


【数据采集与融合】第四次实验
作业一
当当图书爬取实验
作业内容
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法; Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
-
关键词:学生自由选择
实验步骤
1.先创建我们的scrapy项目,这个和上次实验一样,打开cmd终端,cd进入我们想要创建的项目路径下,输入以下指令创建项目dangdang
scrapy startproject dangdang
2.然后我们再进入创建好的项目之下,执行指令如下创建我们的爬虫
scrapy genspider DangDangSpider
3.可以看到我们创建好的项目和爬虫如下
4.开始愉快的编写我们的代码,第一步先设置setting.py文件里面的内容,这个和上一次作业一摸一样,只要修改三个地方就行,这个比较简单,我就不多介绍了
然后我们编写一下item.py文件里面的内容如下:
class DangdangItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
date = scrapy.Field()
publisher = scrapy.Field()
detail = scrapy.Field()
price = scrapy.Field()
5.编写Spider,先决定这次实验使用Xpath来定位,然后F12观察网页内容,找好xpath就可以开始编写了,关键的parse函数如下,本人选择的关键词是python,即爬取python的书籍
def parse(self, response):
global page # 设置页码
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"]) # 解析网页
data = dammit.unicode_markup
selector = scrapy.Selector(text=data) #创建selector对象
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]") # 找到lis列表
print('>>>>>>>第' + str(page) + '页<<<<<<<')
for li in lis:
title = li.xpath("./a[position()=1]/@title").extract_first()
price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date = li.xpath("./p[@class='search_book_author']/span[position()=last()- 1]/text()").extract_first()
publisher = li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title ").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
item = DangdangItem() # 创好对象
item["title"] = title.strip() if title else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
item["detail"] = detail.strip() if detail else ""
yield item
还有一个重要的地方就是实现翻页,我是使用全局变量page来实现的,如果page达到我们想要的页数就可以停止了
link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first()
# 获取下一页的链接
if link:
if page == 3:
# 设置最多爬取页数
print("爬取了3页")
link = False
page += 1
url = response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse)
6.最后就是数据的表示和存储了,这次实验要求存储到MySQL数据库中所以,我们可以事先在外面创建好表,然后再把通过编写pipline把数据插入,如下

开始编写pipline,第一步先和数据库建立连接如下:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
passwd = "huan301505", db = "MyDB", charset = "utf8")
# 连接mysql数据库
self.cursor = self.con.cursor(pymysql.cursors.DictCursor) # 设置游标
self.cursor.execute("delete from books") # 清空数据表
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened = False
第二步打印数据,并插入数据库,再数据量self.count == 125 的时候提交,关闭连接
def process_item(self, item, spider):
try:
if self.opened:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print("=======================================================") # 打印每本书,换行隔开
# 插入数据
self.cursor.execute("insert into books (bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) values (%s, %s, %s, %s, %s, %s)", (item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"]))
self.count += 1 # 计数
if self.count == 125:
# 等于125本的时候提交数据库,关闭连接
self.con.commit()
self.con.close()
self.opened = False # 关闭
print("closed")
print("总共爬取", self.count, "本书籍")
return
实验结果
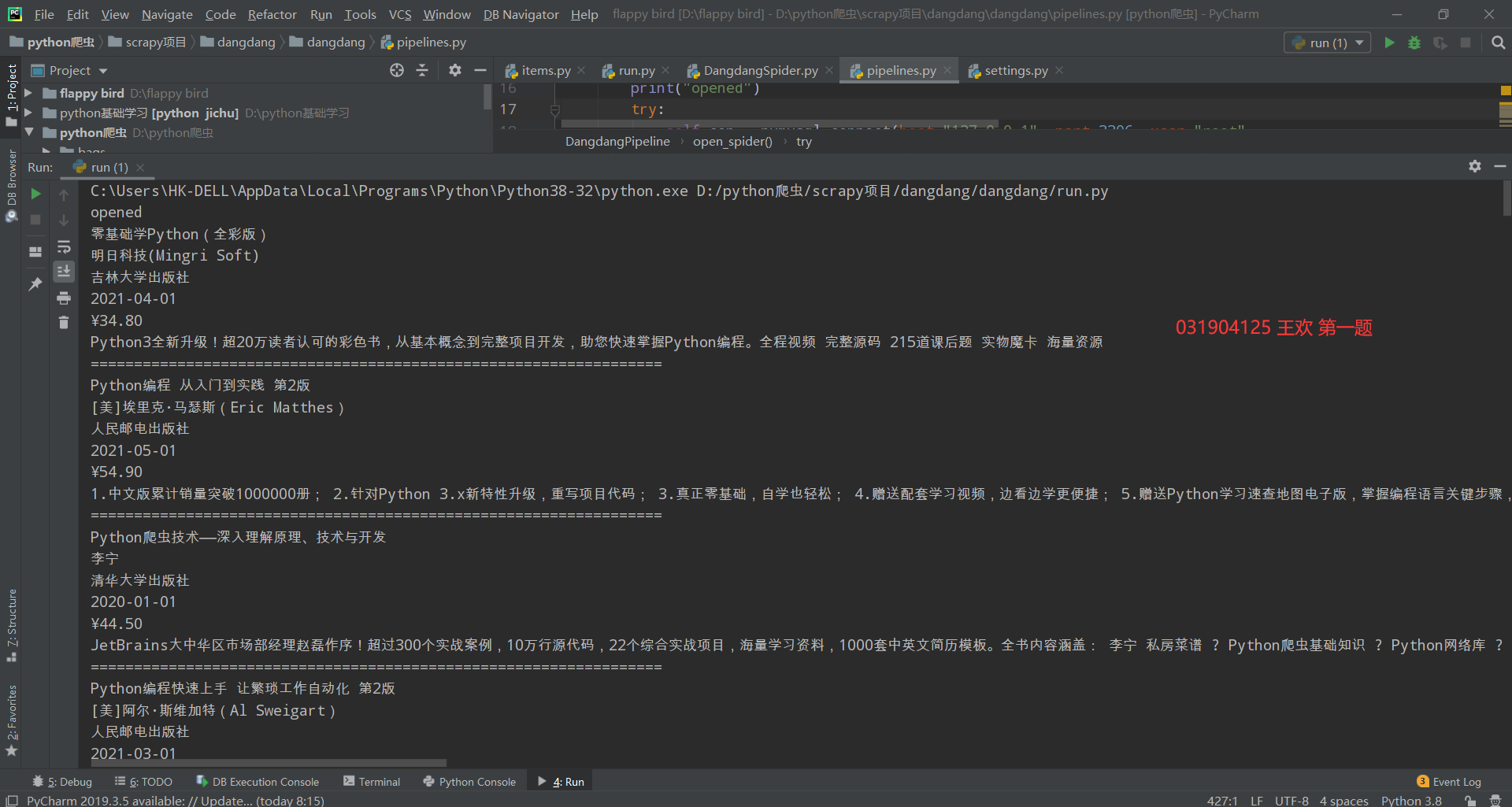
运行结果如下:
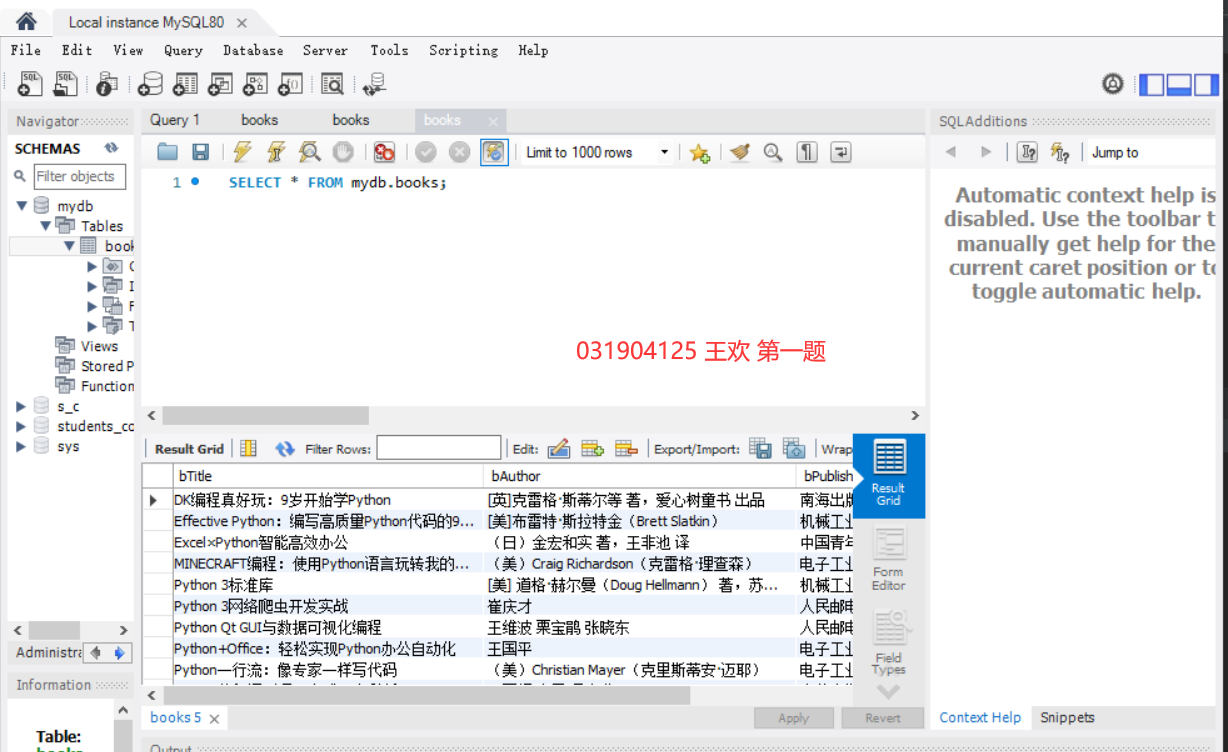
数据库:
实验心得
通过这次实验,我进一步巩固了scrapy用法,还有对网页元素寻找更加熟练
作业二
银行汇率爬取实验
作业内容
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
-
候选网站:招商银行网:http://fx.cmbchina.com/hq/
实验步骤
1.这题和作业一有点类似,都是使用xpath,所以实验前的准备工作我就不罗嗦,包括setting文件,item文件的编写,我们直接跳过来到Spider,我们来观察他的网页发现会比第一题元素定位要简单一点,每一个元组里面的内容位置都在tr中的td里面,所以我们需要先定位tr
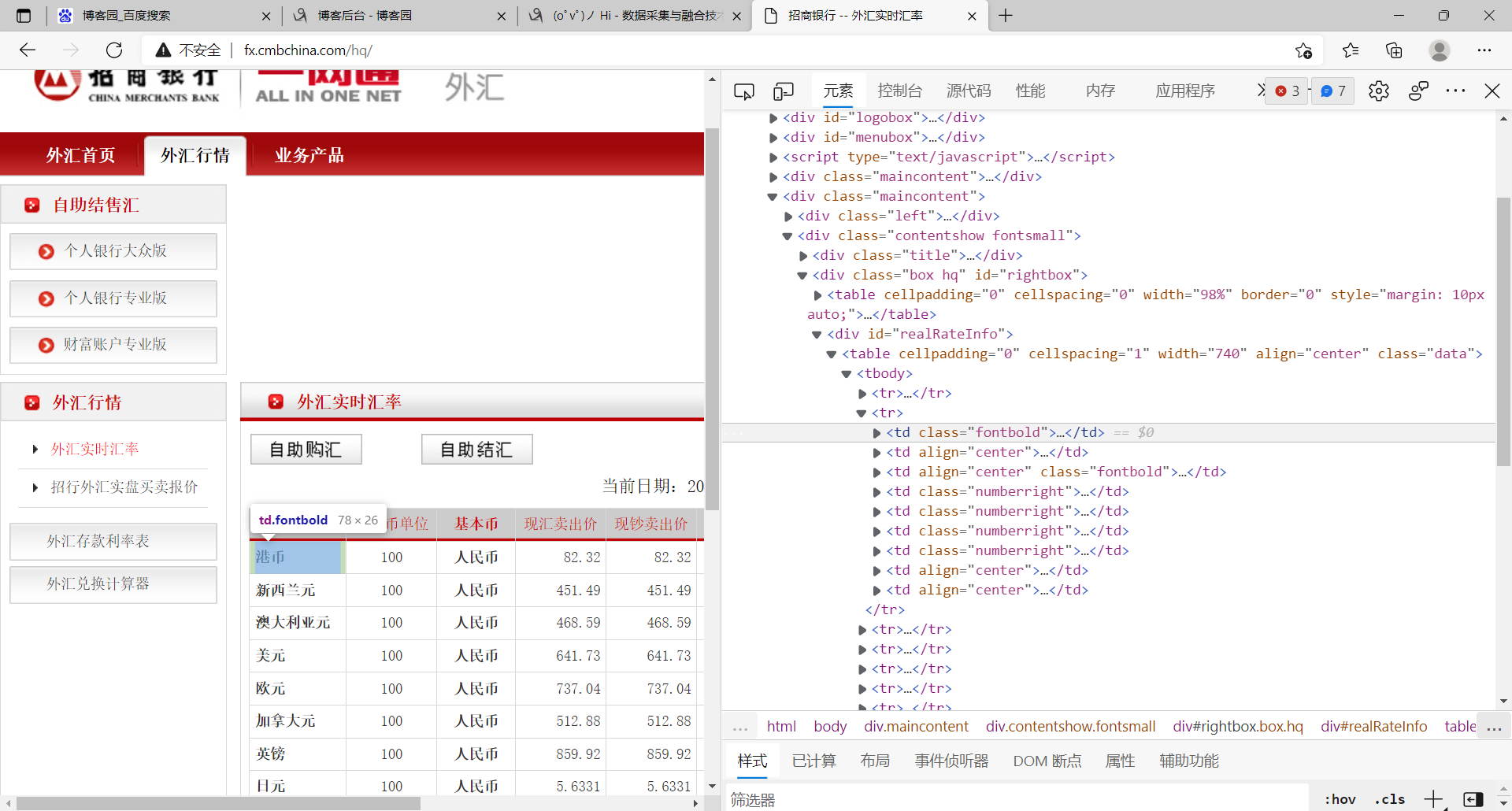
tr列表的的xpath定位语句如下:
tr_lists = selector.xpath('//div[@id="realRateInfo"]/table//tr') # 使用xpath找到tr列表
2.然后我们就可以遍历每一个tr然后提取tr下面的td里面我们想要的内容:
for i in range(1, len(tr_lists)):
# 设置从1开始,因为第0个是表头,不是我们要爬取的数据
Currency = tr_lists[i].xpath('./td[@class="fontbold"]/text()').extract_first()
TSP = tr_lists[i].xpath('./td[4]/text()').extract_first()
CSP = tr_lists[i].xpath('./td[5]/text()').extract_first()
TBP = tr_lists[i].xpath('./td[6]/text()').extract_first()
CBP = tr_lists[i].xpath('./td[7]/text()').extract_first()
Time = tr_lists[i].xpath('./td[8]/text()').extract_first()
item = FxItem() # item对象
item["Currency"] = Currency.strip()
item["TSP"] = TSP.strip()
item["CSP"] = CSP.strip()
item["TBP"] = TBP.strip()
item["CBP"] = CBP.strip()
item["Time"] = Time.strip()
yield item
3.做完这些之后我们就可以开始编写数据保存的工作,作业二的要求也是保存数据在MYSQL数据库,实现如下:
class FxPipeline:
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
passwd = "huan301505", db = "MyDB", charset = "utf8")
# 第一步先连接mysql数据库
self.cursor = self.con.cursor(pymysql.cursors.DictCursor) # 设置游标
self.cursor.execute("delete from fx") # 清空fx数据表
self.opened = True
self.count = 1
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit() # 提交
self.con.close() # 关闭连接
self.opened = False
print("closed")
print("爬取成功")
def process_item(self, item, spider):
try:
if self.opened:
s = "{0:{7}^10}\t{1:{7}^10}\t{2:{7}^10}\t{3:{7}^10}\t{4:{7}^10}\t{5:{7}^10}\t{6:{7}^10}"
if self.count == 1:
# 表头仅仅打印一遍
print(s.format("序号","货币","TSP","CSP","TBP","CBP","Time",chr(12288)))
print(s.format(str(self.count),item["Currency"],item["TSP"],item["CSP"],item["TBP"],item["CBP"],item["Time"],chr(12288)))
self.cursor.execute('insert into fx (id,Currency,TSP,CSP,TBP,CBP,Time) values (%s, %s, %s, %s, %s, %s, %s)',(str(self.count),item["Currency"],item["TSP"],item["CSP"],item["TBP"],item["CBP"],item["Time"]))
self.count += 1
except Exception as err:
print(err)
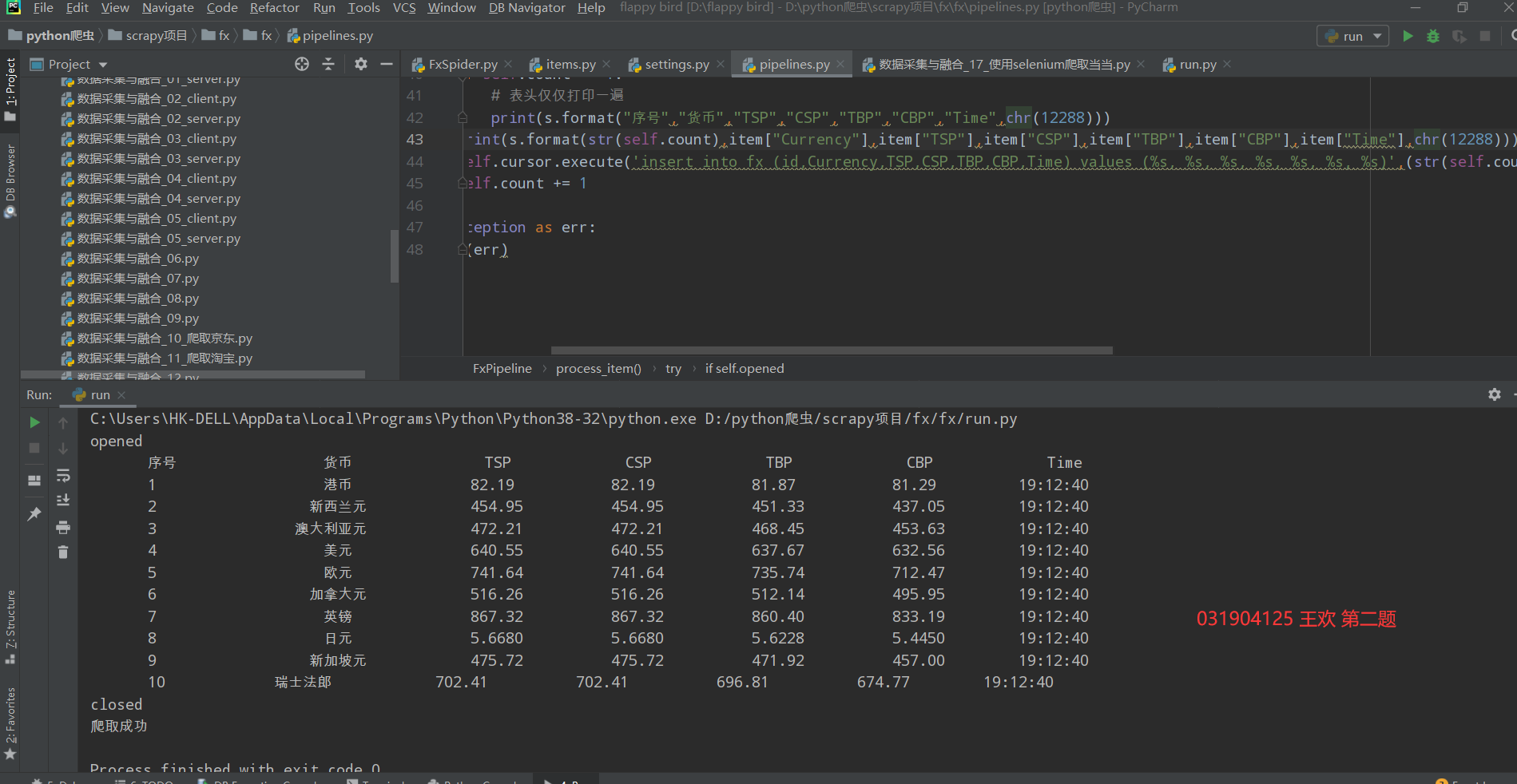
实验结果
运行在pycharm控制台上结果
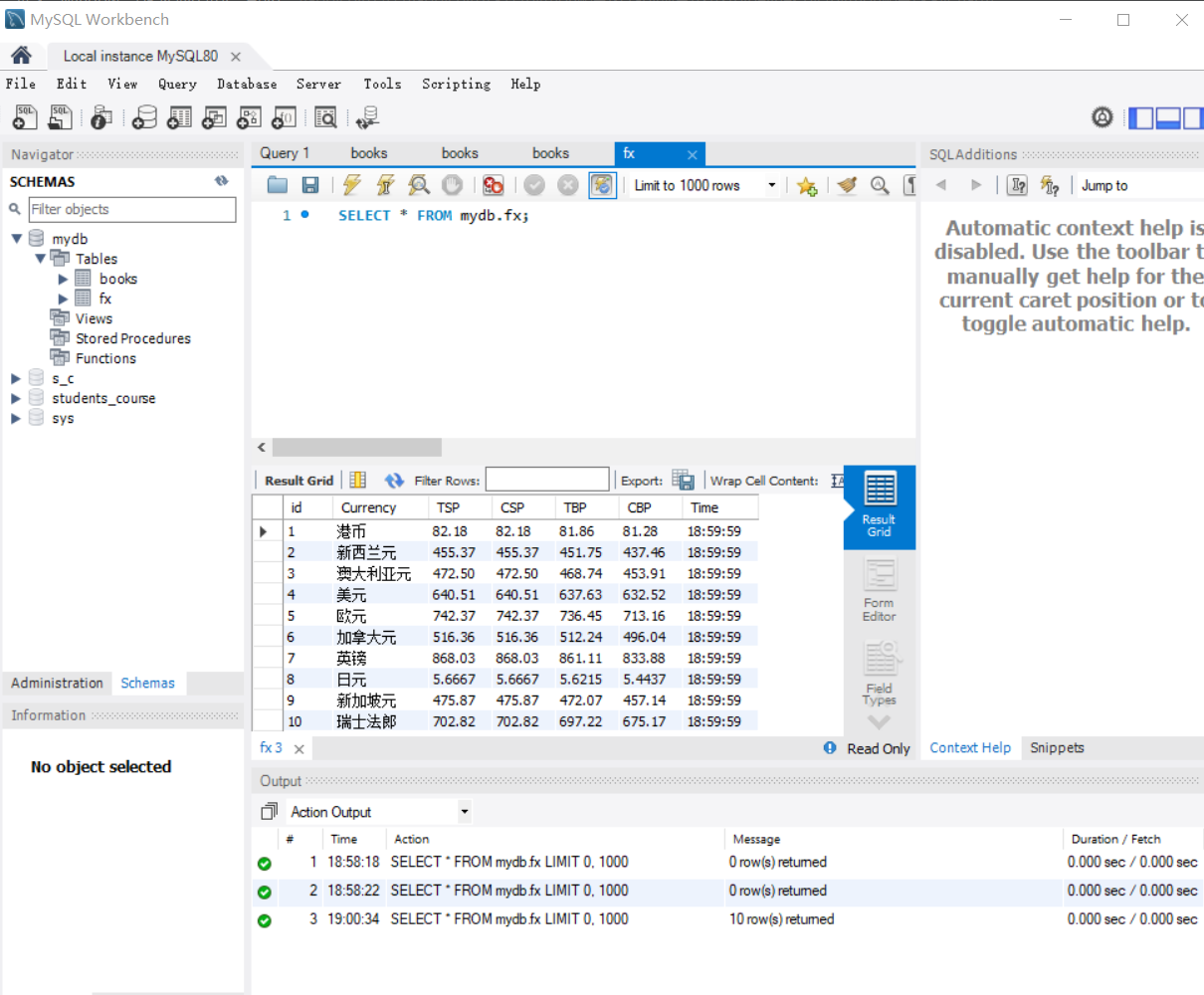
数据库内容:
实验心得
通过这次实验,我进一步巩固了scrapy用法,还有对网页元素寻找更加熟练,有一个地方需要注意的就是xpath直接从网页中复制的问题,有的时候可以用,有的时候又会失灵挺气人的,就比如这次的作业二我定位tr列表就是无法使用直接复制XPATH,后来只能自己写
作业三
股票信息爬取实验
作业内容
-
要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
-
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
实验步骤
1.作业三要求我们使用selenium方式去爬取网页内容,所以我们先进行爬取前的准备工作,导入好selenium相关的包,使用selenuim的webdriver设置一个虚拟浏览器
# 爬取前的准备 browser = webdriver.Chrome() # 设置谷歌 wait = WebDriverWait(browser, 10) # 设置等待时间10秒 url = "http://quote.eastmoney.com/center/gridlist.html" name = ['#hs_a_board','#sh_a_board','#sz_a_board'] # 要爬取的模块列表,1.沪深A股,2.上证A股,3.深证A股
2.因为这次作业都要保存数据在mysql中所以先编写,数据库的类,包括连接数据库,关闭数据库,插入数据这三个方法
# stock数据库类
class mySQL:
def openDB(self):
print("opened")
try:
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root",
passwd = "huan301505", db = "MyDB", charset = "utf8") # 第一步先连接mysql数据库
self.cursor = self.con.cursor(pymysql.cursors.DictCursor) # 设置游标
# self.cursor.execute("create table stocks (Num varchar(16), stockCode varchar(16),stockName varchar(16),Newprice varchar(16),RiseFallpercent varchar(16),RiseFall varchar(16),Turnover varchar(16),Dealnum varchar(16),Amplitude varchar(16),max varchar(16),min varchar(16),today varchar(16),yesterday varchar(16))")
# 创建表stock
self.cursor.execute("delete from stocks") # 清空数据表
self.opened = True
self.count = 1
except Exception as err:
print(err)
self.opened = False
def close(self):
if self.opened:
self.con.commit() # 提交
self.con.close() # 关闭连接
self.opened = False
print("closed")
print("爬取成功!")
#插入数据
def insert(self,Num,stockcode,stockname,newprice,risefallpercent,risefall,turnover,dealnum,Amplitude,max,min,today,yesterday):
try:
self.cursor.execute("insert into stocks(Num,stockCode,stockName,Newprice,RiseFallpercent,RiseFall,Turnover,Dealnum,Amplitude,max,min,today,yesterday) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(Num,stockcode,stockname,newprice,risefallpercent,risefall,turnover,dealnum,Amplitude,max,min,today,yesterday))
except Exception as err:
print(err)
3.然后编写get_data()这个方法,我们可以一步一步来先爬取一页,即当前网页的内容,后面再考虑翻页和转换模块,我获取数据使用的selenuim中的find_elements_by_xpath实现,直接去找全部的数据列表,后面再使用.text的方法拿到数据,
def get_data():
try:
id = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[1]') # 股票序号
stockcode = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[2]/a') # ...
stockname = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[3]/a')
new_price = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[5]/span')
price_extent = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[6]/span')
price_extent_num = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[7]/span')
deal_num = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[8]')
deal_price = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[9]')
extent = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[10]')
most = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[11]/span')
least = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[12]/span')
today = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[13]/span')
yesterday = browser.find_elements_by_xpath('/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[14]')
for i in range(len(stockcode)):
print(id[i].text,"\t\t",stockcode[i].text,"\t\t",
stockname[i].text,"\t\t",new_price[i].text,"\t\t",
price_extent[i].text,"\t\t",price_extent_num[i].text,
deal_num[i].text,"\t\t",deal_price[i].text,"\t\t",
extent[i].text,"\t\t",most[i].text,"\t\t",least[i].text,"\t\t",today[i].text,"\t\t",yesterday[i].text)
# 打印数据
4.成功可以获取数据后再考虑一下翻页,我使用的selenuim中button.click()的方法,使用wait.until((By.Xpath))找到下一页的按钮,去点击它实现翻页
def next_page():
try:
page = 1
while page <= 3:
print("第"+str(page)+"页")
get_data()
button_next = wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="main-table_paginate"]/a[2]')))
button_next.click() # 点击下一页的按钮
time.sleep(1) # 设置等待一秒
webdriver.Chrome().refresh() # 刷新一下页面
page += 1
except Exception as err:
print(err)
在这里有一个问题,就是会出现下面的错误,后来我查了CSDN有人说是因为在爬取一些网站时,有时会提交网页,网页更新后但是页面元素没有连接成功,所以需要我们去刷新它,只需要使用webdriver.Chrome().refresh刷新一下网页就可以,还要在前面等待几秒钟再刷新,我试了一下就解决了这个问题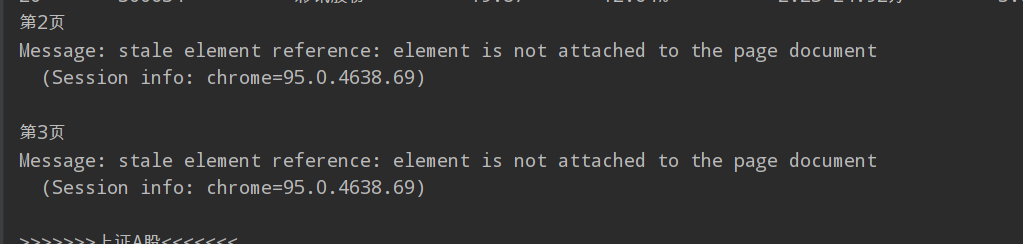
5.实现翻页后就是转换模块了,这作业三要求比较多,还需要我们爬取沪深A股,上证A股,深圳A股,我在这里是使用修改url的方法比较简单,我想还可以使用selenium的button.click()方法去点击它来实现转换
def next_part():
try:
print("开始爬取!")
print("股票信息如下:")
for i in range(len(name)):
new_url = url + name[i] # 修改url
browser.get(new_url) # 获取网页
time.sleep(1)
webdriver.Chrome().refresh() # 刷新一下
if i == 0: print(">>>>>>>沪深A股<<<<<<<")
elif i == 1: print(">>>>>>>上证A股<<<<<<<")
else: print(">>>>>>深圳A股<<<<<<")
next_page() # 开始爬取
stockDB.close() # 循环结束就关闭数据库
except Exception as err:
print(err)
实验结果
运行结果如下:

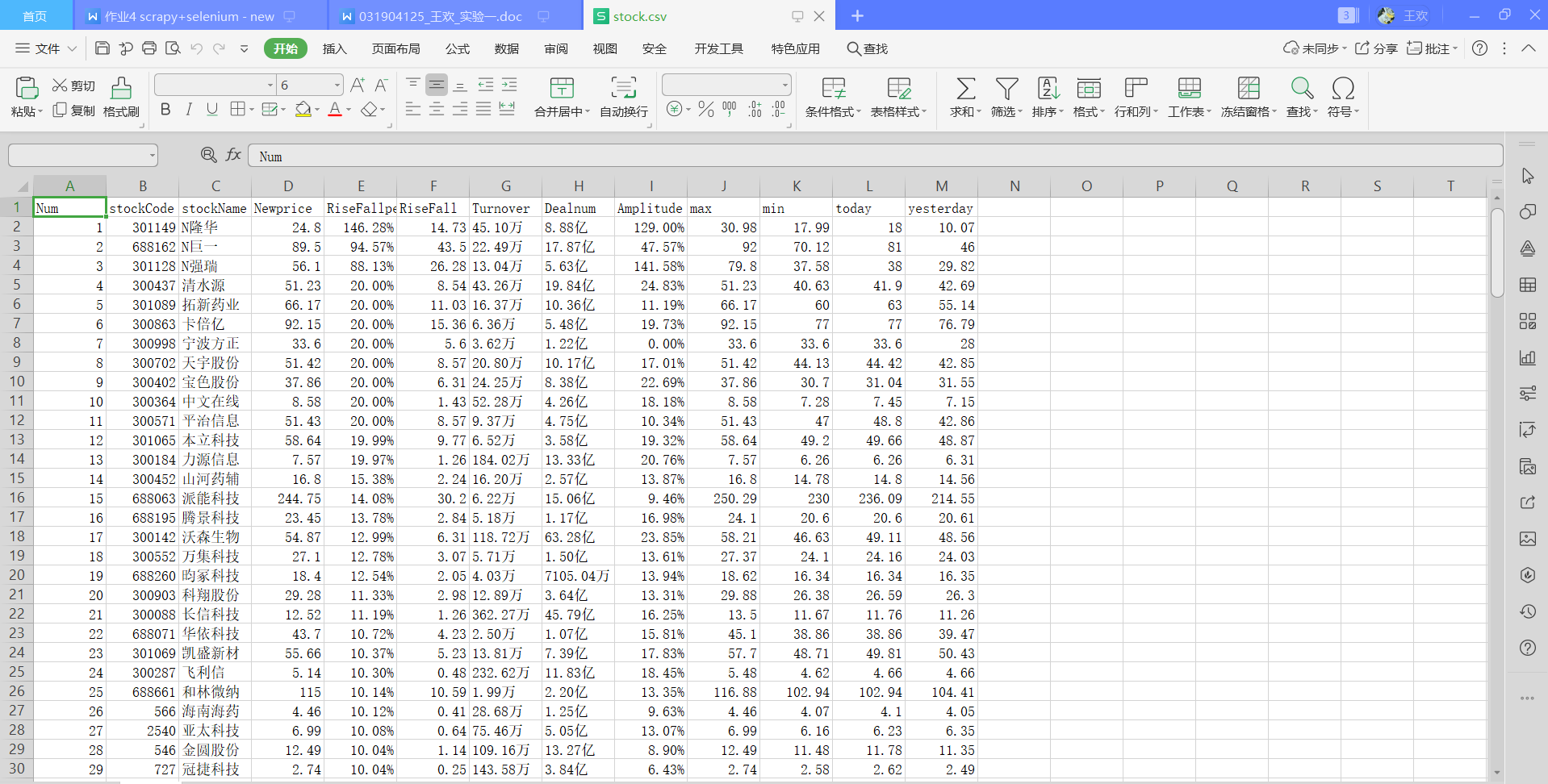
数据库导出csv文件查看如下:
实验心得:
这次实验,我熟悉了selenium的使用,加强了网页爬虫能力,和解决问题的能力,而且通过scrapy与selenium对于xpath使用的对比,对不同框架下的xpath使用有了更深的理解,同时也为下一次的实验奠定了一定的基础,在文章末尾附上这次实验的代码路径:数据采集与融合: 数据采集与融合实践作业 - Gitee.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号