

超高并发架构。美国总统选举,要一个选票系统,要100w tps,1000wqps,选票不可篡改,不可重复
本文 的 原文 地址
原始的内容,请参考 本文 的 原文 地址
尼恩说在前面:
最近大厂机会多了, 在45岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、shein 希音、shopee、百度、网易的面试资格,遇到很多很重要的面试题:
京东场景题:100Wqps 亿级用户的社交关系如何设计?如何查看我的关注,关注我的?
京东场景题: 美国总统选举,要设计一个选票系统,要求 100w tps,1000w qps,选票不可篡改,不可重复,获取我的选票结果,获取最终投票结果。问:接口怎么设计,系统怎么设计
前几天 小伙伴面试 京东,遇到了上面 两个场景题 。
但是由于 没有回答好,导致面试挂了。
第一题的答案如下:
京东场景题:100Wqps 亿级用户的社交关系如何设计?如何查看我的关注,关注我的?
今天尼恩给大家梳理一下第二题:
美国总统选举,要设计一个选票系统,要求 100w tps,1000w qps,选票不可篡改,不可重复,获取我的选票结果,获取最终投票结果。 怎么设计
通过此文,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典》V175版本PDF集群,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
美国总统选举,要设计一个选票系统,要求 100w tps,1000w qps,选票不可篡改,不可重复,获取我的选票结果,获取最终投票结果。
问:接口怎么设计,系统怎么设计
首先,尼恩给大家列三个 业界同规模案例对照
- 微博 Star 投票(春晚 2 亿用户):RedisBloom 布隆抗 80 W TPS,DB 仅 3 k QPS 二次确认;
- 支付宝春节红包(7 亿账户):分片布隆 + 异步 DB,峰值 120 W TPS;
- Google Safe Browsing(30 亿 URL):布隆 + 布谷鸟混合,只读场景用布隆,需更新场景用布谷鸟。
一、选票系统业务分析
1、业务场景与性能挑战
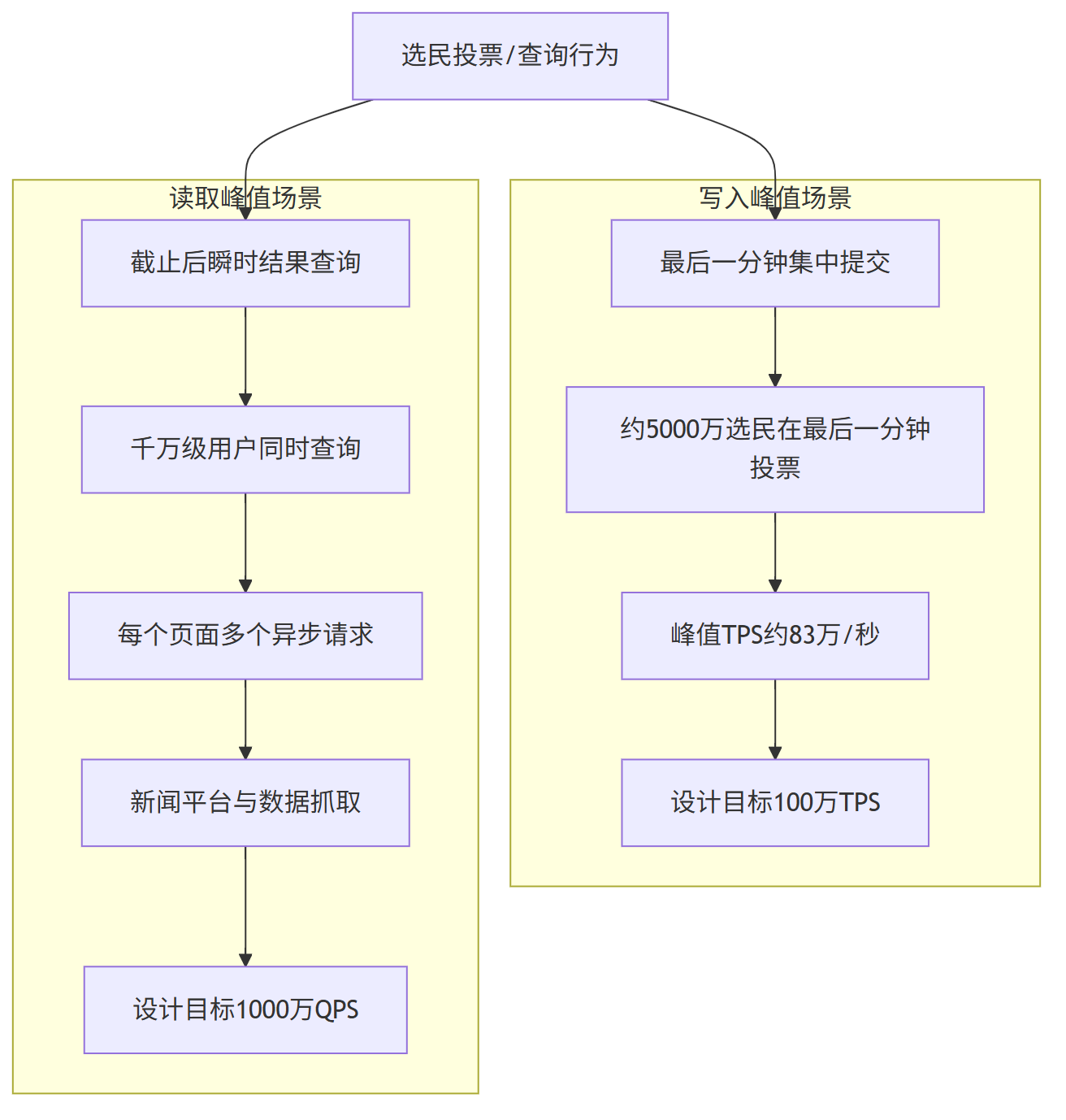
美国总统选举投票及结果查询具有显著的高并发与瞬时峰值特征,集中体现在以下两方面:
100万 TPS 高并发写(最后一分钟高峰) :
大量选民倾向于在投票截止前的最后时刻完成投票,形成典型的“最后一分钟高峰”。
假设约有5000万选民在最后一分钟内提交选票,基础计算如下:
峰值TPS = 50,000,000 votes / 60 seconds ≈ 833,333 votes/second
叠加网络延迟、系统重试及跨时区投票等因素,将设计目标定为100万 TPS 具备合理冗余,可应对极端情况下的洪峰压力。
1000万 QPS 极高 并发读(出票后集中查询) :
投票截止后,全球范围内的选民、媒体与机构会同时发起结果查询。
若有1000万用户同时刷新页面,且平均每个页面产生多个请求(总体结果、分州数据、图表等),系统总QPS将轻松达到千万级别。
此外,各类新闻客户端与数据平台的自动抓取行为会进一步加剧读取压力。
下图概括了投票与结果查询的核心流程及系统所面临的高并发场景:
2、核心接口与功能
系统需提供以下三个核心接口以满足基本业务需求:
| 接口名称 | 方法 | 路径 | 说明 |
|---|---|---|---|
| 提交投票 | POST | /api/v1/vote |
处理选票提交,确保数据正确性与合法性,是系统最核心的写入接口。 |
| 查询个人投票结果 | GET | /api/v1/votes/{voter_id} |
允许选民通过身份标识查询自己的投票记录,确保投票透明性与个人可追溯性。 |
| 查询选举结果(实时统计) | GET | /api/v1/results |
向授权用户或系统提供实时统计结果,支持按地域、候选人等多种维度进行聚合查询。 |
3、关键业务要求
系统设计必须满足以下四项关键业务要求:
(1) 不可篡改:选票一旦提交并确认,其内容应成为只读状态,任何个体(包括系统管理员)均无法修改。
(2) 不可重复:必须通过业务与技术手段严格保证“一人一票”,彻底杜绝任何形式的重复投票。
(3) 选票可追溯:每位选民都应能查询到自身的投票记录,系统需提供清晰、可验证的审计链路。
(4) 实时统计:系统需能够在海量数据写入的同时,高效、准确地进行实时统计并发布投票结果。
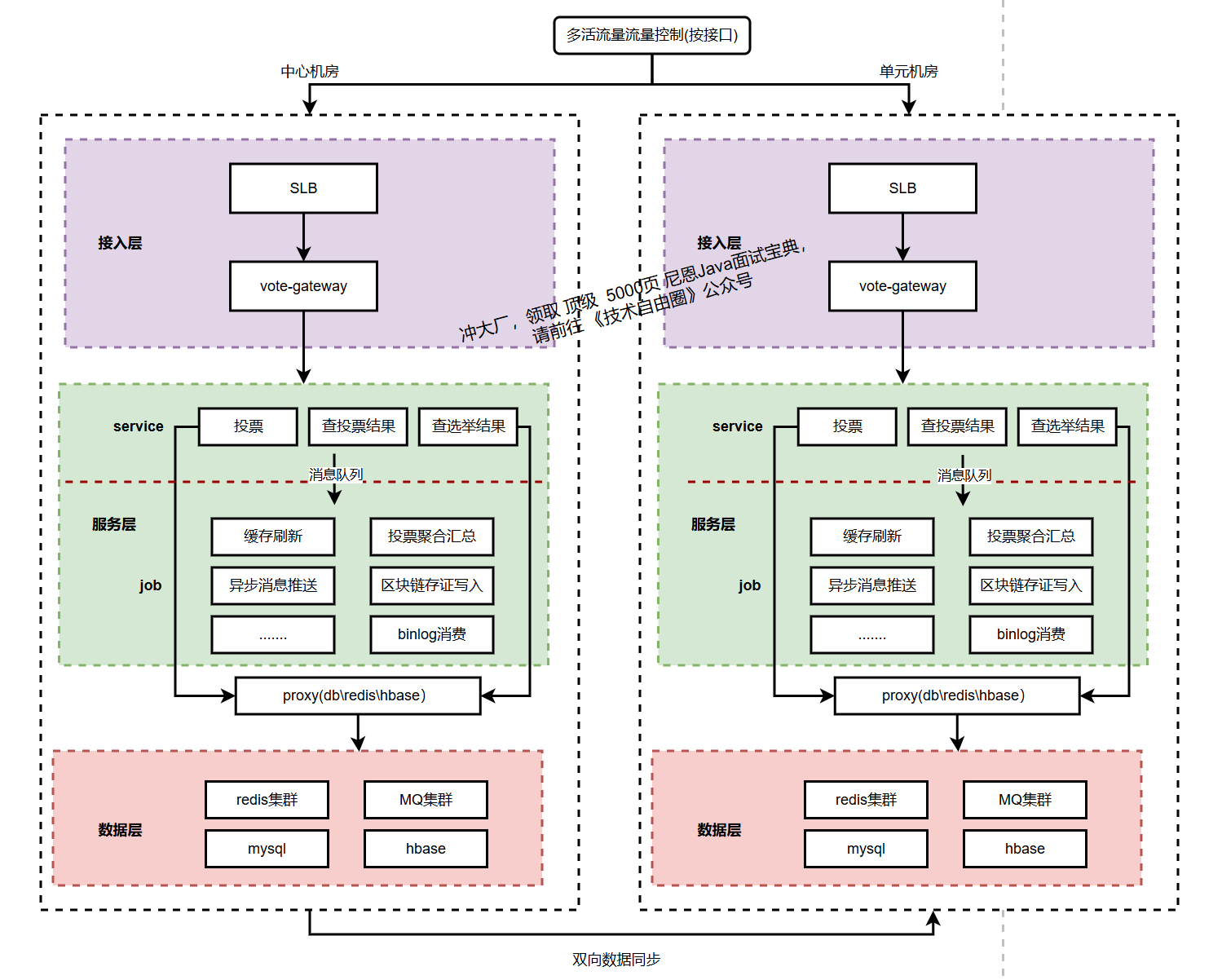
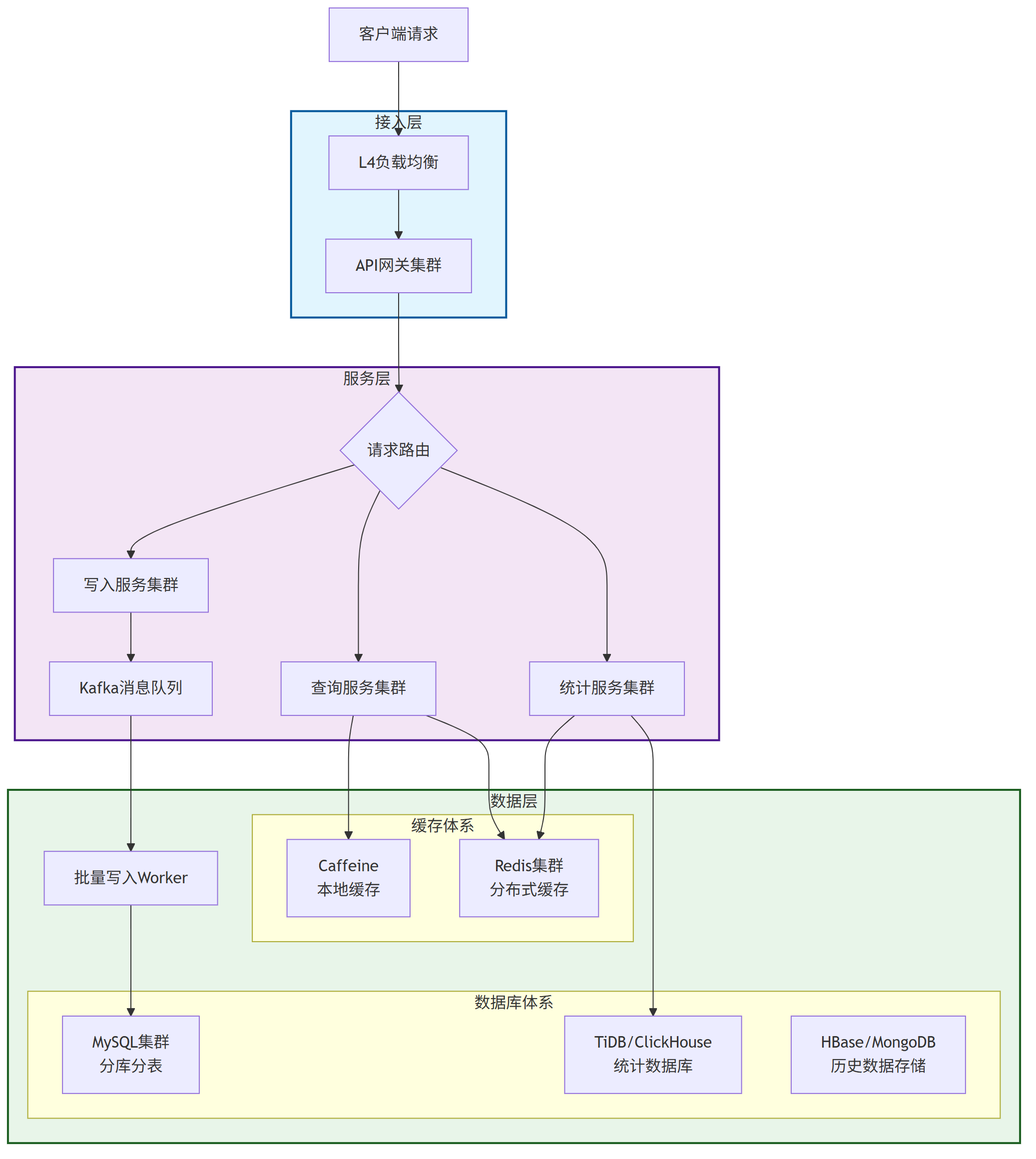
二、总体架构设计
为满足100万TPS写入与1000万QPS读取的性能要求,同时保障数据的不可篡改、不可重复及可追溯性,系统采用分层解耦、读写分离的总体架构。
核心设计思想是通过异步化、批处理、多级缓存与数据分片等技术分散压力,并通过冗余部署确保高可用性。
系统的总体架构如下图所示:
1、接入层
接入层是流量洪峰的第一道屏障,主要负责请求的高效分发与初步过滤。
4层负载均衡 (L4 Load Balancer):采用基于IP+端口的负载均衡器(如F5、LVS),负责进行最快速的流量分发。其优势在于性能极高,能够应对千万级连接而无需解析应用层协议。
7层业务网关 (L7 API Gateway):接收来自L4的流量,执行统一的应用层治理策略,主要包括:
- 身份认证与鉴权:验证选民身份令牌(Token)的合法性。
- 安全防护:抵御CC攻击、刷票、脚本注入等黑灰产行为。
- 流量控制:实施熔断、降级和限流(如对非关键查询接口进行动态限流),保护后端服务不被冲垮。
- 请求路由:将
/vote、/results等不同接口路由至后端的特定服务集群。
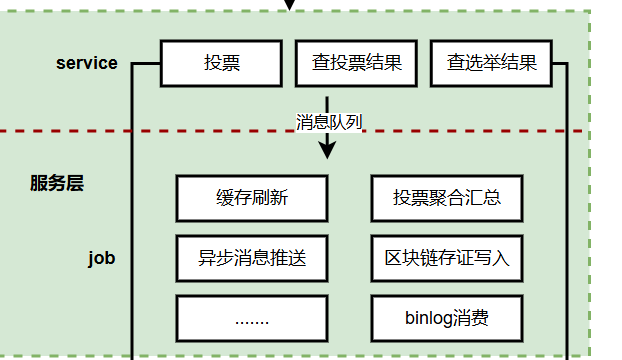
2、服务层
服务层架构,细分为两层:
(1) 服务层:投票和查询
(2) 异步任务层:投票数据的异步写入(比如区块链存证写入等),还有统计数据的异步汇总
服务层采用微服务架构,根据关注点分离(SoC)原则拆分为三个核心服务,实现独立开发、部署和伸缩。
1)选票写入服务:
处理POST /api/v1/vote请求,是写入流量的核心。
选票写入服务本身无状态,不直接同步写入数据库。在完成初步校验(如基本格式、业务时段判断)后,将合法选票消息立即放入高吞吐消息队列(如Kafka)。此举旨在将耗时且不确定的数据库写入操作异步化,从而快速释放连接,轻松应对百万级TPS。写入响应由消息队列的生产确认来保证。
2)选票查询服务:
处理GET /api/v1/votes/{voter_id}请求,提供个人选票查询。
为应对千万级QPS,采用多级缓存策略。首先查询本地缓存(如Guava Cache),未命中则查询分布式缓存(如Redis),以VoterID为Key缓存其投票结果。仅当缓存完全失效时,才查询底层数据库。
3)统计结果服务:
处理GET /api/v1/results请求,提供实时统计结果。
结果数据并非通过实时聚合数据库产生。而是由下游的异步计算任务预先计算好并存入专用统计数据库(如TiDB、ClickHouse)和缓存。本服务直接读取这些预处理好的聚合结果,极大降低读取延迟,保障高性能。
3、数据层
DB架构体系: 一般是 结构化DB+NOSql结合的二级架构模式:
- 结构化DB , 为业务计算提供数据支撑, 如mysql、tidb 等等
- NOSql DB, 提供历史数据支撑,全量数据支撑, 大数据计算支撑, 如hbase,mongdb 等
缓存架构体系: 一般是 分布式缓存+本地缓存的二级架构模式:
- 分布式缓存redis
- 本地缓存caffeine
消息队列:
Apache Kafka集群,作为系统的“主动脉”,承接瞬时的巨量写入请求,实现流量削峰和异步解耦。它为下游的批量入库和实时计算提供可靠的数据流。
三、100W级TPS写入架构设计
1、设计思路
投票业务逻辑相对简单,但面临的核心挑战在于如何将瞬时百万级TPS的写入请求高效、可靠地持久化到数据库中。
直接同步写入数据库的方式无法满足如此高的吞吐量要求,且数据库连接池很容易被耗尽。
因此,我们采用"异步化+批量处理"的核心架构模式,通过消息队列实现流量削峰与解耦,再通过批量写入 worker 将数据高效持久化。
这种模式在Netty、RocketMQ等高性能框架中广泛应用,能极大提升系统吞吐量。
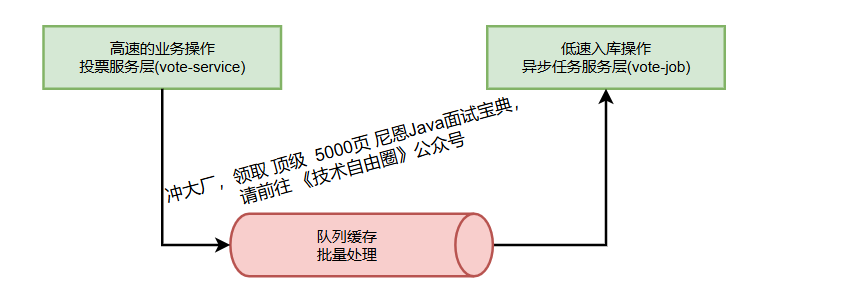
整个写入流程的数据流转与核心组件如下图所示:
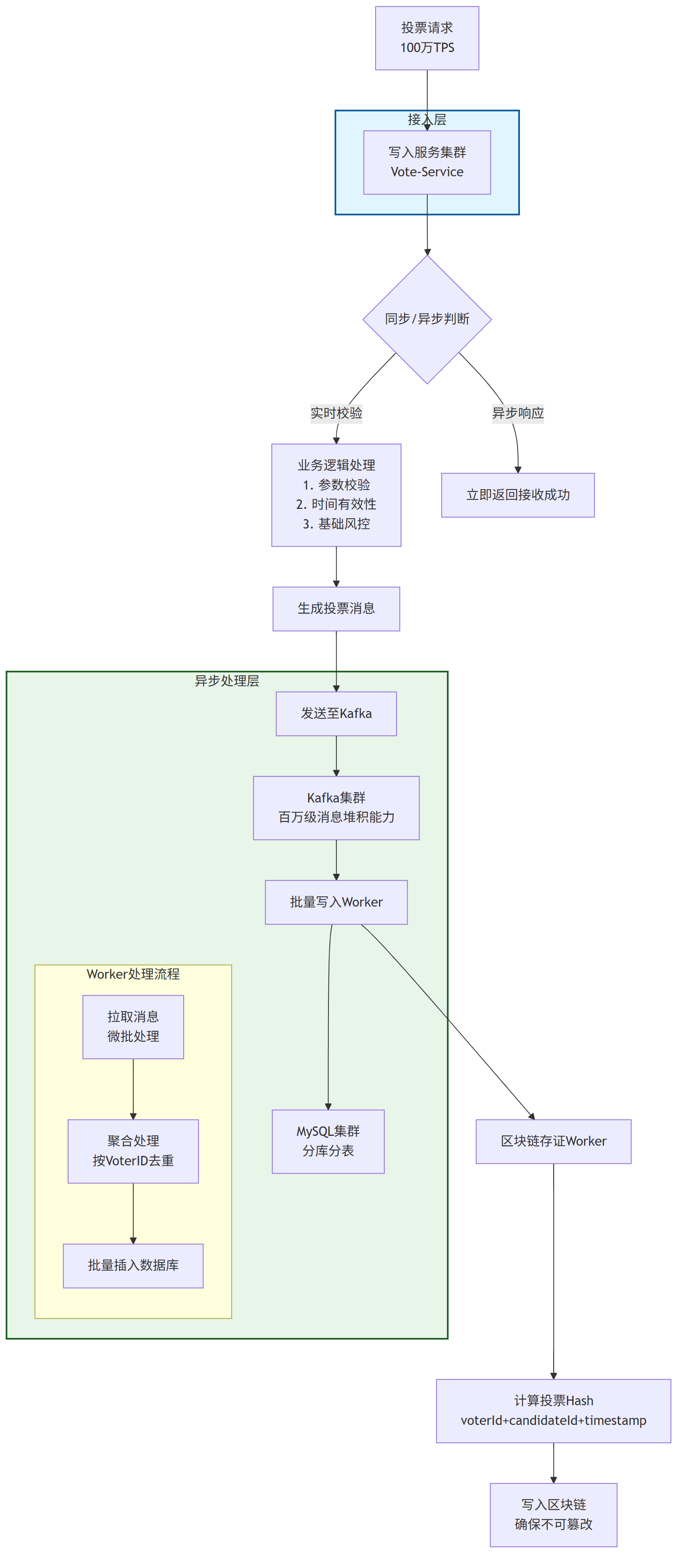
2、写入服务层(Vote-Service)
写入服务层作为系统的前端入口,负责接收和处理投票请求,其核心职责是"快速接收,异步处理"。
2.1 请求处理流程
1)请求接收:通过API网关负载均衡到多个写入服务实例,每个实例均无状态,可水平扩展。
2)基础校验:
- 检查请求基本格式合法性(JSON格式、字段完整性)
- 验证投票时间有效性(是否在选举时间内)
- 执行基础风控检查(如IP频率限制)
3)响应消息::将合法投票请求转换为标准消息格式,大致包含以下字段:
{
"voteId": "uuid_生成全局唯一ID",
"voterId": "选民唯一标识",
"candidateId": "候选人ID",
"timestamp": "投票时间戳",
"state": "所在州",
"signature": "数字签名(可选)"
}
4)异步发送:将消息发送至Kafka集群,发送完成后立即向客户端返回接收成功响应,不等待数据持久化。
2.2 关键技术点
1)连接池管理:服务实例与Kafka保持长连接,避免频繁创建连接的开销
2)批量发送:在内存中微批量聚合消息(如每100ms或积累500条)后发送至Kafka,大幅减少网络往返次数
3)异步IO:完全采用非阻塞IO模型,避免线程阻塞,极大提升单实例吞吐量
3、异步任务层(Vote-Job)
异步任务层是写入架构的核心,负责从Kafka消费消息并执行后续持久化及相关操作。
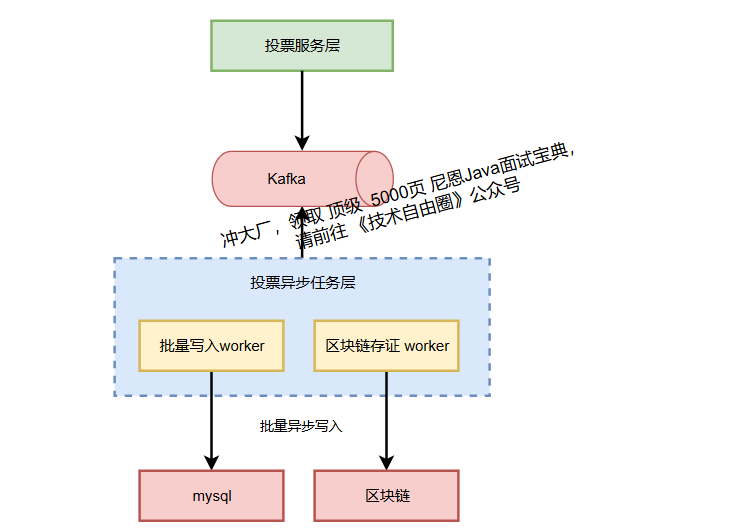
3.1 批量写入Worker
这是保证数据库高效写入的关键组件,其设计要点包括:
(1) 批量消费:以微批处理方式从Kafka拉取消息(如每批次1000条),大幅减少数据库IOPS
(2) 内存聚合:在内存中按时间窗口(如10秒)或数量窗口(如10000条)对投票数据进行聚合,特别是对同一候选人的投票进行计数聚合,减少实际写入次数
(3) 批量插入:使用INSERT INTO ... ON DUPLICATE KEY UPDATE或批量插入语句,将聚合后的数据写入数据库
(4) 重复检查:基于数据库唯一索引(如UNIQUE KEY uk_voter_id (voter_id))实现最终一致性重复投票检查
3.2 区块链存证Worker
为确保选票不可篡改,采用区块链存证方案:
(1) 哈希计算:对每条投票消息的核心字段(voterId, candidateId, timestamp)计算SHA-256哈希值
(2) 批量上链:将多个哈希值组合成Merkle树结构,定期(如每分钟)将Merkle根哈希写入区块链(如以太坊或联盟链)
(3) 成本优化:通过批量上链显著降低区块链交易成本和时间开销
(4) 可验证性:事后可通过比对数据库数据哈希与链上记录,提供不可篡改的审计证据
区块链存证是提供公信力的最佳方案。
- 流程: 对每条投票消息的核心字段(
voterId, candidateId, timestamp)计算一个Hash值。- 存证: 将这个Hash值写入区块链。区块链的特性保证了Hash值一旦上链就无法被篡改。
- 验证: 事后,任何人都可以重新计算数据库中某条票务数据的Hash值,并与链上记录的Hash进行比对。如果不一致,则说明数据被篡改了。这提供了一个强大的事后审计机制。
3.3 监控与流控
为保证系统稳定性,实施全面监控:
(1) 消费延迟监控:实时监控Kafka消费延迟,设置阈值告警
(2) 数据库限流:通过限流组件控制写入数据库的速率,防止数据库过载
(3) 弹性伸缩:根据Kafka堆积消息数量动态调整Worker实例数量
该写入架构通过异步化、批量处理和多重保障机制,既满足了百万级TPS的性能要求,又确保了数据的可靠性、一致性与不可篡改性,为选举系统提供了坚实的数据写入基础。
五、1000万级QPS读取架构设计
1、设计思路
面对每秒千万级的读取请求,我们采用多层缓存、读写分离和空间换时间的核心策略。读取架构需要高效处理两个主要场景:个性化查询(我的选票)和全局聚合查询(选举结果)。
设计二级缓存架构
- 分布式缓存redis
- 本地缓存caffeine
下图展示了读取请求的处理流程与多级缓存架构:
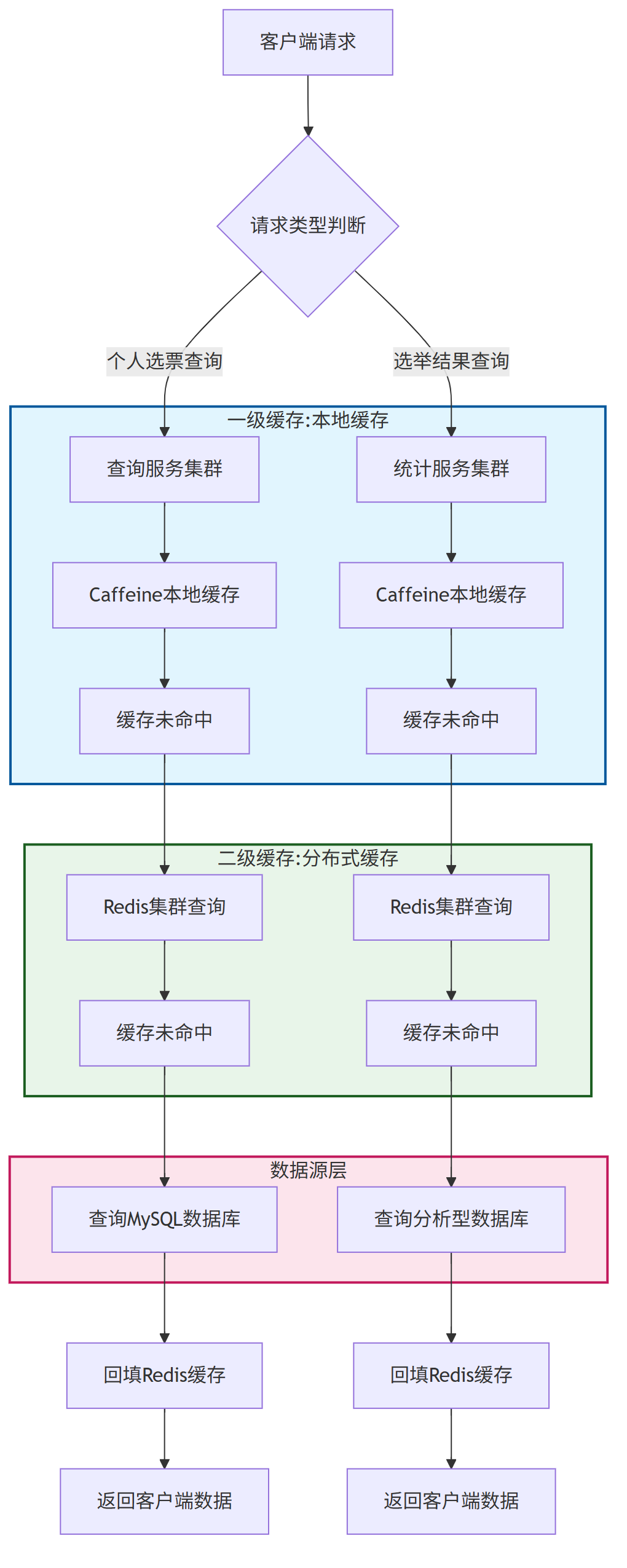
2、二级缓存架构
2.1 一级缓存:本地缓存
本地缓存主要用于应对缓存热点问题和高频访问模式,减少对分布式缓存的压力。
采用Caffeine作为本地缓存实现,其W-TinyLFU淘汰算法能有效提高命中率
缓存内容包括:
- 个人选票查询:以
voterId为键缓存选票信息 - 选举结果:缓存全国及各州统计结果
2.2 二级缓存:分布式缓存
分布式缓存作为主要缓存层,承担大部分读取流量,避免直接访问数据库。
采用Redis集群模式,通过分片实现水平扩展
采用CacheAside模式,即应用先查询缓存,未命中时从数据库加载并回填缓存
2.3 热点探测与处理
建立热点探测机制识别超级热门数据(如关键州的选举结果),通过动态调整本地缓存TTL和容量应对突发流量。
当某个数据的访问频率超过阈值时,系统自动将其标记为热点,延长本地缓存时间并预加载到更多redis节点。
该读取架构通过二级缓存、智能热点识别和多重防护机制,能够有效应对千万级QPS的读取压力,同时保证数据的及时性和一致性,为选举结果查询提供高性能、高可用的技术支持。
六、数据存储架构设计
1、整体存储架构设计
为应对选票系统的高并发读写和海量数据存储需求,我们采用结构化DB与NoSQL结合的二级存储架构。结构化数据库负责实时业务数据处理,NoSQL数据库承担历史数据存储和分析任务,形成互补的存储体系。
整个数据存储架构及数据流转关系如下图所示:
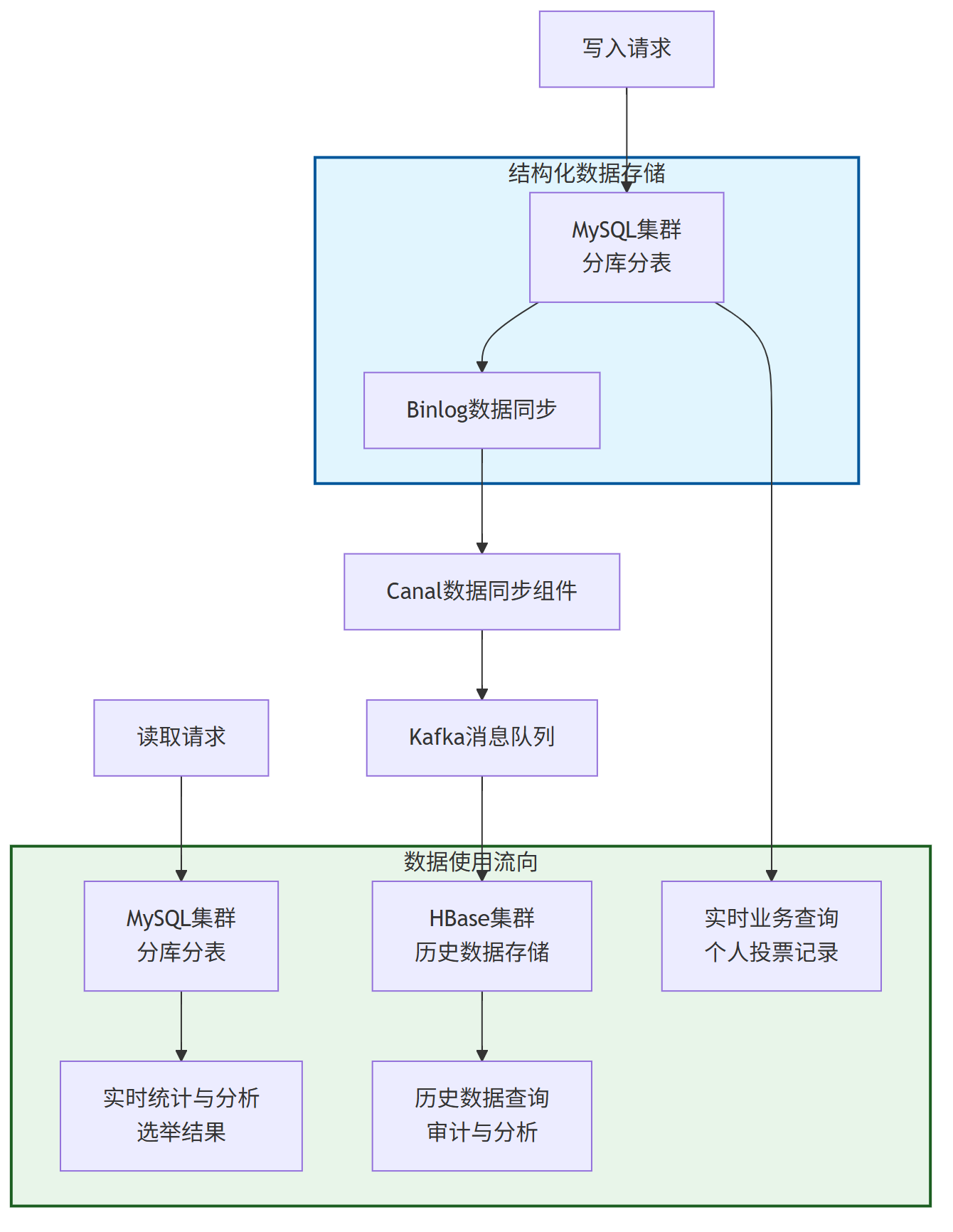
2、结构化数据存储设计
2.1 核心数据表设计
投票记录表(vote_records)存储结构:
| 字段名 | 类型 | 长度 | 必须 | 说明 |
|---|---|---|---|---|
| vote_id | BIGINT | - | 是 | 主键,使用雪花算法生成 |
| voter_id | VARCHAR | 64 | 是 | 选民ID,建立唯一索引 |
| candidate_id | VARCHAR | 32 | 是 | 候选人ID |
| state_code | CHAR | 2 | 是 | 州代码,分片键 |
| vote_timestamp | DATETIME | 3 | 是 | 投票时间,精确到毫秒 |
| voting_method | TINYINT | - | 否 | 投票方式:0=线上,1=线下 |
| device_hash | VARCHAR | 128 | 否 | 设备指纹哈希 |
| ip_address | VARCHAR | 45 | 否 | IP地址(IPv6支持) |
| block_hash | CHAR | 66 | 否 | 区块链存证哈希值 |
| create_time | DATETIME | - | 是 | 记录创建时间 |
投票汇总表(vote_summary)存储结构:
| 字段名 | 类型 | 长度 | 必须 | 说明 |
|---|---|---|---|---|
| summary_id | BIGINT | - | 是 | 主键,自增 |
| candidate_id | VARCHAR | 32 | 是 | 候选人ID |
| state_code | CHAR | 2 | 是 | 州代码 |
| total_votes | BIGINT | - | 是 | 总得票数 |
| last_update | DATETIME | - | 是 | 最后更新时间 |
| summary_type | TINYINT | - | 是 | 汇总类型:0=州级,1=国家级 |
| data_version | BIGINT | - | 是 | 数据版本号,乐观锁控制 |
2.2 分库分表方案设计
针对MySQL数据库,大致分库分表方案
1)分片策略:
- 一级分片:按州代码(state_code)进行一致性哈希分片,将50个州的数据分布到16个物理库
- 二级分片:按主键vote_id哈希取模进行分表,每个库分成64张表
- 全局ID:采用雪花算法生成唯一vote_id,确保全局唯一且有序
2)分片键选择:
一级分片键 - state_code:
- 投票数据天然按州分布,符合业务查询模式
- 大部分统计和查询按州维度进行
- 各州投票量相对均衡,避免严重数据倾斜
二级分片键 - vote_id:
- 主键本身具有全局唯一性,适合作为分片键
- 哈希取模能均匀分布数据,避免热点问题
- 支持通过主键直接定位数据位置
3)分库分表数量
- 物理库数量:16个(支持水平扩展)
- 每个库分表数量:64张表(按vote_id哈希取模)
- 总物理表数量:16库 × 64表 = 1024张表
3、NoSQL数据存储设计
为应对千亿级别数据存储需求,选用HBase作为NoSQL存储方案:
HBase表设计:
# 创建命名空间
create_namespace 'election'
# 创建投票记录表
create 'election:vote_records',
{NAME => 'info', VERSIONS => 1, BLOOMFILTER => 'ROW'},
{NAME => 'stats', VERSIONS => 1},
{NAME => 'meta', VERSIONS => 1}
# RowKey设计:反向时间戳 + 州代码 + 投票ID
# 格式:20231108120000_CA_1234567890
列族设计:
- info列族:存储投票基本信息
- candidate_id: 候选人ID
- voting_method: 投票方式
- voter_hash: 选民ID哈希值(保护隐私)
- stats列族:存储统计相关信息
- device_type: 设备类型
- ip_location: IP地理位置
- vote_duration: 投票耗时
- meta列族:存储元数据信息
- block_hash: 区块链存证哈希
- data_status: 数据状态
- archive_time: 归档时间
4、数据一致性保障架构
基于MySQL Binlog和Canal的数据同步方案确保数据最终一致性:

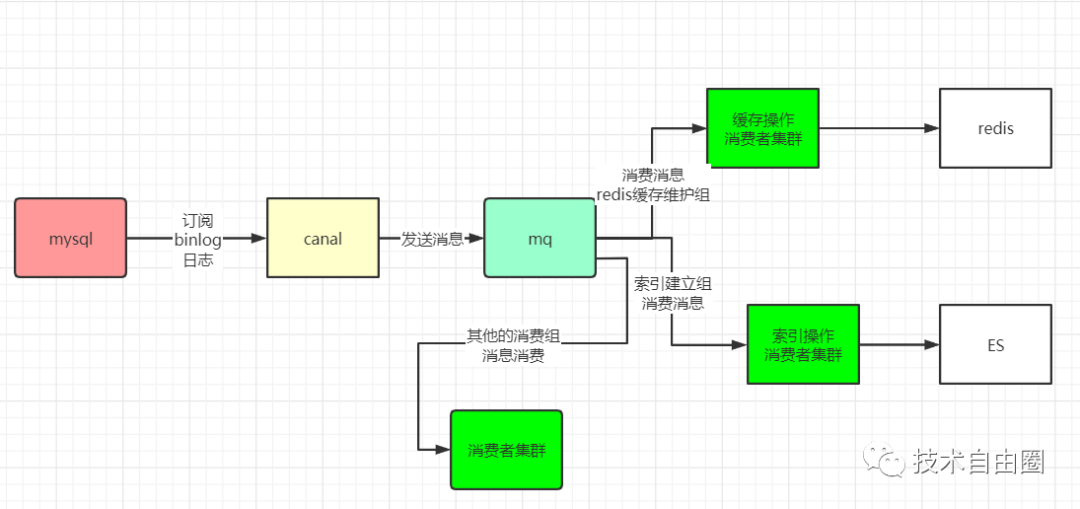
关键组件:
Canal Server:
- 部署为MySQL从库角色
- 配置过滤规则:只同步vote_records表
- 设置内存缓冲区:512MB
Kafka集群:
- 分区策略:按vote_id哈希分区
- 保留策略:保留7天数据
- 副本因子:3副本保证高可用
HBase写入Worker:
- 批量写入:每批次1000条记录
- 异常重试:指数退避重试策略
- 死信队列:无法处理的消息进入死信队列
该数据存储架构通过结构化DB与NoSQL的优势互补,既满足了实时业务的高性能需求,又实现了海量历史数据的经济高效存储,为选票系统提供了全面、可靠的数据持久化解决方案。
七、100万 tps 投票幂等性设计
如何 确保"一人一票"?
100万TPS的高并发场景,需要 一套完整的幂等性保障体系,防止重复投票、异常重试和恶意攻击导致的数据不一致问题。
对于幂等性问题,支付宝团队摸索出来了一个综合性的解决方案:一锁二判三更新。
这个方案,可以作为一个比较通用的综合性的幂等解决方案。
何为“一锁二判三更新”?
简单来说就是当任何一个并发请求过来的时候
1)先锁定单据
2)然后判断单据状态,是否之前已经更新过对应状态了
3.1) 如果之前并没有更新,则本次请求可以更新,并完成相关业务逻辑。
3.2) 如果之前已经有更新,则本次不能更新,也不能完成业务逻辑。
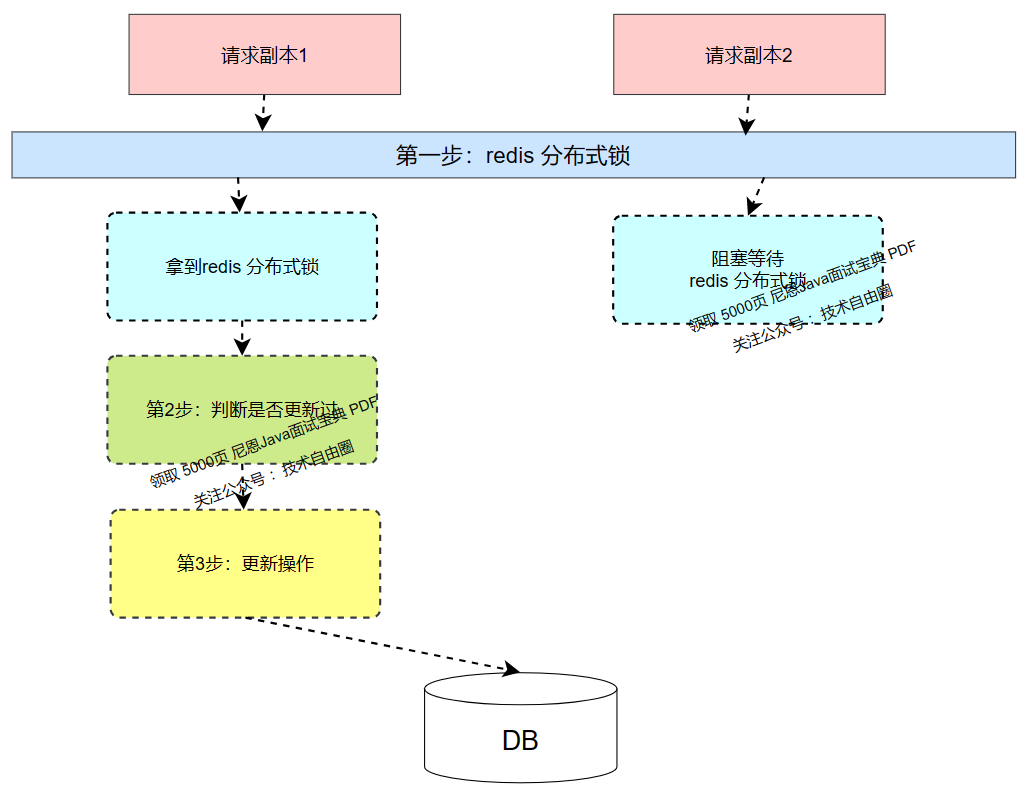
1、第一步:分布式锁控制
在高并发环境下,首先需要确保对同一选民的投票操作串行化处理,避免并发冲突。
分布式锁选型原则:
- 选择基于Redis的分布式锁,平衡性能与一致性需求
- 设置合理的锁超时时间,防止死锁同时保证操作完整性
- 采用唯一请求标识,确保只有加锁方可以释放锁
性能优化措施:
- 引入锁分段机制,将选民ID哈希到多个锁段,提升并发能力
- 实现可重入锁设计,避免同一请求的自我阻塞
- 设置锁等待超时,快速失败返回,避免请求堆积
2、第二步:幂等性判断
获得锁后,进行多层次幂等性校验,确保投票操作的唯一性。
校验策略:
(1) 缓存层检查:查询Redis中是否已存在该选民的投票记录
(2) 数据库验证:检查数据库中的选民投票状态,作为最终判断依据
(3) 状态机校验:通过状态流转机制防止重复处理
多级校验优势:
- 缓存检查提供快速失败,减轻数据库压力
- 数据库验证保证最终准确性,作为最终判断依据
- 状态机管理提供业务流程控制,防止异常状态下的错误操作
3、第三步:数据更新
通过前两步校验后,执行投票数据持久化操作,并确保系统状态的一致性。
数据更新原则:
- 采用原子操作更新数据库,保证数据完整性
- 设置唯一约束索引,防止数据库层面的重复数据
- 更新缓存状态,加速后续相同请求的响应速度
异常处理机制:
- 实现重试策略,采用指数退避算法避免雪崩效应
- 建立异常处理流程,记录失败请求并提供人工干预接口
- 设置超时机制,防止长时间阻塞影响系统吞吐量
八、5000 万-1亿选民 “是否投过” 如何高性能缓存?
...................由于平台篇幅限制, 剩下的内容(5000字+),请参参见原文地址

 浙公网安备 33010602011771号
浙公网安备 33010602011771号