实验一
作业一
(1)实验内容
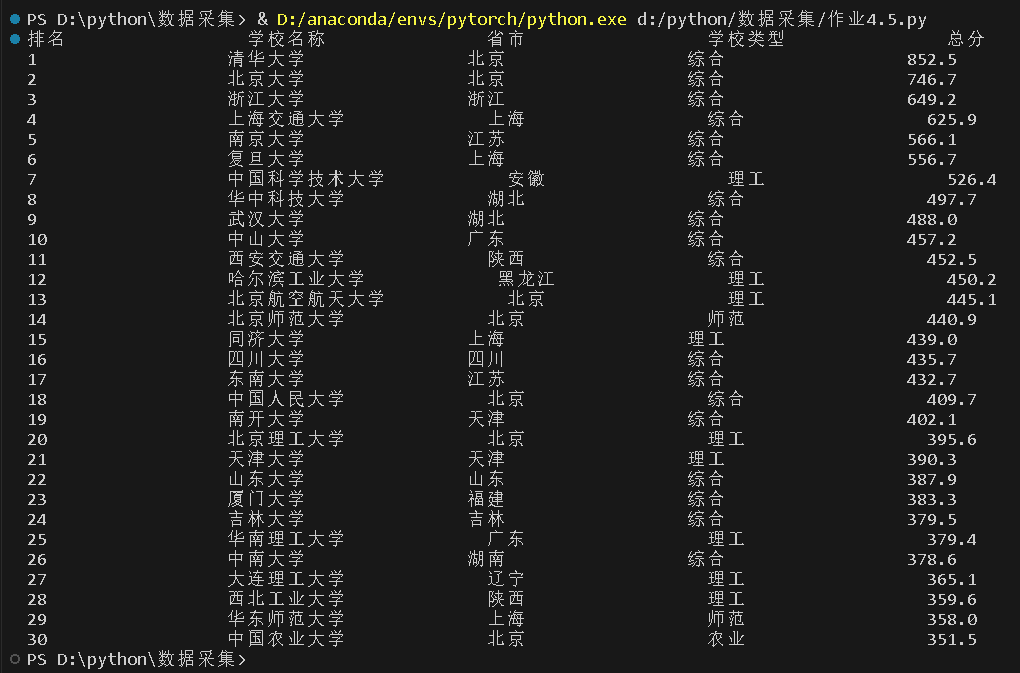
o 要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
o 输出信息:
排名 学校名称 省市 学校类型 总分
1 清华大学 北京 综合 852.5
2 ......
代码如下:
import urllib.request
from bs4 import BeautifulSoup
url = r'http://www.shanghairanking.cn/rankings/bcur/2020'
resp = urllib.request.urlopen(url)
data = resp.read().decode()
soup = BeautifulSoup(data,"lxml")
tags = soup.select('tbody[data-v-4645600d] tr')
print("%-20s%-20s%-20s%-20s%-20s" % ('排名','学校名称','省市','学校类型','总分'))
for tag in tags:
rank = tag.div.text.strip()
name = tag.find(name='a',attrs={'class':'name-cn'}).text.strip()
t = tag.find_all(name='td',attrs={'data-v-4645600d':''})
city = t[2].text.strip()
types = t[3].text.strip()
score = t[4].text.strip()
print("%-20s%-20s%-20s%-20s%-20s" % (rank,name,city,types,score))
结果如下:
(2)心得体会
第一次使用BeautifulSoup,了解并巩固了BeautifulSoup的基本用法,与re相比,BeautifulSoup更加容易上手。由于该网址的翻页不是通过改变url,暂时还不会实现翻页。
作业二
(1)实验内容
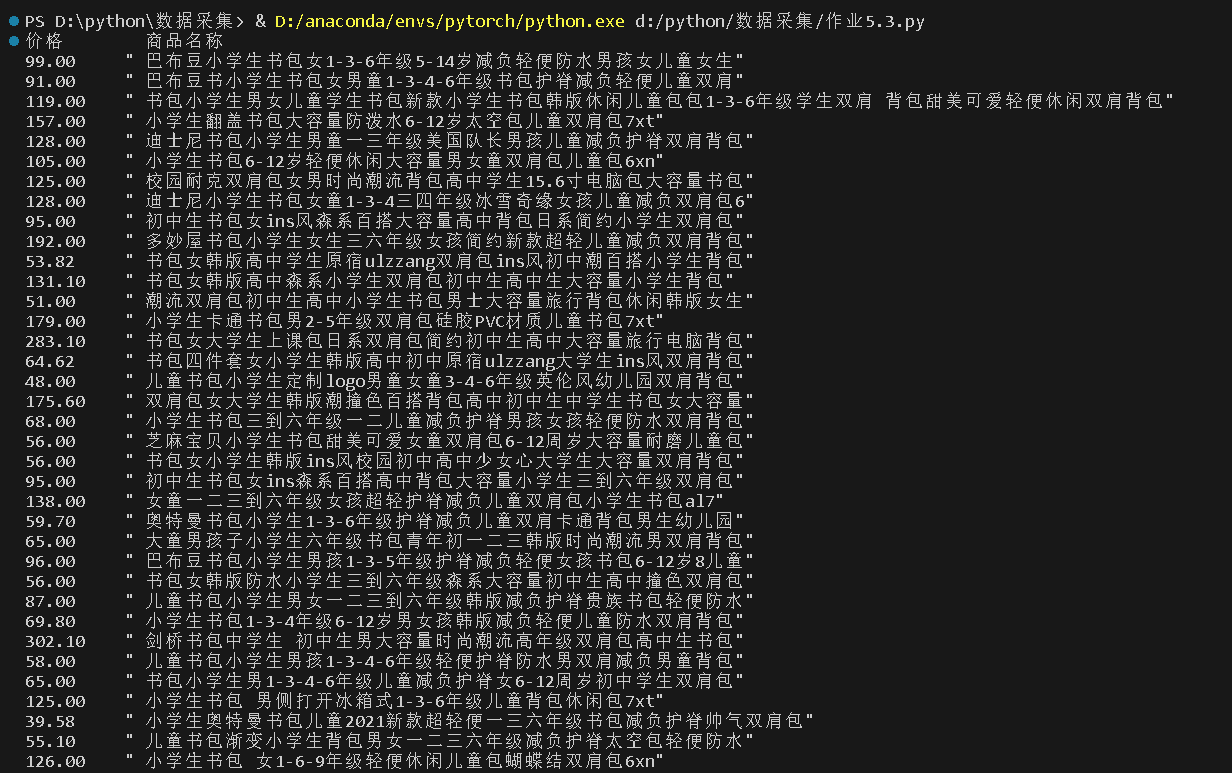
o 要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
o 输出信息:
序号 价格 商品名
1 65.00 xxx
2 ......
代码如下:
import urllib.request
import re
url=r'http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input'
data = urllib.request.urlopen(url).read().decode('gbk')
s = '<span class="price_n">'
e = '</span>'
s1 = '<a title=.*?href'
print('%-10s%s' % ('价格','商品名称'))
m = re.search(s,data)
while m != None:
data = data[m.end():]
n = re.search(e,data)
price = data[5:n.start()]
m = re.search(s1,data)
name = data[m.start()+9:m.end()-5]
data = data[m.end():]
m = re.search(s,data)
print('%-10s%s' % (price,name))
结果如下:
(2)心得体会
先用BeautifulSoup尝试了一下,挺轻松就做出来了,然后再改用re库,但是因为还不熟悉re库,尝试了很久才做出来,了解了re库search函数的用法
作业三
(1)实验内容
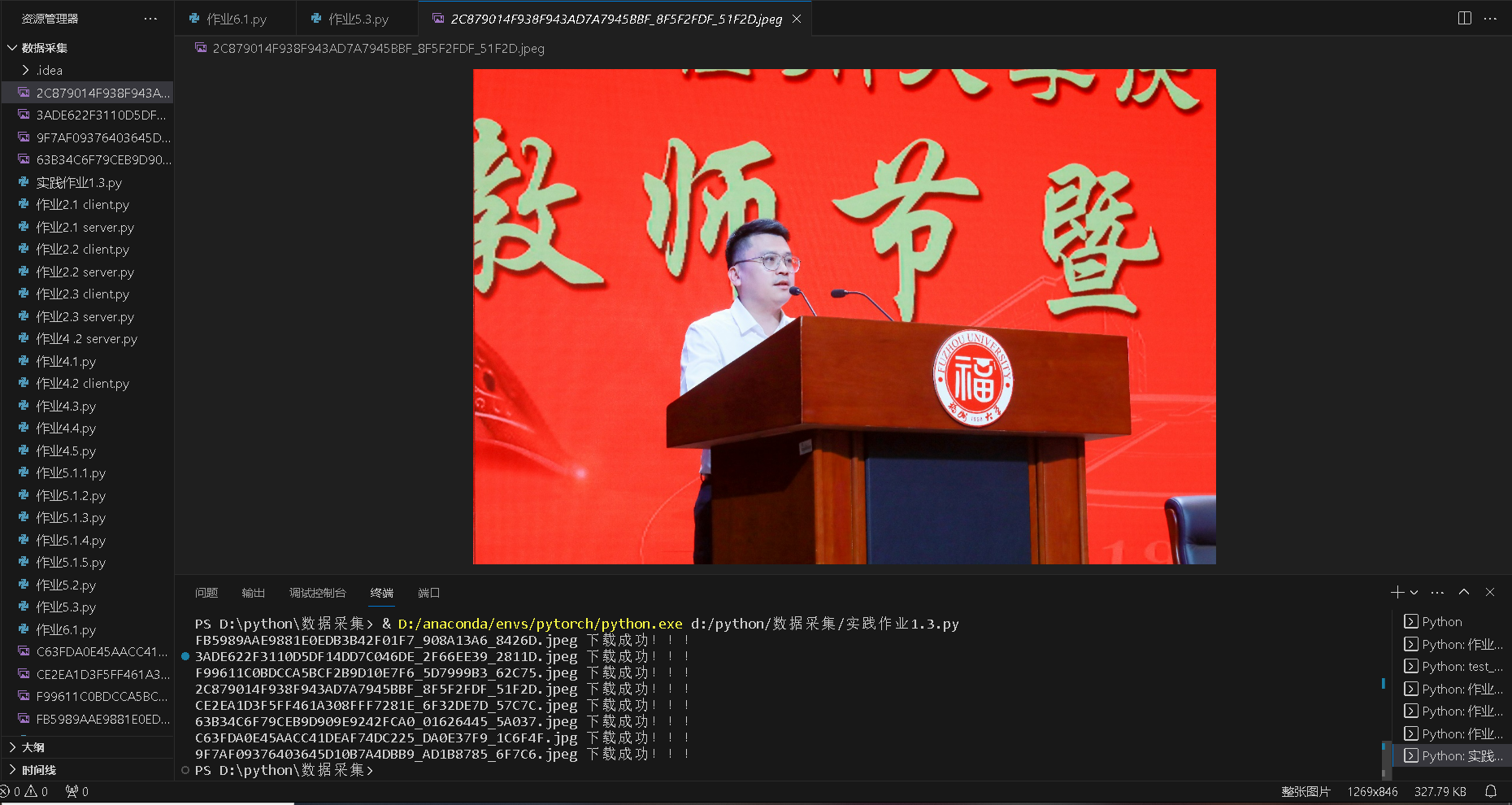
o 要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
o 输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
代码如下:
from bs4 import BeautifulSoup
import urllib.request
url = r'https://xcb.fzu.edu.cn/info/1071/4481.htm'
data = urllib.request.urlopen(url).read().decode()
soup = BeautifulSoup(data,'lxml')
img_list = soup.select("p[class='vsbcontent_img'] img")
for img in img_list:
url = img.attrs['src']
img_url = 'https://xcb.fzu.edu.cn' + url
img_data = urllib.request.urlopen(img_url).read()
# 获取图像路径
filename = url.split('?')[0]
# 获取图像名称
index = filename.rfind('/')
filename = filename[index+1:]
imgPath = './' + filename
with open(imgPath, 'wb') as fp:
fp.write(img_data)
print(filename, '下载成功!!!')
结果如下:
(2)心得体会
这题相对比较简单,只需要找到图片的下载网址,然后发起http请求,保存到本地即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号