
记录Pytorch运行代码的一次结果
参考
Pytorch加载自己的数据集(使用DataLoader读取Dataset)
当我复刻这个博主的代码时:
点击查看代码
import torch
import numpy as np
# 定义GetLoader类,继承Dataset方法,并重写__getitem__()和__len__()方法
class GetLoader(torch.utils.data.Dataset):
# 初始化函数,得到数据
def __init__(self, data_root, data_label):
self.data = data_root
self.label = data_label
# index是根据batchsize划分数据后得到的索引,最后将data和对应的labels进行一起返回
def __getitem__(self, index):
data = self.data[index]
labels = self.label[index]
return data, labels
# 该函数返回数据大小长度,目的是DataLoader方便划分,如果不知道大小,DataLoader会一脸懵逼
def __len__(self):
return len(self.data)
# 随机生成数据,大小为10 * 20列
source_data = np.random.rand(10, 20)
# 随机生成标签,大小为10 * 1列
source_label = np.random.randint(0,2,(10, 1))
# 通过GetLoader将数据进行加载,返回Dataset对象,包含data和labels
torch_data = GetLoader(source_data, source_label)
from torch.utils.data import DataLoader
# 读取数据
datas = DataLoader(torch_data, batch_size=6, shuffle=True, drop_last=False, num_workers=2)
for i, data in enumerate(datas):
# i表示第几个batch, data表示该batch对应的数据,包含data和对应的labels
print("第 {} 个Batch \n{}".format(i, data))
如果你和我一样,无法跑通这个代码,不妨看下去。
首先说说我遇到的错误:
1.Windows fatal exception: stack overflow
2.raise HTTPError(req.full_url, code, msg, hdrs, fp)
HTTPError: Not Found
3.data = self._data_queue.get(timeout=timeout)
File D:\python 3.9\lib\multiprocessing\queues.py:114 in get
raise Empty
4.RuntimeError: DataLoader worker (pid(s) 9492, 6928) exited unexpectedly
Empty
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if name == 'main':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
5.AttributeError: Can't pickle local object 'main.
如果你遇到以上问题,希望我的方法可能有用。
我猜测其中大致原因:
1.和pip包版本有关。
2.num_workers=2,这里可能涉及多进程,原来的代码没有涉及多进程的处理,而碰巧这里需要一定的处理。
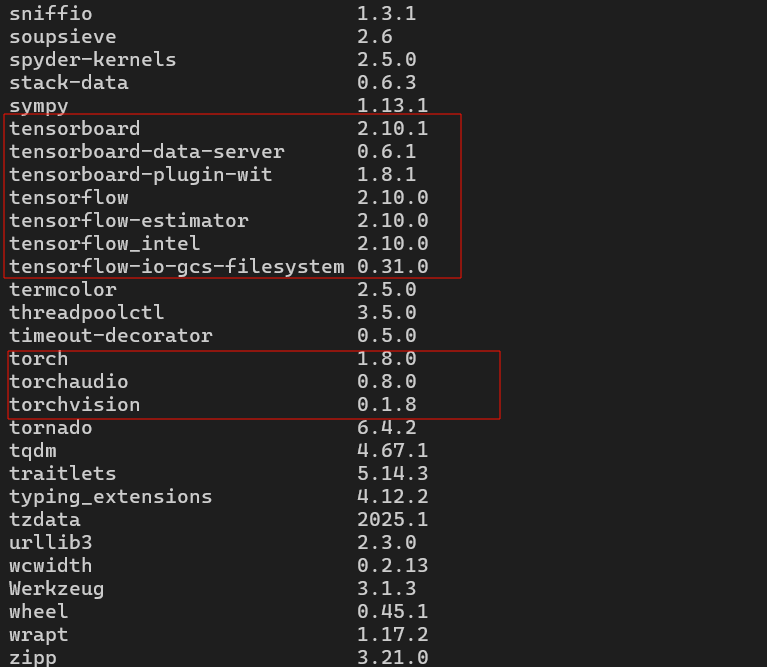
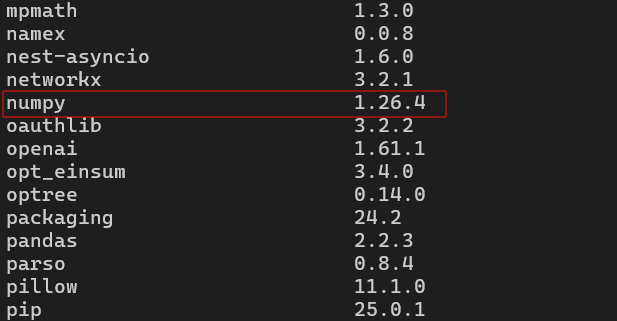
这里贴几张图片:
pip包版本
代码:
点击查看代码
"""
Created on Tue Feb 10 12:24:47 2025
@author: cs1study
"""
import torch
import numpy as np
from torch.utils.data import DataLoader
import multiprocessing
# 定义GetLoader类,继承Dataset方法,并重写__getitem__()和__len__()方法
class GetLoader(torch.utils.data.Dataset):
# 初始化函数,得到数据
def __init__(self, data_root, data_label):
self.data = data_root
self.label = data_label
# index是根据batchsize划分数据后得到的索引,最后将data和对应的labels进行一起返回
def __getitem__(self, index):
data = self.data[index]
labels = self.label[index]
return data, labels
# 该函数返回数据大小长度,目的是DataLoader方便划分,如果不知道大小,DataLoader会一脸懵逼
def __len__(self):
return len(self.data)
def main():
# 随机生成数据,大小为10 * 20列
source_data = np.random.rand(10, 20)
# 随机生成标签,大小为10 * 1列
source_label = np.random.randint(0,2,(10, 1))
# 通过GetLoader将数据进行加载,返回Dataset对象,包含data和labels
torch_data = GetLoader(source_data, source_label)
# 读取数据
datas = DataLoader(torch_data, batch_size=6, shuffle=True, drop_last=False, num_workers=2)
for i, data in enumerate(datas):
# i表示第几个batch, data表示该batch对应的数据,包含data和对应的labels
print("{} Batch \n{}".format(i, data))
if __name__ == '__main__':
try:
p = multiprocessing.Process(target=main)
p.start()
p.join()
except Exception as e:
print(f"Error in main process: {e}")
我的代码结果:
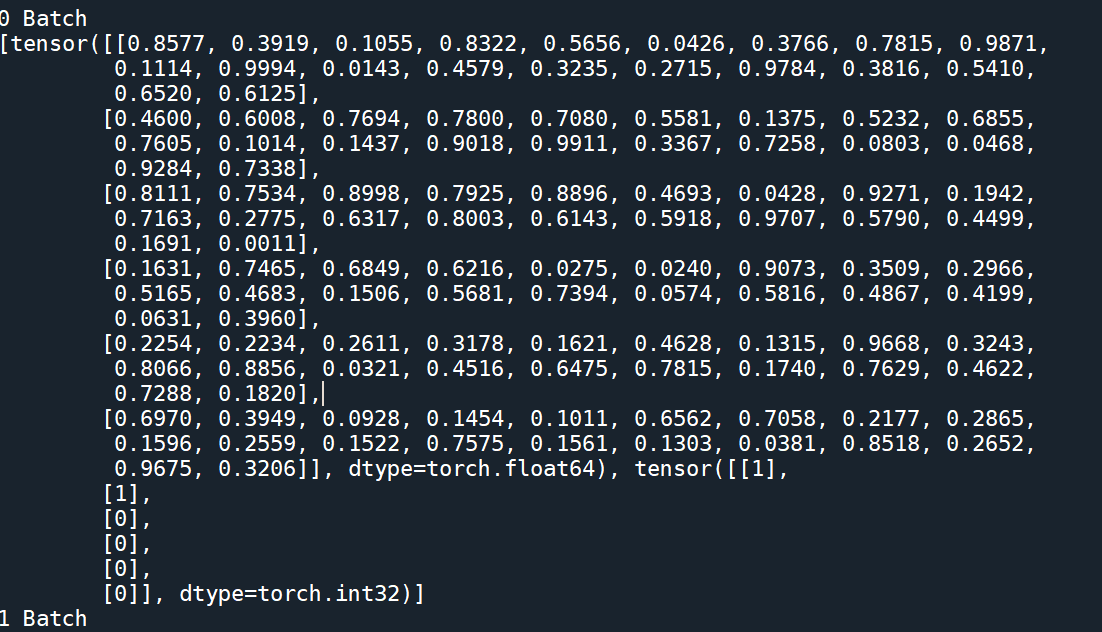
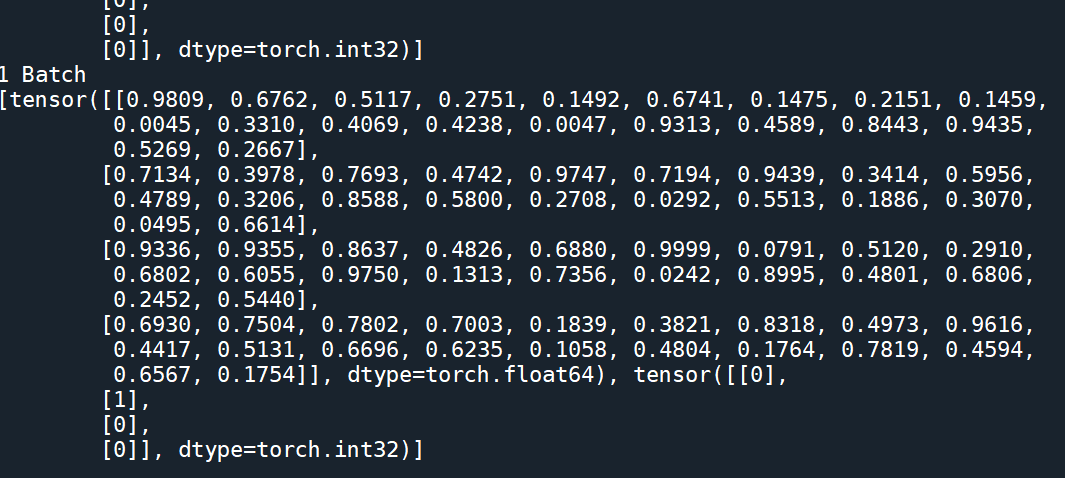
参考文献:
1.pytorch: RuntimeError: DataLoader worker (pid(s) 27292) exited unexpectedly
2.解决“ in get raise Empty _queue.Empty”报错// / OMP: Error #15“的办法
3.安装pytorch时出现 from torch._C import * ImportError: numpy.core.multiarray failed to import 的解决方案
4.Pytorch dataloader中的num_workers (选择最合适的num_workers值)
5.Pytorch加载自己的数据集(使用DataLoader读取Dataset)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号