五笔
口诀
- 一 横区
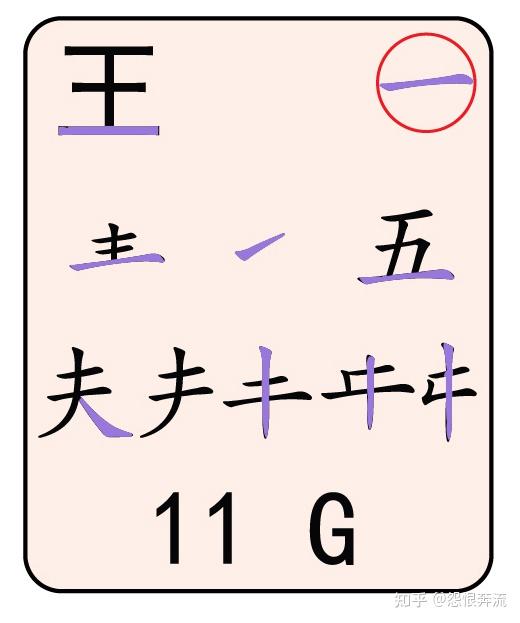
- G 王旁青头五夫一
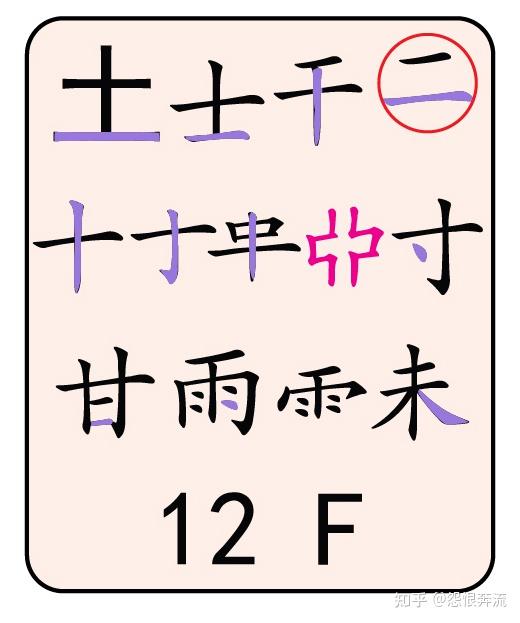
- F 土干十寸未甘雨,革字底
- D 大犬戊其古石厂
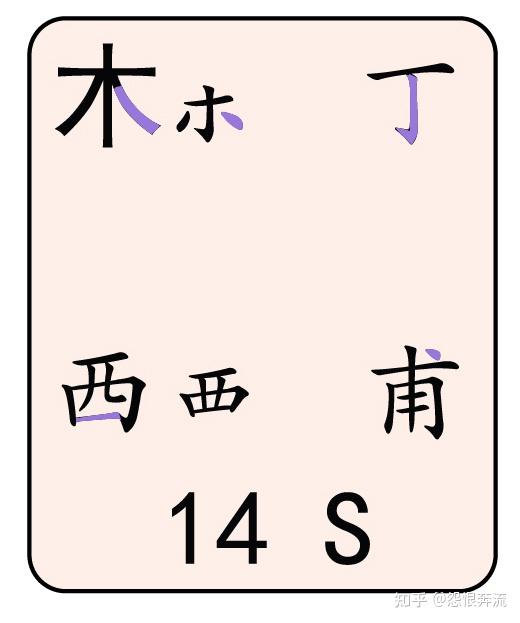
- S 木丁西甫
- A 工戈草头右框七 (廿 nian 二十)
- 丨 竖区
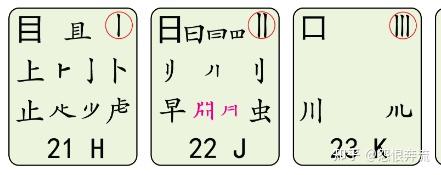
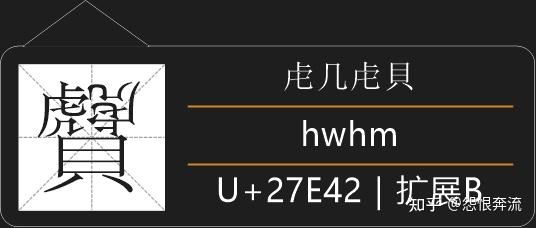
- H 目上卜止虎具头
- J 日早两竖与虫依
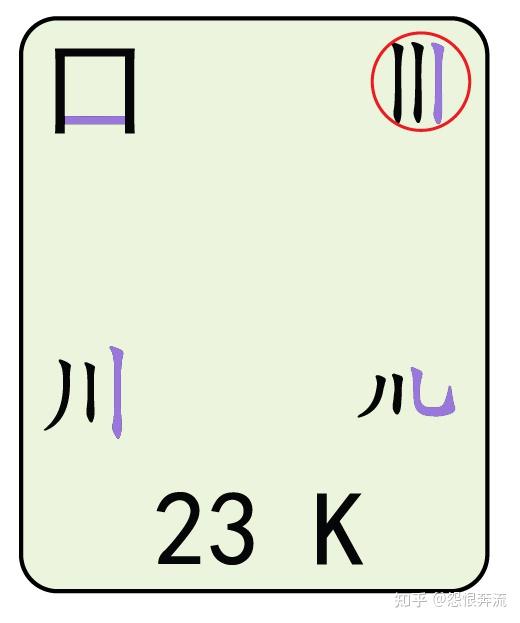
- K 口流川,三个竖
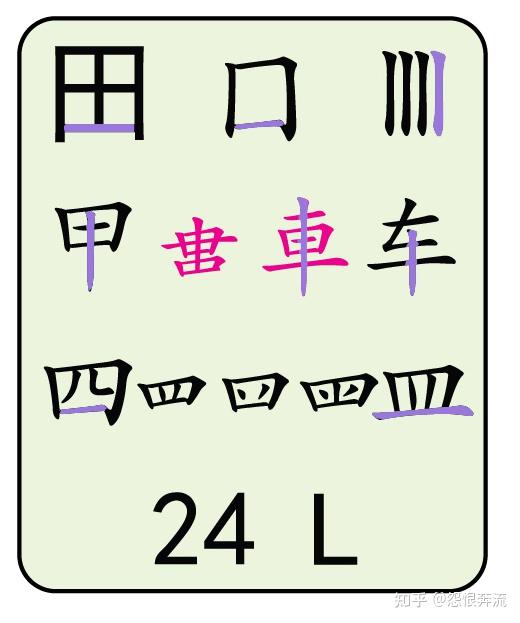
- L 田甲方框四竖车
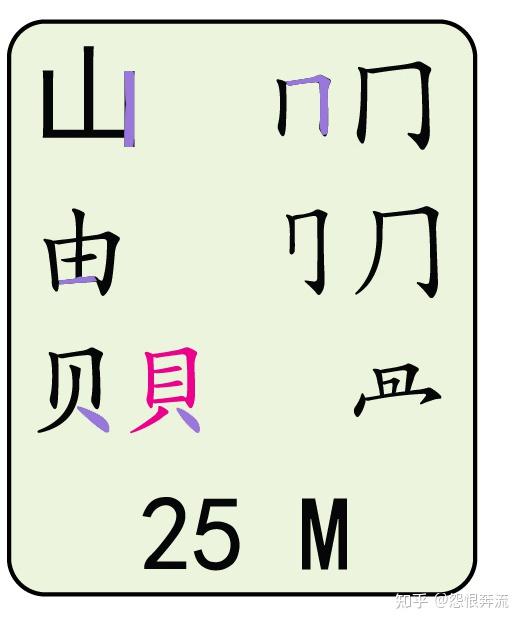
- M 山由贝骨下框集
- 丿 撇区
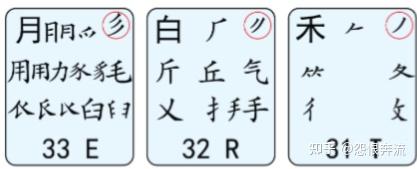
- T 禾竹攵夂双人立 (攵 pu; 夂 zhi zhong同终 ; 彳chi 双人旁 )
- R 白斤气丘叉手提
- E 月臼用力豸毛衣
- W 人八登头几
- Q 金夕鸟儿犭边鱼
- 丶捺区
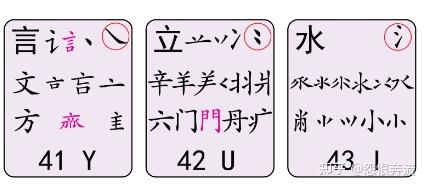
- Y 言文方亠谁人去 (亠 tou 汉字偏旁,京字头,点横头; 讠 同言 言字旁 )
- U 立辛六羊病门舟
- I 水旁三点鳖头小
- O 火业广鹿四点米
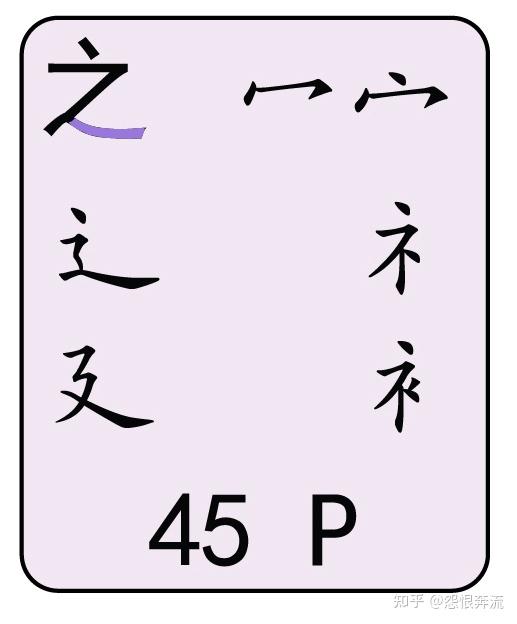
- P 之廴宝盖辶礻衤(廴yin 辶chuo)
- 乙 折区
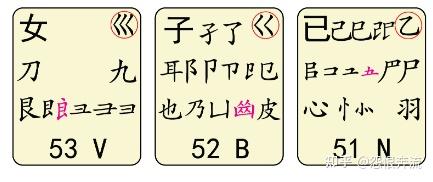
- N 已类左框心尸羽 (忄同心,“竖心旁”)
- B 子了耳也乃凵皮(凵 kan)
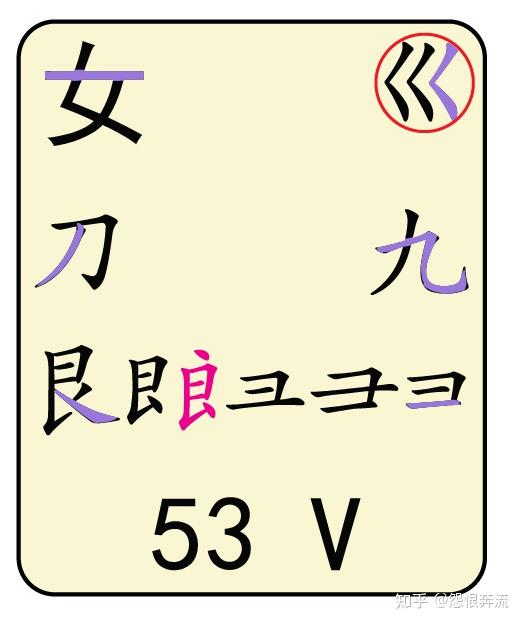
- V 女刀九艮山朝西 (艮gèn)
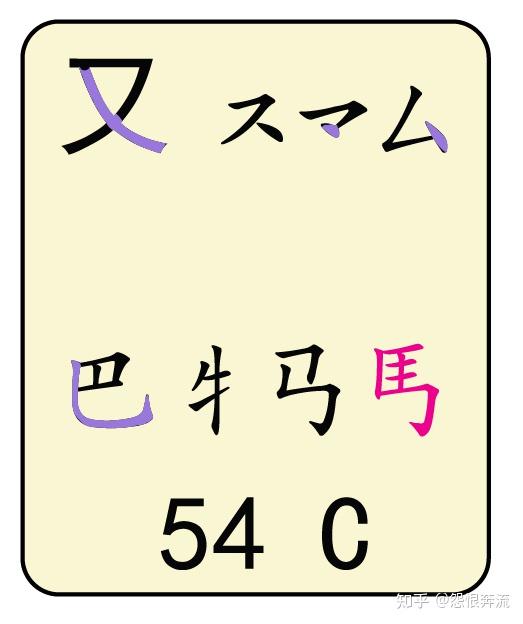
- C 又巴牛厶马失蹄 (厶 si mou)
- X 幺母贯头弓互匕


一,丨,丿,乀(丶),乙(折),其输入方式分别是GGLL、HHLL、TTLL、YYLL、NNLL。

版本安装
windows用搜狗
mac用自带的
一、认识五笔 98
1、五笔 98 简介
五笔字型发明人王永民教授从 1988 起,用 10 年之功研究完成的 “98 规范王码”,是我国第一个符合国家规范并通过鉴定的汉字输入法。这一方案 “在现行五笔字型科学体系的基础上,从理论到实践,完成了多方面的重大创新。其编码体系科学合理、部件规范、编码规则简单明了、好学易用、输入效率高、与原方案具有良好的兼容性,是完全符合部件规范,具有世界领先水平的形码汉字输入技术,是我国汉字输入技术向规范化、社会化、国际化迈进的一次重大突破。其广泛应用,可望早日结束我国当前汉字编码‘万码奔腾’的历史,开创将汉字输入法大规模纳入中小学教学的新局面,标志着我国汉字输入技术进入了一个新的历史阶段。(摘自百度百科)
五笔 98 是五笔字型输入法的第二代,较上一版的 86 版,增加了大量字根,使爽快输入大字集成为可能,对于喜欢输入大字集的朋友非常友好,无理拆分大大减少,实现了拆字思维的统一等。这些改动,使五笔的发展更进一步,对于想学习形码的朋友,可以尝试学一下五笔 98,上手快,字根规律,记忆负担小。
五笔虽然称为五笔,但实际上,每一个汉字最多只需要四个按键就可以确定,最多四个按键就可以确定一个字,所以五笔是一种四码定长的方案。
2、形码简介
以一个字的音素为依据,输入这个汉字的方式,叫作音码,比如拼音,拼音输入法是输入这个字的国语拼音,然后选择出想要的字,这几乎是每个上网人都会的技能,因为拼音教育贯穿整个小学,学习拼音输入法,几乎是没有什么难度,但是代价是恐怖的重码,重码就是输入一串编码,有多个候选项,而不是只有一个候选项,有多个候选项的编码就叫作重码。虽然联网和组词输入可以使自己想要的字靠前,但是大多数时候还是需要看着选项框来选择,而且要一直选,更别说如果遇见一个不会读的生僻字了。拼音输入法支持 u 模式来进行对不认识的字的输入,但这种方法适用于输入少量不认识的字,如果需要输入大量的这种字,恐怕就需要另一种方式了。
与音码相对的,以一个字的形状为依据,输入其汉字部件来组合成这个字的方法,叫作形码,顾名思义,就像大家写字一样,写的是这个汉字的象形。形码输入法就像是在键盘上写出这个字一样,但是我们不用一笔一划地写,而是先提前设置好汉字的部件,需要打某个字的时候,就输入这个汉字的部件,将它们组合,比如 好 字,设置好 女 和 子 两个部件,我们就可以用 女 子 来输入好这个字了,这就是形码的原理。
而形码也分成了双编码型和单编码型,这个稍后讲到。
有音码,有形码,那自然就有音形结合的码,简称音形,它既有音码和形码的优点,同时也有音码和形码的缺点,大家见仁见智。
3、五笔 98 详介
3.1 五笔 98 的分区
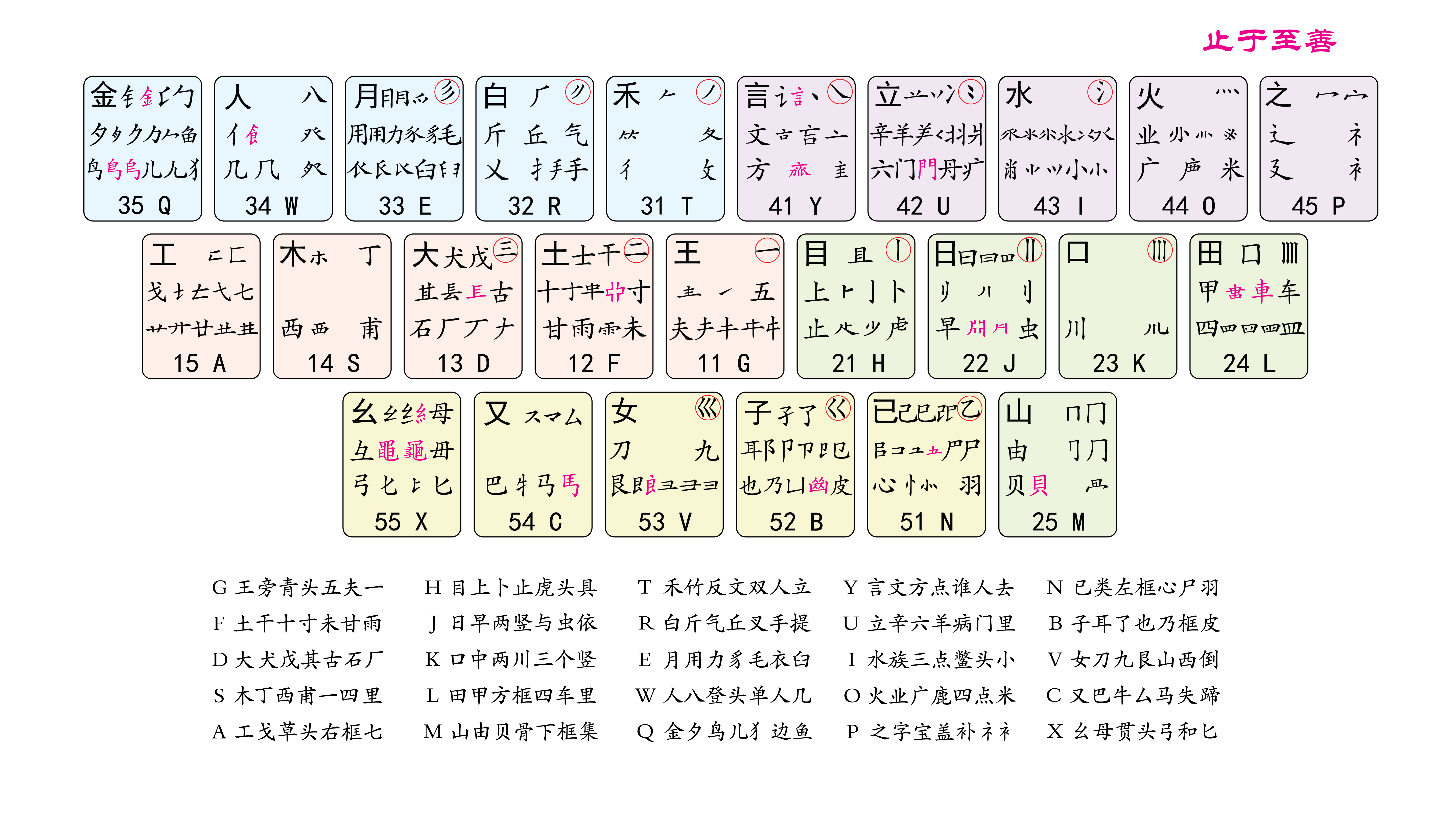
五笔的意思是横竖撇捺折五种笔划,将这五种笔划分别放置进键盘,就形成了五个区,请看:
浅蓝色的五个按键 QWERT 是五笔的撇区,其中的汉字部件大多以撇起笔。其区域编码为 3,以 TREWQ 的顺序来排,其区域编码分别为 31、32、33、34、35。
紫色的 YUIOP 则是捺区,其中的汉字部件大多以捺起笔,需要说明的是,丶 属于捺的范畴,这类点,包含了从左上到右下的点,也包括了从右上到左下的点,如 文 的第一笔,还有 亦 的下半部分,亦的下半部分的最左边就属于自右上到左下的点。以 YUIOP 的顺序来排,其区域编码分别为 41、42、43、44、45。
粉色的 ASDFG 五笔按键则是横区,需要注意的是,提,如刁中的提,冫的第二笔,自左下向右上的提,算作横,七 字中的那一提,也算作横。以 GFDSA 的顺序来排,其区域编码分别为 11、12、13、14、15。
绿色的 HJKLM 是竖区,同样需要注意的是,亅 竖钩这个部件,也算作是竖的一种。以 HJKLM 的顺序来排,其区域编码分别为 21、22、23、24、25。
黄色的 XCVBN 是折区,而 顿 这个字中的竖提,算作折,和前面的 亅 要作区分,方法就是看方向,朝左的就属于竖,朝右的就属于折。以 NBVCX 的顺序来排,其区域编码分别为 51、52、53、54、55。
虽然对汉字部件做了分区,以部件的首笔来确定这个部件的位置,但是并不是严格按照这个规定来实行的,因为考虑到打字的手感,和相似部件的划分等,细心的网友应该能发现。依据部件起笔来分区的输入法方案,称作有序方案,这种方案的汉字部件分类有规律,在学习的过程中,记忆负担小。与之相对的就是乱序方案,乱序的原因是对重码的考虑,使每一个编码尽可能的只有一个候选项,所以将部件进行合理的分配,乱序方案的缺点就是部件的位置没有规律,不方便记忆。
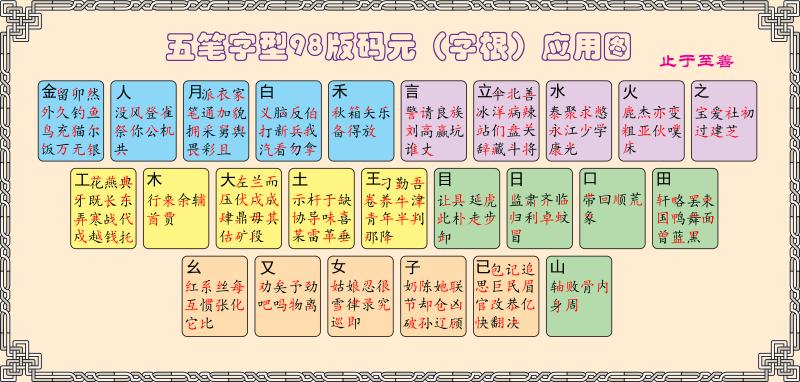
3.2 五笔 98 的码元图
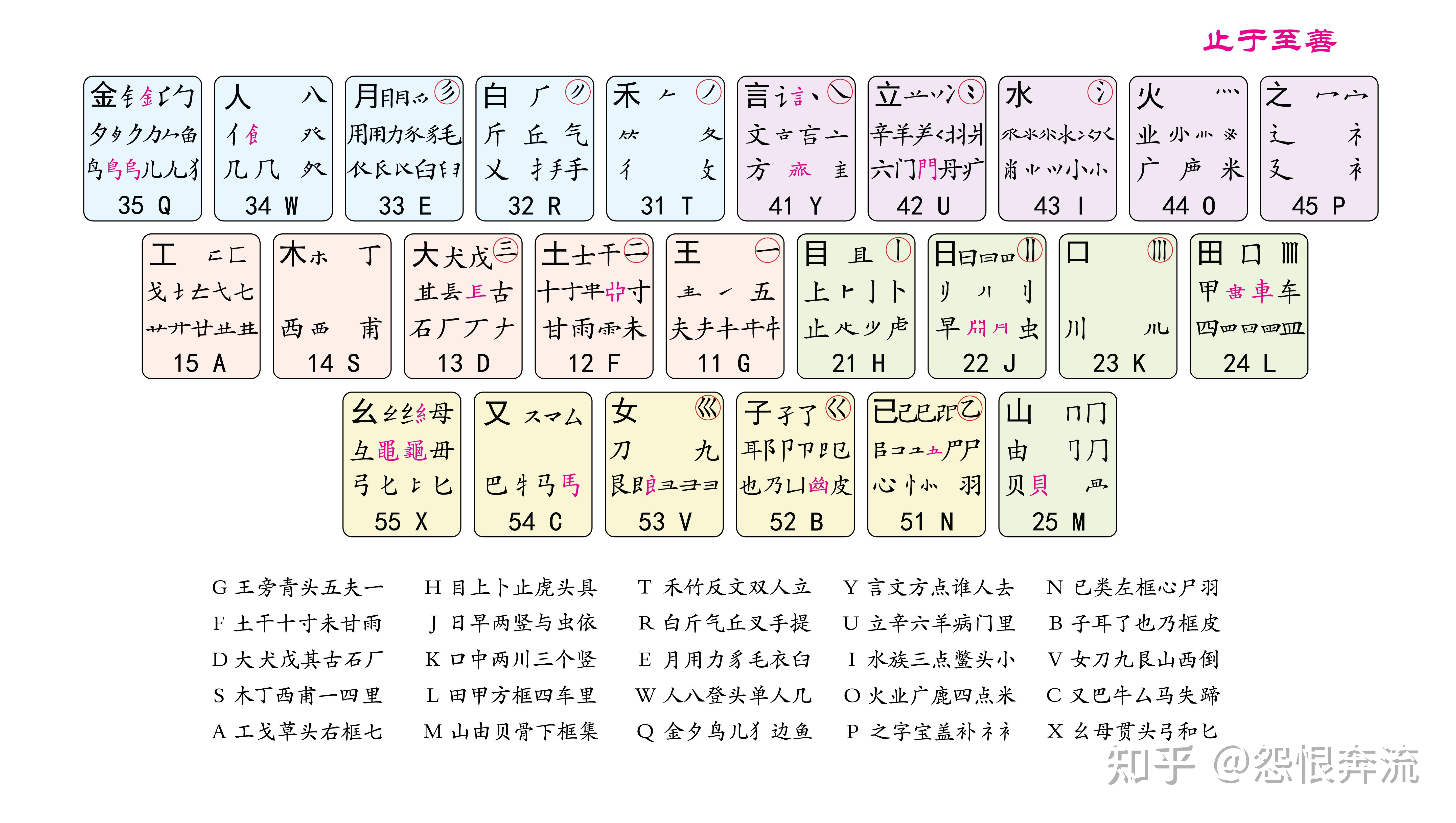
上述中的汉字部件,在五笔 86 中称为字根,在五笔 98 中称为码元,二者是一个意思,大家知道就可以了。在后面的介绍中,二者会混用,码元就是字根,字根有时简称为根。下面以码元图中的一个按键区来介绍,什么是码元(字根):
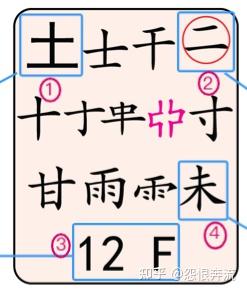
大家请看,这是码元图上 F 键位所展示的码元,通过观察,可以发现这里面,有我们认识的字,比如 十、士、土等,也有我们不认识,但是知道它是哪个字的某部分,比如 革 的下部,零 的上部等。这些码元有自己的名称,我们就依序介绍。
3.2.1 键名码元 图中标号 1
在左上的 土 这个码元,用黑体显示,在每一个键位上都有这样的黑体码元,它们的名字叫键名码元,即为总领这个键的码元。
3.2.2 识别码元 图中标号 2
右上角带圈的 二,叫作识别码元,不是每一个键位上都有这样的码元,大家可以找找看,哪些键上有这种识别码元。
3.2.3 按键编码 图中标号 3
最下方的 12 F,代表这个键位的区域和对应的英文按键。注意看每个码元图都有数字编号,这些编号是分区的编码,如 12 就代表 1 区的第 2 个按键。1 区就是横区,2 区就是竖区,3 区就是撇区,4 区就是捺区,5 区就是折区。
3.2.4 成字码元和普通码元 图中标号 4
在这一个键位上的 士干十寸甘雨未 ,是我们可以说出名字的码元,这些叫作成字码元,也叫字根字。
其余我们叫不出名字来的码元,就是普通码元了,其中粉色的码元是繁体字专属的码元。
3.2.5 补码码元
再看三个码元图:
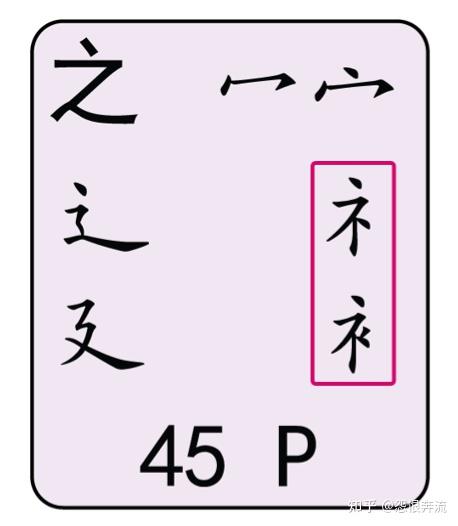


注意 礻 衤 犭 飠 四个码元,它们被称作补码码元,这四个码元有自己的特殊编码,需要记忆,礻 衣字旁的编码是 PY,衤 示字旁的编码是 PU,犭 反犬旁的编码是 QT,飠 的编码是 WV。
为什么要区分这些码元呢?因为不同的码元,有不同的输入方式,区别了这些码元之后,我们才能对五笔 98 的使用得心应手,所以请大家熟知码元的类型。
3.3 单编码型形码
可以观察到,码元图中的码元,没有其它说明的话,那么我们按一下 F,就可以确定我们输入的码元是这个键位的,这看起来好像有点绕,但是请看:

和我们的五笔 98 码元图有所不同,这是宇浩输入法的 D 键位的字根图,我们可以发现,其中的字根后面跟随着英文字母,什么意思呢?意思就是,按键 D 是这个区域的总起,先输入了 D,其中的码元还需要再输入其后所跟随的字母才能确定,这类确定一个字根需要用两个按键的方案,称作双编码方案,而我们的五笔 98,确定一个码元只需要一个按键,那么五笔 98 就被称为单编码型输入法方案。两种编码方案的侧重点不同,取字根的规则也有所不同,不能说孰优孰劣,不能用来比较。
3.4 码元图的学习方法
请大家再看一遍码元图:
其实这些码元在你打字的过程中就会慢慢熟悉,并不需要一上来就死记硬背,就像你学会乘法的规则之后,所有的乘法你就都会了,而不是去记答案。五笔 98 的码元分配是很有规律的,大家主要记这些规律就好,口诀就算是一种方便记忆规律的方法,但一般地,我们并不需要去背。
五种颜色的五个分区,已经有很大程度算得上是规律了,大家要做的就是,保存一张码元图,在打字的时候,卡売了,就去看一眼,就这样就好。人第一聪明的事,是制造工具,第二聪明的事,是使用工具,这张码元图就是我们的工具。
二、五笔 98 的单字输入方式
1、码元的输入方式
1.1 键名码元的输入方式
还记得键名码元吗?它是码元图左上角的黑体字,每个按键都有一个键名码元,它们都是由一个汉字充当,它们所代表的字就称作键名汉字,输入键名汉字,只需要连按这个按键四下就好啦,比如 土 ,我们连按四下 F 就好啦,FFFF 就能输入 土 了,类似地,其余 24 个按键(不包含 Z 键)连按四下,也能打出其键名汉字。但是,细心的同学就会发现,有些键名汉字不需要打足四下,比如 大 ,只需要打 DD,打两下就够了,这是为什么呢?这是我们后面会讲到的简码设置,请继续看吧。
1.2 成字码元的输入方式
码元图中有的字根就是现成的字,其输入方式是首先输入这个字所在的键位,再输入这个字的第一笔,第二笔和最后一笔,注意,按键 GHTYN 分别代表横竖撇捺折,比如我们想输入 寸 这个字,我们就需要先输入这个字所在键位 F,再输入横 G、竖 H、点 Y,那么我们输入 FGHY,就能输入 寸 了,再如 石 ,它在按键 D 上,我们先输入 D,再输入横 G,撇 T,横 G,所以输入 DGTG 就能打出 石 字来。
有些看起来不像个字的,其实也能用其所在按键和第一笔,第二笔和最后一笔来输入,比如 灬 ,它的输入方式是 O,点 Y,点 Y,点 Y,有的同学就好奇了, 灬 的第一笔看起来不像点啊,为什么也要用 Y 呢?因为这种自右上朝左下书写的短撇,也算作是点。
1.3 识别码元的输入方式
与成字码元的输入方式相同,先输入其所在按键,再输入首笔,次笔和末笔。但是 一,丨,丿,乀(丶),乙(折)的输入方式比较特殊,稍后讲到。
1.4 普通码元的输入方式
这类码元无法正常输入,想输入它们需要字体支持,因为这些码元严格意义上不是汉字,而我们的目的是输入汉字,但是我们可以描述这种码元,比如,(革下)就代表 革 的下面那个码元。
1.5 补码码元的输入方式
补码码元有四个,分别是 礻 衤 犭 飠,这个四的按键分别是 PY、PU、QT、WV,需要特别记忆,每一个都需要打两个编码,不可省略当中的编码。这四个补码类似于双编码方案中的字根,但不同的是,双编码方案的字根小码(即字根图上字根后面的小写英文)在输入时有时会省略,字根可以只打大码,不用打小码,而五笔的这四个补码不能省略任何一个,在打单字时必须打全了各自的两个英文按键。
补码的输入方式和成字码元的一样,在打全了补码的两个编码后,再输入第一笔和最后一笔。
犭,犭 T 丿丿,QTTT。
礻,礻 Y 丶丶,PYYY。
衤,衤 U 丶丶,PUYY。
飠,飠 V 丿丶,WVTY。
2、汉字的输入方式
2.1 汉字拆分的依据和规则
我们通过对一个汉字进行观察后,可以在脑海中大致判断出这个汉字需要多少个码元来组合,这个过程我们称之为拆字,每一种形码都有其专属的拆分汉字的方法,也有各自的规则,如何判断一个字的根数量,我们需要学会五笔 98 对于拆字的规则。有些字我们能根据上小学时候的经验轻松说出它是如何构成的,比如 木子李 ,弓长张。但是有些独体字或者十分奇怪的字,我们就需要根据五笔的拆字规则来描述它的构成。
2.1.1 书写顺序
就像我们手写字一样,五笔 98 的第一个拆分规则就是笔顺,先左后右,先上后下,先横后竖,先撇后捺。很好理解,左右结构的字,那肯定是先写左边,再写右边,上下结构的字,就是先写上边,再写下边,一个 人 字,是先撇后捺,一个 十 字,是先横后竖,大家都能轻松理解,只不过对于写字倒插笔的朋友,可能有点小小的不适,但是没关系,这毕竟不是真的在写字,适应就好。比如 好 字,那当然是先写 女 ,再写 子 ,打字时也一样,先打 女 ,再打 子 。但是鉴于各人的书写顺序有差异,所以有些拆分会出现不符合自己学的笔顺的情况,不用太过于纠结,这是正常的。
2.1.2 取大优先
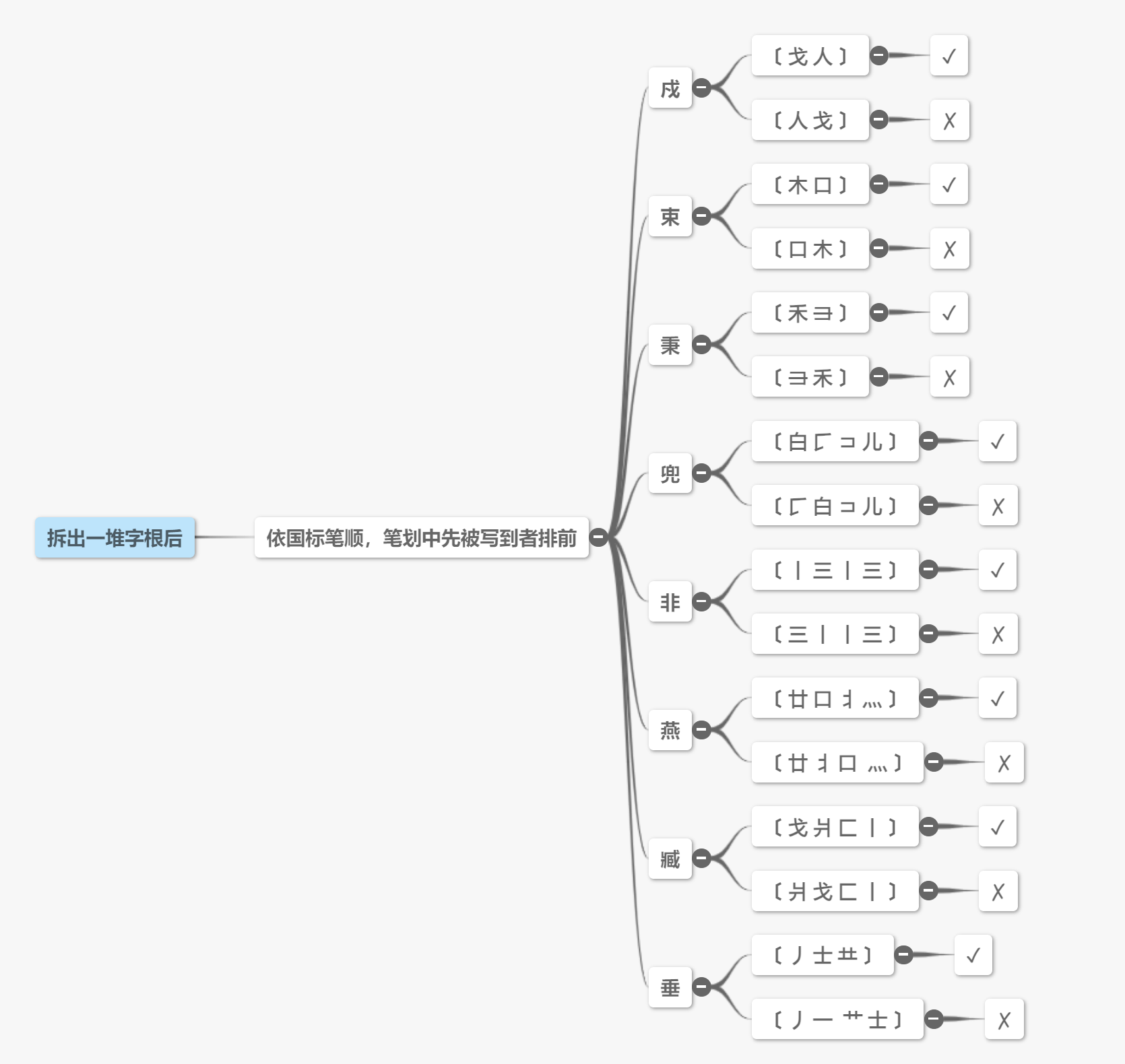
我们需要利用好每一个码元,在各种可能的拆法中,保证书写顺序拆分尽可能大的码元,以保证拆分出的码元数量最少,但是这一条的优先级是在书写顺序之后的,需要注意,因为我们可能会拆出第一根小,而第二根大的情况,称为一小二大的取大优先。比如 世 字,第一个根我们取 廿 ,第二个根取 乙(折),而不是取成 一 ,凵 ,乙(折)。
2.1.3 兼顾直观
这一条是最重要的,因为如果完全按照前两个规则来的话,有可能某个字的拆法会让你难以理解,我们要做出符合大家直觉的拆分,让大家觉得合理,在某些时候,这一条的优先级可以高过前两条。比如 国 字,拆分是 囗,王,丶,大家可以注意到,在写字的时候,外框的下面那横是在写完内部之后再写的,但是我们有 囗 这个字根,为了直观,不能拆成 冂,王,丶,一,这种拆法虽然符合书写顺序,但是没有将 囗 看成一个整体,所以兼顾直观的这条规则,是非常重要的。还有,五笔 98 不会强行断开相连的字的笔划,字根中的笔划,在有些时候需要适当延长,比如 果 字拆成 日 和 木 ,而不是将中间断开拆成 田 和 木 ,最 字拆分成 日 耳 又,延长了 耳 字根的笔划。
2.1.4 能连不交
在满足前三条的情况下,有些字仍难以判断其拆分,比如 天 这个字,可以拆成 一 大,也可以拆成 二 人,但是我们将它拆成 一 大,因为 一 和 大 我们认为是相连的, 二 人 这种拆法,其中 人 贯穿了 二 ,五笔认为是相交,相连的优先级要大于相交。
2.1.5 能散不连
如果一个字的结构可以视作为几个基本字根的分散,就不要认为是相连。比如 主 这个字,我们应拆成 丶 和 王 ,而不是 亠 和 土 ,这算作是一小二大的取大优先,要理解起来较为困难,但是不用管,上述的规则如果你都不理解也没关系,在练习打字的时候,我们就能够越过这些规则,这规则其实是遇见难拆字的时候的判断方法,平时我们是用不到的,有趣的是,如果真正遇见了难拆字,这些规则,有可能也派不上用场。
2.2 不同根数的汉字的输入方式
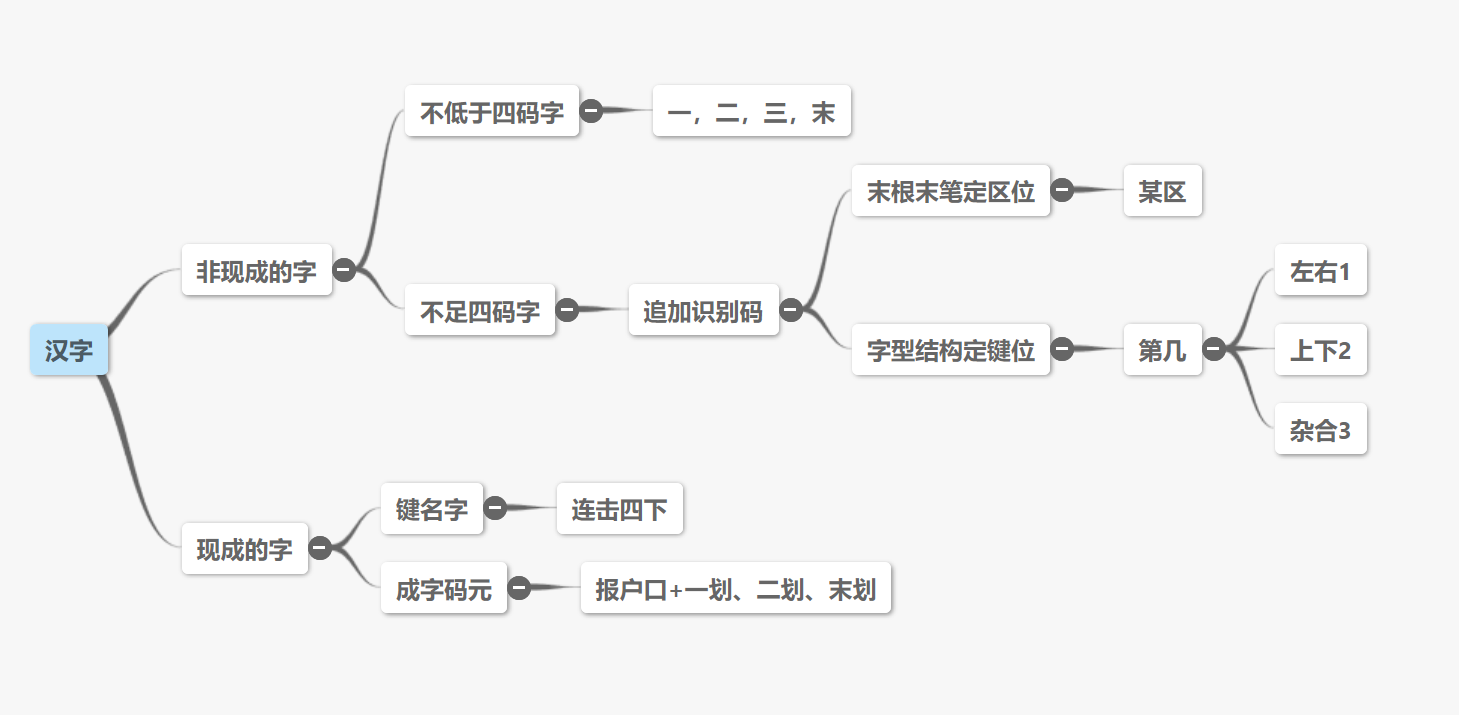
依据上面的汉字拆分规则,我们就可以对某个字进行折分,其中拆分出的字根的数量,对于我们打字有很大影响,根据字根的多少,我们将字分为单根字,二根字,三根字,四根字和多根字。
2.2.1 单笔划字的输入方式
一,丨,丿,乀(丶),乙(折),其输入方式分别是 GGLL、HHLL、TTLL、YYLL、NNLL。需要说明的是,在成字码元的输入那一节中,G 代表横,H 代表竖,T 代表撇,Y 代表捺,N 代表折。仅此五例单笔划,牢记。
2.2.2 单根字的输入方式
单根字就是除了单笔划的那些成字码元,也叫字根字,输入方式是先输入这个字所在的按键,再输入它的第一笔,第二笔和最后一笔的笔划,也就是成字码元的输入方式。
2.2.3 二根字的输入方式
二根字就是两个字根组成的字,比如 她 字,是由 女 和 也 两个字根组合成的,输入方法是分别打出 女 和 也 的所在按键,她字的编码就是 VB,但是由于 VB 这个编码只按了两下,而五笔是一种四码定长的方案,最多四个按键就能确定一个字,但是 VB 不满四码,我们就需要对其进行补充,要再给它加上一码,来完全确定这个字,添加的那一码叫作识别码,后面会重点讲到,且按下不表。注意二根字在加上识别码之后,编码长度也才为三,虽然五笔是四码定长的方案,但是有些时候,定长方案不一定非得达到那个码长。
2.2.4 三根字的输入方式
三根字是三个字根组成的字,比如 你 字,是由 亻 ⺈ 小 三个字根组合的,我们依次输入 亻 ⺈ 小 所在的按键就可以了,即 WQI,但是 WQI 不满四码,我们还是需要对其补充识别码。
2.2.5 四根字和多根字的输入方式
这其实就比二根和三根简单了,因为四根字不用补识别码,直接输入它的四个根所在按键就好,而多根字,则需要输入它的第一根,第二根,第三根和最后一根,其余的根跳过。比如 警 字,它有 艹 勹 口 攵 言 五个根,我们只需要输入 艹 勹 口 言 四个根就好了,因为五笔是四码定长方案,最多输入四码就可以了。
2.2.6 键名字的输入方式
键名字其实就是键名码元,连按四下这个字所在的按键就可以输入了,但是有些键名字不用按满四下,比如 大 ,人 ,之 等字,因为这些字有些非常常用,在制作码表的时候,将它们设置成了简码,方便输入,当然你也可以打四下按键来输入,效果一样,效率不一样。
2.2.7 带有补码的字的输入方式
带有补码 礻 衤 犭 飠 的单字,在输入时,要将补码输全了,比如 补 字,要输入 衤 的 PU,再输入 卜 的 H,补 字就是 PUH,还需补充识别码。
3、识别码
识别码可以说是五笔打字中的一个重难点,但是学懂了之后,识别码就非常好用。识别码是用在二根字和三根字上的,由于二根字和三根字的编码数量少,仅用它们的字根来输入的话,重码会很多,为了减少重码,各种形码采取的方法也不一样,如双编码方案,通过让每个字根两码输入的方式,就算这个字是二根字,也需四码打出,就减少了重码,而五笔 98 作为单编码方案,采用了识别码的方式来避重,可以说识别码是五笔的独创。
识别码全称末笔交叉识别码,在 98 中也叫笔形识别码,是根据字的字型和末根的末笔来联合确定一个字的方法,比如 𪱳 杏 束 三个字,它们都是由 木 和 口 两个字根组合而成的,编码都是 SK,那么要如何在形码中区分三者来降低重码呢?我们就需要用到识别码,我们观察三者,发现这三个的字型可以分为:1、左右型 2、上下型 3、杂合型,有点类似于我们上学时候的左右结构,上下结构,包围结构,半包围,左中右,上中下等结构,但五笔中的字型结构和语文的有些不一样,它只看字根与字根之间的位置关系,我们先来学习五笔中的字型结构。
3.1 五笔中的字型结构
3.1.1 左右型
左右型结构包括了左右和左中右两种结构,非常好识别,比如 你 朝 做 等字,这些字都属于五笔中的左右型。左右型结构在五笔中非常容易辨识,最容易判断。
3.1.2 上下型
上下型结构包括了上下结构和上中下结构,特殊的独体字和品字型结构。这类结构非常难判断,而且与我们上学时候的上下型有点不一样,所以五笔的识别码为人诟病,就因为上下型结构的判断,这将在后续的章节疑难杂症中详细讲解。
3.1.3 杂合型
杂合型结构包括了独体字,包围结构,半包围结构。部分半包围结构的字,在五笔中算作是上下结构,非常难以判断,只能打熟了之后才能理解,在疑难杂症中会详细讲解。
3.2 末根的末笔
除了知道一个字的五笔结构型,还需知道字根的末笔才能配合结构型来构成识别码,字根的末笔就依据书写顺序,将末笔也分成横竖撇捺折五个笔划,特别记住 提 属于横,亅属于竖,丶属于捺,如扇的末根是 羽,羽 的末笔是 提。因为大家写字的顺序有差别,所以五笔 98 规定了某些字的末笔如下:
万的末笔是丿,方的末笔是丿,车的末笔是丨,匕的末笔是乚,刀的末笔是丿,九的末笔是⺄,乃的末笔是丿,心的末笔是丶,如有疑问,需多多查询五笔 98 的编码来熟悉。
疑难杂症章节中,每个字根的末笔都被标记出来了,有疑惑可以先去那一章看。
3.3 末笔交叉识别码
知道了字型和末笔末笔之后,就能确定该用哪个识别码了。识别码需要字型和末根的末笔来决定该补充哪一个编码,根据末根的末笔,可以划出五个区域,没错,正是之前学的五笔的分区的那五个区域,然后再判断字型,如果一个字的末根的末笔是横,那么我们就定位到横区的 GFD 来寻找它的识别码,如果这个字又是左右型的,那么这个字的识别码就是 G,请看图:
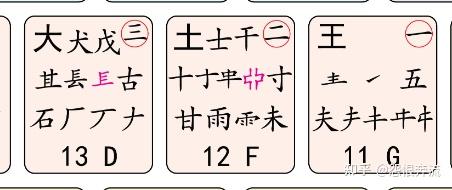
看见右上角的带圈的识别码元了吧,其中的一二三正对应了左右,上下,杂合三种字型,我们之前举的例,𪱳,杏,束 这三个字,末根是 口 ,口 的末笔是横,所以在横区确定这三个字的识别码,𪱳 的结构是左右型,识别码就是 G,杏 的识别码是 F,束 的识别码是 D,GFD 就对应了左右,上下,杂合。
这是竖区,如果有字的末根末笔是竖的,就在这找识别码,左右、上下、杂合对应的识别码是 HJK。
剩下的三个区也一样,TYN 对应左右,RUB 对应上下,EIV 对应杂合。
对 这个字的拆分是 又 寸,末根 寸 末笔是丶,对 为左右型,识别码为 Y,所以 对 的全码是 CFY。
你 这个字的拆分是 亻 ⺈ 小,末根 小 的末笔是丶,你 为左右型,识别码是 Y,所以 你 的全码是 WQIY。
森 这个字的拆分是 木 木 木,末根 木 的末笔是丶,森 为上下型,识别码是 U,所以 森 的全码是 SSSU。
识别码直观地看,是这样的一个表格:

大家一定要熟记识别码的键位,这样才能在打字中行云流水。
3.4 特别注意的结构型
对于杂合型和上下型的字,有些还是难以判断,比如 午 和 千,午 的拆分是 𠂉 十,千 的拆分是 丿 十,它们的编码是一样的,我们规定,如果一个单笔划字根和其它字根相连,无论这个单笔划出现在前面还是后面,都将这种字视为杂合型,多个单笔划的情况,不能适用这条规则,需自行判断其字型。非单笔划和其它字根相连的,视为上下型,那么 午 这个字是 𠂉 和 十 相连,𠂉 不是单笔划,所以 午 是上下型,而 千 是 丿 和 十 相连,丿是单笔划,所以 千 是杂合型。这种独体字判断它的五笔字型有一定难度,但是知晓原理之后,这种字的结构就变得简单了。详细的结构区别,在后续的疑难杂症中讲解。
3.5 特别注意的末根末笔
3.5.1 带国字框 囗 的末根末笔
在全包围的状态下,五笔 98 判断其末根末笔是用被包围的部分来判断的,比如 围 这个字,书写顺序最后一笔是横,但是不用横来当末笔,而是用 韦 的 丨 来当末笔,国 也是,用 丶 来当末笔。
3.5.2 带走之底 辶 廴 的末根末笔
辶 和其它字组合的时候,照书写顺序是后写 辶,但是五笔 98 规定是判断 辶 内的字根,比如 连,先写 车,再写 辶,但是判断末笔应该是 车 的 丨,这样设置是可以理解的,不然识别码就会全都是 I 了,这样就不能起到识别的作用了。但要注意的是,必须是像 连 这样的结构,如果是 莲,链 这样的字,末根末笔,还是得算 辶 的 乀 才行。
4、五笔 98 的简码设置
什么是简码呢?与之相对的概念叫全码,全码就是打字的时候,打全这个字的编码,但是这样做太繁复了,如果每一个字都打全的话,是非常累的,所以为了简便,五笔设置了简码,意思就是不用打全某个字的编码,候选框也已经出现了这个字。
五笔是四码定长方案,最多四码就能打出某个字,但是有些常用字比较难打,但是使用频率较高,五笔就设置了只需要一个编码就能打出的字,两个编码就能打出的字,三个编码就能打出的字,分别称为一简,二简,三简。其中实用的是一简和二简,三简基本记不住。
一简,只需按键一次就出现的字,由于五笔用了除 Z 之外的 25 个英文字母,所以一简有 25 个,以 QWER 的排序,它们分别是:我人有的和主产不为这 ~ 工要在地一上是中国 ~ 经以发了民同,这 25 个字是很常用的字,设置为一个按键就能打出,非常简便。要注意的是,这些字可能并不符合字根的分布规律,比如 Q 上的 我 这个一级简码,我 的全码是 TRNY,并不是以 Q 作开头的,所以一级简码虽然简便,但是大家还是要知道全码,这样方便组词的时候输入。
二简,是两个按键的组合,原理上有 25*25=625 个,但是由于有些按键的组合没有字,所以二简就接近 600 个,在使用五笔的过程中会慢慢熟悉。
三简,记不住,还是打全码吧。
四简,没有四简,四码已经是全码了。
虽然简码是好东西,但是大家还是要熟记全码,因为全码在打词组中,非常重要。
不同的五笔 98 码表(也称为字库或者词典),其设置的简码可能有所不同,但全码一定相同,简码不同的原因是,每个人的用字习惯不一样,可能和职业相关,比如药学需要经常输入生僻字的药名,那么就可以选择有关方面的码表来使用,因人而异,码表的链接我会在后续章节给出。
5、形码简码设置的种类
5.1 简全一致
在我们打字的时候,我们打到了某个字的简码,这时这个字处于首选的位置,我们再打全这个字的码,会发现它仍然在首选的位置上,这种情况叫作简全一致,意思是某个字,它的候选位置和简码或者全码无关,在首选就一直在首选的位置上,不会改变。简全一致的简码设置,它的好处是在打字的时候,某个字的位置是固定的,不会有时在首选,有时在次选或者三选,缺点是在重码的情况下,我们不能让重码的字都有机会出现在首选,而且你打不确定的字的时候,需要看屏幕来选字。
比如,现 规 两个字,你会发现它们的编码都是 GMQN,如果采用简全一致,那么 现 永远都在首选的位置上,当你想打 规 的时候,习惯性地打出字不看候选就上屏,结果你会发现,你打成了 现。
5.2 出简让全
与前者相对的,如果在简码中,某个字出现在首选的位置,那么打全码后,这个字会让出首选给另一个字,这就意味着,某个字的位置不固定,有些时候是首选,有些时候是次选,十分飘忽,不过它的也好处,在常用字重码时,能够让这些字都有机会出现在首选,方便选取,但也有缺点,就是有些常用字和不常用字为互为重码,常用字在简码中出现过了,打全码时,非常用字反而到前面来了,对于习惯打全码的人来说,这很影响效率。
还是 现 规 两个字,它两都是常用字,如果我们设 GMQ 这个三简编码只有一个候选为 现,GMQN 这个全码,规 为首选,现 为次选,那么这两个字都有机会出现在首位了,前提是要记住这个设置,也就是记住 GMQN 上有重码,且 GMQ 的三简为 现,当记住了之后,出简让全也会变得好用,但是简码的数量越多,越不容易记,所以出简让全只适合小部分常用字相互重码的时候。
5.3 出简不出全
在我们的认知里面,码表也就是词库里面的字,它们的编码都是符合规则的,遵循规则就能打出这个字来,但是有一种简码设置,它的字的编码与规则有异,它就是出简不出全,意思就是,某个字在简码中出现过了,那么它就可以不用出现在全码中了,比如上面说的 现 规 二字,如果 GMQ 出现了 现 字,那么 GMQ 就是 现 的全码了,在 GMQN 中不会再出现 现 字了,只出现 规 字。在简码中有,在全码中没有,这就叫出简不出全,为啥会有这种设置,其实就是为了减少重码,形码最忌的东西就是重码,如果能以设置简码而取消其全码的方式来降重,也未尝不可。它的优点是能在一定程度上极大地减少重码的数量,做到一码一字,在打字中可以不用看屏幕来选字,打字可以飞快,但是缺点也很明显,就是不符合规则,如果没记住某个字有简码,去打它的全码,它又不出现,会怀疑自己打错了,而且,简码数量众多,二简理论 625 个,三简理论 15625 个,这数量根本记不住,而且这种设置方式只适合小字集,6000 个字左右的码表,对于大字集来说就是天残。但是这样的方式熟练以后,速度简直出神入化,对于速录员等需要快速打字的工种来说,这种方式效率最高。
此上三种简码设置的方式,简全一致和出简让全其实可以并存的,在常用字与非常用字的重码中,采用简全一致,在常用字与常用字的重码中,采用出简让全,记忆量小的同时也保证了一定的手感,二者结合,根据个人习惯设置,能使打字体验得到质的飞跃,不过需要慢慢磨合,如果想用形码来养老,那么这是最佳的方案了。
而出简不出全适用范围小,破坏规则,只适合少数对打字有需求的人,一般不推荐,而且它不能与前二者相结合,不然有些字有简码,没全码,有些字有简码又有全码,码表就会相当混乱,非常不利于打字。
5.4 不设简码
也有的形码,除了一简有设置,二三简均不设,这样做的好处是,每个字都打全码,不用思考是否有简码,是否有重码排序的问题,直接输入全码,这种方法适用于双编码型形码,因为双编方案每个字根用两个字母来确定,所以难有用三码就能打全的字,基本上,双编方案的二码,三码字,就是它的全码了,虽然大多数三码的码位是空的,但是为了协调,所以不设简码,每个字都以全码的形式打出,如果不熟练,会有些卡壳,熟练之后,节奏会很好。
三、五笔 98 的词组输入方式
形码最大的优点就是能够在四码定长的时候,输出多个字,无论多少个字,都是四下按键,当然前提是你的码表里面要有这个词,这是形码的终级大招,接下来就讲一下词组的输入方式。
1、二字词的输入方式
二字词,大家都知道,两个字及以上的组合才能称为词,二字词的输入方式是,输入第一个字的第一根和第二根,再输入第二个字的第一根和第二根,比如 疯狂 这个词,疯 的全码是 疒 几 乂 和 I 组成的 UWRI,狂 的全码是 犭 王 和 G 组成的 QTGG,疯 的前两个编码是 UW,狂 的前两个编码是 QT,所以 疯狂 的编码是 UWQT。再如 五笔 这个词,五 是字根字,编码是 GGHG,笔 的编码是 TEB,所以 五笔 的编码是 GGTE。
简单来说就是 一二、一二。用未知数来表示则为 AABB。
2、三字词的输入方式
三字词,输入第一个字的第一根,第二个字的第一根和第三个字的第一、第二根。比如 我爱你,注意,组词的时候只能用全码的第一根或者第二根来组,不能用简码来组,我 的一级简码虽然是 Q,但是我们要用 我 的全码 TRNY,那么 爱 的全码是 EPDC,你 的全码是 WQIY,取第一个字的第一个根 T,第二个字的第一个根 E,第三个字的第一二根 WQ,那么 我爱你 的编码就是 TEWQ。
简单来说就是 一、一、一二。用未知数来表示则为 ABCC。
3、四字词和多字词的输入方式
由于五笔是四码定长的方案,无论是字还是词都是四个编码,所以对超过四个字的词,我们则取第一个字的第一根,第二个字的第一根,第三个字的第一根和最后一个字的第一根,比如 何意百炼钢 这句诗,何 的全码是 WSKG,意 的全码是 UJNU,百 的全码是 DJF,钢 的全码是 QMRY,这句诗的编码就是 WUDQ,如果你打不出来,说明你的词库没有这个词,需要你手动添加。
简来来说就是 一、一、一、一。用未知数来表示则为 ABCZ。
四字词就更简单了,取每个字的第一根就可以了。比如 如鱼得水 这个成语,如 VKG,鱼 QGF,得 TJGF,水 IIII,那么这个词的编码就是 VQTI。是不是很简单呢。
简单来说就是 一、一、一、一。用未知数来表示则为 ABCD。
4、带有补码码元的字组成的词的输入方式
前文讲到,在打单字的时候,带有补码的字根,它的两个编码都不能省略,必须打全了。比如 狼,犭 T 丶艮,QTYV,神,礻 Y 日丨,PYJH,初,衤 U 刀 T,PUVT。
在打二字词的时候,补码的两个编码也要打全了。狼狈,犭 T 犭 T,QTQT。正因为这个规则,导致带有补码的二字词的重码数量巨大,谨慎打词。
在打三字词的时候,就看带有补码的字在第几位了,如果在第一和第二位,那么补码的后面一个英文编码就可以省略了,如果在第三位,那么还是必须打全。灰太狼,𠂇大犭 T,DDQT。狼图腾,犭囗月丷,QLEU。
四字词和多字词,那就不管带补码的字在哪,都可以省略补码的后一个英文编码了。狼心狗肺,犭心犭月,QNQE。
四、五笔 98 资源
1、五笔 98 资源库
这网站里面包含了五笔 98 的字根图,练习软件,大字集字体,拆分码元字体,各种词库和码表,还有各平台的输入法软件,也有一些有关五笔 98 的小知识,是最适合自定义五笔 98 的网盘。
2、五笔小筑
3、五笔 98 版权
五笔 98 到现在已经没有专利版权的问题了,以前的五笔输入法大多是 86 五笔,几乎没有 98 五笔,就是因为以前还涉及版权纠纷,98 五笔只能在五码的官网上购买,而 86 早就被盗版攻破,所以大家都在用 86 五笔,很少人用 98 五笔,而且还因为前摄抑制,大家学了 86 后,不愿意转 98,导致 98 的用户极少,如果你还没学过形码,那就来试一试五笔 98 吧。
4、反查
写到这必须提一嘴什么叫反查,反查其实就是根据拼音来临时查询五笔的编码,这是狭义的反查,实际上,反查不限于拼音查五笔,也可以用五笔查拼音,再广义一点,可以用形码查音码,音码查形码,音码查音码,形码查形码。反查是一个非常好用的手段,无论是在初学时候,还是在熟练之后,反查都有必要存在,毕竟突然卡売忘记一个字怎么写,是非常正常的事。就像拼音用户遇到不会读的字,如果能用反查的方式查到这个字的读音,就能打出这个字了。
反查依赖另一种输入方案,这个另一种方案,大多是拼音,因为大家都会,也可以是粤拼,也可能是注音等等。既然需要另一种输入方案,那么一个好的反查方案,能对五笔的学习产生巨大作用,不用担心反查很难,因为现在的各种输入法反查的功能,已经相当完善了,搜狗五笔的拼音五笔混输,其实也是一种反查。而上面给到的资源库软件,也有这种功能,放心使用。
有些同学不知道有反查这种功能,所以在学习五笔的时候,容易半途而废,所以要灵活运用反查,反查甚至能够做到以形查音,遇见了不会读,但是会打的字,就能用反查轻松搞定了。
五、疑难杂症
五笔 98 的有些拆分非常抽象,初见肯定一脸懵,这字能拆成这样的?现在我就从难拆字型和难字拆分等方面介绍五笔 98 的疑难杂症。
1、识别码中的字型判断
前文第二章第三小节已经简单讲述了识别码中的字型判断,在这作出补充,希望能给大家带来帮助。
1.1 字型的意义
语文中的字型与五笔中的有所区别,在语文中是独体字结构的字,在五笔中可能是上下型结构,但是在语文中是左右型结构的字,在五笔中也是左右型结构,语文中是上下型结构的字,五笔中也是上下型,二者又有些相同,需要熟悉五笔的规则,才能知道二者到底有何异同。其中的难点就是判断独体字与包围字是杂合型结构还是上下型结构。
1.2 半包围结构判断
半包围结构分为两面包围和三面包围,其中的三面包围字,比如 区,凶,冈,它们无一例外地属于杂合型,相信大家可以理解,重难点是两面包围的判别。如下:
1.2.1 左下包围右上
赵,这,廷,翅,题,翘 等都是左下包围右上,这样的字属于杂合型,但是题和翘没有识别码,仅作举例。
1.2.2 右上包围左下
包,司,句,匀,载,贰,戠 等都是右上包围左下,这样的字属于杂合型,贰和戠没有识别码,仅作举例。
1.2.3 左上包围右下
这样的字就有区别了,大家需要仔细思考。
原,灰,在,房,眉,床,屎,病,友,后,左,右,布,厷 等字,都是左上包围右下,但是它们并不全是杂合型,其中的 灰 友 左 右 布 厷,是上下型,那看来带 𠂇 的字都是上下型了。但是 尢 是杂合型,这个不难理解,除了 𠂇 之外,君 这个字,也是左下包围右下,它也是上下型。
这一类字可以依靠熟练度来区分,现在不理解没有关系,这些是常用字,会经常使用到,多多练习就能熟知其结构了。可能还有其它类似的左上包围右下结构,在此就不例举了。
1.3 分离资格
引用两条规则
汉字中含分离的 一点 的,取消该点的分离资格。
单笔划相连的,取消分离资格。
取消了分离资格之后,就意味着这个字成为了相连的结构,这就是前文所提的单笔划与字根相连、包含 丶 的字,视其为杂合型的原因,这是五笔 98 规定的两条规则,有了这个说明了之后,大家也就能理解为什么那些字是杂合型了。
1.4 字型判断
综合上面所有学习过的规则,其实字型结构判断的依据就是字根之间的位置关系,我们知道识别码是在二根字和三根字里才会用到的,所以我们就分别讲述二根字和三根字中的字根位置关系。
1.4.1 二根字
如果字根左右相离的,属于左右型。比如 银 字。
如果字根上下相离或者上下相连,且字根中没有单笔划的,属于上下型。比如 李 字。
如果字根相交或者有包围关系,或者字根中有单笔划与另一字根相连,或者字根中有 丶 的,属于杂合型。比如 耒 击 生 主 等字。
1.4.2 三根字
如果三个根都左右相离的,属于左右型。比如 沏 字。
如果一根在左,两根在右且符合上下或者杂合型的,属于左右型。比如 谈 泄 等字。
如果两根在左且符合上下或者杂合型,一根在右的,属于左右型。比如 别 邦 等字。
如果三个根都上下相离或者相连的,属于上下型。比如 竟 字。
如果一根在上,两根在下且符合左右或者杂合型的,属于上下型。比如 萌 而 等字。
如果两根在上且符合左右或者杂合型,一根在下的,属于上下型。比如 焚 春 等字。
如果三个根都相交的,属于杂合型。比如不了。
如果一个根相交两根的,属于杂合型。比如 韦 字。
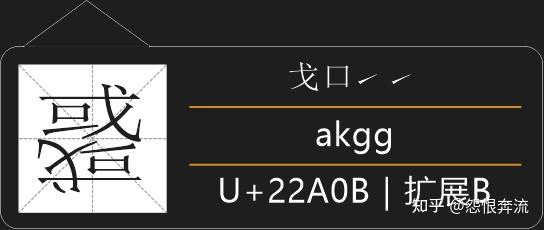
如果一个根包围两根的,属于杂合型。比如 或 字。
2、字根末笔讲解
在写字中,大家可能有各自的书写顺序,所以我在这介绍每一个能作为末根的字根的末笔,大家学习之后,对打字能有更深的理解。依据 QWER 的键位来介绍键位中字根的末笔。
Q 中的字根,能成为末根的,只有 金 夕 (万下) 儿 和(无中撇折)这四个根了,其它的字根是不可能出现在一个字的最后的。其中的末笔用紫色标注,以此为例,其它键位不再赘述,以图片的形式展示。

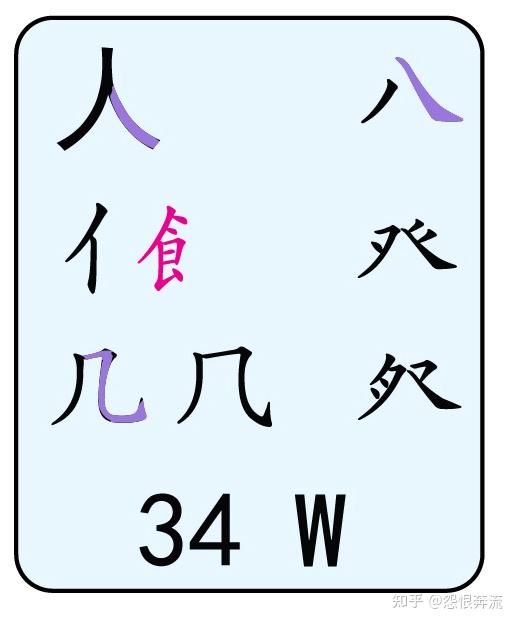

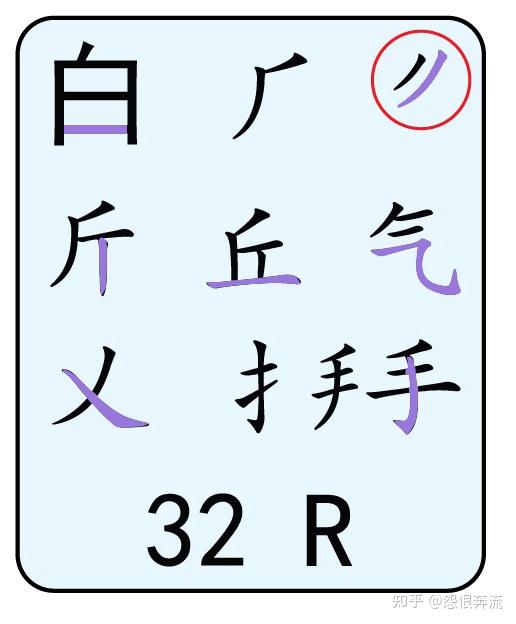
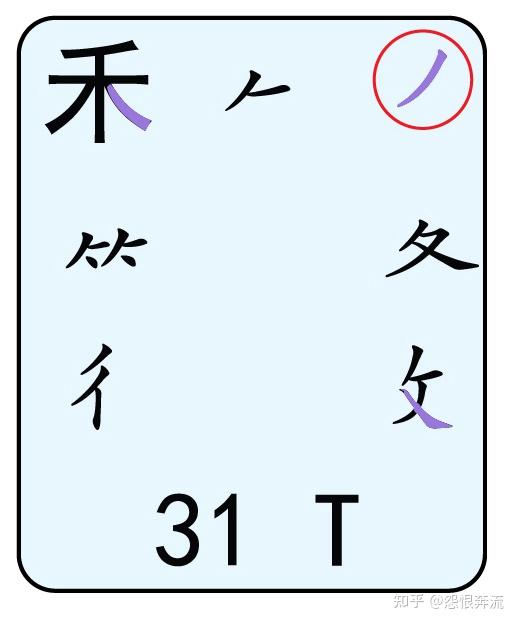


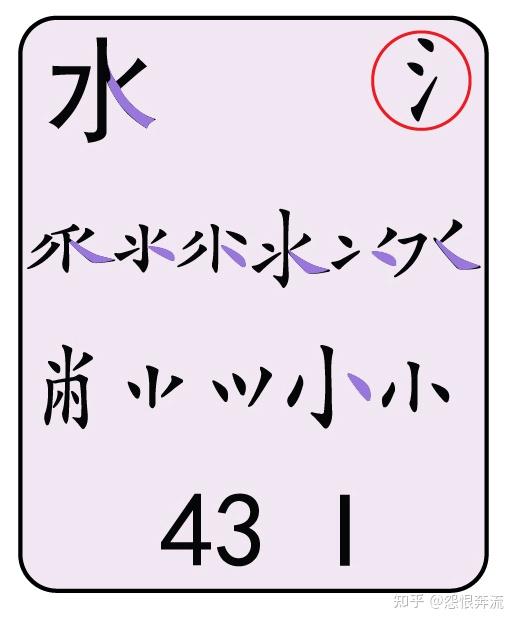








其中大多数字根的末笔都很好辨识,但是一些繁体根的末笔,就比较陌生,如 黽 的末笔是横,(龜下)也一样是横,末根末笔对识别码影响很大,窂记之后,识别码就不那么难了。除了末根末笔对打字有影响外,一些字的笔顺对打字也影响很大,因为在打这些字的时候,没有现成的根,我们只能输入单笔划,所以一些难字的笔顺,我们也要学习。
3、拆分规则的优先级
在第二章的第二节,我们讲到过汉字拆分的规则,它们分别是书写顺序,取大优先,兼顾直观,能连不交,能散不连,其中能连不交,能散不连是必定的,即是 散 > 连 > 交 的顺序,这是固定的。但是书写顺序,取大优先和兼顾直观这三点,没有必然的优先级关系,它们应用在不同的汉字上,优先级是不一样的,五笔的拆分规则是依据汉字本身来适应优先级的,而不是五笔本身,如果五笔强制规定了拆分的优先级,那许多字的拆法都会颠覆你对汉字的认知。
4、难字笔顺讲解
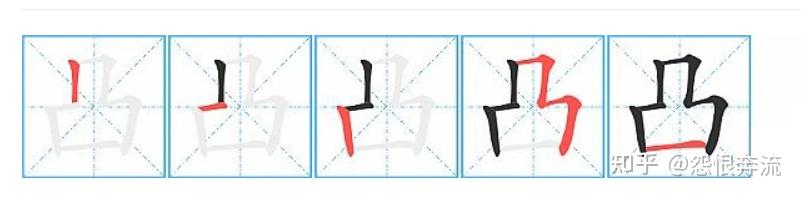
凸,HGHG。
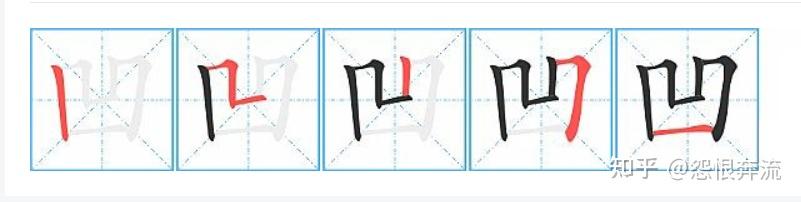
凹,HNHG。
門,UHNG。
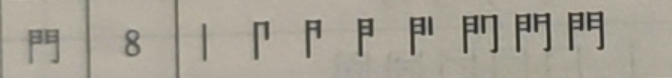
龜,TXD。

飛,NUTH。

枾,SFJG。

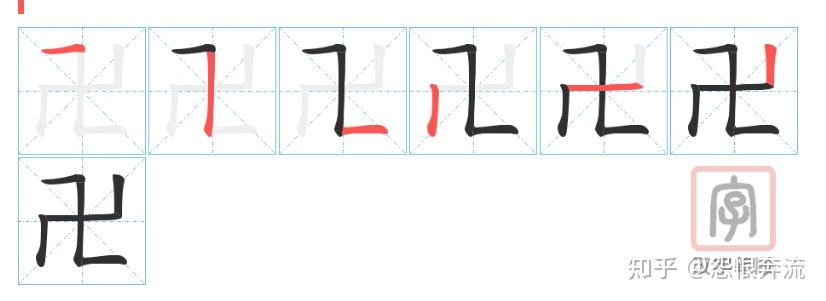
卐,NGHG。
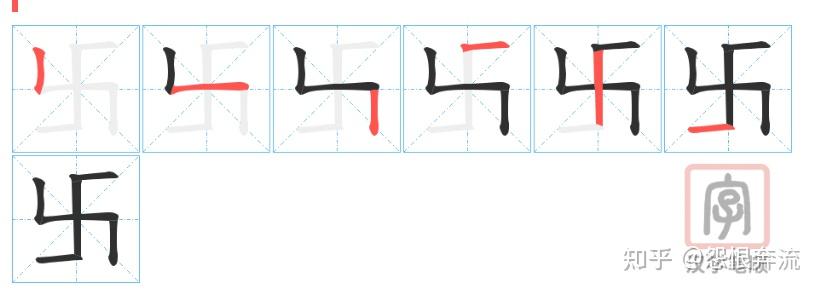
卍,NHGH。
5、难字拆分举例
拜,手三十 H,RDFH。由于五笔 98 没有 亖 四横这个字根,拜 的右边就被拆为了 三 十 的组合。
耒,二木 I,FSI。五笔 98 取消了五笔 86 的(木去横)这个字根,所以 耒 就被拆成了 二 木 的组合。
我,丿扌乙丿丶,TRNY。虽然 我 字中明显有一个 戈 的根,但是也有 扌 的根,我们不能将笔划强行断开,所以将 扌 的横延长, 而右边的 戈 就少了一横,不能再拆出 戈 了,所以这个字是这样拆的。
釜,八乂干䒑,WRFU。虽然 釜 中明显有一个 金 的根,但是注意到它的 金 上面是交叉的,并不是 人 ,而是 乂 ,所以这个字是这样拆的。
生,丿龶 D,TGD。单笔划和字根相连,属于杂合型。
牛,丿(丰少一横)K,TGK。单笔划和字根相连,属于杂合型。
㒳,冂丨丿乀丿乀,MHTY。这种 冂 杠内的字根有与之相连的,基本先打这个根。
繭,艹冂丨糹虫,AMHJ。原理同上一个。
燕,艹口(北左)匕灬,AKUO。这种上中下结构的字,依据笔顺,会先打中间的字根,这个字就先打了中间的 口 ,这种类型的字还有很多,打熟练了之后,对于手写也是很有帮助的。
變,言糹糹攵,YXXT。这个字也是遵从书写顺序的,大家写繁体写得少,对其不熟悉是非常正常的,以前不知道,但是你现在知道了,YXXT。
樊,木乂乂木大,SRRD。这个字就不从中间开始取了,因为按笔顺,是从左往右写的,拆分的时候也是从左往右。
兜,白(留左上去点)(反匚)儿,RQNQ。这个字是上下结构,而上面是左中右结构,在书写中,我们先写的是 白 ,所以五笔 98 先取了 白 ,再取左右。
兆,儿(四点)I,QII。这个字在书写中先写到 丿,再写到左边两点,再写竖弯钩,再写右边两点,先写先取,所以先中间,后外边。
脊,(四点)人月 F,IWEF。这个字和 兆 不同,在书写中是先写了点,所以先取 四点 这个字根。
臧,戈爿匚丨(反匚)丨,AUAH。这个字的拆法一直为其它形码所诟病,认为五笔 98 中有 戊 这个根,却拆出 戈 爿 这个两的组合来,其实这是因为我们的书写顺序,是先写到 戈 的那一横,再写 爿 的,所以这种拆分也是可以理解的。顺便一提,爿 的拆分是 UNHT,它是个字根字,先打它所在的按键 U,再打第一笔,第二笔和最后一笔 NHT。
戍,戈人 I,AWI。这个字需要相当的想象,因为五笔 98 中有戊这个根,这个字彷佛无论如何都应该拆成 戊 丶 I,但是由于 DYI 这个编码已经有字了,所以五笔 98 考虑到重码,参照了字源,将 戍 字拆成了 戈 人 ,很大程度上这可以算作是无理码了,大家记住这个特例就好,不必深究。
果,日木 I,JSI,这个字是把 木 的竖延长了,为了保证不断开笔划,大家应该可以理解。
束,木口 D,SKD。这个字同样可以看作是将 木 的竖从中间延长了,类似这种的 秉 ,柬,東 字,都是这种原理。
非,丨三丨三,HDHD。在五笔 86 中,拆成了 刂三三 ,但是这不符合笔顺,所以五笔 98 将其改成这样,对手写有些许帮助。
斲,匚(反匚)(亞中间)一斤,ANFR。这个字有点抽象,五笔 98 将这字拆了比较合理的字根,大家知道就可以了。
鬥,丨王王亅,HGGH。繁体字虽不常写,但是在打字中,出现的频率还是高的,记住一些简单繁体的拆分,做到书简识繁,也是很重要的。
曹,一冂龷日,GMAJ。还是依照汉字的书写顺序,先写了 一 ,再写 冂 ,完全符合笔顺。
夷,一弓人 I,GXWI。这字为啥没有拆成 大弓 呢?因为先写 一 ,再写 弓 ,最后写 人 ,还是和笔顺有关。
秉,禾彐 D,TVD。这字为什么又能这样拆呢?很大程度上是因为 98 取消了 86 的一个(木去横)这个根,不然就可以拆成 丿一彐(木去横),而 86 也确实是这样拆的,对于上面的 夷 为什么不拆成 大弓 ,我想可能是因为,98 中有 人 这个根吧。
束,木口 D,SKD。延长 木 以容纳 口 ,也不难接受。
毋,乙乙𠂇E,NNDE。虽然 X 键上有 毌 这个根,但是 毌(guan4) 毋(wu4)是不同的字,还是要区分的。
甴,冂丨二 D,MHFD。没有好的办法,死记。
曱,冂干 K,MFK。没有好的办法,死记。
卍,乙丨一丨,NHGH,网上找的笔顺似乎与这个拆分有不同,笔顺是左上一横,中间一竖,右下一横,左下一竖,中间一横,右上一坚,但是拆分将前三笔合成了 横折横 ,变成了折,而后三笔没变。
卐,乙一丨一,NGHG。从左上开始写,竖折坚,然后是右上的横,中间的竖,左下的横。
〇,LLLL。这也是个汉字,是 零 的简写,在五笔 98 中是一个特殊的字,拆成 LLLL。
爿,U 乙丨一丿,UNHT。这个字读 pan2。
鼎,目乙丆丨一丨乙,HNDN。要注意左下角是个 丆 根。
班,王丶丿王,GYTG。注意中间的部件可不是按键 J 上的(帅左),根据字体的不同,班 中间的部件都是点撇,而之前提到过,自右上到左下的短撇也算作点,而(帅左)是竖撇,所以 班 拆分成 王丶丿王,类似地,辨 同样拆分成 辛丶丿辛 。
乘,禾(北左)匕 V,TUXV。将 禾 视作一个整体来拆分。
乖,丿十(北左)匕,TFUX。和 乘 类似。
乗,禾龷 D,TAD。这是日本字,拆法与 秉 字类似。
率,亠幺(四点)十,YXIF。这个字同样也是先中间,后两边。
身,丿冂三丿,TMDT。这个字中取了个 三 ,没见过拆分之前,这个字还是比较难打的。
𠄷,口口口冂一,KKKG。这个字上的三个菱形,算作是旋转的 口 ,所以拆成 口 。
円,冂丨一 D,MHGD。这个字拆成了笔划,见过就会拆了。
且,月一 D,EGD。类似 且 的字,都拆出 月 和 一 。
直,十(具上)F,FHF。注意这个字中间是三横。
真,十(具上)八 U,FHWU。中间也是三横。
具,(具上)八 U,HWU。中间也是三横。
养,䒑夫刂 J,UGJJ。注意这类字的字头,拆分成了 䒑 夫 。
春,三人日 F,DWJF。是 三 人,不是 一 夫,也不是 二 大。
卷,丷夫⺋ B,UGBB。能散不连。
美,丷王大 U,UGDU。
甩,月乙 V,ENV。这个字虽然非常像 用 ,而且 E 上也确实有 用 这个根,但是这字不能用 用 来拆。
庸,广彐月丨,OVEH。这个字同样有 用 在里面,但是根据笔顺和不断开笔划,不能拆出 用 来。
丑,乙丨一一,NHGG。这个字完全按照了笔划来拆分,需要特殊记忆。
夨,乙一乀 I,NGYI。这个字的首笔折,是撇折撇。
興,(臼)冂一口一八,EMGW。这个字的中间按照同来拆,可能有人的笔顺是先写中间的同,再写两边,但是在五笔 98 中,是左中右的。
學,(臼)乂乂冖子,ERRB。这个字同样是左中右地写,拆分也是先外后内。
鬱,木𠂉十凵木冖𠂭凵匕彡,STFE。这个字看起来虽然难写,但是拆分出来之后,全是简单的根的组合,也并不难。
彧,戈口一(两撇),AKGR。这个字先打 或 ,再补上两撇,这样比较好打,如果要打三撇,那就拆得比较零碎了。
芈,丨一⺊(干出头),HGHG。这个字的左上角先写 丨 ,再写 一 ,接着是右上角的 ⺊ ,最后是中间的(干出头)。
倂,亻丿一𠂇丿干,WTGF。这个字中的(歪干)拆成了 一𠂇,有点迷惑。
栞,一𠂇干木,GDFS。这个字的左上就是(歪干)。
㐃,(三角)丨 K,LHK。这个字上面的三角兼容在 L 键上。
乄,乙丶 I,NYI。先撇折,再点。
㱐,二止丶 I,FHYI。武 字少了一折。
𡬝,十亅丶 I,FHYI。这是 等 字的二简字。
𡆢,囗乙 V,LNV。汉字中也有许多带弧度的笔划,统统算作折。
𩃅,一冖(川)亻⺊口,FPKK。中间的三竖不常用,但是它在按键 K 上。
𠺞,一冖丨一𠆢土口,GPHK。这字上头不是 雨 ,得按笔划来拆。
𢀯,一⺉厂乙目目工,GJDA。过于抽象,但是还是可以拆出来的。
𥙥,礻 Y 已工,PYNA。说实话这字根本看不出来,我不在这举例,估计都没人知道这字。
𪚦,一刂(龜下)D,GJXD。虽然(龜下)开了个洞,但是辨识度相当地高。
越,土龰戈乚,FHAN。越 的右边折法比较特殊,并不是像笔划一样的 横 竖提 折钩 撇 点,而是拆成了 戈乚 ,比较抽象,但是见过了之后,也就会拆了。
𠤺,匚丿𧘇丿,ATET。这里面的 𧘇 左上有撇,右边也有一撇,按照书写顺序补全这两撇就可以了。
𢍒,(聚下)丿廾 J,ITAJ。(聚下)多了一撇,先打(聚下),再补全那一撇。
𡘎,大丿(两撇)(畏下),DTRE。这字一看下面好像是(聚下),但是不是,非常相似,其实是(畏下),先一撇,再两撇,剩的就是(畏下)了,要注意(畏下)不包括横,颇具难度。
淵,氵(淵右去一)一 G,IJGG。注意第二个根是没有中间的一横的,末根是 一。
肅,彐十(淵右去一)K,VFJK。第三个根变成了末根,注意它的末笔是 丨 。
6、镜像、倒立、旋转汉字拆分
在中文 Unicode 字符集中,存在许多有趣的汉字,这些字有倒立的,有中心旋转的,还有左右或者上下镜像的汉字,虽然我们日常不会打出这些字,但是瞭解这些有趣的汉字的拆分,可以使我们对五笔 98 有更深的理解。
5.1 镜像汉字拆分
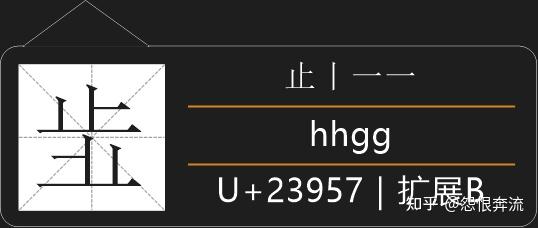
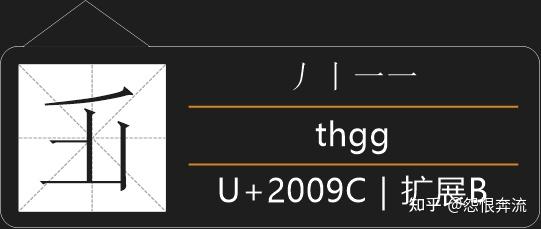
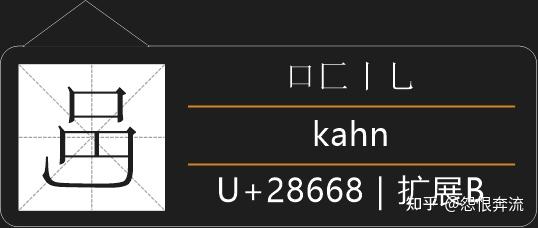
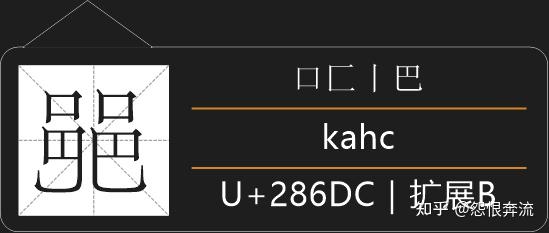
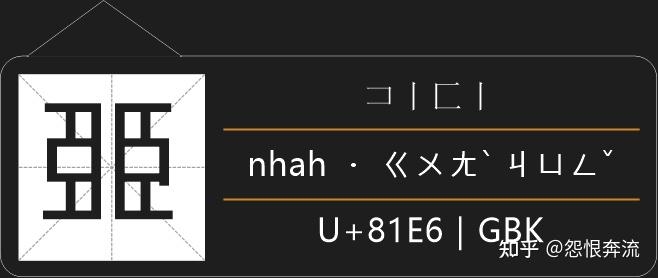

可以看到这些字和原字是左右镜像的,还是能够通过笔顺来完成拆分的,所以这类字采用拆分划的方法进行拆分。
5.2 倒立汉字拆分


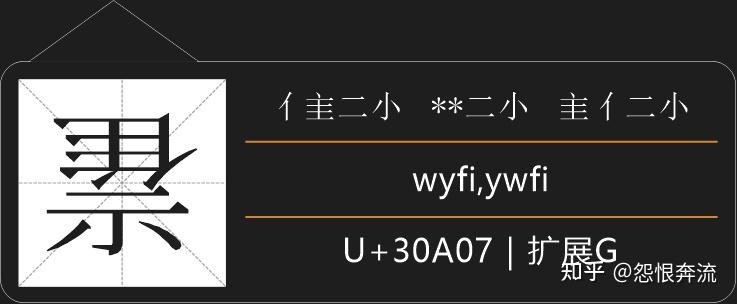


这些字就不一而足了,如果是独体倒立字,勉强可以拆成笔划,但如果是组合倒立字,就必须倒字正拆了,按照它正立时候的字根来进行拆分。这些字的拆分还是做了兼容,毕竟太抽象了。
5.3 旋转汉字拆分


同样,可以拆成笔划的,就按照笔划拆,实在不行的,就倒字正拆。
7、汉字部件拆分
7.1 三画
尢,𠂇乚,DN。
兀,一儿,GQ。
尣,八儿,WQ。
屮,凵丨,BH。
巾,冂丨,MH。
弋,七丶,AY。
飞,⺄(两点),NU。
马,(马上)一,CG。
7.2 四画
戶,丿尸,TN。
支,十又,FC。
攴,卜又,HC。
斗,⺀十,UF。
无,二儿,FQ。
欠,⺈人,QW。
歹,一夕,GQ。
歺,卜夕,HQ。
殳,几又,WC。
毋,乚乛𠂇,NND。
比,匕匕,XX。
氏,(氏去七)七,QA。
爪,⺁丨乀,RHY。
父,八乂,WR。
爻,乂乂,RR。
片,丿丨一乙,THGN。
牙,匸丨丿,AHT。
牛,丿(半下),TG。
见,冂儿,MQ。
韦,二乛丨,FNH。
风,几乂,WR。
7.3 五画
玄,亠幺,YX。
玉,王丶,GY。
瓜,⺁厶乀,RCY。
瓦,一乚⺄丶,GNNY。
生,丿(青头),TG。
疋,乛龰,NH。
矛,龴乚亅丿,CNHT。
矢,𠂉大,TD。
示,二小,FI。
穴,宀八,PW。
鸟,(鸟上)一,QG。
龙,𠂇匕丶,DXY。
7.4 六画
竹,𠂉丨𠂉亅,THTH。
糸,幺小,XI。
缶,𠂉十凵,TFB。
网,冂乂乂,MRR。
老,土丿匕,FTX。
而,丆冂刂,DMJ。
耒,二木,FS。
聿,彐(半下),VG。
肉,冂人人,MWW。
臣,匚丨(反匚)丨,AHNH。
自,丿目,TH。
至,一厶土,GCF。
舌,丿古,TD。
舛,夕(韋下),QG。
舟,丿(舟下),TU。
色,⺈巴,QC。
血,丿皿,TL。
行,彳一丁,TGS。
衣,亠(衣下),YE。
页,丆贝,DM。
齐,文刂,YJ。
7.5 七画
角,⺈用,QE。
谷,八人口,WWK。
豆,一口䒑,GKU。
豕,一(豕下),GE。
赤,土(亦下),FO。
走,土龰,FH。
足,口龰,KH。
身,丿冂三丿,TMDT。
辰,厂二(衣下),DFE。
邑,口巴,KC。
酉,西一,SG。
釆,丿米,TO。
里,日土,JF。
卤,卜囗乂,HLR。
麦,(青头)攵,GT。
龟,⺈日乚,QJN。
7.6 八画
隶,彐水,VI。
隹,亻(隹右),WY。
青,(青头)月,GE。
非,丨三丨三,HDHD。
鱼,(鱼上)一,QG。
齿,止(人凵),HB。
7.7 九画
面,丆囗刂二,DLJF。
革,廿(革下),AF。
韭,丨三丨三一,HDHDG。
音,立日,UJ。
食,人丶艮,WYV。
首,䒑丿目,UTH。
香,禾日,TJ。
7.8 十画
骨,(骨上)月,ME。
高,(亠口)冂口,YMK。
髟,镸彡,DE。
鬲,一口冂䒑丨,GKMUH。
鬼,白儿厶,RQC。
7.9 十一画
鹿,(鹿上)匕匕,OXX。
麻,广木木,OSS。
黄,(共头)由八,AMW。
7.10 十二画
黍,禾人水,TWI。
黑,(黑头)土灬,LFO。
鼎,目乙丆丨一丨乙,HNDHGHN。
7.11 十三画
鼓,土口䒑十又,FKUFC。
鼠,臼乚(两点)乙(两点)乙,ENUNUN。
7.12 十四画
鼻,丿目田一刂,THLGJ。
7.13 十七画
龠,人一口口口冂卄,WGKKKMA。
六、五笔杂谈
1、笔形识别码和构形识别码
所谓笔形识别码,其实就是我们之前学的末笔交叉识别码,是根据末根末笔和整个字的字型来联合使用,用以避重的方法,无论是在五笔 86,还是 98,还是新世纪,还是其它的衍生版本,都在使用,但在 86 中,识别码采用的是整个字的末笔,在 98 中,改成了末根的末笔,但是末笔交叉识别码的名称却延续了下来,也叫末笔字型识别码。大家似乎也只听说过这一种识别码,但其实五笔 98 的专利书中有一个并未实行的识别码方案,叫作构形识别码。
构形识别码,全称是末笔构形识别码,利用整个字的末笔及其与其它部件的关系,来联合判断字的构形,以避重的方法,此方法适用于添加了笔形识别码后,仍不足五码的情况。
为什么是不足五码的情况?五笔 98 不是四码定长的方案吗?其实在五笔 98 的专利书中,五笔 98 是四码与五码的不定长方案,在 GB2312 和 BIG5 字集中取四码,在 GB13000.1 字集中取五码。在取五码的字集中,便应用了构形识别码,以解决码长不足的问题。
每个汉字的末笔都属于横竖撇捺折中的一个,再根据末笔和其它笔划的关系,形成了名为构形识别码的避重方法:
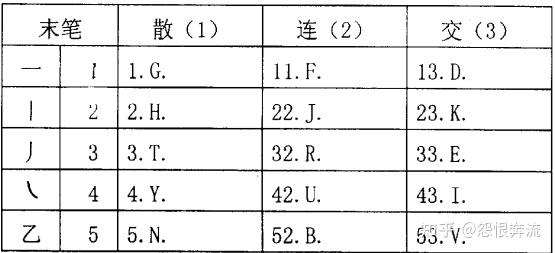
如图,一个字的末笔和其它笔划有散、连、交的关系,再根据这个末笔的类型,我们就可以用上图的 15 个键位代表构形识别码,在笔形识别码中,识别码元是带圈的,而构形识别码,识别码元是用方框框住的。
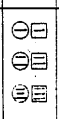
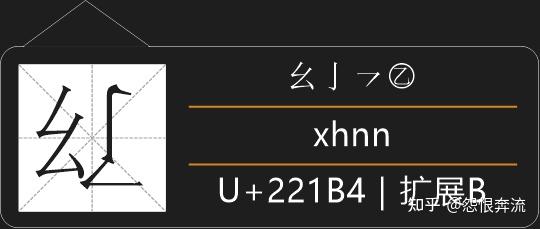
构形识别码追加在已有笔形识别码但码长仍不足五码的字上,比如 红 字,在原始情况下,它的编码是 XAG,红 的末笔是 一 ,和其它笔划的关系是相连,所以它的构形识别码是 F,那么 红 的全码是 XAGF。要注意构形识别码是用在使用五码的字集中的。
利用构形识别码,可以将五笔原本加了识别码还不能区分的汉字分开,比如 本 和 酉 两个字,它们的编码都是 SGD,在加了构形识别码之后,本 的编码变成了 SGDD,酉 的编码变成了 SGDF。在经典例子 云 去 支 三个字中,使用构形识别码,编码从 FCU 分别变为 FCUU,FCUU,FCUI,将 支 字分离了重码,但 云 去 两字仍是重码。
但是构形识别码在现行的五笔方案中,却没有被使用,这其实也是有原因的,笔形识别码在判断字型是上下还是杂合的时候,已经很烧脑了,为人诟病,如果再加上一个构形识别码,就更烧脑了,而且构形识别码使用在五码字集中,而五笔取消了五码,所以构形识别码就这样消失了,更何况构形识别码对于分离重码的效果,也并没有那么理想,它的消失,是可以想象的。而且,如果现在在四码方案加上构形识别码,那么就只能加给二根字,而二根字由于信息太少了,能用构形识别码来分重的,也不是很多,现在的笔形识别码分重能力已经很优秀了,再加构形识别码,确实有画蛇添足之嫌。
2、单编方案与双编方案对比
单编方案就是一个编码确定一个字根,双编方案就是两个编码确定一个字根,这在前面说过,这两种形式的编码方案,在一定程度上是可以比较的,具体表现在单字的输入方式上,我们已经知道,单字有单根字,二根字,三根字和多根字,我们就以此来对比单编和双编,在单字上有何优劣。单根方案以五笔 98 为例,双编方案以宇浩码为例。
2.1 单根字的对比
在五笔 98 中,单根字的输入方式是,先输入此字所在键位,然后以 GHTYN 为横竖撇捺折来写出第一笔,第二笔和末笔,打单根字的时候,码长不定。单根字其实并不好打,因为用字根打字,和用笔画打字,是两种思维,所以五笔 98 在打单根字的时候,体验不佳。可以利用 Z 键来打,比如 AZ 是 A 键上的一个字根字,AZZ 是另外一个,AZZZ 是另外一个,字根字的数量不多,记忆量小,这种方法可行。
在宇浩输入法中,单根字的输入方式是,先输入这个字的大码和小码,然后再重复小码,即 Aaa,定长为三,且在设置字根的时候,每一个字根的小码都不相同,所以重码较少。
综合来说,双编优于单编。
2.2 二根字的对比
在五笔 98 中,二根字的输入方式是,输入两个根的编码,再根据字型和末笔来输入识别码,定长为三,且二根字的字型较好判断,输入难度较低。
在宇浩输入法中,二根字的输入方式是,输入首根的大码,次根的大小码,首根的小码,即 ABba,定长为四,除了要记忆这两个字根的大小码外,还要采用回头码的方式来完成输入,而回头码这一设定,在思维的流畅性上,稍有欠缺。
综合来说,单编优于双编。
2.3 三根字的对比
在五笔 98 中,三根字的输入方式是,输入这三个根的编码,再根据字型和末笔来输入识别码,定长为四,也不是很难。
在宇浩输入法中,三根字的输入方式是,输入首根的大码,次根的大码和末根的大小码,即 ABCc,定长为四,对标五笔来看,前三码,二者都没区别,没有小码的双编,其实就是单编,而最后一码,宇浩采用末根的小码,是要优于识别码的,因为小码只管记住就好,而五笔还需判断字型和末笔,过于复杂。
综合来说,双编优于单编。
2.4 多根字的对比
在五笔 98 中,多根字的输入方式是,输入一二三末根的编码,没有识别码。
在宇浩输入法中,多根字的输入方式是,输入一二三末根的大码,即 ABCZ。
二者已经没有区别了,因为没有小码的双编就是单编,看似平手,实际是双编优于单编,因为双编是利用算法来生成的,已经利用算法来在重码方面,双手平衡方面和字根布置方面登峰造极了,而五笔 98 是上个世纪的产物,已经输太多了。
3、识别码于双编方案
仔细观察双编方案,会发现大部分字根后面都有小码,在二根字和三根字中,这些小码其实就起到了五笔中识别码的作用,用以避重,每个字根的小码都不尽相同,五笔只有 15 个识别码,而双编有 25 个,所以双编的重码是低于五笔的,那么,用双编的小码来定义识别码的话,识别码就是可变小码,每个能成为末根的字根都有三个小码,根据这个字根的末笔,来确定这三个小码是 gfd 还是 hjk 之类的,比如 刀 这个字根,末笔为撇,那么它的小码就是 tre 这三个中的一个,至于要选取哪个,还要看字型的,如果是上下型,就选取 r 来作为刀的小码,这时刀的编码就成了 Vr,比如 分 字,WVr,这时的 r 就起到了双编中小码的作用。
这给了我们一个启示,如果识别码能从 15 个扩展成 25 个,那么对于重码的减少,作用肯定会很大,不过双编中的小码有些采用音托,即拼音首字母来编配,有些是根据字根的形来编配,25 个字母中的任何一个都能成为某个根的小码,而识别码,字根的末笔是确定的,那么最多只有三个字母可能成为这个根的小码,局限太大了,至今依然没有一个好方法,能扩展识别码的范围。
4、补码码元于双编方案
五笔中的补码,就是 犭 衤 礻 飠 这四个字根,它们在五笔中需要两个编码来确定,那么它们算不算双编方案中的双编字根呢?不算,原因是,在双编方案中,每个字根的小码都可能出现省略的情况,比如四根字的编码,完全由字根的大码组成,而小码全被省略了,但是在五笔中,补码字根的小码不能省略,必须打全了第一码和第二码,所以补码虽然是双编码组成的,但是还是区别于双编方案中的双编码的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号