LMCC 大模型学习记录
CH4 小结
神器,我还是小看VScode 了。

- 层归一化可以确保每个层的输出具有一致的均值和方差,从而稳定训练过程。
- 快捷连接是通过将一层的输出直接传递到更深层来跳过一个或多个层的连接,它能帮助缓解在训练深度神经网络(如大语言模型)时遇到的梯度消失问题。
- 作为GPT模型的核心模块组件,Transformer块融合了掩码多头注意力模块和使用GELU激活函数的全连接前馈神经网络。
- GPT模型是具有许多重复Transformer块的大语言模型,这些Transformer块有数百万到数十亿个参数。
- GPT模型具有多种规模,比如参数量分别为1.24亿、3.45亿、7.62亿和15.4亿的模型,我们可以使用相同的GPTModel Python类来实现它们。
- 类GPT大语言模型的文本生成能力涉及根据给定的输入上下文来逐个预测词元,然后将输出张量解码为人类可读的文本。
- 在没有训练的情况下,GPT 模型生成的文本是不连贯的,这显示了模型训练对于生成连贯文本的重要性。
CH3 小结
--!! 进行代码的整理。
- 注意力机制可以将输入元素转换为增强的上下文向量表示,这些表示涵盖了关于所有输入的信息。
- 自注意力机制通过对输入进行加权求和来计算上下文向量表示。
- 在简化的注意力机制中,注意力权重是通过点积计算得出的。
- 点积是两个向量的元素逐个相乘并将这些乘积相加的一种简洁计算方法。
- 尽管矩阵乘法不是必需的,但它可以通过替代嵌套的for循环使计算更高效、更紧凑。
- 在用于大语言模型的自注意力机制(也被称为“缩放点积注意力”)中,我们引入了可训练的权重矩阵来计算输入的中间变换:查询矩阵、值矩阵和键矩阵。
- 在处理从左到右读取和生成文本的大语言模型时,我们会添加一个因果注意力掩码,以防止模型访问未来的词元。
- 除了使用因果注意力掩码将注意力权重置0,还可以添加dropout掩码来减少大语言模型中的过拟合。
- 基于Transformer的大语言模型中的注意力模块涉及多个因果注意力实例,这被称为“多头注意力”。
- 可以通过堆叠多个因果注意力模块实例来创建多头注意力模块。
- 创建多头注意力模块的一种更高效的方法是使用批量矩阵乘法。
CH2 小结
- 由于大语言模型无法直接处理原始文本,因此我们必须将文本数据转换为名为“嵌入”的数值向量。嵌入将离散的数据(如词语或图像)映射到连续的向量空间,使其能够用于神经网络的训练。 (由于类 GPT大语言模型是使用反向传播算法(backpropagation algorithm)训练的深度神经网络,因此需要连续的向量表示或嵌入。 即让机器学习能够理解语义)
- 首先,原始文本被分解为词元,这些词元可能是单词或字符。然后,这些词元被转换为整数表示,即词元ID。
- 为了增强模型对不同上下文的理解和处理能力,可以引入诸如<|unk|>、<|endoftext|>等特殊词元,来处理未知词汇或在不相关的文本之间划分边界。
- 通过使用BPE分词器,GPT-2、GPT-3等大语言模型可以将未知词汇分解为子词单元或单个字符来有效地处理它们。
- 通过使用滑动窗口方法对已经分词的数据进行采样,可以生成大语言模型训练所需的输入-目标对。
- 作为一种查找操作,PyTorch中的嵌入层用来检索与词元ID对应的向量。所得的嵌入向量为词元提供了连续的表示形式,这对于训练像大语言模型这样的深度学习模型至关重要。
- 尽管词元嵌入为每个词元提供了一致的向量表示,但它们并不包含词元在序列中的位置信息。为了解决这一问题,通常采用两种位置嵌入策略:绝对位置嵌入和相对位置嵌入。
- OpenAI的GPT模型采用了绝对位置嵌入,这些嵌入被添加到词元嵌入向量中,并在模型训练过程中进行优化。
CH1 小结
- 大语言模型彻底革新了自然语言处理领域。在此之前,自然语言处理领域主要采用基于明确规则的系统和较为简单的统计方法。而如今,大语言模型的兴起为这一领域引入了
基于深度学习的新方法,在理解、生成和翻译人类语言方面取得了显著的进步。 - 现代大语言模型的训练主要包含两个步骤。
- 首先,在海量的无标注文本上进行预训练,将预测的句子中的下一个词作为“标签”。
- 随后,在更小规模且经过标注的目标数据集上进行微调,以遵循指令和执行分类任务。
- 大语言模型采用的是基于Transformer的架构。这一架构的核心组件是注意力机制,它使得大语言模型在逐词生成输出时,能够根据需要选择性地关注输入序列中的各个部分。
- 原始的Transformer架构由两部分组成:一个是用于解析文本的编码器,另一个是用于生成文本的解码器。
- 专注于生成文本和执行指令的大语言模型(如GPT-3和ChatGPT)只实现了解码器部分,从而简化了整个架构。
- 由数以亿计的语料构成的大型数据集是预训练大语言模型的关键。
- 尽管类GPT大语言模型的常规预训练任务是预测句子中的下一个词,但它们展现出了能够完成分类、翻译或总结文本等任务的“涌现”特性。
- 当一个大语言模型完成预训练后,该模型便能作为基础模型,通过高效的微调来适应各类下游任务。
- 在自定义数据集上进行微调的大语言模型能够在特定任务上超越通用的大语言模型。
CH0环境搭建
第一步:安装python
注:电脑上有python环境直接跳过这一步
访问 https://www.python.org/ 网页,在 Download 页面找到 Windows 进入,选择 Windows installer(64-bit) 下载(Python版本建议在3.10 - 3.13,下图示以3.11.9为例)
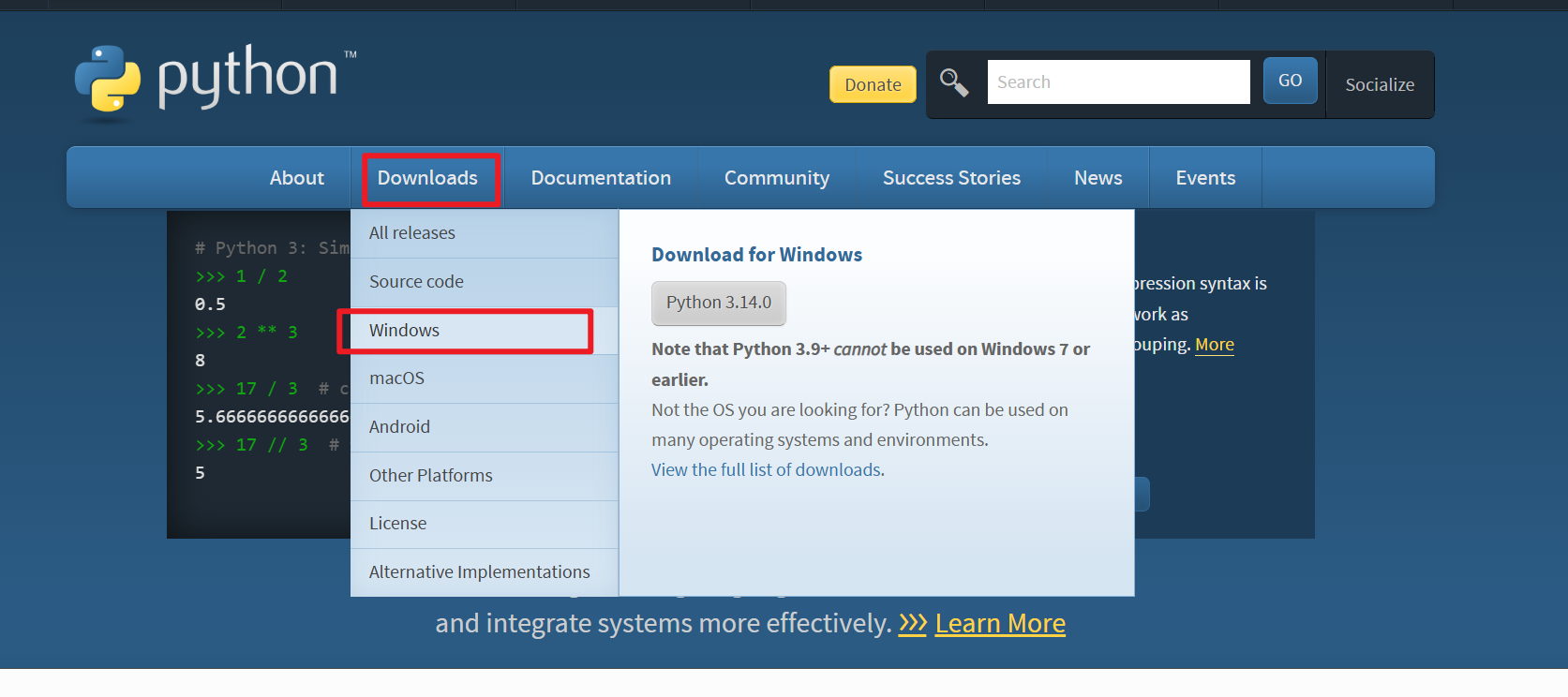
注意:win7系统不支持哦
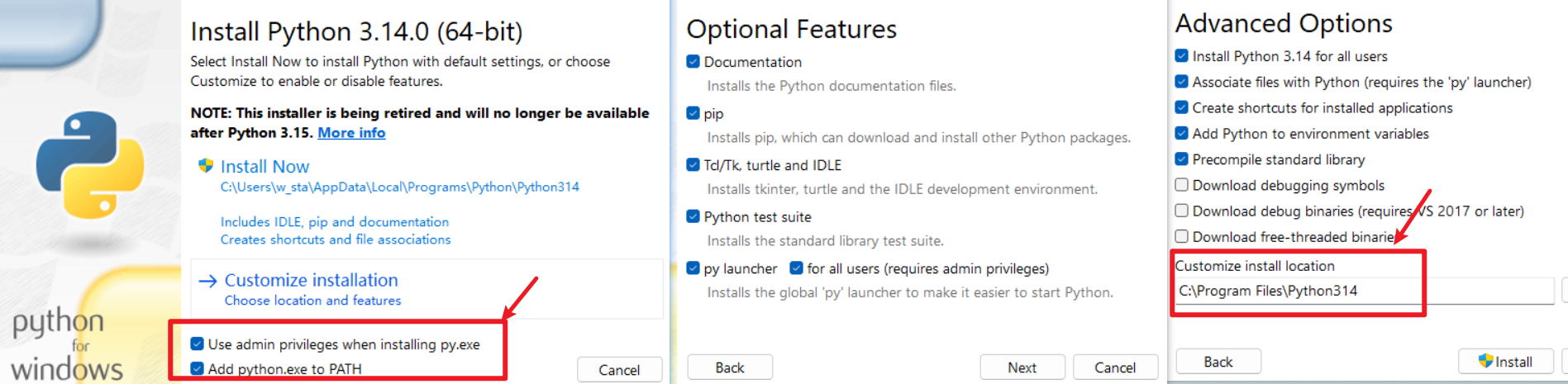
打开下载好的.exe文件进行安装,勾选 Add python.exe to PATH 和 Use admin privileges when installing py.exe,选择 Customize installation 进行下一步。
第二步:安装PyTorch
打开 任务管理器 → 性能 → GPU,查看显卡型号。
如果是 NVIDIA GeForce / RTX / Quadro / Tesla 等系列,继续下一步。
如果是 Intel 核显 或 AMD 显卡 → 只能使用 CPU 版本 的 PyTorch。
访问 https://pytorch.org 网页,点击 Get started。
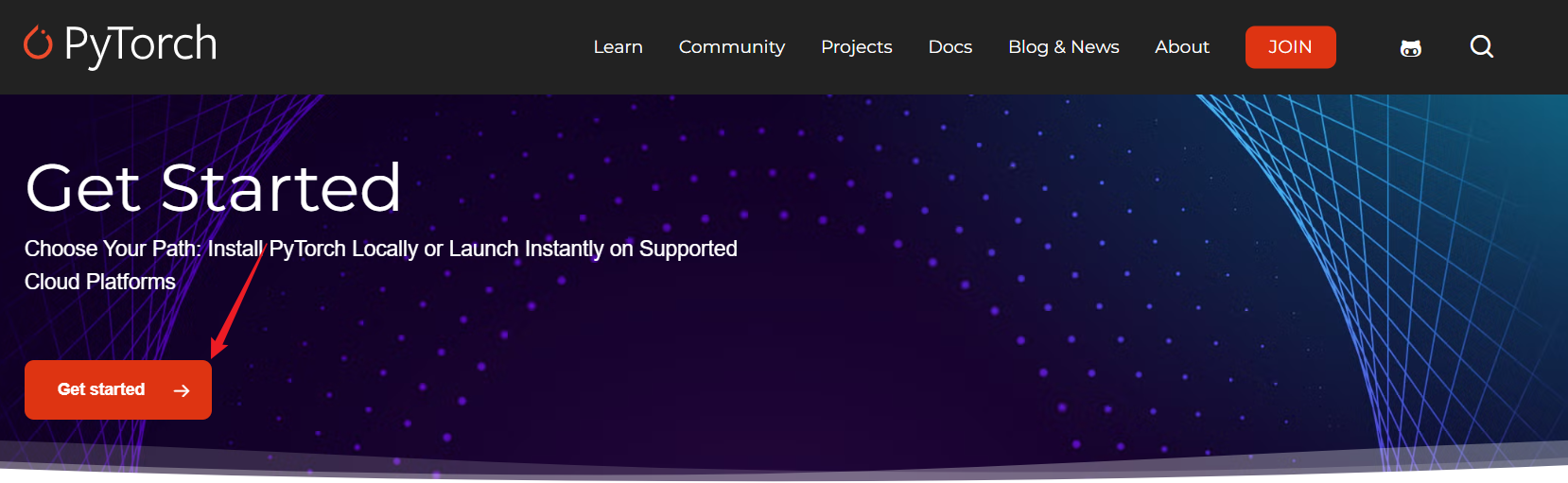

笔者的电脑没有显卡,就选择CPU版本的。
win+R输入powershell 回车。输入下面的指令(下面的指令均在powershell上完成)
pip3 install torch torchvision
第三步: transformers 下载
win+R输入powershell 回车。输入下面的指令:
python -m pip install -U transformers
至此,我应该是完成了环境配置。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号