
机器学习算法分类
机器学习算法分类
按照学习方式分类,总共可以分为四大类,分别是监督学习,非监督学习,半监督学习和强化学习。每一类下面又会细分为很多算法,图中是将常见的列了出来。
监督学习:监督学习是使用某种算法,通过已有的训练样本(即已知数据及其对应的输出,标签)去学习从输入到输出之间的映射函数,训练得到一个最优模型。当获得足够好的最优模型后,输入新的变量时可以以此预测输出变量。因为算法从数据集学习的过程可以被看作一名教师在监督学习,所以称为监督学习。监督式学习可以进一步分为分类(输出类别标签)和回归(输出连续值)问题。
非监督学习:只有输入变量,没有相关的输出变量。目标是对数据中潜在的结构和分布建模,以便对数据做进一步的学习。无“标签”,通过分析数据本身进行建模,发掘底层信息和隐藏结构。
半监督学习:半监督式学习是一种监督式学习与非监督式学习相结合的一种学习方法。拥有大部分的输入数据(自变量)和少部分的有标签数据(因变量)。可以使用非监督式学习发现和学习输入变量的结构;使用监督式学习技术对无标签的数据进行标签的预测,并将这些数据传递给监督式学习算法作为训练数据,然后使用这个模型在新的数据上进行预测。
强化学习:强化学习是智能体(Agent)以“试错”的方式进行学习,通过与环境不断地进行交互获得的奖赏来选择合适的行为,目标是使智能体获得最大的奖赏,中由环境提供的强化信号是对产生动作的好坏作一种评价(通常为标量信号),而不是告诉强化学习系统RLS(reinforcement learning system)如何去产生正确的动作。由于外部环境提供的信息很少,RLS必须靠自身的经历进行学习。通过这种方式,RLS在行动-评价的环境中获得知识,改进行动方案以适应环境。强化学习是一种动态的交互过程,而前面三种则是静态的。
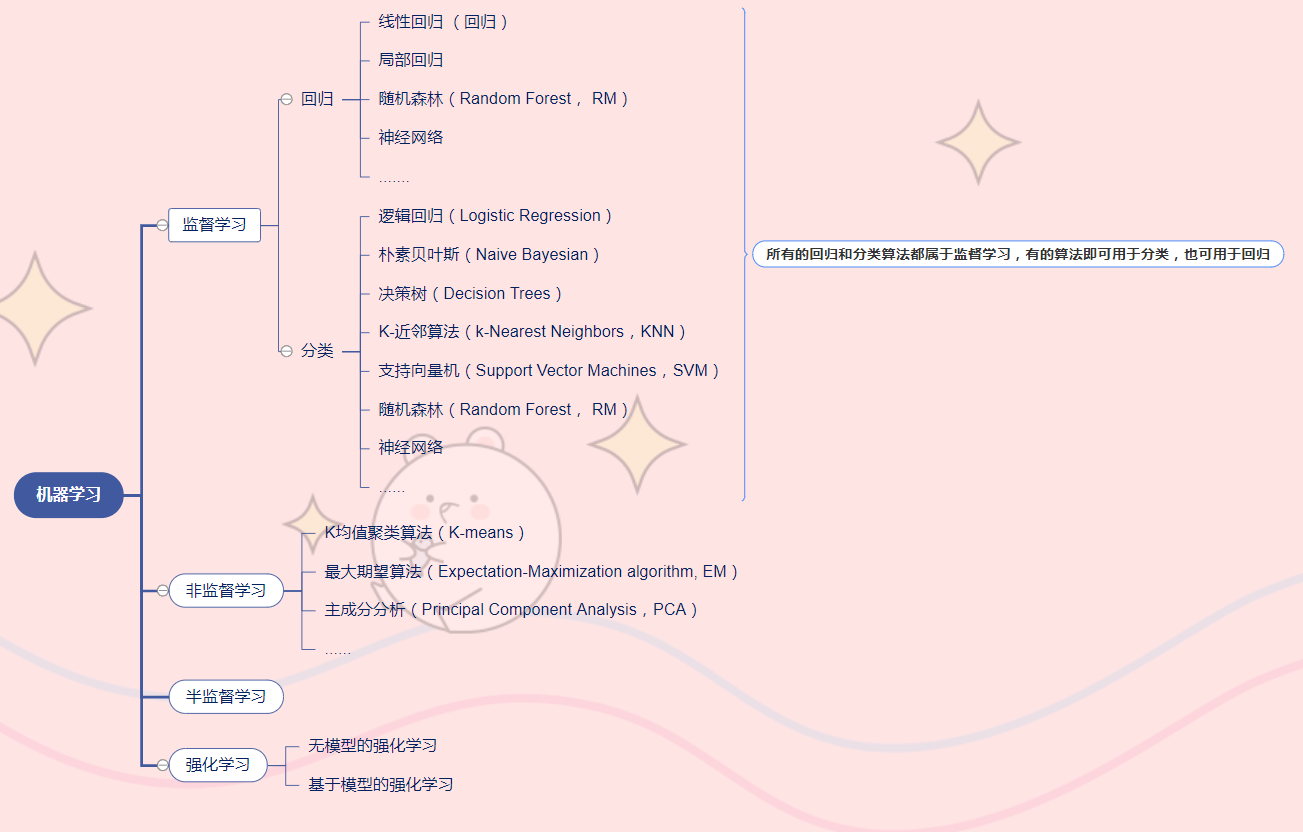
下面说一下最常见的十种机器学习算法,这是必须掌握的,当然,以后需要掌握的算法也会越来越多的。
- 线性回归
- 逻辑回归
- 朴素贝叶斯
- KNN算法
- 支持向量机
- K-均值算法
- 随机森林
- 决策树
- 神经网络
- Boosting和AdaBoost算法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号