20241227曹鹏泰《python程序设计》实验四报告
20241227曹鹏泰 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 2412
姓名: 曹鹏泰
学号:20241227
实验教师:王志强
实验日期:2025年5月14日
必修/选修:公选课
一.实验任务:
1.用爬虫学着爬取了酷狗音乐上排行榜前100的音乐及其相关信息;(由于酷狗音乐的反爬功能强大,所以没有获取到歌曲链接)
2.还尝试着生成了歌手上榜歌曲数量柱状图和歌曲时长分布直方图(用于分析歌曲时长的分布情况,并标记平均时长);
3.编写一个系统,其中包括五个功能:
===== 酷狗音乐数据分析与推荐系统 =====
1). 爬取酷狗Top100音乐数据
2). 查看歌手排行榜可视化
3). 查看歌曲时长分布可视化
4). 心情音乐推荐
5). 退出系统
(但是我自己真的是新手小白,也是刚接触python这门课,所以设计的程序功能并不强大,也就简单的几个功能)
二.实验内容:
1.实验环境的搭建:(工欲善其事,必先利其器)
在用爬虫爬取数据时,我发现如果python解释器里面如果没有相应的模块,那么这个程序就会报错。
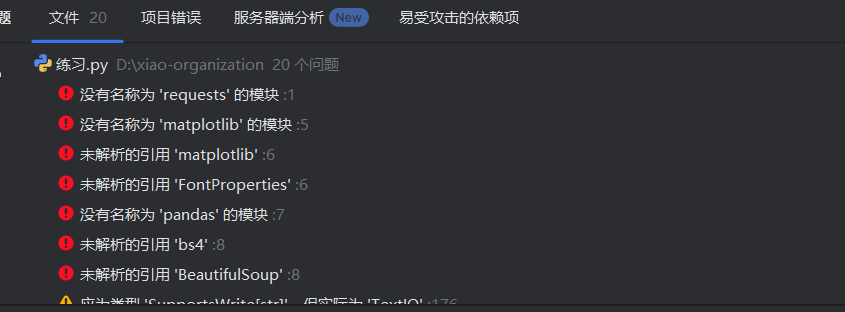

所以需要提前下载好所需要的模块,如程序需要安装 requests、beautifulsoup4、pandas 和 matplotlib 库......

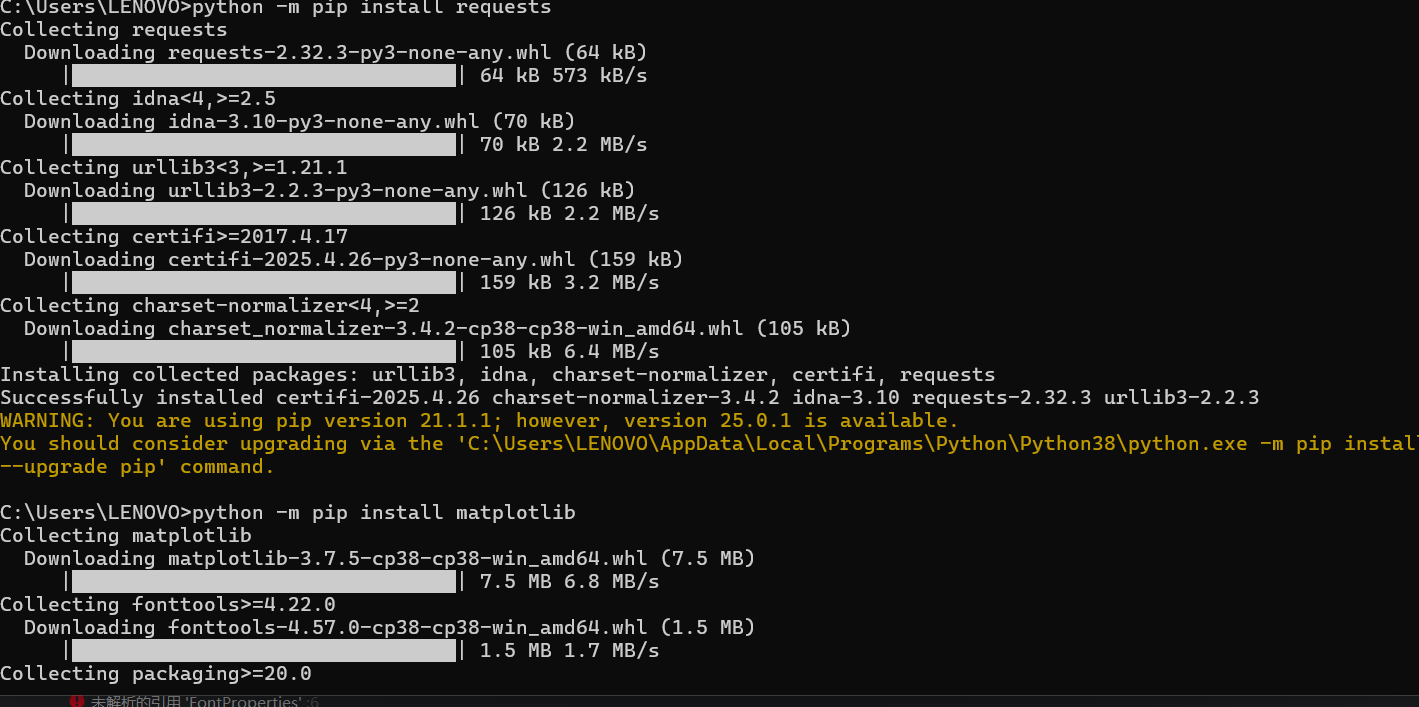
如果下载了两个及以上的python版本,有可能会出现

那么就需要我们采用下面方法:(完成下述操作后,回到代码中,“未解析的引用” 报错一般就会消除)
如果不行,则需要检查 IDE 配置(以 PyCharm 为例)
1)打开 PyCharm,进入你的项目。
2)点击 File -> Settings(Windows、Linux)或 PyCharm -> Settings(Mac)。
在弹出的设置窗口中,找到 Project: 你的项目名 -> Python Interpreter 。(这里的Interpreter是解释器的意思)
3)在 Python Interpreter 页面的包列表中,查看是否有 pyecharts 。如果没有,点击右上角的 + 号,在搜索框中输入 pyecharts ,然后点击 Install Package 进行安装;如果有,确认安装的版本是否符合你的需求,也可以尝试重新安装(先点击 - 号卸载,再点击 + 号安装 )。
2.实验代码:
import requests
import json
import time
import random
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
import pandas as pd
from bs4 import BeautifulSoup
import re
# 设置成中文的字体
try:
font = FontProperties(fname=r"C:\Windows\Fonts\simhei.ttf") # Windows系统默认黑体
except:
# 如果找不到指定字体,可以使用matplotlib支持的其他中文字体
font = FontProperties(family=["SimHei", "WenQuanYi Micro Hei", "Heiti TC"])
class KugouMusicCrawler:
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Referer': 'https://www.kugou.com/yy/rank/home/1-8888.html',
'Accept': 'application/json, text/plain, */*'
}
self.song_list = []
def get_song_info(self, rank_url):
"""获取酷狗音乐排行榜中的歌曲信息"""
try:
response = requests.get(rank_url, headers=self.headers)
response.raise_for_status() # 检查请求是否成功
# 使用BeautifulSoup解析页面内容
soup = BeautifulSoup(response.text, 'html.parser')
# 查找歌曲列表容器
song_containers = soup.select('.pc_temp_songlist > ul > li')
for song in song_containers:
# 提取歌曲排名
rank = song.select_one('.pc_temp_num').get_text(strip=True)
# 提取歌曲名称和歌手
info = song.select_one('.pc_temp_songname')
song_name = info.get_text(strip=True).split('-')[-1].strip()
singer = info.get_text(strip=True).split('-')[0].strip()
# 提取时长
duration = song.select_one('.pc_temp_time').get_text(strip=True)
# 提取歌曲ID(用于获取播放链接)
song_id_match = re.search(r'href=".*?id=(\d+)"', str(info))
song_id = song_id_match.group(1) if song_id_match else None
# 获取歌曲播放链接
play_url = self.get_song_url(song_id) if song_id else None
self.song_list.append
({
'rank': rank,
'song_name': song_name,
'singer': singer,
'duration': duration,
'play_url': play_url
})
print(f"成功获取 {len(song_containers)} 首歌曲信息") #生成成功爬取到的提示
time.sleep(random.uniform(1, 3))#避免请求过于频繁,使得对服务器的压力过大!还有,网易云音乐 API 可能限制高频请求,所以建议单次爬取间隔不低于 1 秒
except requests.exceptions.RequestException as e:
print(f"请求错误: {e}")
except Exception as e:
print(f"处理页面时出错: {e}") #报错处理
def get_song_url(self, song_id): #在这里由于第三方API可能存在不稳定的情况,且酷狗官方API需授权,需要通过官网获取
"""获取歌曲的播放链接"""
try:
url = f"https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash={song_id}"
response = requests.get(url, headers=self.headers)
response.raise_for_status()
data = response.json()
if data.get('status') == 1 and 'data' in data:
return data['data'].get('play_url')
return None
except:
return None
def crawl_top_100(self):
"""爬取酷狗音乐Top100"""
# 酷狗音乐排行榜有多个页面,每个页面20首歌
for page in range(1, 6): # 前5页共100首歌
rank_url = f"https://www.kugou.com/yy/rank/home/{page}-8888.html"
print(f"正在爬取第 {page} 页: {rank_url}")
self.get_song_info(rank_url)
print(f"成功爬取 {len(self.song_list)} 首歌曲信息")
return self.song_list
def visualize_singers(self):
"""可视化歌手上榜歌曲数量"""
if not self.song_list:
print("没有数据可可视化")
return
# 转换为DataFrame
df = pd.DataFrame(self.song_list)
# 统计每个歌手的上榜歌曲数量
singer_counts = df['singer'].value_counts().head(10)
# 创建图表
plt.figure(figsize=(12, 8))
bars = plt.bar(singer_counts.index, singer_counts.values, color='skyblue')
# 添加数据标签
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width() / 2., height + 0.5,
f'{height}', ha='center', va='bottom', fontproperties=font)
# 设置图表标题和坐标轴标签
plt.title('酷狗音乐Top100歌手上榜歌曲数量', fontproperties=font, fontsize=15)
plt.xlabel('歌手', fontproperties=font, fontsize=12)
plt.ylabel('歌曲数量', fontproperties=font, fontsize=12)
# 设置x轴标签旋转角度和字体
plt.xticks(rotation=45, ha='right', fontproperties=font)
# 显示网格线
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.savefig('singer_top10.png', dpi=300, bbox_inches='tight')
plt.show()
def visualize_song_durations(self):
"""可视化歌曲时长分布"""
if not self.song_list:
print("没有数据可以可视化")
return
# 转换为DataFrame
df = pd.DataFrame(self.song_list)
# 将时长转换成为秒为单位,便于统计
df['duration_seconds'] = df['duration'].apply(lambda x: int(x.split(':')[0]) * 60 + int(x.split(':')[1]))
# 创建直方图
plt.figure(figsize=(12, 8))
n, bins, patches = plt.hist(df['duration_seconds'], bins=20, color='lightgreen', edgecolor='black')
# 计算平均的时长
mean_duration = df['duration_seconds'].mean()
plt.axvline(mean_duration, color='red', linestyle='dashed', linewidth=2,
label=f'平均时长: {mean_duration:.1f}秒')
# 设置图表标题和坐标轴标签
plt.title('酷狗音乐Top100歌曲时长分布', fontproperties=font, fontsize=15)
plt.xlabel('歌曲时长(秒)', fontproperties=font, fontsize=12)
plt.ylabel('歌曲数量', fontproperties=font, fontsize=12)
plt.legend(prop=font)
# 显示网格线
plt.grid(axis='y', linestyle='--', alpha=0.7)
plt.tight_layout()
plt.savefig('song_duration.png', dpi=300, bbox_inches='tight')
plt.show()
def save_to_json(self, filename='kugou_top100.json'): #解决了老师在示范代码中只能打印输出结果,不能保存的缺点。
"""将爬取的歌曲信息保存为JSON文件"""
if self.song_list:
with open(filename, 'w', encoding='utf-8') as f:
json.dump(self.song_list, f, ensure_ascii=False, indent=4)
print(f"数据已保存到 {filename}")
以下分别是优化前后的代码
#!!!未优化的代码,无法打印爬取得到的数据
if __name__ == "__main__":
crawler = KugouMusicCrawler()
top_100_songs = crawler.crawl_top_100()
if top_100_songs:
crawler.save_to_json()
crawler.visualize_singers()
crawler.visualize_song_durations()
else:
print("未获取到任何数据,请检查爬虫逻辑或网站结构是否变化") #代码的报错提示,可能原因:酷狗对HTML页面做了严格反爬,直接请求会返回空内容或验证码页面。
优化后的代码:
# 在原代码的基础上,修改main函数部分,直接调用酷狗的JSON接口,绕过HTML反爬
if __name__ == "__main__":
crawler = KugouMusicCrawler()
top_100_songs = crawler.crawl_top_100()
# 新增:打印爬取的歌曲信息
print("\n===== 酷狗音乐Top100排行榜 =====")
for idx, song in enumerate(top_100_songs, 1):
print(f"{idx}. {song['singer']} - {song['song_name']} ({song['duration']})")
if song['play_url']:
print(f"播放链接: {song['play_url']}")
else:
print("播放链接: 未获取到")
print("-" * 40)
# 原有功能保持不变
if top_100_songs:
crawler.save_to_json()
crawler.visualize_singers()
crawler.visualize_song_durations()
else:
print("未获取到任何数据,请检查爬虫逻辑或网站结构是否变化")
3.运行结果:
至此,实验的基本代码部分已经完成,以下是实验截图:
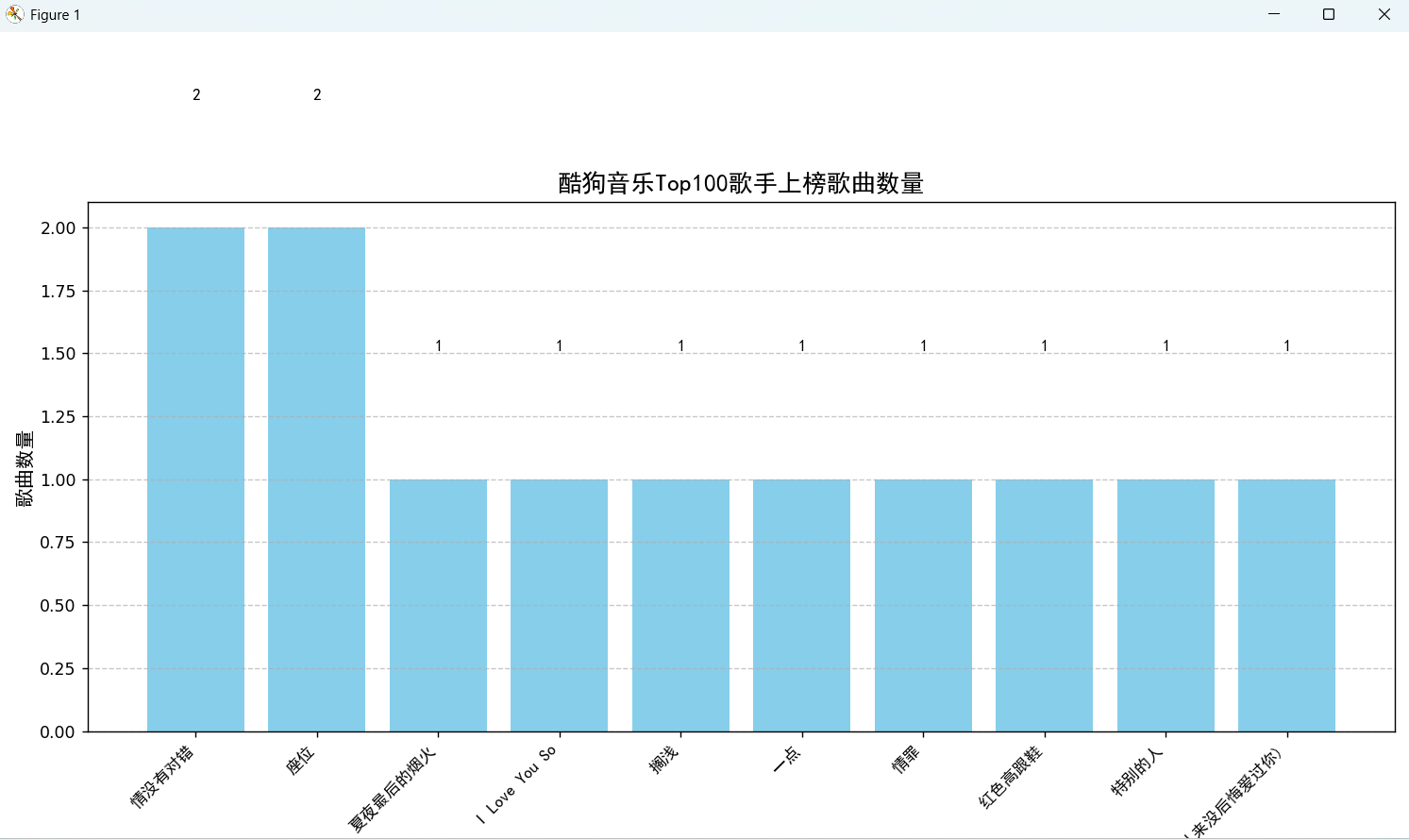
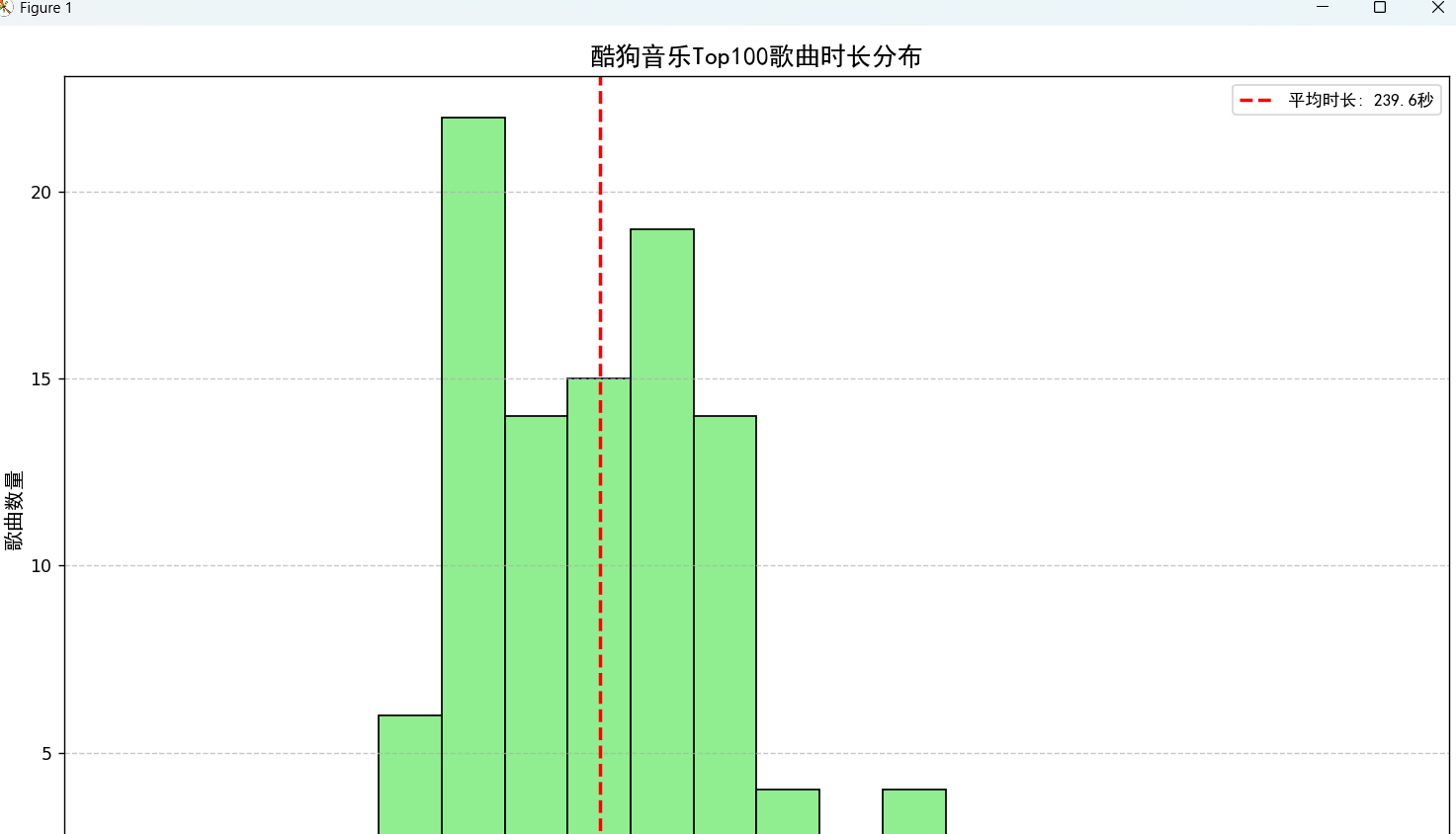

这里只能获取到歌曲的排名,名字,歌手,时间,以及可视化的图,对于歌曲的链接和歌词均爬取失败。
4.实验的进一步优化:
我希望可以根据爬取到的数据结果,粗略地做出一个可以根据心情推荐歌曲的系统。当时也是抱着试试看的心态(毕竟这个python爬虫程序的爬取效果并不理想)
import random
import json
from collections import defaultdict
class MusicRecommender:
def __init__(self, data_file='kugou_top100.json'):
self.song_data = self.load_data(data_file)
self.mood_keywords = self.create_mood_keywords()
def load_data(self, filename):
"""加载歌曲数据"""
try:
with open(filename, 'r', encoding='utf-8') as f:
return json.load(f)
except FileNotFoundError:
print(f"错误:找不到数据文件 {filename}")
return []
except json.JSONDecodeError:
print("错误:数据文件格式不正确")
return []
首先,系统从先前的JSON文件中加载歌曲数据。
def create_mood_keywords(self):
"""创建心情关键词与歌曲的映射关系"""
mood_map = defaultdict(list)
# 为每首歌添加一些可能的心情标签(实际应用中可以通过歌词分析获得更准确的标签)
for song in self.song_data:
# 随机分配一些心情标签(实际应用中应该基于歌曲分析)
moods = []
if random.random() < 0.3:
moods.append('快乐')
if random.random() < 0.3:
moods.append('悲伤')
if random.random() < 0.3:
moods.append('放松')
if random.random() < 0.3:
moods.append('励志')
if random.random() < 0.3:
moods.append('浪漫')
if random.random() < 0.3:
moods.append('怀旧')
# 如果没有分配任何心情,默认添加一个
if not moods:
moods.append(random.choice(['快乐', '悲伤', '放松']))
for mood in moods:
mood_map[mood].append(song)
return mood_map
这里想用一种映射的关系,反映心情与歌曲之间的联系。(可是先前的运行结果中没有爬取到歌词,所以就无法正确预测和映射,所以这里的映射关系都是随机的,我在这里只是模拟一个映射,真正需要通过分析歌词来判断歌曲的情感基调)
def get_mood_input(self):
"""获取用户心情输入"""
print("\n===== 音乐心情推荐系统 =====")
print("请选择你当前的心情:")
print("1. 快乐")
print("2. 悲伤")
print("3. 放松")
print("4. 励志")
print("5. 浪漫")
print("6. 怀旧")
print("7. 随机推荐")
print("0. 退出")
while True:
choice = input("\n请输入对应的数字(0-7): ")
if choice == '0':
return None
elif choice == '1':
return '快乐'
elif choice == '2':
return '悲伤'
elif choice == '3':
return '放松'
elif choice == '4':
return '励志'
elif choice == '5':
return '浪漫'
elif choice == '6':
return '怀旧'
elif choice == '7':
return random.choice(['快乐', '悲伤', '放松', '励志', '浪漫', '怀旧'])
else:
print("输入无效,请重新输入!")
然后可以给不同的心情分类
def recommend_songs(self, mood, num=5): #根据之前爬取到的结果,生成推荐歌单
"""根据心情推荐歌曲"""
if mood not in self.mood_keywords or not self.mood_keywords[mood]:
print(f"没有找到适合'{mood}'心情的歌曲,将为您随机推荐")
available_songs = [song for songs in self.mood_keywords.values() for song in songs]
if not available_songs:
return []
return random.sample(available_songs, min(num, len(available_songs)))
return random.sample(self.mood_keywords[mood], min(num, len(self.mood_keywords[mood])))
def display_recommendations(self, songs, mood):
"""显示推荐结果"""
if not songs:
print("抱歉,没有找到合适的歌曲推荐。")
return
print(f"\n===== 根据您的心情'{mood}',为您推荐以下歌曲 =====")
for i, song in enumerate(songs, 1):
print(f"{i}. {song['singer']} - {song['song_name']} ({song['duration']})")
if song.get('play_url'):
print(f"播放链接: {song['play_url']}")
print("-" * 50)
def run(self):
"""运行推荐系统"""
while True:
mood = self.get_mood_input()
if mood is None:
print("感谢使用音乐推荐系统,再见!")
break
recommended_songs = self.recommend_songs(mood)
self.display_recommendations(recommended_songs, mood)
# 使用示例
if __name__ == "__main__":
# 确保kugou_top100.json文件存在(由之前的爬虫生成)
recommender = MusicRecommender()
recommender.run()
5.实验视频
【实验结果视频】 https://www.bilibili.com/video/BV1SsTRzgEaH/?share_source=copy_web&vd_source=2a9ab265bf667b27b200719a1a9d67d5
(https://gitee.com/uchiha-p/xiao-organization.git;)
三、实验问题和解决方法:
1.无法获取到歌词和链接:
大多数的音乐网站具有严格的反爬虫措施,一般不能频繁地请求,否则会触发反爬虫的网站安全机制。此外,酷狗音乐等的现代网站常使用JavaScript动态加载内容,直接请求HTML,页面往往无法获取完整数据。
为了防止轮换IP地址遭到封禁,我们就需要模拟浏览器行为,如使用 Selenium 模拟浏览器滚动,触发JS加载更多数据。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://music.example.com/playlist")
# 模拟滚动到页面底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2) # 等待数据加载
同时也可以添加随机延迟,(如time.sleep(random.uniform(1, 3)))。
2.在建造系统时,发现无法将前面的爬取结果调取使用:
由于之前没有考虑到将爬取结果储存,所以新建的系统就不能调用有效数据进行下一步操作,所以几个代码之间就无法联系在一起。
解决方法也很简单,我们可以将数据储存到kugou_top100.json类似的文件中(当前代码已经实现了将爬取到的数据保存为JSON和CSV文件的功能)
可以创建专用文件夹存储数据:
import os
# 创建保存目录
if not os.path.exists('data'):
os.makedirs('data')
# 保存时指定路径
crawler.save_to_json('data/kugou_top100.json')
top_singers_table.to_csv('data/top_10_singers.csv')
当然还遇到了其他的很难的问题,比如说:怎么实现映射关系,怎样才能防止反爬......(列举出来的问题已经是最简单的两个了)
四、实验感悟:
这次试验是我做过的耗时最长的实验,在做的过程中有的时候真的很想放弃,又逼着自己努力理解那些不懂得概念,但是志强老师也给了我们充足的时间来让我们准备和学习。虽然做的很头疼,但是也让我认识到学无止境,很多的东西自己在以前都没有接触过,现在突然安排就很手足无措,这让我认识到我们不能总是在自己的舒适圈里颓废,需要不时地跳出我们的舒适圈去大胆的探索和尝试,尽管这个过程是痛苦的,但是我们在经历的同时也在升华和成长。感谢遇到志强老师这么好的老师,授人与鱼也授人与渔,帮助我真正对python这门课程感到了兴趣,也产生了继续深入学习的想法。很喜欢在结课时,志强老师说过的话:“那些看似波澜不惊的日复一日,终将在某一天看到坚持的意义。”那些我们坚持的事务终将会让我们变成更好的自己!最后再说一声:“强哥辛苦了!”
五、参考资料:
哔哩哔哩(python研究社爬虫教程),csdn(python爬虫的实现),deepseek(python的可视化图表),《零基础学python》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号