
希音面试:es延时如何解决?在mysql+ canal同步 es建索引场景,这个延时如何解决?
本文 的 原文 地址
原始的内容,请参考 本文 的 原文 地址
尼恩说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多很重要的面试题:
- 字节面试: es怎么提升速度和精准度?
- 提升搜索精准度,有那些的实用技巧?
- es延时如何解决?在mysql+ canal同步 es建索引场景,这个延时如何解决?
最近有小伙伴在面试 希音,又遇到了相关的面试题。小伙伴懵了,因为没有遇到过,所以支支吾吾的说了几句,面试官不满意,面试挂了。
其中第一道题目的答案是:
希音面试:ClickHouse Group By 执行流程 ?CK 能支持 十亿级数据 实时分析的原理 是什么?
这篇文章,帮助小伙伴回答 第二题。
所以,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典PDF》V175版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
一、问题本质:从同步机制到实时系统的治理思维
面试官提出的「延时」问题,实质上是考察候选人能否将"binlog→ES索引"这条数据同步链路视为一个完整的端到端分布式系统进行治理的能力。
延时只是表面现象,根本原因在于四大核心议题缺乏体系化设计:数据一致性保障、流量峰值消减、故障恢复机制,以及全链路可观测性。这需要我们从单纯的同步技术优化,转变为对整个数据流水线的系统性治理。
二、同步 ES 延迟 底层原理与延时瓶颈分析
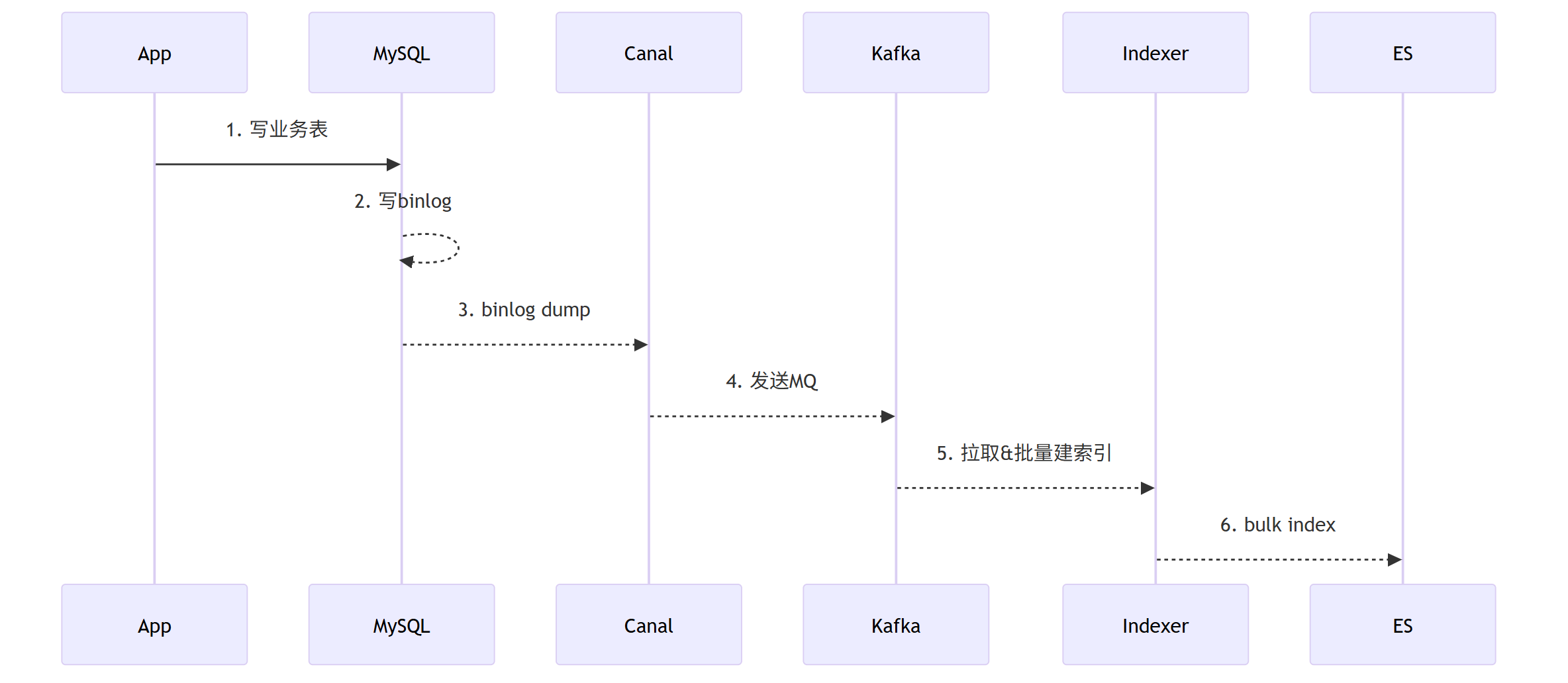
关键延时点分析
| 环节 | 典型延迟 | 主要瓶颈因素 |
|---|---|---|
| Canal拉取 | 毫秒到秒级 | 单点瓶颈/线程池容量 |
| Kafka传输 | 毫秒级 | 批量大小/压缩策略/ACK机制 |
| Indexer消费 | 10毫秒到分钟 | 批量策略/ES负载/背压控制 |
| ES刷新 | 1秒(默认) | refresh_interval设置 |
| 故障恢复 | 分钟级以上 | 下游降级与重试机制缺失 |
从技术架构角度看,这是一个典型的生产者-消费者模型,各个环节都是异步处理的。这种设计虽然保证了系统的高吞吐量和可靠性,但也引入了固有的延迟。
需要理解:延迟是系统为了高吞吐、高可靠和强有序性而付出的必然代价。
我们的目标不是消除延迟,而是将延迟控制在业务可接受的范围内,并对业务透明化。
三、分而治之:4层 全链路 分层 调优 方案 介绍
整个数据同步链路是一个典型的生产者-消费者模型,并且各个环节都是异步的。
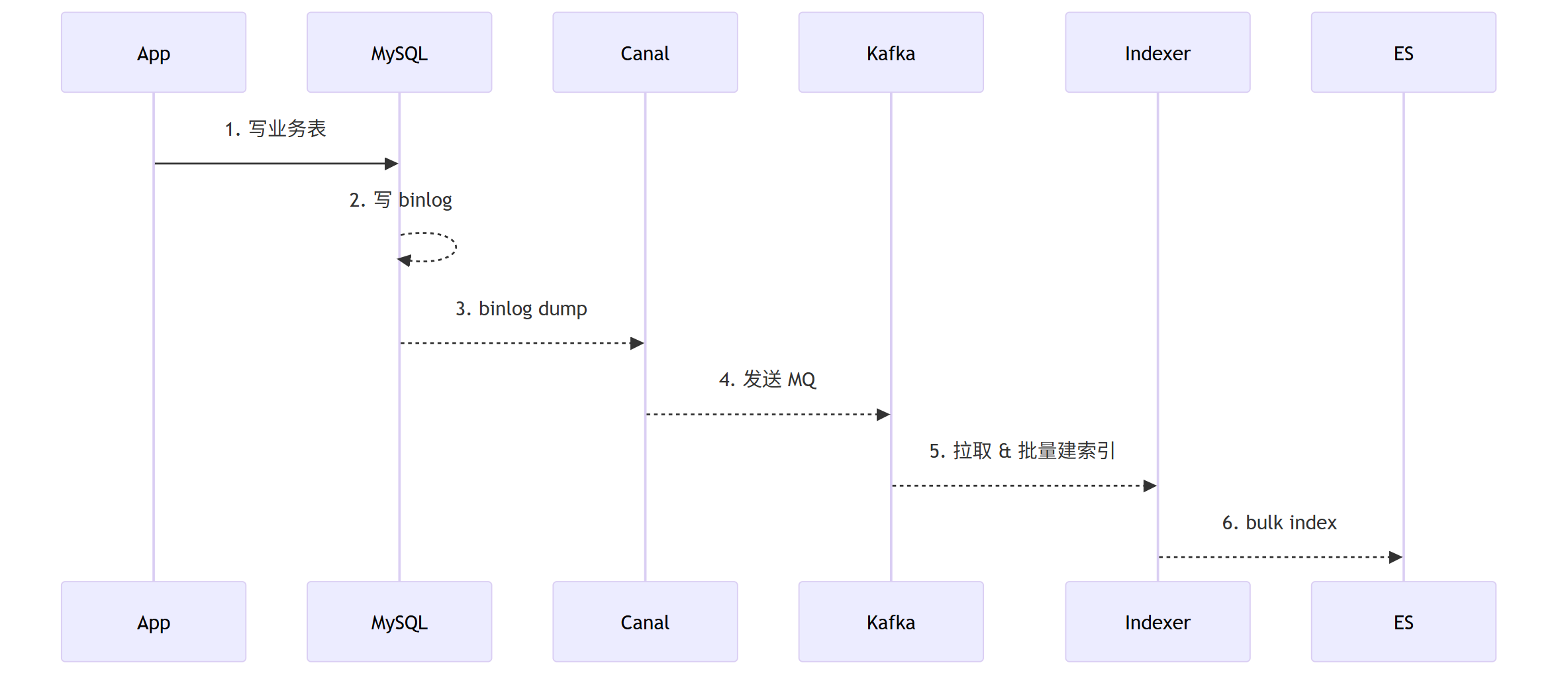
在提出解决方案前,我们必须先透彻理解问题产生的根源。
延迟并非来自单一环节,而是由数据链路的固有特性决定的。
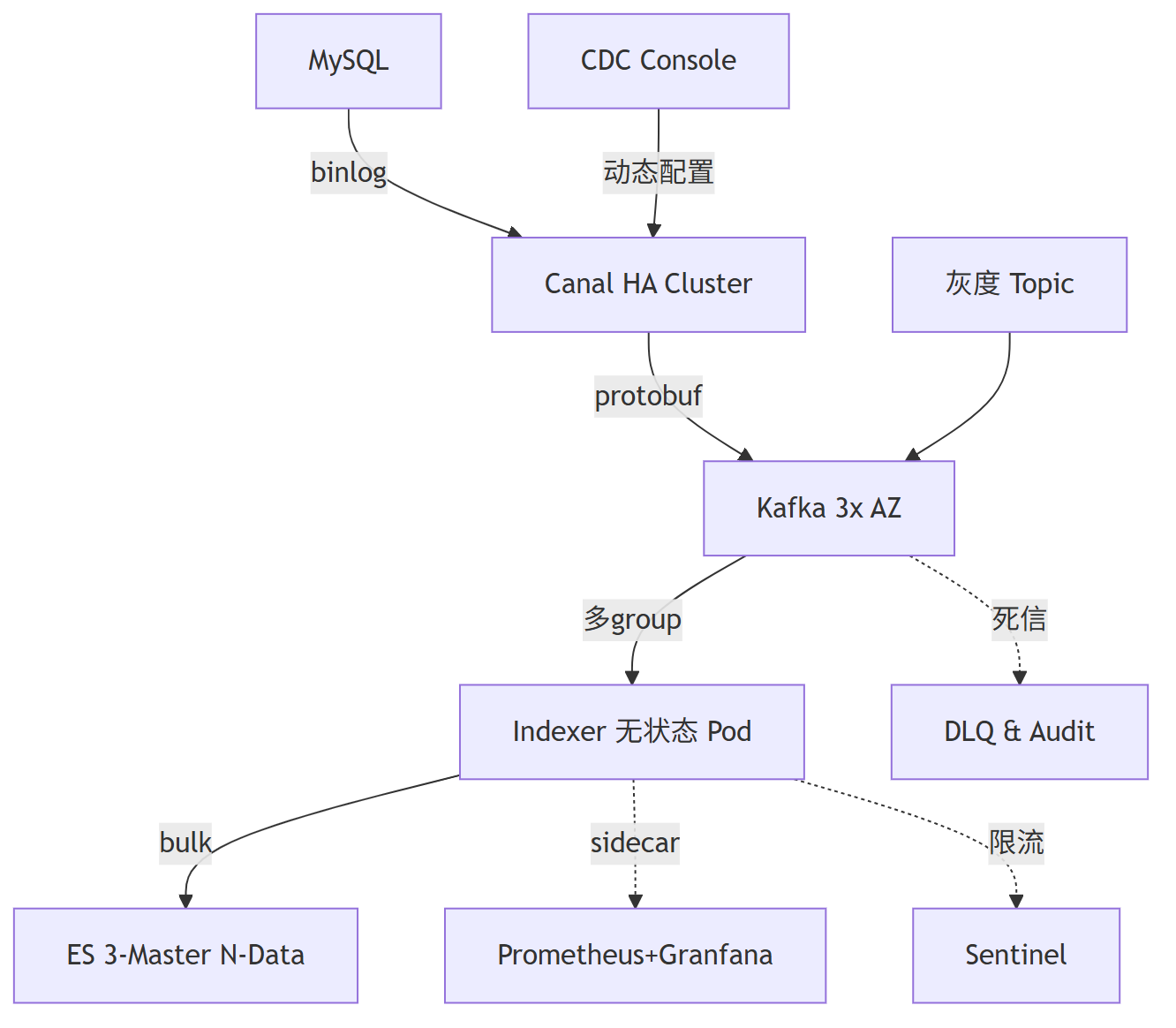
1. 采集层(Canal)优化
瓶颈分析:
- 解析转换开销:Binlog到JSON的转换消耗大量CPU资源,特别是在高QPS场景下
- 串行处理限制:复杂表结构下的单线程处理瓶颈,早期Canal版本尤其明显
解决方案:
- 高可用架构:部署Canal-Server多节点配合Zookeeper选主机制,避免单点故障
- 并行处理:按库表拆分instance,隔离大表热点,提高整体处理能力
- 协议优化:采用protobuf+snappy压缩组合,可降低60%网络IO开销
- 动态过滤:通过控制台下放
instance.filter.regex配置,减少不必要的数据同步
2. 传输层(Kafka)优化
瓶颈分析:
- 批量延迟:linger.ms等待造成的累积延迟,影响实时性
- 分区倾斜:主键分布不均导致的消费不均,可能造成部分分区积压
解决方案:
- 分区策略:按主键hash保证同key顺序性,确保相关数据有序处理
- 可靠性保障:ACK=all配合min.insync.replicas=2,防止数据丢失
- 分级处理:建立双Topic机制,
tp_order_normal处理低延时需求(<1s),tp_order_large处理大事务异步批处理 - 死信管理:实现消费失败3次进入DLQ的审计补偿机制,保证数据可靠性
3. 计算层(Indexer)优化
瓶颈分析:
- 消费积压:生产速度超过消费速度,造成消息堆积
- 批量效率:Bulk参数配置不合理,影响写入性能
解决方案:
- 幂等设计:使用ES
_id = table+pk实现天然幂等,避免重复数据问题 - 批量优化:动态调整batch size(100~5000范围),根据负载自动调节
- 背压控制:集成Sentinel实现限流,阻塞Kafka poll,防止下游过载
- 资源隔离:为热点索引配置独立消费组,避免相互影响
4. 存储层(ES)优化
瓶颈分析:
- 刷新延迟:refresh_interval固有延迟,影响数据可见性
- 写入瓶颈:Bulk Queue堆积,降低写入吞吐量
解决方案:
- 刷新策略:将refresh_interval从1s优化至300ms,平衡实时性与性能
- 可靠性权衡:设置translog.durability=async,允许短暂的数据丢失风险以提升性能
- 冷热分层:实施routing分区与冷热分层策略,热节点使用SSD存储配合高配CPU,温节点使用HDD存储标准配置
- 预创建优化:提前创建index并执行shrink操作,减少rollover时的性能抖动
四、端到端可观测体系 + 自愈机制 构建
建立全链路监控体系是保障系统稳定性的关键。
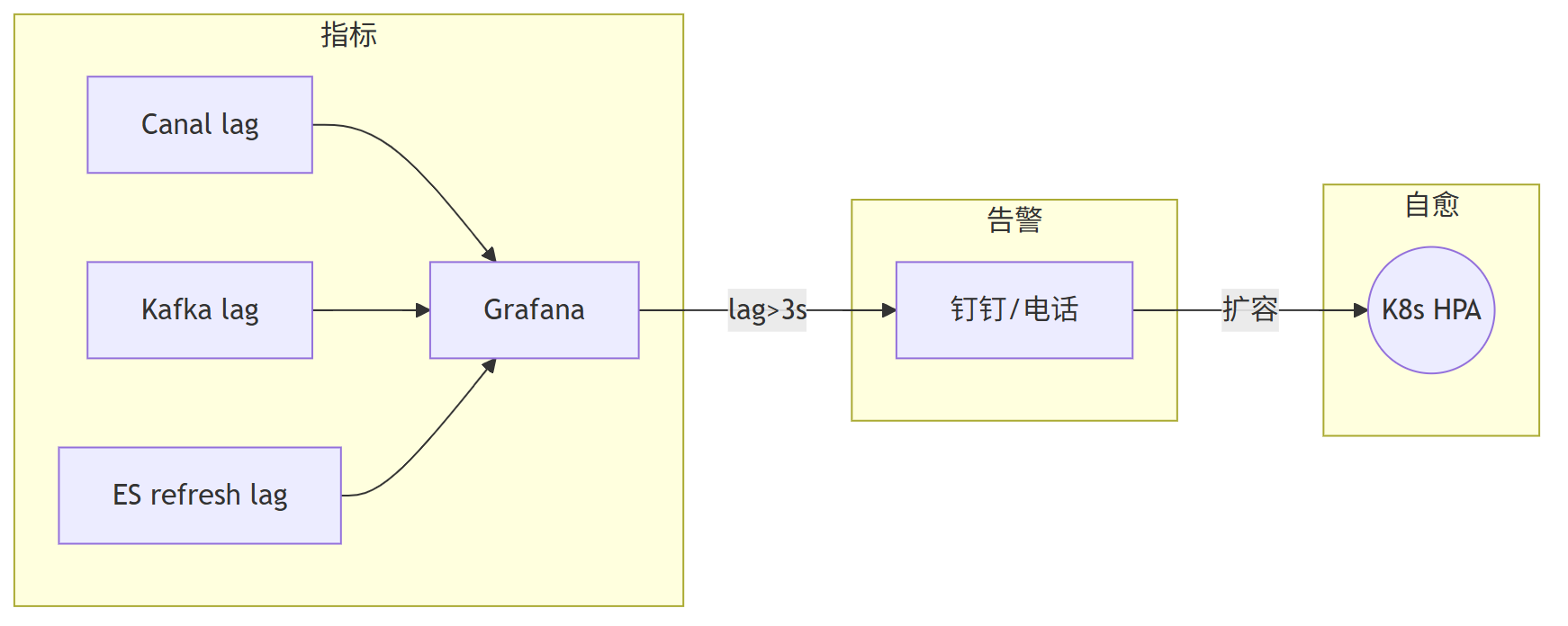
需要监控Canal延迟、Kafka堆积情况、ES刷新延迟等关键指标,并通过Grafana进行可视化展示。
设置合理的延迟阈值告警(如>3s),并联动K8s HPA实现自动扩容,形成完整的自愈机制。
监控体系应该包括实时指标展示、多级告警触发和自动化处理能力。
当检测到延迟超过阈值时,系统能够自动触发扩容操作,同时通过钉钉、电话等方式通知相关人员,确保问题及时得到处理。
五、查询路由与降级方案
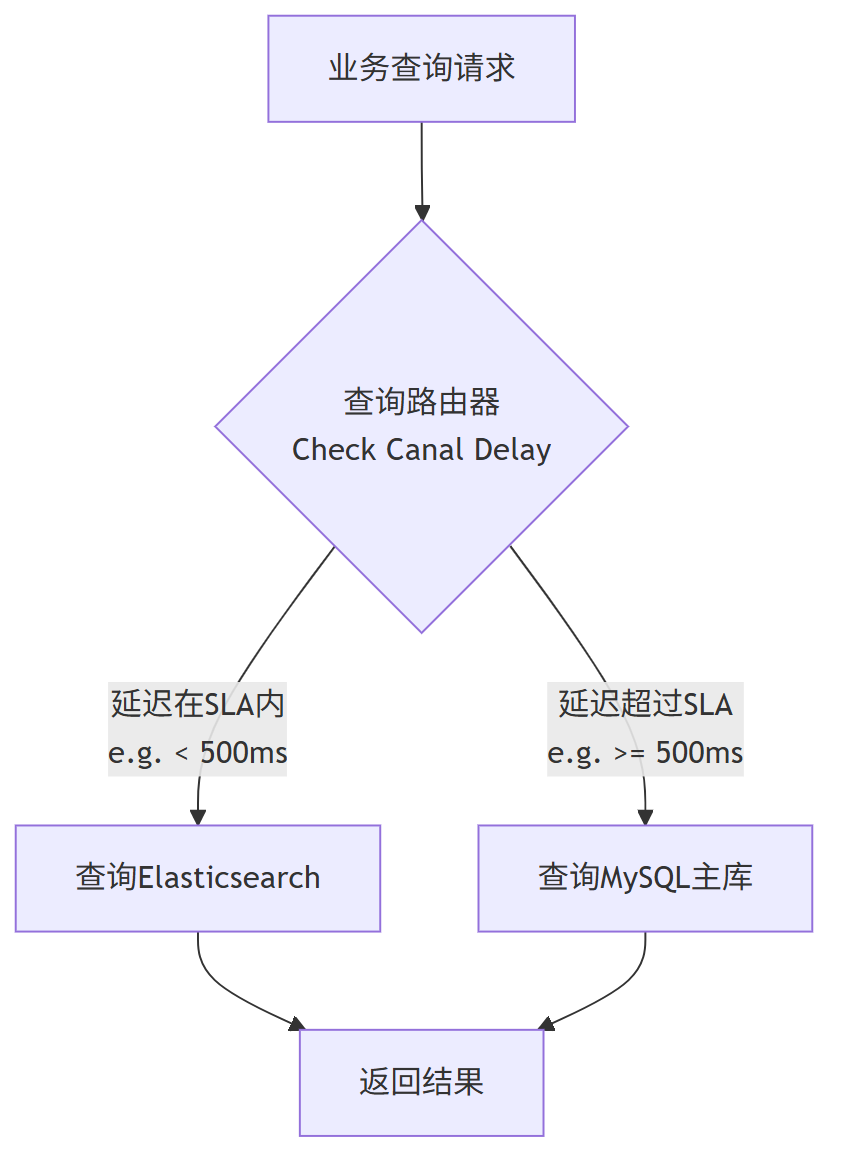
(1) 实时获取 Canal→ES 延迟 t(见下节)
(2) 网关/SDK 根据 t < SLA 路由 ES,否则降级到 MySQL
(3) 业务透明,兼顾高性能与强一致
实施方案:
1、开发实时延迟监控组件,持续获取Canal到ES的延迟时间 t,提供准确的数据支持
2、在网关或SDK层集成智能路由决策逻辑:
- 当t < SLA(如500ms)时:查询ES,享受高性能查询 benefits
- 当t ≥ SLA时:降级查询MySQL主库,保证数据准确性
方案优势:
- 对业务透明:业务代码无需感知底层切换,减少适配工作量
- 精准降级:基于实时延迟数据做出决策,避免不必要的降级
- 高可用保障:极端情况下MySQL主库兜底,确保系统可靠性
六、LatencyProbe组件实现
设计原理:
通过TraceId染色和时间戳差值计算端到端延迟,提供准确的延迟测量
核心实现:
1、Canal端注入Trace信息,为每条数据添加唯一标识和时间戳
2、Indexer端计算时间差,精确测量处理延迟
3、双通道上报:Kafka供链路大盘分析+Prometheus供指标收集和告警
由于平台篇幅限制, 剩下的内容(5000字+),请参参见原文地址

 浙公网安备 33010602011771号
浙公网安备 33010602011771号