RabbitMQ和Elasticsearch的使用笔记
RabbitMQ介绍
微服务间通讯有同步和异步两种方式:
异步通讯:就像发邮件,不需要马上回复(RabbitMQ)。
RabbitMQ中的一些角色:
-
publisher:生产者
-
consumer:消费者
-
exchange个:交换机,负责消息路由
-
queue:队列,存储消息
-
virtualHost:虚拟主机,隔离不同租户的exchange、queue、消息的隔离
RabbitMQ安装(基于Docker)
从docker仓库拉去
docker pull rabbitmq:3-management
安装
docker run \ -e RABBITMQ_DEFAULT_USER=itcast \ -e RABBITMQ_DEFAULT_PASS=123321 \ --name mq \ --hostname mq1 \ -p 15672:15672 \ -p 5672:5672 \ -d \ rabbitmq:3-management
这里第二行是设置登录管理界面的用户名,第三行是密码,第四行是容器名字,第五行是主机名称,第六行是管理界面所需要暴露的端口,第七行是RabbitMQ进程端口。
Elasticsearch 使用一种称为 倒排索引 的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
elasticsearch是面向文档(Document)存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中,
和MYSQL对比:
docker network create es-net
kibana拉取
docker pull kibana:7.12.1
安装
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
第三行是kibana的地址,es是上面创建的网络,来确保两个在同一网络环境
es拉取
docker pull elasticsearch:7.12.1
es安装
docker run -d \ --name es \ -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \ -e "discovery.type=single-node" \ -v es-data:/usr/share/elasticsearch/data \ -v es-plugins:/usr/share/elasticsearch/plugins \ --privileged \ --network es-net \ -p 9200:9200 \ -p 9300:9300 \ elasticsearch:7.12.1
第三行是指定es的运行内存大小,可根据自己的机器修改,第四行是指定为非集群模式,五六行是挂在数据卷的位置。
RabbitMQ使用
通过SpringAMQP是基于RabbitMQ封装的一套模板,并且还利用SpringBoot对其实现了自动装配。
导入SpringAMQP依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
rabbitMQ---yml配置
spring:
rabbitmq:
host: 你的服务器ip地址
port: 5672
username: 配置时设置的用户名
password: 密码
virtual-host: /
消息发送(publisher)
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringAmqpTest {
@Autowired private RabbitTemplate rabbitTemplate; @Test public void testSimpleQueue() { // 队列名称 String queueName = "simple.queue"; // 消息 String message = "hello, spring amqp!"; // 发送消息 rabbitTemplate.convertAndSend(queueName, message); }
}
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
@Component
public class SpringRabbitListener {
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueueMessage(String msg) throws InterruptedException {
System.out.println("spring 消费者接收到消息:【" + msg + "】");
}
}
消息发送
@Test
public void testWorkQueue() throws InterruptedException {
// 队列名称
String queueName = "simple.queue";
// 消息
String message = "hello, message_";
for (int i = 0; i < 50; i++) {
// 发送消息
rabbitTemplate.convertAndSend(queueName, message + i);
Thread.sleep(20);
}
}
消息接收
@RabbitListener(queues = "simple.queue")
public void listenWorkQueue1(String msg) throws InterruptedException {
System.out.println("消费者1接收到消息:【" + msg + "】" + LocalTime.now());
Thread.sleep(20);
}
@RabbitListener(queues = "simple.queue")
public void listenWorkQueue2(String msg) throws InterruptedException {
System.err.println("消费者2........接收到消息:【" + msg + "】" + LocalTime.now());
Thread.sleep(200);
}
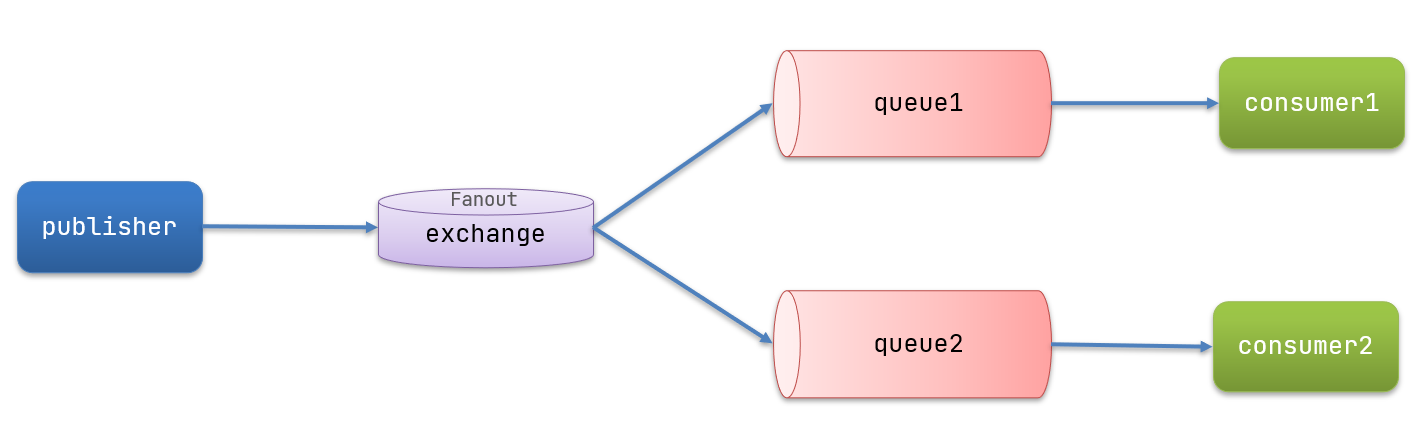
绑定队列和交换机在消费者consumer服务中
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.FanoutExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class FanoutConfig {
/**
* 声明交换机
* @return Fanout类型交换机
*/
@Bean
public FanoutExchange fanoutExchange(){
return new FanoutExchange("itcast.fanout");
}
/**
* 第1个队列
*/
@Bean
public Queue fanoutQueue1(){
return new Queue("fanout.queue1");
}
/**
* 绑定队列和交换机
*/
@Bean
public Binding bindingQueue1(Queue fanoutQueue1, FanoutExchange fanoutExchange){
return BindingBuilder.bind(fanoutQueue1).to(fanoutExchange);
}
/**
* 第2个队列
*/
@Bean
public Queue fanoutQueue2(){
return new Queue("fanout.queue2");
}
/**
* 绑定队列和交换机
*/
@Bean
public Binding bindingQueue2(Queue fanoutQueue2, FanoutExchange fanoutExchange){
return BindingBuilder.bind(fanoutQueue2).to(fanoutExchange);
}
}
消息发送
@Test
public void testFanoutExchange() {
// 队列名称
String exchangeName = "itcast.fanout";
// 消息
String message = "hello, everyone!";
rabbitTemplate.convertAndSend(exchangeName, "", message);
}
消息接收
@RabbitListener(queues = "fanout.queue1")
public void listenFanoutQueue1(String msg) {
System.out.println("消费者1接收到Fanout消息:【" + msg + "】");
}
@RabbitListener(queues = "fanout.queue2")
public void listenFanoutQueue2(String msg) {
System.out.println("消费者2接收到Fanout消息:【" + msg + "】");
}

@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue1"),
exchange = @Exchange(name = "itcast.direct", type = ExchangeTypes.DIRECT),
key = {"red", "blue"}
))
public void listenDirectQueue1(String msg){
System.out.println("消费者接收到direct.queue1的消息:【" + msg + "】");
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue2"),
exchange = @Exchange(name = "itcast.direct", type = ExchangeTypes.DIRECT),
key = {"red", "yellow"}
))
public void listenDirectQueue2(String msg){
System.out.println("消费者接收到direct.queue2的消息:【" + msg + "】");
}
@Test
public void testSendDirectExchange() {
// 交换机名称
String exchangeName = "itcast.direct";
// 消息
String message = "message ";
// 发送消息
rabbitTemplate.convertAndSend(exchangeName, "red", message);
}
显然,JDK序列化方式并不合适。我们希望消息体的体积更小、可读性更高,因此可以使用JSON方式来做序列化和反序列化。
在publisher和consumer两个服务中都引入依赖:
<dependency>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-xml</artifactId>
<version>2.9.10</version>
</dependency>
配置消息转换器。
在启动类中添加一个Bean即可:
@Bean
public MessageConverter jsonMessageConverter(){
return new Jackson2JsonMessageConverter();
}
小结:服务者publisher消息发送只需要管要发送的交换机名字、Binding和消息,而消费者需要监听是否收到消息
首先打开ip:5601
创建索引库和映射
PUT /索引库名称
{
"mappings": {
"properties": {
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": "false"
},
"字段名3":{
"properties": {
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}
GET /索引库名
修改索引库
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
DELETE /索引库名
文档操作
新增文档
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
// ...
}
例:
POST /test/_doc/1
{
"info": "Java讲师",
"email": "123@qq.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}
查询文档
GET /{索引库名称}/_doc/{id}
例:
GET /test/_doc/1
删除文档
DELETE /{索引库名}/_doc/id值
PUT /{索引库名}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
POST /heima/_update/1
{
"doc": {
"email": "ZhaoYun@qq.cn"
}
}
PUT /hotel
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword",
"copy_to": "all"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
-
location:地理坐标,里面包含精度、纬度
-
all:一个组合字段,其目的是将多字段的值 利用copy_to合并,提供给用户搜索
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
因为SpringBoot默认的ES版本是7.6.2,所以我们需要覆盖默认的ES版本
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
初始化RestHighLevelClient
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.io.IOException;
public class HotelIndexTest {
private RestHighLevelClient client;
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.150.101:9200")
));
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
}
@Test
void createHotelIndex() throws IOException {
// 1.创建Request对象
CreateIndexRequest request = new CreateIndexRequest("hotel");
// 2.准备请求的参数:DSL语句
request.source(*DSL语句*, XContentType.JSON);
// 3.发送请求
client.indices().create(request, RequestOptions.DEFAULT);
}
@Test
void testDeleteHotelIndex() throws IOException {
// 1.创建Request对象
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
// 2.发送请求
client.indices().delete(request, RequestOptions.DEFAULT);
}
@Test
void testExistsHotelIndex() throws IOException {
// 1.创建Request对象
GetIndexRequest request = new GetIndexRequest("hotel");
// 2.发送请求
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
// 3.输出
System.err.println(exists ? "索引库已经存在!" : "索引库不存在!");
}
@Test
void testAddDocument() throws IOException {
// 1.根据id查询酒店数据
Hotel hotel = hotelService.getById(61083L);
// 2.将hotel 转json
String json = JSON.toJSONString(hotel );
// 1.准备Request对象
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
// 2.准备Json文档
request.source(json, XContentType.JSON);
// 3.发送请求
client.index(request, RequestOptions.DEFAULT);
}
@Test
void testGetDocumentById() throws IOException {
// 1.准备Request
GetRequest request = new GetRequest("hotel", "61082");
// 2.发送请求,得到响应
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 3.解析响应结果
String json = response.getSourceAsString();
HotelDoc hotel = JSON.parseObject(json, Hotel.class);
System.out.println(hotel);
}
@Test
void testDeleteDocument() throws IOException {
// 1.准备Request
DeleteRequest request = new DeleteRequest("hotel", "61083");
// 2.发送请求
client.delete(request, RequestOptions.DEFAULT);
}
@Test
void testUpdateDocument() throws IOException {
// 1.准备Request
UpdateRequest request = new UpdateRequest("hotel", "61083");
// 2.准备请求参数
request.doc(
"price", "952",
"starName", "四钻"
);
// 3.发送请求
client.update(request, RequestOptions.DEFAULT);
}
@Test
void testBulkRequest() throws IOException {
// 批量查询酒店数据
List<Hotel> hotels = hotelService.list();
// 1.创建Request
BulkRequest request = new BulkRequest();
// 2.准备参数,添加多个新增的Request
for (Hotel hotel : hotels) {
// 2.1.创建新增文档的Request对象
request.add(new IndexRequest("hotel")
.id(hotel.getId().toString())
.source(JSON.toJSONString(hotel), XContentType.JSON));
}
// 3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
}
-
-
全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
-
match查询:单字段查询
-
multi_match查询:多字段查询,任意一个字段符合条件就算符合查询条件
-
match和multi_match的区别是什么?
-
match:根据一个字段查询
-
-
-
-
-
精确查询:根据精确词条值查找数据,一般是查找keyword、数值、日期、boolean等类型字段。例如:
-
ids 根据id查询
-
range 根据值的范围查询
-
term 根据词条精确值查询
-
-
地理(geo)查询:根据经纬度查询。例如:
-
geo_distance 附近查询,也叫做距离查询
-
geo_bounding_box 矩形范围查询
-
-
复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:
function score 查询中包含四部分内容:
-
原始查询条件:query部分,基于这个条件搜索文档,并且基于BM25算法给文档打分,原始算分(query score)
-
过滤条件:filter部分,符合该条件的文档才会重新算分
-
算分函数:符合filter条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数
-
weight:函数结果是常量
-
field_value_factor:以文档中的某个字段值作为函数结果
-
random_score:以随机数作为函数结果
-
script_score:自定义算分函数算法
-
-
运算模式:算分函数的结果、原始查询的相关性算分,两者之间的运算方式,包括:
-
multiply:相乘
-
replace:用function score替换query score
-
其它,例如:sum、avg、max、min
-
function score的运行流程如下:
-
1)根据原始条件查询搜索文档,并且计算相关性算分,称为原始算分(query score)
-
2)根据过滤条件,过滤文档
-
3)符合过滤条件的文档,基于算分函数运算,得到函数算分(function score)
-
4)将原始算分(query score)和函数算分(function score)基于运算模式做运算,得到最终结果,作为相关性算分。
因此,其中的关键点是:
-
过滤条件:决定哪些文档的算分被修改
-
算分函数:决定函数算分的算法
-
运算模式:决定最终算分结果
示例:
GET /hotel/_search
{
"query": {
"function_score": {
"query": { .... }, // 原始查询,可以是任意条件
"functions": [ // 算分函数
{
"filter": { // 满足的条件,品牌必须是如家
"term": {
"brand": "如家"
}
},
"weight": 2 // 算分权重为2
}
],
"boost_mode": "sum" // 加权模式,求和
}
}
}
布尔查询(bool)
布尔查询是一个或多个查询子句的组合,每一个子句就是一个子查询。子查询的组合方式有:
-
must:必须匹配每个子查询,类似“与”
-
should:选择性匹配子查询,类似“或”
-
must_not:必须不匹配,不参与算分,类似“非”
-
filter:必须匹配,不参与算分
每一个不同的字段,其查询的条件、方式都不一样,必须是多个不同的查询,而要组合这些查询,就必须用bool查询了。
需要注意的是,搜索时,参与打分的字段越多,查询的性能也越差。因此这种多条件查询时,建议这样做:
-
搜索框的关键字搜索,是全文检索查询,使用must查询,参与算分
-
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{"term": {"city": "上海" }}
],
"should": [
{"term": {"brand": "皇冠假日" }},
{"term": {"brand": "华美达" }}
],
"must_not": [
{ "range": { "price": { "lte": 500 } }}
],
"filter": [
{ "range": {"score": { "gte": 45 } }}
]
}
}
}
查询的语法基本一致:
GET /indexName/_search
{
"query": {
"查询类型": {
"查询条件": "条件值"
}
}
}
搜索结果处理
排序
普通字段排序
排序条件是一个数组,也就是可以写多个排序条件。按照声明的顺序,当第一个条件相等时,再按照第二个条件排序,以此类推
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"FIELD": "desc" // 排序字段、排序方式ASC、DESC
}
]
}
地理坐标排序
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance" : {
"FIELD" : "纬度,经度", // 文档中geo_point类型的字段名、目标坐标点
"order" : "asc", // 排序方式
"unit" : "km" // 排序的距离单位
}
}
]
}
这个查询的含义是:
-
指定一个坐标,作为目标点
-
计算每一个文档中,指定字段(必须是geo_point类型)的坐标 到目标点的距离是多少
-
根据距离排序
基本的分页
GET /hotel/_search { "query": { "match_all": {} }, "from": 0, // 分页开始的位置,默认为0 "size": 10, // 期望获取的文档总数 "sort": [ {"price": "asc"} ] }
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 990, // 分页开始的位置,默认为0
"size": 10, // 期望获取的文档总数
"sort": [
{"price": "asc"}
]
}
GET /hotel/_search
{
"query": {
"match": {
"FIELD": "TEXT" // 查询条件,高亮一定要使用全文检索查询
}
},
"highlight": {
"fields": { // 指定要高亮的字段
"FIELD": {
"pre_tags": "<em>", // 用来标记高亮字段的前置标签
"post_tags": "</em>" // 用来标记高亮字段的后置标签
}
}
}
}
-
-
第二步,利用
request.source()构建DSL,DSL中可以包含查询、分页、排序、高亮等-
query():代表查询条件,利用QueryBuilders.matchAllQuery()构建一个match_all查询的DSL
-
-
示例:
@Test void testMatchAll() throws IOException { // 1.准备Request SearchRequest request = new SearchRequest("hotel"); // 2.准备DSL request.source() .query(QueryBuilders.matchAllQuery()); // 3.发送请求 SearchResponse response = client.search(request, RequestOptions.DEFAULT); // 4.解析响应 handleResponse(response); } private void handleResponse(SearchResponse response) { // 4.解析响应 SearchHits searchHits = response.getHits(); // 4.1.获取总条数 long total = searchHits.getTotalHits().value; System.out.println("共搜索到" + total + "条数据"); // 4.2.文档数组 SearchHit[] hits = searchHits.getHits(); // 4.3.遍历 for (SearchHit hit : hits) { // 获取文档source String json = hit.getSourceAsString(); // 反序列化 HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class); System.out.println("hotelDoc = " + hotelDoc); } }
@Test
void testMatch() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
request.source()
.query(QueryBuilders.matchQuery("all", "如家"));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
QueryBuilders.termQuery(“字段”,“值”);
QueryBuilders.rangeQuery(“字段”).gte(min).lte(max);
布尔查询
与其它查询的差别同样是在查询条件的构建,QueryBuilders,结果解析等其他代码完全不变。
@Test
void testBool() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.准备BooleanQuery
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
// 2.2.添加term
boolQuery.must(QueryBuilders.termQuery("city", "杭州"));
// 2.3.添加range
boolQuery.filter(QueryBuilders.rangeQuery("price").lte(250));
request.source().query(boolQuery);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
@Test
void testPageAndSort() throws IOException {
// 页码,每页大小
int page = 1, size = 5;
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
request.source().query(QueryBuilders.matchAllQuery());
// 2.2.排序 sort
request.source().sort("price", SortOrder.ASC);
// 2.3.分页 from、size
request.source().from((page - 1) * size).size(5);
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
@Test
void testHighlight() throws IOException {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
request.source().query(QueryBuilders.matchQuery("all", "如家"));
// 2.2.高亮
request.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(false));
// 3.发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析响应
handleResponse(response);
}
高粱结果解析
private void handleResponse(SearchResponse response) {
// 4.解析响应
SearchHits searchHits = response.getHits();
// 4.1.获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total + "条数据");
// 4.2.文档数组
SearchHit[] hits = searchHits.getHits();
// 4.3.遍历
for (SearchHit hit : hits) {
// 获取文档source
String json = hit.getSourceAsString();
// 反序列化
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
// 获取高亮结果
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if (!CollectionUtils.isEmpty(highlightFields)) {
// 根据字段名获取高亮结果
HighlightField highlightField = highlightFields.get("name");
if (highlightField != null) {
// 获取高亮值
String name = highlightField.getFragments()[0].string();
// 覆盖非高亮结果
hotelDoc.setName(name);
}
}
System.out.println("hotelDoc = " + hotelDoc);
}
}
可以让我们极其方便的实现对数据的统计、分析、运算。例如:
-
什么品牌的手机最受欢迎?
-
这些手机的平均价格、最高价格、最低价格?
-
这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
聚合常见的有三类:
-
桶(Bucket)聚合:用来对文档做分组
-
TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组
-
Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
-
-
度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
-
Avg:求平均值
-
Max:求最大值
-
Min:求最小值
-
Stats:同时求max、min、avg、sum等
-
-
管道(pipeline)聚合:其它聚合的结果为基础做聚合
注意:参加聚合的字段必须是keyword、日期、数值、布尔类型
DSL实现
GET /hotel/_search
{
"size": 0, // 设置size为0,结果中不包含文档,只包含聚合结果
"aggs": { // 定义聚合
"brandAgg": { //给聚合起个名字
"terms": { // 聚合的类型,按照品牌值聚合,所以选择term
"field": "brand", // 参与聚合的字段
"size": 20 // 希望获取的聚合结果数量
}
}
}
}
GET /hotel/_search
{
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"order": {
"_count": "asc" // 按照_count升序排列
},
"size": 20
}
}
}
}
GET /hotel/_search
{
"query": {
"range": {
"price": {
"lte": 200 // 只对200元以下的文档聚合
}
}
},
"size": 0,
"aggs": {
"brandAgg": {
"terms": {
"field": "brand",
"size": 20
}
}
}
}
RestAPI
@Override
public Map<String, List<String>> filters(RequestParams params) {
try {
// 1.准备Request
SearchRequest request = new SearchRequest("hotel");
// 2.准备DSL
// 2.1.query
buildBasicQuery(params, request);
// 2.2.设置size
request.source().size(0);
// 2.3.聚合
buildAggregation(request);
// 3.发出请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 4.解析结果
Map<String, List<String>> result = new HashMap<>();
Aggregations aggregations = response.getAggregations();
// 4.1.根据品牌名称,获取品牌结果
List<String> brandList = getAggByName(aggregations, "brandAgg");
result.put("品牌", brandList);
// 4.2.根据品牌名称,获取品牌结果
List<String> cityList = getAggByName(aggregations, "cityAgg");
result.put("城市", cityList);
// 4.3.根据品牌名称,获取品牌结果
List<String> starList = getAggByName(aggregations, "starAgg");
result.put("星级", starList);
return result;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private void buildAggregation(SearchRequest request) {
request.source().aggregation(AggregationBuilders
.terms("brandAgg")
.field("brand")
.size(100)
);
request.source().aggregation(AggregationBuilders
.terms("cityAgg")
.field("city")
.size(100)
);
request.source().aggregation(AggregationBuilders
.terms("starAgg")
.field("starName")
.size(100)
);
}
private List<String> getAggByName(Aggregations aggregations, String aggName) {
// 4.1.根据聚合名称获取聚合结果
Terms brandTerms = aggregations.get(aggName);
// 4.2.获取buckets
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
// 4.3.遍历
List<String> brandList = new ArrayList<>();
for (Terms.Bucket bucket : buckets) {
// 4.4.获取key
String key = bucket.getKeyAsString();
brandList.add(key);
}
return brandList;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号