SQL Server数据库--索引
什么是索引
描述:
汉语字典中的汉字按页存放,一般都有汉语拼音目录(索引)、偏旁部首目录等
我们可以根据拼音或偏旁部首,快速查找某个字词
SQL Server中的数据也是按页存放
索引:
是SQL Server编排数据的内部方法。它为SQL Server提供一种方法来编排查询数据
索引页:
数据库中存储索引的数据页;索引页类似于汉语字(词)典中按拼音或笔画排序的目录页
索引的作用:
通过使用索引,可以大大提高数据库的检索速度,改善数据库性能
索引类型
唯一索引
唯一索引不允许两行具有相同的索引值
主键索引
是唯一索引的特殊类型
聚集索引(Clustered)
表中各行的物理顺序与键值的逻辑(索引)顺序相同,同一张表里只可以有一个“聚集索引”
非聚集索引(Non-clustered)
非聚集索引指定表的逻辑顺序
如何创建索引
使用SQL Server Management Studio创建索引
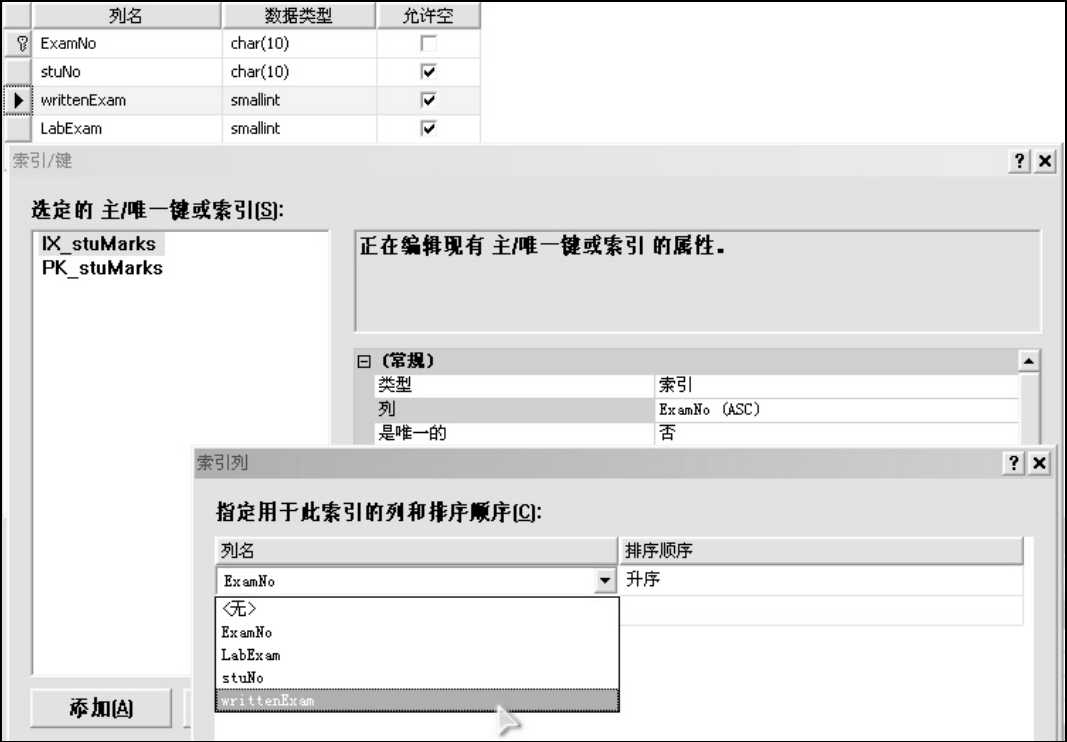
使用T-SQL语句创建索引
CREATE [UNIQUE] [CLUSTERED|NONCLUSTERED] INDEX index_name ON table_name (column_name…) [WITH FILLFACTOR=x]
[UNIQUE] :唯一索引
[CLUSTERED|NONCLUSTERED]:聚集索引或非聚集索引,同一张表里只可以有一个“聚集索引”
[WITH FILLFACTOR=x]:填充因子(系数):指定一个0~100之间的值,表示索引页填充的百分比
使用T-SQL语句删除索引
表名和索引名称之间,用“.”分隔
DROP INDEX table_name.index_name
删除表时,该表的所有索引同时会被删除
示例
在Student表的StudentName列创建非聚集索引
USE MySchool GO /*--检测是否存在该索引(索引存放在系统表sysindexes中)--*/ IF EXISTS (SELECT name FROM sysindexes WHERE name = 'IX_Student_StudentName') DROP INDEX Student.IX_Student_StudentName --删除索引 GO /*--学生姓名列创建非聚集索引:填充因子为30%--*/ CREATE NONCLUSTERED INDEX IX_Student_StudentName ON Student(StudentName) WITH FILLFACTOR = 30 GO
使用索引查询“李”姓的学生信息
/*----指定按索引:IX_Student_StudentName查询----*/ SELECT * FROM Student WITH (INDEX=IX_Student_StudentName) WHERE StudentName LIKE '李%'
索引的优缺点
优点
1.加快访问速度
2.加强行的唯一性
缺点
1.带索引的表在数据库中需要更多的存储空间
2.操纵数据的命令需要更长的处理时间,因为它们需要对索引进行更新
创建索引的指导原则
按照下列标准选择建立索引的列
1.频繁搜索的列
2.经常用作查询选择的列
3.经常排序、分组的列
4.经常用作连接的列(主键/外键)
请不要使用下面的列创建索引
1.仅包含几个不同值的列
2.表中仅包含几行
使用索引时注意事项
A.查询时减少使用*返回全部列,不要返回不需要的列
B.索引应该尽量小,在字节数小的列上建立索引
C.WHERE子句中有多个条件表达式时,包含索引列的表达式应置于其他条件表达式之前
D.避免在ORDER BY子句中使用表达式
E.根据业务数据发生频率,定期重新生成或重新组织索引,进行碎片整理
查看索引
使用系统存储过程sp_helpIndex查看有关表或视图上索引的信息
EXEC sp_helpIndex name --name 可以是表名或视图名
查看Result表的索引信息
EXEC sp_helpindex Result
使用视图sys.indexes查看索引
SELECT * FROM sys.indexes
查看MySchool数据库中全部索引信息
USE MySchool SELECT * FROM sys.indexes
笔记
索引 (36字符串主键)absdhjagsjdhgasjdhg
主键索引:默认聚集索引(唯一建、聚集索引)
唯一索引
聚集索引
每张表只能有一个聚集索引,按照磁盘物理顺序 0-1 a-z
非聚集索引
每张表可以有N个非聚集索引(普通索引、唯一索引、全文索引)
索引:针对表的某个字段去建立
优点:帮助提高查询效率
缺点:占用物理磁盘空间
一般什么样的字段适合建立索引?
首要条件:经常用作查询 产品名称、产品型号
产品描述(大字段)like
唯一,字段内容小,数据重复性低
--十万级、百万级 --假如循环插入100万条数据、数据有规律可循 insert into test1 values(3,'华为手机pro20') --后台报表啊 select * from test1 with(index=test1_name)--使用索引 where name='华为手机pro20' --非聚集索引nonclustered --唯一:可选unique --创建一个唯一非聚集索引 顺序不是磁盘物理顺序 create unique nonclustered index test1_name --名称,确保唯一性,有意义 on test1(name)--表名+列名 with fillfactor=50 --填充因子百分比0-100之间 --假如你设计的表,不需要频繁的做添加、删除 --缺点:占空间 --57同学 --假如标明57个人 --填充因子为0 --1,2,3,4,5,6,7,8....57 --视图:查询效率是没有关系 --优点:简化查询语句 select * from sysindexes where name ='test1_name'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号