截取处理UTF-8编码字符串
前置知识
编码占用字节数
英文字母和中文汉字在不同字符集编码下的字节数
英文字母:
字节数 : 1;编码:GB2312
字节数 : 1;编码:GBK
字节数 : 1;编码:GB18030
字节数 : 1;编码:ISO-8859-1
字节数 : 1;编码:UTF-8
字节数 : 4;编码:UTF-16
字节数 : 2;编码:UTF-16BE
字节数 : 2;编码:UTF-16LE
中文汉字:
字节数 : 2;编码:GB2312
字节数 : 2;编码:GBK
字节数 : 2;编码:GB18030
字节数 : 1;编码:ISO-8859-1
字节数 : 3;编码:UTF-8
字节数 : 4;编码:UTF-16
字节数 : 2;编码:UTF-16BE
字节数 : 2;编码:UTF-16LE
参考:https://blog.csdn.net/it_qingfengzhuimeng/article/details/102517212
UTF-8编码规律
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种unicode的实现方式。其它实现方式还包含UTF-16和UTF-32,只是在互联网上基本不用。反复一遍,这里的关系是,UTF-8是Unicode的实现方式之中的一个。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它能够使用1~6个字节表示一个符号,依据不同的符号而变化字节长度。
UTF-8的编码规则非常easy,仅仅有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是同样的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,所有为这个符号的unicode码。
如表:
1字节 0xxxxxxx
2字节 110xxxxx 10xxxxxx
3字节 1110xxxx 10xxxxxx 10xxxxxx
4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字节 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字节 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
参考:https://blog.csdn.net/weixin_33744141/article/details/85633757
UTF-8编码规律观察
#include <stdio.h>
#include <iostream>
#include <string.h>
#include <stdlib.h>
#include <bitset>
#include <bits/stdc++.h>
using namespace std;
int main()
{
//char string[100]={0};
char* a="我a";
for(int i=0;i<strlen(a);i++)
{
unsigned int intvalue = 0;
intvalue = (unsigned int)a[i];//需要强转成无符号,才能转换成正确的二进制表示
bitset<8> str(intvalue);
cout<<"十进制:"<<intvalue<<endl;
cout<<"二进制:"<<str<<endl;
}
return 0;
}
表示一个n位的二进制数,<>中填写位数;
执行结果如下:
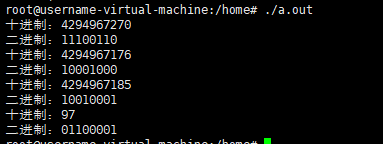
bitset用法
#include <bitset>
int value=3;
bitset< n > s(value);
cout<<s<<endl;
正文 UTF-8字符串截取
应用场景:当一个字符串需要拷贝到一个数组空间中,而且(数组空间字节大小)<(这个字符串所占用的字节大小)的时候,就需要将这个字符串从某处截断,以保存到更小的数组空间中。但是在截断中文字符串或者中英文混合字符串的时候,由于终端字符串占用字节数不为1,所以截断需要考虑以整个文字为单位进行截断,否则将中文切成两份就会导致乱码问题。
截断规则:首先将长字符串拷贝到空间更小的数组中,拷贝大小为数组空闲大小,然后判断该数组的末尾是否存在一个不完整字符,如果存在就用'\0'截断这个字符。
方法1:
static BOOL32 CorrectUtf8Str(s8 * pStr, const u16 wStrLen)
{
if ( !pStr )
{
return FALSE;
}
#ifdef _UTF8
u8 byFollowLen = 0; // utf8整字所包含的字节,除掉领头的11xx xxxx
u8 byCountLen = 0;
for ( u16 wLoop = wStrLen; wLoop > 0; wLoop--)
{
if ( pStr[wLoop-1] != '\0')
{
u8 byTmpVal = (u8)pStr[wLoop-1];
if( (byTmpVal & 0xc0 ) == 0x80 )//不是字符第一个标志位字节,跳过
{
byCountLen++;//用来表示该字符除首位字节(表示位)外,其他末尾有多少个字节
continue;
}
else if ( (byTmpVal & 0xfe ) == 0xfc ) // 1111 110x 后面跟5个10xx xxxx,下同
{
byFollowLen = 5;
}
else if ( (byTmpVal & 0xfc ) == 0xf8 ) // 1111 10xx: 4
{
byFollowLen = 4;
}
else if ( (byTmpVal & 0xf8 ) == 0xf0 ) // 1111 0xxx: 3
{
byFollowLen = 3;
}
else if ( (byTmpVal & 0xf0 ) == 0xe0 ) // 1110 xxxx: 2
{
byFollowLen = 2;
}
else if ( (byTmpVal & 0xe0 ) == 0xc0 ) // 110x xxxx: 1
{
byFollowLen = 1;
}
else
{
byFollowLen = 0;
}
if(byCountLen == byFollowLen)
{
return FALSE;
}
// if ( wLoop + byFollowLen > wStrLen ) //超过最大长度,肯定有截断
// {
// pStr[wLoop-1] = '\0';
// return TRUE;
// }
for(u16 wClearLoop = wLoop; wClearLoop < wStrLen + 1; wClearLoop++)
{
pStr[wClearLoop-1] = '\0';
}
return TRUE;
// for ( u8 byLoop = 0; byLoop < byFollowLen; byLoop++)
// {
// if ( pStr[wLoop+byLoop] == '\0' || (pStr[wLoop+byLoop] & 0xc0) != 0x80 ) // 等于 0 或者不是 10xx xxxx的格式,表示有截断
// {
// pStr[wLoop-1] = '\0';
// return TRUE;
// }
// }
}
}
#endif
return FALSE;
}
方法2:
static BOOL32 CorrectUtf8Str(s8 * pStr, const u16 wStrLen)
{
if ( !pStr )
{
return FALSE;
}
#ifdef _UTF8
u8 byFollowLen = 0; // utf8整字所包含的字节,除掉领头的11xx xxxx
for ( u16 wLoop = wStrLen; wLoop > 0; wLoop--)
{
if ( pStr[wLoop-1] != '\0')
{
if ( (pStr[wLoop-1] & 0xfe ) == 0xfc ) // 1111 110x 后面跟5个10xx xxxx,下同
{
byFollowLen = 5;
}
else if ( (pStr[wLoop-1] & 0xfc ) == 0xf8 ) // 1111 10xx: 4
{
byFollowLen = 4;
}
else if ( (pStr[wLoop-1] & 0xf8 ) == 0xf0 ) // 1111 0xxx: 3
{
byFollowLen = 3;
}
else if ( (pStr[wLoop-1] & 0xf0 ) == 0xe0 ) // 1110 xxxx: 2
{
byFollowLen = 2;
}
else if ( (pStr[wLoop-1] & 0xe0 ) == 0xc0 ) // 110x xxxx: 1
{
byFollowLen = 1;
}
else
{
byFollowLen = 0;
}
if ( wLoop + byFollowLen > wStrLen ) //超过最大长度,肯定有截断
{
pStr[wLoop-1] = '\0';
return TRUE;
}
for ( u8 byLoop = 0; byLoop < byFollowLen; byLoop++)
{
if ( pStr[wLoop+byLoop] == '\0' || (pStr[wLoop+byLoop] & 0xc0) != 0x80 ) // 等于 0 或者不是 10xx xxxx的格式,表示有截断
{
pStr[wLoop-1] = '\0';
return TRUE;
}
}
}
}
#endif
return FALSE;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号