


【数据采集与融合】第一次实验
一、作业一
-
要求:使用用
urllib和re库方法定向爬取给定网址中国最好学科排名(计算机科学与技术)的数据。 -
输出形式:
| 2020排名 | 全部层次 | 学校类型 | 总分 |
|---|---|---|---|
| 1 | 前2% | 中国人民大学 | 1069.0 |
| 2 | .... | ........... | ...... |
作业一实现如下:
1.1 使用urllib.request.urlopen获取网页html
因为这里我贴上的是部分代码,主代码中使用urllib爬取必须加上try异常处理语句
url = 'https://www.shanghairanking.cn/rankings/bcsr/2020/0812' resp = urllib.request.urlopen(url) html = resp.read().decode() html = html.replace("\n", "") # 获取html,需要提前删除换行符,不然会影响后面的正则爬取
1.2 通过re正则表达式直接寻找我们想要爬取的内容,比如学校排名,学校名称......
name_list = re.findall(r'class="name-cn" data-v-b80b4d60>(.*?)</a>',html,re.M|re.S) # 获取学校名称列表
rank = re.findall(r'class="ranking" data-v-68e330ae>(.*?)</div>',html,re.M|re.S)
for i in range(len(rank)): rank[i] = rank[i].replace(" ","") # 获取学校排名列表,由于rank中的元素带有多个空格,所以对爬到的数据去除空格 tr_list = re.findall("<td data-v-68e330ae>(.*?)</td></tr>", html) level_score = [] for list in tr_list: level_score.append(re.findall("<td data-v-68e330ae> (.*?) ", list)) # 获取学校层次以及分数排名
1.3 将爬取到的数据打印出来
s = "{0:^10}\t{1:{4}^10}\t{2:{4}^10}\t{3:^10}" print(s.format("学校排名","学校层次","学校名称","总分",chr(12288))) for i in range(len(tr_list)): l_s = level_score[i] print(s.format(rank[i],l_s[0],name_list[i],l_s[1],chr(12288)))
1.4 结果如下
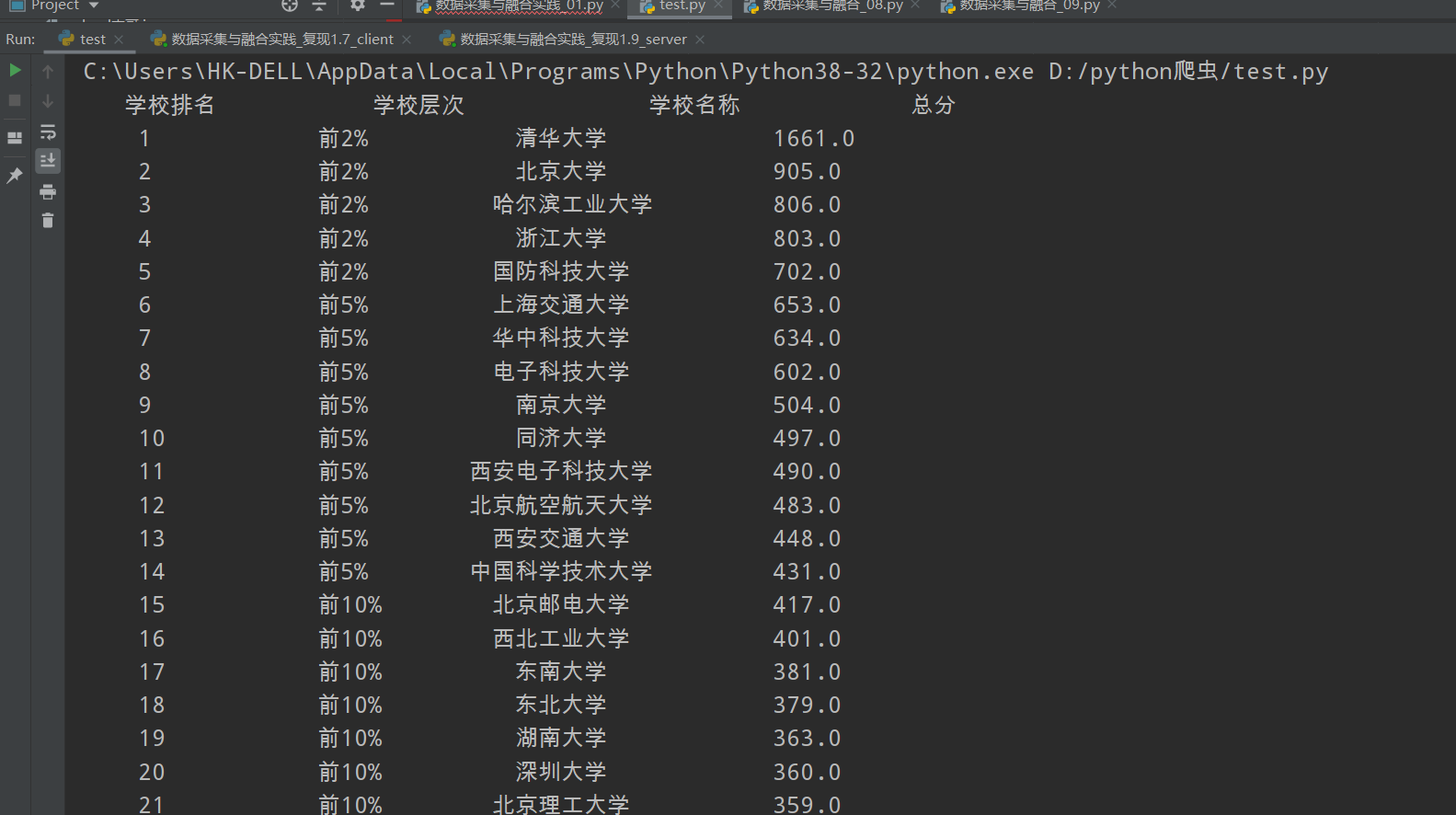
1.5 全代码如下
import urllib.request import urllib.parse import re try: url = 'https://www.shanghairanking.cn/rankings/bcsr/2020/0812' resp = urllib.request.urlopen(url) html = resp.read().decode() html = html.replace("\n", "") # 获取html,需要提前删除换行符,不然会影响后面的正则爬取 name_list = re.findall(r'class="name-cn" data-v-b80b4d60>(.*?)</a>',html,re.M|re.S) # 获取学校名称列表 rank = re.findall(r'class="ranking" data-v-68e330ae>(.*?)</div>',html,re.M|re.S) for i in range(len(rank)): rank[i] = rank[i].replace(" ","") # 获取学校排名列表,由于rank中的元素带有多个空格,所以对爬到的数据去除空格 tr_list = re.findall("<td data-v-68e330ae>(.*?)</td></tr>", html) level_score = [] for list in tr_list: level_score.append(re.findall("<td data-v-68e330ae> (.*?) ", list)) # 获取学校层次以及分数排名 s = "{0:^10}\t{1:{4}^10}\t{2:{4}^10}\t{3:^10}" print(s.format("学校排名","学校层次","学校名称","总分",chr(12288))) for i in range(len(tr_list)): l_s = level_score[i] print(s.format(rank[i],l_s[0],name_list[i],l_s[1],chr(12288))) except Exception as err: print(err)
1.6 心的体会
在学习正则表达式的时候卡壳了,起初我使用re.findall(r'<tr>(.*?)<\tr>',html)不知道为啥一直爬不出来,后来经过询问同学才知道是忽略了考虑空格和换行符的问题,修改语法tr_list = re.findall("<td data-v-68e330ae>(.*?)</td></tr>", html)就可以运行了,解决了卡壳,还是需要多多练习编写正则表达式,自身水平还有待提高
二、作业二
-
要求:用
requests和Beautiful Soup库方法设计爬取数据服务AQI实时报。 -
输出形式
序号 |
城市 |
AQI |
PM2.5 |
SO2 |
NO2 |
CO |
首要污染物 |
|---|---|---|---|---|---|---|---|
1 |
北京 |
55 |
6 |
5 |
1.0 |
225 |
- |
2 |
.... |
.... |
.... |
.... |
.... |
.... |
.... |
作业二实现如下:
2.1 使用request.get获取html
def Gethtml(url): try: header = { "User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"} resp = requests.get(url,headers=header) resp.raise_for_status() resp.encoding = resp.apparent_encoding html = resp.text return html except Exception as err: print(err)
2.2使用BeautifulSoup煲一锅美味汤,使用find函数获取信息
def FillCitylist(cities,html): soup = BeautifulSoup(html,'lxml') i = 1 for tr_list in soup.select("tbody > tr"): td_list = tr_list.find_all('td') city_name = td_list[0].text.strip() if city_name == "北京市" and i != 1: break # 我发现它爬取过程会循环回到北京市,所以我设置一个if来判断 AQI = td_list[1].text.strip() # 获取AQI PM2_5 = td_list[2].text.strip() # 获取PM2.5 SO2 = td_list[4].text.strip() # 获取SO2 NO2 = td_list[5].text.strip() # 获取NO2 CO = td_list[6].text.strip() # 获取CO FIRST = td_list[8].text.strip() # 首要污染物 cities.append([i,city_name,AQI,PM2_5,SO2,NO2,CO,FIRST]) i += 1
2.3 打印数据
def PrintCityAQI(cities): s = "{0:^10}\t{1:^10}\t{2:^10}\t{3:^10}\t{4:^10}\t{5:^10}\t{6:^10}\t{7:^10}" print(s.format("序号","城市","AQI","PM2.5","SO2","NO2","CO","首要污染物")) for i in range(len(cities)): city = cities[i] print(s.format(city[0],city[1],city[2],city[3],city[4],city[5],city[6],city[7]))
2.4 输出结果如下
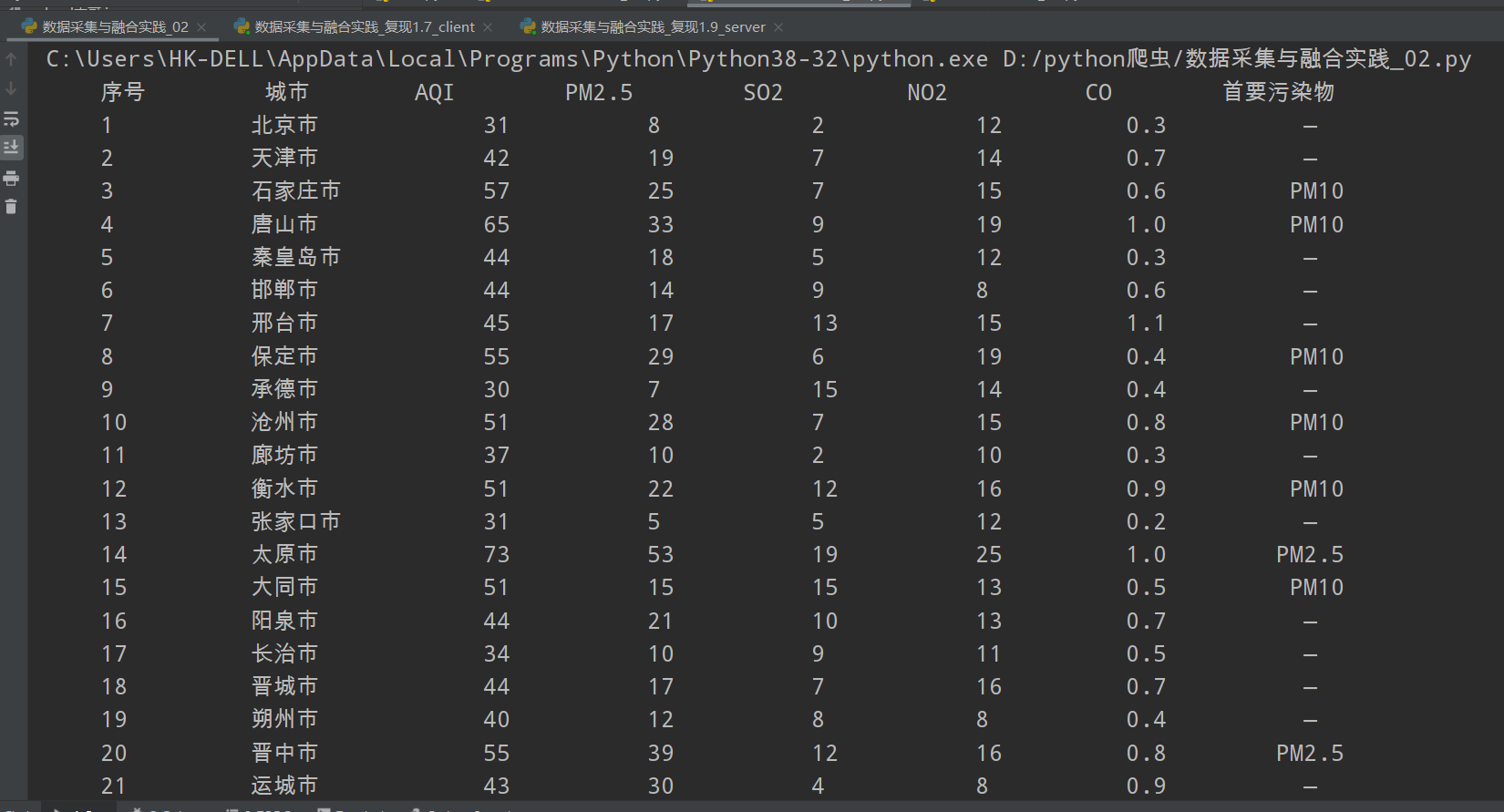
2.5全代码如下
import requests from bs4 import BeautifulSoup def Gethtml(url): try: header = { "User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"} resp = requests.get(url,headers=header) resp.raise_for_status() resp.encoding = resp.apparent_encoding html = resp.text return html except Exception as err: print(err) def FillCitylist(cities,html): soup = BeautifulSoup(html,'lxml') i = 1 for tr_list in soup.select("tbody > tr"): td_list = tr_list.find_all('td') city_name = td_list[0].text.strip() if city_name == "北京市" and i != 1: break # 我发现它爬取过程会循环回到北京市,所以我设置一个if来判断 AQI = td_list[1].text.strip() # 获取AQI PM2_5 = td_list[2].text.strip() # 获取PM2.5 SO2 = td_list[4].text.strip() # 获取SO2 NO2 = td_list[5].text.strip() # 获取NO2 CO = td_list[6].text.strip() # 获取CO FIRST = td_list[8].text.strip() # 首要污染物 cities.append([i,city_name,AQI,PM2_5,SO2,NO2,CO,FIRST]) i += 1 def PrintCityAQI(cities): s = "{0:^10}\t{1:^10}\t{2:^10}\t{3:^10}\t{4:^10}\t{5:^10}\t{6:^10}\t{7:^10}" print(s.format("序号","城市","AQI","PM2.5","SO2","NO2","CO","首要污染物")) for i in range(len(cities)): city = cities[i] print(s.format(city[0],city[1],city[2],city[3],city[4],city[5],city[6],city[7])) def main(): url = 'https://datacenter.mee.gov.cn/aqiweb2/' cities = [] html = Gethtml(url) FillCitylist(cities,html) PrintCityAQI(cities) if __name__ == '__main__': main()
2.6 心得体会
这一次的作业中让我又一次复习了一遍BeautifulSoup库的相关内容,收益颇多,在进行实验的过程中出现了一次索引越界的问题,后来用pycharm的bug查找发现在爬取过程中不断找错,发现问题所在。这一次的作业和之前的爬取大学排名的一次作业有点类似都是使用BeautifulSoup来获取信息,所以实现起来没那么困难,可以独立完成
三、作业三
-
要求:使用
urllib和requests及re爬取一个给定网页福州大学新闻网下的所有图片 -
输出形式:将自选网页内的所有jpg文件保存在一个文件夹中
作业三实现如下:
3.1 获取网页的源代码
header = { "User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"} resp = requests.get(url,headers=header) resp.raise_for_status() resp.encoding = resp.apparent_encoding html = resp.text.replace("\n","") # 获取html
3.2 使用正则表达式获取图片的url
ImageList = re.findall(r'<img.*?src="(.*?)"',html,re.S|re.M)
3.3 使用os创建一个FZU文件夹用来存放图片
os.makedirs('./FZU/')
3.4 遍历列表,使用urllib.request.urlretrieve()保存图片
i = 1 for image in ImageList: imageurl = "http://news.fzu.edu.cn" + image # 获取图片的url imagename = "./FZU/"+ "第" + str(i) + "张.jpg" # 创建图片的路径 urllib.request.urlretrieve(imageurl,imagename) print("成功加载第%d张图片" % i) # 保存图片 i += 1
3.5 结果如下:
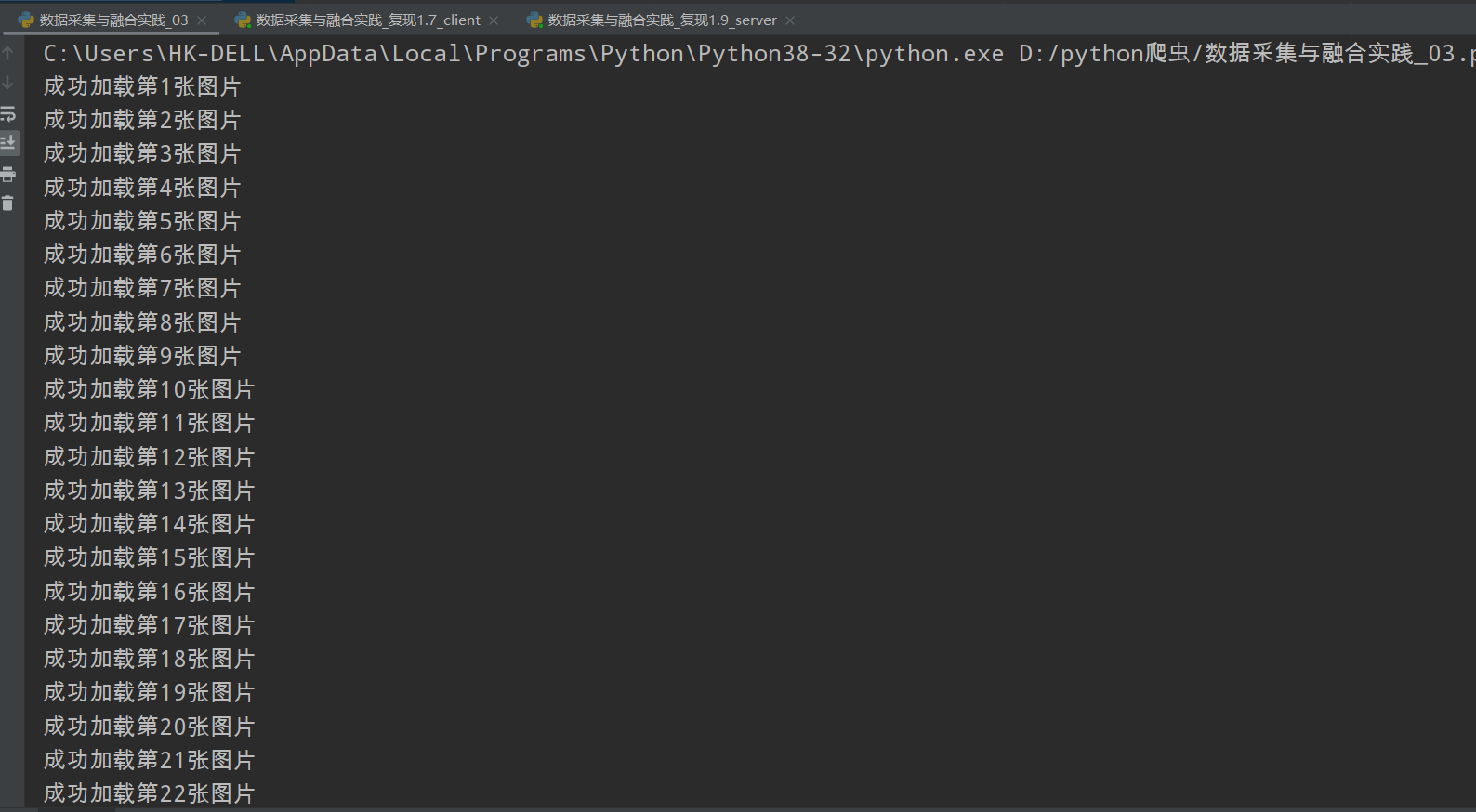
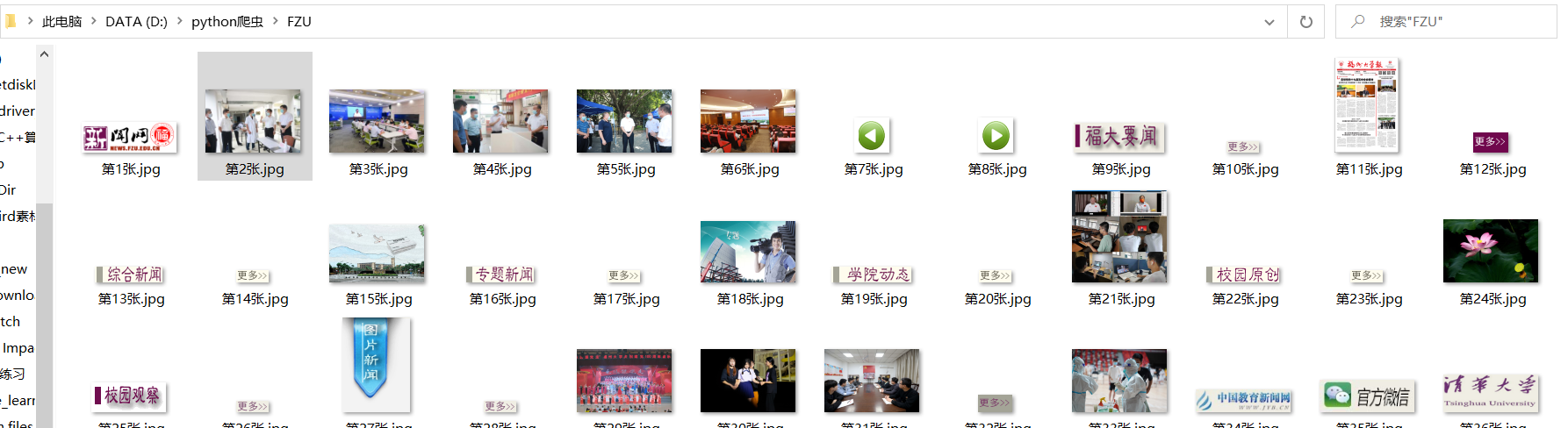
3.6 全代码如下
import requests import re import urllib.request import os from bs4 import BeautifulSoup def getphoto(url): header = { "User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"} resp = requests.get(url,headers=header) resp.raise_for_status() resp.encoding = resp.apparent_encoding html = resp.text.replace("\n","") # 获取html ImageList = re.findall(r'<img.*?src="(.*?)"',html,re.S|re.M) os.makedirs('./FZU/') i = 1 for image in ImageList: imageurl = "http://news.fzu.edu.cn" + image # 获取图片的url imagename = "./FZU/"+ "第" + str(i) + "张.jpg" # 创建图片的路径 urllib.request.urlretrieve(imageurl,imagename) print("成功加载第%d张图片" % i) # 保存图片 i += 1 url = 'http://news.fzu.edu.cn/' getphoto(url)
3.7 心得体会
这次实验让我巩固了正,则表达式的使用,又让我学会了使用urllib.request.urlresive()方法来直接保存图片到相应的路径,有用的小技巧有增加啦!为我下一次的实验打下良好的基础,最后附上我的Gitee码云仓库链接,代码地址:第一次实践作业 · 王欢/数据采集与融合 - 码云 - 开源中国 (gitee.com)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号