BUAA-OO-Unit1-单元总结
BUAA-OO-Unit1-单元总结
一、 结合课程内容进行题目分析及架构设计
① 题目简析
针对课上所说的数据结构及功能结构,建立抽象层次。
面对第一单元作业,主要为层次化关系。
表达式的层次化管理:项、因子等层次 ---> 采用递归下降的算法
表达式的化简(计算):主要为展开和合并。展开:如指数、括号、自定义函数、sum函数的展开。合并:合并同类项、三角函数的一些优化。
控制输入输出的类:可以依照training的思路,创建Lexer类分析词法(顺序分析读入字符串),再创建Parser类分析句法(结合递归下降算法)。关于结果的输出则可以直接重写表达式类、项类等的toString()方法。
② 架构思路
对表达式的层次处理
主要依据为——运算符的优先级,如图所示。

主要要求的运算符为+,-,*,**,(),sum,f,sin,cos 。
可以根据运算符的优先级进行分层。如双目运算符优先级最低,加减组成表达式,乘法组成项。接着是单目运算符,最为特殊的是乘方,它可以和其他因子形成幂次的反应。最后是优先级最高的因子层,我将各种常数、变量、表达式因子、三角函数因子、自定义函数因子放在这里。
当然,针对这棵层次结构树可以进行相应的简化,如单目运算符乘方,可以在预处理的时候将其展开,并且求和函数和自定义函数也可以再预处理的时候进行展开。
最终得到如下的图:

输入输出处理
在输入输出处理中,我借鉴了training的思路。
1、Lexer类:通过外界的一个字符串传入,这个类能够提取句子中的词法,如分析当前成分是sin还是x还是小括号等。
2、Parser类:通过递归下降的思想,即针对每一个语法成分,都用一种单独的方法提取,并返回这个语法成分。
3、自定义函数读入预处理:定义一个Function类,属性有name,parameters,expr。name为String变量,标志为函数名。parameters为ArrayList类型,标志为函数的参数表。expr为Expr类对象,标志为函数表达式。定义的方法为:toExpr(),可以根据传入参数,对expr中的parameters进行替换,因此,就需要对每个因子递归定义replace()方法,要注意克隆时候的问题。
4、Sum函数的读入预处理:其实他很类似于自定义函数,但是我还是将他单独作为一类,原因是:它不能实现确定表达式。需要定义的属性为:循环变量i,迭代起始数,和迭代结束数,同时需要有toExpr()方法,传入参数(循环变量i)展开成表达式。
化简(计算)处理
有了递归下降的思想,肯定能很自然地想到递归下降化简计算。
因此需要考虑三个问题:
1、每一次递归需要下一层返回给本层什么东西?
2、如何进行快速化简,利用何种容器?
3、定义什么运算法则?
第一个问题,由于需要计算化简,因此直接返回Factor Term 或是Expr是不好操作的。(如果直接返回这些类,则需要定义各种化简,太过繁琐)因此,我们可以从最后需要得到的结果进行分析,统一形式:
第一次作业:系数*变量**幂+…+系数*变量**幂
e.g. 233*x**3+233*x**6…
第二次作业: (提供一个我的思路)
系数*最简类1**幂*…*最简类n**幂+…+系数*最简类1**幂*…
e.g. 233*x**3*sin(x)**2+sin(x)**3*cos(x**2)**4…
第二个问题,由于有指数和系数,合并同类项很自然可以想到利用HashMap<,>的键值快速匹配计算。
第一次作业:定义HashMap<BigInteger,BigInteger>存储多项式
第二次作业、第三次作业:
定义HashMap<HashMap<“最简类”,幂>,系数>存储最简式子
ps. 利用自定义的类当作HashMap的键,需要自己为每一个类重写hashCode()和equals()方法,这两个方法可以又IDEA自动生成,这样HashMap才能判断键是否重复。
第三个问题,以第二、三次作业为例,分析架构,真正需要计算的只有Expr中terms的“+”(我把[+-]当作符号处理,预处理的时候简化了)和Term中factors的“*”。(其他的许多最基本的类都很容易构造出上述的HashMap,作为递归基)
通过上面三个问题,可以得出Factor类都要提供的一些功能:
1、属性:HashMap<…,…>
2、方法:
add(HashMap<…,…>, HashMap<…,…>)
multi(HashMap<…,…>,HashMap<…,…>)
Ps. 由于在预处理的时候,进行了指数展开以及函数展开,因此各个展开操作在计算处理就不需要实现了,(当然,如果没有预处理展开也只需定义几个展开方法即可)。
二、 三次作业的具体实现
①第一次作业

UML图分析
第一次作业的UML图如上所示。我将所有类分成了两个功能类,一个是用于解析的类,一个是句子成分的类(也可以叫做表达式类)。这些类都是根据第一大点提到的架构思路创建的。
其中,需要补充的是:TokenType是Lexer中的一个enum类型的类,目的是为了方便Parser的识别,提高代码可读性。
TokenType可以如下编写:
public enum TokenType {
ERR, EOL,
CONSTANT, X, LBRACKET, RBRACKET,
PLUS, MINUS, MULTI, EXP
}
句子成分类中,Expr为表达式类,它里面包含多个项组成terms。Term为项类,它里面包含多个因子组成factors,主要包括Expr以及常量Constant和变量Var。至于指数的处理,则直接在句法分析时的Parser中,将其展开归入到factors中去。
同时,为了方便计算化简,这些句子成分类都将继承Factor类,便于统一管理,统一计算化简。因此,直接在Factor里面定义化简的各种方法,主要有add()和multi()方法,同时,还需要每一个Factor重写update()方法,目的是为了递归化简。
复杂度分析
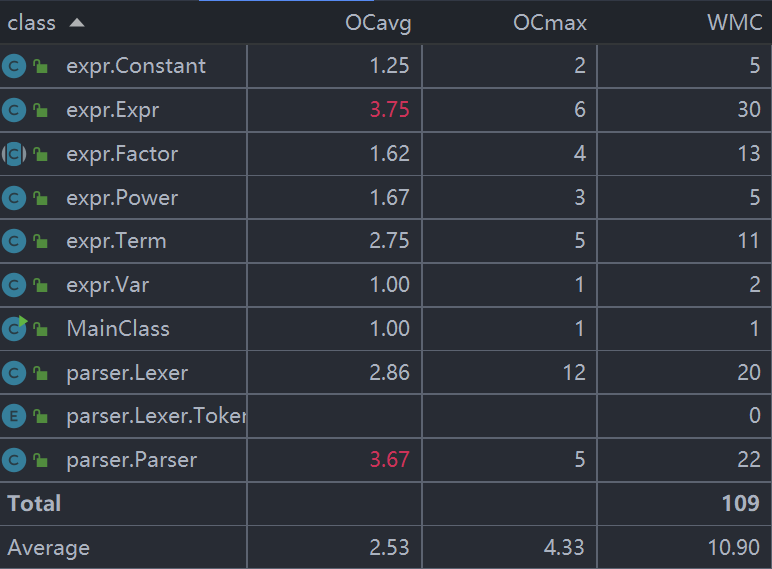
可以看到,主要复杂度在Expr类和Parser类。由于这两个类是核心,需要由各个类调用,形成递归循环层次,因此方法的圈复杂度较高,是比较可能出bug的类。但是由于在先前做好了架构的分析,因此没有出现较为严重的bug,在强测和互测中均无发现bug。
②第二、三次作业

UML图分析
由于架构在迭代方面较为优越。
因此增删的部分较少。这里只重点说明迭代开发部分:
Function类:
该类用于存储自定义函数,并提供根据传入参数,替换函数表达式为新表达式输出的功能。
name:函数名,用于对算数表达式读入时候作为索引。
parameters:参数表,根据顺序,存储每一个形式参数。
expr:表达式,为函数的定义式,其用于替换。
toExpr(ArrayList<Factor> actualParameters):通过传入实际参数表,将形式参数替换成实际参数并输出成Expr。
Sum类:
该类用于读入sum函数,并提供将求和表达式中的变量i替换成迭代起始数到迭代结束数的和,并输出新表达式的功能。
itr:迭代器,一般为i
bottom:迭代起始数,类型为Constant,本质为BigInteger
top:迭代结束数,类型为Constant,本质为BigInteger
term:为求和表达式,由于一般为因子(或者是指数)因此直接定义为项类。
toExpr():将迭代器对求和表达式从迭代起始数迭代累加至迭代结束数,转换成表达式Expr输出。
Sin和Cos类:
三角函数类,作为同变量Var类型同样层级的类。
Factor类:
将HashMap<BigInteger,BigInteger>更改成HashMap<HashMap<Factor,BigInteger>,BigInteger>。同时,只需小幅度更改其他有关poly的方法就行。同时,应对每一个Factor类
三角优化
由于采用HashMap<HashMap<Factor,BigInteger>,BigInteger>的容器存储计算结果,则已经解决了合并同类项的优化问题,因此,只需着重放在三角函数上的化简即可。
虽然,针对三角函数的大部分化简,只需实现两个和角公式即可。
ps:\(sin(a+b)=sin(a)cos(b)+cos(a)sin(b)\)可以实现sin的二倍角优化,\(cos(a+b)=cos(a)cos(b)-sin(a)sin(b)\)可以实现cos的二倍角优化,以及sin和cos的平方和优化
但是,由于没能想好更加合理的优化算法,只会暴力搜索替换,因此,复杂度容易爆增,因此,我只选择了化简\(sin(x)^2+cos(x)^2 = 1\)的化简。
优化的算法是:暴力搜索\(sin(x)^2\)并替换成\(1-cos(x)^2\)并再进行计算,直到搜索不到\(sin(x)^2\),\(cos(x)^2\)同理,将得到的这些结果进行字符串长度比较,输出最短的即可。
复杂度分析

可以发现Expr类和Parser类同第一次作业,圈复杂度较高。同时,这次由于关于三角函数平方和的优化我都放在主类MainClass中实现,因此,主类的圈复杂度十分高。这是由于优化方面太过暴力,引用了很多类而形成的高复杂度高耦合的情况。这是很不好的。也因此,大家大部分的Bug都是出在优化的代码中。
ps.由于第二次作业的架构已经完美实现了第三次作业的因子嵌套任务,因此两次作业的区别不大,在第二次到第三次作业的迭代开发中只进行了小修小补,故这里一同进行分析。
三、在测试自己的程序以及他人程序中碰到的bug
自己程序的bug
在三次的强测和互测中,均无发现bug。
因此再次我只讨论针对自己在编程初期遇到的bug。
主要有如下bug:
1、由于对迭代器的认知不足,在for循环遍历HashMap<>时,针对HashMap<>进行了删减操作,导致程序出错。
2、直接利用idea生成equals和hashcode方法时,只会默认将该类的所有属性进行比较或者取hash值,因此,需要自己手动更改equals判断的属性以及hash函数判断的属性。否则会出现无法合并的情况。
3、当三角函数内部是表达式因子的时候,不会在表达式外加括号。由于我在三角函数里面存的是Expr类,因此还需要定义一种方法来判断这个Expr是表达式因子还是其他基础因子。在特判的函数里条件写错了。
互测中Hack的bug
第一次作业:
1、针对0次方的bug测试
主要的bug有两处:表达式(即括号)外的0次方处理出问题;0的0次方为1的问题。
2、针对多加减处理的bug
主要的bug在于多个正负号处理出的问题,尤其是遇到三个加减符号,或者是遇到形如+-(+-...)之类的正负号问题。
第二次作业:
3、针对sin(-x)的符号提取优化的bug
主要的bug在于碰到sin(-x)即无脑提取负号。当遇到sin(-1)**2的数据时,直接提取负号从语义上便会出错。
4、针对平方和化简的bug
主要的bug在于遇到两个平方和能化简的时候会出现异常。原因在于没考虑多个平方和化简的情况,循环出现失误。
5、针对结果为0但输出为空的bug
主要的bug在于没有把输出结果为空的情况在最外层判断。导致当数据为如sin(-1)-sin(-1)时,输出为空。
第三次作业:
6、针对sin(0)的优化bug
面对sin(0)**1+sin(0)**0数据,优化失误,直接输出0。
7、针对sum求和函数中的上下限超int范围的bug
若将sum求和函数的上下限定义成int范围的数据,则会导致超出数据范围的错误。
四、学习心得体会
第一单元的学习过程虽然困难艰辛,但是确实收获颇丰。
首先,我在之前的学习过程中,既没有接触过面向对象的编程思想,也没有接触过面向对象的编程语言(如C++,Java)。而这门课不仅需要Java的编程语法基础,也需要面向对象的架构编程设计,因此对我这种学生的压力就很大。好在课程组在开学前提供了pre的预习资料,使得我能够在开学前一段时间预习了解了java以及面向对象的一些知识,做到了入门。同时,也继承了大一程序设计课程和数据结构课程培养出来的编程习惯。在第一单元的前两次作业拿到了100分的成绩并从未hack过,在第三次作业拿到了96.8的成绩,且未hack过。算是个很好的成绩了。
接着,我在互测环节中,也更加注重于测试的全面性。虽然由于时间原因没有搭建自动评测机,但是手动构造边界数据的能力大幅度提升,几乎可以覆盖到绝大部分情况,也因此能够在互测中取得不错的hack成绩。
最后,十分感谢课程组各位助教的帮助,尤其是吴家焱助教,指导十分耐心,为我解答了许多设计上出现的问题。
希望在第二单元,我也能够保持下去,取得不错的成绩。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号