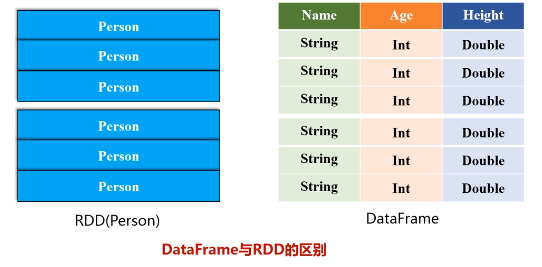
DataFrame与RDD的区别
![]()
从示例文件people.json中创建DataFrame,保存成csv格式的文件
package com.zwq
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession;
object DataFrame {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("DataFrameApp")
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
// val df = spark.read.json("resources/people.json")
// df.show()
val peopleDF = spark.read.format("json").load("resources/people.json")
peopleDF.select("name", "age").write.format("csv").save("resources/people.csv")
}
}
DataFrame常用操作
df.printSchema 打印模式信息
df.select(df("name"), df("age")+1).show()
df.filter(df("age">20).show()
df.groupBy("age").count().show()
//排序
df.sort(df("age").desc).show()
//多列排序
df.sort(df("age").desc, df("name").asc).show()
//对列进行重命名
df.select(df("name").as("username"), df("age")).show()
利用反射机制推断RDD模式 关键:定义一个case Class
package com.zwq
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object RDD2DataFrame {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("DataFrameApp")
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
val peopleDF = spark.sparkContext.textFile("resources/people.txt")
.map(_.split(","))
.map(attributes => Person(attributes(0), attributes(1).trim.toInt))
.toDF()
peopleDF.createOrReplaceTempView("people") //必须注册为临时表才能供下面的查询使用
val personsRDD = spark.sql("select name,age from people where age > 20")
personsRDD.map(t=>s"Name: ${t(0)}, Age: ${t(1)}").show();
// peopleDF.show()
}
}
case class Person(name:String, age:Long)
用编程机制定义RDD模式 对于事先无法 提前定义case class
-
制作 表头
-
制作表中记录
-
拼装在一
package com.zwq
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types._
object RDD2DataFrame2 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("DataFrameApp")
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
val fields = Array(StructField("name", StringType, true), StructField("age", IntegerType, true))
val schema = StructType(fields)
val rowRDD = spark.sparkContext.textFile("resources/people.txt")
.map(_.split(","))
.map(attributes => Row(attributes(0), attributes(1).trim.toInt))
val peopleDF = spark.createDataFrame(rowRDD, schema)
peopleDF.createOrReplaceTempView("people")
val results = spark.sql("SELECT name,age FROM people");
results.show();
}
}
通过JDBC连接MySQL数据库
package com.zwq
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object JDBCApp {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("DataFrameApp")
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
val jdbcDF = spark.read.format("jdbc")
.option("url", "jdbc:mysql://localhost:3306/spark")
.option("driver", "com.mysql.jdbc.Driver")
.option("dbtable", "student")
.option("user", "root")
.option("password", "root")
.load()
jdbcDF.show()
}
}
向MySQl数据库写入数据
package com.zwq
import java.util.Properties
import org.apache.spark.SparkConf
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
object JDBCApp {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("DataFrameApp")
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
val fields = List(StructField("id", IntegerType, true),
StructField("name", StringType, true),
StructField("gender", StringType, true),
StructField("age", IntegerType, true))
val schema = StructType(fields)
val studentRDD = spark.sparkContext.parallelize(Array("3 Rongcheng M 26", "4 Guanhua M 27"))
.map(_.split(" "))
val rowRDD = studentRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).trim, p(3).toInt))
val studentDF = spark.createDataFrame(rowRDD, schema)
val prop = new Properties()
prop.put("user", "root")
prop.put("password", "root")
prop.put("driver", "com.mysql.jdbc.Driver")
studentDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/spark", "spark.student", prop)
}
}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号