
Java面向过程
一些知识
- 编译型:编译型语言 会通过编译器将源代码一次性翻译成可被该平台执行的机器码。一般情况下,编译语言的执行速度比较快,开发效率比较低。常见的编译性语言有 C、C++、Go、Rust 等等。
- 解释型:解释型语言会通过解释器一句一句的将代码解释(interpret)为机器代码后再执行。解释型语言开发效率比较快,执行速度比较慢。常见的解释性语言有 Python、JavaScript、PHP 等等。
- java:编译与解释共存。这是因为 Java 语言既具有编译型语言的特征,也具有解释型语言的特征。因为 Java 程序要经过先编译,后解释两个步骤,由 Java 编写的程序需要先经过编译步骤,生成字节码(.class 文件),这种字节码必须由 Java 解释器来解释执行。
Java程序开发的三个步骤
- 编写代码-->HelloWorld.java
- 编译代码(使用javac编译)-->HelloWorld.class
- 运行代码(使用java运行)
JDK组成
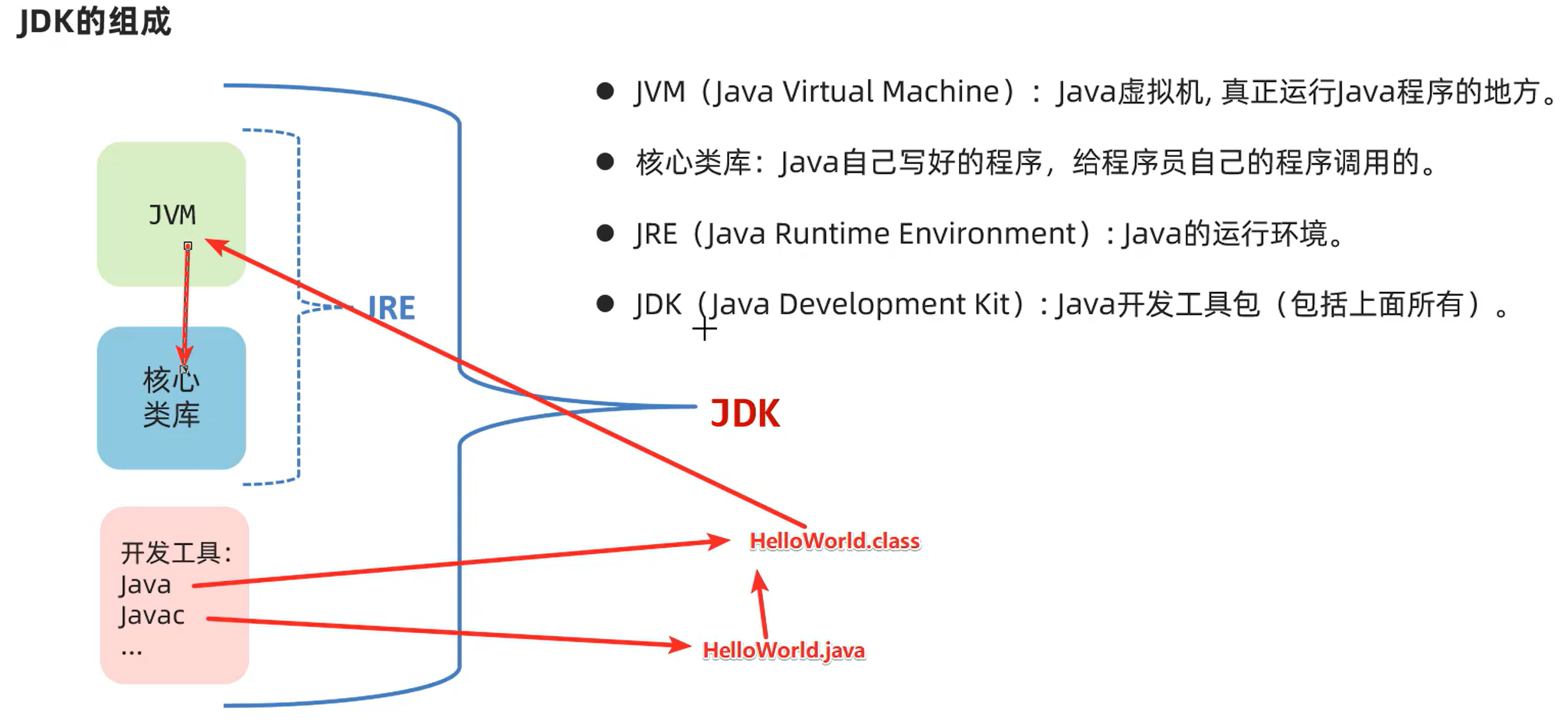
一次编译,处处可用
是因为sum公司给不同的系统都配置了JVM虚拟机。我们的程序只需要开发一次,就可以在各种安装了JVM的系统平台上运行。
快捷键
ALT + 回车 快捷键
Ctrl + D 复制当前行至下一行
数据类型
进制:
二进制:0b
八进制: 0
十六进制: 0x 0-9 A-F
基本数据类型
blearn byte short char int long float double
float:
- 有限 离散 舍入误差 大约 接近但不等于 (最好完全避免使用浮点数进行比较)
- 所有的字符本质还是数字,Unicode编码是十六进制 2字节 65536字符 U0000-UFFFF
类型转换
- 在运算中,不同的数据先转化为同一列数据再进行运算。 顺序:byte,short,char-->int-->long-->float-->double
- 用运算符运算的时候,运算结果的数据类型为参与运算的变量中最高优先级的数据类型,如果是byte,short,char进行运算,都先会自动转型为int类型。
- 强制转换的时候要注意内存溢出的问题或者精度问题;
- 从高到低需要强制转换,从低到高是自动转换的
- 不能对布尔值进行转换
- 不能把对象类型转换为不相干的类型
类似(int)这样的强制转换是基本类型之间的转换,不能用于对象类型。要把字符串变成整数,只能用解析方法。
int num = Integer.parseInt("123");
| 方法 | 用途 |
|---|---|
| Integer.parseInt(String) | 字符串 → int |
| Double.parseDouble(String) | 字符串 → double |
| Long.parseLong(String) | 字符串 → long |
| String.valueOf(int) | int → 字符串 |
| Integer.toString(int) | int → 字符串(同上) |
变量
- 局部变量:必须声明和初始化值
- 实例变量:在方法的外面类的里面,从属于对象,如果不自行初始化,会使用这个类型的默认值 0 0.0 u000 false。除了基本类型,其余的都是null
- 类变量:加了static
- 命名规范:
- 类成员变量、局部变量、方法名:首字母小写+驼峰原则
- 常量:大写字母和下划线
- 类名:首字母大写+驼峰原则
常量
不会变动的值,用final定义,常量名一般使用大写字符。修饰符是不存在先后顺序的
final 常量名=值
运算符
逻辑运算符:&&, ||, !
条件运算符: ?: 比如 x ? y : z 表示如果x为True,则结果为y,否则为z
自增:++ ; 自减:-- (一元运算符) a++表示先赋值再自增,++a表示先自增再赋值
<<:左移,相当于*2
>>:右移,相当于/2
包
包的本质是文件夹。一般利用公司域名倒置作为包名。
包要放到最上面,再放导入包。
生成JavaDoc
CMD javadoc -encoding UTF-8 -charset UTF-8 java文件
intellij IDE中 选择TOOLS的Generate JavaDoc
人机交互
通过Scanner类来获取用户的输入
基本语法:Scanner s = new Scanner(System.in);
通过next()和nextLine()方法获取输入的字符串,在读取前一般需要使用hasNext()与hasNextLine()判断是否还有输入的数据.
next()不能得到带空格的字符串
- next():读取下一个字符串,遇到空格、换行、制表符等分隔符停止。
- nextLine(): 读取一整行的文本,直到遇到换行符 \n(包括空格、制表符)
- nextInt(): 读取整数类型(int),遇到非数字或换行符停止。
判断字符串是否相等的时候使用equals函数比==要安全。
for循环
- 基础for循环:初始化可以是空语句
for(初始化; 布尔表达式; 更新)
{ //代码语句}
- 增强for循环
for (元素类型 元素名(自己取的变量名称):集合名或数组名)
)
{//代码句子}
- 带标签的for循环(类似C++中的goto)
public class zhiShu {
public static void main(String[] args){
int count = 0;
outer:for (int i=101; i<150; i++){
for (int j=2; j<i/2; j++){
if (i%j ==0){
continue outer;
}
}
System.out.print(i+"\t");
}
}
}
输出
println 输出会换行
print 输出不换行
printf
转义符: "\t" "\n"
System.exit(0) #表示停止虚拟机运行
方法
基本定义
类+对象+方法
修饰符 返回值类型 方法名(参数类型 参数名){
方法体
return 方法值;
}
方法中遇到return会直接终止
调用方法:对象名.方法名()
Java都是值传递,值传递是复制一份,引用传递是新建一个快捷方式
方法重载
- 定义:重载就是在一个类中,有相同的函数名称,但形参不同的函数。
- 重载规则:
- 方法名称必须相同
- 参数列表必须不同(个数不同、或类型不同、参数排列顺序不同等)(其中顺序不同是指类型的顺序不同,与起什么变量名无关,比如int a int b和int b int a就是相同的顺序)
- 方法的返回类型可以相同也可以不相同
- 仅仅通过返回值类型不同不足以成为方法的重载
CMD中给main函数传参
javac命令是编译,java命令是执行
javac命令编译时,可以就在当下目录,但是执行时如果导入了包,就必须要退回上一级目录,再写全称目录来进行传参。
比如我有文件 D:\JavaProjects\untitled\src\grammaly\ChuanCan.java
编译时可以在 D:\JavaProjects\untitled\src\grammaly目录下写javac ChuanCan.java
但是执行时必须回退至 D:\JavaProjects\untitled\src 写 java grammly.ChuanCan.java
可变参数
在指定参数类型后面加一个省略号(...)
一个方法中只能指定一个可变参数,必须是方法的最后一个参数。任何普通的参数必须在他之前声明。
数组
数组时相同类型数据的有序集合。
长度 array.length
- 定义 声明
int[] nums;
int nums[];
- 创建,开辟空间
nums = new int[10]
- 静态初始化
int[] a = {1,2,3,4,5,6,7,8} - 动态初始化(包含默认初始化,即隐式初始化)
int[] a = new int[2];
a[0]=1;
a[1]=2;
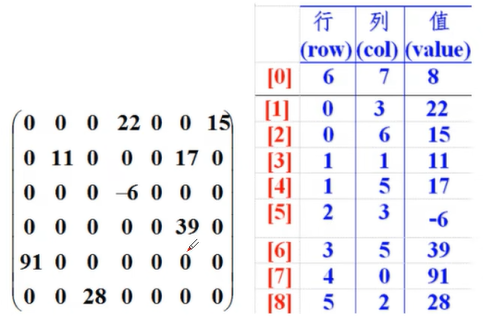
稀疏数组
当一个数组中大部分元素为0.或者为同一值的时候,可以用稀疏数组来保存该数组。
处理方式:
- 记录数组一共有几行几列,有多少个不同值
- 把具有不同值的元素和行列及值记录在一个小规模的数组中,从而缩小程序的规模
![]()
堆
存放new的对象和数组
栈
存放基本变量类型

数组(Arrays)
java.util.Arrays
Arrays.toString(a):打印出数组元素
Arrays.sort(a):数组进行排序:升序
Arrays.fill(a,0):给数组进行赋值,将数值赋值给数据中的每个元素
API(Application Programming Interface):应用程序编程接口
Scanner 键盘输入
Random 随机数
列表(Lists)
ArrayList<String> arrayList = new ArrayList<>();`
动态数组,可变大小;高效的随机访问和快速尾部插入;
缺点:中间插入和删除相对较慢。
数据类型只能是引用数据类型
- 增加 .add()
- 访问 .get(int index)
- 修改 .set(int index, E element)
- 删除 .remove(int index或者 “内容”)
- 计算大小 .size()
- 迭代
for (String i: sites) {
System.out.println(i);}
- 排序 java.util.Collections
Collections.sort(sites)
基本数据类型与其包装类
| 基本类型 | 引用类型 |
|---|---|
| boolean | Boolean |
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
链表
java.util.LinkedList;
List<Integer> linkedList = new LinkedList<>();
双向链表,元素之间通过指针连接。插入和删除元素高效,迭代器性能好。
缺点:随机访问相对较慢。
- 开头添加元素 .addFirst();
- 结尾添加元素 .addLast();
- 开头/结尾移除元素 .removeFirst/removeLast();
public class ListNode {
// 结点的值
int val;
// 下一个结点
ListNode next;
// 节点的构造函数(无参)
public ListNode() {
}
// 节点的构造函数(有一个参数)
public ListNode(int val) {
this.val = val;
}
// 节点的构造函数(有两个参数)
public ListNode(int val, ListNode next) {
this.val = val;
this.next = next;
}
}
集合(Sets)
用于存储不重复的元素,常见的实现有 HashSet 和 TreeSet。
Set<String> hashSet = new HashSet<>();
Set<Integer> treeSet = new TreeSet<>();
HashSet:
特点: 无序集合,基于HashMap实现。
优点: 高效的查找和插入操作。
缺点: 不保证顺序。
TreeSet:
特点:TreeSet 是有序集合,底层基于红黑树实现,不允许重复元素。
优点: 提供自动排序功能,适用于需要按顺序存储元素的场景。
缺点: 性能相对较差,不允许插入 null 元素。
映射(Maps)
用于存储键值对,常见的实现有 HashMap 和 TreeMap。
Map<String, Integer> hashMap = new HashMap<>();
Map<String, Integer> treeMap = new TreeMap<>();
HashMap:
特点: 基于哈希表实现的键值对存储结构。
优点: 高效的查找、插入和删除操作。
缺点: 无序,不保证顺序。
TreeMap:
特点: 基于红黑树实现的有序键值对存储结构。
优点: 有序,支持按照键的顺序遍历。
缺点: 插入和删除相对较慢。
栈(Stack)
先进后出
Stack<Integer> stack = new Stack<>();
队列(Queue)
先进先出
Queue<String> queue = new LinkedList<>();
堆(Heap)
PriorityQueue<Integer> minHeap = new PriorityQueue<>();
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(Collections.reverseOrder());
树(Trees)
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) { val = x; }
}
字符串
- java.lang.String 类代表字符串,使用的时候不需要导包
- 字符串的内容是不会发生改变的,他的对象在创建后不能被更改
创建方式
- 直接赋值
String s1 = "abc"
- 使用new的方式获取一个字符串对象
String s2 = new String()
- 传递一个字符串,根据传递的字符串内容再创建一个新的字符串对象
String s3 = new String("abc")
- 传递一个字符数组,根据字符数组的内容再创建一个新的字符串对象
char [] chs ={'a', 'b', 'c', 'd'}
String s4 = new String(chs)
修改字符串内容时,将字符串转换成字符数组,再变回字符串
- 传递一个字节数组,根据字节数组的内容再创建一个新的字符串对象
byte[] bytes = {97, 98, 99, 100};
String s5 = new String(bytes)
会去查找ASCII码,转换成对应的字符串,比如上如例子会输出abcd
在网络中传输的数据其实都是字节信息
StringTable(串池)
当使用双引号直接赋值时,系统会检查该字符串在串池中是否存在,不存在就创建新的,存在的话就复用。使用new方式创建时不会复用。
字符串比较
""比较基础数据类型的时候比较的数据值,引用数据类型比较的是地址值,键盘输入的字符串也是通过new产生的。字符串重写了equals,object类中的equals没有被重写的时候,与相同,比较内存地址。
- boolearn equals 完全一样的结果才是true 否则是false
- boolearn equalsIgnoreCase 忽略大小写比较
boolearn result = s1.equals(s2);
字符串索引
str.charAt(索引)获取str中索引位置的字符
str.length() (字符串中的length是一个方法,所以右括号;数组中是arr.length,是一个属性)
char类型的变量在参与计算的时候自动类型提升为int 查询ascii码表
StringBuilder: 字符串拼接和反转的时候用
看作一个容器,创建之后里面的内容是可变的。打印对象不是地址值,是属性值,因为java已经写好的类,在底层做了特殊处理。
StringBuilder str = new StringBuilder(str);
- 添加元素 str.append(数据)
- 顺序反转 str.reverse()
- 获取长度 str.length()
- 变回成字符串 str.toString()
StringJoiner
StringJoiner(间隔符号)
StringJoiner(间隔符号,开始符号,结束符号)
StringJoiner.add(内容)
StringJoiner.length() 表示的是字符的个数
StringJoiner.toString()
Collection是单列集合的祖宗接口
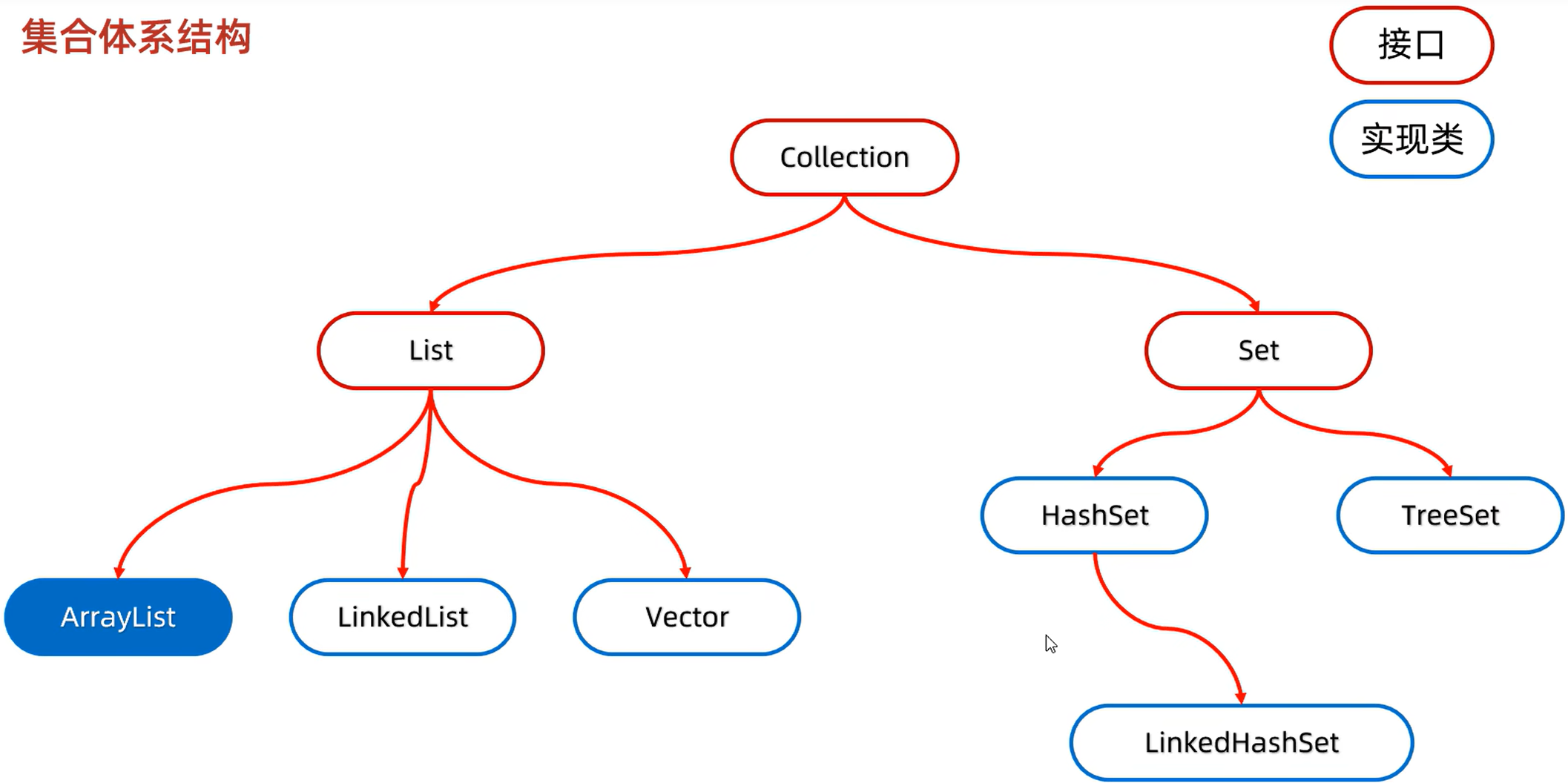
Lis系列集合:添加的元素是有序、可重复、有索引。(有序指的是存和取出来的是有序的)
Set系列集合:添加的元素是无序、不重复、无索引
低层是依赖equals方法进行判断是否存在的。如果集合中存储到时自己自定义对象,也想通过contains方法来判断是否包含,那么一定要重写equals方法
Collection遍历方式
- 迭代器遍历:不依赖索引
list.Iterator()默认返回当前集合的0索引处。haNext判断当前位置是否有元素。next()获取当前位置的元素,并移动指针。
![]()

- 细节注意点:
- 报错NoSuchElementException2
- 迭代器遍历完毕,指针不会复位
- 循环中只能用一次next方法
- 迭代器遍历时,不能用集合的方法进行增加或者删除。如果实在要删除,就要使用迭代器的move方法。
- 增强for遍历
所有单列集合和数组才能用增强for进行遍历。
for (元素的数据类型 变量名:数组或者集合){
}
修改增强for中的变量,不会改变集合中原本的数据
- Lambda表达式遍历
coll.forEach(s -> System.out.printl(s))
List
有索引。当删除元素的时候,会优先调用实参跟形参类型一致的方法
独有遍历方式:列表迭代器
hasPrevious();previous;
可以用列表迭代器的add元素来添加元素。

ArrayList
底层实现是数组。第一次添加元素时,会扩容至10,之后的扩容是1.5倍(老容量+老容量右移一位(也就是减半)),如果一次性加入很多数据,会动态扩容。
LinkedList集合
底层数据结构是双链表,查询慢,增删快
Set集合的实现类
HashSet:无序、不重复、无索引
LinkedHashSet:有序、不重复、无索引
TreeSet: 可排序、不重复、无索引
- HashSet
哈希值:对象的整数表达形式,根据hashCode方法计算出来的int类型的整数;该方法定义在Object类中,所有对象都可以调用,默认使用地址值就行计算;一般情况下会,会重写hashCode方法,利用对象内部的属性值计算哈希值。
对象的哈希值特点
- 如果没有重写hashCode方法,不同对象计算出的哈希值是不同的
- 如果已经重写hashcode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
- 在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能一样。(哈希碰撞)
- hashset要传入自定义对象时,一定要重写equals和hashcode方法。
底层采取哈希表存储数据,JDK8后由数组+链表+红黑树实现
-
LinkedHashSet
数据结构仍然是哈希表,但是每个元素又额外多了一个双链表的机制记录存储的顺序 -
TreeSet
基于红黑树的数据结构实现的。
需要重写排序的规则
平衡二叉树
任意节点的左右子树高度差不超过1
红黑树
是一种特殊的二叉查找树,每个节点都可以是红或黑,不是高度平衡的。满足特有的红黑规则
规则:
- 每一个节点是红色的,或者是黑色的
- 根节点必须是黑色
- 叶节点是黑色的
- 两个红色节点不能相连
- 往意节点到所有后代叶节点的简单路径上,黑色节点数量相同;
- 红黑树在添加节点时,添加的节点默认是红色的
Stream:用于操作集合或者数组的数据,结合了Lambda表达式
File类:可以是文件或文件夹
只能对文件本身进行操作,不能读写文件里面存储的数据。File对象可以指代一个不存在的文件路径
- File(String pathname)
- File.separator; .length()获取当前文件的字节数;.exists();getName()获得文件的名称(包含后缀);
IO流:用于读取数据(读写文件或网络中的数据)
字符集
ASCII字符集
标准ASCII使用1个字节存储一个字符,首位是0,总共可表示128个字符。只有英文、数字、符号等,占1个字节。
GBK(国标)
一个中文字符编码成两个字节的形式存储。GBK兼容了ASCII字符集;汉字的第一个字节的第一位必须是1。汉字占2个字节,英文、数字占1个字节。
Unicode字符集(统一码,也叫万国码)
- UTF-32 4个字节表示一个字符
- UTF-8 :
可变长编码方案,共分四个长度区:1个字节,2个字节,3个字节,4个字节;
英文字符、数字等只占1个字节,汉字字符占用3个字节。
![]()
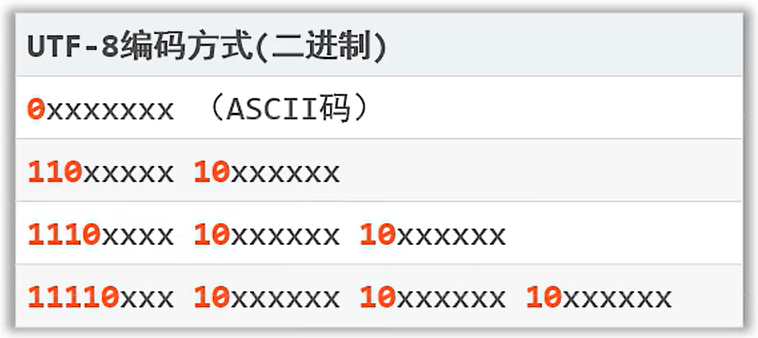
字符编码和解码时候所使用的字符集必须一致,否则会乱码。英文和数字一般不会乱码。
异常
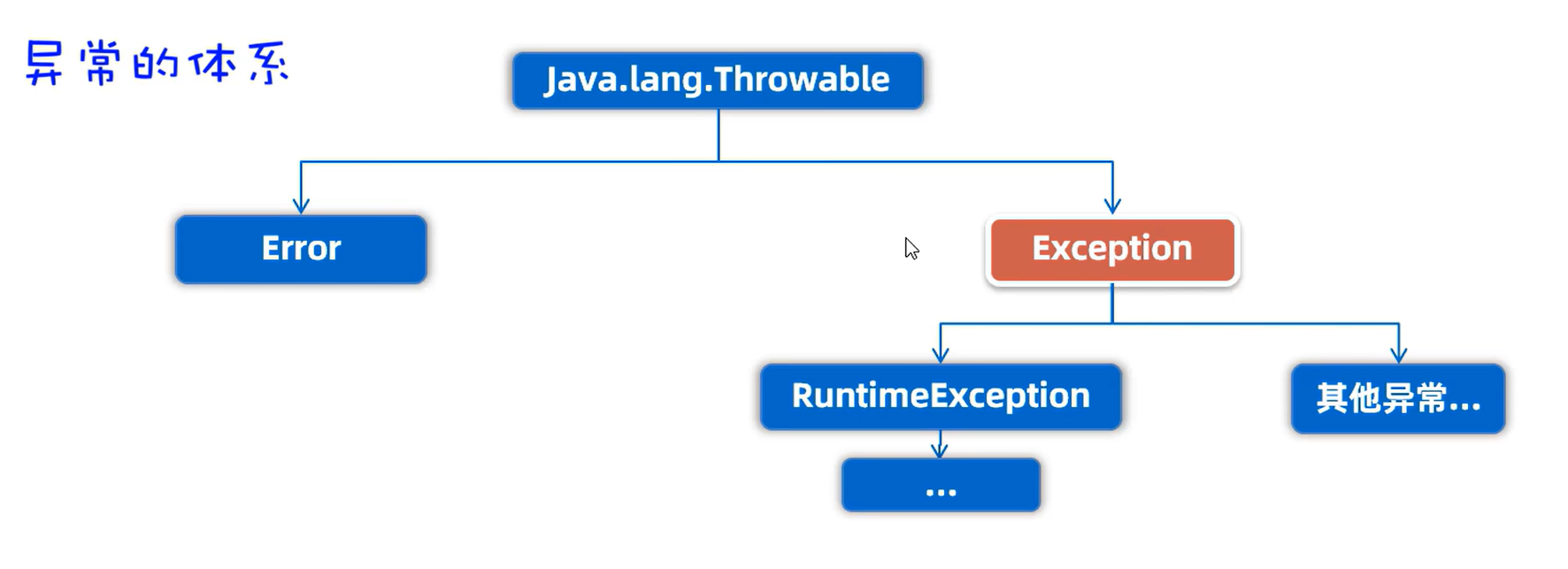
RuntimeException是运行时异常,编译阶段不会出现错误提醒,运行时出现的异常
处理异常(alt+回车抛出异常,ctrl+alt+T捕获try-catch)
- 捕获异常,记录异常并响应合适的信息给用户
- 捕获异常,尝试重新修复
释放资源
- try-catch-finally:无论try中的程序是正常执行了,还是出现了异常,最后都一定会执行finally区,除非JVM终止(System.exit(0))。不要再finally中return数据。
作用:一般用于在程序执行完成后进行资源的释放操作(专业级做法)。
try{
...
}catch(IOException e){
...
}finally{
}
- try-with-resource:资源对象(流对象)用完之后会自动关闭。资源必须实现AutoCloseable接口。
try(定义资源1;定义资源2;...){
可能出现异常的代码;
}catch(异常类名 变量名){
异常的处理代码;
}
字节流
字节流适合做一切文件数据的拷贝(音视频,文本)﹔字节流不适合读取中文内容输出。
字符流
字符输出流写出数据后,必须刷新流,或者关闭流
字符流适合做文本文件的操作(读,写)。
reflection
- 加载类,获取类的字节码:Class对象
- 获取类的构造器:Constructor对象
- 获取类的成员变量:Field对象
- 获取类的成员方法:Method对象
![]()




作用:
可以得到一个类的全部成分然后操作;可以破坏封装性;做java框架

 浙公网安备 33010602011771号
浙公网安备 33010602011771号