


数据采集与融合第三次实践
作业①
要求:#
指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后3位)#
输出信息:#
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件夹中,并给出截图。
本人爬取的网站就是,实验中给出的实例网站 http://www.weather.com.cn,实现如下:
单线程:
1.1实验步骤
先准备函数gethtml(url), 功能是得到网页的html,这个对于所有爬取网页的爬虫都是有必要事先准备的:
def gethtml(url):
header = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
resp = requests.get(url,headers=header)
html = resp.text
return html
因为需要得到125张图片所以第一个网页中的图片肯定是不够的所以要从现有的网页中获取一些其他网页的链接,再从那些新的网页中去爬取新的图片,直到爬到125张图片
准备函数geturl(),获取网页中的新链接,因为本人不需要爬取太多图片,所以几个链接就足够125张图片
def geturls(page_link_list):
html = gethtml(page_link_list[0])
# 先获取第一张网页
soup = BeautifulSoup(html,'lxml')
links = soup.select('li > a')
flag = 1
for link in links:
link = link['href']
# 获取每一个链接
page_link_list.append(link)
if flag >= 5:
break
# 本人只爬了五个链接
flag += 1
因为我们要爬取的是网页中的图片,所以需要准备getimage(url)的一个函数去的得到网页中的图片,至于如何得到,本人用的是使用正则表达式如下:
images_list = re.findall(r'<img.*?src="(.*?)"',html,re.S|re.M)
具体getimage()函数内容如下:
num = 1
def getimage(html,i):
html = html.replace("\n","")
images_list = re.findall(r'<img.*?src="(.*?)"',html,re.S|re.M)
# 使用re获取图片链接
global num
for link in images_list:
if link != '' and link[0] == 'h':
# 因为我爬出来的有些图片链接为空值所以我将空链接的图片跳过
print(link)
imagename = './image/'+'第'+str(i)+'页'+'第'+str(num) + '张.jpg'
DownLoad(link,imagename)
# 下载图片
num += 1
if num == 126:
return False
对于爬取下来的图片我们还需要做的工作就是保存图片,所以再写一个简单的DownLoad()函数,实现图片保存,在这里我使用的是urlib.request.urlretrieve()这个方法可以很方便的对爬取的图片进行保存:
def DownLoad(link,imagename):
urllib.request.urlretrieve(link, imagename)
# 保存图片
写好所有的函数后,再写一个主函数去调用上面的函数,具体如何调用如下:
def main():
page_link_list = ['http://www.weather.com.cn/']
geturls(page_link_list)
# 获取多个网页链接
os.mkdir('./image')
print("开始爬取图片")
i = 1
for url in page_link_list:
print("第"+str(i)+"个url")
html = gethtml(url)
if(getimage(html,i) == False):
break
i += 1
print("爬取图片结束")
if __name__ == '__main__':
main()
1.2运行结果:
控制台结果,打印出所有图片url:
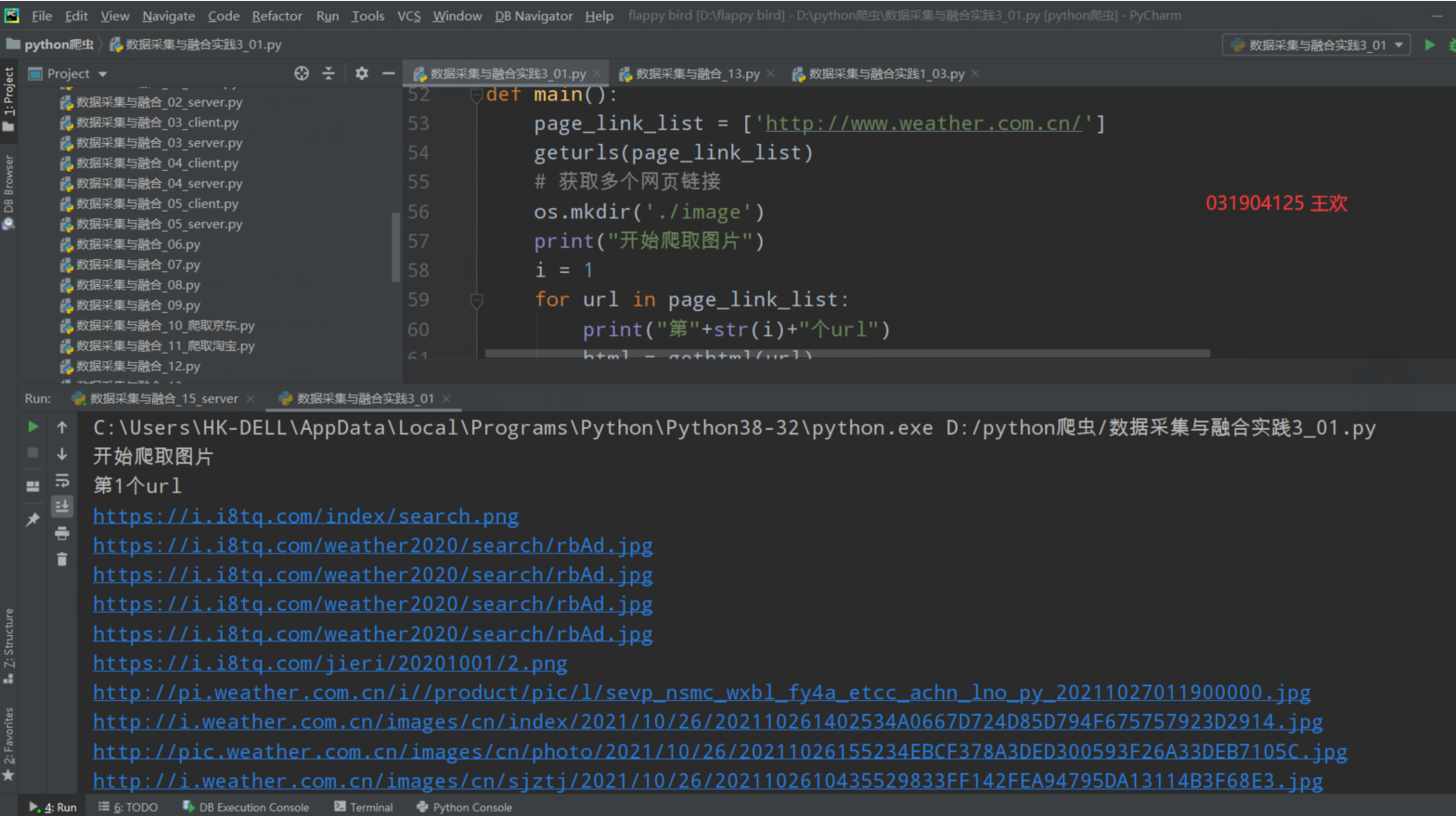
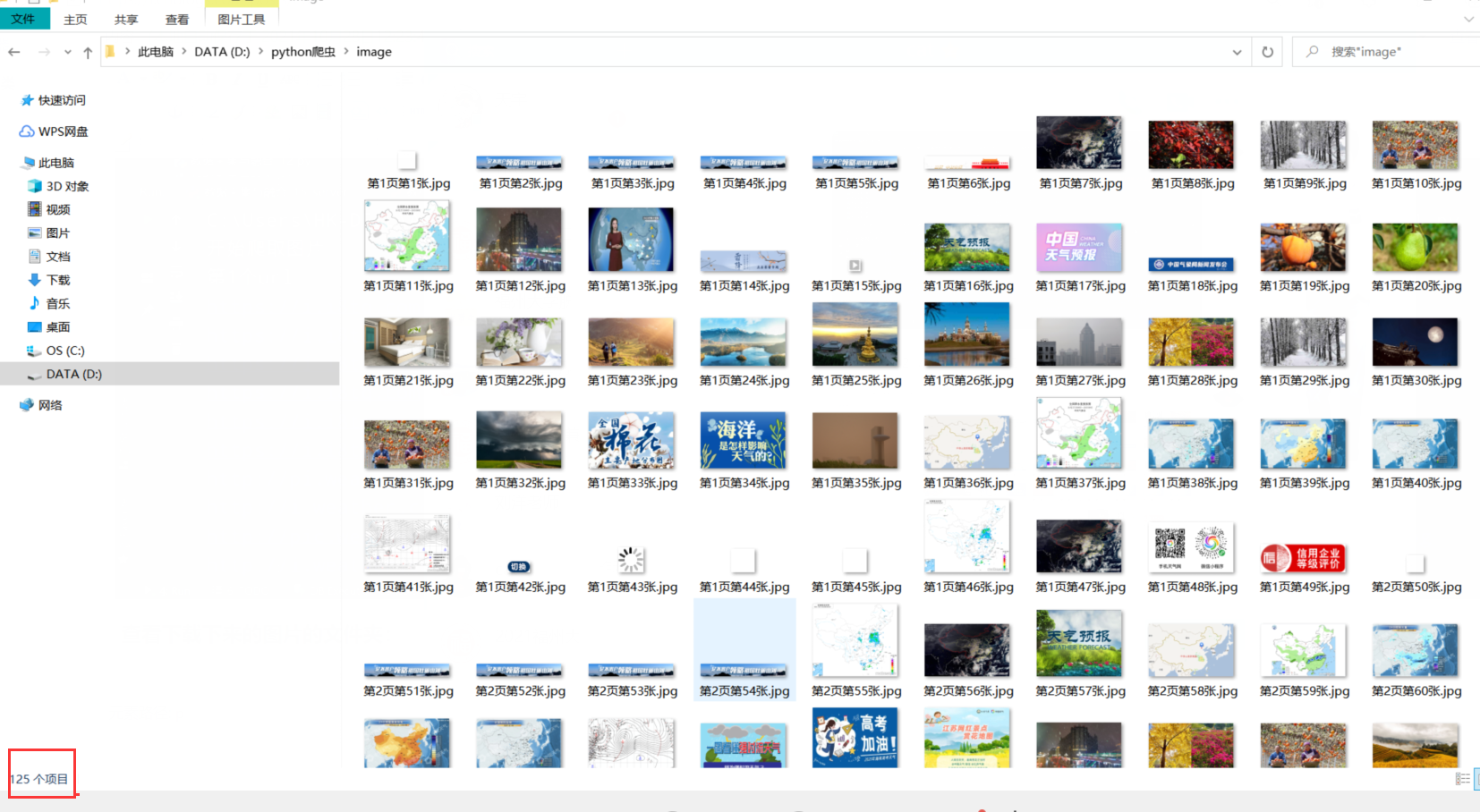
查看下载下来的图片的文件夹:
观察爬取下来的图片个数,发现刚好125张图片
多线程:
1.1实验步骤
这次实验作业一还要求我们使用多线程,我是参考课本中的实例,仅对getimage()函数进行了简单的修改,加入多线程,实现如下:
num = 1
def getimage(html,i):
html = html.replace("\n","")
images_list = re.findall(r'<img.*?src="(.*?)"',html,re.S|re.M)
# 使用re获取图片链接
global num
for link in images_list:
if link != '' and link[0] == 'h':
# 因为我爬出来的有些图片链接为空值所以我将空链接的图片跳过
print(link)
imagename = './image/'+'第'+str(i)+'页'+'第'+str(num) + '张.jpg'
"""多线程下载图片"""
T = threading.Thread(target=DownLoad,args=(link,imagename))
T.setDaemon(False)
T.start()
# 下载图片
num += 1
if num == 126:
return False
1.2运行结果
因为本人仅改动了getimage()这个函数,其余的函数都没什么改变,所以修改好后直接运行结果如下:
和单线程的结果有些类似,但是速度更快了
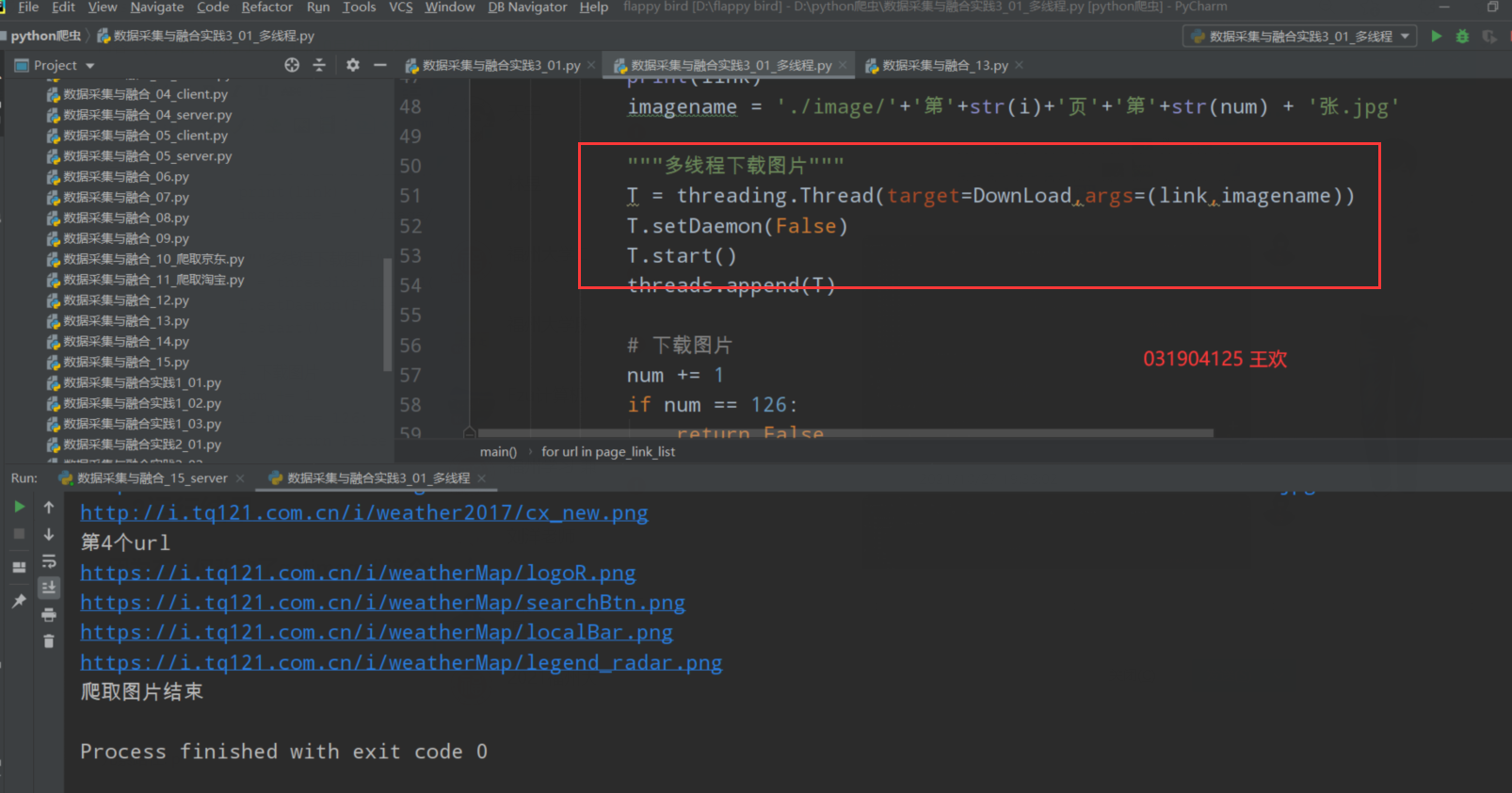
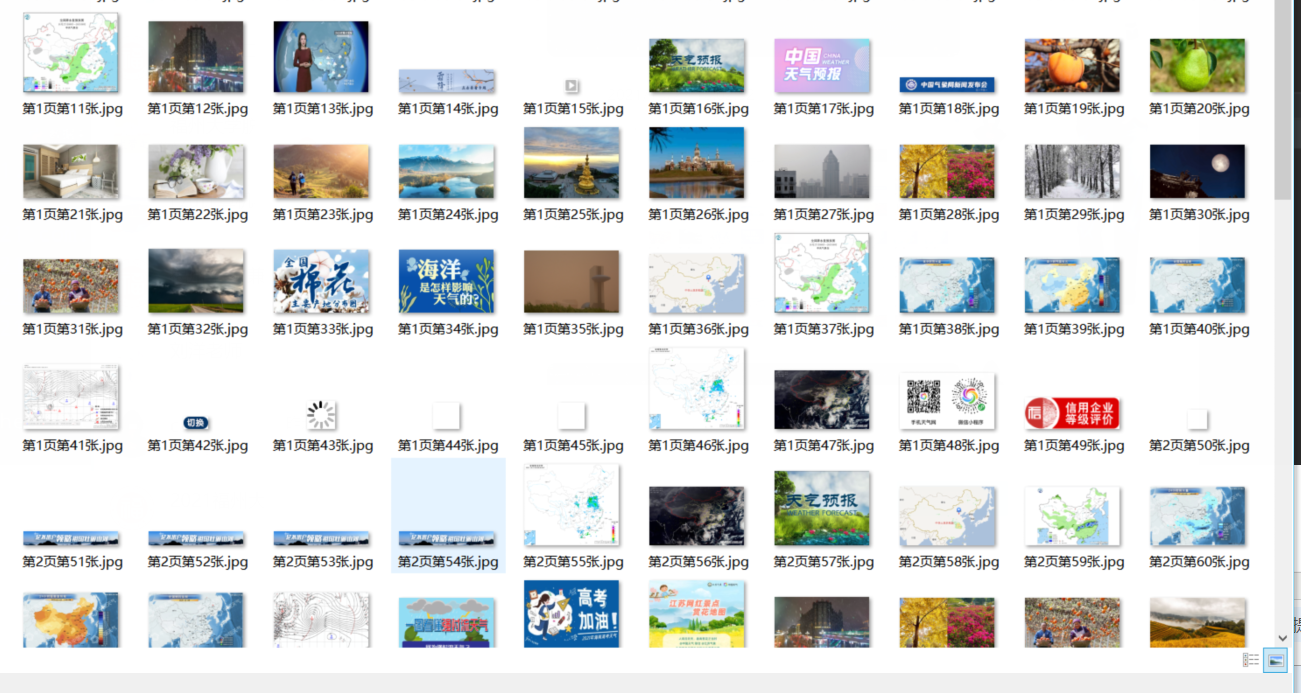
图片文件夹内容:
1.3实验心得
1.本次实验我学到了如何爬取多个不同网页的图片,同时复习了re正则表达式的使用获取元素内容
2.这次实验还复习了之前学过的多线程爬取,更加快速的实现图片的保存
3.这次实验为我后面的爬虫实验奠定了一定的基础
作业②
要求:#
使用scrapy框架复现作业①。#
输出信息:#
同作业①
1.1实验步骤
实验准备,先在文件夹下创建scrapy项目,指令如下:
scrapy startproject weather
进入刚才创建的weather项目文件,然后创建一个爬虫,指令如下:
scrapy genspider Weather www.weather.com.cn//
准备好scrapy项目后,先设置setting.py文件内容,本人仅修改了三个地方如下(仅供参考):
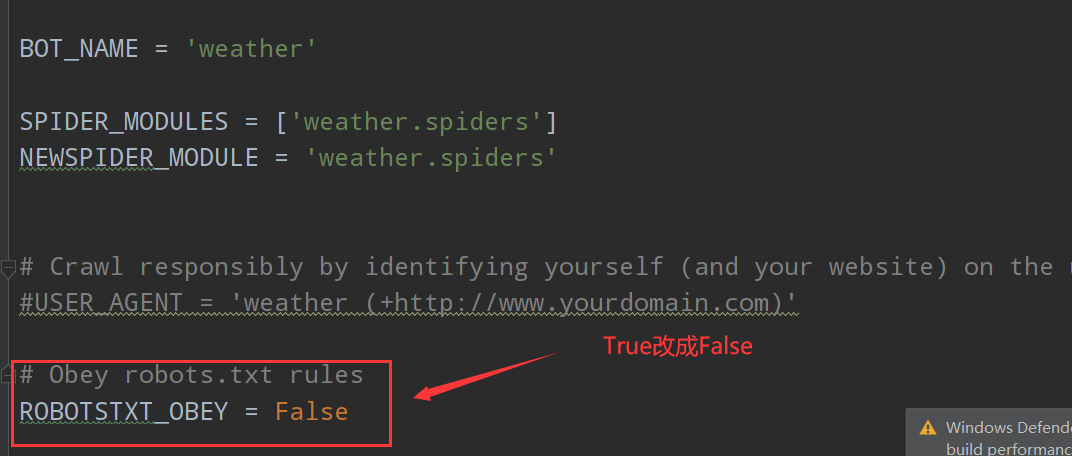


设置好setting.py后,接下来开始编写工作:
1.先编好item.py文件,因为我们需要爬取的只是图像,所以item.py中我只设置了一个内容
import scrapy
class WeatherItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_url = scrapy.Field()
# 图片链接
2.编写爬虫Weather.py程序,内容如下,我采用了再编写一个parse_for_page()的函数专门来处理每一个页面,但是实现要先删除或者注释掉
allowed_domains = ['http://www.weather.com.cn/']这一句允许的域名,把它变为不限制域名,否则scrapy.Request()中的callback=这个回调无法得到新的网
页的response
import scrapy
from scrapy项目.weather.weather.items import WeatherItem
class WeatherSpider(scrapy.Spider):
name = 'Weather'
# allowed_domains = ['http://www.weather.com.cn/']
# 注释掉允许的域名这个列表,可以使后面的callback不会受限
start_urls = 'http://www.weather.com.cn//'
def start_requests(self):
yield scrapy.Request(self.start_urls,callback=self.parse)
def parse_for_page(self, response):
item = WeatherItem()
item["image_url"] = response.xpath('//img//@src').extract()
# 获取图片
yield item
def parse(self, response):
try:
links = response.xpath('//a//@href').extract()
yield scrapy.Request(self.start_urls, callback=self.parse_for_page)
# 初始页面先处理
for link in links:
if link != 'javascript:void(0)':
# 观察我爬取到网页链接中出现”javascript:void(0)“将它去除
yield scrapy.Request(link,callback=self.parse_for_page)
# callback = parse_for_page专门处理网页
except Exception as err:
print(err)
3.编写pipline.py,将item中爬取的内容存储下来:
from itemadapter import ItemAdapter
import os
import urllib.request
flag = 1
class WeatherPipeline:
def process_item(self, item, spider):
global flag
for url in item["image_url"]:
if flag <= 125:
image_name = './image_02/'+'第'+str(flag)+'张.jpg'
print("成功下载第"+str(flag)+"张图片")
urllib.request.urlretrieve(url,image_name)
flag += 1
4.作完以上工作后,我们再编写一个run.py文件,运行我们的爬虫
内容如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl Weather -s LOG_ENABLED=False".split())
1.2运行结果
控制台运行结果:
查看图片文件夹如下:
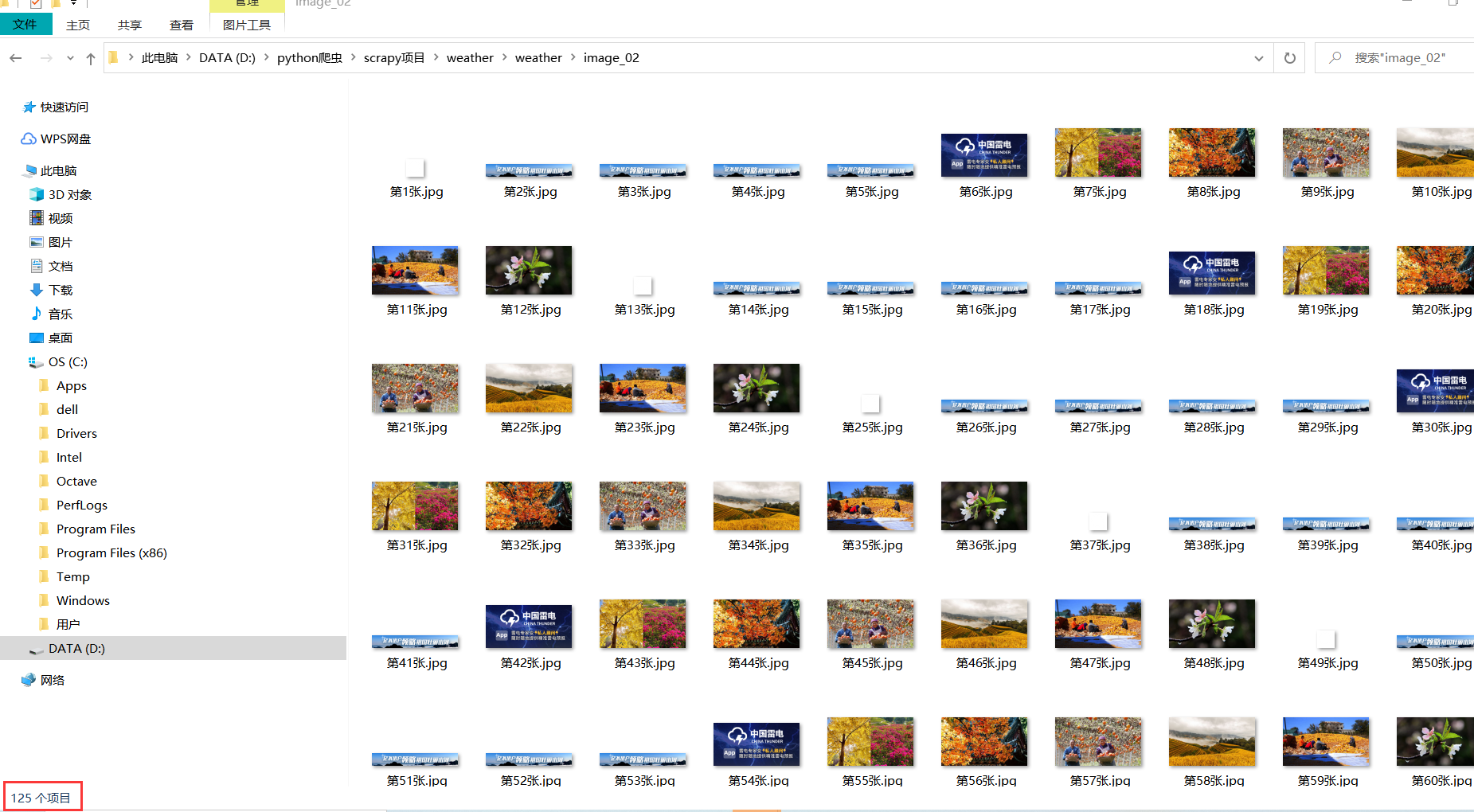
第一时间看到这个图片文件夹的时候我挺疑惑的,因为我出现了许多重复的图片,但是仔细想想,这个天气网站中的不少链接打开里面就会出现很多重复的图片,所以我后面也没去在意了
1.3实验心得
这次实验的第二题是使用scrapy对作业一的复现,核心内容还是获取图片进行保存,但重要的是使用框架改变,这次实验巩固了之前对scrapy爬虫框架的学习,加深了使用scrapy爬虫的爬虫经验,为后面的实验打下基础
作业③
要求:#
爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在imgs路径下。#
候选网站#
https://movie.douban.com/top250#
输出信息:
| 序号 | 电影名称 | 导演 | 演员 | 简介 | 电影评分 | 电影封面 |
|---|---|---|---|---|---|---|
| 1 | 肖申克的救赎 | 弗兰克·德拉邦特 | 蒂姆·罗宾斯 | 希望让人自由 | 9.7 | ./imgs/xsk.jpg |
| 2.... |
1.1实验步骤
实验前准备,和作业二一致,先创建一个movie的scrapy项目,然后再创建一个对应的爬虫,这个比较简单,我就不多解释了,指令如下
scrapy startproject movie
创建爬虫
scrapy genspider MovieSpider movie.douban.com/top250
然后也是先设置setting.py中的参数,这里我和作业二的设置完全一样就不做展示了,我们直接进入程序编写
1.编写item.py文件,内容如下:
import scrapy
class MovieItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field() # 电影名称
director = scrapy.Field() # 导演
actor = scrapy.Field() # 演员
state = scrapy.Field() # 简介
rank = scrapy.Field() # 电影评分
image_url = scrapy.Field() # 电影封面
2.编写MovieSpider.py文件,内容如下:
对于spider里面的代码我着重要说明的一点就是在获取电影导演和电影主演的部分,因为网页中导演和主演的内容是牵连在一起的如下:
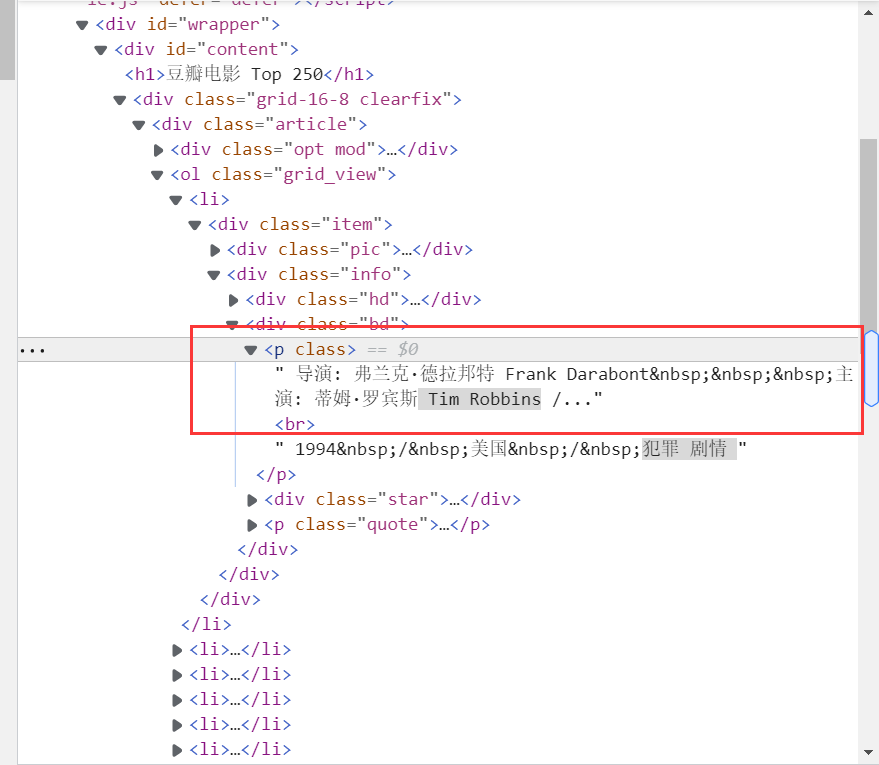
所以我们要如何获取导演和主演就成为一个难点,在这里我是使用re正则表达式findall()方法同时获取有导演和主演的列表,具体实现在代码中,唯一一个比较搞人心态的就是有一个叫做金夫妮的演员卡了我很久,所以我把它单独拿出来获取,因为我看作业的要求好像没有要求翻页,嘿嘿省了一点工作。
import scrapy
from scrapy项目.movie.movie.items import MovieItem
import re
class MoviespiderSpider(scrapy.Spider):
name = 'MovieSpider'
allowed_domains = ['https://movie.douban.com/top250']
start_urls = 'https://movie.douban.com/top250/'
def start_requests(self):
yield scrapy.Request(self.start_urls,callback=self.parse)
def parse(self, response):
# li_lists = response.xpath('//*[@id="content"]/div/div[1]/ol/li')
# for li in li_lists:
item = MovieItem()
item["name"] = response.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()').extract()
directors_actors = response.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/p[1]/text()[1]').extract()
directors = []
actors = []
for list in directors_actors:
list = list.replace("\n","")
# 去除换行符
name_list = re.findall(r"(?<=:).*?(?= )",list)
# 这个name_list中包含有导演名字还有演员名字
directors.append(name_list[1])
if len(name_list) != 4:
# 因为html文本中有一行内容如下: 导演: 拜伦·霍华德 Byron Howard / 瑞奇·摩尔 Rich Moore 主演: 金妮弗·...
# 这个主演金夫妮我用前面的re正则无法取出,所以只好单独来取
name_list = re.findall(r"(?<=:).*?(?=·)",list)
actors.append(name_list[1])
else:
actors.append(name_list[3])
item["director"] = directors # 导演
item["actor"] = actors # 演员
item["state"] = response.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/p[2]/span/text()').extract()
item["rank"] = response.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()').extract()
item["image_url"] = response.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[1]/a/img/@src').extract()
yield item
3.编写pipline.py把item内容打印,并存入数据库,同时将图片下载保存下来
打印内容比较简单,所以我介绍一下存入数据库实现,这个和之前做过的一个实验很像,我还是像之前一样编写一个DB类,具体内容包括,创建,插入,打开,关闭,实现如下:
class movieDB:
def openDB(self):
self.con = sqlite3.connect("movie.db") # 连接数据库,没有的话会注定创建一个
self.cursor = self.con.cursor() # 设置一个游标
try:
self.cursor.execute("create table movies(rank varchar(10),name varchar(10),director varchar(10),actor varchar(10),state varchar(20),score varchar(10),surface varchar(50))")
# 创建电影表
except:
self.cursor.execute("delete from movies")
def closeDB(self):
self.con.commit() # 自杀
self.con.close() # 关闭数据库
def insert(self,Rank,Name,Director,Actor,State,Score,Surface):
try:
self.cursor.execute("insert into movies(rank,name,director,actor,state,score,surface) values (?,?,?,?,?,?,?)", (Rank, Name, Director, Actor, State, Score, Surface))
# 插入数据
except Exception as err:
print(err)
pipline.py剩下的内容就是打印和保存图片,实现如下:
class MoviePipeline:
def process_item(self, item, spider):
print("序号\t\t电影名称\t\t导演\t\t演员\t\t简介\t\t评分\t\t电影封面")
movie_names = item["name"]
directors = item["director"]
actors = item["actor"]
states = item["state"]
scores = item["rank"]
image_urls = item["image_url"]
os.mkdir("./img/") # 创建一个img存放图片
moviedb = movieDB() # 创建数据库对象
moviedb.openDB() # 打开数据库
for i in range(len(movie_names)):
print(str(i+1)+"\t"+movie_names[i]+"\t"+directors[i]+"\t"+actors[i]+"\t"+states[i]+"\t"+scores[i]+"\t\t"+image_urls[i])
moviedb.insert(i+1,movie_names[i],directors[i],actors[i],states[i],scores[i],image_urls[i])
urllib.request.urlretrieve(image_urls[i],"./img/"+movie_names[i]+".jpg")
print("成功存入数据库")
moviedb.closeDB() # 关闭数据库
4.做完以上工作之后编写一个run.py文件去运行爬虫:
from scrapy import cmdline
cmdline.execute("scrapy crawl MovieSpider".split())
1.2运行结果
控制台内容:
有一点一点偷懒的地方就是打印对齐问题,我直接用\t把内容分隔,所以打印的内容会有点乱,但是总归是爬下来了
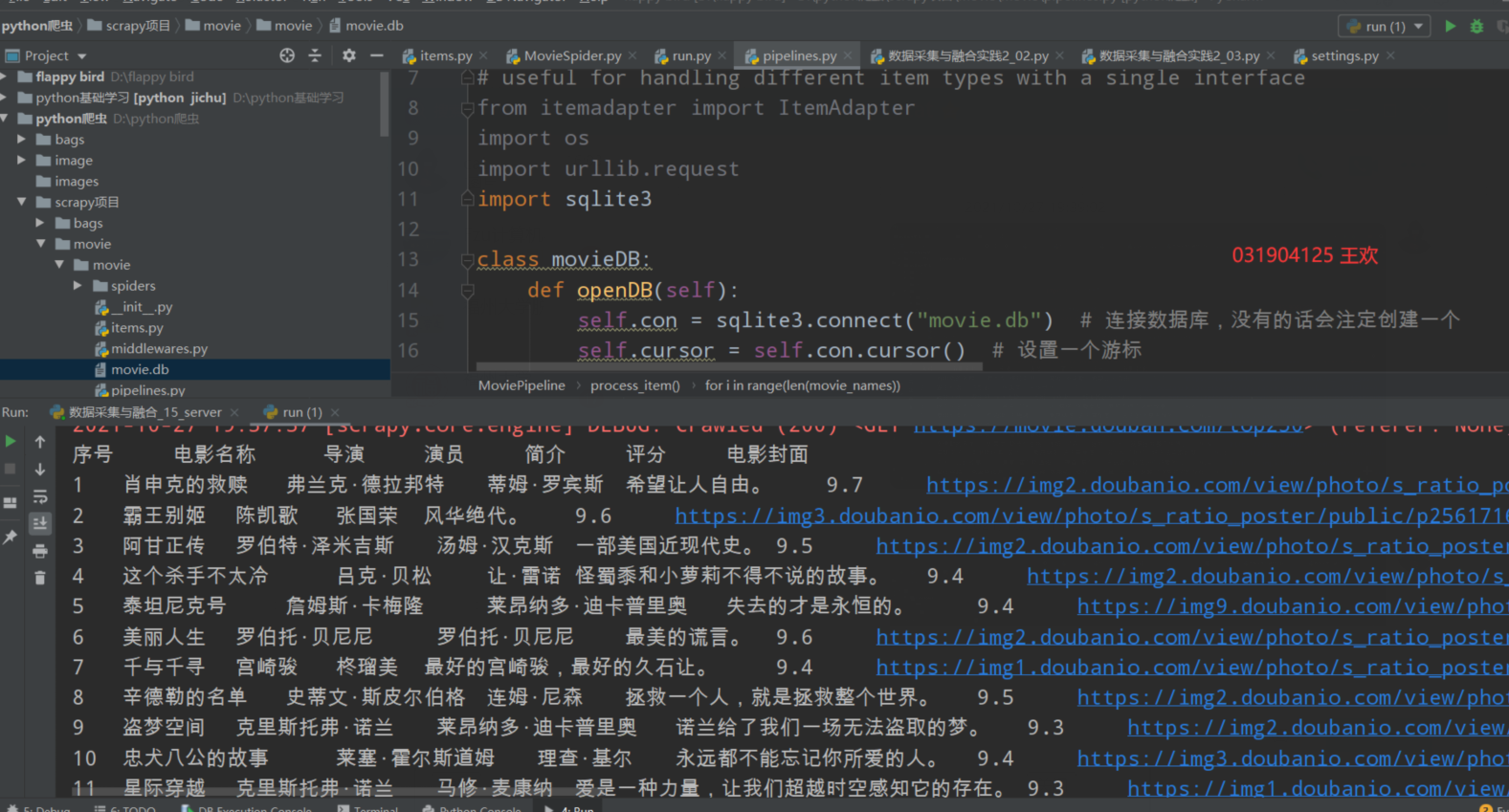
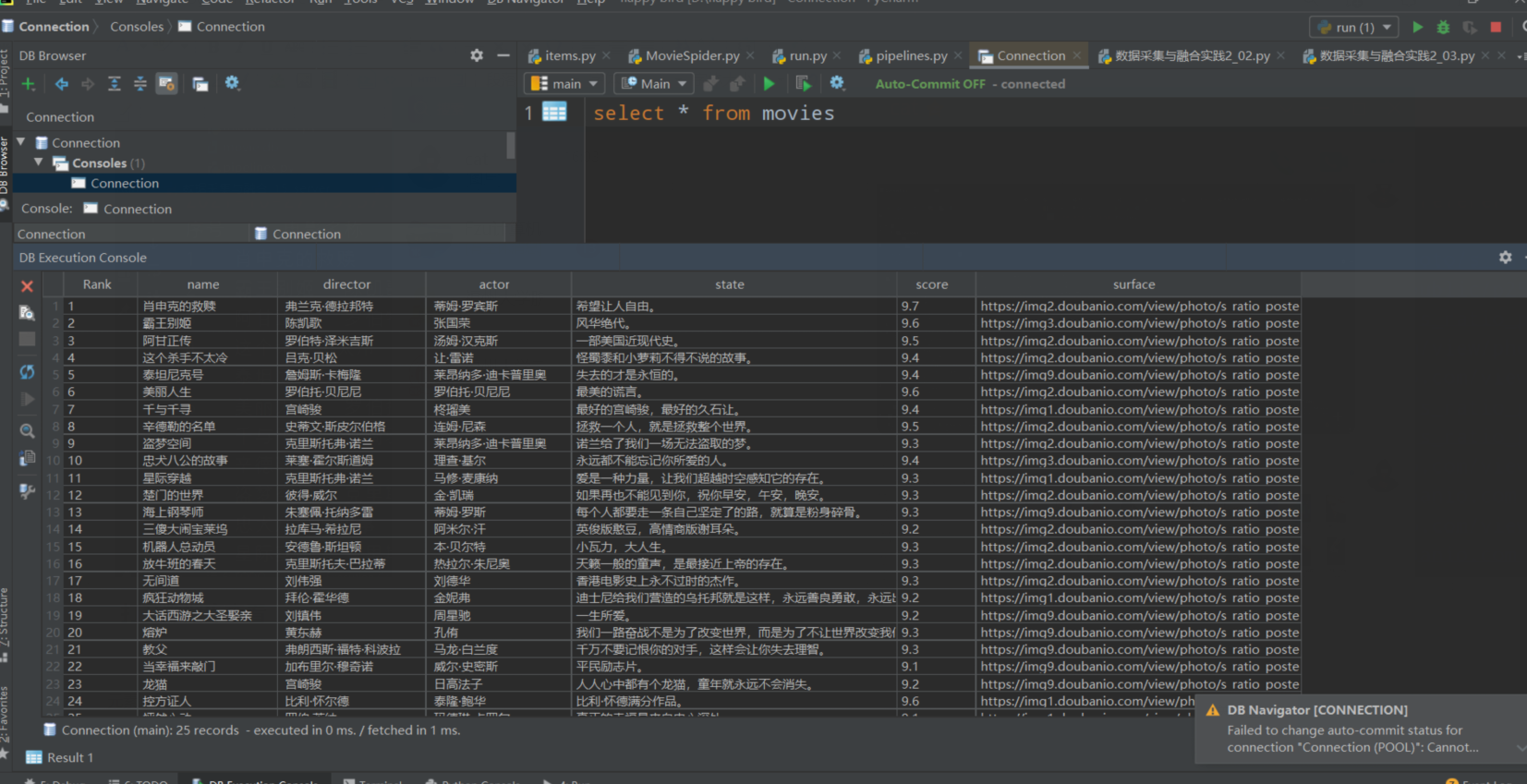
打开数据库查看
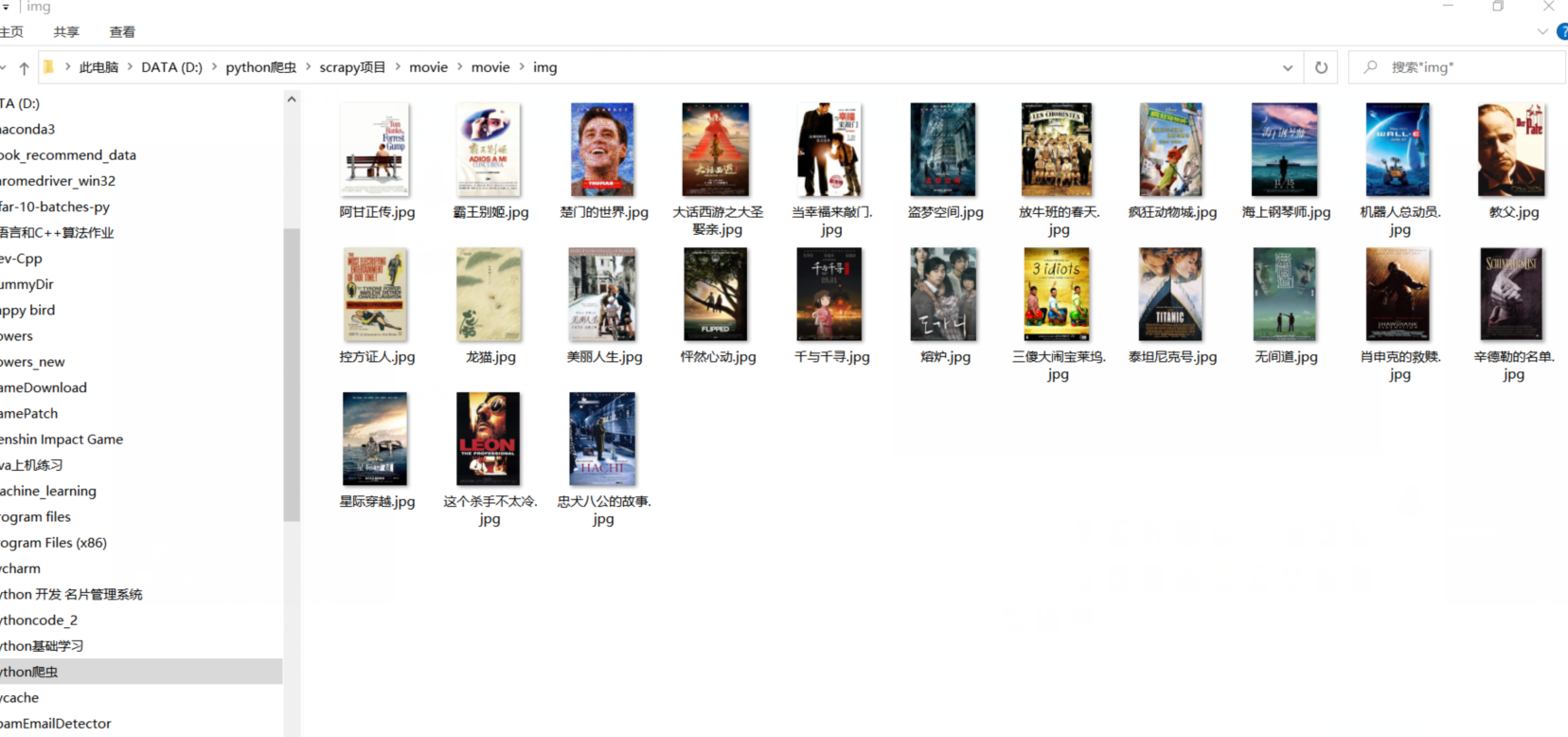
再打开img图片文件夹内容:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号