
python之webdriver页面操作基础(二)
一、基础应用:
#回到上一个页面 driver.back() #下一个页面 driver.forward() #刷新 driver.refresh() #获取页面标题 print(driver.title) #获取页面url地址 print(driver.cunrrent_url) #获取当前页面的句柄 print(driver.current_window_handle) #定位 --id driver.find_element_by_id("kw") #定位 --name driver.find_element_by_name("wd") #元素操作 driver.get("http://www.baidu.com") #元素定位 --多个name找的页面第一个(从上往下) ele=driver.find_elements_by_name("wd") #class属性 --参数只能是一个参数值 ele_clas=driver.find_element_by_class_name("wd") #标签名 ele=driver.find_element_by_tag_name("input") #链接 -a a_all=driver.find_element_by_link_text("新闻") a_part=driver.find_element_by_partial_link_text("产品")
二、XPATH:
xpath绝对定位(绝对路径):/开头,一层一层的找
/html/body/div[1]/div[1]/div[5]/div/div/form/input[3]
ps:元素右键copy full xpath
存在问题:严格按照顺序、位置
xpath相对定位://开头,不用考虑位置顺序
语法:
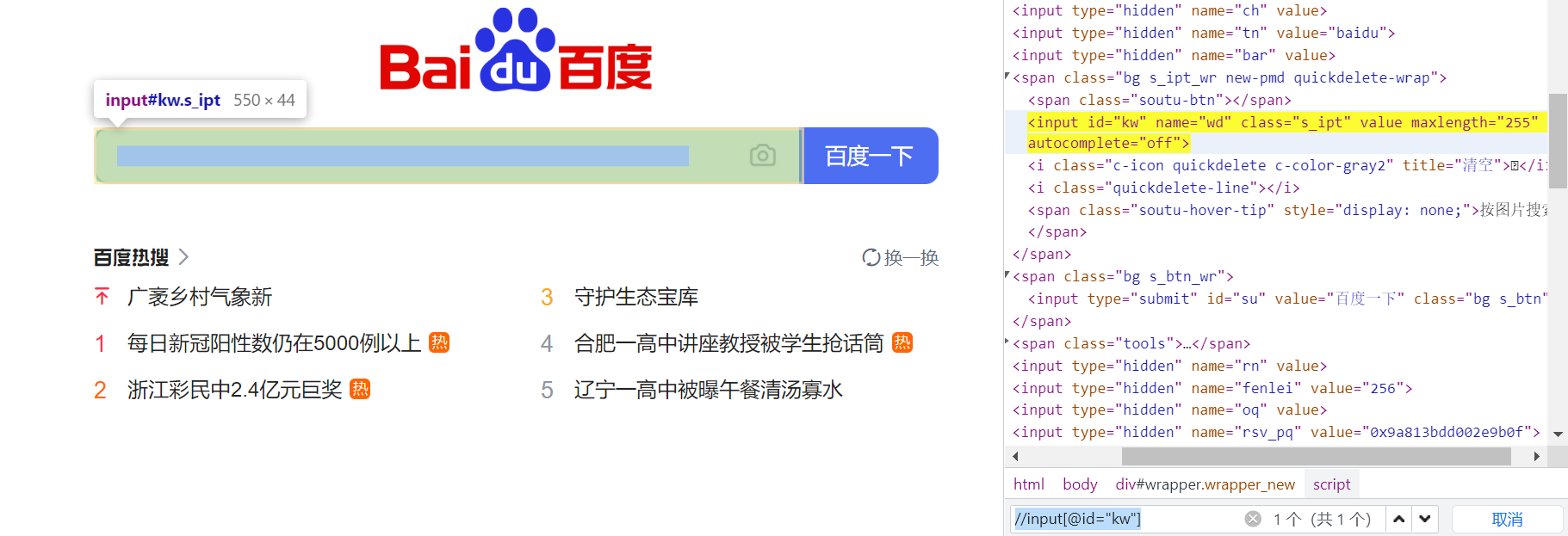
1.//标签名[@属性名=值]
//input[@id="kw"]
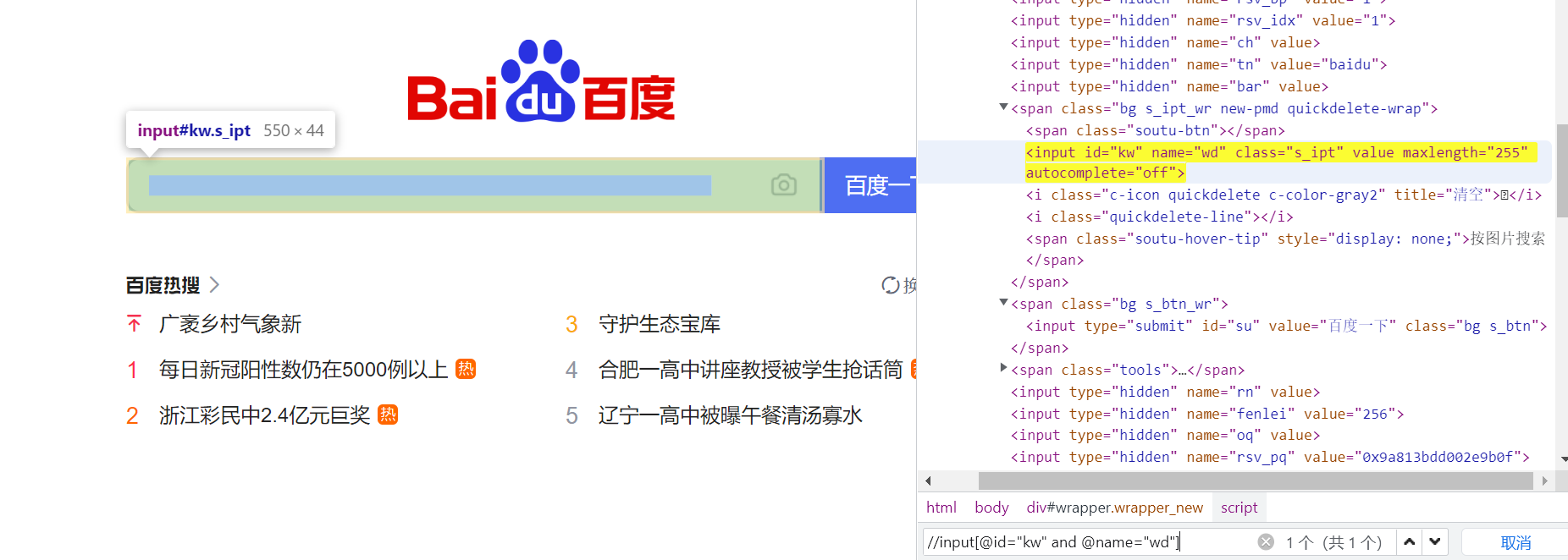
2.多个属性组合用:and,or
//input[@id="kw" and @name="wd"]
3.文本内容(需要判断文本内容是否唯一不变)
#text不是属性,不用加@
//span[@class="fs-22" and text()="chenran"]
4.文本模糊匹配
//标签名[contain(text(),内容)]
//标签名[contain(@id,"kw")]
//标签名[contain(@id,"kw") and contain(text(),内容)]
//span[contain(text(),"人数")]
5.*
#不指定标签/属性:
//*[contain(text(),"人数")]
//span[@*="fs-22"]
6.层级关系
#后面的单斜杠代表直系后代(直属子系)
//div[@id='u1']/a[@name="cr_login"]
#双斜杠不仅仅直系后代(孙系。。。)
//div[@id='u1']//a[@name="cr_login"]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号