Spark编程--文件数据读写
把RDD写入到文本文件中

分布式文件系统HDFS的数据读写

JSON文件数据读写 (注scala 2.11.8运行不了)

读写HBase数据
HBase简介
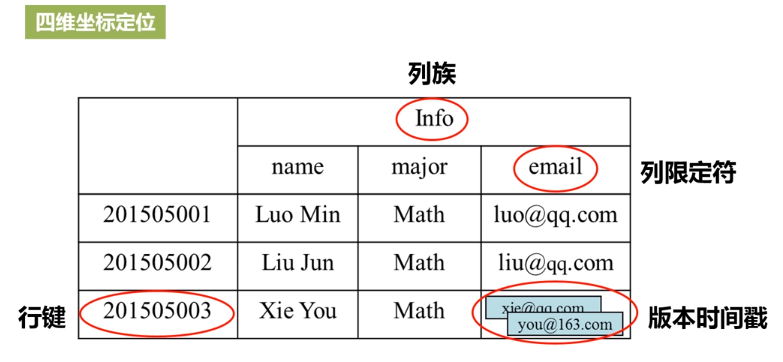
从HBase读取
package com.zwq import org.apache.hadoop.hbase.HBaseConfiguration import org.apache.hadoop.hbase.mapreduce.TableInputFormat import org.apache.hadoop.hbase.util.Bytes import org.apache.spark.{SparkConf, SparkContext} object HBaseApp extends App { val conf = HBaseConfiguration.create(); val sc = new SparkContext(new SparkConf()) conf.set(TableInputFormat.INPUT_TABLE, "student") var stuRDD = sc.newAPIHadoopRDD(conf, classOf[TableInputFormat], classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable], classOf[org.apache.hadoop.hbase.client.Result]) val count = stuRDD.count() println("Students RDD Count:" + count) stuRDD.cache() stuRDD.foreach({ case (_, result) => val key = Bytes.toString(result.getRow) val name = Bytes.toString(result.getValue("info".getBytes, "name".getBytes)) val gender = Bytes.toString(result.getValue("info".getBytes, "gender".getBytes)) val age = Bytes.toString(result.getValue("info".getBytes, "age".getBytes)) println("Row key:" + key + " Name:" + name + " Gender:" + gender + "Age: " + age) }) }

向HBase 写入数据
object SparkWriteHBaseApp extends App { val sparkConf = new SparkConf().setAppName("SparkWriteHBase").setMaster("local") val sc = new SparkContext(sparkConf) val tablename = "student" sc.hadoopConfiguration.set(TableOutputFormat.OUTPUT_TABLE, tablename) val job = new Job(sc.hadoopConfiguration) job.setOutputKeyClass(classOf[ImmutableBytesWritable]) job.setMapOutputValueClass(classOf[Result]) job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]]) val indataRDD = sc.makeRDD(Array("3,Rongcheng,M,26", "4,Guanhua,M,27")) val rdd = indataRDD.map(_.split(",")).map { arr => { val put = new Put(Bytes.toBytes(arr(0))) put.add(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes(arr(1))) put.add(Bytes.toBytes("info"), Bytes.toBytes("gender"), Bytes.toBytes(arr(2))) put.add(Bytes.toBytes("info"), Bytes.toBytes("age"), Bytes.toBytes(arr(3).toInt)) (new ImmutableBytesWritable, put) } } rdd.saveAsNewAPIHadoopDataset(job.getConfiguration) }
项目pom.xml 文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.zwq</groupId> <artifactId>sparkfirst</artifactId> <version>1.0</version> <inceptionYear>2008</inceptionYear> <properties> <scala.version>2.11.8</scala.version> <spark.version>2.4.5</spark.version> <hbase.version>2.1.4</hbase.version> </properties> <repositories> <repository> <id>scala-tools.org</id> <name>Scala-Tools Maven2 Repository</name> <url>http://scala-tools.org/repo-releases</url> </repository> </repositories> <pluginRepositories> <pluginRepository> <id>scala-tools.org</id> <name>Scala-Tools Maven2 Repository</name> <url>http://scala-tools.org/repo-releases</url> </pluginRepository> </pluginRepositories> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>${hbase.version}</version> <exclusions> <exclusion> <groupId>jdk.tools</groupId> <artifactId>jdk.tools</artifactId> </exclusion> <exclusion> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-common</artifactId> <version>${hbase.version}</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-server</artifactId> <version>${hbase.version}</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-mapreduce</artifactId> <version>${hbase.version}</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-protocol</artifactId> <version>${hbase.version}</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.4</version> <scope>test</scope> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> <configuration> <scalaVersion>${scala.version}</scalaVersion> <args> <arg>-target:jvm-1.5</arg> </args> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-eclipse-plugin</artifactId> <configuration> <downloadSources>true</downloadSources> <buildcommands> <buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand> </buildcommands> <additionalProjectnatures> <projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature> </additionalProjectnatures> <classpathContainers> <classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer> <classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer> </classpathContainers> </configuration> </plugin> </plugins> </build> <reporting> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <configuration> <scalaVersion>${scala.version}</scalaVersion> </configuration> </plugin> </plugins> </reporting> </project>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号