

Hadoop的安装,图文并茂的安装过程
题目1: Hadoop的安装,图文并茂的安装过程
实验内容及结果
第一步,下载安装包
- 下载地址: https://dlcdn.apache.org/hadoop/common/,选择hadoop-3.3.6版本。
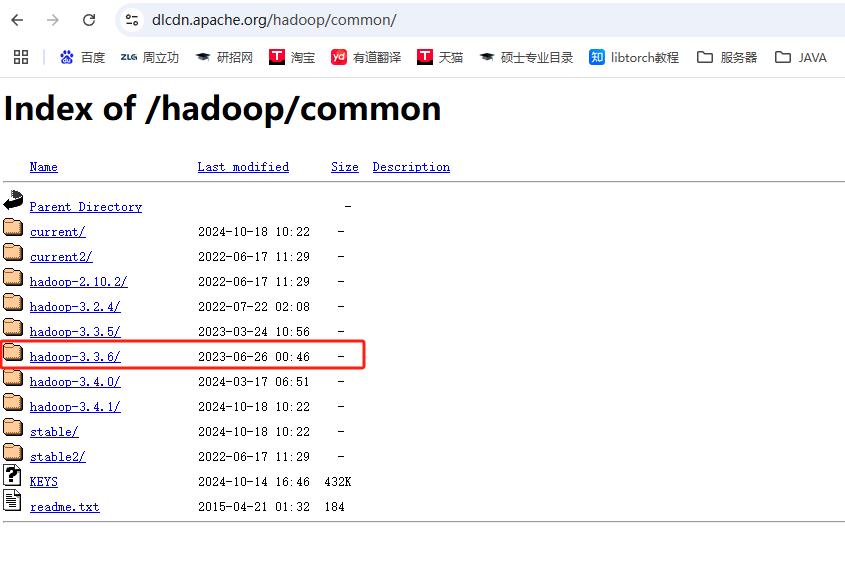
图1-1 选择下载版本
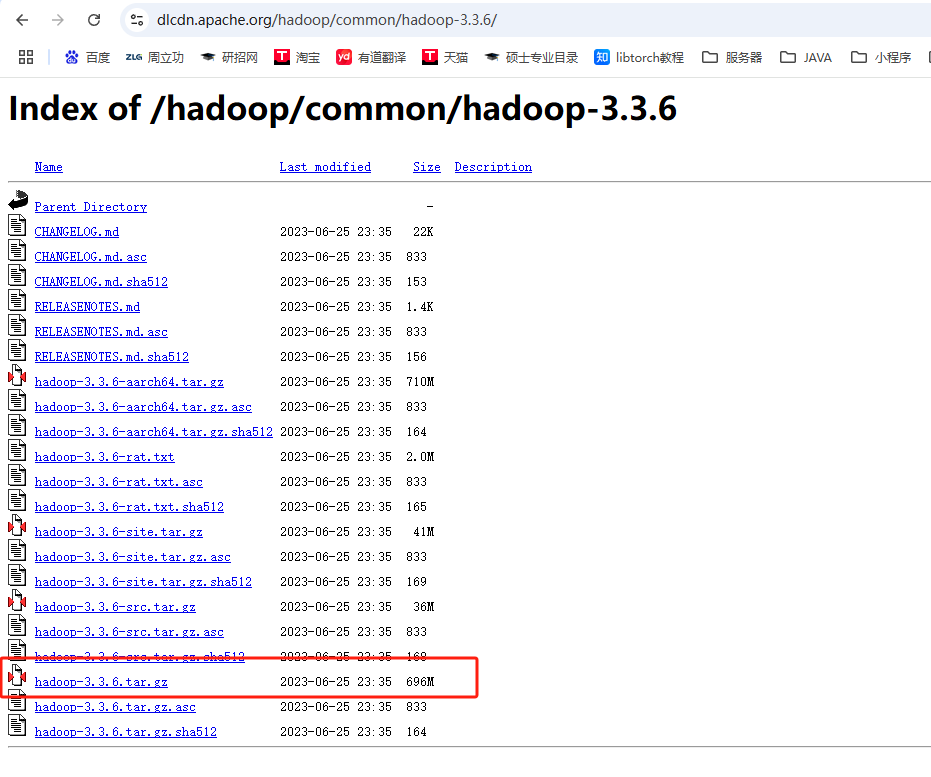
图1-2 选择hadoop-3.3.6.tar.gz
图1-3 推荐用迅雷加速下载
- 下载解压下来,解压到指定的路径:D:\hadoop
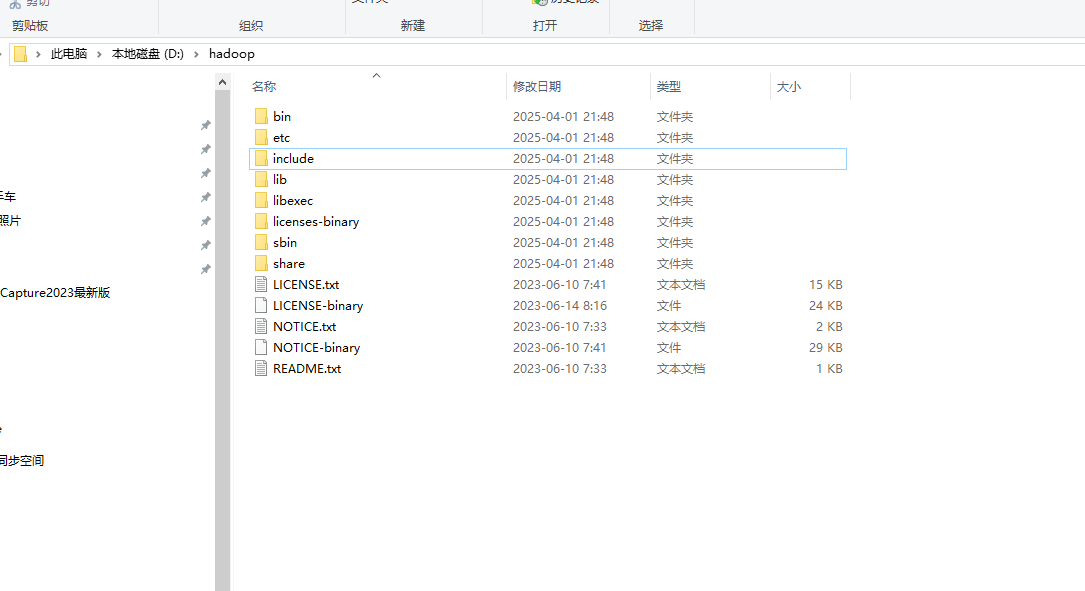
图1-4 解压文件到指定目录
第二步,下载bin执行文件
下载bin文件替换原本存在的linux文件
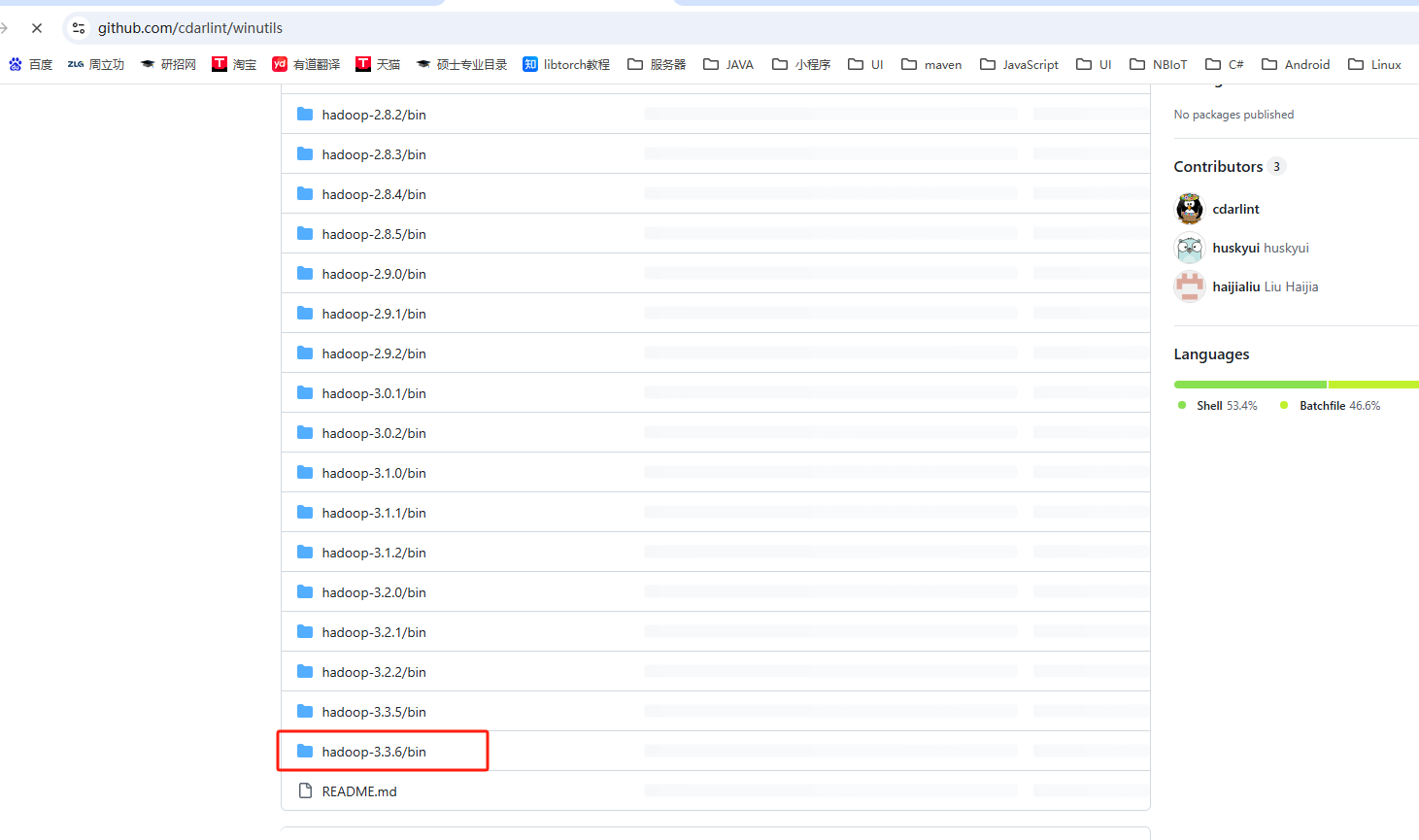
图2-1 下载bin文件
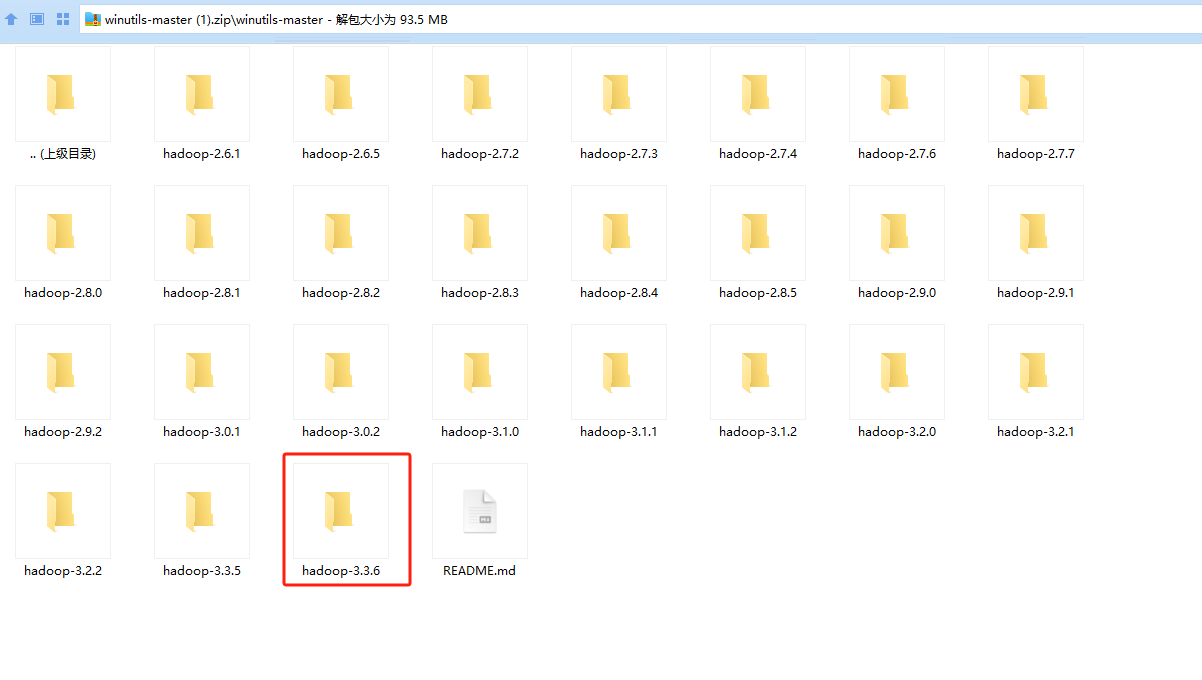
图2-2 选择对应的bin文件夹
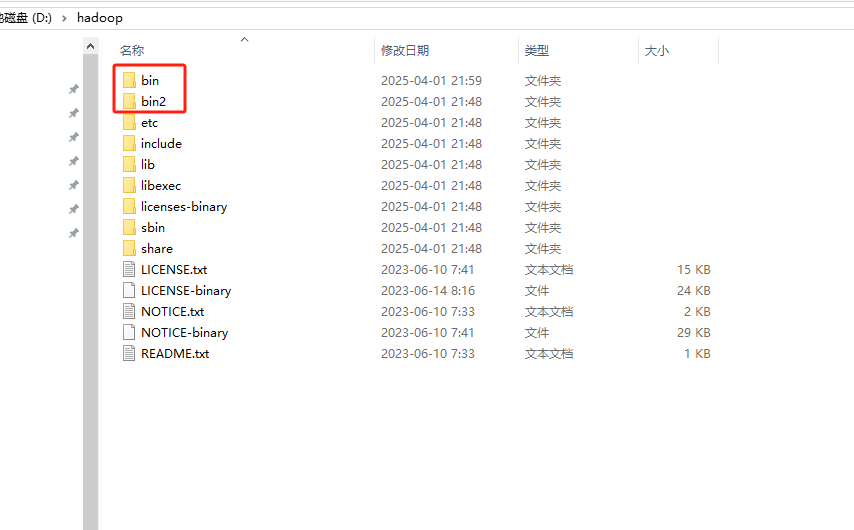
图2-2 备分并替换bin文件夹
第三步,配置环境变量
- HADOOP_HOME 对应的值填上面我们记下的安装路径
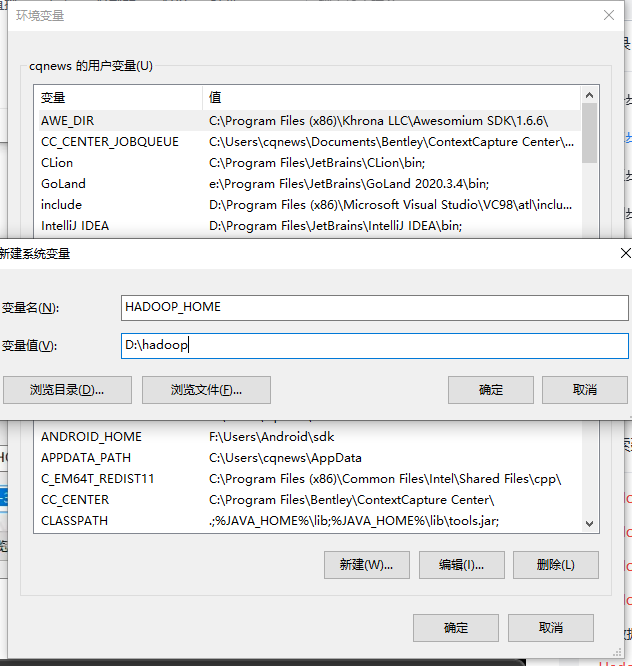
图3-1 配置hadoop主目录环境变量
- path 环境变量中增加执行目录
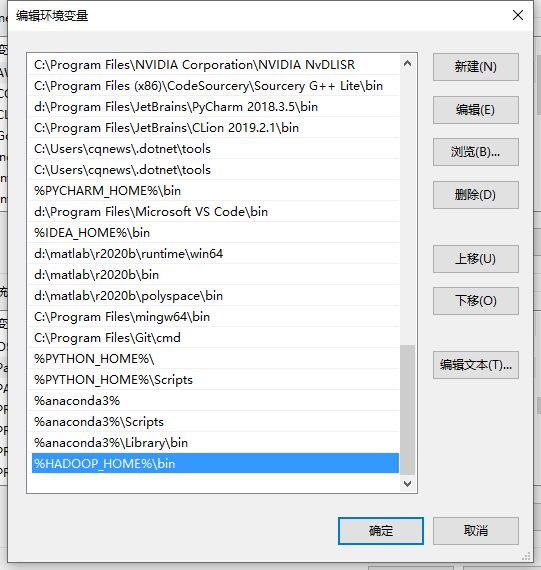
图3-2 添加Hadoop\bin到path环境变量
- 检测环境变量是否配置成功
在配置环境变量后我们检查一下环境变量是否生效,在cmd或powershell下运行 hadoop version 看看情况
- hadoop version
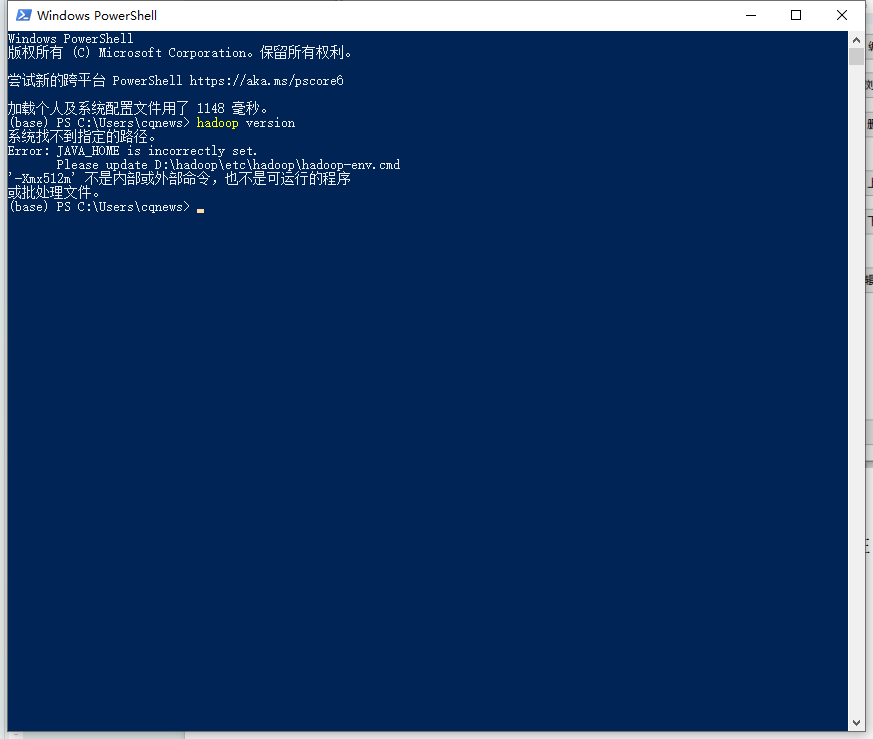
图3-3 出现异常
在配置环境变量后我们检查环境的时候,出现故障,初步查明是因为以前配置的JAVA_HOME 路径中有空格。
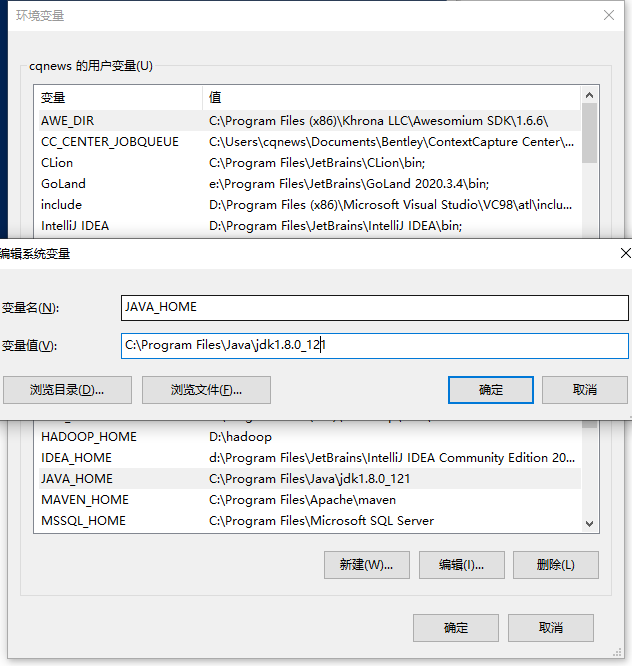
图3-4 JAVA_HOME 出现异常
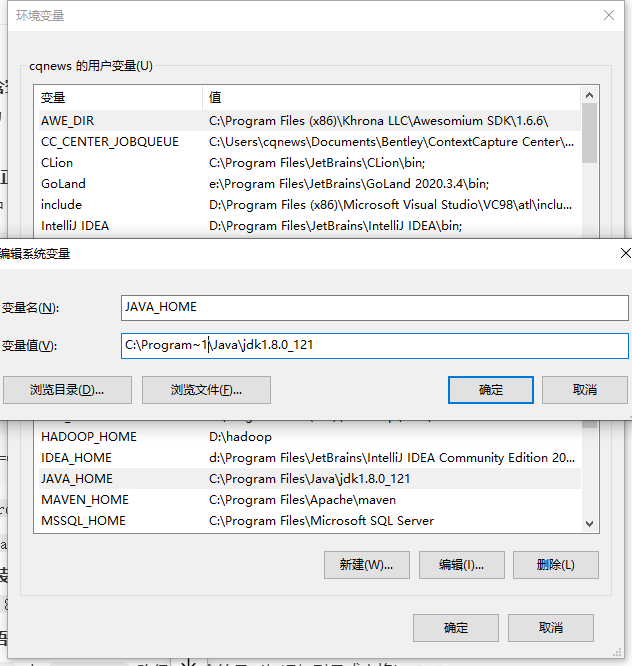
图3-5 JAVA_HOME修正方案
- 环境校验成功
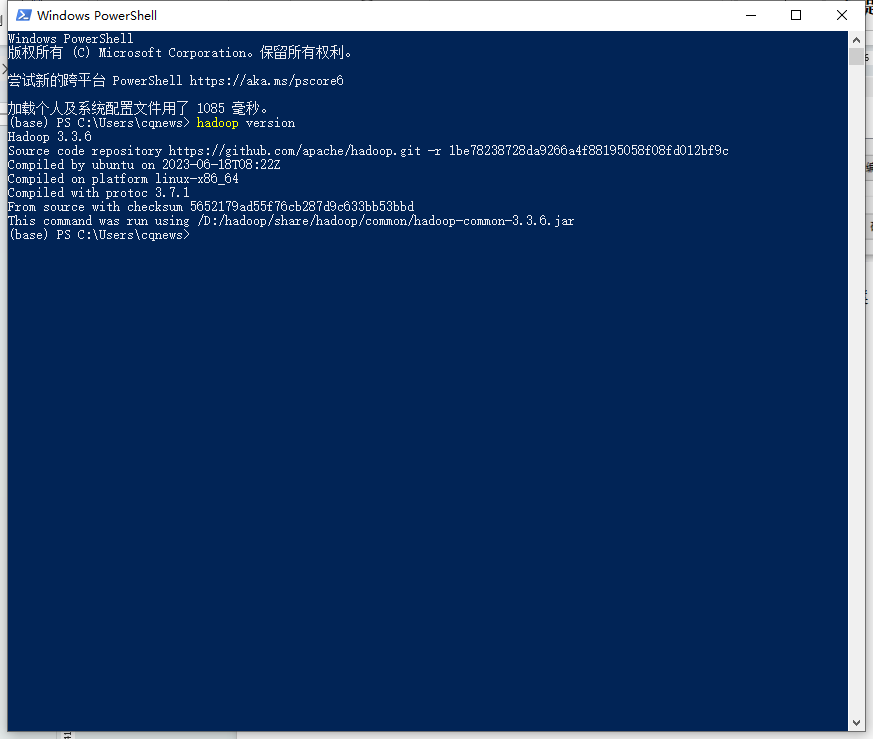
图3-6 环境校验完成
第四步,配置文件
首先在d:\hadoop创建一个data文件夹,然后在data文件夹下面创建三个文件夹,分别是 datanode、namenode、tmp
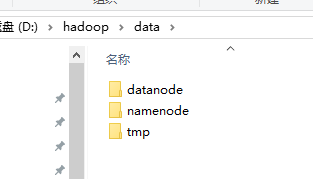
图4-1 创建三个文件夹供配置使用
- 配置core-site.xml
core-site.xml配置文件在 D:\hadoop\etc\hadoop下面,core-site.xml文件是 Hadoop 配置文件之一,用于配置 Hadoop 的核心参数。这些参数定义了 Hadoop 集群的基本行为和特性,包括文件系统的默认配置、网络设置、安全设置等。
- <configuration>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/D:/hadoop/data/tmp</value>
- </property>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://localhost:9000</value>
- </property>
- </configuration>
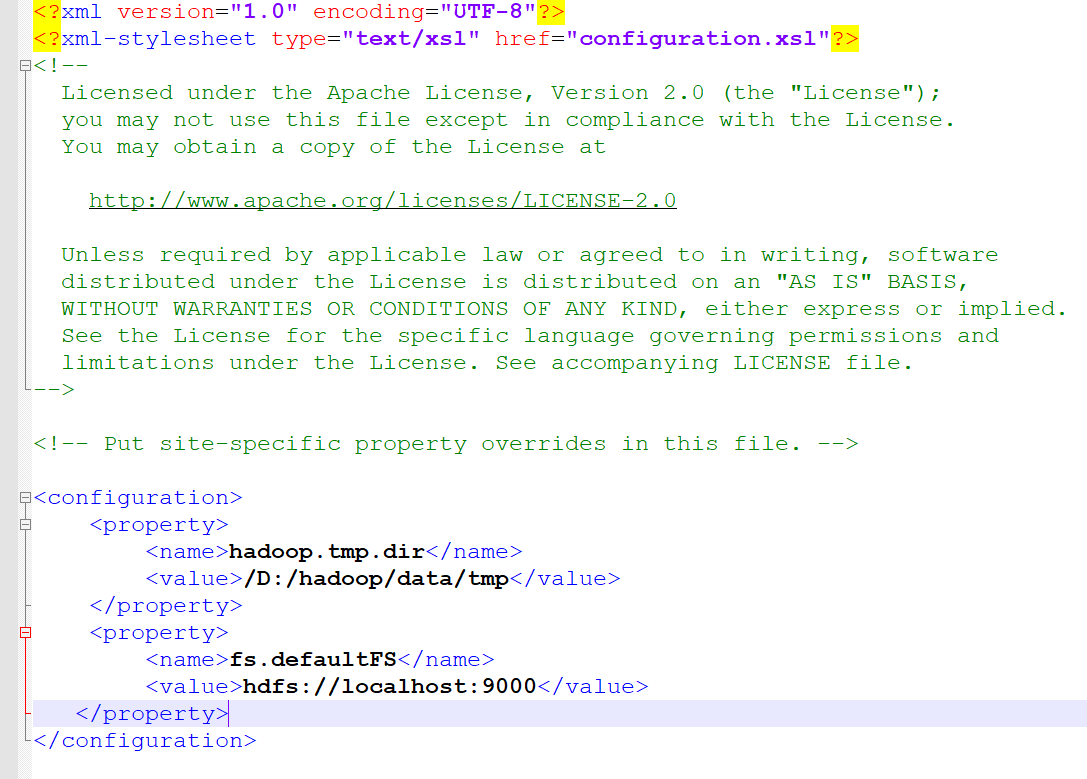
图4-2 core-site.xml 参数配置
注意以"/"开头中间用"/"隔开,使用 Windows 系统,路径格式应该是/D:/hadoop/data/tmp,而不是 D:\hadoop\data\tmp。
- hadoop.tmp.dir:指定 Hadoop 临时文件的存储目录。
- fs.defaultFS:指定 Hadoop 默认的文件系统 URI。
- 配置mapred-site.xml
mapred-site.xml用于设置 MapReduce框架的具体参数。
- mapreduce.framework.name:确保 MapReduce 任务由 YARN 资源管理器调度和管理。
- mapred.job.tracker:指定 JobTracker 的地址
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- <property>
- <name>mapred.job.tracker</name>
- <value>hdfs://localhost:9000</value>
- </property>
- </configuration>
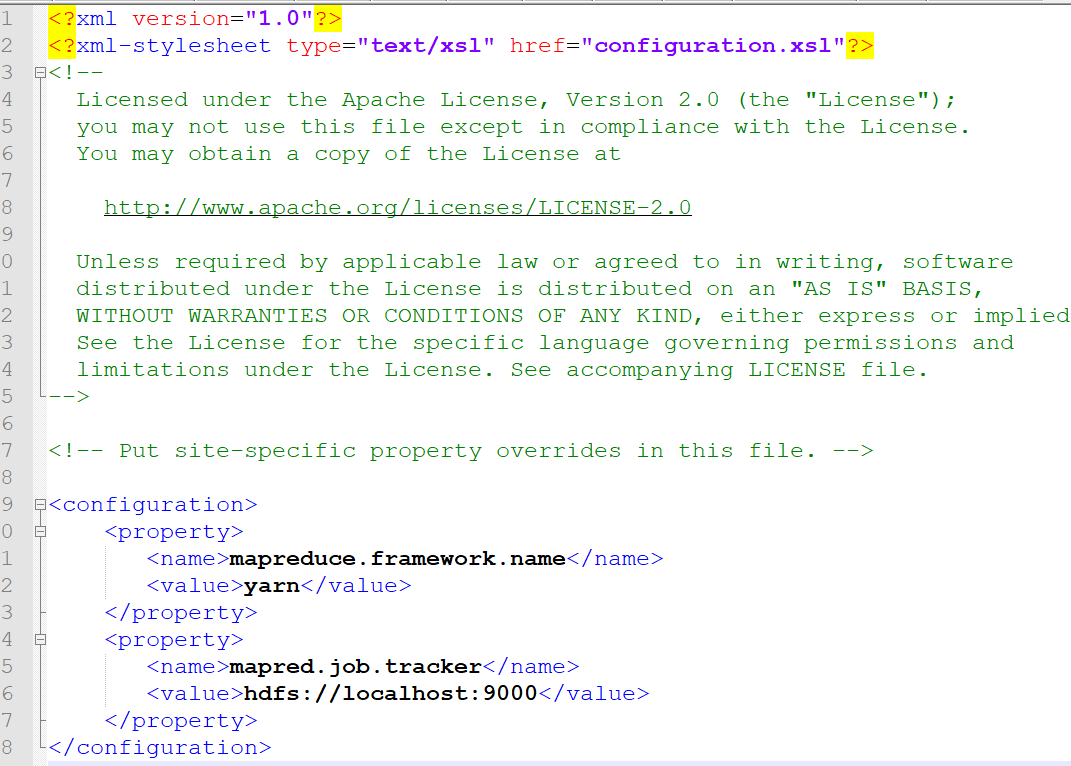
图4-3 mapred-site.xml 参数配置
- 配置yarn-site.xml
yarn-site.xml 是 用于设置 YARN资源管理器的具体参数。
(1) yarn.nodemanager.aux-services:确保 MapReduce 框架可以使用 YARN 的 Shuffle 服务。
(2) yarn.nodemanager.aux-services.mapreduce.shuffle.class:确保 Shuffle 服务由 ShuffleHandler 类处理,这是 MapReduce 框架所需的。
- <configuration>
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
- <value>org.apache.hahoop.mapred.ShuffleHandler</value>
- </property>
- </configuration>
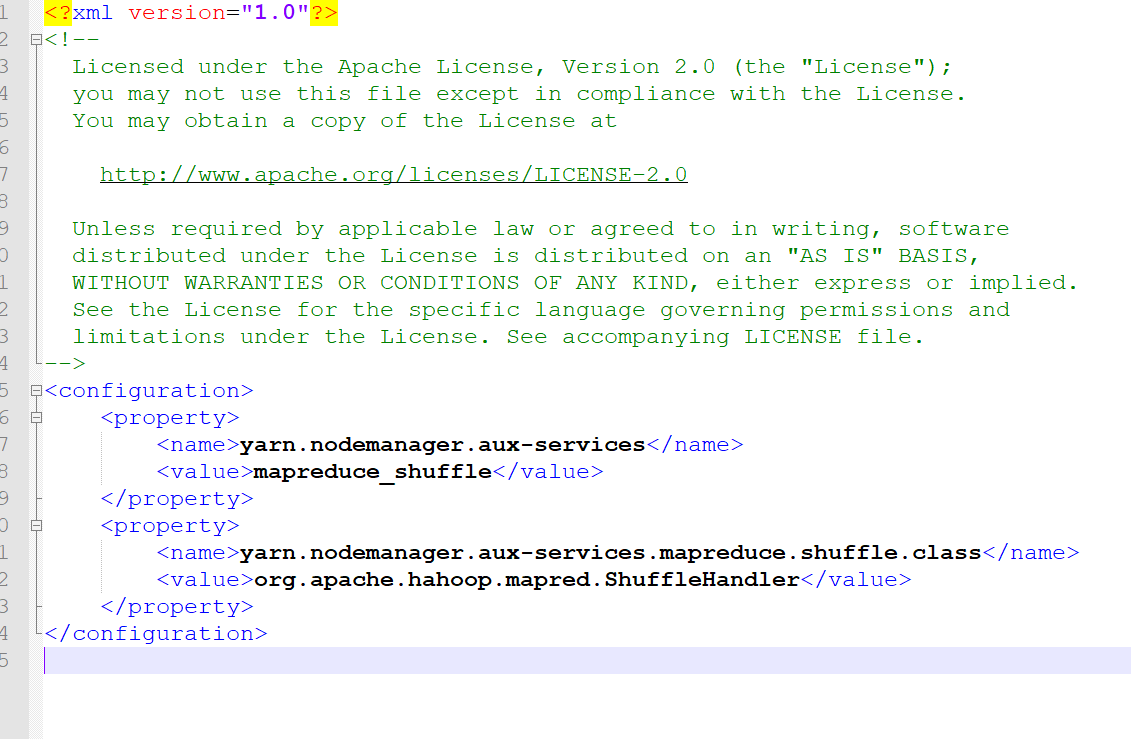
图4-4 yarn-site.xml 参数配置
- 配置hdfs-site.xml
hdfs-site.xml 是 Hadoop 用于设置 HDFS的具体参数。
- <configuration>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>/D:/hadoop/data/namenode</value>
- </property>
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>/D:/hadoop/data/datanode</value>
- </property>
- </configuration>
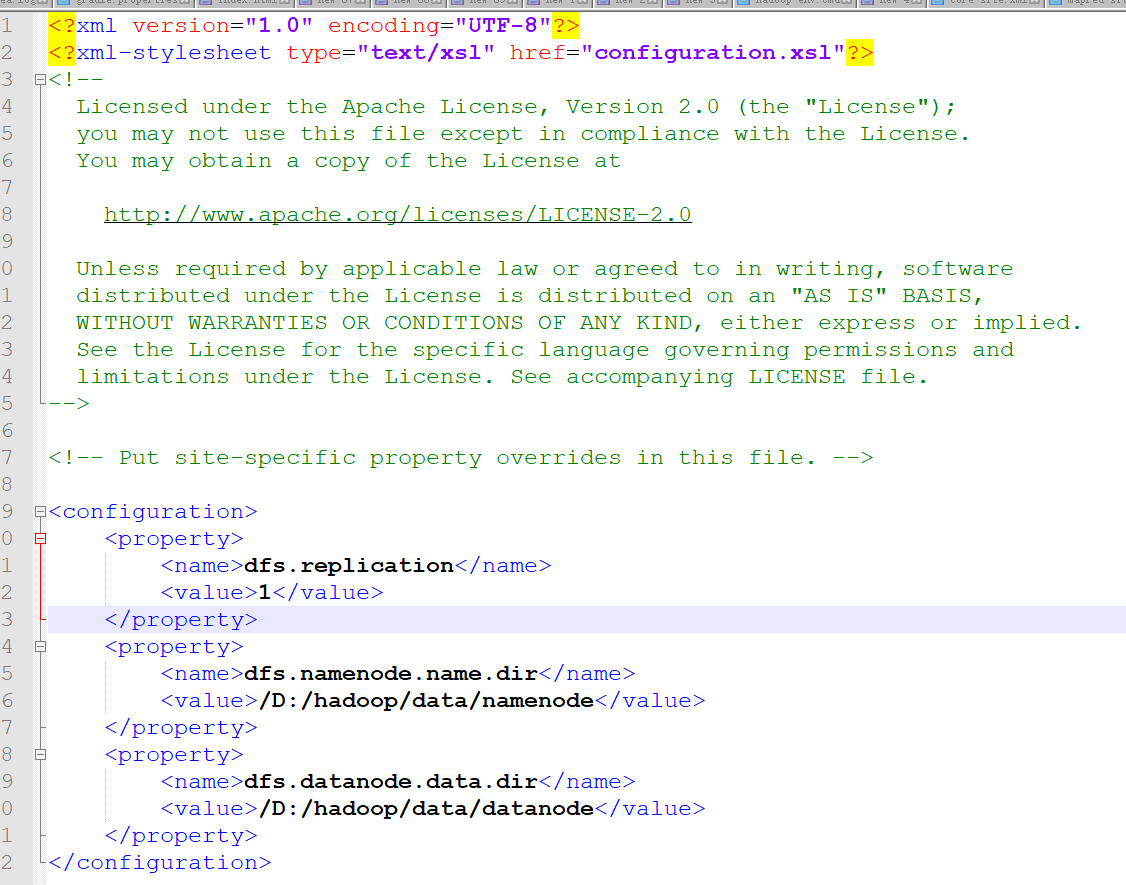
图4-5 hdfs-site.xml 参数配置
第五步,启动服务
- namenode格式化
- hdfs namenode -format
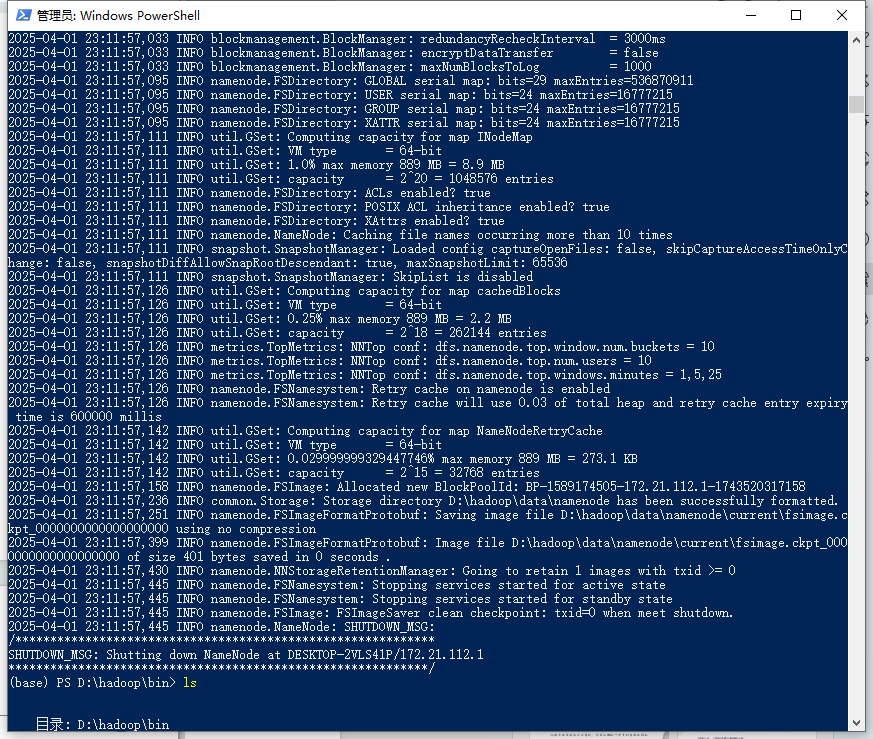
图5-1 nodename格式化
- 执行系统所有服务的初始化与启动流程
- start-all.cmd
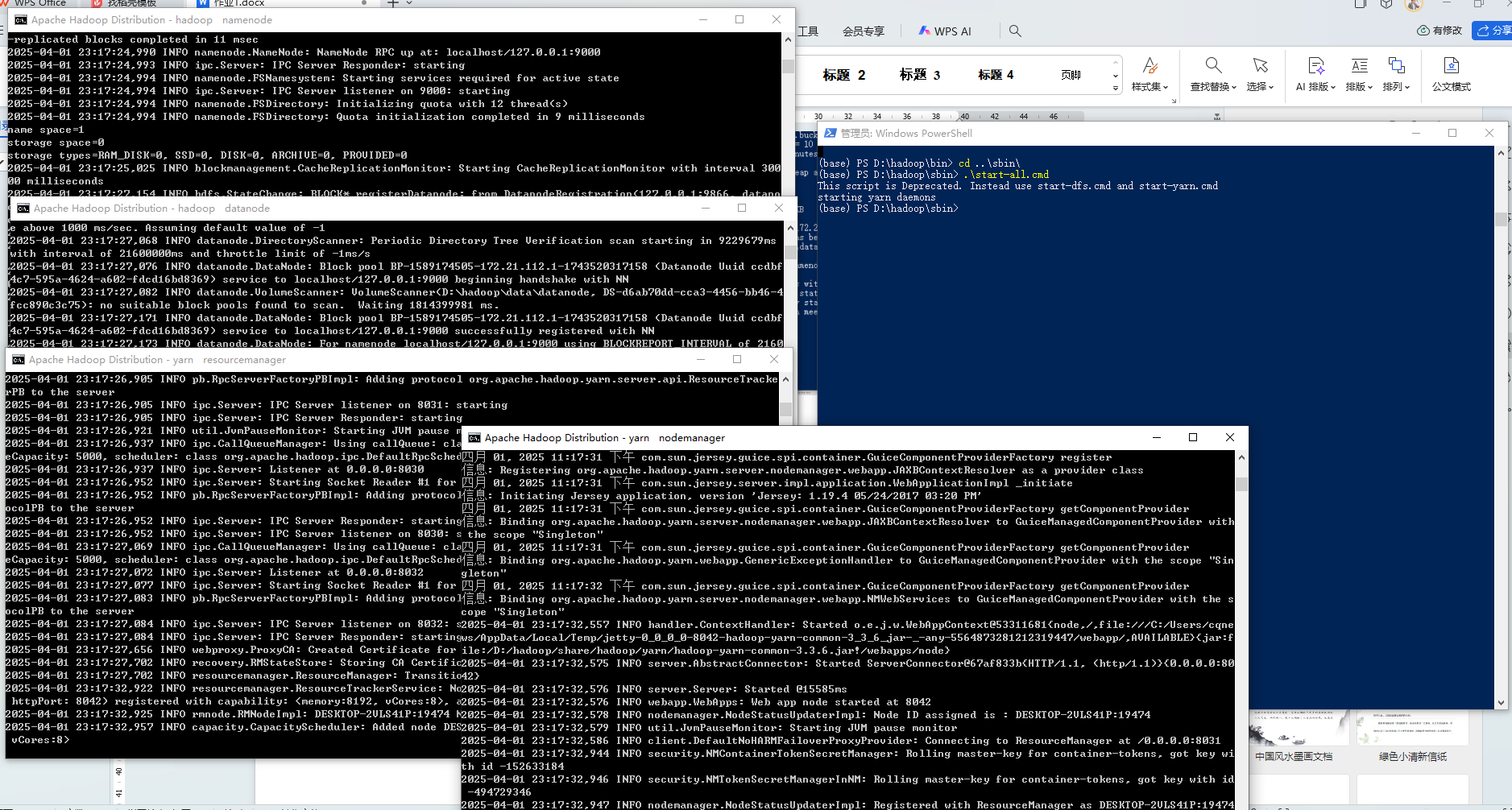
图5-2启动所有服务
第六步,访问web服务
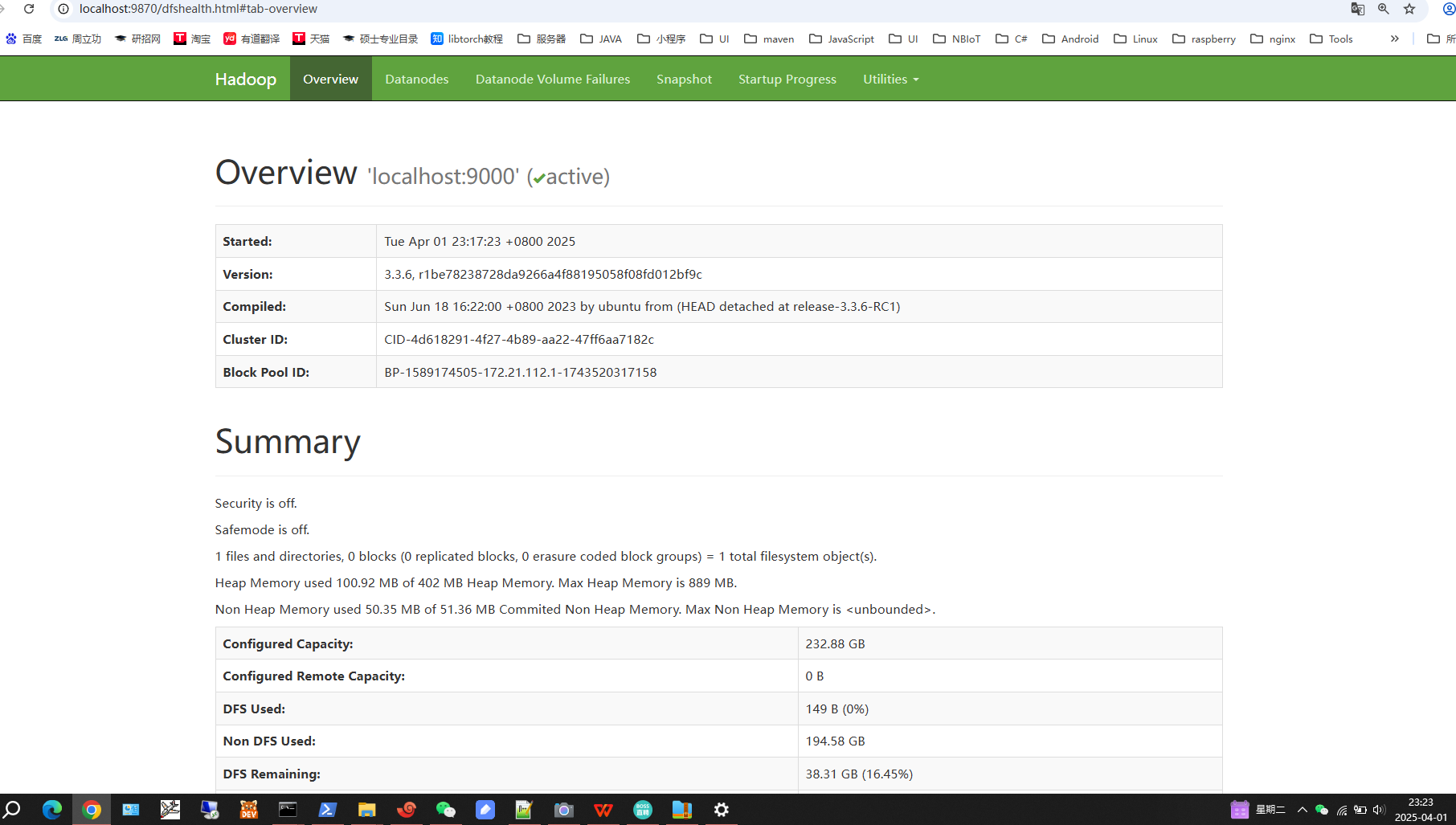
图6-1 概览页面
任务页面: http://localhost:8088/
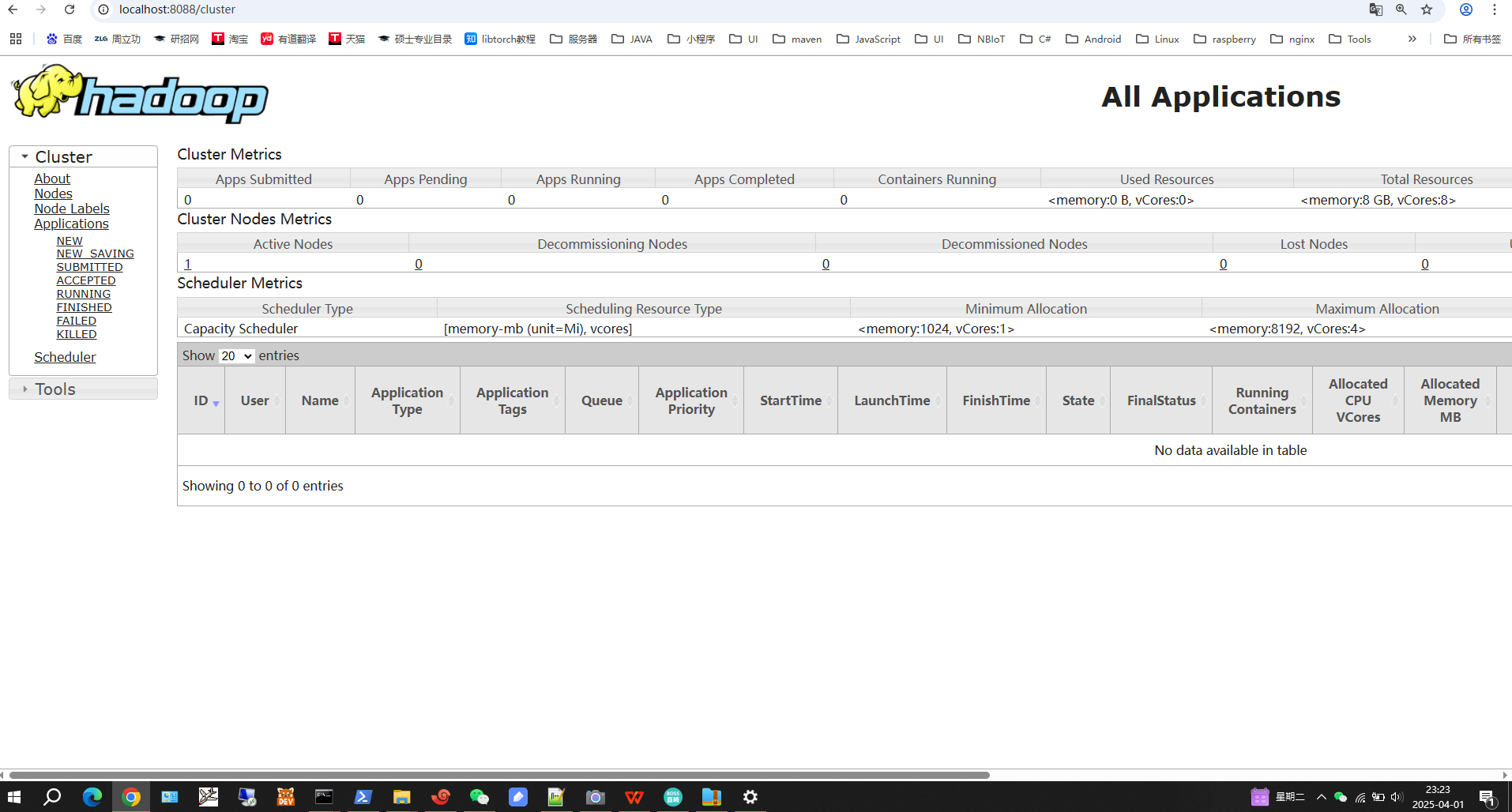
图6-2 任务页面
谢谢观看

 浙公网安备 33010602011771号
浙公网安备 33010602011771号