
Spark编程--分区
分区
分区的作用和原则
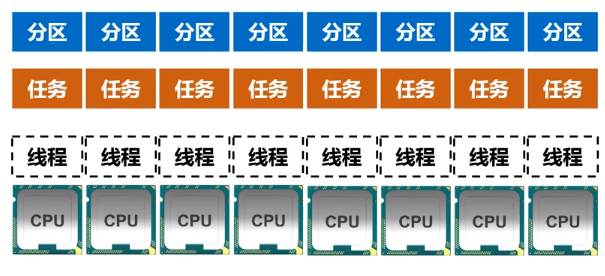
分区第一个作用增加程序的并行度实现分布式计算
分区第二个作用减少通信开销



spark.default.parallelism
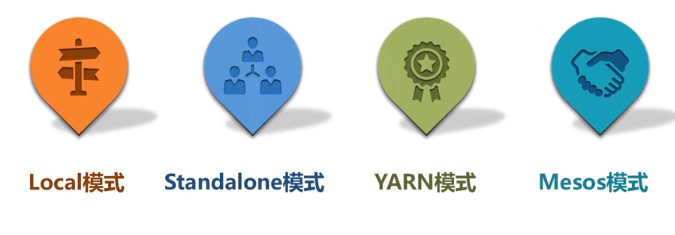
Local模式 默认为本地机器的CPU 数目
Apache Mesos模式 没有设置时,默认分区数目为8
Standalone模式和YARN模式 规则:集群中所有CPU核心数目总和 spark.default.parallelism 中的最大值
设置分区的方法
创建RDD时手动指定分区个数
sc.textFile(path, partitionNum)
使用repartition分法重新设置分区个数

自定义分区方法
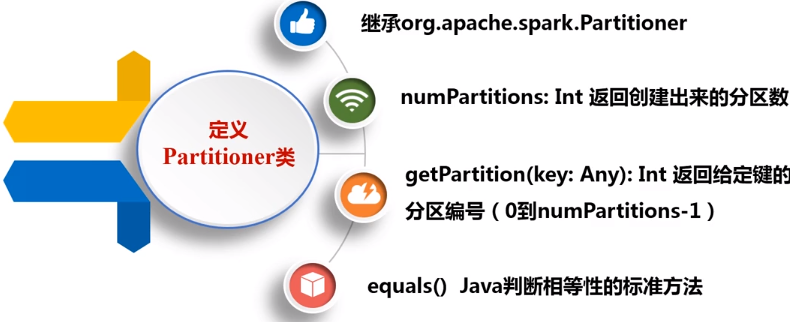
1 package com.zwq 2 import org.apache.spark.{Partitioner, SparkConf, SparkContext} 3 4 class MyPartitioner(numParts: Int) extends Partitioner { 5 override def numPartitions: Int = numParts 6 //分区号获取函数 7 override def getPartition(key: Any) = { 8 key.toString.toInt % 10 9 } 10 } 11 12 13 object TestPartitioner extends App { 14 val conf = new SparkConf().setAppName("testPartitioner").setMaster("local") 15 var sc = new SparkContext(conf) 16 17 val data = sc.parallelize(1 to 10, 5) 18 19 //根据尾号转变为10个分区,分别写到10个文件中 20 21 data.map((_, 1)).partitionBy(new MyPartitioner(10)).map(_._1).saveAsTextFile("partitioner") 22 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号