

🧬 C# 神经网络计算库和问题求解
Andrew Kirillov 著
Conmajia 译
2019 年 1 月 12 日原文发表于 CodeProject(2006 年 11 月 19 日),已获作者本人授权。
本文介绍了一个用于神经网络计算的 C# 库,并展示了如何用这个函数库进行问题求解。
这个库最终命名为 ANNT(Artificial Neural Networks Technology),是 AForge.NET 科学计算库 AForge.Neuro 的组成部分。AForge.NET 是 Andrew Kirillov 的杰作之一,主要用于计算机视觉、人工智能、机器学习、图像处理、机器人等领域。
简介
众所周知,很多问题在求解时难于找到一个正式的算法。这类问题有些找不到简单的传统方法解决,有些甚至没有适合的解法。若是应用神经网络算法,则往往可以得到较为满意的结果。神经网络的研究发端于 20 世纪 50 年代,但在当时由于各种条件限制,加之能应用处理的任务数量很少,没有太大实用价值。到了 70 年代,随着多层神经网络和反向传播算法出现,这一领域又再次繁荣起来。众多研究者开始探索神经网络,创造了各种神经结构,并用这些结构求解许多不同的问题。如今,神经网络广泛应用于分类、识别、逼近、预测、聚类、记忆模拟等任务,并且适用范围还在不断扩大。
本文介绍了一个用于神经网络计算的 C# 库。它实现了几种常用的神经网络结构及训练算法,如反向传播、Kohonen 自组织映射、弹性网络、三角规则学习和感知器学习。下面是演示的几个例子:
- 分类(用感知器学习算法训练的单层神经网络)
- 近似(采用反向传播学习算法训练的多层神经网络)
- 时间序列预测(采用反向传播学习算法训练的多层神经网络)
- 颜色聚类(Kohonen 自组织映射)
- 旅行商问题(弹性网络)
文章开头的源码和演示文件中包含了以上内容和一些没有列出的例子。
这篇文章不是讲解神经网络基础理论的入门书籍,如果你一窍不通,相关的理论和代码在互联网上有大把资源可用。本文假设读者对神经网络已经具备了一定的了解,专注于讨论用于神经网络计算的 C# 库,以及如何把它应用于求解问题。
使用方法
设计一个函数库,重点之一是要保证它适应性强,便于理解。与其把几个神经网络实体杂糅到一个类里搞得一团乱麻既不好用也不好看,倒不如把它们分开成几个类更便于使用和学习。有些库坚持把神经元网络和学习算法组合在一起,搞得很难针对同一神经网络开发其他的学习算法。还有些除了在一个类里实现整个神经元网络架构外,压根就没有神经元、神经元层、层网络之类的东西。当然,具体情况具体分析,这种做法好不好也是存在争议的。有些特定情况下并不需要或者难以将网络分层或者没有多层结构,那么这些和成一堆的“大面团子”自然有它可取之处。但是大多数时候,把这些内容各自作为清晰的类处理,不仅更简明易懂,而且可以更容构建新的神经网络结构。
这个库包含了 6 个主要的部分:
Neuron(神经元)- 所有神经元的基类,包含了神经元的权重、输出值、输入值等。
Layer(神经元层)- 神经元的集合,抽象基类。
Network(网络)- 神经元层的集合,抽象基类,包含了铺铜神经网络用到的通用功能。
IActivationFunction(激活函数接口)- 用于激活神经元的激活函数,函数的输出作为神经元的权重输出。
IUnsupervisedLearning(无监管学习接口)- 无监管学习算法的接口,即系统提供输入样本而不提供期望输出。
ISupervisedLearning(监管学习接口)- 监管学习算法的接口,即系统同时提供了输入样本和期望输出。
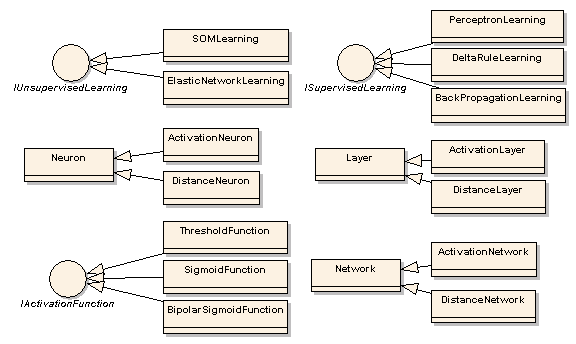
ANNT 提供了以下的神经网络结构:
激活网络
一个单层或多层的神经网络,网络中每个神经元将其输出作为激活函数的输出,参数是其输入与阈值的加权和。该网络经过监督学习算法的训练,可以解决近似、预测、分类和识别等任务。
距离网络
每个神经元将输出作为权重值和输入值之间的距离的神经网络,由单层组成,可作为 Kohonen 自组织映射、弹性网络、Hamming 网络等的基本网络。
采用了不同的学习算法用于训练不同的神经网络:
感知器(perceptron[1])
可以追述到 1957 年的算法,适合作为首次学习的神经网络学习算法。它用于单层激活网络,其中每个神经元具有阈值激活功能。它的应用范围很小,并且限制了线性可分离数据的分类。
增量规则(delta rule[2])
该算法是继感知器学习算法之后的下一步。它利用激活函数的导数,并且可能仅适用于单层激活网络,其中每个神经元都有一个连续的激活函数而不是阈值激活函数。最流行的连续激活功能是单极和双极乙状结肠功能。由于该算法仅适用于一层网络,因此主要局限于某些分类识别任务。
反向传播(back propagation[3])
这是最流行的多层神经网络学习算法之一,最早出现在 1974 年。由于该算法能够训练多层神经网络,其应用范围非常广泛,包括逼近、预测、目标识别等任务。
自组织映射学习(self-organizing map[4])
简称 SOM 算法(Self-Organizing Map),由 Kohonen 提出,是公认的解决集群问题的最著名的无监督学习算法之一。它将神经网络视为节点的二维映射,其中每个节点可以表示一个单独的类,以这种方式组织网络,从而可以找到数据样本之间的相关性和相似性。
弹性网络(elastic net[5])
类似于 SOM 学习算法的思想,但它不将网络神经元视为节点的二维映射,而是将其视为一个环。在学习过程中,环会得到一些形状,表示一个解决方案。旅行商问题是这种学习算法最常见的例子之一。
更多详细内容,可以参考 AForge.NET 科学计算库附带的帮助文档,ANNT 的相关内容可以在 AForge.Neuro 部分找到。
AForge.Neuro 帮助文档演示
分类(classification)
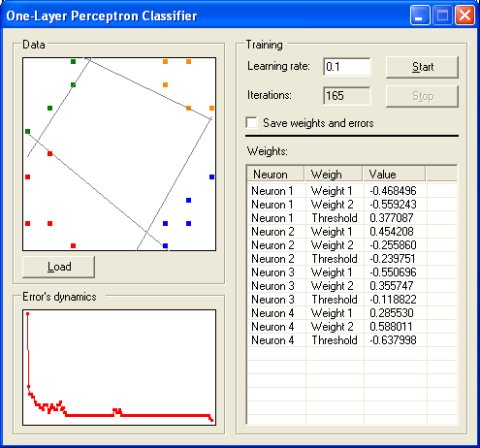
这个例子中使用了一个具有阈值激活函数的单层激活网络和感知器学习算法。神经元的数量等于不同数据类的数量,并且每个神经元都被训练为只对某些类进行分类。将一个数据样本传递给训练后的网络,网络中的一个神经元应被激活(产生等于 1 的输出),但所有其他神经元应被停用(产生等于 0 的输出)。数据样本的类别由激活神经元的数量决定。在这种情况下,如果有多个神经元激活或没有神经元激活,网络就无法正确地分类显示的数据样本。在二维数据样本的情况下,每个神经元的权重和阈值代表一条线,将一个类与所有其他类分开。
// 准备学习数据
double[][] input = new double[samples][];
double[][] output = new double[samples][];
// 生成感知器
ActivationNetwork network = new ActivationNetwork( new ThresholdFunction( ),
2, classesCount );
// 生成训练器
PerceptronLearning teacher = new PerceptronLearning( network );
// 设置学习速率
teacher.LearningRate = learningRate;
// 循环
while ( ... )
{
// 运行学习程序
double error = teacher.RunEpoch( input, output );
...
}
尽管这个网络结构很简单,但还是可以用于很多分类、识别任务。唯一的限制是它只能区分线性可分离的数据。
逼近(approximation)
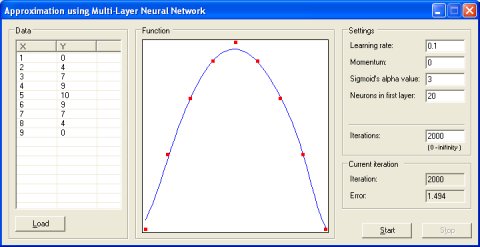
这个例子演示了使用反向传播算法训练的多层神经网络,该算法应用于函数的逼近问题。假设只知道有限数量点上的函数值,但是要计算其他点上的函数,这些点在 min 和 max X 的范围内。在训练阶段,对网络进行训练,以产生正确的函数值。训练完成后,网络用于计算训练过程中网络不可用的其他函数值。
// 准备学习数据
double[][] input = new double[samples][];
double[][] output = new double[samples][];
// 生成多层神经网络
ActivationNetwork network = new ActivationNetwork(
new BipolarSigmoidFunction( sigmoidAlphaValue ),
1, neuronsInFirstLayer, 1 );
// 生成训练器
BackPropagationLearning teacher = new BackPropagationLearning( network );
// 设置学习速率和动量
teacher.LearningRate = learningRate;
teacher.Momentum = momentum;
// 循环
while ( ... )
{
// 运行学习程序
double error = teacher.RunEpoch( input, output ) / samples;
...
}
这种多层神经网络结构不仅可以用于二维函数的逼近,还可以处理任意维的函数。但是别忘了,网络层和神经元的数量以及像 sigmoid[6] \(\alpha\) 值这样的参数可能会极大地影响学习速度。网络的某些错误设置可能会导致无法学习任何内容。所以,小心点,尝试更多的实验。
时间序列预测[7](time series prediction)
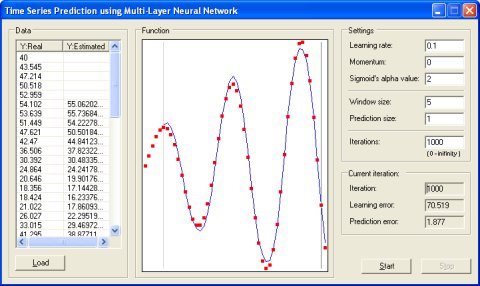
该个例子演示了一种具有反向传播学习算法,但应用于时间序列预测的多层神经网络。时间序列预测问题是一个非常重要和非常普遍的问题,许多研究人员在该领域尝试了许多不同的算法和方法。这个问题最受欢迎的领域之一是交易预测:如果你能预测股票的未来价值或货币兑换率,并且做得很好,那么你就可能成为一个有钱人。在训练阶段,向网络提供一定数量的时间序列先前值,并训练网络预测时间序列的下一个值。训练样本越多,预测模型就越好。另外,一个非常重要的参数是窗口大小,即历史中有多少值用于预测未来的值。窗口越大,你有可能得到更好的模型,但也可能得不到,这取决于时间序列,并且需要实验。但是,更大的窗口意味着会减少所需的培训样本量,因此这是矛盾的需要进行折衷处理。
演示代码与上一个例子相同,只更改了准备学习数据的过程。
颜色聚类(color clusterization)
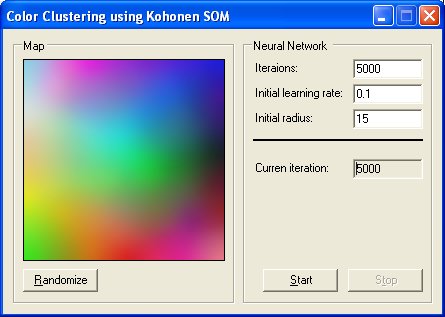
这是一个非常简单的示例,演示了 Kohonen 自组织映射的组织过程。创建了一个由 10000 个随机初始化权重的神经元组成的方形 SOM 网络。每个神经元有三个权重,它们被解释为用于可视化的 RGB 值。因此,网络的初始可视化将显示某种嘈杂的彩色图。在学习过程中,随机的颜色被一个接一个地选择并传递给网络的输入。重复学习迭代,神经网络以这样的方式组织自己:在可视化过程中,它不再像一幅随机的图片,但它得到了某种结构——颜色,近似 RGB 调色板,也更近似 Kohonen 映射。
// 设置神经元权重随机范围
Neuron.RandRange = new DoubleRange( 0, 255 );
// 创建网络
DistanceNetwork network = new DistanceNetwork( 3, 100 * 100 );
// 创建学习算法
SOMLearning trainer = new SOMLearning( network );
// 输入
double[] input = new double[3];
// 循环
while ( ... )
{
// 更新学习速率和半径
// ...
// 准备网络输入
input[0] = rand.Next( 256 );
input[1] = rand.Next( 256 );
input[2] = rand.Next( 256 );
// 运行学习迭代
trainer.Run( input );
...
}
这个例子里,你会发现神经网络总是创建不同的图片,而观察这些图产生的过程是很有趣的,你甚至可以用它们来做个屏保。
你也可以用其他对象来代替颜色,这些对象可以用特征的实值向量描述。在学习过程中将这些特征向量传递到 Kohonen 映射中,它们将自动进行组织,训练完成后就可以查看二维图,并根据其特征发现哪些对象相似且彼此接近。
旅行商问题(traveling salesman problem)
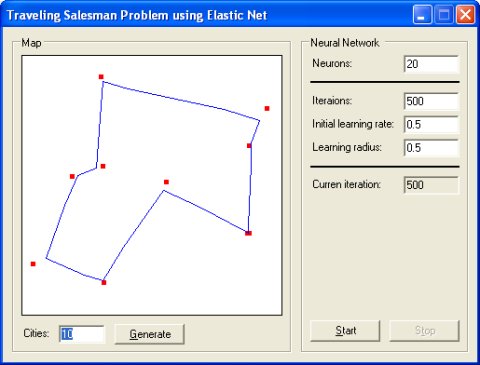
旅行商问题证明了弹性网络的应用。弹性网络在自组织概念上与 SOM 相似,但在神经网络的解释上有所不同。SOM 将神经网络解释为节点的二维映射,而弹性网络将其解释为节点环。在训练阶段,将特征向量逐一呈现给网络,使网络得到某种形状,这代表了一种解决方案。TSP 问题的情况下,每个神经元都有两个权重,表示 (x, y) 坐标。在训练阶段,任意城市的坐标逐一传递到网络的输入端,网络以这样的方式组织其权重,使其代表旅行社的路径。
// 设置随机范围
Neuron.RandRange = new DoubleRange( 0, 1000 );
// 生成网络
DistanceNetwork network = new DistanceNetwork( 2, neurons );
// 生成学习算法
ElasticNetworkLearning trainer = new ElasticNetworkLearning( network );
// 输入
double[] input = new double[2];
// 循环
while ( ... )
{
// 设置网络输入
int currentCity = rand.Next( citiesCount );
input[0] = map[currentCity, 0];
input[1] = map[currentCity, 1];
// 运行训练迭代
trainer.Run( input );
...
}
这种方法的缺点是它不能提供精确的解——神经元的权重可能接近但是不等于城市坐标。这种方法的另一个缺点是城市太多时效率下降。但是,该方法仍不失为神经网络应用的一个很好的证明。
结论
上面的五个例子表明,ANNT 库是灵活的、可重用的,并且很容易用于不同的任务。尽管,由于神经网络体系结构及学习算法种类繁多,仍有许多工作要做,但是,ANNT 可以用于许多不同的问题,并且可以扩展以解决更多的问题。我希望这个库不仅对我接下来的研究工作有用,而且其他不同的研究人员也能从中有所收获。
历史版本
- [12.01.2019] 译文首次发表
- [19.11.2006] 原文首次发表
许可
本文以及任何相关的源代码和文件都是根据 GNU通用公共许可证(GPLv3)授权的。
关于作者

Andrew Kirillov,来自英国🇬🇧,目前就职于 IBM。
Perceptron, Wikipedia ↩︎
Delta Rule, Wikipedia ↩︎
Back Propagation, Wikipedia ↩︎
Self-Organizing Map, Wikipedia ↩︎
Elastic Net Tutorial, Andrei Cimponeriu, Oct. 12, 1999 ↩︎
一种常用的非线性激活函数,其表达式为$$\sigma(x)=\frac{1}{1+e^{-x}}.$$sigmoid 的缺点在于当输入非常大或者非常小时容易饱和,饱和后神经元梯度趋于 0,即容易导致神经元“死亡”。 ↩︎
时间序列预测法其实是一种回归预测方法,属于定量预测,其基本原理是;一方面承认事物发展的延续性,运用过去时间序列的数据进行统计分析,推测出事物的发展趋势;另一方面充分考虑到偶然因素影响而产生的随机性,为了消除随机波动的影响,利用历史数据进行统计分析,并对数据进行适当处理,进行趋势预测。 ↩︎
if(jQuery('#no-reward').text() == 'true') jQuery('.bottom-reward').addClass('hidden');

 浙公网安备 33010602011771号
浙公网安备 33010602011771号