

二、redis为什么那么快?
1.redis 到底有多块
Redis采用的是基于内存的采用的是单进程单线程模型的 KV 数据库,由C语言编写,官方提供的数据是可以达到100000+的QPS(每秒内查询次数)。这个数据不比采用单进程多线程的同样基于内存的 KV 数据库 Memcached 差!
2.redis 性能测试
1〉主要观点:
a.可以使用redis-benchmark对Redis的性能进行评估,命令行提供了普通/流水线方式、不同压力评估特定命令的性能的功能。
b.redis性能卓越,作为key-value系统最大负载数量级为10W/s, set和get耗时数量级为10ms和5ms。使用流水线的方式可以提升redis操作的性能。
2〉测试工具
Redis包含的redis-benchmark实用程序可模拟N个客户端同时发送M个总查询的运行命
测试结果,我也不知道为什么这么低,后面找时间再研究
非流水线:
D:\Program Files\redis\redis3.2>redis-benchmark -r 1000000 -n 2000000 -t get,set,lpush,lpop -q SET: 2797.27 requests per second GET: 2647.28 requests per second LPUSH: 2577.08 requests per second LPOP: 2961.03 requests per second
流水线:
D:\Program Files\redis\redis3.2>redis-benchmark -r 1000000 -n 2000000 -t get,set,lpush,lpop -q -P 16 SET: 45220.22 requests per second GET: 48659.43 requests per second LPUSH: 46605.93 requests per second LPOP: 46154.20 requests per second
修改-P 的参数后
D:\Program Files\redis\redis3.2>redis-benchmark -r 1000000 -n 2000000 -t get,set,lpush,lpop -q -P 100 SET: 223363.84 requests per second GET: 235710.09 requests per second LPUSH: 257765.19 requests per second LPOP: 242483.02 requests per second
3.redis 为什么那么快
1〉基于内存操作
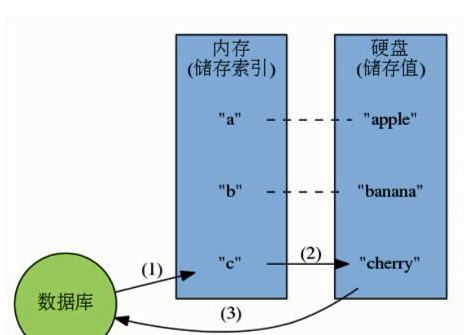
1)硬盘数据库的工作模式:
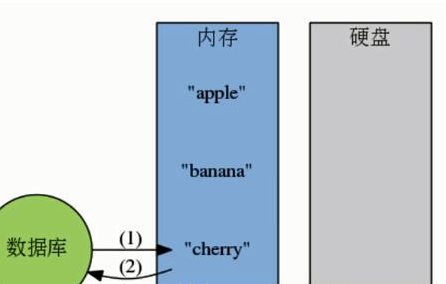
(2)内存数据库的工作模式:
2〉单线程:
Redis使用单个线程处理请求,避免了多个线程之间线程切换和锁资源争用的开销
3〉优化的数据结构:
Redis有诸多可以直接应用的优化数据结构的实现,应用层可以直接使用原生的数据结构提升性能
4〉非阻塞IO:
Redis使用多路复用IO技术
select机制
基本原理:select 函数监视的文件描述符分3类,分别是writefds、readfds、和exceptfds。调用后select函数会阻塞,直到有描述符就绪(有数据 可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。当select函数返回后,可以通过遍历fdset,来找到就绪的描述符。
缺点:每次调用select,都需要把fd_set集合从用户态拷贝到内核态,如果fd_set集合很大时,那这个开销也很大;同时每次调用select都需要在内核遍历传递进来的所有fd_set,如果fd_set集合很大时,那这个开销也很大;为了减少数据拷贝带来的性能损坏,内核对被监控的fd_set集合大小做了限制,并且这个是通过宏控制的,大小不可改变(限制为1024)
poll机制
poll的机制与select类似,管理多个描述符也是进行轮询,根据描述符的状态进行处理
但是poll没有最大文件描述符数量的限制,poll改变了文件描述符集合的描述方式,使用了pollfd结构而不是select的fd_set结构,使得poll支持的文件描述符集合限制远大于select的1024
epoll机制
基本原理:epoll支持水平触发和边缘触发,最大的特点在于边缘触发,它只告诉进程哪些fd刚刚变为就绪态,并且只会通知一次。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。
优点:1、epoll没有描述符个数限制,使用一个文件描述符管理多个描述符,将用户关心的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。2、是Linux下多路复用IO接口select/poll的增强版本,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率,原因就是获取事件的时候,它无须遍历整个被侦听的描述符集,只要遍历那些被内核IO事件异步唤醒而加入Ready队列的描述符集合就行了。
因为Redis 为每个 I/O 多路复用函数库都实现了相同的API,所以I/O多路复用程序的底层实现是可以互换的。
Redis 在 I/O 多路复用程序的实现源码中用 #include 宏定义了相应的规则,程序会在编译时自动选择系统中性能最高的 I/O 多路复用函数库来作为 Redis 的 I/O 多路复用程序的底层实现(ae.c文件):
/* Include the best multiplexing layer supported by this system.
* The following should be ordered by performances, descending. */
#ifdef HAVE_EVPORT
#include "ae_evport.c"
#else
#ifdef HAVE_EPOLL
#include "ae_epoll.c"
#else
#ifdef HAVE_KQUEUE
#include "ae_kqueue.c"
#else
#include "ae_select.c"
#endif
#endif
#endif

 浙公网安备 33010602011771号
浙公网安备 33010602011771号