=0; i<srcSize; i++)
dest.set(i, src.get(i));
} else {
ListIterator<? super T> di=dest.listIterator();
ListIterator<? extends T> si=src.listIterator();
for (int i=0; i<srcSize; i++) {
di.next();
di.set(si.next());
}
}
}
我们按照这个源码简单改造下
public class CollectionsTest {
/**
* 将源集合数据拷贝到目标集合
*
* @param dest 目标集合
* @param src 源集合
* @return 目标集合
*/
public static <T> void copy(List<? super T> dest, List<? extends T> src) {
int srcSize = src.size();
for (int i = 0; i < srcSize; i++) {
dest.add(src.get(i));
}
}
public static void main(String[] args) {
ArrayList<Animal> animals = new ArrayList();
ArrayList<Pig> pigs = new ArrayList();
pigs.add(new Pig("黑猪", "黑色"));
pigs.add(new Pig("花猪", "花色"));
CollectionsTest.copy(animals, pigs);
System.out.println("dest = " + animals);
}
}
输出结果:
dest = [Animal(name=黑猪, color=黑色), Animal(name=花猪, color=花色)]
通过一个案例来理解 ?和 T 和 Object 的区别
1、实体转换
我们在实际开发中,经常进行实体转换,比如SO转DTO,DTO转DO等等,所以需要一个转换工具类。
如下示例
/**
* 实体转换工具类
* TODO 说明该工具类不能直接用于生产,因为为了代码看去清爽点,我少了一些必要检验,所以如果直接拿来使用可以会在某些场景下会报错。
*/
public class EntityUtil {
/**
* 集合实体转换
* @param target 目标实体类
* @param list 源集合
* @return 装有目标实体的集合
*/
public static <T> List<T> changeEntityList(Class<T> target, List<?> list) throws Exception {
if (list == null || list.size() == 0) {
return null;
}
List<T> resultList = new ArrayList<T>();
for (Object obj : list) {//用Object接收
resultList.add(changeEntityNew(target, obj));
}
return resultList;
}
/**
* 实体转换
* @param target 目标实体class对象
* @param baseTO 源实体
* @return 目标实体
*/
public static <T> T changeEntity(Class<T> target, Object baseTO) throws Exception{
T obj = target.newInstance();
if (baseTO == null) {
return null;
}
BeanUtils.copyProperties(baseTO, obj);
return obj;
}
}
使用工具类示例
private void changeTest() throws Exception {
ArrayList<Pig> pigs = new ArrayList();
pigs.add(new Pig("黑猪", "黑色"));
pigs.add(new Pig("花猪", "花色"));
//实体转换
List<Animal> animals = EntityUtil.changeEntityList(Animal.class, pigs);
}
这是一个很好的例子,从这个例子中我们可以去理解 ?和 T 和 Object的使用场景。
我们先以集合转换来说
public static <T> List<T> changeEntityListNew(Class<T> target, List<?> list);
首先其实我们并不关心传进来的集合内是什么对象,我们只关心我们需要转换的集合内是什么对象,所以我们传进来的集合就可以用List<?>表示任何对象的集合都可以。返回呢,这里指定的是ClassList<T>集合。
再以实体转换方法为例
public static <T> T changeEntityNew(Class<T> target, Object baseTO)
同样的,我们并不关心源对象是什么,我们只关心需要转换的对象,只需关心需要转换的对象为T。
那为什么这里用Object上面用?呢,其实上面也可以改成List<Object> list,效果是一样的,上面List<?> list在遍历的时候最终不就是用Object接收的吗?
?和Object的区别
?类型不确定和Object作用差不多,好多场景下可以通用,但?可以缩小泛型的范围,如:List<? extends Animal>,指定了范围只能是Animal的子类,但是用List<Object>,没法做到缩小范围。
方法前的泛型是啥意思?
参考(111条消息) Java的方法前面有一个<T>是什么?_soralink的博客-CSDN博客,感谢soralink!
我们在看java源码的时候会发现有的方法前面会用。我管这个方法叫做范型方法,英文是Generic Methods。
代码样例:
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
这个抽象方法在返回类型的前面有一个。其实这个声明类似于泛型声明,但是这个方法前面的声名只能作用在方法中。
这个范型可以用于静态和非静态方法但是用<>包裹的泛型必须放在返回类型的前面。在<>里面我们可以放多个范型。
代码举例:
public class Util {
public static <K, V> boolean compare(Pair<K, V> p1, Pair<K, V> p2) {
return p1.getKey().equals(p2.getKey()) &&
p1.getValue().equals(p2.getValue());
}
}
public class Pair<K, V> {
private K key;
private V value;
public Pair(K key, V value) {
this.key = key;
this.value = value;
}
public void setKey(K key) { this.key = key; }
public void setValue(V value) { this.value = value; }
public K getKey() { return key; }
public V getValue() { return value; }
}
这段代码是从官网抄过来的。可以看到在静态方法compare前面放了一个<K, V>。因为我们提前不知道放进来的Pair里面放的是什么类型的,但是我们希望任何类型的Pair都可以放进来。所以我们就用了这种写法。 之后看一下怎么调用这个方法
//完整调用方法
Pair<Integer, String> p1 = new Pair<>(1, "apple");
Pair<Integer, String> p2 = new Pair<>(2, "pear");
boolean same = Util.<Integer, String>compare(p1, p2);
//类型推断调用
Pair<Integer, String> p1 = new Pair<>(1, "apple");
Pair<Integer, String> p2 = new Pair<>(2, "pear");
boolean same = Util.compare(p1, p2);
其实在调用的时候我们可以指定要传入的类型就像第一种调用用法。如果我们省略的话,编译器会推断出什么类型是要被传入的。
总结
- 只用于读功能时,泛型结构使用<? extends T>
- 只用于写功能时,泛型结构使用<? super T>
- 如果既用于写,又用于读操作,那么直接使用
- 如果操作与泛型类型无关,那么使用<?>
Java SPI 机制详解
本文来自 Kingshion 投稿。欢迎更多朋友参与到 JavaGuide 的维护工作,这是一件非常有意义的事情。详细信息请看:JavaGuide 贡献指南 。
在面向对象的设计原则中,一般推荐模块之间基于接口编程,通常情况下调用方模块是不会感知到被调用方模块的内部具体实现。一旦代码里面涉及具体实现类,就违反了开闭原则。如果需要替换一种实现,就需要修改代码。
为了实现在模块装配的时候不用在程序里面动态指明,这就需要一种服务发现机制。Java SPI 就是提供了这样一个机制:为某个接口寻找服务实现的机制。这有点类似 IoC 的思想,将装配的控制权移交到了程序之外。
SPI 介绍
何谓 SPI?
SPI 即 Service Provider Interface ,字面意思就是:“服务提供者的接口”,我的理解是:专门提供给服务提供者或者扩展框架功能的开发者去使用的一个接口。
SPI 将服务接口和具体的服务实现分离开来,将服务调用方和服务实现者解耦,能够提升程序的扩展性、可维护性。修改或者替换服务实现并不需要修改调用方。很多框架都使用了 Java 的 SPI 机制,比如:Spring 框架、数据库加载驱动、日志接口、以及 Dubbo 的扩展实现等等。
SPI 和 API 有什么区别?
那 SPI 和 API 有啥区别?
说到 SPI 就不得不说一下 API 了,从广义上来说它们都属于接口,而且很容易混淆。下面先用一张图说明一下:
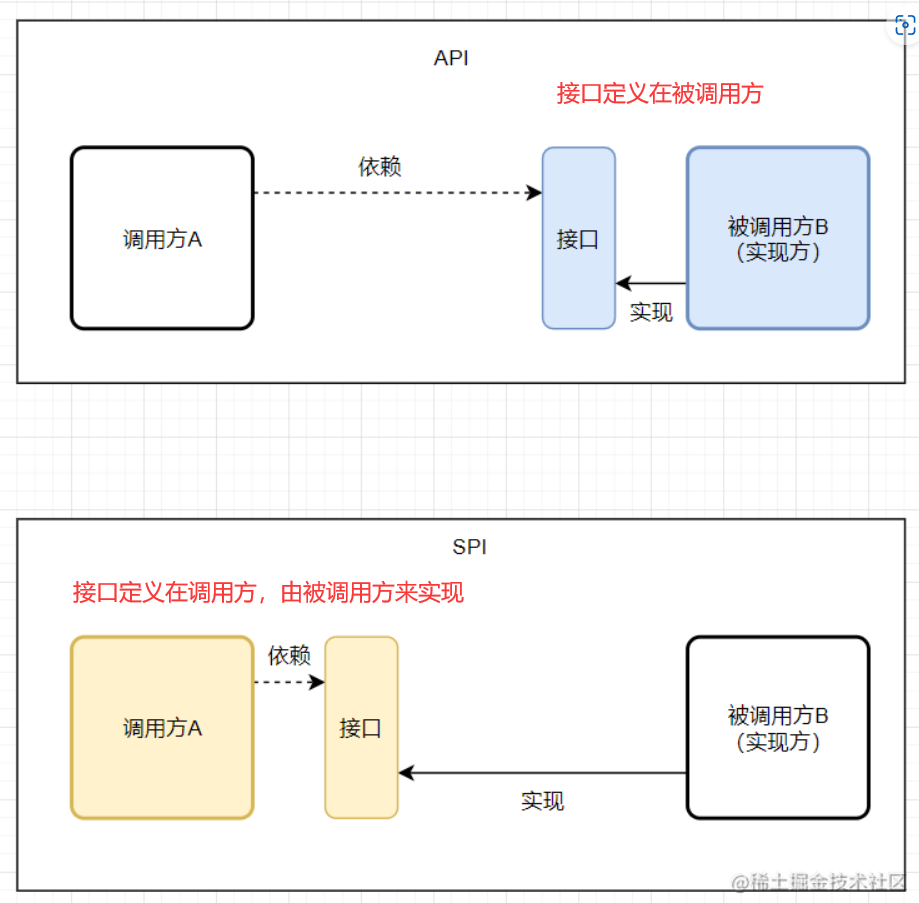
一般模块之间都是通过通过接口进行通讯,那我们在服务调用方和服务实现方(也称服务提供者)之间引入一个“接口”。
当实现方提供了接口和实现,我们可以通过调用实现方的接口从而拥有实现方给我们提供的能力,这就是 API ,这种接口和实现都是放在实现方的。
当接口存在于调用方这边时,就是 SPI ,由接口调用方确定接口规则,然后由不同的厂商去根据这个规则对这个接口进行实现,从而提供服务。
举个通俗易懂的例子:公司 H 是一家科技公司,新设计了一款芯片,然后现在需要量产了,而市面上有好几家芯片制造业公司,这个时候,只要 H 公司指定好了这芯片生产的标准(定义好了接口标准),那么这些合作的芯片公司(服务提供者)就按照标准交付自家特色的芯片(提供不同方案的实现,但是给出来的结果是一样的)。
实战演示
Spring 框架提供的日志服务 SLF4J 其实只是一个日志门面(接口),但是 SLF4J 的具体实现可以有几种,比如:Logback、Log4j、Log4j2 等等,而且还可以切换,在切换日志具体实现的时候我们是不需要更改项目代码的,只需要在 Maven 依赖里面修改一些 pom 依赖就好了。
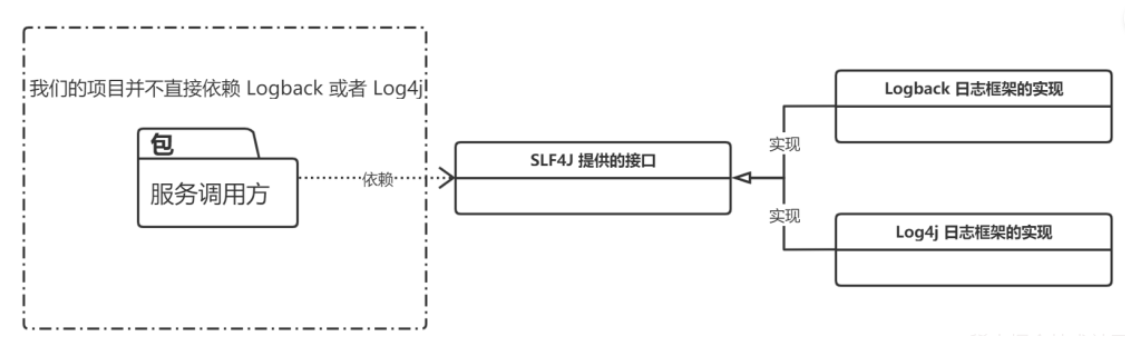
这就是依赖 SPI 机制实现的,那我们接下来就实现一个简易版本的日志框架。
Service Provider Interface
新建一个 Java 项目 service-provider-interface 目录结构如下:(注意直接新建 Java 项目就好了,不用新建 Maven 项目,Maven 项目会涉及到一些编译配置,如果有私服的话,直接 deploy 会比较方便,但是没有的话,在过程中可能会遇到一些奇怪的问题。)
项目目录结构:
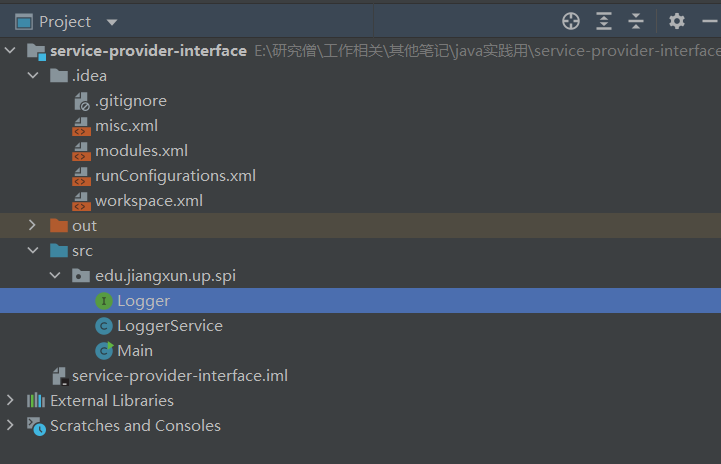
新建 Logger 接口,这个就是 SPI , 服务提供者接口,后面的服务提供者就要针对这个接口进行实现。
package edu.jiangxuan.up.spi;
/**
* 这个就是 SPI , 服务提供者接口,后面的服务提供者就要针对这个接口进行实现。
*/
public interface Logger {
void info(String msg);
void debug(String msg);
}
接下来就是 LoggerService 类,这个主要是为服务使用者(调用方)提供特定功能的。这个类也是实现 Java SPI 机制的关键所在,如果存在疑惑的话可以先往后面继续看。
package edu.jiangxuan.up.spi;
import java.util.ArrayList;
import java.util.List;
import java.util.ServiceLoader;
/**
* 这个主要是为服务使用者(调用方)提供特定功能的。这个类也是实现 Java SPI 机制的关键所在.
*/
public class LoggerService {
private static final LoggerService SERVICE = new LoggerService();
private final Logger logger;
private final List<Logger> loggerList;
private LoggerService() {
ServiceLoader<Logger> loader = ServiceLoader.load(Logger.class);
List<Logger> list = new ArrayList<>();
for (Logger log : loader) {
list.add(log);
}
// LoggerList 是所有 ServiceProvider
loggerList = list;
if (!list.isEmpty()) {
logger = list.get(0);// Logger 只取一个
} else {
logger = null;
}
}
public static LoggerService getService() {
return SERVICE;
}
public void info(String msg) {
if (logger == null) {
System.out.println("info 中没有发现 Logger 服务提供者");
} else {
logger.info(msg);//只用第一个实现类的info方法
}
}
public void debug(String msg) {
if (loggerList.isEmpty()) {
System.out.println("debug 中没有发现 Logger 服务提供者");
}
loggerList.forEach(log -> log.debug(msg));//会遍历所有的实现类的debug方法
}
}
新建 Main 类(服务使用者,调用方),启动程序查看结果。
package edu.jiangxuan.up.spi;
public class Main {
public static void main(String[] args) {
LoggerService service = LoggerService.getService();
service.info("Hello SPI");
service.debug("Hello SPI");
}
}
程序结果:

此时我们只是空有接口,并没有为 Logger 接口提供任何的实现,所以输出结果中没有按照预期打印相应的结果。
接着,你可以使用命令或者直接使用 IDEA 将整个程序直接打包成 jar 包。IDEA打包的步骤可以参考:(111条消息) idea中java程序打jar包的两种方式(超详细)_sunny潘先生的博客-CSDN博客_idea打jar包方式
Service Provider
接下来新建一个项目用来实现 Logger 接口。新建项目 service-provider 目录结构如下:
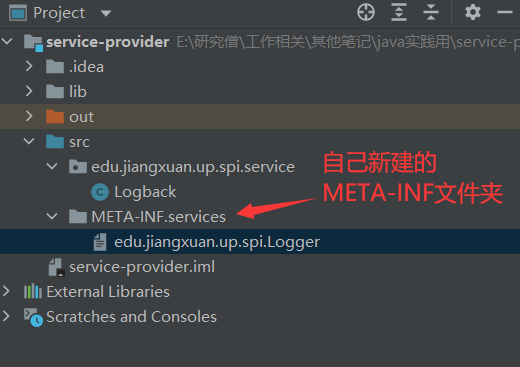
新建 Logback 类.
package edu.jiangxuan.up.spi.service;
import edu.jiangxuan.up.spi.Logger;
public class Logback implements Logger {
@Override
public void info(String s) {System.out.println("Logback info 打印日志:" + s);}
@Override
public void debug(String s) {System.out.println("Logback debug 打印日志:" + s);}
}
实现 Logger 接口,在 src 目录下新建 META-INF/services 文件夹,然后新建文件 edu.jiangxuan.up.spi.Logger (SPI 的全类名),文件里面的内容是:edu.jiangxuan.up.spi.service.Logback (Logback 的全类名,即 SPI 的实现类的包名 + 类名)。这是 JDK SPI 机制 ServiceLoader 约定好的标准。
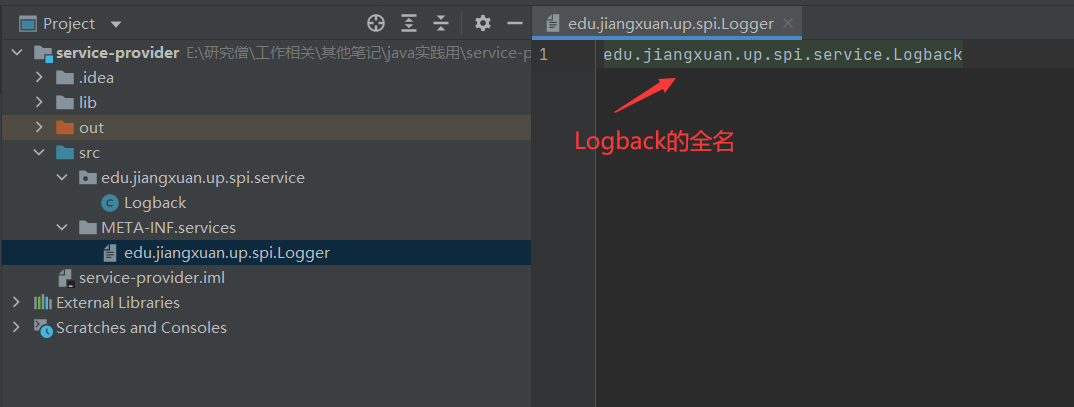
这里先大概解释一下:Java 中的 SPI 机制就是在每次类加载的时候会先去找到 class 相对目录下的 META-INF 文件夹下的 services 文件夹下的文件,将这个文件夹下面的所有文件先加载到内存中,然后根据这些文件的文件名和里面的文件内容找到相应接口的具体实现类,找到实现类后就可以通过反射去生成对应的对象,保存在一个 list 列表里面,所以可以通过迭代或者遍历的方式拿到对应的实例对象,生成不同的实现。
META-INF文件夹用来干嘛的?
如果META-INF文件夹存在的话,是用来存储包和扩展的配置数据,包含安全,版本,扩展和服务。META-INF下支持四种类型,会被java自动识别并解析,用于配置应用,扩展,类加载器,服务。
1.MANIFEST.MF。MANIFEST文件用来定义扩展和包相关的数据,
2.INDEX.LIST。如果使用了jar工具的 "-i"选项,这个文件就会自动生成.文件包含了路径信息和应用或扩展的包定义.它是部分jar索引的实现方式,可用来提高类加载器的加载速度
3.x.SF。jar包的签名文件,包含清单信息,SF表示signature file, "x" 是文件名
4.x.DSA。. DSA是一种非对称的数字签名算法.可简单理解为"私钥加密生成数字签名,公钥验证数据及签名", x.DSA是"x.SF"文件关联的同名的"签名块文件",里面存着x.SF的数字签名. SF签名文件和DSA签名块文件可用"jarsigner"命令生成.其实还支持RSA算法,对应的是.RSA的 后缀名
5.services/ 目录文件,存放 服务提供者 的配置文件
所以会提出一些规范要求:文件名一定要是接口的全类名,然后里面的内容一定要是实现类的全类名,实现类可以有多个,直接换行就好了,多个实现类的时候,会一个一个的迭代加载。
接下来同样将 service-provider 项目打包成 jar 包,这个 jar 包就是服务提供方的实现。通常我们导入 maven 的 pom 依赖就有点类似这种,只不过我们现在没有将这个 jar 包发布到 maven 公共仓库中,所以在需要使用的地方只能手动的添加到项目中。
效果展示
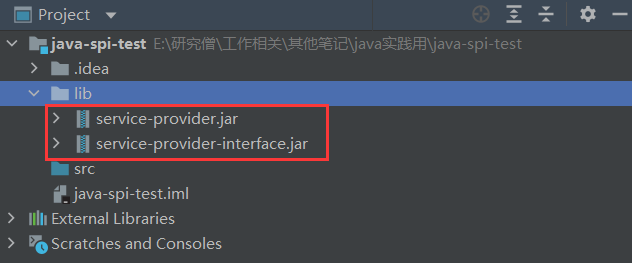
为了更直观的展示效果,我这里再新建一个专门用来测试的工程项目:java-spi-test
然后先导入 Logger 的接口 jar 包,再导入具体的实现类的 jar 包。
新建 Main 方法测试:
package edu.jiangxuan.up.service;
import edu.jiangxuan.up.spi.LoggerService;
public class TestJavaSPI {
public static void main(String[] args) {
LoggerService loggerService = LoggerService.getService();
loggerService.info("你好");
loggerService.debug("测试Java SPI 机制");
}
}
运行结果如下:
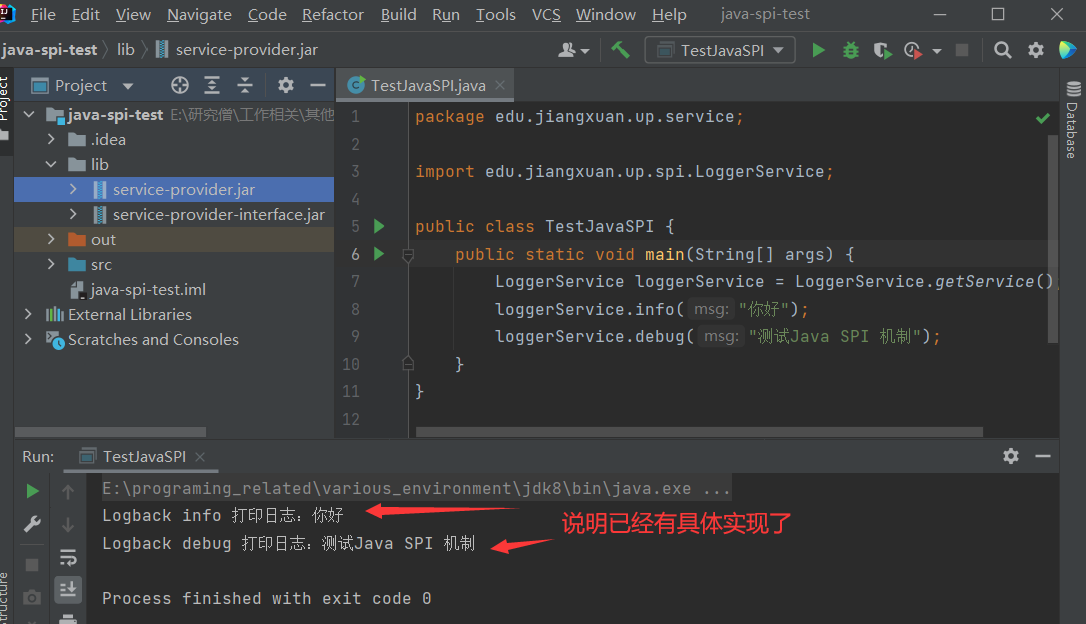
Logback info 打印日志:你好 Logback debug 打印日志:测试 Java SPI 机制
说明导入 jar 包中的实现类生效了。如果我们不导入具体的实现类的 jar 包,那么此时程序运行的结果就会是:
info 中没有发现 Logger 服务提供者 debug 中没有发现 Logger 服务提供者
通过使用 SPI 机制,可以看出服务(LoggerService)和 服务提供者两者之间的耦合度非常低,如果说我们想要换一种实现,那么其实只需要修改 service-provider 项目中针对 Logger 接口的具体实现就可以了,只需要换一个 jar 包即可,也可以有在一个项目里面有多个实现,这不就是 SLF4J 原理吗?
如果某一天需求变更了,此时需要将日志输出到消息队列,或者做一些别的操作,这个时候完全不需要更改 Logback 的实现,只需要新增一个服务实现(service-provider)可以通过在本项目里面新增实现也可以从外部引入新的服务实现 jar 包。我们可以在服务(LoggerService)中选择一个具体的 服务实现(service-provider) 来完成我们需要的操作。
假如我有多个实现类(比如多个厂商实现了这个接口),那么我的debug方法会遍历所有的实现类的debug方法,但是info只取第一个。比如service-provider中又有一个实现了Logger接口的Logback2。
package edu.jiangxuan.up.spi.service;
import edu.jiangxuan.up.spi.Logger;
public class Logback2 implements Logger {
@Override
public void info(String s) {System.out.println("Logback222 info 打印日志:" + s);}
@Override
public void debug(String s) {System.out.println("Logback222 debug 打印日志:" + s);}
}
并且把他的全类名配置进去
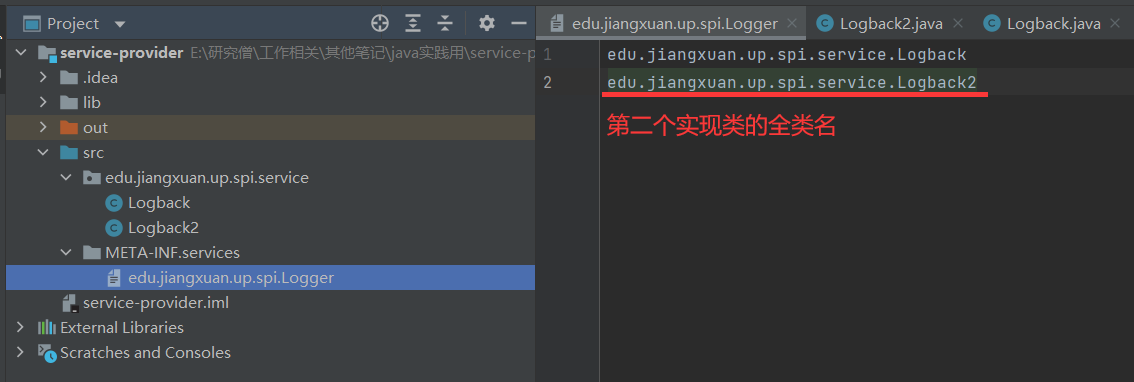
打成jar包后再运行java-spi-test,得到如下结果:
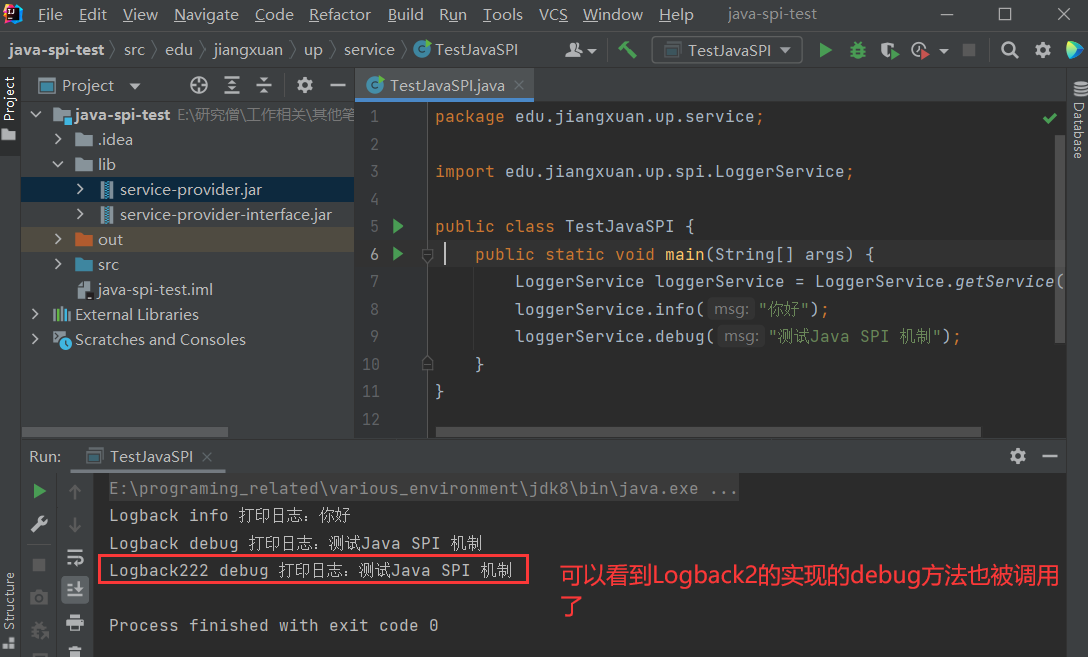
那么接下来我们具体来说说 Java SPI 工作的重点原理—— ServiceLoader 。
ServiceLoader
ServiceLoader 具体实现
想要使用 Java 的 SPI 机制是需要依赖 ServiceLoader 来实现的,那么我们接下来看看 ServiceLoader 具体是怎么做的:
ServiceLoader 是 JDK 提供的一个工具类, 位于package java.util;包下。
A facility to load implementations of a service.
这是 JDK 官方给的注释:一种加载服务实现的工具。
再往下看,我们发现这个类是一个 final 类型的,所以是不可被继承修改,同时它实现了 Iterable 接口。之所以实现了迭代器,是为了方便后续我们能够通过迭代的方式得到对应的服务实现。
public final class ServiceLoader<S> implements Iterable<S>{ xxx...}
可以看到一个熟悉的常量定义:private static final String PREFIX = "META-INF/services/";
下面是 load 方法:可以发现 load 方法支持两种重载后的入参;
public static <S> ServiceLoader<S> load(Class<S> service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
public static <S> ServiceLoader<S> load(Class<S> service,ClassLoader loader) {
return new ServiceLoader<>(service, loader);
}
private ServiceLoader(Class<S> svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
reload();
}
public void reload() {
providers.clear();
lookupIterator = new LazyIterator(service, loader);
}
根据代码的调用顺序,在 reload() 方法中是通过一个内部类 LazyIterator 实现的。先继续往下面看。
ServiceLoader 实现了 Iterable 接口的方法后,具有了迭代的能力,在这个 iterator 方法被调用时,首先会在 ServiceLoader 的 Provider 缓存中进行查找,如果缓存中没有命中那么则在 LazyIterator 中进行查找。
public Iterator<S> iterator() {
return new Iterator<S>() {
Iterator<Map.Entry<String, S>> knownProviders= providers.entrySet().iterator();
public boolean hasNext() {
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext(); // 调用 LazyIterator
}
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next(); // 调用 LazyIterator
}
public void remove() {throw new UnsupportedOperationException();}
};
}
在调用 LazyIterator 时,具体实现如下:
public boolean hasNext() {
if (acc == null) {
return hasNextService();
} else {
PrivilegedAction<Boolean> action = new PrivilegedAction<Boolean>() {
public Boolean run() {
return hasNextService();
}
};
return AccessController.doPrivileged(action, acc);
}
}
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
//通过PREFIX(META-INF/services/)和类名 获取对应的配置文件,得到具体的实现类
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}
public S next() {
if (acc == null) {
return nextService();
} else {
PrivilegedAction<S> action = new PrivilegedAction<S>() {
public S run() {
return nextService();
}
};
return AccessController.doPrivileged(action, acc);
}
}
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,"Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service,"Provider " + cn + " not a subtype");
}
try {
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service,"Provider " + cn + " could not be instantiated",x);
}
throw new Error(); // This cannot happen
}
自己实现一个 ServiceLoader
package edu.jiangxuan.up.service;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.lang.reflect.Constructor;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.Enumeration;
import java.util.List;
public class MyServiceLoader<S> {
// 对应的接口 Class 模板
private final Class<S> service;
// 对应实现类的 可以有多个,用 List 进行封装
private final List<S> providers = new ArrayList<>();
// 类加载器
private final ClassLoader classLoader;
// 暴露给外部使用的方法,通过调用这个方法可以开始加载自己定制的实现流程。
public static <S> MyServiceLoader<S> load(Class<S> service) {
return new MyServiceLoader<>(service);
}
// 构造方法私有化
private MyServiceLoader(Class<S> service) {
this.service = service;
this.classLoader = Thread.currentThread().getContextClassLoader();
doLoad();
}
// 关键方法,加载具体实现类的逻辑
private void doLoad() {
try {
// 读取所有 jar 包里面 META-INF/services 包下面的文件,这个文件名就是接口名,然后文件里面的内容就是具体的实现类的路径加全类名
Enumeration<URL> urls = classLoader.getResources("META-INF/services/" + service.getName());
// 挨个遍历取到的文件
while (urls.hasMoreElements()) {
// 取出当前的文件
URL url = urls.nextElement();
System.out.println("File = " + url.getPath());
// 建立链接
URLConnection urlConnection = url.openConnection();
urlConnection.setUseCaches(false);
// 获取文件输入流
InputStream inputStream = urlConnection.getInputStream();
// 从文件输入流获取缓存
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
// 从文件内容里面得到实现类的全类名
String className = bufferedReader.readLine();
while (className != null) {
// 通过反射拿到实现类的实例
Class<?> clazz = Class.forName(className, false, classLoader);
// 如果声明的接口跟这个具体的实现类是属于同一类型,(可以理解为Java的一种多态,接口跟实现类、父类和子类等等这种关系。)则构造实例
if (service.isAssignableFrom(clazz)) {
Constructor<? extends S> constructor = (Constructor<? extends S>) clazz.getConstructor();
S instance = constructor.newInstance();
// 把当前构造的实例对象添加到 Provider的列表里面
providers.add(instance);
}
// 继续读取下一行的实现类,可以有多个实现类,只需要换行就可以了。
className = bufferedReader.readLine();
}
}
} catch (Exception e) {
System.out.println("读取文件异常。。。");
}
}
// 返回spi接口对应的具体实现类列表
public List<S> getProviders() {
return providers;
}
}
主要的流程就是:
- 通过 URL 工具类从 jar 包的
/META-INF/services目录下面找到对应的文件, - 读取这个文件的名称找到对应的 spi 接口,
- 通过
InputStream流将文件里面的具体实现类的全类名读取出来, - 根据获取到的全类名,先判断跟 spi 接口是否为同一类型,如果是的,那么就通过反射的机制构造对应的实例对象,
- 将构造出来的实例对象添加到
Providers的列表中。
总结
其实不难发现,SPI 机制的具体实现本质上还是通过反射完成的。即:我们按照规定将要暴露对外使用的具体实现类在 META-INF/services/ 文件下声明。
另外,SPI 机制在很多框架中都有应用:Spring 框架的基本原理也是类似的反射。还有 Dubbo 框架提供同样的 SPI 扩展机制,只不过 Dubbo 和 spring 框架中的 SPI 机制具体实现方式跟咱们今天学得这个有些细微的区别,不过整体的原理都是一致的,相信大家通过对 JDK 中 SPI 机制的学习,能够一通百通,加深对其他高深框的理解。
通过 SPI 机制能够大大地提高接口设计的灵活性,但是 SPI 机制也存在一些缺点,比如:
- 遍历加载所有的实现类,这样效率还是相对较低的;
- 当多个
ServiceLoader同时load时,会有并发问题。
Java语法糖详解
作者:Hollis
语法糖是大厂 Java 面试常问的一个知识点。
本文从 Java 编译原理角度,深入字节码及 class 文件,抽丝剥茧,了解 Java 中的语法糖原理及用法,帮助大家在学会如何使用 Java 语法糖的同时,了解这些语法糖背后的原理。
什么是语法糖?
语法糖(Syntactic Sugar) 也称糖衣语法,是英国计算机学家 Peter.J.Landin 发明的一个术语,指在计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。简而言之,语法糖让程序更加简洁,有更高的可读性。
我们所熟知的编程语言中几乎都有语法糖。作者认为,语法糖的多少是评判一个语言够不够牛逼的标准之一。很多人说 Java 是一个“低糖语言”,其实从 Java 7 开始 Java 语言层面上一直在添加各种糖,主要是在“Project Coin”项目下研发。尽管现在 Java 有人还是认为现在的 Java 是低糖,未来还会持续向着“高糖”的方向发展。
Java 中有哪些常见的语法糖?
前面提到过,语法糖的存在主要是方便开发人员使用。但其实, Java 虚拟机并不支持这些语法糖。这些语法糖在编译阶段就会被还原成简单的基础语法结构,这个过程就是解语法糖。
说到编译,大家肯定都知道,Java 语言中,javac命令可以将后缀名为.java的源文件编译为后缀名为.class的可以运行于 Java 虚拟机的字节码。如果你去看com.sun.tools.javac.main.JavaCompiler的源码,你会发现在compile()中有一个步骤就是调用desugar(),这个方法就是负责解语法糖的实现的。
Java 中最常用的语法糖主要有泛型、变长参数、条件编译、自动拆装箱、内部类等。本文主要来分析下这些语法糖背后的原理。一步一步剥去糖衣,看看其本质。
switch 支持 String 与枚举
前面提到过,从 Java 7 开始,Java 语言中的语法糖在逐渐丰富,其中一个比较重要的就是 Java 7 中switch开始支持String。
在开始之前先科普下,Java 中的switch自身原本就支持基本类型。比如int、char等。对于int类型,直接进行数值的比较。对于char类型则是比较其 ascii 码。所以,对于编译器来说,switch中其实只能使用整型,任何类型的比较都要转换成整型。比如byte。short,char(ackii 码是整型)以及int。
那么接下来看下switch对String的支持,有以下代码:
public class switchDemoString {
public static void main(String[] args) {
String str = "world";
switch (str) {
case "hello":
System.out.println("hello");
break;
case "world":
System.out.println("world");
break;
default:
break;
}
}
}
反编译后内容如下:
public class switchDemoString
{
public switchDemoString()
{
}
public static void main(String args[])
{
String str = "world";
String s;
switch((s = str).hashCode())
{
default:
break;
case 99162322:
if(s.equals("hello"))
System.out.println("hello");
break;
case 113318802:
if(s.equals("world"))
System.out.println("world");
break;
}
}
}
看到这个代码,你知道原来 字符串的 switch 是通过equals()和hashCode()方法来实现的。 还好hashCode()方法返回的是int,而不是long。
仔细看下可以发现,进行switch的实际是哈希值,然后通过使用equals方法比较进行安全检查,这个检查是必要的,因为哈希可能会发生碰撞。因此它的性能是不如使用枚举进行 switch 或者使用纯整数常量,但这也不是很差。
泛型
我们都知道,很多语言都是支持泛型的,但是很多人不知道的是,不同的编译器对于泛型的处理方式是不同的,通常情况下,一个编译器处理泛型有两种方式:Code specialization和Code sharing。C++和 C#是使用Code specialization的处理机制,而 Java 使用的是Code sharing的机制。
Code sharing 方式为每个泛型类型创建唯一的字节码表示,并且将该泛型类型的实例都映射到这个唯一的字节码表示上。将多种泛型类形实例映射到唯一的字节码表示是通过类型擦除(
type erasue)实现的。
也就是说,对于 Java 虚拟机来说,他根本不认识Map<String, String> map这样的语法。需要在编译阶段通过类型擦除的方式进行解语法糖。
类型擦除的主要过程如下: 1.将所有的泛型参数用其最左边界(最顶级的父类型)类型替换。 2.移除所有的类型参数。
以下代码:
Map<String, String> map = new HashMap<String, String>();
map.put("name", "hollis");
map.put("wechat", "Hollis");
map.put("blog", "www.hollischuang.com");
解语法糖之后会变成:
Map map = new HashMap();
map.put("name", "hollis");
map.put("wechat", "Hollis");
map.put("blog", "www.hollischuang.com");
以下代码:
public static <A extends Comparable<A>> A max(Collection<A> xs) {
Iterator<A> xi = xs.iterator();
A w = xi.next();
while (xi.hasNext()) {
A x = xi.next();
if (w.compareTo(x) < 0)
w = x;
}
return w;
}
类型擦除后会变成:
public static Comparable max(Collection xs){
Iterator xi = xs.iterator();
Comparable w = (Comparable)xi.next();
while(xi.hasNext())
{
Comparable x = (Comparable)xi.next();
if(w.compareTo(x) < 0)
w = x;
}
return w;
}
虚拟机中没有泛型,只有普通类和普通方法,所有泛型类的类型参数在编译时都会被擦除,泛型类并没有自己独有的Class类对象。比如并不存在List<String>.class或是List<Integer>.class,而只有List.class。
自动装箱与拆箱
自动装箱就是 Java 自动将原始类型值转换成对应的包装类的对象,比如将 int 的变量转换成 Integer 对象,这个过程叫做装箱,反之将 Integer 对象转换成 int 类型值,这个过程叫做拆箱。因为这里的装箱和拆箱是自动进行的非人为转换,所以就称作为自动装箱和拆箱。原始类型 byte, short, char, int, long, float, double 和 boolean 对应的封装类为 Byte, Short, Character, Integer, Long, Float, Double, Boolean。
先来看个自动装箱的代码:
public static void main(String[] args) {
int i = 10;
Integer n = i;
}
反编译后代码如下:
public static void main(String args[]){
int i = 10;
Integer n = Integer.valueOf(i);
}
再来看个自动拆箱的代码:
public static void main(String[] args) {
Integer i = 10;
int n = i;
}
反编译后代码如下:
public static void main(String args[]){
Integer i = Integer.valueOf(10);
int n = i.intValue();
}
从反编译得到内容可以看出,在装箱的时候自动调用的是Integer的valueOf(int)方法。而在拆箱的时候自动调用的是Integer的intValue方法。
所以,装箱过程是通过调用包装器的 valueOf 方法实现的,而拆箱过程是通过调用包装器的 xxxValue 方法实现的。
如何避免自动拆箱?
比如我有一个ArrayList<Intger>,现在调用remove(Object c)方法时,放进去一个Integer对象,它却给我调用成了remove(int index)的方法了。这种坑可以用list.remove((Integer) c);或者list.remove((Object) c);来显式的调用。
可变长参数
可变参数(variable arguments)是在 Java 1.5 中引入的一个特性。它允许一个方法把任意数量的值作为参数。
看下以下可变参数代码,其中 print 方法接收可变参数:
public static void main(String[] args){
print("Holis", "公众号:Hollis", "博客:www.hollischuang.com", "QQ:907607222");
}
public static void print(String... strs){
for (int i = 0; i < strs.length; i++){
System.out.println(strs[i]);
}
}
反编译后代码:
public static void main(String args[]){
print(new String[] {
"Holis", "\u516C\u4F17\u53F7:Hollis", "\u535A\u5BA2\uFF1Awww.hollischuang.com", "QQ\uFF1A907607222"
});
}
public static transient void print(String strs[]){
for(int i = 0; i < strs.length; i++)
System.out.println(strs[i]);
}
从反编译后代码可以看出,可变参数在被使用的时候,他首先会创建一个数组,数组的长度就是调用该方法是传递的实参的个数,然后再把参数值全部放到这个数组当中,然后再把这个数组作为参数传递到被调用的方法中。
枚举
Java SE5 提供了一种新的类型-Java 的枚举类型,关键字enum可以将一组具名的值的有限集合创建为一种新的类型,而这些具名的值可以作为常规的程序组件使用,这是一种非常有用的功能。
要想看源码,首先得有一个类吧,那么枚举类型到底是什么类呢?是enum吗?答案很明显不是,enum就和class一样,只是一个关键字,他并不是一个类,那么枚举是由什么类维护的呢,我们简单的写一个枚举:
public enum t {
SPRING,SUMMER;
}
然后我们使用反编译,看看这段代码到底是怎么实现的,反编译后代码内容如下:
public final class T extends Enum
{
private T(String s, int i)
{
super(s, i);
}
public static T[] values()
{
T at[];
int i;
T at1[];
System.arraycopy(at = ENUM$VALUES, 0, at1 = new T[i = at.length], 0, i);
return at1;
}
public static T valueOf(String s)
{
return (T)Enum.valueOf(demo/T, s);
}
public static final T SPRING;
public static final T SUMMER;
private static final T ENUM$VALUES[];
static
{
SPRING = new T("SPRING", 0);
SUMMER = new T("SUMMER", 1);
ENUM$VALUES = (new T[] {
SPRING, SUMMER
});
}
}
通过反编译后代码我们可以看到,public final class T extends Enum,说明,该类是继承了Enum类的,同时final关键字告诉我们,这个类也是不能被继承的。
当我们使用enum来定义一个枚举类型的时候,编译器会自动帮我们创建一个final类型的类继承Enum类,所以枚举类型不能被继承。
内部类
内部类又称为嵌套类,可以把内部类理解为外部类的一个普通成员。
内部类之所以也是语法糖,是因为它仅仅是一个编译时的概念,outer.java里面定义了一个内部类inner,一旦编译成功,就会生成两个完全不同的.class文件了,分别是outer.class和outer$inner.class。所以内部类的名字完全可以和它的外部类名字相同。
public class OutterClass {
private String userName;
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public static void main(String[] args) {
}
class InnerClass{
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
}
以上代码编译后会生成两个 class 文件:OutterClass$InnerClass.class 、OutterClass.class 。当我们尝试对OutterClass.class文件进行反编译的时候,命令行会打印以下内容:Parsing OutterClass.class...Parsing inner class OutterClass$InnerClass.class... Generating OutterClass.jad 。他会把两个文件全部进行反编译,然后一起生成一个OutterClass.jad文件。文件内容如下:
public class OutterClass
{
class InnerClass
{
public String getName()
{
return name;
}
public void setName(String name)
{
this.name = name;
}
private String name;
final OutterClass this$0;
InnerClass()
{
this.this$0 = OutterClass.this;
super();
}
}
public OutterClass()
{
}
public String getUserName()
{
return userName;
}
public void setUserName(String userName){
this.userName = userName;
}
public static void main(String args1[])
{
}
private String userName;
}
条件编译
—般情况下,程序中的每一行代码都要参加编译。但有时候出于对程序代码优化的考虑,希望只对其中一部分内容进行编译,此时就需要在程序中加上条件,让编译器只对满足条件的代码进行编译,将不满足条件的代码舍弃,这就是条件编译。
如在 C 或 CPP 中,可以通过预处理语句来实现条件编译。其实在 Java 中也可实现条件编译。我们先来看一段代码:
ublic class ConditionalCompilation {
public static void main(String[] args) {
final boolean DEBUG = true;
if(DEBUG) {
System.out.println("Hello, DEBUG!");
}
final boolean ONLINE = false;
if(ONLINE){
System.out.println("Hello, ONLINE!");
}
}
}
反编译后代码如下:
public class ConditionalCompilation
{
public ConditionalCompilation()
{
}
public static void main(String args[])
{
boolean DEBUG = true;
System.out.println("Hello, DEBUG!");
boolean ONLINE = false;
}
}
首先,我们发现,在反编译后的代码中没有System.out.println("Hello, ONLINE!");,这其实就是条件编译。当if(ONLINE)为 false 的时候,编译器就没有对其内的代码进行编译。
所以,Java 语法的条件编译,是通过判断条件为常量的 if 语句实现的。其原理也是 Java 语言的语法糖。根据 if 判断条件的真假,编译器直接把分支为 false 的代码块消除。通过该方式实现的条件编译,必须在方法体内实现,而无法在整个 Java 类的结构或者类的属性上进行条件编译,这与 C/C++的条件编译相比,确实更有局限性。在 Java 语言设计之初并没有引入条件编译的功能,虽有局限,但是总比没有更强。
断言
在 Java 中,assert关键字是从 JAVA SE 1.4 引入的,为了避免和老版本的 Java 代码中使用了assert关键字导致错误,Java 在执行的时候默认是不启动断言检查的(这个时候,所有的断言语句都将忽略!),如果要开启断言检查,则需要用开关-enableassertions或-ea来开启。
看一段包含断言的代码:
public class AssertTest {
public static void main(String args[]) {
int a = 1;
int b = 1;
assert a == b;
System.out.println("公众号:Hollis");
assert a != b : "Hollis";
System.out.println("博客:www.hollischuang.com");
}
}
反编译后代码如下:
public class AssertTest {
public AssertTest()
{
}
public static void main(String args[])
{
int a = 1;
int b = 1;
if(!$assertionsDisabled && a != b)
throw new AssertionError();
System.out.println("\u516C\u4F17\u53F7\uFF1AHollis");
if(!$assertionsDisabled && a == b)
{
throw new AssertionError("Hollis");
} else
{
System.out.println("\u535A\u5BA2\uFF1Awww.hollischuang.com");
return;
}
}
static final boolean $assertionsDisabled = !com/hollis/suguar/AssertTest.desiredAssertionStatus();
}
很明显,反编译之后的代码要比我们自己的代码复杂的多。所以,使用了 assert 这个语法糖我们节省了很多代码。其实断言的底层实现就是 if 语言,如果断言结果为 true,则什么都不做,程序继续执行,如果断言结果为 false,则程序抛出 AssertError 来打断程序的执行。-enableassertions会设置$assertionsDisabled 字段的值。
数值字面量
在 java 7 中,数值字面量,不管是整数还是浮点数,都允许在数字之间插入任意多个下划线。这些下划线不会对字面量的数值产生影响,目的就是方便阅读。
比如:
public class Test {
public static void main(String... args) {
int i = 10_000;
System.out.println(i);
}
}
反编译后:
public class Test
{
public static void main(String[] args)
{
int i = 10000;
System.out.println(i);
}
}
反编译后就是把_删除了。也就是说 编译器并不认识在数字字面量中的_,需要在编译阶段把他去掉。
for-each
增强 for 循环(for-each)相信大家都不陌生,日常开发经常会用到的,他会比 for 循环要少写很多代码,那么这个语法糖背后是如何实现的呢?
public static void main(String... args) {
String[] strs = {"Hollis", "公众号:Hollis", "博客:www.hollischuang.com"};
for (String s : strs) {
System.out.println(s);
}
List<String> strList = ImmutableList.of("Hollis", "公众号:Hollis", "博客:www.hollischuang.com");
for (String s : strList) {
System.out.println(s);
}
}
反编译后代码如下:
public static transient void main(String args[])
{
String strs[] = {
"Hollis", "\u516C\u4F17\u53F7\uFF1AHollis", "\u535A\u5BA2\uFF1Awww.hollischuang.com"
};
String args1[] = strs;
int i = args1.length;
for(int j = 0; j < i; j++)
{
String s = args1[j];
System.out.println(s);
}
List strList = ImmutableList.of("Hollis", "\u516C\u4F17\u53F7\uFF1AHollis", "\u535A\u5BA2\uFF1Awww.hollischuang.com");
String s;
for(Iterator iterator = strList.iterator(); iterator.hasNext(); System.out.println(s))
s = (String)iterator.next();
}
代码很简单,for-each 的实现原理其实就是使用了普通的 for 循环和迭代器。
try-with-resource
Java 里,对于文件操作 IO 流、数据库连接等开销非常昂贵的资源,用完之后必须及时通过 close 方法将其关闭,否则资源会一直处于打开状态,可能会导致内存泄露等问题。
关闭资源的常用方式就是在finally块里是释放,即调用close方法。比如,我们经常会写这样的代码:
public static void main(String[] args) {
BufferedReader br = null;
try {
String line;
br = new BufferedReader(new FileReader("d:\\hollischuang.xml"));
while ((line = br.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
// handle exception
} finally {
try {
if (br != null) {
br.close();
}
} catch (IOException ex) {
// handle exception
}
}
}
从 Java 7 开始,jdk 提供了一种更好的方式关闭资源,使用try-with-resources语句,改写一下上面的代码,效果如下:
public static void main(String... args) {
try (BufferedReader br = new BufferedReader(new FileReader("d:\\ hollischuang.xml"))) {
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
// handle exception
}
}
看,这简直是一大福音啊,虽然我之前一般使用IOUtils去关闭流,并不会使用在finally中写很多代码的方式,但是这种新的语法糖看上去好像优雅很多呢。看下他的背后:
public static transient void main(String args[])
{
BufferedReader br;
Throwable throwable;
br = new BufferedReader(new FileReader("d:\\ hollischuang.xml"));
throwable = null;
String line;
try
{
while((line = br.readLine()) != null)
System.out.println(line);
}
catch(Throwable throwable2)
{
throwable = throwable2;
throw throwable2;
}
if(br != null)
if(throwable != null)
try
{
br.close();
}
catch(Throwable throwable1)
{
throwable.addSuppressed(throwable1);
}
else
br.close();
break MISSING_BLOCK_LABEL_113;
Exception exception;
exception;
if(br != null)
if(throwable != null)
try
{
br.close();
}
catch(Throwable throwable3)
{
throwable.addSuppressed(throwable3);
}
else
br.close();
throw exception;
IOException ioexception;
ioexception;
}
}
其实背后的原理也很简单,那些我们没有做的关闭资源的操作,编译器都帮我们做了。所以,再次印证了,语法糖的作用就是方便程序员的使用,但最终还是要转成编译器认识的语言。
Lambda 表达式
关于 lambda 表达式,有人可能会有质疑,因为网上有人说他并不是语法糖。其实我想纠正下这个说法。Labmda 表达式不是匿名内部类的语法糖,但是他也是一个语法糖。实现方式其实是依赖了几个 JVM 底层提供的 lambda 相关 api。
先来看一个简单的 lambda 表达式。遍历一个 list:
public static void main(String... args) {
List<String> strList = ImmutableList.of("Hollis", "公众号:Hollis", "博客:www.hollischuang.com");
strList.forEach( s -> { System.out.println(s); } );
}
为啥说他并不是内部类的语法糖呢,前面讲内部类我们说过,内部类在编译之后会有两个 class 文件,但是,包含 lambda 表达式的类编译后只有一个文件。
反编译后代码如下:
public static /* varargs */ void main(String ... args) {
ImmutableList strList = ImmutableList.of((Object)"Hollis", (Object)"\u516c\u4f17\u53f7\uff1aHollis", (Object)"\u535a\u5ba2\uff1awww.hollischuang.com");
strList.forEach((Consumer<String>)LambdaMetafactory.metafactory(null, null, null, (Ljava/lang/Object;)V, lambda$main$0(java.lang.String ), (Ljava/lang/String;)V)());
}
private static /* synthetic */ void lambda$main$0(String s) {
System.out.println(s);
}
可以看到,在forEach方法中,其实是调用了java.lang.invoke.LambdaMetafactory#metafactory方法,该方法的第四个参数 implMethod 指定了方法实现。可以看到这里其实是调用了一个lambda$main$0方法进行了输出。
再来看一个稍微复杂一点的,先对 List 进行过滤,然后再输出:
public static void main(String... args) {
List<String> strList = ImmutableList.of("Hollis", "公众号:Hollis", "博客:www.hollischuang.com");
List HollisList = strList.stream().filter(string -> string.contains("Hollis")).collect(Collectors.toList());
HollisList.forEach( s -> { System.out.println(s); } );
}
反编译后代码如下:
public static /* varargs */ void main(String ... args) {
ImmutableList strList = ImmutableList.of((Object)"Hollis", (Object)"\u516c\u4f17\u53f7\uff1aHollis", (Object)"\u535a\u5ba2\uff1awww.hollischuang.com");
List<Object> HollisList = strList.stream().filter((Predicate<String>)LambdaMetafactory.metafactory(null, null, null, (Ljava/lang/Object;)Z, lambda$main$0(java.lang.String ), (Ljava/lang/String;)Z)()).collect(Collectors.toList());
HollisList.forEach((Consumer<Object>)LambdaMetafactory.metafactory(null, null, null, (Ljava/lang/Object;)V, lambda$main$1(java.lang.Object ), (Ljava/lang/Object;)V)());
}
private static /* synthetic */ void lambda$main$1(Object s) {
System.out.println(s);
}
private static /* synthetic */ boolean lambda$main$0(String string) {
return string.contains("Hollis");
}
两个 lambda 表达式分别调用了lambda$main$1和lambda$main$0两个方法。
所以,lambda 表达式的实现其实是依赖了一些底层的 api,在编译阶段,编译器会把 lambda 表达式进行解糖,转换成调用内部 api 的方式。
可能遇到的坑
泛型
一、当泛型遇到重载
public class GenericTypes {
public static void method(List<String> list) {
System.out.println("invoke method(List<String> list)");
}
public static void method(List<Integer> list) {
System.out.println("invoke method(List<Integer> list)");
}
}
上面这段代码,有两个重载的函数,因为他们的参数类型不同,一个是List<String>另一个是List<Integer> ,但是,这段代码是编译通不过的。因为我们前面讲过,参数List<Integer>和List<String>编译之后都被擦除了,变成了一样的原生类型 List,擦除动作导致这两个方法的特征签名变得一模一样。
二、当泛型遇到 catch
泛型的类型参数不能用在 Java 异常处理的 catch 语句中。因为异常处理是由 JVM 在运行时刻来进行的。由于类型信息被擦除,JVM 是无法区分两个异常类型MyException<String>和MyException<Integer>的
三、当泛型内包含静态变量
public class StaticTest{
public static void main(String[] args){
GT<Integer> gti = new GT<Integer>();
gti.var=1;
GT<String> gts = new GT<String>();
gts.var=2;
System.out.println(gti.var);
}
}
class GT<T>{
public static int var=0;
public void nothing(T x){}
}
以上代码输出结果为:2!
由于经过类型擦除,所有的泛型类实例都关联到同一份字节码上,泛型类的所有静态变量是共享的。
自动装箱与拆箱
对象相等比较
public static void main(String[] args) {
Integer a = 1000;
Integer b = 1000;
Integer c = 100;
Integer d = 100;
System.out.println("a == b is " + (a == b));
System.out.println(("c == d is " + (c == d)));
}
输出结果:
a == b is false
c == d is true
在 Java 5 中,在 Integer 的操作上引入了一个新功能来节省内存和提高性能。整型对象通过使用相同的对象引用实现了缓存和重用。
适用于整数值区间-128 至 +127。
只适用于自动装箱。使用构造函数创建对象不适用。
增强 for 循环(经常遇到!)
for (Student stu : students) {
if (stu.getId() == 2)
students.remove(stu);
}
会抛出ConcurrentModificationException异常。
Iterator 是工作在一个独立的线程中,并且拥有一个 mutex 锁。 Iterator 被创建之后会建立一个指向原来对象的单链索引表,当原来的对象数量发生变化时,这个索引表的内容不会同步改变,所以当索引指针往后移动的时候就找不到要迭代的对象,所以按照 fail-fast 原则 Iterator 会马上抛出java.util.ConcurrentModificationException异常。
所以 Iterator 在工作的时候是不允许被迭代的对象被改变的。但你可以使用 Iterator 本身的方法remove()来删除对象,Iterator.remove() 方法会在删除当前迭代对象的同时维护索引的一致性。
集合
集合概述
Java 集合概览
Java 集合, 也叫作容器,主要是由两大接口派生而来:一个是 Collection接口,主要用于存放单一元素;另一个是 Map 接口,主要用于存放键值对。对于Collection 接口,下面又有三个主要的子接口:List、Set 和 Queue。
Java 集合框架如下图所示:
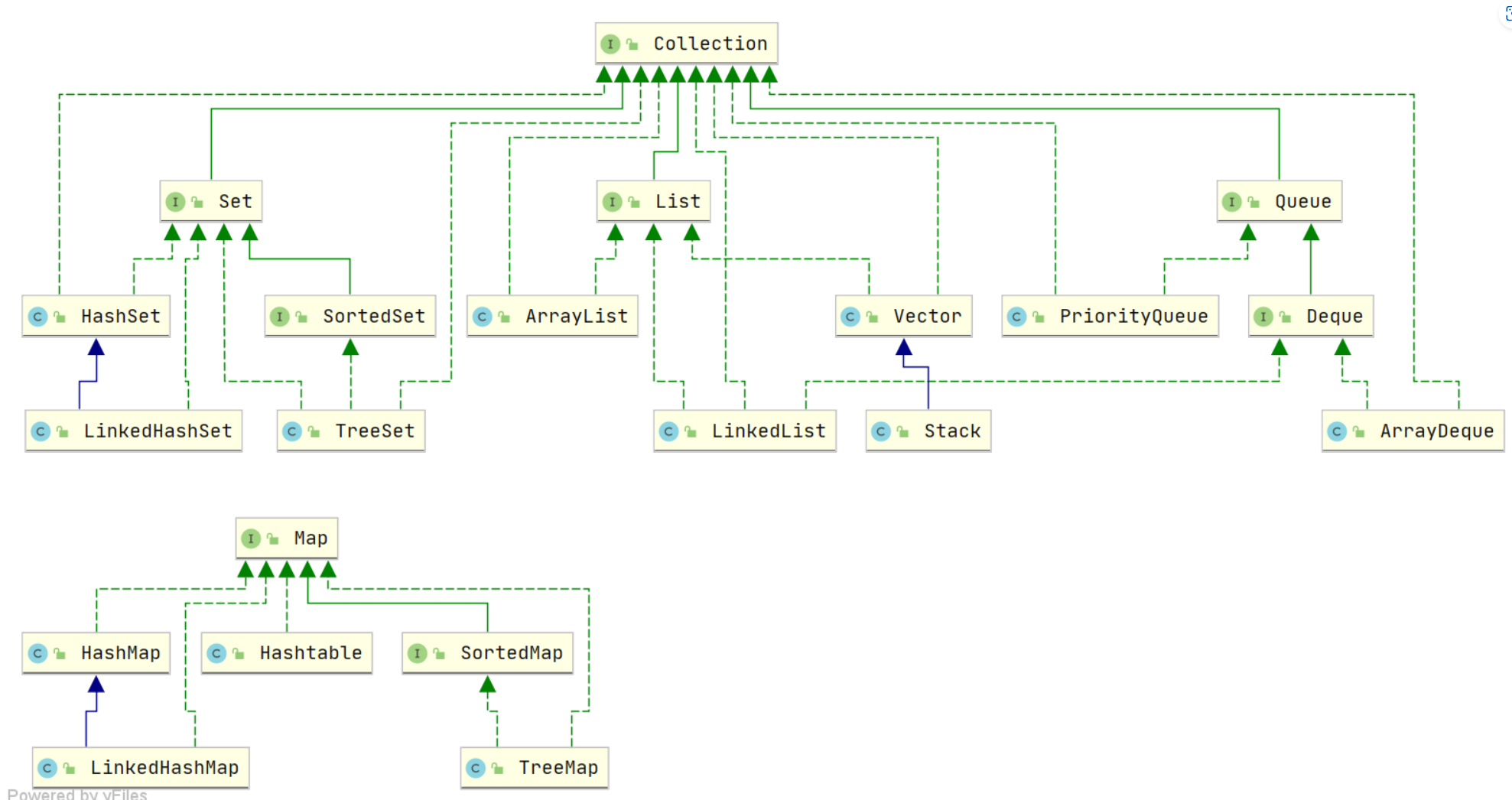
注:图中只列举了主要的继承派生关系,并没有列举所有关系。比方省略了AbstractList, NavigableSet等抽象类以及其他的一些辅助类,如想深入了解,可自行查看源码。
说说 List, Set, Queue, Map 四者的区别?
List(对付顺序的好帮手): 存储的元素是有序的、可重复的。Set(注重独一无二的性质): 存储的元素是无序的、不可重复的。Queue(实现排队功能的叫号机): 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。Map(用 key 来搜索的专家): 使用键值对(key-value)存储,类似于数学上的函数 y=f(x),"x" 代表 key,"y" 代表 value,key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值
集合框架底层数据结构总结
先来看一下 Collection 接口下面的集合List。
List
ArrayList:Object[]数组Vector:Object[]数组LinkedList: 双向链表(JDK1.6 之前为循环链表,JDK1.7 取消了循环)
Set
HashSet(无序,唯一): 基于HashMap实现的,底层采用HashMap来保存元素LinkedHashSet:LinkedHashSet是HashSet的子类,并且其内部是通过LinkedHashMap来实现的。有点类似于我们之前说的LinkedHashMap其内部是基于HashMap实现一样,不过还是有一点点区别的TreeSet(有序,唯一): 红黑树(自平衡的排序二叉树)
Queue
PriorityQueue:Object[]数组来实现二叉堆ArrayQueue:Object[]数组 + 双指针
再来看看 Map 接口下面的集合。
Map
HashMap: JDK1.8 之前HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。LinkedHashMap:LinkedHashMap继承自HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。详细可以查看:《LinkedHashMap 源码详细分析(JDK1.8)》Hashtable: 数组+链表组成的,数组是Hashtable的主体,链表则是主要为了解决哈希冲突而存在的TreeMap: 红黑树(自平衡的排序二叉树)
如何选用集合?
主要根据集合的特点来选用,比如我们需要根据键值获取到元素值时就选用 Map 接口下的集合,需要排序时选择 TreeMap,不需要排序时就选择 HashMap,需要保证线程安全就选用 ConcurrentHashMap。
当我们只需要存放元素值时,就选择实现Collection 接口的集合,需要保证元素唯一时选择实现 Set 接口的集合比如 TreeSet 或 HashSet,不需要就选择实现 List 接口的比如 ArrayList 或 LinkedList,然后再根据实现这些接口的集合的特点来选用。
为什么要使用集合?
当我们需要保存一组类型相同的数据的时候,我们应该是用一个容器来保存,这个容器就是数组,但是,使用数组存储对象具有一定的弊端, 因为我们在实际开发中,存储的数据的类型是多种多样的,于是,就出现了“集合”,集合同样也是用来存储多个数据的。
数组的缺点是一旦声明之后,长度就不可变了;同时,声明数组时的数据类型也决定了该数组存储的数据的类型;而且,数组存储的数据是有序的、可重复的,特点单一。 但是集合提高了数据存储的灵活性,Java 集合不仅可以用来存储不同类型不同数量的对象,还可以保存具有映射关系的数据。
Collection 子接口之 List
ArrayList 和 Vector 的区别?
ArrayList是List的主要实现类,底层使用Object[ ]存储,适用于频繁的查找工作,线程不安全 ;Vector是List的古老实现类,底层使用Object[ ]存储,线程安全的。
ArrayList 与 LinkedList 区别?
- 是否保证线程安全:
ArrayList和LinkedList都是不同步的,也就是不保证线程安全; - 底层数据结构:
ArrayList底层使用的是Object数组;LinkedList底层使用的是 双向链表 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!) - 插入和删除是否受元素位置的影响:
ArrayList采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候,ArrayList会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。LinkedList采用链表存储,所以,如果是在头尾插入或者删除元素不受元素位置的影响(add(E e)、addFirst(E e)、addLast(E e)、removeFirst()、removeLast()),时间复杂度为 O(1),如果是要在指定位置i插入和删除元素的话(add(int index, E element),remove(Object o)), 时间复杂度为 O(n) ,因为需要先移动到指定位置再插入。
- 是否支持快速随机访问:
LinkedList不支持高效的随机元素访问,而ArrayList支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。 - 内存空间占用:
ArrayList的空间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
我们在项目中一般是不会使用到 LinkedList 的,需要用到 LinkedList 的场景几乎都可以使用 ArrayList 来代替,并且,性能通常会更好!就连 LinkedList 的作者约书亚 · 布洛克(Josh Bloch)自己都说从来不会使用 LinkedList 。
另外,不要下意识地认为 LinkedList 作为链表就最适合元素增删的场景。我在上面也说了,LinkedList 仅仅在头尾插入或者删除元素的时候时间复杂度近似 O(1),其他情况增删元素的时间复杂度都是 O(n) 。
补充内容:双向链表和双向循环链表
双向链表: 包含两个指针,一个 prev 指向前一个节点,一个 next 指向后一个节点。
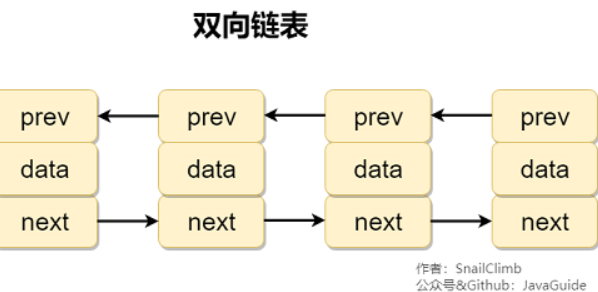
双向循环链表: 最后一个节点的 next 指向 head,而 head 的 prev 指向最后一个节点,构成一个环。
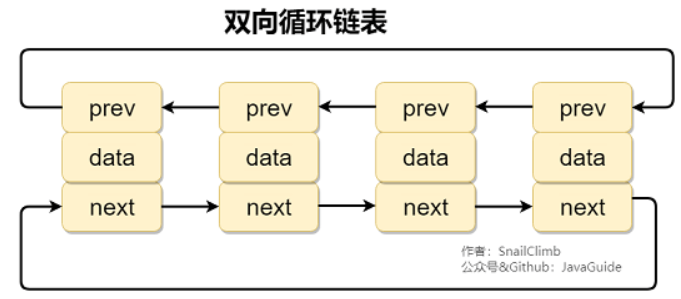
补充内容:RandomAccess 接口
public interface RandomAccess {
}
查看源码我们发现实际上 RandomAccess 接口中什么都没有定义。所以,在我看来 RandomAccess 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
在 binarySearch() 方法中,它要判断传入的 list 是否 RandomAccess 的实例,如果是,调用indexedBinarySearch()方法,如果不是并且list的大小大雨了5000(private static final int BINARYSEARCH_THRESHOLD = 5000;),那么调用iteratorBinarySearch()方法
public static <T> int binarySearch(List<? extends Comparable<? super T>> list, T key) {
if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
return Collections.indexedBinarySearch(list, key);
else
return Collections.iteratorBinarySearch(list, key);
}
ArrayList 实现了 RandomAccess 接口, 而 LinkedList 没有实现。为什么呢?我觉得还是和底层数据结构有关!ArrayList 底层是数组,而 LinkedList 底层是链表。数组天然支持随机访问,时间复杂度为 O(1),所以称为快速随机访问。链表需要遍历到特定位置才能访问特定位置的元素,时间复杂度为 O(n),所以不支持快速随机访问。,ArrayList 实现了 RandomAccess 接口,就表明了他具有快速随机访问功能。 RandomAccess 接口只是标识,并不是说 ArrayList 实现 RandomAccess 接口才具有快速随机访问功能的!
ArrayList扩容机制详情见之后的源码阅读
Collection 子接口之 Set
comparable 和 Comparator 的区别
comparable接口实际上是出自java.lang包 它有一个compareTo(Object obj)方法用来排序,一般用于在类声明时继承接口后重写compareTo(Object obj)方法,实现了comparable接口后,传入像TreeMap这种带有排序性质的集合后就会自动排好序的。comparator接口实际上是出自 java.util 包它有一个compare(Object obj1, Object obj2)方法用来排序,一般用于Collection.sort(List,new Comparator...{ 其中重写compare方法})。
一般我们需要对一个集合使用自定义排序时,我们就要重写compareTo()方法或compare()方法,当我们需要对某一个集合实现两种排序方式,比如一个 song 对象中的歌名和歌手名分别采用一种排序方法的话,我们可以重写compareTo()方法和使用自制的Comparator方法或者以两个 Comparator 来实现歌名排序和歌星名排序,第二种代表我们只能使用两个参数版的 Collections.sort().
Comparator 定制排序
ArrayList<Integer> arrayList = new ArrayList<Integer>();
arrayList.add(-1);
arrayList.add(3);
arrayList.add(3);
arrayList.add(-5);
arrayList.add(7);
arrayList.add(4);
arrayList.add(-9);
arrayList.add(-7);
System.out.println("原始数组:");
System.out.println(arrayList);
// void reverse(List list):反转
Collections.reverse(arrayList);
System.out.println("Collections.reverse(arrayList):");
System.out.println(arrayList);
// void sort(List list),按自然排序的升序排序
Collections.sort(arrayList);
System.out.println("Collections.sort(arrayList):");
System.out.println(arrayList);
// 定制排序的用法
Collections.sort(arrayList, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
});
System.out.println("定制排序后:");
System.out.println(arrayList);
Output:
原始数组:
[-1, 3, 3, -5, 7, 4, -9, -7]
Collections.reverse(arrayList):
[-7, -9, 4, 7, -5, 3, 3, -1]
Collections.sort(arrayList):
[-9, -7, -5, -1, 3, 3, 4, 7]
定制排序后:
[7, 4, 3, 3, -1, -5, -7, -9]
重写 compareTo 方法实现按年龄来排序
// person对象没有实现Comparable接口,所以必须实现,这样才不会出错,才可以使treemap中的数据按顺序排列
// 前面一个例子的String类已经默认实现了Comparable接口,详细可以查看String类的API文档,另外其他
// 像Integer类等都已经实现了Comparable接口,所以不需要另外实现了
public class Person implements Comparable<Person> {
private String name;
private int age;
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
/**
* T重写compareTo方法实现按年龄来排序
*/
@Override
public int compareTo(Person o) {
if (this.age > o.getAge()) {//年龄大的排到后面去
return 1;
}
if (this.age < o.getAge()) {
return -1;
}
return 0;
}
}
TreeMap根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序。
public static void main(String[] args) {
TreeMap<Person, String> pdata = new TreeMap<Person, String>();
pdata.put(new Person("张三", 30), "zhangsan");
pdata.put(new Person("李四", 20), "lisi");
pdata.put(new Person("王五", 10), "wangwu");
pdata.put(new Person("小红", 5), "xiaohong");
// 得到key的值的同时得到key所对应的值
Set<Person> keys = pdata.keySet();
for (Person key : keys) {
System.out.println(key.getAge() + "-" + key.getName());
}
}
Output:
5-小红
10-王五
20-李四
30-张三
无序性和不可重复性的含义是什么
- 无序性不等于随机性 ,无序性是指存储的数据在底层数组中并非按照数组索引的顺序添加 ,而是根据数据的哈希值决定的。
- 不可重复性是指添加的元素按照
equals()判断时 ,返回 false,需要同时重写equals()方法和hashCode()方法
比较 HashSet、LinkedHashSet 和 TreeSet 三者的异同
HashSet、LinkedHashSet和TreeSet都是Set接口的实现类,都能保证元素唯一,并且都不是线程安全的。HashSet、LinkedHashSet和TreeSet的主要区别在于底层数据结构不同。HashSet的底层数据结构是哈希表(基于HashMap实现)。LinkedHashSet的底层数据结构是链表和哈希表,元素的插入和取出顺序满足 FIFO。TreeSet底层数据结构是红黑树,元素是有序的,排序的方式有自然排序和定制排序。- 底层数据结构不同又导致这三者的应用场景不同。
HashSet用于不需要保证元素插入和取出顺序的场景,LinkedHashSet用于保证元素的插入和取出顺序满足 FIFO 的场景,TreeSet用于支持对元素自定义排序规则的场景。
Collection 子接口之 Queue
Queue 与 Deque 的区别
Queue 是单端队列,只能从一端插入元素,另一端删除元素,实现上一般遵循 先进先出(FIFO) 规则。
Queue 扩展了 Collection 的接口,根据 因为容量问题而导致操作失败后处理方式的不同 可以分为两类方法: 一种在操作失败后会抛出异常,另一种则会返回特殊值。
Queue 接口 |
抛出异常 | 返回特殊值 |
|---|---|---|
| 插入队尾 | add(E e) | offer(E e) |
| 删除队首 | remove() | poll() |
| 查询队首元素 | element() | peek() |
Deque 是双端队列,在队列的两端均可以插入或删除元素。Deque 扩展了 Queue 的接口, 增加了在队首和队尾进行插入和删除的方法,同样根据失败后处理方式的不同分为两类:
Deque 接口 |
抛出异常 | 返回特殊值 |
|---|---|---|
| 插入队首 | addFirst(E e) | offerFirst(E e) |
| 插入队尾 | addLast(E e) | offerLast(E e) |
| 删除队首 | removeFirst() | pollFirst() |
| 删除队尾 | removeLast() | pollLast() |
| 查询队首元素 | getFirst() | peekFirst() |
| 查询队尾元素 | getLast() | peekLast() |
事实上,Deque 还提供有 push() 和 pop() 等其他方法,可用于模拟栈。
ArrayDeque 与 LinkedList 的区别
ArrayDeque 和 LinkedList 都实现了 Deque 接口,两者都具有队列的功能,但两者有什么区别呢?
ArrayDeque是基于可变长的数组和双指针来实现,而LinkedList则通过链表来实现。ArrayDeque不支持存储NULL数据,但LinkedList支持。ArrayDeque是在 JDK1.6 才被引入的,而LinkedList早在 JDK1.2 时就已经存在。ArrayDeque插入时可能存在扩容过程, 不过均摊后的插入操作依然为 O(1)。虽然LinkedList不需要扩容,但是每次插入数据时均需要申请新的堆空间,均摊性能相比更慢。
从性能的角度上,选用 ArrayDeque 来实现队列要比 LinkedList 更好。此外,ArrayDeque 也可以用于实现栈。
说一说 PriorityQueue
PriorityQueue 是在 JDK1.5 中被引入的, 其与 Queue 的区别在于元素出队顺序是与优先级相关的,即总是优先级最高的元素先出队。
这里列举其相关的一些要点:
PriorityQueue利用了二叉堆的数据结构来实现的,底层使用可变长的数组来存储数据PriorityQueue通过堆元素的上浮和下沉,实现了在 O(logn) 的时间复杂度内插入元素和删除堆顶元素。PriorityQueue是非线程安全的,且不支持存储NULL和non-comparable的对象。PriorityQueue默认是小顶堆,但可以接收一个Comparator作为构造参数,从而来自定义元素优先级的先后。
PriorityQueue 在面试中可能更多的会出现在手撕算法的时候,典型例题包括堆排序、求第K大的数、带权图的遍历等,所以需要会熟练使用才行。
Map 接口
HashMap 和 Hashtable 的区别
- 线程是否安全:
HashMap是非线程安全的,Hashtable是线程安全的,因为Hashtable内部的方法基本都经过synchronized修饰。(如果你要保证线程安全的话就使用ConcurrentHashMap吧!); - 效率: 因为线程安全的问题,
HashMap要比Hashtable效率高一点。另外,Hashtable基本被淘汰,不要在代码中使用它; - 对 Null key 和 Null value 的支持:
HashMap可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个;Hashtable 不允许有 null 键和 null 值,否则会抛出NullPointerException。 - 初始容量大小和每次扩充容量大小的不同 : ① 创建时如果不指定容量初始值,
Hashtable默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。HashMap默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。② 创建时如果给定了容量初始值,那么Hashtable会直接使用你给定的大小,而HashMap会将其扩充为 2 的幂次方大小(HashMap中的tableSizeFor()方法保证,下面给出了源代码)。也就是说HashMap总是使用 2 的幂作为哈希表的大小,后面会介绍到为什么是 2 的幂次方。 - 底层数据结构: JDK1.8 以后的
HashMap在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间(后文中我会结合源码对这一过程进行分析)。Hashtable没有这样的机制。
HashMap 中带有初始容量的构造函数:
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
下面这个方法保证了 HashMap 总是使用 2 的幂作为哈希表的大小。
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
HashMap 和 HashSet 区别
如果你看过 HashSet 源码的话就应该知道:HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了 clone()、writeObject()、readObject()是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。
Java HashSet | 菜鸟教程 (runoob.com)
HashSet 基于 HashMap 来实现的,是一个不允许有重复元素的集合。HashSet 允许有 null 值。
HashSet 是无序的,即不会记录插入的顺序。HashSet 不是线程安全的, 如果多个线程尝试同时修改 HashSet,则最终结果是不确定的。 您必须在多线程访问时显式同步对 HashSet 的并发访问。HashSet 实现了 Set 接口。
HashMap |
HashSet |
|---|---|
实现了 Map 接口 |
实现 Set 接口 |
| 存储键值对 | 仅存储对象 |
调用 put()向 map 中添加元素 |
调用 add()方法向 Set 中添加元素 |
HashMap 使用键(Key)计算 hashcode |
HashSet 使用成员对象来计算 hashcode 值,对于两个对象来说 hashcode 可能相同,所以equals()方法用来判断对象的相等性 |
HashMap 和 TreeMap 区别
TreeMap 和HashMap 都继承自AbstractMap ,但是需要注意的是TreeMap它还实现了NavigableMap接口和SortedMap 接口。
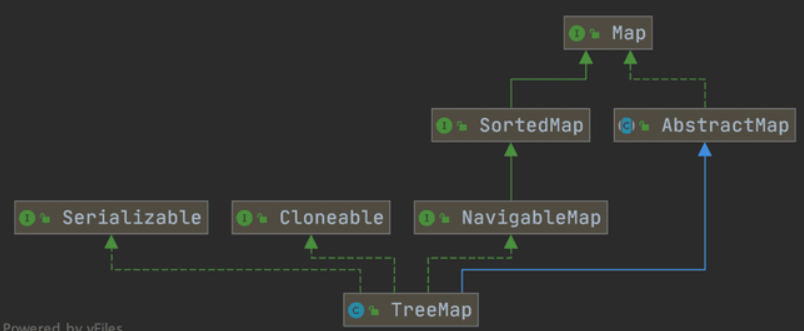
实现 NavigableMap 接口让 TreeMap 有了对集合内元素的搜索的能力。实现SortedMap接口让 TreeMap 有了对集合中的元素根据键排序的能力。默认是按 key 的升序排序,不过我们也可以指定排序的比较器。示例代码如下:
/**
* @author shuang.kou
* @createTime 2020年06月15日 17:02:00
*/
public class Person {
private Integer age;
public Person(Integer age) {this.age = age;}
public Integer getAge() {return age;}
public static void main(String[] args) {
TreeMap<Person, String> treeMap = new TreeMap<>(new Comparator<Person>() {
@Override
public int compare(Person person1, Person person2) {
int num = person1.getAge() - person2.getAge();
return Integer.compare(num, 0);
}
});
treeMap.put(new Person(3), "person1");
treeMap.put(new Person(18), "person2");
treeMap.put(new Person(35), "person3");
treeMap.put(new Person(16), "person4");
treeMap.entrySet().stream().forEach(personStringEntry -> {
System.out.println(personStringEntry.getValue());
});
}
}
输出:
person1
person4
person2
person3
可以看出,TreeMap 中的元素已经是按照 Person 的 age 字段的升序来排列了。上面,我们是通过传入匿名内部类的方式实现的,你可以将代码替换成 Lambda 表达式实现的方式:
TreeMap<Person, String> treeMap = new TreeMap<>((person1, person2) -> {
int num = person1.getAge() - person2.getAge();
return Integer.compare(num, 0);
});
综上,相比于HashMap来说 TreeMap 主要多了对集合中的元素根据键排序的能力以及对集合内元素的搜索的能力。
如何设计一个按照value排序的map?
直接上代码:
import java.util.HashMap;
import java.util.HashSet;
import java.util.Set;
import java.util.TreeMap;
public class ValueSortedMap<K,V extends Comparable<V>> extends HashMap<K,V> {
private static final long serialVersionUID = 1L;
private TreeMap<V, Set<K>> valueMap;
public ValueSortedMap(){
super();
valueMap = new TreeMap<>();
}
@Override
public V put(K key, V value) {
if(containsKey(key)){
//若存在
V oldValue = get(key);
if(oldValue.equals(value)){
return value;
}else{
Set<K> existedSet = valueMap.get(oldValue);
existedSet.remove(key);
if (existedSet.isEmpty()){
valueMap.remove(oldValue);
}
}
}
Set<K> set = valueMap.getOrDefault(value, new HashSet<>());
set.add(key);
valueMap.put(value,set);
return super.put(key,value);
}
public TreeMap<V, Set<K>> getValueMap() {
return valueMap;
}
}
用法:
public static void main(String[] args){
ValueSortedMap<String, Integer> map = new ValueSortedMap<>();
map.put("One", 1);
map.put("Three", 3);
map.put("Two", 2);
map.put("Three",0);
map.put("Three",-2);
map.put("Four",1);
System.out.println(map.get("Three"));
TreeMap<Integer, Set<String>> valueKeyMap = map.getValueKeyMap();
for (Map.Entry<Integer, Set<String>> entry : valueKeyMap.entrySet()) {
Integer value = entry.getKey();
Set<String> keys = entry.getValue();//取的是set;因为同一个value可以有多个key存在。
for (String key : keys) {
System.out.println("Key: " + key + ", Value: " + value);
}
}
}
遍历的时候通过 NavigableMap<Integer, Set<String>> valueKeyMap = map.getValueKeyMap();中的entrySet()进行遍历。其实就是在TreeMap的基础上再加一个用value作为键,Set作为值的TreeMap内部对象,该对象的值Set是value=键的key的集合。因为TreeMap默认是按照键排序的。
HashSet 如何检查重复?
以下内容摘自JavaGuide的 Java 启蒙书《Head first java》第二版:
当你把对象加入
HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。
在 JDK1.8 中,HashSet的add()方法只是简单的调用了HashMap的put()方法,并且判断了一下返回值以确保是否有重复元素。直接看一下HashSet中的源码:
// Returns: true if this set did not already contain the specified element
// 返回值:当 set 中没有包含 add 的元素时返回真
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
而在HashMap的putVal()方法中也能看到如下说明:
// Returns : previous value, or null if none
// 返回值:如果插入位置没有元素返回null,否则返回上一个元素
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
...
}
也就是说,在 JDK1.8 中,实际上无论HashSet中是否已经存在了某元素,HashSet都会直接插入,只是会在add()方法的返回值处告诉我们插入前是否存在相同元素。因为本质上调用的是map.put(e, PRESENT),key是e,value是PRESENT,如果键e存在的话,map做的也只是覆盖而已,如果不存在的话,则会用链表or红黑树来存储hashCode冲突的对象。
HashMap 的底层实现
JDK1.8 之前
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的 hashcode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
那么它是如何解决冲突的呢?即key值不同的两个或多个Map.Entry<K,V>可能会插在同一个桶下面,但是当查找到某个特定的hash值的时候,下面挂了很多个<K,V>映射,怎么确定哪个是我要找的那个<K,V>呢?这就是HashMap底层结构的一个亮点,在它的Entry中不仅仅只是插入value的,他是插入整个Entry 的,里面包含key和value的,所以能识别同一个hash值下的不同Map.Entry。
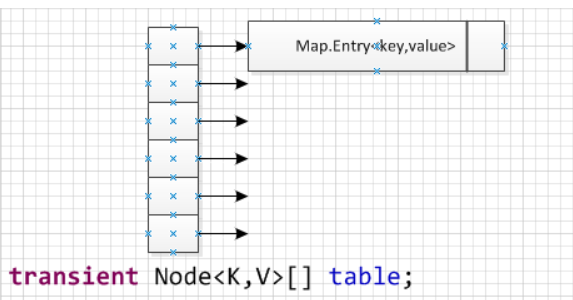
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
JDK 1.8 HashMap 的 hash 方法源码:JDK 1.8 的 hash 方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^ :按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
对比一下 JDK1.7 的 HashMap 的 hash 方法源码.
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
所谓 “拉链法” 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
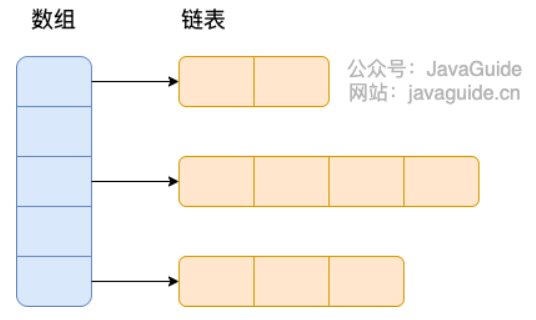
JDK1.8 之后
相比于之前的版本, JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。有关红黑树的介绍可以参考图解:什么是红黑树? - 知乎 (zhihu.com) 和 (112条消息) 红黑树详解_晓之木初的博客-CSDN博客_红黑树
从源码角度考虑就是,链表长度大于8时,会调用treeifyBin函数,然后在treeifyBin函数内部会判断数组长度是否小于64,如果小于64则会调用resize()进行数组扩容,扩容成原来的2倍。
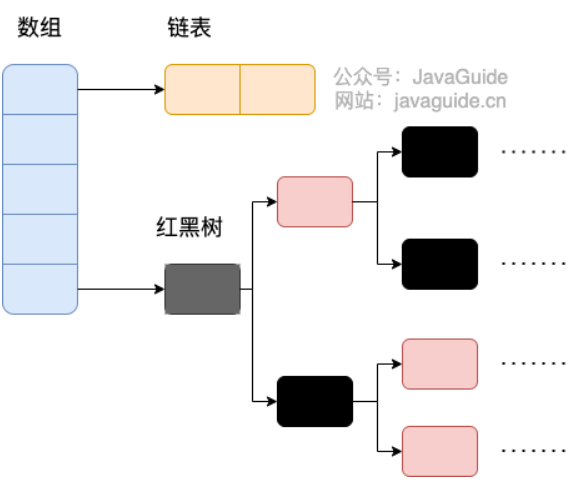
TreeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
我们来结合源码分析一下 HashMap 链表到红黑树的转换。
1、 putVal 方法中执行链表转红黑树的判断逻辑。
链表的长度大于 8 的时候,就执行 treeifyBin (转换红黑树)的逻辑。
// 遍历链表
for (int binCount = 0; ; ++binCount) {
// 遍历到链表最后一个节点
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果链表元素个数大于等于TREEIFY_THRESHOLD(8)
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// 红黑树转换(并不会直接转换成红黑树)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
2、treeifyBin 方法中判断是否真的转换为红黑树。
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// 判断当前数组的长度是否小于 64
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
// 如果当前数组的长度小于 64,那么会选择先进行数组扩容
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
// 否则才将列表转换为红黑树
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树。
HashMap 的长度为什么是 2 的幂次方
为了能让 HashMap 存取高效,尽量减少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648 到 2147483647,前后加起来大概 40 亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个 40 亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ (n - 1) & hash”。(n 代表数组长度)。这也就解释了 HashMap 的长度为什么是 2 的幂次方。
这个算法应该如何设计呢?
我们首先可能会想到采用%取余的操作来实现。但是,重点来了:“取余(%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是 2 的 n 次方;)。” 并且 采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方。
HashMap 多线程操作导致死循环问题
主要原因在于并发下的 Rehash 会造成元素之间会形成一个循环链表。不过,jdk 1.8 后解决了这个问题,但是还是不建议在多线程下使用 HashMap,因为多线程下使用 HashMap 还是会存在其他问题比如数据丢失。并发环境下推荐使用 ConcurrentHashMap 。
HashMap通常会用一个指针数组(假设为table[])来做分散所有的key,当一个key被加入时,会通过Hash算法通过key算出这个数组的下标i,然后就把这个<key, value>插到table[i]中,如果有两个不同的key被算在了同一个i,那么就叫冲突,又叫碰撞,这样会在table[i]上形成一个链表。我们知道,如果table[]的尺寸很小,比如只有2个,如果要放进10个keys的话,那么碰撞非常频繁,于是一个O(1)的查找算法,就变成了链表遍历,性能变成了O(n),这是Hash表的缺陷
所以,Hash表的尺寸和容量非常的重要。一般来说,Hash表这个容器当有数据要插入时,都会检查容量有没有超过设定的thredhold,如果超过,需要增大Hash表的尺寸,但是这样一来,整个Hash表里的无素都需要被重算一遍(因为要对Hash表中的数组的长度取余)。这叫rehash,这个成本相当的大。
HashMap的rehash源代码
下面,我们来看一下Java的HashMap的源代码。
Put一个Key,Value对到Hash表中:
public V put(K key, V value)
{
......
//算Hash值
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//如果该key已被插入,则替换掉旧的value (链接操作)
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//该key不存在,需要增加一个结点
addEntry(hash, key, value, i);
return null;
}
检查容量是否超标
void addEntry(int hash, K key, V value, int bucketIndex)
{
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//查看当前的size是否超过了我们设定的阈值threshold,如果超过,需要resize
if (size++ >= threshold)
resize(2 * table.length);
}
新建一个更大尺寸的hash表,然后把数据从老的Hash表中迁移到新的Hash表中。
void resize(int newCapacity)
{
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
......
//创建一个新的Hash Table
Entry[] newTable = new Entry[newCapacity];
//将Old Hash Table上的数据迁移到New Hash Table上
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
迁移的源代码,注意高亮处:
正常的ReHash的过程
画了个图做了个演示。
-
我假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度,进行取余操作)。
-
最上面的是old hash 表,其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以后都冲突在table[1]这里了。
-
接下来的三个步骤是Hash表 resize成4,然后所有的<key,value> 重新rehash的过程
并发下的Rehash
1)假设我们有两个线程。我用红色和浅蓝色标注了一下
我们再回头看一下我们的 transfer代码中的这个细节:
do {
Entry<K,V> next = e.next; // <--假设线程一执行到这里就被调度挂起了
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
而我们的线程二执行完成了。于是我们有下面的这个样子。
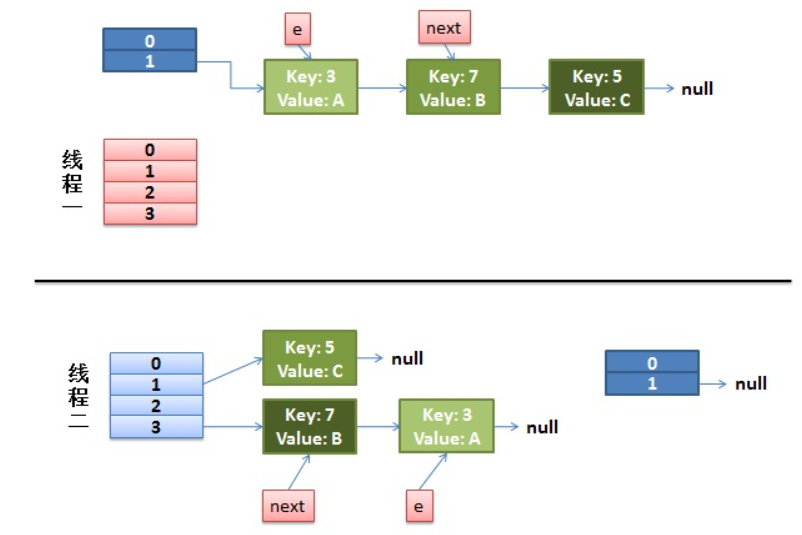
注意,因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转后。
2)线程一被调度回来执行。
- 先是执行 newTalbe[i] = e;
- 然后是e = next,导致了e指向了key(7),
- 而下一次循环的next = e.next导致了next指向了key(3)
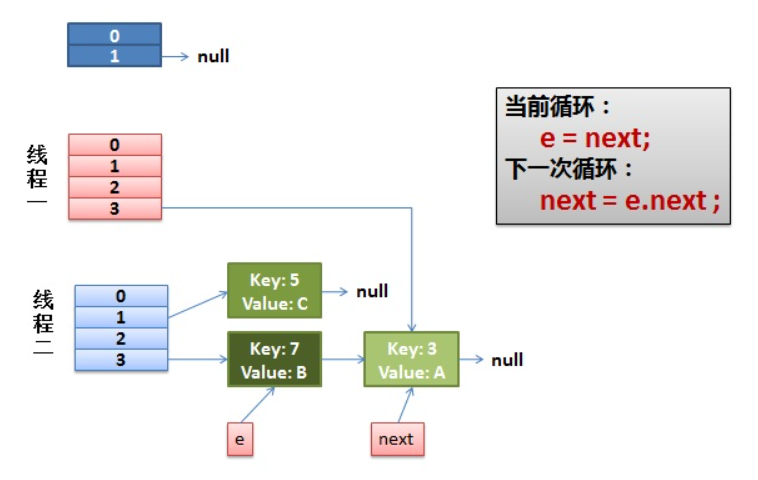
3)一切安好。
线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。
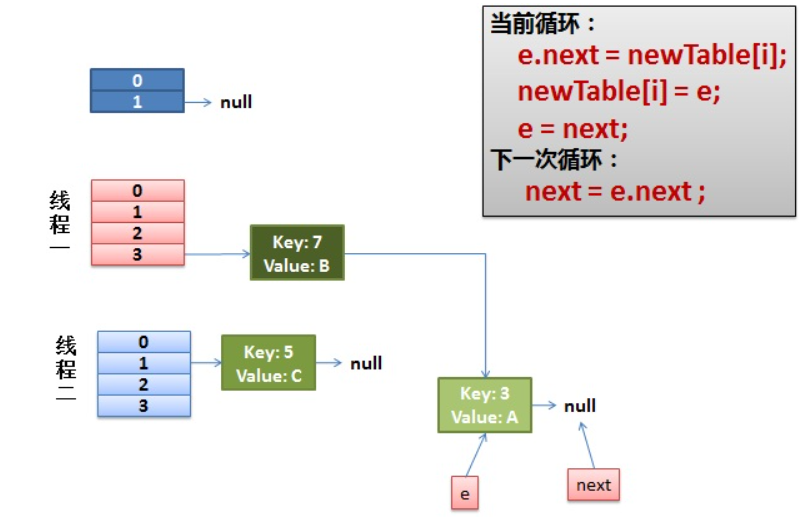
4)环形链接出现。
e.next = newTable[i] 导致 key(3).next 指向了 key(7)
注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
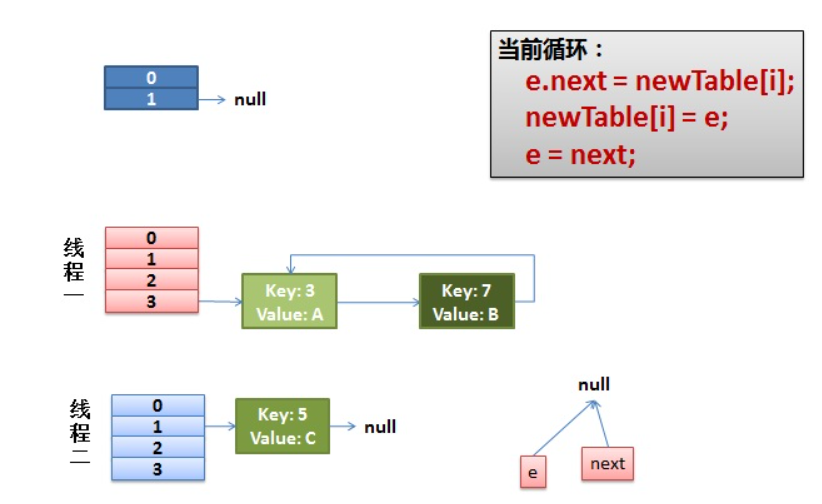
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
HashMap 有哪几种常见的遍历方式?
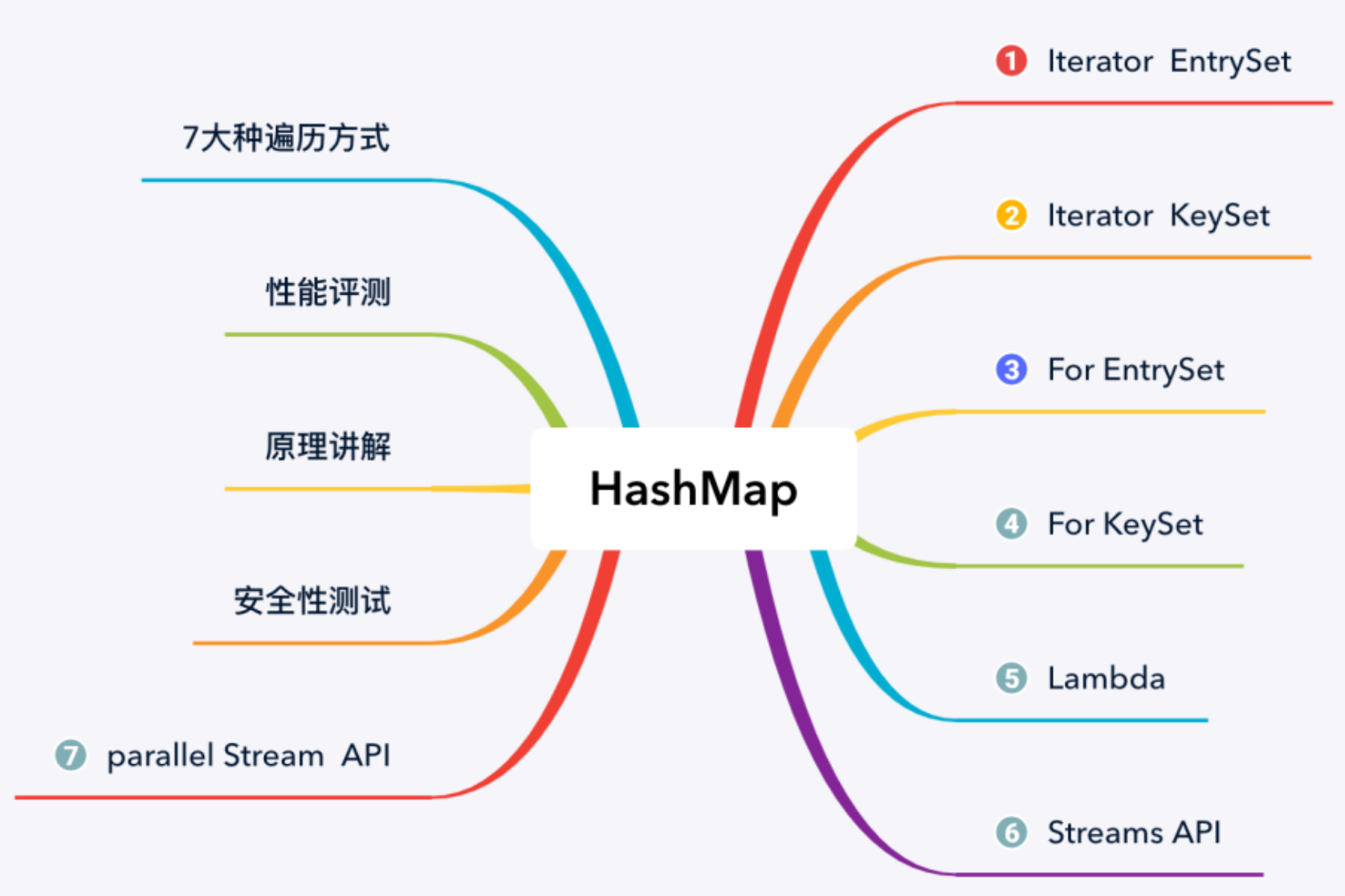
HashMap 遍历从大的方向来说,可分为以下 4 类:
- 迭代器(Iterator)方式遍历;
- For Each 方式遍历;
- Lambda 表达式遍历(JDK 1.8+);
- Streams API 遍历(JDK 1.8+)。
但每种类型下又有不同的实现方式,因此具体的遍历方式又可以分为以下 7 种:
- 使用迭代器(Iterator)EntrySet 的方式进行遍历;
- 使用迭代器(Iterator)KeySet 的方式进行遍历;
- 使用 For Each EntrySet 的方式进行遍历;
- 使用 For Each KeySet 的方式进行遍历;
- 使用 Lambda 表达式的方式进行遍历;
- 使用 Streams API 单线程的方式进行遍历;
- 使用 Streams API 多线程的方式进行遍历。
接下来我们来看每种遍历方式的具体实现代码。
迭代器方式遍历
1.迭代器 EntrySet
public class HashMapTest {
public static void main(String[] args) {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Java中文社群");
// 遍历
Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
}
}
2.迭代器 KeySet
public class HashMapTest {
public static void main(String[] args) {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Java中文社群");
// 遍历
Iterator<Integer> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
Integer key = iterator.next();
System.out.println(key);
System.out.println(map.get(key));
}
}
}
For Each方式遍历
3.ForEach EntrySet
本质上和迭代器方法1是类似的。
public class HashMapTest {
public static void main(String[] args) {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Java中文社群");
// 遍历
for (Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
}
}
}
4.ForEach KeySet
本质上和迭代器方法2是类似的。
public class HashMapTest {
public static void main(String[] args) {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Java中文社群");
// 遍历
for (Integer key : map.keySet()) {
System.out.println(key);
System.out.println(map.get(key));
}
}
}
5.Lambda表达式遍历
jdk1.8及以上才支持。
public class HashMapTest {
public static void main(String[] args) {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Java中文社群");
// 遍历
map.forEach((key, value) -> {
System.out.println(key);
System.out.println(value);
});
}
}
6.Streams API 单线程
public class HashMapTest {
public static void main(String[] args) {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Java中文社群");
// 遍历
map.entrySet().stream().forEach((entry) -> {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
});
}
}
7.Streams API 多线程
public class HashMapTest {
public static void main(String[] args) {
// 创建并赋值 HashMap
Map<Integer, String> map = new HashMap();
map.put(1, "Java");
map.put(2, "JDK");
map.put(3, "Spring Framework");
map.put(4, "MyBatis framework");
map.put(5, "Java中文社群");
// 遍历
map.entrySet().parallelStream().forEach((entry) -> {
System.out.println(entry.getKey());
System.out.println(entry.getValue());
});
}
}
性能分析
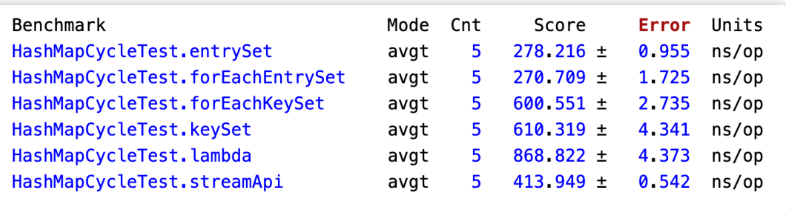
其中 Units 为 ns/op 意思是执行完成时间(单位为纳秒),而 Score 列为平均执行时间, ± 符号表示误差。从以上结果可以看出,两个 entrySet 的性能相近,并且执行速度最快,接下来是 stream ,然后是两个 keySet,性能最差的是 KeySet 。
结论:从以上结果可以看出 entrySet 的性能比 keySet 的性能高出了一倍之多,因此我们应该尽量使用 entrySet 来实现 Map 集合的遍历。
字节码分析
要理解以上的测试结果,我们需要把所有遍历代码通过 javac 编译成字节码来看具体的原因。
编译后,我们使用 Idea 打开字节码,内容如下:
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
package com.example;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Map.Entry;
public class HashMapTest {
static Map<Integer, String> map = new HashMap() {
{
for(int var1 = 0; var1 < 2; ++var1) {
this.put(var1, "val:" + var1);
}
}
};
public HashMapTest() {
}
public static void main(String[] var0) {
entrySet();
keySet();
forEachEntrySet();
forEachKeySet();
lambda();
streamApi();
parallelStreamApi();
}
public static void entrySet() {
Iterator var0 = map.entrySet().iterator();
while(var0.hasNext()) {
Entry var1 = (Entry)var0.next();
System.out.println(var1.getKey());
System.out.println((String)var1.getValue());
}
}
public static void keySet() {
Iterator var0 = map.keySet().iterator();
while(var0.hasNext()) {
Integer var1 = (Integer)var0.next();
System.out.println(var1);
System.out.println((String)map.get(var1));
}
}
public static void forEachEntrySet() {//与entrySet()是一致的
Iterator var0 = map.entrySet().iterator();
while(var0.hasNext()) {
Entry var1 = (Entry)var0.next();
System.out.println(var1.getKey());
System.out.println((String)var1.getValue());
}
}
public static void forEachKeySet() {//与keySet()是一致的
Iterator var0 = map.keySet().iterator();
while(var0.hasNext()) {
Integer var1 = (Integer)var0.next();
System.out.println(var1);
System.out.println((String)map.get(var1));
}
}
public static void lambda() {
map.forEach((var0, var1) -> {
System.out.println(var0);
System.out.println(var1);
});
}
public static void streamApi() {
map.entrySet().stream().forEach((var0) -> {
System.out.println(var0.getKey());
System.out.println((String)var0.getValue());
});
}
public static void parallelStreamApi() {
map.entrySet().parallelStream().forEach((var0) -> {
System.out.println(var0.getKey());
System.out.println((String)var0.getValue());
});
}
}
从结果可以看出,除了 Lambda 和 Streams API 之外,通过迭代器循环和 for 循环的遍历的 EntrySet 最终生成的代码是一样的,他们都是在循环中创建了一个遍历对象 Entry 。所以我们在使用迭代器或是 for 循环 EntrySet 时,他们的性能都是相同的,因为他们最终生成的字节码基本都是一样的;同理 KeySet 的两种遍历方式也是类似的。
EntrySet 之所以比 KeySet 的性能高是因为,KeySet 在循环时使用了 map.get(key),而 map.get(key) 相当于又遍历了一遍 Map 集合去查询 key 所对应的值。为什么要用“又”这个词?那是因为在使用迭代器或者 for 循环时,其实已经遍历了一遍 Map 集合了,因此再使用 map.get(key) 查询时,相当于遍历了两遍。
而 EntrySet 只遍历了一遍 Map 集合,之后通过代码“Entry<Integer, String> entry = iterator.next()”把对象的 key 和 value 值都放入到了 Entry 对象中,因此再获取 key 和 value 值时就无需再遍历 Map 集合,只需要从 Entry 对象中取值就可以了。
所以,EntrySet 的性能比 KeySet 的性能高出了一倍,因为 KeySet 相当于循环了两遍 Map 集合,而 EntrySet 只循环了一遍。
安全性测试
从上面的性能测试结果和原理分析,我想大家应该选用那种遍历方式,已经心中有数的,而接下来我们就从「安全」的角度入手,来分析那种遍历方式更安全。我们把以上遍历划分为四类进行测试:迭代器方式、For 循环方式、Lambda 方式和 Stream 方式,测试代码如下。
1.迭代器方式
Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
if (entry.getKey() == 1) {
// 删除
System.out.println("del:" + entry.getKey());
iterator.remove();
} else {
System.out.println("show:" + entry.getKey());
}
}
以上程序的执行结果:
show:0
del:1
show:2
测试结果:迭代器中循环删除数据安全。
2.For 循环方式
for (Map.Entry<Integer, String> entry : map.entrySet()) {
if (entry.getKey() == 1) {
// 删除
System.out.println("del:" + entry.getKey());
map.remove(entry.getKey());
} else {
System.out.println("show:" + entry.getKey());
}
}
以上程序的执行结果:
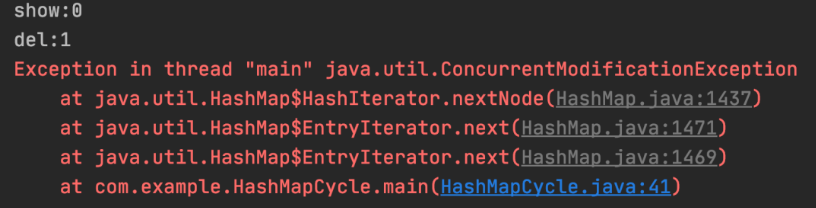
测试结果:For 循环中删除数据非安全。
3.Lambda 方式
map.forEach((key, value) -> {
if (key == 1) {
System.out.println("del:" + key);
map.remove(key);
} else {
System.out.println("show:" + key);
}
});
以上程序的执行结果:
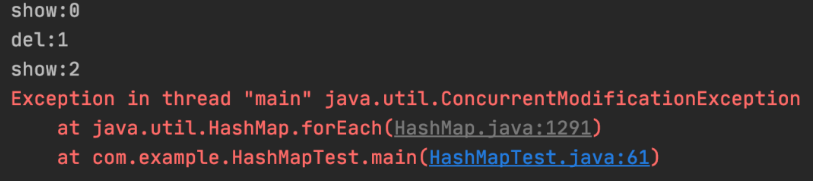
测试结果:Lambda 循环中删除数据非安全。
Lambda 删除的正确方式:
map.keySet().removeIf(key -> key == 1);
map.forEach((key, value) -> {
System.out.println("show:" + key);
});
以上程序的执行结果为:
show:0
show:2
从上面的代码可以看出,可以先使用 Lambda 的 removeIf 删除多余的数据,再进行循环是一种正确操作集合的方式。
4.Stream 方式
map.entrySet().stream().forEach((entry) -> {
if (entry.getKey() == 1) {
System.out.println("del:" + entry.getKey());
map.remove(entry.getKey());
} else {
System.out.println("show:" + entry.getKey());
}
});
执行结果:
测试结果:Stream 循环中删除数据非安全。
Stream 循环的正确方式:
map.entrySet().stream().filter(m -> 1 != m.getKey()).forEach((entry) -> {
if (entry.getKey() == 1) {
System.out.println("del:" + entry.getKey());
} else {
System.out.println("show:" + entry.getKey());
}
});
以上程序的执行结果:
show:0
show:2
从上面的代码可以看出,可以使用 Stream 中的 filter 过滤掉无用的数据,再进行遍历也是一种安全的操作集合的方式。但是这也并没有删除元素。
小结
我们不能在遍历中使用集合 map.remove() 来删除数据,这是非安全的操作方式,但我们可以使用迭代器的 iterator.remove() 的方法来删除数据,这是安全的删除集合的方式。同样的我们也可以使用 Lambda 中的 removeIf 来提前删除数据,或者是使用 Stream 中的 filter 过滤掉(但是并没有实际上删除)要删除的数据进行循环,这样都是安全的,当然我们也可以在 for 循环前删除数据在遍历也是线程安全的。
总结
我们讲了 HashMap 4 种遍历方式:迭代器、for、lambda、stream,以及具体的 7 种遍历方法,综合性能和安全性来看,我们应该尽量使用迭代器(Iterator)来遍历 EntrySet 的遍历方式来操作 Map 集合,这样就会既安全又高效了。
ConcurrentHashMap 和 Hashtable 的区别
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
- 底层数据结构: JDK1.7 的
ConcurrentHashMap底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable和 JDK1.8 之前的HashMap的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的; - 实现线程安全的方式(重要):
- 在 JDK1.7 的时候,
ConcurrentHashMap对整个桶数组进行了分割分段(Segment,分段锁),每一把锁只锁容器其中一部分数据(下面有示意图),多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 - 到了 JDK1.8 的时候,
ConcurrentHashMap已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用synchronized和 CAS 来操作。(JDK1.6 以后synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的HashMap,虽然在 JDK1.8 中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本; Hashtable(同一把锁) :使用synchronized来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
- 在 JDK1.7 的时候,
下面,我们再来看看两者底层数据结构的对比图。
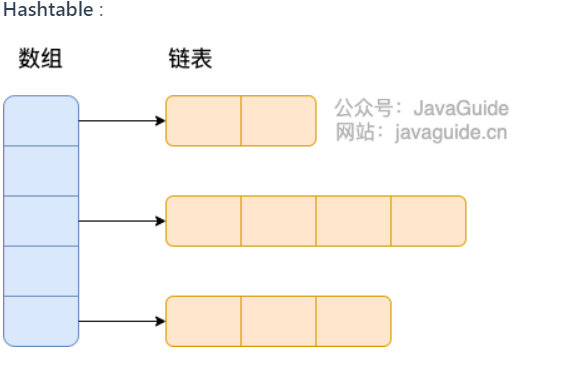
JDK1.7 的 ConcurrentHashMap :
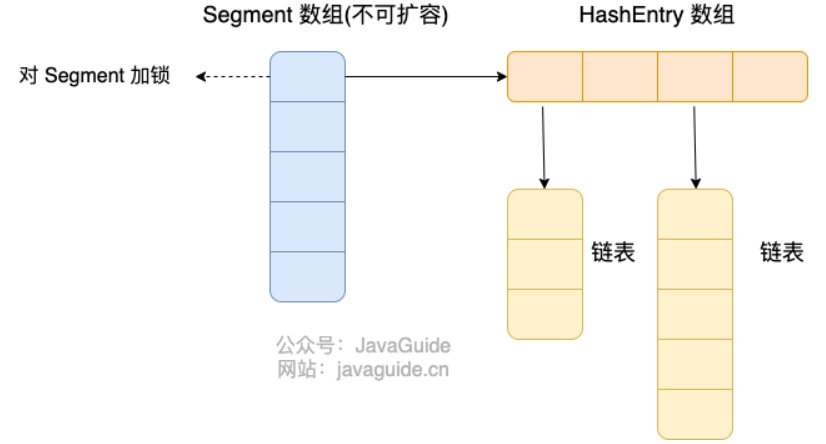
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。Segment 数组中的每个元素包含一个 HashEntry 数组,每个 HashEntry 数组属于链表结构。
JDK1.8 的 ConcurrentHashMap :
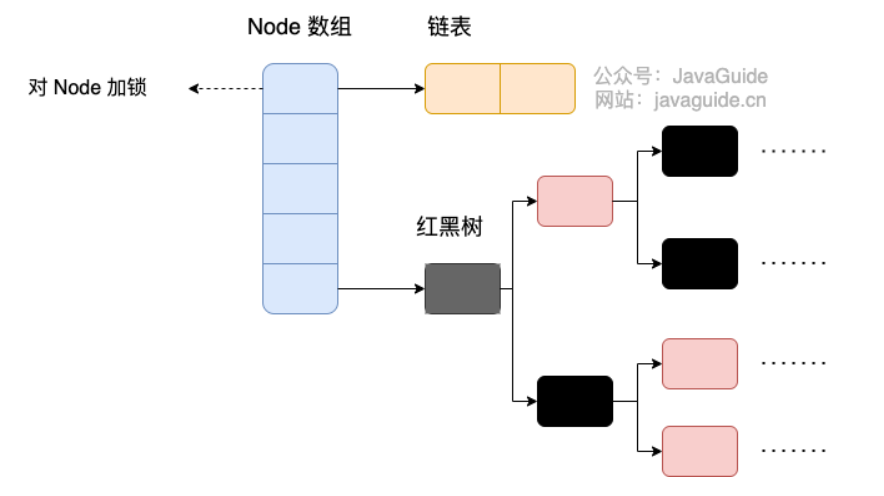
JDK1.8 的 ConcurrentHashMap 不再是 Segment 数组 + HashEntry 数组 + 链表,而是 Node 数组 + 链表 / 红黑树。不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode。当冲突链表达到一定长度时,链表会转换成红黑树。
TreeNode是存储红黑树节点,被TreeBin包装。TreeBin通过root属性维护红黑树的根结点,因为红黑树在旋转的时候,根结点可能会被它原来的子节点替换掉,在这个时间点,如果有其他线程要写这棵红黑树就会发生线程不安全问题,所以在 ConcurrentHashMap 中TreeBin通过waiter属性维护当前使用这棵红黑树的线程,来防止其他线程的进入。
static final class TreeBin<K,V> extends Node<K,V> {
TreeNode<K,V> root;
volatile TreeNode<K,V> first;
volatile Thread waiter;
volatile int lockState;
// values for lockState
static final int WRITER = 1; // set while holding write lock
static final int WAITER = 2; // set when waiting for write lock
static final int READER = 4; // increment value for setting read lock
...
}
ConcurrentHashMap 线程安全的具体实现方式/底层具体实现
JDK1.8 之前
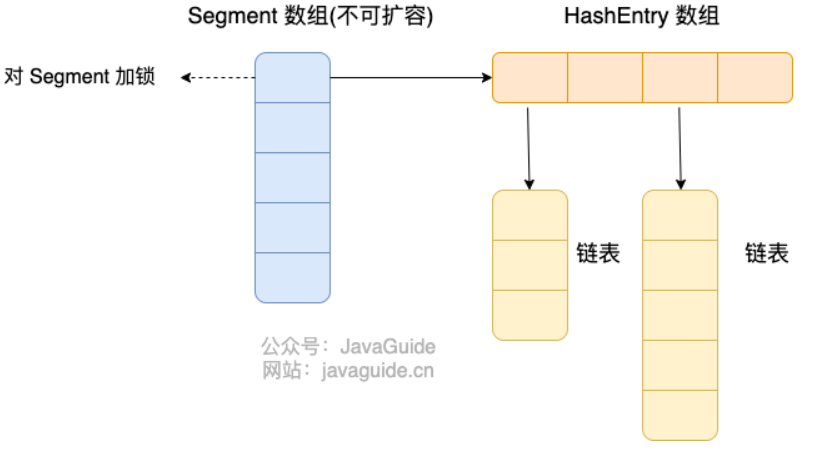
首先将数据分为一段一段(这个“段”就是 Segment)的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
Segment 继承了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据。
static class Segment<K,V> extends ReentrantLock implements Serializable {
}
一个 ConcurrentHashMap 里包含一个 Segment 数组,Segment 的个数一旦初始化就不能改变。 Segment 数组的大小默认是 16,也就是说默认可以同时支持 16 个线程并发写。
Segment 的结构和 HashMap 类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 的锁。也就是说,对同一 Segment 的并发写入会被阻塞,不同 Segment 的写入是可以并发执行的。
JDK1.8 之后
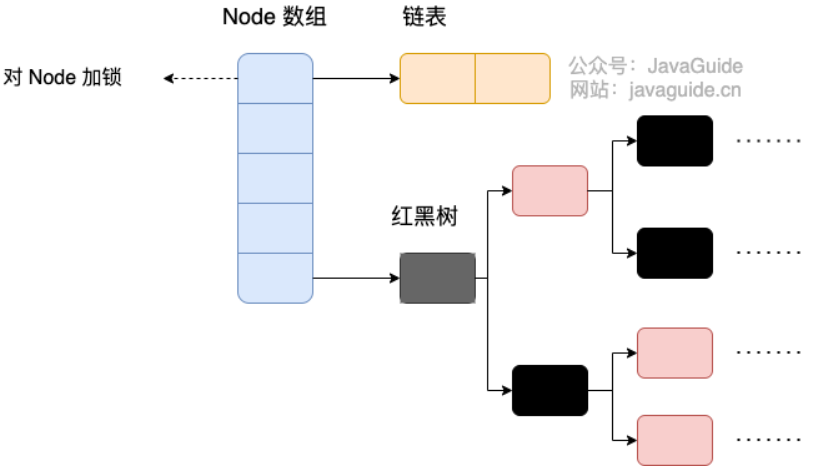
Java 8 几乎完全重写了 ConcurrentHashMap,代码量从原来 Java 7 中的 1000 多行,变成了现在的 6000 多行。
ConcurrentHashMap 取消了 Segment 分段锁,采用 Node + CAS + synchronized 来保证并发安全。数据结构跟 HashMap 1.8 的结构类似,数组+链表/红黑二叉树。Java 8 在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为 O(N))转换为红黑树(寻址时间复杂度为 O(log(N)))。
Node数组的结构,包含了hash信息。
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
Java 8 中,锁粒度更细,synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,就不会影响其他 Node 的读写,效率大幅提升。
JDK 1.7 和 JDK 1.8 的 ConcurrentHashMap 实现有什么不同?
- 线程安全实现方式 :JDK 1.7 采用
Segment分段锁来保证安全,Segment是继承自ReentrantLock。JDK1.8 放弃了Segment分段锁的设计,采用Node + CAS + synchronized保证线程安全,锁粒度更细,synchronized只锁定当前链表或红黑二叉树的首节点。 - Hash 碰撞解决方法 : JDK 1.7 采用拉链法,JDK1.8 采用拉链法结合红黑树(链表长度超过一定阈值时,将链表转换为红黑树)。
- 并发度 :JDK 1.7 最大并发度是 Segment 的个数,默认是 16。JDK 1.8 最大并发度是 Node 数组的大小,并发度更大。
Java集合使用注意事项总结
集合判空
《阿里巴巴 Java 开发手册》的描述如下:
判断所有集合内部的元素是否为空,使用
isEmpty()方法,而不是size()==0的方式。
这是因为 isEmpty() 方法的可读性更好,并且时间复杂度为 O(1)。
绝大部分我们使用的集合的 size() 方法的时间复杂度也是 O(1),不过,也有很多复杂度不是 O(1) 的,比如 java.util.concurrent 包下的某些集合(ConcurrentLinkedQueue 、ConcurrentHashMap...)。
下面是 ConcurrentHashMap 的 size() 方法和 isEmpty() 方法的源码。
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
public boolean isEmpty() {
return sumCount() <= 0L; // ignore transient negative values
}
集合转 Map
《阿里巴巴 Java 开发手册》的描述如下:
在使用
java.util.stream.Collectors类的toMap()方法转为Map集合时,一定要注意当 value 为 null 时会抛 NPE 异常。
class Person {
private String name;
private String phoneNumber;
// getters and setters
}
List<Person> bookList = new ArrayList<>();
bookList.add(new Person("jack","18163138123"));
bookList.add(new Person("martin",null));
// 空指针异常
bookList.stream().collect(Collectors.toMap(Person::getName, Person::getPhoneNumber));
下面我们来解释一下原因。
首先,我们来看 java.util.stream.Collectors 类的 toMap() 方法 ,可以看到其内部调用了 Map 接口的 merge() 方法。
public static <T, K, U, M extends Map<K, U>>
Collector<T, ?, M> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction,
Supplier<M> mapSupplier) {
BiConsumer<M, T> accumulator
= (map, element) -> map.merge(keyMapper.apply(element),
valueMapper.apply(element), mergeFunction);
return new CollectorImpl<>(mapSupplier, accumulator, mapMerger(mergeFunction), CH_ID);
}
Map 接口的 merge() 方法如下,这个方法是接口中的默认实现。
如果你还不了解 Java 8 新特性的话,请看这篇文章:《Java8 新特性总结》 。
default V merge(K key, V value,BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
Objects.requireNonNull(value);
V oldValue = get(key);
V newValue = (oldValue == null) ? value : remappingFunction.apply(oldValue, value);
if(newValue == null) {
remove(key);
} else {
put(key, newValue);
}
return newValue;
}
merge() 方法会先调用 Objects.requireNonNull() 方法判断 value 是否为空。
public static <T> T requireNonNull(T obj) {
if (obj == null)
throw new NullPointerException();
return obj;
}
集合遍历
《阿里巴巴 Java 开发手册》的描述如下:
不要在 foreach 循环里进行元素的
remove/add操作。remove 元素请使用Iterator方式,如果并发操作,需要对Iterator对象加锁。
通过反编译你会发现 foreach 语法底层其实还是依赖 Iterator 。不过, remove/add 操作直接调用的是集合自己的方法,而不是 Iterator 的 remove/add方法。这就导致 Iterator 莫名其妙地发现自己有元素被 remove/add ,然后,它就会抛出一个 ConcurrentModificationException 来提示用户发生了并发修改异常。这就是单线程状态下产生的 fail-fast 机制。
fail-fast 机制 :多个线程对 fail-fast 集合进行修改的时候,可能会抛出
ConcurrentModificationException。 即使是单线程下也有可能会出现这种情况,上面已经提到过。具体可以参考:(112条消息) fail-fast(快速失败)机制_-=Leessang=-的博客-CSDN博客_fail-fast机制
Java8 开始,可以使用 Collection#removeIf()方法删除满足特定条件的元素,如
List<Integer> list = new ArrayList<>();
for (int i = 1; i <= 10; ++i) {
list.add(i);
}
list.removeIf(filter -> filter % 2 == 0); /* 删除list中的所有偶数 */
System.out.println(list); /* [1, 3, 5, 7, 9] */
集合去重
《阿里巴巴 Java 开发手册》的描述如下:
可以利用
Set元素唯一的特性,可以快速对一个集合进行去重操作,避免使用List的contains()进行遍历去重或者判断包含操作。
这里我们以 HashSet 和 ArrayList 为例说明。
// Set 去重代码示例
public static <T> Set<T> removeDuplicateBySet(List<T> data) {
if (CollectionUtils.isEmpty(data)) {
return new HashSet<>();
}
return new HashSet<>(data);
}
// List 去重代码示例
public static <T> List<T> removeDuplicateByList(List<T> data) {
if (CollectionUtils.isEmpty(data)) {
return new ArrayList<>();
}
List<T> result = new ArrayList<>(data.size());
for (T current : data) {
if (!result.contains(current)) {
result.add(current);
}
}
return result;
}
两者的核心差别在于 contains() 方法的实现。HashSet 的 contains() 方法底部依赖的 HashMap 的 containsKey() 方法,时间复杂度接近于 O(1)(没有出现哈希冲突的时候为 O(1))。
private transient HashMap<E,Object> map;
public boolean contains(Object o) {
return map.containsKey(o);
}
我们有 N 个元素插入进 Set 中,那时间复杂度就接近是 O (n)。ArrayList 的 contains() 方法是通过遍历所有元素的方法来做的,时间复杂度接近是 O(n)。
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
我们的 List 有 N 个元素,那时间复杂度就接近是 O (n^2)。
集合转数组
《阿里巴巴 Java 开发手册》的描述如下:
使用集合转数组的方法,必须使用集合的
toArray(T[] array),传入的是类型完全一致、长度为 0 的空数组。
toArray(T[] array) 方法的参数是一个泛型数组,如果 toArray 方法中没有传递任何参数的话返回的是 Object类 型数组。
String [] s= new String[]{
"dog", "lazy", "a", "over", "jumps", "fox", "brown", "quick", "A"
};
List<String> list = Arrays.asList(s);
Collections.reverse(list);
//没有指定类型的话会报错
s=list.toArray(new String[0]);
由于 JVM 优化,new String[0]作为Collection.toArray()方法的参数现在使用更好,new String[0]就是起一个模板的作用,指定了返回数组的类型,0 是为了节省空间,因为它只是为了说明返回的类型。详见:https://shipilev.net/blog/2016/arrays-wisdom-ancients/
还可以参考[(112条消息) list.toArray(new String0])_ziJ~的博客-CSDN博客_new string[0]和[(112条消息) collection.toArray(new String0])中new String[0]的作用_小白要挣扎的博客-CSDN博客
数组转集合
《阿里巴巴 Java 开发手册》的描述如下:
使用工具类
Arrays.asList()把数组转换成集合时,不能使用其修改集合相关的方法, 它的add/remove/clear方法会抛出UnsupportedOperationException异常。
我在之前的一个项目中就遇到一个类似的坑。Arrays.asList()在平时开发中还是比较常见的,我们可以使用它将一个数组转换为一个 List 集合。
String[] myArray = {"Apple", "Banana", "Orange"};
List<String> myList = Arrays.asList(myArray);
//上面两个语句等价于下面一条语句
List<String> myList = Arrays.asList("Apple","Banana", "Orange");
JDK 源码对于这个方法的说明:
/**
*返回由指定数组支持的``固定大小``的列表。此方法作为基于数组和基于集合的API之间的桥梁,
* 与 Collection.toArray()结合使用。返回的List是可序列化并实现RandomAccess接口。
*/
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}
下面我们来总结一下使用注意事项。
1、Arrays.asList()是泛型方法,传递的数组必须是对象数组,而不是基本类型。
int[] myArray = {1, 2, 3};
List myList = Arrays.asList(myArray);
System.out.println(myList.size());//1
System.out.println(myList.get(0));//数组地址值
System.out.println(myList.get(1));//报错:ArrayIndexOutOfBoundsException
int[] array = (int[]) myList.get(0);
System.out.println(array[0]);//1
当传入一个原生数据类型数组时,Arrays.asList() 的真正得到的参数就不是数组中的元素,而是数组对象本身!此时 List 的唯一元素就是这个数组,这也就解释了上面的代码。
我们使用包装类型数组就可以解决这个问题。
Integer[] myArray = {1, 2, 3};
2、使用集合的修改方法: add()、remove()、clear()会抛出异常。
List myList = Arrays.asList(1, 2, 3);
myList.add(4);//运行时报错:UnsupportedOperationException
myList.remove(1);//运行时报错:UnsupportedOperationException
myList.clear();//运行时报错:UnsupportedOperationException
Arrays.asList() 方法返回的并不是 java.util.ArrayList ,而是 java.util.Arrays 的一个内部类,这个内部类并没有实现集合的修改方法或者说并没有重写这些方法。
List myList = Arrays.asList(1, 2, 3);
System.out.println(myList.getClass());//class java.util.Arrays$ArrayList
下面是 java.util.Arrays$ArrayList 的简易源码,我们可以看到这个类重写的方法有哪些。
private static class ArrayList<E> extends AbstractList<E> implements RandomAccess, java.io.Serializable
{
...
@Override
public E get(int index) {
...
}
@Override
public E set(int index, E element) {
...
}
@Override
public int indexOf(Object o) {
...
}
@Override
public boolean contains(Object o) {
...
}
@Override
public void forEach(Consumer<? super E> action) {
...
}
@Override
public void replaceAll(UnaryOperator<E> operator) {
...
}
@Override
public void sort(Comparator<? super E> c) {
...
}
}
我们再看一下java.util.AbstractList的 add/remove/clear 方法就知道为什么会抛出 UnsupportedOperationException 了。
public E remove(int index) {
throw new UnsupportedOperationException();
}
public boolean add(E e) {
add(size(), e);
return true;
}
public void add(int index, E element) {
throw new UnsupportedOperationException();
}
public void clear() {
removeRange(0, size());
}
protected void removeRange(int fromIndex, int toIndex) {
ListIterator<E> it = listIterator(fromIndex);
for (int i=0, n=toIndex-fromIndex; i<n; i++) {
it.next();
it.remove();
}
}
那我们如何正确的将数组转换为 ArrayList ?
1、手动实现工具类
//JDK1.5+
static <T> List<T> arrayToList(final T[] array) {
final List<T> l = new ArrayList<T>(array.length);
for (final T s : array) {
l.add(s);
}
return l;
}
Integer [] myArray = { 1, 2, 3 };
System.out.println(arrayToList(myArray).getClass());//class java.util.ArrayList
2、最简便的方法
List list = new ArrayList<>(Arrays.asList("a", "b", "c"))
3、使用 Java8 的 Stream(推荐)
Integer [] myArray = { 1, 2, 3 };
List myList = Arrays.stream(myArray).collect(Collectors.toList());
//基本类型也可以实现转换(依赖boxed的装箱操作)
int [] myArray2 = { 1, 2, 3 };
List myList = Arrays.stream(myArray2).boxed().collect(Collectors.toList());
4、使用 Guava
对于不可变集合,你可以使用ImmutableList类及其of()与copyOf()工厂方法:(参数不能为空)
List<String> il = ImmutableList.of("string", "elements"); // from varargs
List<String> il = ImmutableList.copyOf(aStringArray); // from array
对于可变集合,你可以使用Lists类及其newArrayList()工厂方法:
List<String> l1 = Lists.newArrayList(anotherListOrCollection); // from collection
List<String> l2 = Lists.newArrayList(aStringArray); // from array
List<String> l3 = Lists.newArrayList("or", "string", "elements"); // from varargs
5、使用 Apache Commons Collections
List<String> list = new ArrayList<String>();
CollectionUtils.addAll(list, str);
6、 使用 Java9 的 List.of()方法
Integer[] array = {1, 2, 3};
List<Integer> list = List.of(array);
源码分析
ArrayList源码&扩容机制分析
ArrayList 简介
ArrayList 的底层是数组队列,相当于动态数组。与 Java 中的数组相比,它的容量能动态增长。在添加大量元素前,应用程序可以使用ensureCapacity操作来增加 ArrayList 实例的容量。这可以减少递增式再分配的数量。
ArrayList继承于 AbstractList ,实现了 List, RandomAccess, Cloneable, java.io.Serializable 这些接口。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
}
RandomAccess是一个标志接口(因为RandomAccess接口里的内容为空,也就是没有需要实现的方法),表明实现这个这个接口的 List 集合是支持快速随机访问的。在ArrayList中,我们即可以通过元素的序号快速获取元素对象,这就是快速随机访问。ArrayList实现了Cloneable接口 ,即覆盖了函数clone(),能被克隆。ArrayList实现了java.io.Serializable接口,这意味着ArrayList支持序列化,能通过序列化去传输
Arraylist 和 Vector 的区别?
ArrayList是List的主要实现类,底层使用Object[ ]存储,适用于频繁的查找工作,线程不安全 ;Vector是List的古老实现类,底层使用Object[ ]存储,线程安全的。
Arraylist 与 LinkedList 区别?
- 是否保证线程安全:
ArrayList和LinkedList都是不同步的,也就是不保证线程安全; - 底层数据结构:
Arraylist底层使用的是Object数组;LinkedList底层使用的是 双向链表 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!) - 插入和删除是否受元素位置的影响: ①
ArrayList采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候,ArrayList会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ②LinkedList采用链表存储,所以对于add(E e)方法的插入,删除元素时间复杂度不受元素位置的影响,近似 O(1),如果是要在指定位置i插入和删除元素的话((add(int index, E element)) 时间复杂度近似为o(n))因为需要先移动到指定位置再插入。 - 是否支持快速随机访问:
LinkedList不支持高效的随机元素访问,而ArrayList支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。 - 内存空间占用:
ArrayList的空 间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
ArrayList的泛型知识
这是我在做亚信科技笔试题遇到的问题
List list1 = new ArrayList();
list1.add(0);
list1.add("123123");
list1.add(new Object());
System.out.println(list1.get(0) instanceof Integer);//true
System.out.println(list1.get(1) instanceof String);//true
System.out.println(list1.get(2) instanceof String);//false
我们知道ArrayList中使用的是Object数组,那么为什么instanceof都可以正确判断出类型呢?
instanceof关键字用于检查一个对象是否属于特定类或其子类的实例。在运行时,instanceof会检查对象的实际类型,而不仅仅是它的声明类型。这使得instanceof可以正确地识别出ArrayList中的实际对象类型。在给定的代码示例中,我们可以看到ArrayList中添加了三个不同类型的对象:一个Integer,一个String,和一个Object。虽然ArrayList使用的是Object数组来存储这些对象,但是在运行时,这些对象仍然保留了它们的实际类型。
在底层实现上,Object数组实际上存储的是对象引用(也就是指向实际对象的内存地址)。当您将某个对象(例如String对象)赋值给Object数组的一个元素时,实际上是将该对象的引用(内存地址)存储在数组中。
总之,在Java中,数组存储的是对象引用,而非实际对象。这使得您可以利用多态的特性在Object数组中存储不同类型的对象。在运行时,JVM会保留对象的实际类型,从而允许您执行类型检查和类型转换操作。
ArrayList 核心源码解读
其中modCount++代表的是ArrayList调整的次数。
package java.util;
import java.util.function.Consumer;
import java.util.function.Predicate;
import java.util.function.UnaryOperator;
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
/**
* 默认初始容量大小
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 空数组(用于空实例)。
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
//用于默认大小空实例的共享空数组实例。
//我们把它从EMPTY_ELEMENTDATA数组中区分出来,以知道在添加第一个元素时容量需要增加多少。
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* 保存ArrayList数据的数组
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* ArrayList 所包含的元素个数
*/
private int size;
/**
* 带初始容量参数的构造函数(用户可以在创建ArrayList对象时自己指定集合的初始大小)
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
//如果传入的参数大于0,创建initialCapacity大小的数组
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
//如果传入的参数等于0,创建空数组
this.elementData = EMPTY_ELEMENTDATA;
} else {
//其他情况,抛出异常
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
*默认无参构造函数
*DEFAULTCAPACITY_EMPTY_ELEMENTDATA 为0.初始化为10,也就是说初始其实是空数组 当添加第一个元素的时候数组容量才变成10
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* 构造一个包含指定集合的元素的列表,按照它们由集合的迭代器返回的顺序。
*/
public ArrayList(Collection<? extends E> c) {
//将指定集合转换为数组
elementData = c.toArray();
//如果elementData数组的长度不为0
if ((size = elementData.length) != 0) {
// 如果elementData不是Object类型数据(c.toArray可能返回的不是Object类型的数组所以加上下面的语句用于判断)
if (elementData.getClass() != Object[].class)
//将原来不是Object类型的elementData数组的内容,赋值给新的Object类型的elementData数组
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// 其他情况,用空数组代替
this.elementData = EMPTY_ELEMENTDATA;
}
}
/**
* 修改这个ArrayList实例的容量是列表的当前大小。 应用程序可以使用此操作来最小化ArrayList实例的存储。
*/
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
//下面是ArrayList的扩容机制
//ArrayList的扩容机制提高了性能,如果每次只扩充一个,
//那么频繁的插入会导致频繁的拷贝,降低性能,而ArrayList的扩容机制避免了这种情况。
/**
* 如有必要,增加此ArrayList实例的容量,以确保它至少能容纳元素的数量
* @param minCapacity 所需的最小容量
*/
public void ensureCapacity(int minCapacity) {
//如果是true,minExpand的值为0,如果是false,minExpand的值为10
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
//如果最小容量大于已有的最大容量
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
//1.得到最小扩容量
//2.通过最小容量扩容
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 获取“默认的容量”和“传入参数”两者之间的最大值
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
//判断是否需要扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
//调用grow方法进行扩容,调用此方法代表已经开始扩容了
grow(minCapacity);
}
/**
* 要分配的最大数组大小
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* ArrayList扩容的核心方法。
*/
private void grow(int minCapacity) {
// oldCapacity为旧容量,newCapacity为新容量
int oldCapacity = elementData.length;
//将oldCapacity 右移一位,其效果相当于oldCapacity /2,
//我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,
int newCapacity = oldCapacity + (oldCapacity >> 1);
//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//再检查新容量是否超出了ArrayList所定义的最大容量,
//若超出了,则调用hugeCapacity()来比较minCapacity和 MAX_ARRAY_SIZE,
//如果minCapacity大于MAX_ARRAY_SIZE,则新容量则为Interger.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE。
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
//比较minCapacity和 MAX_ARRAY_SIZE
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
/**
*返回此列表中的元素数。
*/
public int size() {
return size;
}
/**
* 如果此列表不包含元素,则返回 true 。
*/
public boolean isEmpty() {
//注意=和==的区别
return size == 0;
}
/**
* 如果此列表包含指定的元素,则返回true 。
*/
public boolean contains(Object o) {
//indexOf()方法:返回此列表中指定元素的首次出现的索引,如果此列表不包含此元素,则为-1
return indexOf(o) >= 0;
}
/**
*返回此列表中指定元素的首次出现的索引,如果此列表不包含此元素,则为-1
*/
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
//equals()方法比较
if (o.equals(elementData[i]))
return i;
}
return -1;
}
/**
* 返回此列表中指定元素的最后一次出现的索引,如果此列表不包含元素,则返回-1。.
*/
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
/**
* 返回此ArrayList实例的浅拷贝。 (元素本身不被复制。)
*/
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
//Arrays.copyOf功能是实现数组的复制,返回复制后的数组。参数是被复制的数组和复制的长度
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// 这不应该发生,因为我们是可以克隆的
throw new InternalError(e);
}
}
/**
*以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。
*返回的数组将是“安全的”,因为该列表不保留对它的引用。 (换句话说,这个方法必须分配一个新的数组)。
*因此,调用者可以自由地修改返回的数组。 此方法充当基于阵列和基于集合的API之间的桥梁。
*/
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
/**
* 以正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素);
*返回的数组的运行时类型是指定数组的运行时类型。 如果列表适合指定的数组,则返回其中。
*否则,将为指定数组的运行时类型和此列表的大小分配一个新数组。
*如果列表适用于指定的数组,其余空间(即数组的列表数量多于此元素),则紧跟在集合结束后的数组中的元素设置为null 。
*(这仅在调用者知道列表不包含任何空元素的情况下才能确定列表的长度。)
*/
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
if (a.length < size)
// 新建一个运行时类型的数组,但是ArrayList数组的内容
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
//调用System提供的arraycopy()方法实现数组之间的复制
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
// Positional Access Operations
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
/**
* 返回此列表中指定位置的元素。
*/
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
/**
* 用指定的元素替换此列表中指定位置的元素。
*/
public E set(int index, E element) {
//对index进行界限检查
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
//返回原来在这个位置的元素
return oldValue;
}
/**
* 将指定的元素追加到此列表的末尾。
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
//这里看到ArrayList添加元素的实质就相当于为数组赋值
elementData[size++] = e;
return true;
}
/**
* 在此列表中的指定位置插入指定的元素。
*先调用 rangeCheckForAdd 对index进行界限检查;然后调用 ensureCapacityInternal 方法保证capacity足够大;
*再将从index开始之后的所有成员后移一个位置;将element插入index位置;最后size加1。
*/
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
//arraycopy()这个实现数组之间复制的方法一定要看一下,下面就用到了arraycopy()方法实现数组自己复制自己
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
/**
* 删除该列表中指定位置的元素。 将任何后续元素移动到左侧(从其索引中减去一个元素)。
*/
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
//从列表中删除的元素
return oldValue;
}
/**
* 从列表中删除指定元素的第一个出现(如果存在)。 如果列表不包含该元素,则它不会更改。
*返回true,如果此列表包含指定的元素
*/
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
/*
* Private remove method that skips bounds checking and does not
* return the value removed.
*/
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
/**
* 从列表中删除所有元素。
*/
public void clear() {
modCount++;
// 把数组中所有的元素的值设为null
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
/**
* 按指定集合的Iterator返回的顺序将指定集合中的所有元素追加到此列表的末尾。
*/
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
/**
* 将指定集合中的所有元素插入到此列表中,从指定的位置开始。
*/
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
int numMoved = size - index;
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
}
/**
* 从此列表中删除所有索引为fromIndex (含)和toIndex之间的元素。
*将任何后续元素移动到左侧(减少其索引)。
*/
protected void removeRange(int fromIndex, int toIndex) {
modCount++;
int numMoved = size - toIndex;
System.arraycopy(elementData, toIndex, elementData, fromIndex,
numMoved);
// clear to let GC do its work
int newSize = size - (toIndex-fromIndex);
for (int i = newSize; i < size; i++) {
elementData[i] = null;
}
size = newSize;
}
/**
* 检查给定的索引是否在范围内。
*/
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* add和addAll使用的rangeCheck的一个版本
*/
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* 返回IndexOutOfBoundsException细节信息
*/
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+size;
}
/**
* 从此列表中删除指定集合中包含的所有元素。
*/
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
//如果此列表被修改则返回true
return batchRemove(c, false);
}
/**
* 仅保留此列表中包含在指定集合中的元素。
*换句话说,从此列表中删除其中不包含在指定集合中的所有元素。
*/
public boolean retainAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, true);
}
/**
* 从列表中的指定位置开始,返回列表中的元素(按正确顺序)的列表迭代器。
*指定的索引表示初始调用将返回的第一个元素为next 。 初始调用previous将返回指定索引减1的元素。
*返回的列表迭代器是fail-fast 。
*/
public ListIterator<E> listIterator(int index) {
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: "+index);
return new ListItr(index);
}
/**
*返回列表中的列表迭代器(按适当的顺序)。
*返回的列表迭代器是fail-fast 。
*/
public ListIterator<E> listIterator() {
return new ListItr(0);
}
/**
*以正确的顺序返回该列表中的元素的迭代器。
*返回的迭代器是fail-fast 。
*/
public Iterator<E> iterator() {
return new Itr();
}
ArrayList 扩容机制分析
先从 ArrayList 的构造函数说起
(JDK8)ArrayList 有三种方式来初始化,构造方法源码如下:
/**
* 默认初始容量大小
*/
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
*默认构造函数,使用初始容量10构造一个空列表(无参数构造)
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* 带初始容量参数的构造函数。(用户自己指定容量)
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {//初始容量大于0
//创建initialCapacity大小的数组
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {//初始容量等于0
//创建空数组
this.elementData = EMPTY_ELEMENTDATA;
} else {//初始容量小于0,抛出异常
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
*构造包含指定collection元素的列表,这些元素利用该集合的迭代器按顺序返回
*如果指定的集合为null,throws NullPointerException。
*/
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
细心的同学一定会发现 :以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为 10。 下面在我们分析 ArrayList 扩容时会讲到这一点内容!
补充:JDK6 new 无参构造的
ArrayList对象时,直接创建了长度是 10 的Object[]数组 elementData 。
一步一步分析 ArrayList 扩容机制
这里以无参构造函数创建的 ArrayList 为例分析
先来看 add 方法
/**
* 将指定的元素追加到此列表的末尾。
*/
public boolean add(E e) {
//添加元素之前,先调用ensureCapacityInternal方法
ensureCapacityInternal(size + 1); // Increments modCount!!
//这里看到ArrayList添加元素的实质就相当于为数组赋值
elementData[size++] = e;
return true;
}
注意 :JDK11 移除了
ensureCapacityInternal()和ensureExplicitCapacity()方法
再来看看 ensureCapacityInternal() 方法
(JDK7)可以看到 add 方法 首先调用了ensureCapacityInternal(size + 1)
//得到最小扩容量
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 获取默认的容量和传入参数的较大值
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
当 要 add 进第 1 个元素时,minCapacity 为 1,在 Math.max()方法比较后,minCapacity 为 10。
此处和后续 JDK8 代码格式化略有不同,核心代码基本一样
ensureExplicitCapacity() 方法
如果调用 ensureCapacityInternal() 方法就一定会进入(执行)这个方法,下面我们来研究一下这个方法的源码!
//判断是否需要扩容
private void ensureExplicitCapacity(int minCapacity) {
modCount++;//用于标志修改次数的,在判断fail-fast错误时有用
// overflow-conscious code
if (minCapacity - elementData.length > 0)
//调用grow方法进行扩容,调用此方法代表已经开始扩容了
grow(minCapacity);
}
我们来仔细分析一下:
- 当我们要 add 进第 1 个元素到 ArrayList 时,elementData.length 为 0 (因为还是一个空的 list),因为执行了
ensureCapacityInternal()方法 ,所以 minCapacity 此时为 10。此时,minCapacity - elementData.length > 0成立,所以会进入grow(minCapacity)方法。 - 当 add 第 2 个元素时,minCapacity 为 2,此时 elementData.length(容量)在添加第一个元素后扩容成 10 了。此时,
minCapacity - elementData.length > 0不成立,所以不会进入 (执行)grow(minCapacity)方法。 - 添加第 3、4···到第 10 个元素时,依然不会执行 grow 方法,数组容量都为 10。
直到添加第 11 个元素,minCapacity(为 11)比 elementData.length(为 10)要大。进入 grow 方法进行扩容。
grow() 方法
/**
* 要分配的最大数组大小
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* ArrayList扩容的核心方法。
*/
private void grow(int minCapacity) {
// oldCapacity为旧容量,newCapacity为新容量
int oldCapacity = elementData.length;
//将oldCapacity 右移一位,其效果相当于oldCapacity /2,
//我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,
int newCapacity = oldCapacity + (oldCapacity >> 1);
//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) `hugeCapacity()` 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,
//如果minCapacity大于最大容量,则新容量则为`Integer.MAX_VALUE`,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 `Integer.MAX_VALUE - 8`。
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍左右(oldCapacity 为偶数就是 1.5 倍,否则是 1.5 倍左右)! 奇偶不同,比如 :10+10/2 = 15, 33+33/2=49。如果是奇数的话会丢掉小数.
">>"(移位运算符):>>1 右移一位相当于除 2,右移 n 位相当于除以 2 的 n 次方。这里 oldCapacity 明显右移了 1 位所以相当于 oldCapacity /2。对于大数据的 2 进制运算,位移运算符比那些普通运算符的运算要快很多,因为程序仅仅移动一下而已,不去计算,这样提高了效率,节省了资源
我们再来通过例子探究一下grow() 方法 :
- 当 add 第 1 个元素时,oldCapacity 为 0,经比较后第一个 if 判断成立,newCapacity = minCapacity(为 10)。但是第二个 if 判断不会成立,即 newCapacity 不比 MAX_ARRAY_SIZE 大,则不会进入
hugeCapacity方法。数组容量为 10,add 方法中 return true,size 增为 1。 - 当 add 第 11 个元素进入 grow 方法时,newCapacity 为 15,比 minCapacity(为 11)大,第一个 if 判断不成立。新容量没有大于数组最大 size,不会进入 hugeCapacity 方法。数组容量扩为 15,add 方法中 return true,size 增为 11。
- 以此类推······
这里补充一点比较重要,但是容易被忽视掉的知识点:
- java 中的
length属性是针对数组说的,比如说你声明了一个数组,想知道这个数组的长度则用到了 length 这个属性. - java 中的
length()方法是针对字符串说的,如果想看这个字符串的长度则用到length()这个方法. - java 中的
size()方法是针对泛型集合说的,如果想看这个泛型有多少个元素,就调用此方法来查看!
总之加了()就是调用方法的意思,只有对象可以调用方法,基本类型是无法调用方法的!
hugeCapacity() 方法。
从上面 grow() 方法源码我们知道: 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) hugeCapacity() 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,如果 minCapacity 大于最大容量,则新容量则为Integer.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 Integer.MAX_VALUE - 8。
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
//对minCapacity和MAX_ARRAY_SIZE进行比较
//若minCapacity大,将Integer.MAX_VALUE作为新数组的大小
//若MAX_ARRAY_SIZE大,将MAX_ARRAY_SIZE作为新数组的大小
//MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
System.arraycopy() 和 Arrays.copyOf()方法
阅读源码的话,我们就会发现 ArrayList 中大量调用了这两个方法。比如:我们上面讲的扩容操作以及add(int index, E element)、toArray() 等方法中都用到了该方法!
System.arraycopy() 方法
源码:
// 我们发现 arraycopy 是一个 native 方法,接下来我们解释一下各个参数的具体意义
/**
* 复制数组
* @param src 源数组
* @param srcPos 源数组中的起始位置
* @param dest 目标数组
* @param destPos 目标数组中的起始位置
* @param length 要复制的数组元素的数量
*/
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
场景:
/**
* 在此列表中的指定位置插入指定的元素。
*先调用 rangeCheckForAdd 对index进行界限检查;然后调用 ensureCapacityInternal 方法保证capacity足够大;
*再将从index开始之后的所有成员后移一个位置;将element插入index位置;最后size加1。
*/
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
//arraycopy()方法实现数组自己复制自己
//elementData:源数组;index:源数组中的起始位置;elementData:目标数组;index + 1:目标数组中的起始位置; size - index:要复制的数组元素的数量;
System.arraycopy(elementData, index, elementData, index + 1, size - index);
elementData[index] = element;
size++;
}
我们写一个简单的方法测试以下:
public class ArraycopyTest {
public static void main(String[] args) {
int[] a = new int[10];
a[0] = 0;
a[1] = 1;
a[2] = 2;
a[3] = 3;
System.arraycopy(a, 2, a, 3, 3);
a[2]=99;
for (int i = 0; i < a.length; i++) {
System.out.print(a[i] + " ");
}
}
}
输出:
0 1 99 2 3 0 0 0 0 0
Arrays.copyOf()方法
源码:copyOf有很多种重载实现,其中original数组的元素的类型不仅包括基本数据类型,也包括泛型等等...
public static int[] copyOf(int[] original, int newLength) {
// 申请一个新的数组
int[] copy = new int[newLength];
// 调用System.arraycopy,将源数组中的数据进行拷贝,并返回新的数组
System.arraycopy(original, 0, copy, 0,Math.min(original.length, newLength));
return copy;
}
场景:
/**
以正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素); 返回的数组的运行时类型是指定数组的运行时类型。
*/
public Object[] toArray() {
//elementData:要复制的数组;size:要复制的长度
return Arrays.copyOf(elementData, size);
}
个人觉得使用 Arrays.copyOf()方法主要是为了给原有数组扩容,测试代码如下:
public class ArrayscopyOfTest {
public static void main(String[] args) {
int[] a = new int[3];
a[0] = 0;
a[1] = 1;
a[2] = 2;
int[] b = Arrays.copyOf(a, 10);
System.out.println("b.length"+b.length);
}
}
结果:10
两者联系和区别
联系:看两者源代码可以发现 copyOf()内部实际调用了 System.arraycopy() 方法
区别:arraycopy() 需要目标数组,将原数组拷贝到你自己定义的数组里或者原数组,而且可以选择拷贝的起点和长度以及放入新数组中的位置 copyOf() 是系统自动在内部新建一个数组,并返回该数组。
ensureCapacity方法
ArrayList 源码中有一个 ensureCapacity 方法不知道大家注意到没有,这个方法 ArrayList 内部没有被调用过,所以很显然是提供给用户调用的,那么这个方法有什么作用呢?
/**
如有必要,增加此 ArrayList 实例的容量,以确保它至少可以容纳由minimum capacity参数指定的元素数。
*
* @param minCapacity 所需的最小容量
*/
public void ensureCapacity(int minCapacity) {
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
理论上来说,最好在向 ArrayList 添加大量元素之前用 ensureCapacity 方法,以减少增量重新分配的次数。
我们通过下面的代码实际测试以下这个方法的效果:
public class EnsureCapacityTest {
public static void main(String[] args) {
ArrayList<Object> list = new ArrayList<Object>();
final int N = 10000000;
long startTime = System.currentTimeMillis();
for (int i = 0; i < N; i++) {
list.add(i);
}
long endTime = System.currentTimeMillis();
System.out.println("使用ensureCapacity方法前:"+(endTime - startTime));
}
}
运行结果:
使用ensureCapacity方法前:2158
接着用ensureCapacity
public class EnsureCapacityTest {
public static void main(String[] args) {
ArrayList<Object> list = new ArrayList<Object>();
final int N = 10000000;
long startTime1 = System.currentTimeMillis();
list.ensureCapacity(N);
for (int i = 0; i < N; i++) {
list.add(i);
}
long endTime1 = System.currentTimeMillis();
System.out.println("使用ensureCapacity方法后:"+(endTime1 - startTime1));
}
}
运行结果:
使用ensureCapacity方法后:1773
通过运行结果,我们可以看出向 ArrayList 添加大量元素之前使用ensureCapacity 方法可以提升性能。不过,这个性能差距几乎可以忽略不计。而且,实际项目根本也不可能往 ArrayList 里面添加这么多元素。
HashMap源码&底层数据结构分析
感谢 changfubai 对本文的改进做出的贡献!
HashMap 简介
HashMap 主要用来存放键值对,它基于哈希表的 Map 接口实现,是常用的 Java 集合之一,是非线程安全的。
HashMap 可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。 JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
HashMap 默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。并且, HashMap 总是使用 2 的幂作为哈希表的大小。
底层数据结构分析
JDK1.8 之前
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。
HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
JDK 1.8 HashMap 的 hash 方法源码:
JDK 1.8 的 hash 方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
static final int hash(Object key) {
int h;
// key.hashCode():返回散列值也就是hashcode
// ^ :按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
对比一下 JDK1.7 的 HashMap 的 hash 方法源码.
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
所谓 “拉链法” 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值(其实是Entry<key,value>,即键和值都会加到链表中)加到链表中即可。
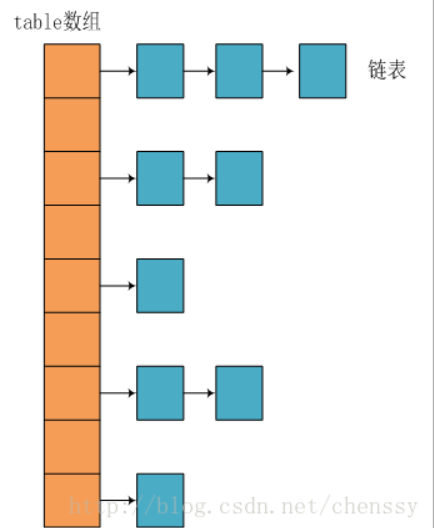
JDK1.8 之后
相比于之前的版本,JDK1.8 以后在解决哈希冲突时有了较大的变化。
当链表长度大于阈值(默认为 8)时,会首先调用 treeifyBin()方法。这个方法会根据 HashMap 数组来决定是否转换为红黑树。只有当数组长度大于或者等于 64 的情况下,才会执行转换红黑树操作,以减少搜索时间。否则,就是只是执行 resize() 方法对数组扩容。相关源码这里就不贴了,重点关注 treeifyBin()方法即可!
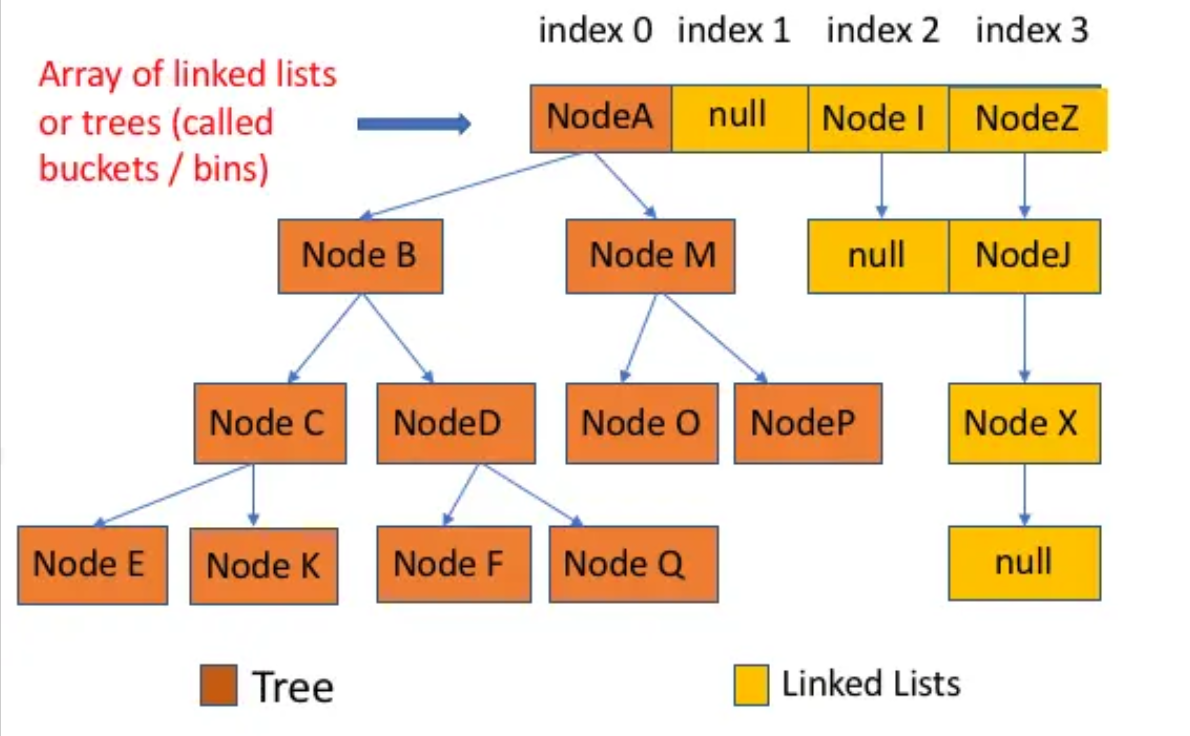
类的属性:
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
// 序列号
private static final long serialVersionUID = 362498820763181265L;
// 默认的初始容量是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的填充因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 当桶(bucket)上的结点数大于这个值时会转成红黑树
static final int TREEIFY_THRESHOLD = 8;
// 当桶(bucket)上的结点数小于这个值时树转链表
static final int UNTREEIFY_THRESHOLD = 6;
// 桶中结构转化为红黑树对应的table的最小容量
static final int MIN_TREEIFY_CAPACITY = 64;
// 存储元素的数组,总是2的幂次倍
transient Node<k,v>[] table;
// 存放具体元素的集
transient Set<map.entry<k,v>> entrySet;
// 存放元素的个数,注意这个不等于数组的长度。
transient int size;
// 每次扩容和更改map结构的计数器
transient int modCount;
// 临界值(容量*填充因子) 当实际大小超过临界值时,会进行扩容
int threshold;
// 加载因子
final float loadFactor;
}
- loadFactor 加载因子
loadFactor 加载因子是控制数组存放数据的疏密程度,loadFactor 越趋近于 1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor 越小,也就是趋近于 0,数组中存放的数据(entry)也就越少,也就越稀疏。
loadFactor 太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor 的默认值为 0.75f 是官方给出的一个比较好的临界值。
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
- threshold
threshold = capacity * loadFactor,当 Size>=threshold的时候,那么就要考虑对数组的扩增了,也就是说,这个的意思就是 衡量数组是否需要扩增的一个标准。
Node 节点类源码:
// 继承自 Map.Entry<K,V>
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;// 哈希值,存放元素到hashmap中时用来与其他元素hash值比较
final K key;//键
V value;//值
// 指向下一个节点
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
// 重写hashCode()方法
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 重写 equals() 方法
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
树节点类源码:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // 父
TreeNode<K,V> left; // 左
TreeNode<K,V> right; // 右
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red; // 判断颜色
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
// 返回根节点
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
HashMap 源码分析
构造方法
HashMap 中有四个构造方法,它们分别如下:
// 默认构造函数。
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
// 包含另一个“Map”的构造函数
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);//下面会分析到这个方法
}
// 指定“容量大小”的构造函数
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 指定“容量大小”和“加载因子”的构造函数
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
putMapEntries 方法:
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
// 判断table是否已经初始化
if (table == null) { // pre-size
// 未初始化,s为m的实际元素个数
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
// 计算得到的t大于阈值,则初始化阈值
if (t > threshold)
threshold = tableSizeFor(t);
}
// 已初始化,并且m元素个数大于阈值,进行扩容处理
else if (s > threshold)
resize();
// 将m中的所有元素添加至HashMap中
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
put 方法
HashMap 只提供了 put 用于添加元素,putVal 方法只是给 put 方法调用的一个方法,并没有提供给用户使用。
对 putVal 方法添加元素的分析如下:
- 如果定位到的数组位置没有元素 就直接插入。
- 如果定位到的数组位置有元素就和要插入的 key 比较,如果 key 相同就直接覆盖,如果 key 不相同,就判断 p 是否是一个树节点,如果是就调用
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)将元素添加进入。如果不是就遍历链表插入(插入的是链表尾部)。
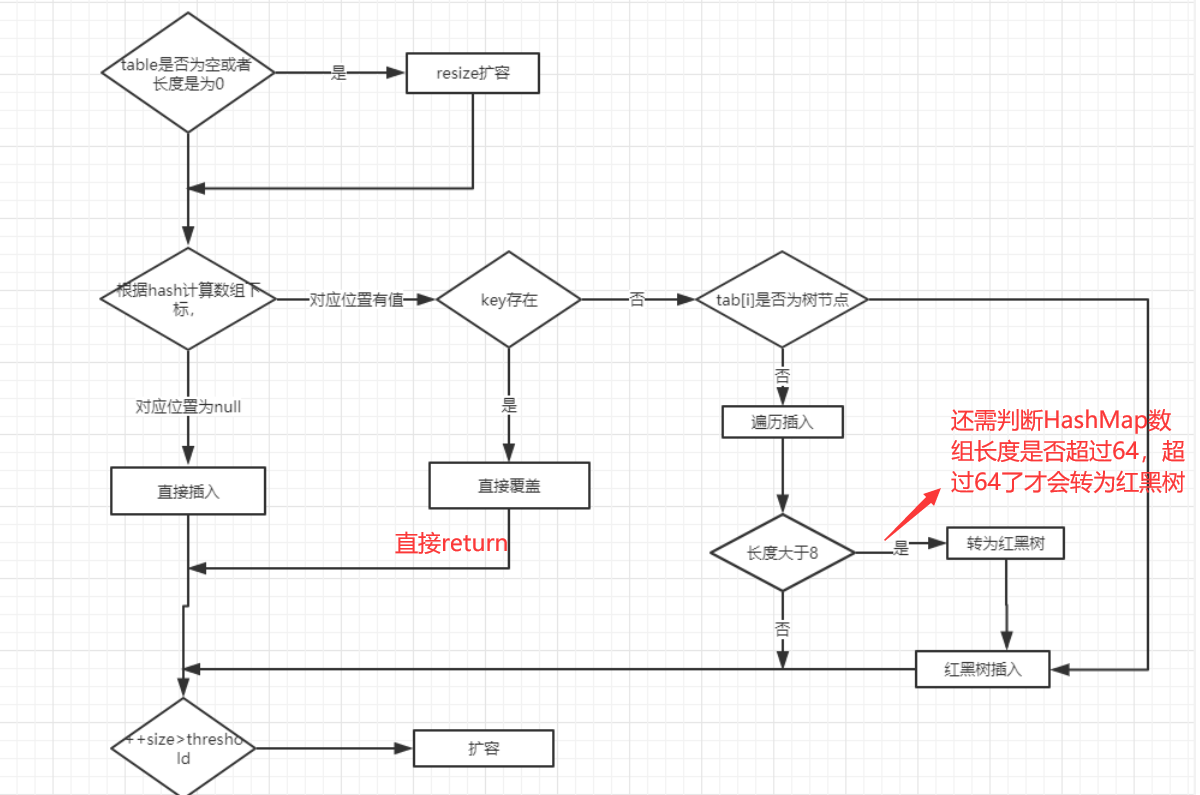
说明:上图有两个小问题:
- 直接覆盖之后应该就会 return,不会有后续操作。参考 JDK8 HashMap.java 658 行(issue#608)。
- 当链表长度大于阈值(默认为 8)并且 HashMap 数组长度超过 64 的时候才会执行链表转红黑树的操作,否则就只是对数组扩容。参考 HashMap 的
treeifyBin()方法(issue#1087)。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// table未初始化或者长度为0,进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 桶中已经存在元素(处理hash冲突)
else {
Node<K,V> e; K k;
// 判断table[i]中的元素是否与插入的key一样,若相同那就直接使用插入的值p替换掉旧的值e。
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 判断插入的是否是红黑树节点
else if (p instanceof TreeNode)
// 放入树中
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 不是红黑树节点则说明为链表结点
else {
// 在链表最末插入结点
for (int binCount = 0; ; ++binCount) {
// 到达链表的尾部
if ((e = p.next) == null) {
// 在尾部插入新结点
p.next = newNode(hash, key, value, null);
// 结点数量达到阈值(默认为 8 ),执行 treeifyBin 方法
// 这个方法会根据 HashMap 数组来决定是否转换为红黑树。
// 只有当数组长度大于或者等于 64 的情况下,才会执行转换红黑树操作,以减少搜索时间。否则,就是只是对数组扩容。
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
// 跳出循环
break;
}
// 判断链表中结点的key值与插入的元素的key值是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 相等,跳出循环
break;
// 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表
p = e;
}
}
// 表示在桶中找到key值、hash值与插入元素相等的结点
if (e != null) {
// 记录e的value
V oldValue = e.value;
// onlyIfAbsent为false或者旧值为null
if (!onlyIfAbsent || oldValue == null)
//用新值替换旧值
e.value = value;
// 访问后回调
afterNodeAccess(e);
// 返回旧值
return oldValue;
}
}
// 结构性修改
++modCount;
// 实际大小大于阈值则扩容
if (++size > threshold)
resize();
// 插入后回调
afterNodeInsertion(evict);
return null;
}
我们再来对比一下 JDK1.7 put 方法的代码
对于 put 方法的分析如下:
- ① 如果定位到的数组位置没有元素 就直接插入。
- ② 如果定位到的数组位置有元素,遍历以这个元素为头结点的链表,依次和插入的 key 比较,如果 key 相同就直接覆盖,不同就采用头插法插入元素。
public V put(K key, V value)
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) { // 先遍历
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i); // 再插入
return null;
}
get 方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 数组元素相等
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 桶中不止一个节点
if ((e = first.next) != null) {
// 在树中get
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 在链表中get
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
resize 方法
进行扩容,会伴随着一次重新 hash 分配,并且会遍历 hash 表中所有的元素,是非常耗时的。在编写程序中,要尽量避免 resize。当 Size>=threshold(threshold = capacity * loadFactor)的时候,注意!这个size就是hashmap里存的键值对的个数,而不是数组中被占位置的个数,举个例子,假如一个hashmap里有10个键值对并且恰巧都碰撞到数组的同一个位置上,那么这个时候的size=10而不是1,那么就要考虑对数组的扩增了。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超过最大值就不再扩充了,就只好随你碰撞去吧
//static final int MAXIMUM_CAPACITY = 1 << 30;即2^30
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没超过最大值,就扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {
// signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的resize上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 把每个bucket都移动到新的buckets中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 原索引
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引+oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原索引放到bucket里
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引+oldCap放到bucket里
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
HashMap 常用方法测试
package map;
import java.util.Collection;
import java.util.HashMap;
import java.util.Set;
public class HashMapDemo {
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<String, String>();
// 键不能重复,值可以重复
map.put("san", "张三");
map.put("si", "李四");
map.put("wu", "王五");
map.put("wang", "老王");
map.put("wang", "老王2");// 老王被覆盖
map.put("lao", "老王");
System.out.println("-------直接输出hashmap:-------");
System.out.println(map);
/**
* 遍历HashMap
*/
// 1.获取Map中的所有键
System.out.println("-------foreach获取Map中所有的键:------");
Set<String> keys = map.keySet();
for (String key : keys) {
System.out.print(key+" ");
}
System.out.println();//换行
// 2.获取Map中所有值
System.out.println("-------foreach获取Map中所有的值:------");
Collection<String> values = map.values();
for (String value : values) {
System.out.print(value+" ");
}
System.out.println();//换行
// 3.得到key的值的同时得到key所对应的值
System.out.println("-------得到key的值的同时得到key所对应的值:-------");
Set<String> keys2 = map.keySet();
for (String key : keys2) {
System.out.print(key + ":" + map.get(key)+" ");
}
/**
* 如果既要遍历key又要value,那么建议这种方式,因为如果先获取keySet然后再执行map.get(key),map内部会执行两次遍历。
* 一次是在获取keySet的时候,一次是在遍历所有key的时候。
*/
// 当我调用put(key,value)方法的时候,首先会把key和value封装到
// Entry这个静态内部类对象中,把Entry对象再添加到数组中,所以我们想获取
// map中的所有键值对,我们只要获取数组中的所有Entry对象,接下来
// 调用Entry对象中的getKey()和getValue()方法就能获取键值对了
Set<java.util.Map.Entry<String, String>> entrys = map.entrySet();
for (java.util.Map.Entry<String, String> entry : entrys) {
System.out.println(entry.getKey() + "--" + entry.getValue());
}
/**
* HashMap其他常用方法
*/
System.out.println("after map.size():"+map.size());
System.out.println("after map.isEmpty():"+map.isEmpty());
System.out.println(map.remove("san"));
System.out.println("after map.remove():"+map);
System.out.println("after map.get(si):"+map.get("si"));
System.out.println("after map.containsKey(si):"+map.containsKey("si"));
System.out.println("after containsValue(李四):"+map.containsValue("李四"));
System.out.println(map.replace("si", "李四2"));
System.out.println("after map.replace(si, 李四2):"+map);
}
}
ConcurrentHashMap源码&底层数据结构分析
本文来自公众号:末读代码的投稿,原文地址:https://mp.weixin.qq.com/s/AHWzboztt53ZfFZmsSnMSw 。
上一篇文章介绍了 HashMap 源码,反响不错,也有很多同学发表了自己的观点,这次又来了,这次是 ConcurrentHashMap 了,作为线程安全的HashMap ,它的使用频率也是很高。那么它的存储结构和实现原理是怎么样的呢?
1. ConcurrentHashMap 1.7
1. 存储结构
Java 7 中 ConcurrentHashMap 的存储结构如上图,ConcurrnetHashMap 由很多个 Segment 组合,而每一个 Segment 是一个类似于 HashMap 的结构,所以每一个 HashMap 的内部可以进行扩容。但是 Segment 的个数一旦初始化就不能改变,默认 Segment 的个数是 16 个,你也可以认为 ConcurrentHashMap 默认支持最多 16 个线程并发。
2. 初始化
通过 ConcurrentHashMap 的无参构造探寻 ConcurrentHashMap 的初始化流程。
/**
* Creates a new, empty map with a default initial capacity (16),
* load factor (0.75) and concurrencyLevel (16).
*/
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
无参构造中调用了有参构造,传入了三个参数的默认值,他们的值是。
/**
* 默认初始化容量
*/
static final int DEFAULT_INITIAL_CAPACITY = 16;
/**
* 默认负载因子
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 默认并发级别
*/
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
接着看下这个有参构造函数的内部实现逻辑。
@SuppressWarnings("unchecked")
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {
// 参数校验
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
// 校验并发级别大小,大于 1<<16,重置为 65536
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
// 2的多少次方
int sshift = 0;
int ssize = 1;
// 这个循环可以找到 concurrencyLevel 之上最近的 2的次方值
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// 记录段偏移量
this.segmentShift = 32 - sshift;
// 记录段掩码
this.segmentMask = ssize - 1;
// 设置容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// c = 容量 / ssize ,默认 16 / 16 = 1,这里是计算每个 Segment 中的类似于 HashMap 的容量
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
//Segment 中的类似于 HashMap 的容量至少是2或者2的倍数
while (cap < c)
cap <<= 1;
// create segments and segments[0]
// 创建 Segment 数组,设置 segments[0]
Segment<K,V> s0 = new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
总结一下在 Java 7 中 ConcurrnetHashMap 的初始化逻辑。
- 必要参数校验。
- 校验并发级别
concurrencyLevel大小,如果大于最大值,重置为最大值。无参构造默认值是 16. - 寻找并发级别
concurrencyLevel之上最近的 2 的幂次方值,作为初始化容量大小,默认是 16。 - 记录
segmentShift偏移量,这个值为【容量 = 2 的N次方】中的 N,在后面 Put 时计算位置时会用到。默认是 32 - sshift = 28. - 记录
segmentMask,默认是 ssize - 1 = 16 -1 = 15. - 初始化
segments[0],默认大小为 2,负载因子 0.75,扩容阀值是 2*0.75=1.5,插入第二个值时才会进行扩容
3. put
/**
* Maps the specified key to the specified value in this table.
* Neither the key nor the value can be null.
*
* <p> The value can be retrieved by calling the <tt>get</tt> method
* with a key that is equal to the original key.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>
* @throws NullPointerException if the specified key or value is null
*/
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
// hash 值无符号右移 28位(初始化时获得),然后与 segmentMask=15 做与运算
// 其实也就是把高4位与segmentMask(1111)做与运算
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
// 如果查找到的 Segment 为空,初始化
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
/**
* Returns the segment for the given index, creating it and
* recording in segment table (via CAS) if not already present.
*
* @param k the index
* @return the segment
*/
@SuppressWarnings("unchecked")
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
// 判断 u 位置的 Segment 是否为null
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
// 获取0号 segment 里的 HashEntry<K,V> 初始化长度
int cap = proto.table.length;
// 获取0号 segment 里的 hash 表里的扩容负载因子,所有的 segment 的 loadFactor 是相同的
float lf = proto.loadFactor;
// 计算扩容阀值
int threshold = (int)(cap * lf);
// 创建一个 cap 容量的 HashEntry 数组
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { // recheck
// 再次检查 u 位置的 Segment 是否为null,因为这时可能有其他线程进行了操作
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
// 自旋检查 u 位置的 Segment 是否为null
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
// 使用CAS 赋值,只会成功一次
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
上面的源码分析了 ConcurrentHashMap 在 put 一个数据时的处理流程,下面梳理下具体流程。
-
计算要 put 的 key 的位置,获取指定位置的
Segment。 -
如果指定位置的
Segment为空,则初始化这个Segment.初始化 Segment 流程:
- 检查计算得到的位置的
Segment是否为null. - 为 null 继续初始化,使用
Segment[0]的容量和负载因子创建一个HashEntry数组。 - 再次检查计算得到的指定位置的
Segment是否为null. - 使用创建的
HashEntry数组初始化这个 Segment. - 自旋判断计算得到的指定位置的
Segment是否为null,使用 CAS 在这个位置赋值为Segment.
- 检查计算得到的位置的
-
Segment.put插入 key,value 值。
上面探究了获取 Segment 段和初始化 Segment 段的操作。最后一行的 Segment 的 put 方法还没有查看,继续分析。
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 获取 ReentrantLock 独占锁,获取不到,scanAndLockForPut 获取。
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
// 计算要put的数据位置
int index = (tab.length - 1) & hash;
// CAS 获取 index 坐标的值
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
// 检查是否 key 已经存在,如果存在,则遍历链表寻找位置,找到后替换 value
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
// first 有值说明 index 位置已经有值了,有冲突,链表头插法。
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// 容量大于扩容阀值,小于最大容量,进行扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
// index 位置赋值 node,node 可能是一个元素,也可能是一个链表的表头
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
由于 Segment 继承了 ReentrantLock,所以 Segment 内部可以很方便的获取锁,put 流程就用到了这个功能。
-
tryLock()获取锁,获取不到使用scanAndLockForPut方法继续获取。 -
计算 put 的数据要放入的 index 位置,然后获取这个位置上的
HashEntry。 -
遍历 put 新元素,为什么要遍历?因为这里获取的
HashEntry可能是一个空元素,也可能是链表已存在,所以要区别对待。如果这个位置上的
HashEntry不存在:- 如果当前容量大于扩容阀值,小于最大容量,进行扩容。
- 直接头插法插入。
如果这个位置上的
HashEntry存在:- 判断链表当前元素 key 和 hash 值是否和要 put 的 key 和 hash 值一致。一致则替换值
- 不一致,获取链表下一个节点,直到发现相同进行值替换,或者链表表里完毕没有相同的。
- 如果当前容量大于扩容阀值,小于最大容量,进行扩容。
- 直接链表头插法插入。
-
如果要插入的位置之前已经存在,替换后返回旧值,否则返回 null.
这里面的第一步中的 scanAndLockForPut 操作这里没有介绍,这个方法做的操作就是不断的自旋 (即 不断循环着请求锁)tryLock() 获取锁。当自旋次数大于指定次数时,使用 lock() 阻塞获取锁。在自旋时顺表获取下 hash 位置的 HashEntry。
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
// 自旋获取锁
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
else if (++retries > MAX_SCAN_RETRIES) {
// 自旋达到指定次数后,阻塞等到只到获取到锁
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
4. 扩容 rehash
ConcurrentHashMap 的扩容只会扩容到原来的两倍。老数组里的数据移动到新的数组时,位置要么不变,要么变为 index+ oldSize,参数里的 node 会在扩容之后使用链表头插法插入到指定位置。
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
// 老容量
int oldCapacity = oldTable.length;
// 新容量,扩大两倍
int newCapacity = oldCapacity << 1;
// 新的扩容阀值
threshold = (int)(newCapacity * loadFactor);
// 创建新的数组
HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) new HashEntry[newCapacity];
// 新的掩码,默认2扩容后是4,-1是3,二进制就是11。
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
// 遍历老数组
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
// 计算新的位置,新的位置只可能是不便或者是老的位置+老的容量。
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
// 如果当前位置还不是链表,只是一个元素,直接赋值
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
// 如果是链表了
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
// 新的位置只可能是不便或者是老的位置+老的容量。
// 遍历结束后,lastRun 后面的元素位置都是相同的
for (HashEntry<K,V> last = next; last != null; last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
// ,lastRun 后面的元素位置都是相同的,直接作为链表赋值到新位置。
newTable[lastIdx] = lastRun;
// Clone remaining nodes
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
// 遍历剩余元素,头插法到指定 k 位置。
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
// 头插法插入新的节点
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
有些同学可能会对最后的两个 for 循环有疑惑,这里第一个 for 是为了寻找这样一个节点,这个节点后面的所有 next 节点的新位置都是相同的。然后把这个作为一个链表赋值到新位置。第二个 for 循环是为了把剩余的元素通过头插法插入到指定位置链表。这样实现的原因可能是基于概率统计,有深入研究的同学可以发表下意见。
5. get
到这里就很简单了,get 方法只需要两步即可。
- 计算得到 key 的存放位置。
- 遍历指定位置查找相同 key 的 value 值。
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// 计算得到 key 的存放位置
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
// 如果是链表,遍历查找到相同 key 的 value。
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
2. ConcurrentHashMap 1.8
1. 存储结构
可以发现 Java8 的 ConcurrentHashMap 相对于 Java7 来说变化比较大,不再是之前的 Segment 数组 + HashEntry 数组 + 链表,而是 Node 数组 + 链表 / 红黑树。当冲突链表达到一定长度时,链表会转换成红黑树。
2. 初始化 initTable
默认的大小还是16
/**
* Initializes table, using the size recorded in sizeCtl.
*/
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// 如果 sizeCtl < 0 ,说明另外的线程执行CAS 成功,正在进行初始化。
if ((sc = sizeCtl) < 0)
// 让出 CPU 使用权
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
从源码中可以发现 ConcurrentHashMap 的初始化是通过自旋和 CAS 操作完成的。里面需要注意的是变量 sizeCtl ,它的值决定着当前的初始化状态。
- -1 说明正在初始化
- -N 说明有N-1个线程正在进行扩容
- 表示 table 初始化大小,如果 table 没有初始化
- 表示 table 容量,如果 table 已经初始化。
3. put
直接过一遍 put 源码。
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
// key 和 value 不能为空
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
// f = 目标位置元素
Node<K,V> f; int n, i, fh;// fh 后面存放目标位置的元素 hash 值
if (tab == null || (n = tab.length) == 0)
// 数组桶为空,初始化数组桶(自旋+CAS)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 桶内为空,CAS 放入,不加锁,成功了就直接 break 跳出
if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 使用 synchronized 加锁加入节点
synchronized (f) {
if (tabAt(tab, i) == f) {
// 说明是链表
if (fh >= 0) {
binCount = 1;
// 循环加入新的或者覆盖节点
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
// 红黑树
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
- 根据 key 计算出 hashcode 。
- 判断是否需要进行初始化。
- 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
- 如果当前位置的
hashcode == MOVED == -1,则需要进行扩容。 - 如果都不满足,则利用 synchronized 锁写入数据。
- 如果数量大于
TREEIFY_THRESHOLD则要执行树化方法,在treeifyBin中会首先判断当前数组长度≥64时才会将链表转换为红黑树。
4. get
get 流程比较简单,直接过一遍源码。
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// key 所在的 hash 位置
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// 如果指定位置元素存在,头结点hash值相同
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
// key hash 值相等,key值相同,直接返回元素 value
return e.val;
}
else if (eh < 0)
// 头结点hash值小于0,说明正在扩容或者是红黑树,find查找
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
// 是链表,遍历查找
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
总结一下 get 过程:
- 根据 hash 值计算位置。
- 查找到指定位置,如果头节点就是要找的,直接返回它的 value.
- 如果头节点 hash 值小于 0 ,说明正在扩容或者是红黑树,查找之。
- 如果是链表,遍历查找之。
总结:
总的来说 ConcurrentHashMap 在 Java8 中相对于 Java7 来说变化还是挺大的
3. 总结
Java7 中 ConcurrentHashMap 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个 Segment 都是一个类似 HashMap 数组的结构,它可以扩容,它的冲突会转化为链表。但是 Segment 的个数一旦初始化就不能改变。
Java8 中的 ConcurrentHashMap 使用的 Synchronized 锁加 CAS 的机制。结构也由 Java7 中的 Segment 数组 + HashEntry 数组 + 链表 进化成了 Node 数组 + 链表 / 红黑树,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表(与1.8的HashMap类似)。
有些同学可能对 Synchronized 的性能存在疑问,其实 Synchronized 锁自从引入锁升级策略后,性能不再是问题,有兴趣的同学可以自己了解下 Synchronized 的锁升级。
Java IO基础知识总结
IO 流简介
IO 即 Input/Output,输入和输出。数据输入到计算机内存的过程即输入,反之输出到外部存储(比如数据库,文件,远程主机)的过程即输出。数据传输过程类似于水流,因此称为 IO 流。IO 流在 Java 中分为输入流和输出流,而根据数据的处理方式又分为字节流和字符流。
Java IO 流的 40 多个类都是从如下 4 个抽象类基类中派生出来的。
InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
字节流
InputStream(字节输入流)
InputStream用于从源头(通常是文件)读取数据(字节信息)到内存中,java.io.InputStream抽象类是所有字节输入流的父类。
InputStream 常用方法 :
read():返回输入流中下一个字节的数据。返回的值介于 0 到 255 之间。如果未读取任何字节,则代码返回-1,表示文件结束。read(byte b[ ]): 从输入流中读取一些字节存储到数组b中。如果数组b的长度为零,则不读取。如果没有可用字节读取,返回-1。如果有可用字节读取,则最多读取的字节数最多等于b.length, 返回读取的字节数。这个方法等价于read(b, 0, b.length)。read(byte b[], int off, int len):在read(byte b[ ])方法的基础上增加了off参数(偏移量)和len参数(要读取的最大字节数)。skip(long n):忽略输入流中的 n 个字节 ,返回实际忽略的字节数。available():返回输入流中可以读取的字节数。close():关闭输入流释放相关的系统资源。
从 Java 9 开始,InputStream 新增加了多个实用的方法:
readAllBytes():读取输入流中的所有字节,返回字节数组。readNBytes(byte[] b, int off, int len):阻塞直到读取len个字节。transferTo(OutputStream out): 将所有字节从一个输入流传递到一个输出流。
FileInputStream 是一个比较常用的字节输入流对象,可直接指定文件路径,可以直接读取单字节数据,也可以读取至字节数组中。
FileInputStream 代码示例:
try (InputStream fis = new FileInputStream("input.txt")) {
System.out.println("Number of remaining bytes:"+ fis.available());
int content;
long skip = fis.skip(2);
System.out.println("The actual number of bytes skipped:" + skip);
System.out.print("The content read from file:");
while ((content = fis.read()) != -1) {
System.out.print((char) content);
}
} catch (IOException e) {
e.printStackTrace();
}
input.txt 文件内容:
输出:
Number of remaining bytes:11
The actual number of bytes skipped:2
The content read from file:JavaGuide
不过,一般我们是不会直接单独使用 FileInputStream ,通常会配合 BufferedInputStream(字节缓冲输入流,后文会讲到)来使用。
像下面这段代码在我们的项目中就比较常见,我们通过 readAllBytes() 读取输入流所有字节并将其直接赋值给一个 String 对象。
// 新建一个 BufferedInputStream 对象
BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("input.txt"));
// 读取文件的内容并复制到 String 对象中
String result = new String(bufferedInputStream.readAllBytes());
System.out.println(result);
DataInputStream 用于读取指定类型数据,不能单独使用,必须结合 FileInputStream 。
FileInputStream fileInputStream = new FileInputStream("input.txt");
//必须将fileInputStream作为构造参数才能使用
DataInputStream dataInputStream = new DataInputStream(fileInputStream);
//可以读取任意具体的类型数据
dataInputStream.readBoolean();
dataInputStream.readInt();
dataInputStream.readUTF();
ObjectInputStream 用于从输入流中读取 Java 对象(反序列化),ObjectOutputStream 用于将对象写入到输出流(序列化)。
ObjectInputStream input = new ObjectInputStream(new FileInputStream("object.data"));
MyClass object = (MyClass) input.readObject();
input.close();
另外,用于序列化和反序列化的类必须实现 Serializable 接口,对象中如果有属性不想被序列化,使用 transient 修饰。
OutputStream(字节输出流)
OutputStream用于将数据(字节信息)写入到目的地(通常是文件),java.io.OutputStream抽象类是所有字节输出流的父类。
OutputStream 常用方法 :
write(int b):将特定字节写入输出流。write(byte b[ ]): 将数组b写入到输出流,等价于write(b, 0, b.length)。write(byte[] b, int off, int len): 在write(byte b[ ])方法的基础上增加了off参数(偏移量)和len参数(要读取的最大字节数)。flush():刷新此输出流并强制写出所有缓冲的输出字节。close():关闭输出流释放相关的系统资源。
FileOutputStream 是最常用的字节输出流对象,可直接指定文件路径,可以直接输出单字节数据,也可以输出指定的字节数组。
FileOutputStream 代码示例:
try (FileOutputStream output = new FileOutputStream("output.txt")) {
byte[] array = "JavaGuide".getBytes();
output.write(array);
} catch (IOException e) {
e.printStackTrace();
}
运行结果:
类似于 FileInputStream,FileOutputStream 通常也会配合 BufferedOutputStream(字节缓冲输出流,后文会讲到)来使用。
FileOutputStream fileOutputStream = new FileOutputStream("output.txt");
BufferedOutputStream bos = new BufferedOutputStream(fileOutputStream)
DataOutputStream 用于写入指定类型数据,不能单独使用,必须结合 FileOutputStream
// 输出流
FileOutputStream fileOutputStream = new FileOutputStream("out.txt");
DataOutputStream dataOutputStream = new DataOutputStream(fileOutputStream);
// 输出任意数据类型
dataOutputStream.writeBoolean(true);
dataOutputStream.writeByte(1);
ObjectInputStream 用于从输入流中读取 Java 对象(ObjectInputStream,反序列化),ObjectOutputStream将对象写入到输出流(ObjectOutputStream,序列化)。
ObjectOutputStream output = new ObjectOutputStream(new FileOutputStream("file.txt")
Person person = new Person("Guide哥", "JavaGuide作者");
output.writeObject(person);
字符流
不管是文件读写还是网络发送接收,信息的最小存储单元都是字节。 那为什么 I/O 流操作要分为字节流操作和字符流操作呢?
个人认为主要有两点原因:
- 字符流是由 Java 虚拟机将字节转换得到的,这个过程还算是比较耗时。
- 如果我们不知道编码类型就很容易出现乱码问题。
乱码问题这个很容易就可以复现,我们只需要将上面提到的 FileInputStream 代码示例中的 input.txt 文件内容改为中文即可,原代码不需要改动。
输出:
Number of remaining bytes:9
The actual number of bytes skipped:2
The content read from file:§å®¶å¥½
可以很明显地看到读取出来的内容已经变成了乱码。
因此,I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
字符流默认采用的是 Unicode 编码,我们可以通过构造方法自定义编码。顺便分享一下之前遇到的笔试题:
常用字符编码所占字节数?
utf8:英文占 1 字节,中文占 3 字节,unicode:任何字符都占 2 个字节,gbk:英文占 1 字节,中文占 2 字节。
实际上 我们可以理解为字符流=字节流+编码表,为什么可以这样理解呢,因为字节流读数据是默认采用了ASCII编码,而ASCll编码是主要针对一个字节代表一个字符的数据,而我们中文汉字是一个字符=两个字节,如果采用了ASCll编码读取汉字就会出现乱码,在字节流中我们没有办法改变采用其他编码种类,而字符流可以,它采用UTF编码,是支持中文的,我们还可以在字符流对象中设置采用别的编码种类,字符流就是在字节流的基础上增加了可以选择其他编码种类的功能。
Reader(字符输入流)
Reader用于从源头(通常是文件)读取数据(字符信息)到内存中,java.io.Reader抽象类是所有字符输入流的父类。
Reader 用于读取文本, InputStream 用于读取原始字节。
Reader 常用方法 :
read(): 从输入流读取一个字符。read(char[] cbuf): 从输入流中读取一些字符,并将它们存储到字符数组cbuf中,等价于read(cbuf, 0, cbuf.length)。read(char[] cbuf, int off, int len):在read(char[] cbuf)方法的基础上增加了off参数(偏移量)和len参数(要读取的最大字节数)。skip(long n):忽略输入流中的 n 个字符 ,返回实际忽略的字符数。close(): 关闭输入流并释放相关的系统资源。
InputStreamReader 是字节流转换为字符流的桥梁,其子类 FileReader 是基于该基础上的封装,可以直接操作字符文件。
// 字节流转换为字符流的桥梁
public class InputStreamReader extends Reader {
}
// 用于读取字符文件,就是继承的InputStreamReader
public class FileReader extends InputStreamReader {
}
FileReader 代码示例:
try (FileReader fileReader = new FileReader("input.txt");) {
int content;
long skip = fileReader.skip(3);
System.out.println("The actual number of bytes skipped:" + skip);
System.out.print("The content read from file:");
while ((content = fileReader.read()) != -1) {
System.out.print((char) content);
}
} catch (IOException e) {
e.printStackTrace();
}
提问?为啥这里并没有指定编码格式,字符流还是正确读出了汉字?因为InputStreamReader在没有指定字符编码的情况下,默认使用UTF-8编码。
比如InputStreamReader会用到StreamDecoder下的forInputStreamReader()方法,该方法会去取默认的字符编码格式,如下块代码所示:
/**
* Returns the default charset of this Java virtual machine.
*
* <p> The default charset is determined during virtual-machine startup and
* typically depends upon the locale and charset of the underlying
* operating system.
*
* @return A charset object for the default charset
*
* @since 1.5
*/
public static Charset defaultCharset() {
if (defaultCharset == null) {
synchronized (Charset.class) {
String csn = AccessController.doPrivileged(
new GetPropertyAction("file.encoding"));
Charset cs = lookup(csn);
if (cs != null)
defaultCharset = cs;
else
defaultCharset = forName("UTF-8");
}
}
return defaultCharset;
}
有关编码的信息可以查看:Java默认编码Unicode和ASCII、UTF-8等的区别 - 达摩院的BLOG - 博客园 (cnblogs.com)
输出:
The actual number of bytes skipped:3
The content read from file:我是Guide。
UTF-8的一些介绍:
1.UTF-8如何分辨中文、英文等等?
UTF-8使用1~4字节为每个字符编码:
一个US-ASCIl字符只需1字节编码(Unicode范围由U+0000~U+007F)。
带有变音符号的拉丁文、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文等字母则需要2字节编码(Unicode范围由U+0080~U+07FF)。
其他语言的字符(包括中日韩文字、东南亚文字、中东文字等)包含了大部分常用字,使用3字节编码。
其他极少使用的语言字符使用4字节编码。
而且,每个变长的编码都有固定开头
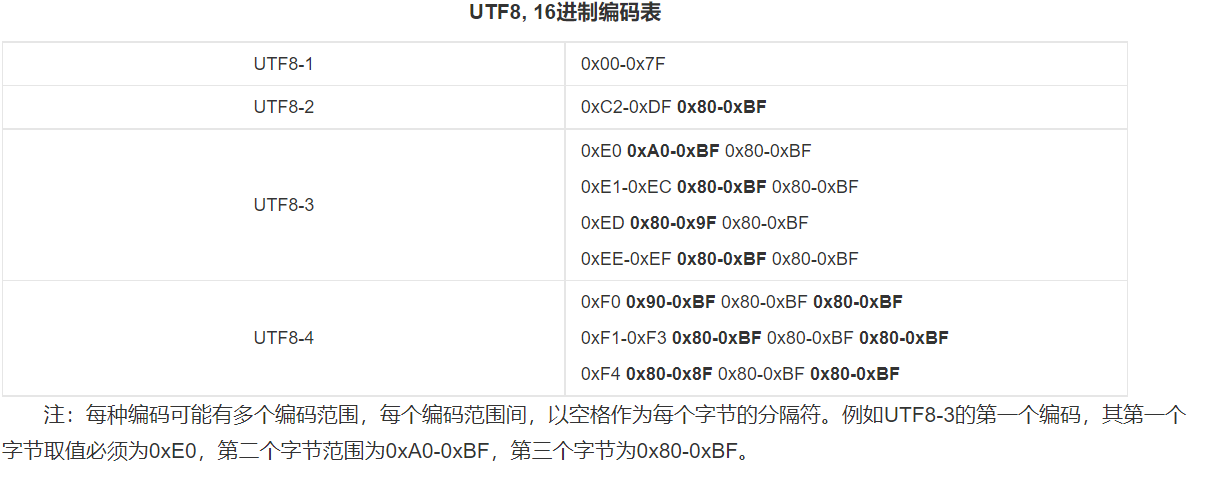
Writer(字符输出流)
Writer用于将数据(字符信息)写入到目的地(通常是文件),java.io.Writer抽象类是所有字节输出流的父类。
Writer 常用方法 :
write(int c): 写入单个字符。write(char[] cbuf):写入字符数组cbuf,等价于write(cbuf, 0, cbuf.length)。write(char[] cbuf, int off, int len):在write(char[] cbuf)方法的基础上增加了off参数(偏移量)和len参数(要读取的最大字节数)。write(String str):写入字符串,等价于write(str, 0, str.length())。write(String str, int off, int len):在write(String str)方法的基础上增加了off参数(偏移量)和len参数(要读取的最大字节数)。append(CharSequence csq):将指定的字符序列附加到指定的Writer对象并返回该Writer对象。append(char c):将指定的字符附加到指定的Writer对象并返回该Writer对象。flush():刷新此输出流并强制写出所有缓冲的输出字符。close():关闭输出流释放相关的系统资源。
OutputStreamWriter 是字符流转换为字节流的桥梁,其子类 FileWriter 是基于该基础上的封装,可以直接将字符写入到文件。
// 字符流转换为字节流的桥梁
public class OutputStreamWriter extends Writer {
}
// 用于写入字符到文件
public class FileWriter extends OutputStreamWriter {
}
FileWriter 代码示例:
try (Writer output = new FileWriter("output.txt")) {
output.write("你好,我是Guide。");
} catch (IOException e) {
e.printStackTrace();
}
输出结果:
字节缓冲流
IO 操作是很消耗性能的,缓冲流将数据加载至缓冲区,一次性读取/写入多个字节,从而避免频繁的 IO 操作,提高流的传输效率。字节缓冲流这里采用了装饰器模式来增强 InputStream 和OutputStream子类对象的功能。
举个例子,我们可以通过 BufferedInputStream(字节缓冲输入流)来增强 FileInputStream 的功能。
// 新建一个 BufferedInputStream 对象
BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("input.txt"));
字节流和字节缓冲流的性能差别主要体现在我们使用两者的时候都是调用 write(int b) 和 read() 这两个一次只读取一个字节的方法的时候。由于字节缓冲流内部有缓冲区(字节数组),因此,字节缓冲流会先将读取到的字节存放在缓存区,大幅减少 IO 次数,提高读取效率。
我使用 write(int b) 和 read() 方法,分别通过字节流和字节缓冲流复制一个 524.9 mb 的 PDF 文件耗时对比如下:
使用缓冲流复制PDF文件总耗时:15428 毫秒
使用普通字节流复制PDF文件总耗时:2555062 毫秒
两者耗时差别非常大,缓冲流耗费的时间是字节流的 1/165。
测试代码如下:
@Test
void copy_pdf_to_another_pdf_buffer_stream() {
// 记录开始时间
long start = System.currentTimeMillis();
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream("深入理解计算机操作系统.pdf"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("深入理解计算机操作系统-副本.pdf"))) {
int content;
while ((content = bis.read()) != -1) {
bos.write(content);
}
} catch (IOException e) {
e.printStackTrace();
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("使用缓冲流复制PDF文件总耗时:" + (end - start) + " 毫秒");
}
@Test
void copy_pdf_to_another_pdf_stream() {
// 记录开始时间
long start = System.currentTimeMillis();
try (FileInputStream fis = new FileInputStream("深入理解计算机操作系统.pdf");
FileOutputStream fos = new FileOutputStream("深入理解计算机操作系统-副本.pdf")) {
int content;
while ((content = fis.read()) != -1) {
fos.write(content);
}
} catch (IOException e) {
e.printStackTrace();
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("使用普通流复制PDF文件总耗时:" + (end - start) + " 毫秒");
}
如果是调用 read(byte b[]) 和 write(byte b[], int off, int len) 这两个写入一个字节数组的方法的话,只要字节数组的大小合适,两者的性能差距其实不大,基本可以忽略。
这次我们使用 read(byte b[]) 和 write(byte b[], int off, int len) 方法,分别通过字节流和字节缓冲流复制一个 524.9 mb 的 PDF 文件耗时对比如下:
使用缓冲流复制PDF文件总耗时:695 毫秒
使用普通字节流复制PDF文件总耗时:989 毫秒
两者耗时差别不是很大,缓冲流的性能要略微好一点点。
测试代码如下:
@Test
void copy_pdf_to_another_pdf_with_byte_array_buffer_stream() {
// 记录开始时间
long start = System.currentTimeMillis();
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream("深入理解计算机操作系统.pdf"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("深入理解计算机操作系统-副本.pdf"))) {
int len;
byte[] bytes = new byte[4 * 1024];
while ((len = bis.read(bytes)) != -1) {
bos.write(bytes, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("使用缓冲流复制PDF文件总耗时:" + (end - start) + " 毫秒");
}
@Test
void copy_pdf_to_another_pdf_with_byte_array_stream() {
// 记录开始时间
long start = System.currentTimeMillis();
try (FileInputStream fis = new FileInputStream("深入理解计算机操作系统.pdf");
FileOutputStream fos = new FileOutputStream("深入理解计算机操作系统-副本.pdf")) {
int len;
byte[] bytes = new byte[4 * 1024];
while ((len = fis.read(bytes)) != -1) {
fos.write(bytes, 0, len);
}
} catch (IOException e) {
e.printStackTrace();
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("使用普通流复制PDF文件总耗时:" + (end - start) + " 毫秒");
}
BufferedInputStream(字节缓冲输入流)
BufferedInputStream 从源头(通常是文件)读取数据(字节信息)到内存的过程中不会一个字节一个字节的读取,而是会先将读取到的字节存放在缓存区,并从内部缓冲区中单独读取字节。这样大幅减少了 IO 次数,提高了读取效率。
BufferedInputStream 内部维护了一个缓冲区,这个缓冲区实际就是一个字节数组,通过阅读 BufferedInputStream 源码即可得到这个结论。
public
class BufferedInputStream extends FilterInputStream {
// 内部缓冲区数组
protected volatile byte buf[];
// 缓冲区的默认大小
private static int DEFAULT_BUFFER_SIZE = 8192;
// 使用默认的缓冲区大小
public BufferedInputStream(InputStream in) {
this(in, DEFAULT_BUFFER_SIZE);
}
// 自定义缓冲区大小
public BufferedInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
}
缓冲区的大小默认为 8192 字节,当然了,你也可以通过 BufferedInputStream(InputStream in, int size) 这个构造方法来指定缓冲区的大小。
BufferedOutputStream(字节缓冲输出流)
BufferedOutputStream 将数据(字节信息)写入到目的地(通常是文件)的过程中不会一个字节一个字节的写入,而是会先将要写入的字节存放在缓存区,并从内部缓冲区中单独写入字节。这样大幅减少了 IO 次数,提高了读取效率
try (BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("output.txt"))) {
byte[] array = "JavaGuide".getBytes();
bos.write(array);
} catch (IOException e) {
e.printStackTrace();
}
类似于 BufferedInputStream ,BufferedOutputStream 内部也维护了一个缓冲区,并且,这个缓存区的大小也是 8192 字节。
字符缓冲流
BufferedReader (字符缓冲输入流)和 BufferedWriter(字符缓冲输出流)类似于 BufferedInputStream(字节缓冲输入流)和BufferedOutputStream(字节缓冲输入流),内部都维护了一个字节数组作为缓冲区。不过,前者主要是用来操作字符信息。
打印流
下面这段代码大家经常使用吧?
System.out.print("Hello!");
System.out.println("Hello!");
System.out 实际是用于获取一个 PrintStream 对象,print方法实际调用的是 PrintStream 对象的 write 方法。
PrintStream 属于字节打印流,与之对应的是 PrintWriter (字符打印流)。PrintStream 是 OutputStream 的子类,PrintWriter 是 Writer 的子类。
public class PrintStream extends FilterOutputStream
implements Appendable, Closeable {
}
public class PrintWriter extends Writer {
}
随机访问流
这里要介绍的随机访问流指的是支持随意跳转到文件的任意位置进行读写的 RandomAccessFile 。
RandomAccessFile 的构造方法如下,我们可以指定 mode(读写模式)。
// openAndDelete 参数默认为 false 表示打开文件并且这个文件不会被删除
public RandomAccessFile(File file, String mode)
throws FileNotFoundException {
this(file, mode, false);
}
// 私有方法
private RandomAccessFile(File file, String mode, boolean openAndDelete) throws FileNotFoundException{
// 省略大部分代码
}
读写模式主要有下面四种:
r: 只读模式。rw: 读写模式rws: 相对于rw,rws同步更新对“文件的内容”或“元数据”的修改到外部存储设备。rwd: 相对于rw,rwd同步更新对“文件的内容”的修改到外部存储设备。
文件内容指的是文件中实际保存的数据,元数据则是用来描述文件属性比如文件的大小信息、创建和修改时间。
RandomAccessFile 中有一个文件指针用来表示下一个将要被写入或者读取的字节所处的位置。我们可以通过 RandomAccessFile 的 seek(long pos) 方法来设置文件指针的偏移量(距文件开头 pos 个字节处)。如果想要获取文件指针当前的位置的话,可以使用 getFilePointer() 方法。
RandomAccessFile 代码示例:
RandomAccessFile randomAccessFile = new RandomAccessFile(new File("input.txt"), "rw");
System.out.println("读取之前的偏移量:" + randomAccessFile.getFilePointer() + ",当前读取到的字符" + (char) randomAccessFile.read() + ",读取之后的偏移量:" + randomAccessFile.getFilePointer());
// 指针当前偏移量为 6
randomAccessFile.seek(6);
System.out.println("读取之前的偏移量:" + randomAccessFile.getFilePointer() + ",当前读取到的字符" + (char) randomAccessFile.read() + ",读取之后的偏移量:" + randomAccessFile.getFilePointer());
// 从偏移量 7 的位置开始往后写入字节数据
randomAccessFile.write(new byte[]{'H', 'I', 'J', 'K'});
// 指针当前偏移量为 0,回到起始位置
randomAccessFile.seek(0);
System.out.println("读取之前的偏移量:" + randomAccessFile.getFilePointer() + ",当前读取到的字符" + (char) randomAccessFile.read() + ",读取之后的偏移量:" + randomAccessFile.getFilePointer());
input.txt 文件内容: ABCDEFG
输出:
读取之前的偏移量:0,当前读取到的字符A,读取之后的偏移量:1
读取之前的偏移量:6,当前读取到的字符G,读取之后的偏移量:7
读取之前的偏移量:0,当前读取到的字符A,读取之后的偏移量:1
input.txt 文件内容变为 ABCDEFGHIJK 。
RandomAccessFile 的 write 方法在写入对象的时候如果对应的位置已经有数据的话,会将其覆盖掉。
RandomAccessFile randomAccessFile = new RandomAccessFile(new File("input.txt"), "rw");
randomAccessFile.write(new byte[]{'H', 'I', 'J', 'K'});
假设运行上面这段程序之前 input.txt 文件内容变为 ABCD ,运行之后则变为 HIJK 。
RandomAccessFile 比较常见的一个应用就是实现大文件的 断点续传 。何谓断点续传?简单来说就是上传文件中途暂停或失败(比如遇到网络问题)之后,不需要重新上传,只需要上传那些未成功上传的文件分片即可。分片(先将文件切分成多个文件分片)上传是断点续传的基础。
Java IO设计模式总结
装饰器模式
装饰器(Decorator)模式 可以在不改变原有对象的情况下拓展其功能。
装饰器模式通过组合替代继承来扩展原始类的功能,在一些继承关系比较复杂的场景(IO 这一场景各种类的继承关系就比较复杂)更加实用。
对于字节流来说, FilterInputStream (对应输入流)和FilterOutputStream(对应输出流)是装饰器模式的核心,分别用于增强 InputStream 和OutputStream子类对象的功能。
我们常见的BufferedInputStream(字节缓冲输入流)、DataInputStream 等等都是FilterInputStream 的子类,BufferedOutputStream(字节缓冲输出流)、DataOutputStream等等都是FilterOutputStream的子类。
举个例子,我们可以通过 BufferedInputStream(字节缓冲输入流)来增强 FileInputStream 的功能。
BufferedInputStream 构造函数如下:
public BufferedInputStream(InputStream in) {
this(in, DEFAULT_BUFFER_SIZE);
}
public BufferedInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
可以看出,BufferedInputStream 的构造函数其中的一个参数就是 InputStream ,从而增强FileInputStream。BufferedInputStream 代码示例:
BufferedInputStream 代码示例:
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream("input.txt"))) {
int content;
long skip = bis.skip(2);
while ((content = bis.read()) != -1) {
System.out.print((char) content);
}
} catch (IOException e) {
e.printStackTrace();
}
这个时候,你可以会想了:为啥我们直接不弄一个BufferedFileInputStream(字符缓冲文件输入流)呢?
BufferedFileInputStream bfis = new BufferedFileInputStream("input.txt");
如果 InputStream的子类比较少的话,这样做是没问题的。不过, InputStream的子类实在太多,继承关系也太复杂了。如果我们为每一个子类都定制一个对应的缓冲输入流,那岂不是太麻烦了。如果你对 IO 流比较熟悉的话,你会发现ZipInputStream 和ZipOutputStream 还可以分别增强 BufferedInputStream 和 BufferedOutputStream 的能力。
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(fileName));
ZipInputStream zis = new ZipInputStream(bis);
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(fileName));
ZipOutputStream zipOut = new ZipOutputStream(bos);
ZipInputStream 和ZipOutputStream 分别继承自InflaterInputStream 和DeflaterOutputStream。
public
class InflaterInputStream extends FilterInputStream {
}
public
class DeflaterOutputStream extends FilterOutputStream {
}
这也是装饰器模式很重要的一个特征,那就是可以对原始类嵌套使用多个装饰器。为了实现这一效果,装饰器类需要跟原始类继承相同的抽象类或者实现相同的接口。上面介绍到的这些 IO 相关的装饰类和原始类共同的父类是 InputStream 和OutputStream。
对于字符流来说,BufferedReader 可以用来增加 Reader (字符输入流)子类的功能,BufferedWriter 可以用来增加 Writer (字符输出流)子类的功能。
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(fileName), "UTF-8"));
IO 流中的装饰器模式应用的例子实在是太多了,不需要特意记忆,完全没必要哈!搞清了装饰器模式的核心之后,你在使用的时候自然就会知道哪些地方运用到了装饰器模式。
适配器模式
适配器(Adapter Pattern)模式 主要用于接口互不兼容的类的协调工作,你可以将其联想到我们日常经常使用的电源适配器。
适配器模式中存在被适配的对象或者类称为 适配者(Adaptee) ,作用于适配者的对象或者类称为适配器(Adapter) 。适配器分为对象适配器和类适配器。类适配器使用继承关系来实现,对象适配器使用组合关系来实现。
IO 流中的字符流和字节流的接口不同,它们之间可以协调工作就是基于适配器模式来做的,更准确点来说是对象适配器。通过适配器,我们可以将字节流对象适配成一个字符流对象,这样我们可以直接通过字节流对象来读取或者写入字符数据。
InputStreamReader 和 OutputStreamWriter 就是两个适配器(Adapter), 同时,它们两个也是字节流和字符流之间的桥梁。InputStreamReader 使用 StreamDecoder (流解码器)对字节进行解码,实现字节流到字符流的转换, OutputStreamWriter 使用StreamEncoder(流编码器)对字符进行编码,实现字符流到字节流的转换。
InputStream 和 OutputStream 的子类是被适配者, InputStreamReader 和 OutputStreamWriter是适配器。
// InputStreamReader 是适配器,FileInputStream 是被适配的类
InputStreamReader isr = new InputStreamReader(new FileInputStream(fileName), "UTF-8");
// BufferedReader 增强 InputStreamReader 的功能(装饰器模式)
BufferedReader bufferedReader = new BufferedReader(isr);
java.io.InputStreamReader 部分源码:
public class InputStreamReader extends Reader {
//用于解码的对象
private final StreamDecoder sd;
public InputStreamReader(InputStream in) {
super(in);
try {
// 获取 StreamDecoder 对象
sd = StreamDecoder.forInputStreamReader(in, this, (String)null);
} catch (UnsupportedEncodingException e) {
throw new Error(e);
}
}
// 使用 StreamDecoder 对象做具体的读取工作
public int read() throws IOException {
return sd.read();
}
}
java.io.OutputStreamWriter 部分源码:
public class OutputStreamWriter extends Writer {
// 用于编码的对象
private final StreamEncoder se;
public OutputStreamWriter(OutputStream out) {
super(out);
try {
// 获取 StreamEncoder 对象
se = StreamEncoder.forOutputStreamWriter(out, this, (String)null);
} catch (UnsupportedEncodingException e) {
throw new Error(e);
}
}
// 使用 StreamEncoder 对象做具体的写入工作
public void write(int c) throws IOException {
se.write(c);
}
}
适配器模式和装饰器模式有什么区别呢?
装饰器模式 更侧重于动态地增强原始类的功能,装饰器类需要跟原始类继承相同的抽象类或者实现相同的接口。并且,装饰器模式支持对原始类嵌套使用多个装饰器。
适配器模式 更侧重于让接口不兼容而不能交互的类可以一起工作,当我们调用适配器对应的方法时,适配器内部会调用适配者类或者和适配类相关的类的方法,这个过程透明的。就比如说 StreamDecoder (流解码器)和StreamEncoder(流编码器)就是分别基于 InputStream 和 OutputStream 来获取 FileChannel对象并调用对应的 read 方法和 write 方法进行字节数据的读取和写入。
StreamDecoder(InputStream in, Object lock, CharsetDecoder dec) {
// 省略大部分代码
// 根据 InputStream 对象获取 FileChannel 对象
ch = getChannel((FileInputStream)in);
}
适配器和适配者两者不需要继承相同的抽象类或者实现相同的接口。
另外,FutrueTask 类使用了适配器模式,Executors 的内部类 RunnableAdapter 实现属于适配器,用于将 Runnable 适配成 Callable。
FutureTask参数包含 Runnable 的一个构造方法:
public FutureTask(Runnable runnable, V result) {
// 调用 Executors 类的 callable 方法
this.callable = Executors.callable(runnable, result);
this.state = NEW;
}
Executors中对应的方法和适配器:
// 实际调用的是 Executors 的内部类 RunnableAdapter 的构造方法
public static <T> Callable<T> callable(Runnable task, T result) {
if (task == null)
throw new NullPointerException();
return new RunnableAdapter<T>(task, result);
}
// 适配器
static final class RunnableAdapter<T> implements Callable<T> {
final Runnable task;
final T result;
RunnableAdapter(Runnable task, T result) {
this.task = task;
this.result = result;
}
public T call() {
task.run();
return result;
}
}
工厂模式
工厂模式用于创建对象,NIO 中大量用到了工厂模式,比如 Files 类的 newInputStream 方法用于创建 InputStream 对象(静态工厂)、 Paths 类的 get 方法创建 Path 对象(静态工厂)、ZipFileSystem 类(sun.nio包下的类,属于 java.nio 相关的一些内部实现)的 getPath 的方法创建 Path 对象(简单工厂)。
InputStream is = Files.newInputStream(Paths.get(generatorLogoPath))
观察者模式
NIO 中的文件目录监听服务使用到了观察者模式。NIO 中的文件目录监听服务基于 WatchService 接口和 Watchable 接口。WatchService 属于观察者,Watchable 属于被观察者。
Watchable 接口定义了一个用于将对象注册到 WatchService(监控服务) 并绑定监听事件的方法 register 。
public interface Path
extends Comparable<Path>, Iterable<Path>, Watchable{
}
public interface Watchable {
WatchKey register(WatchService watcher,
WatchEvent.Kind<?>[] events,
WatchEvent.Modifier... modifiers)
throws IOException;
}
WatchService 用于监听文件目录的变化,同一个 WatchService 对象能够监听多个文件目录。
// 创建 WatchService 对象
WatchService watchService = FileSystems.getDefault().newWatchService();
// 初始化一个被监控文件夹的 Path 类:
Path path = Paths.get("workingDirectory");
// 将这个 path 对象注册到 WatchService(监控服务) 中去
WatchKey watchKey = path.register(watchService, StandardWatchEventKinds...);
Path 类 register 方法的第二个参数 events (需要监听的事件)为可变长参数,也就是说我们可以同时监听多种事件。
WatchKey register(WatchService watcher,
WatchEvent.Kind<?>... events)
throws IOException;
常用的监听事件有 3 种:
StandardWatchEventKinds.ENTRY_CREATE:文件创建。StandardWatchEventKinds.ENTRY_DELETE: 文件删除。StandardWatchEventKinds.ENTRY_MODIFY: 文件修改。
register 方法返回 WatchKey 对象,通过WatchKey 对象可以获取事件的具体信息比如文件目录下是创建、删除还是修改了文件、创建、删除或者修改的文件的具体名称是什么。
WatchKey key;
while ((key = watchService.take()) != null) {
for (WatchEvent<?> event : key.pollEvents()) {
// 可以调用 WatchEvent 对象的方法做一些事情比如输出事件的具体上下文信息
}
key.reset();
}
WatchService 内部是通过一个 daemon thread(守护线程)采用定期轮询的方式来检测文件的变化,简化后的源码如下所示。
class PollingWatchService extends AbstractWatchService
{
// 定义一个 daemon thread(守护线程)轮询检测文件变化
private final ScheduledExecutorService scheduledExecutor;
PollingWatchService() {
scheduledExecutor = Executors
.newSingleThreadScheduledExecutor(new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setDaemon(true);
return t;
}});
}
void enable(Set<? extends WatchEvent.Kind<?>> events, long period) {
synchronized (this) {
// 更新监听事件
this.events = events;
// 开启定期轮询
Runnable thunk = new Runnable() { public void run() { poll(); }};
this.poller = scheduledExecutor
.scheduleAtFixedRate(thunk, period, period, TimeUnit.SECONDS);
}
}
}
Java IO模型详解
前言
I/O 一直是很多小伙伴难以理解的一个知识点,这篇文章我会将我所理解的 I/O 讲给你听,希望可以对你有所帮助。
I/O
何为 I/O?
I/O(Input/Outpu) 即输入/输出 。
我们先从计算机结构的角度来解读一下 I/O。
根据冯.诺依曼结构,计算机结构分为 5 大部分:运算器、控制器、存储器、输入设备、输出设备。
输入设备(比如键盘)和输出设备(比如显示器)都属于外部设备。网卡、硬盘这种既可以属于输入设备,也可以属于输出设备。输入设备向计算机输入数据,输出设备接收计算机输出的数据。
从计算机结构的视角来看的话, I/O 描述了计算机系统与外部设备之间通信的过程。
我们再先从应用程序的角度来解读一下 I/O。根据大学里学到的操作系统相关的知识:为了保证操作系统的稳定性和安全性,一个进程的地址空间划分为 用户空间(User space) 和 内核空间(Kernel space ) 。
像我们平常运行的应用程序都是运行在用户空间,只有内核空间才能进行系统态级别的资源有关的操作,比如文件管理、进程通信、内存管理等等。也就是说,我们想要进行 IO 操作,一定是要依赖内核空间的能力。并且,用户空间的程序不能直接访问内核空间。当想要执行 IO 操作时,由于没有执行这些操作的权限,只能发起系统调用请求操作系统帮忙完成。因此,用户进程想要执行 IO 操作的话,必须通过 系统调用 来间接访问内核空间
我们在平常开发过程中接触最多的就是 磁盘 IO(读写文件) 和 网络 IO(网络请求和响应)。
从应用程序的视角来看的话,我们的应用程序对操作系统的内核发起 IO 调用(系统调用),操作系统负责的内核执行具体的 IO 操作。也就是说,我们的应用程序实际上只是发起了 IO 操作的调用而已,具体 IO 的执行是由操作系统的内核来完成的。
当应用程序发起 I/O 调用后,会经历两个步骤:
- 内核等待 I/O 设备准备好数据
- 内核将数据从内核空间拷贝到用户空间。
有哪些常见的 IO 模型?
UNIX 系统下, IO 模型一共有 5 种: 同步阻塞 I/O、同步非阻塞 I/O、I/O 多路复用、信号驱动 I/O 和异步 I/O。这也是我们经常提到的 5 种 IO 模型。
Java 中 3 种常见 IO 模型
参考
- 《深入拆解 Tomcat & Jetty》
- 如何完成一次 IO:https://llc687.top/126.html
- 程序员应该这样理解 IO:https://www.jianshu.com/p/fa7bdc4f3de7open in new window
- 10 分钟看懂, Java NIO 底层原理:https://www.cnblogs.com/crazymakercircle/p/10225159.html
- IO 模型知多少 | 理论篇:https://www.cnblogs.com/sheng-jie/p/how-much-you-know-about-io-models.html
- 《UNIX 网络编程 卷 1;套接字联网 API 》6.2 节 IO 模型
BIO (Blocking I/O)
BIO 属于同步阻塞 IO 模型 。同步阻塞 IO 模型中,应用程序发起 read 调用后,会一直阻塞,直到内核把数据拷贝到用户空间。
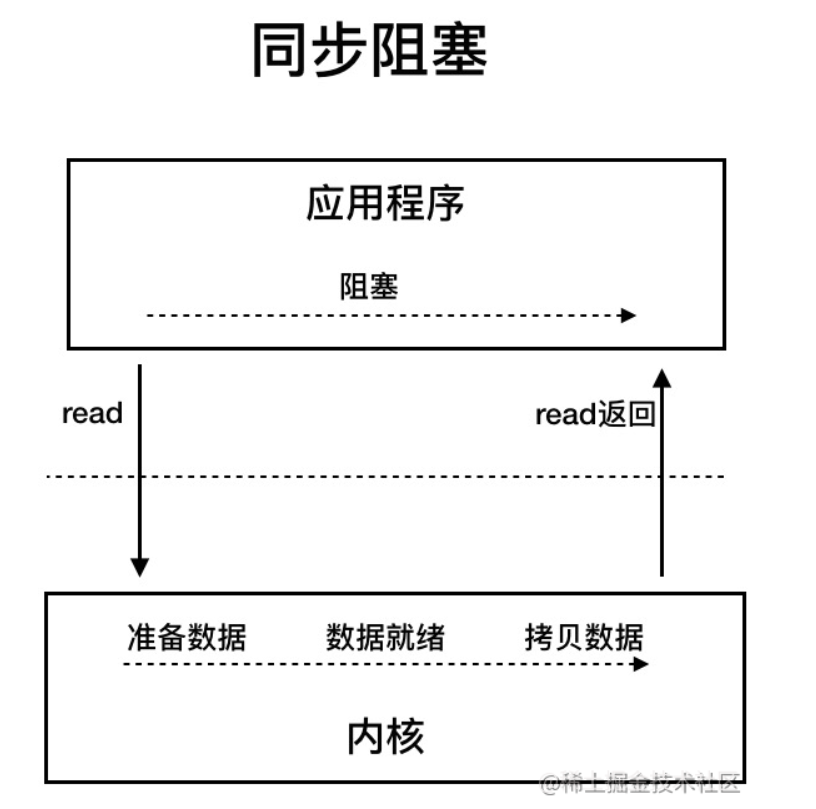
在客户端连接数量不高的情况下,是没问题的。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
NIO (Non-blocking/New I/O)
Java 中的 NIO 于 Java 1.4 中引入,对应 java.nio 包,提供了 Channel , Selector,Buffer 等抽象。NIO 中的 N 可以理解为 Non-blocking,不单纯是 New。它是支持面向缓冲的,基于通道的 I/O 操作方法。 对于高负载、高并发的(网络)应用,应使用 NIO 。Java 中的 NIO 可以看作是 I/O 多路复用模型。也有很多人认为,Java 中的 NIO 属于同步非阻塞 IO 模型。
跟着我的思路往下看看,相信你会得到答案!
我们先来看看 同步非阻塞 IO 模型。
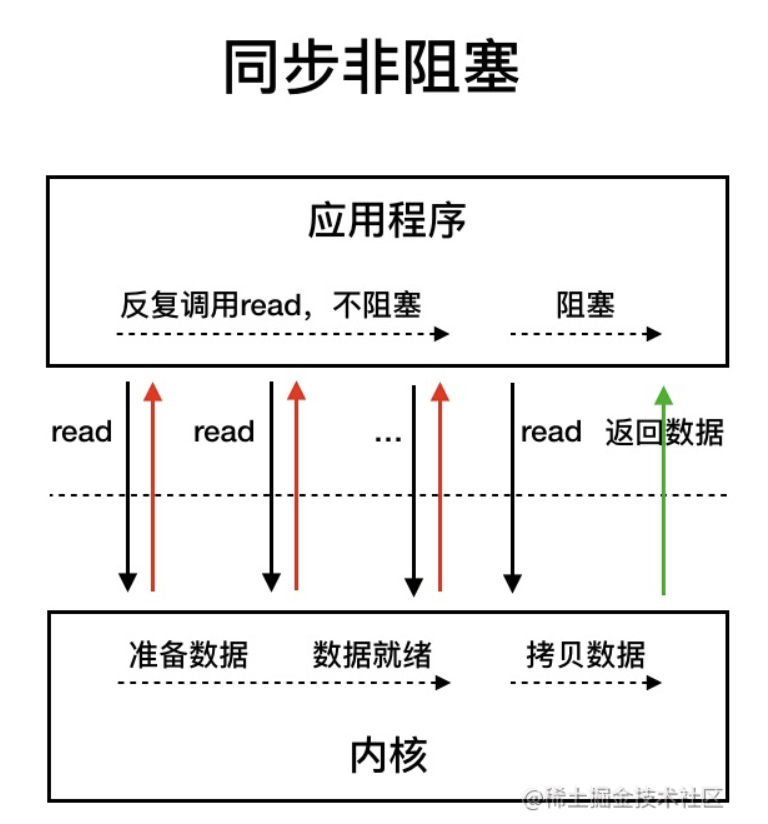
同步非阻塞 IO 模型中,应用程序会一直发起 read 调用,等待数据从内核空间拷贝到用户空间的这段时间里,线程依然是阻塞的,直到在内核把数据拷贝到用户空间。相比于同步阻塞 IO 模型,同步非阻塞 IO 模型确实有了很大改进。通过轮询操作,避免了一直阻塞。大白话就是,当不在拷贝数据(拷贝数据从内核空间到用户空间)时,你可以发起很多read,但是一旦拷贝正在进行,那么read就不能发起,即线程被阻塞,当拷贝完毕后,又可以read了。那么上图中红色的线条就代表着发起read后,系统还没有从内核空间中拷贝数据到用户空间中,这个时候就不能read到,所以read失败,隔一段时间再轮询着read,只要拷贝完毕了,那么就可以read到了,即绿色的线条。
但是,这种 IO 模型同样存在问题:应用程序不断进行 I/O 系统调用轮询数据是否已经准备好的过程是十分消耗 CPU 资源的。
这个时候,I/O 多路复用模型 就上场了。IO多路复用模型,就是通过一种新的系统调用,一个进程可以监视多个文件描述符,一旦某个描述符就绪(一般是内核缓冲区可读/可写),内核kernel能够通知程序进行相应的IO系统调用。
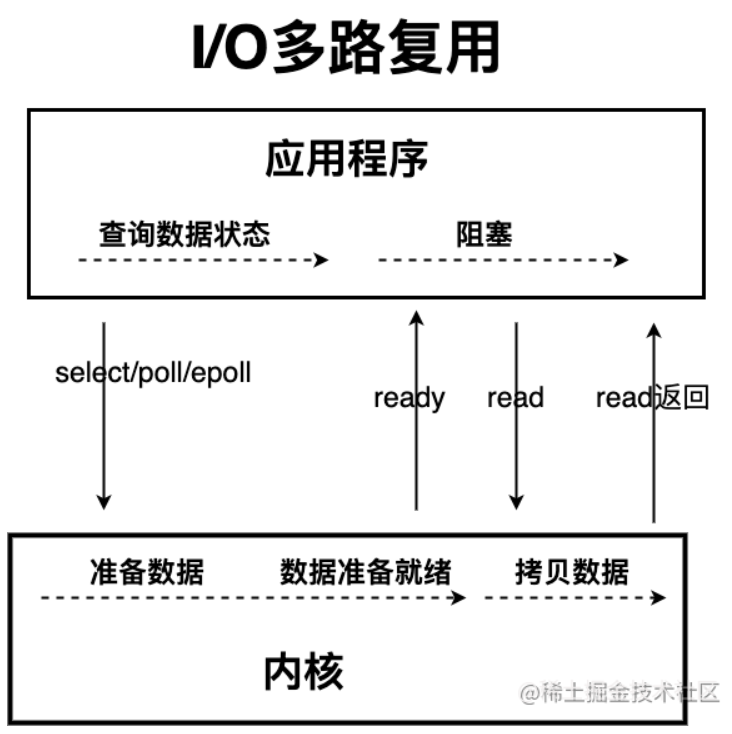
IO 多路复用模型中,应用程序的线程首先发起 select 调用,询问内核数据是否准备就绪,等内核把数据准备好了,用户线程再发起 read 调用。read 调用的过程(数据从内核空间 -> 用户空间)还是阻塞的。IO多路复用模型的基本原理就是select/epoll系统调用,单个线程不断的轮询select/epoll系统调用所负责的成百上千的socket连接,当某个或者某些socket网络连接有数据到达了,就返回这些可以读写的连接。因此,好处也就显而易见了——通过一次select/epoll系统调用,就查询到到可以读写的一个甚至是成百上千的网络连接。
目前支持 IO 多路复用的系统调用,有 select,epoll 等等。select 系统调用,目前几乎在所有的操作系统上都有支持。
- select 调用 :内核提供的系统调用,它支持一次查询多个系统调用的可用状态。几乎所有的操作系统都支持。
- epoll 调用 :linux 2.6 内核,属于 select 调用的增强版本,优化了 IO 的执行效率。
IO 多路复用模型,通过减少无效的系统调用,减少了对 CPU 资源的消耗。Java 中的 NIO ,有一个非常重要的选择器 ( Selector ) 的概念,也可以被称为 多路复用器。通过它,只需要一个线程便可以管理多个客户端连接。当客户端数据到了之后,才会为其服务。
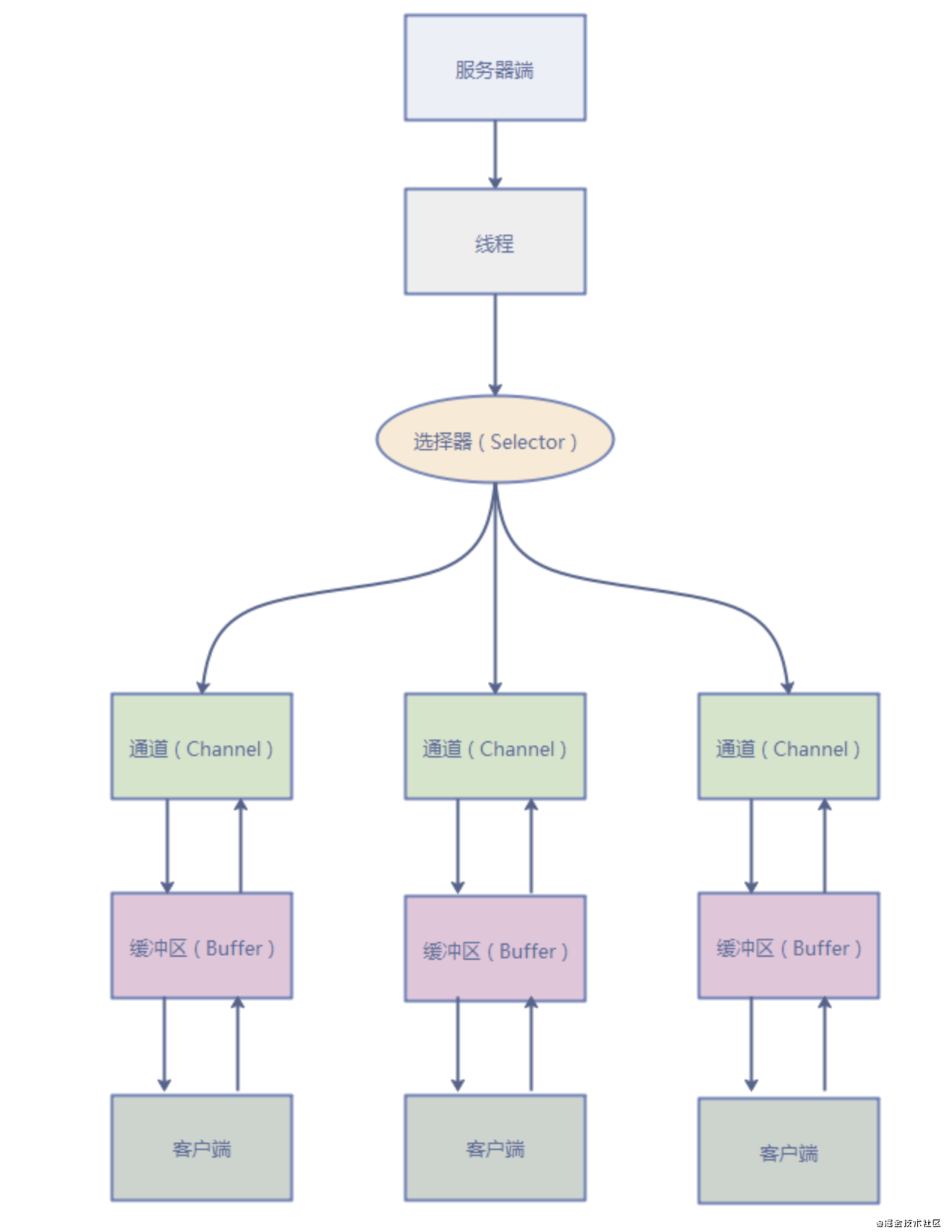
Java的NIO(new IO)技术,使用的就是IO多路复用模型。在linux系统上,使用的是epoll系统调用。
多路复用IO的缺点:本质上,select/epoll系统调用,属于同步IO,也是阻塞IO。都需要在读写事件就绪后,自己负责进行读写,也就是说这个读写过程是阻塞的。
IO多路复用的三种实现(对应三种系统调用)
参考select、poll、epoll详解_fyygree的博客-CSDN博客_epoll poll select和 彻底搞懂 select/poll/epoll,就这篇了!_Linux服务器开发的博客-CSDN博客_select/poll/epoll
1.select
IO多路复用模型是建立在内核提供的多路分离函数select基础之上的,使用select函数可以避免同步非阻塞IO模型中轮询等待的问题,即一次性将N个客户端socket连接传入内核然后阻塞,交由内核去轮询,当某一个或多个socket连接有事件发生时,解除阻塞并返回事件列表,用户进程在循环遍历处理有事件的socket连接。这样就避免了多次调用recv()系统调用,避免了用户态到内核态的切换。
select函数仅仅知道有几个I/O事件发生了,但并不知道具体是哪几个socket连接有I/O事件,还需要轮询去查找,时间复杂度为O(n),处理的请求数越多,所消耗的时间越长。
底层数据结构的实现
本质上是一个数组 + 队列实现的。
假设此时客户端发送了数据,网卡接收到的数据塞到对应的 socket 的接收队列中,此时 socket 知道来数据了,那如何唤醒 select 呢?其实每个 socket 有个属于自己的睡眠队列,select 会安排一个内应,即在被管理的 socket 的睡眠队列里面塞入一个 entry。
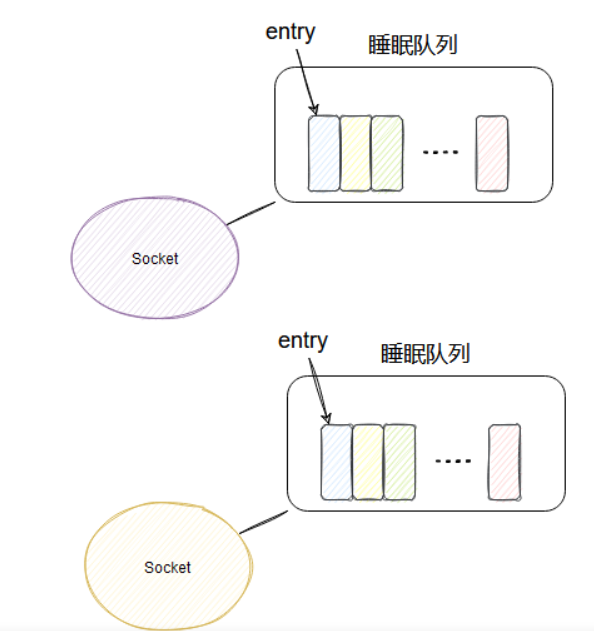
当 socket 接收到网卡的数据后,就会去它的睡眠队列里遍历 entry,调用 entry 设置的 callback 方法,这个 callback 方法里就能唤醒 select (select会轮询)! 所以 select 在每个被它管理的 socket 的睡眠队列里都塞入一个与它相关的 entry,这样不论哪个 socket 来数据了,它立马就能被唤醒然后干活! 但是,select 的实现不太好,因为唤醒的 select 此时只知道来活了,并不知道具体是哪个 socket 来数据了,所以只能傻傻地遍历所有 socket ,看看到底是哪个 scoket 来活了,然后把所有来活的 socket 封装成事件返回。
select函数执行流程
- 从用户空间拷贝fd_set(注册的事件集合)到内核空间
- 遍历所有fd文件(文件描述符,linux中,一切皆为文件,连接也是文件,有对应的文件描述符),并将当前进程挂到每个fd的等待队列中,当某个fd文件设备收到消息后,会唤醒设备等待队列上睡眠的进程,那么当前进程就会被唤醒
- 如果遍历完所有的fd没有I/O事件,则当前进程进入睡眠,当有某个fd文件有I/O事件或当前进程睡眠超时后,当前进程重新唤醒再次遍历所有fd文件
这里再提一嘴 select 的限制,因为被管理的 socket fd 需要从用户空间拷贝到内核空间,为了控制拷贝的大小而做了限制,即每个 select 能拷贝的 fds 集合大小只有1024。
select函数的缺点
- 单个进程所打开的FD是有限制的,通过
FD_SETSIZE设置,默认1024 - 每次调用 select,都需要把 fd 集合从用户态拷贝到内核态,这个开销在 fd 很多时会很大
- 每次调用select都需要将进程加入到所有监视socket的等待队列,每次唤醒都需要从每个队列中移除
- select函数在每次调用之前都要对参数进行重新设定,这样做比较麻烦,而且会降低性能
- 进程被唤醒后,程序并不知道哪些socket收到数据,还需要遍历一次
2.poll
poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间,然后查询每个fd对应的设备状态, 但是它没有最大连接数的限制,原因是它是基于链表来存储的
3.epoll
epoll可以理解为event pool,不同与select、poll的轮询机制,epoll采用的是事件驱动机制,每个fd上有注册有回调函数,当网卡接收到数据时会回调该函数,同时将该fd的引用放入rdlist就绪列表中。 当调用epoll_wait检查是否有事件发生时,只需要检查eventpoll对象中的rdlist双链表中是否有epitem元素即可。如果rdlist不为空,则把发生的事件复制到用户态,同时将事件数量返回给用户。
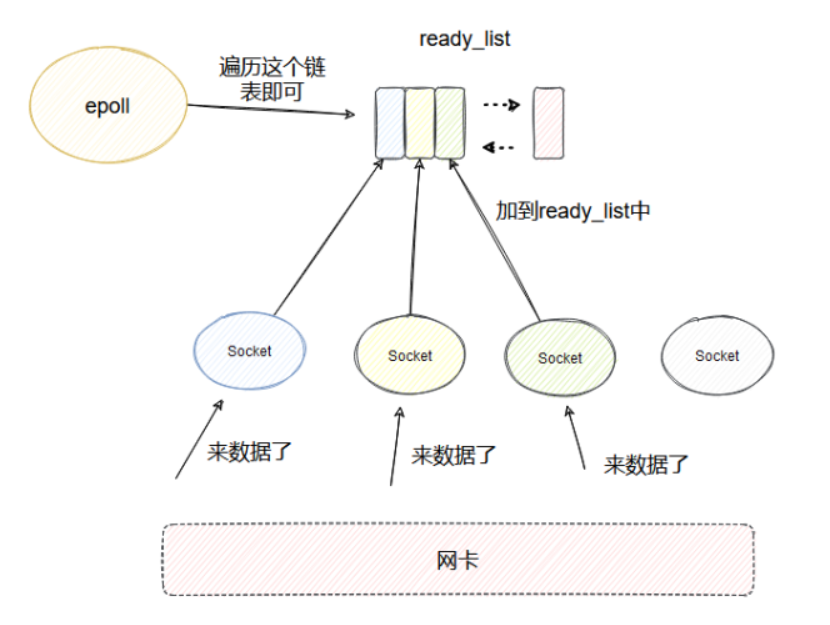
再补一张图
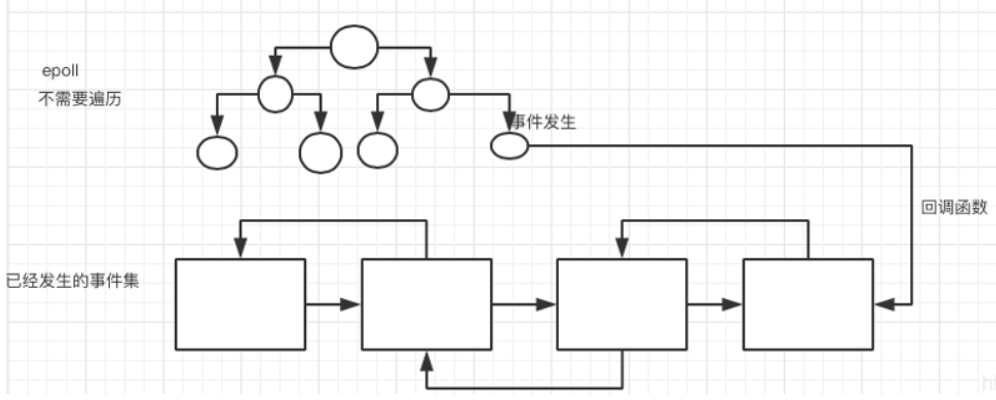
首先,搞了个叫 epoll_ctl 的方法,这方法就是用来管理维护 epoll 所监控的哪些 socket。如果你的 epoll 要新加一个 socket 来管理,那就调用 epoll_ctl,要删除一个 socket 也调用 epoll_ctl,通过不同的入参来控制增删改。这样,在内核里面就维护了此 epoll 管理的 socket 集合,这样就不用每次调用的时候都得把所有管理的 fds 拷贝到内核了。
这个 socket 集合是用红黑树实现的。这样被唤醒的 epoll 只需要遍历 ready_list 即可,这个链表里一定是有数据可读的 socket,相比于 select 就不会做无用的遍历了。 同时收集到的可读的 fd 按理是要拷贝到用户空间的,这里又做了个优化,利用了 mmp,让用户空间和内核空间映射到同一块内存中,这样就避免了拷贝。
epoll总结
- EPOLL支持的最大文件描述符上限是整个系统最大可打开的文件数目, 1G内存理论上最大创建10万个文件描述符
- 每个文件描述符上都有一个callback函数,当socket有事件发生时会回调这个函数将该fd的引用添加到就绪列表中,select和poll并不会明确指出是哪些文件描述符就绪,而epoll会。造成的区别就是,系统调用返回后,调用select和poll的程序需要遍历监听的整个文件描述符找到是谁处于就绪,而epoll则直接处理即可。
- select、poll采用轮询的方式来检查文件描述符是否处于就绪态,而epoll采用回调机制。造成的结果就是,随着fd的增加,select和poll的效率会线性降低,而epoll不会受到太大影响,除非活跃的socket很多
AIO (Asynchronous I/O)
AIO 也就是 NIO 2。Java 7 中引入了 NIO 的改进版 NIO 2,它是异步 IO 模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
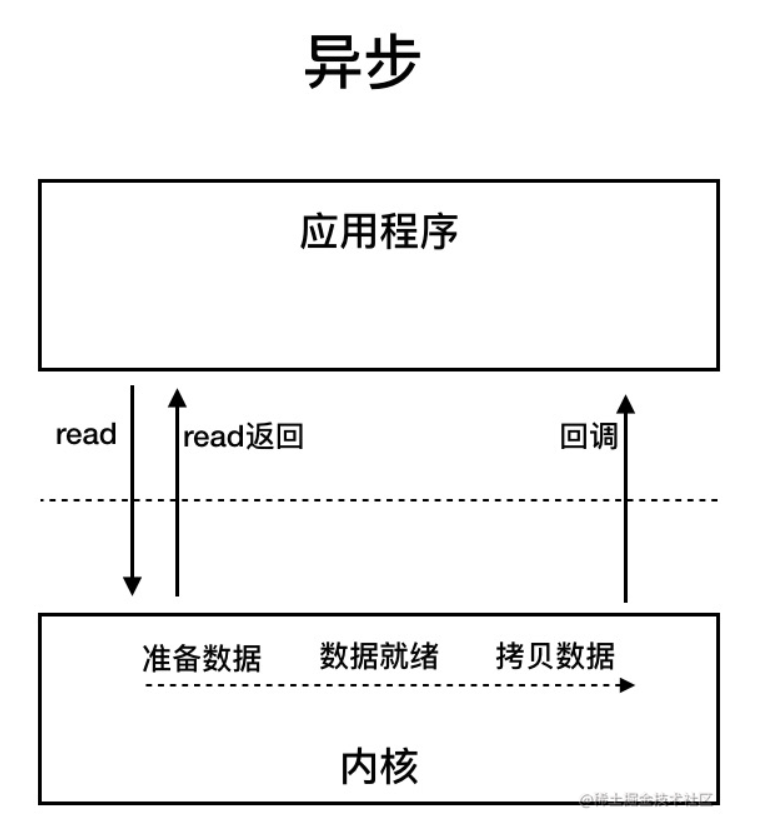
目前来说 AIO 的应用还不是很广泛。Netty 之前也尝试使用过 AIO,不过又放弃了。这是因为,Netty 使用了 AIO 之后,在 Linux 系统上的性能并没有多少提升。
异步IO模型缺点:
需要完成事件的注册与传递,这里边需要底层操作系统提供大量的支持,去做大量的工作。
目前来说, Windows 系统下通过 IOCP 实现了真正的异步 I/O。但是,就目前的业界形式来说,Windows 系统,很少作为百万级以上或者说高并发应用的服务器操作系统来使用。而在 Linux 系统下,异步IO模型在2.6版本才引入,目前并不完善。所以,这也是在 Linux 下,实现高并发网络编程时都是以 IO 复用模型模式为主。
最后,来一张图,简单总结一下 Java 中的 BIO、NIO、AIO。
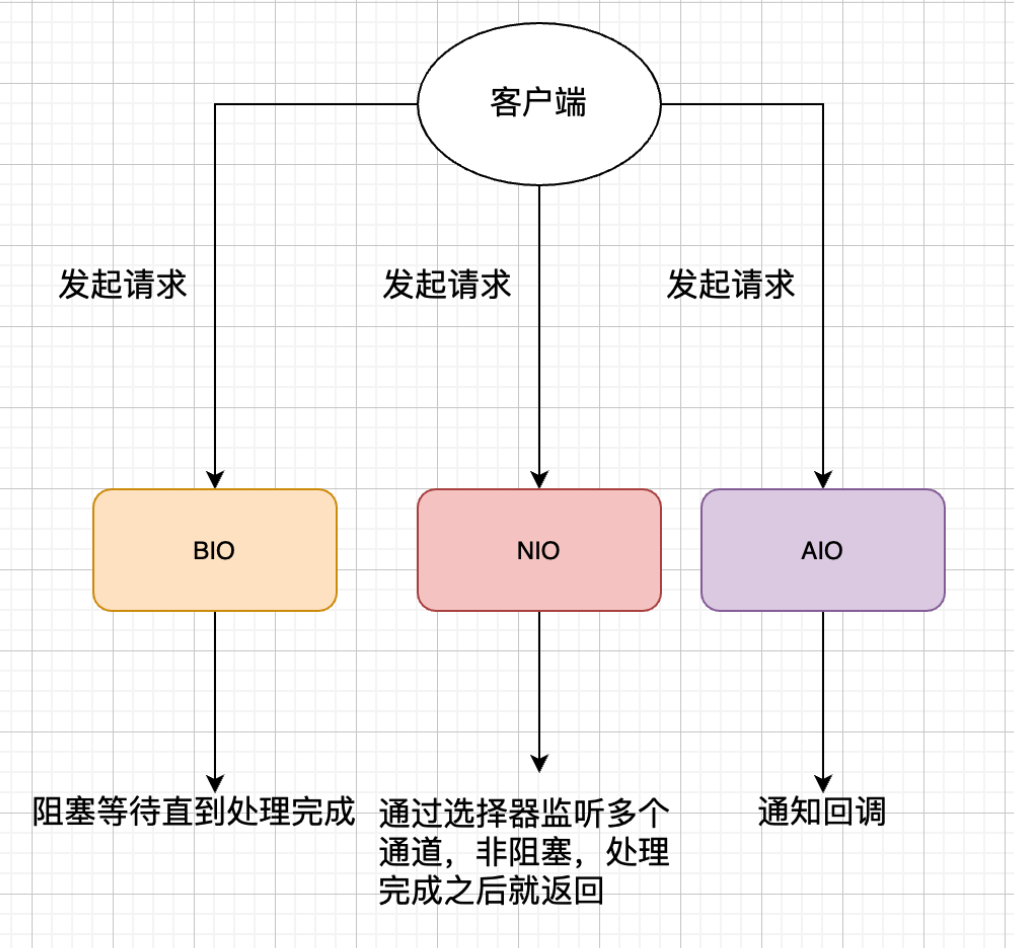

 浙公网安备 33010602011771号
浙公网安备 33010602011771号