B树和B+树的区别
1、B树
B树(也有被称作 B- 树,B-树和B树是同一个东西,统称B树)。本质是一种多路平衡查找树,目的在于提高磁盘的效率,二叉树的查找效率已经很高了,但是如果存储大量信息,这个二叉树的深度就会很高,这些不同深度的信息在硬盘上存储的会很分散,在不同的道上,所以降低了查找效率,而B树可以改善这一问题。

B树的两个明显特点:
- 树内的每个节点都存储数据
- 叶子节点之间无指针相邻
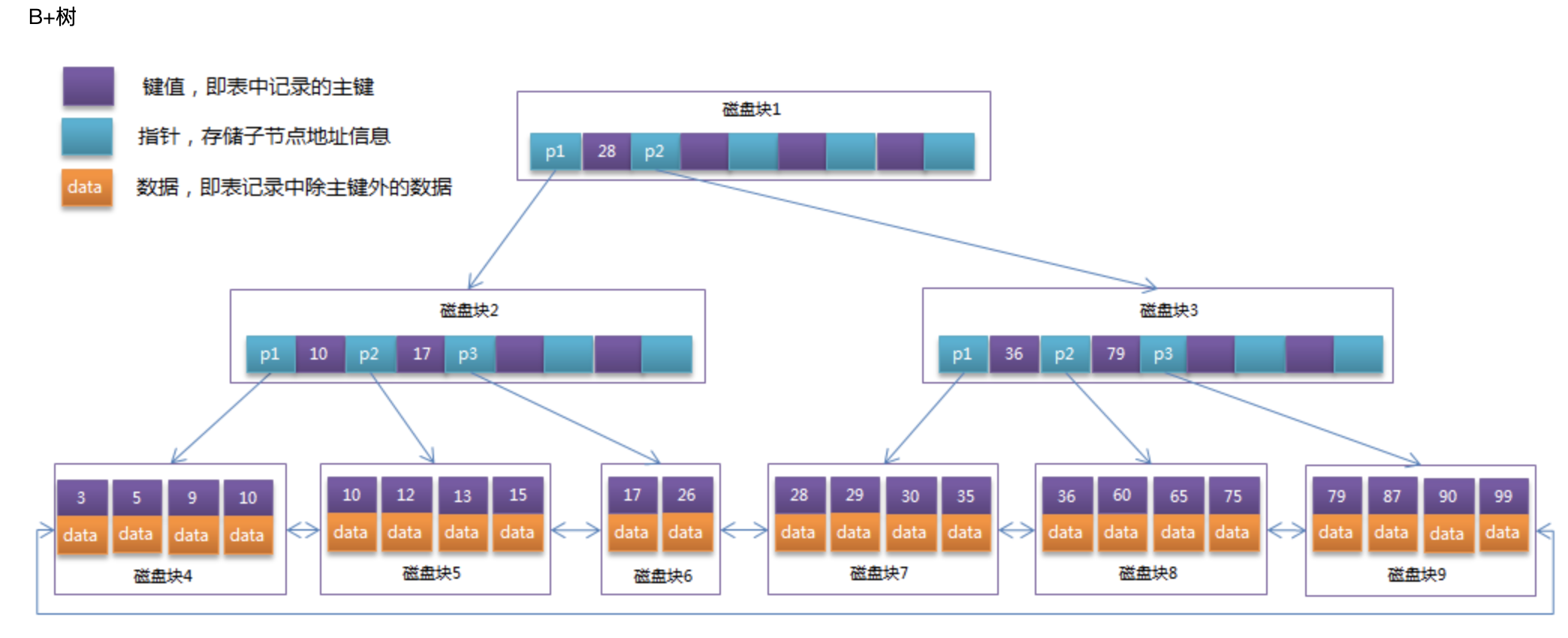
2、B+树
B+树是B树的一个变种,它把所有的关联数据都存储在叶子结点中,内部结点只存放关键字和孩子指针,因此最大化了内部结点的分支因子。使其更适合实现外存储索引结构。
动态数据结构演示: https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
B+树的两个明显特点:
- 数据只出现在叶子节点
- 所有叶子节点增加了一个链指针
B+树和B树的特点总结:
(1)B树的每个节点都存储数据,因此查询单条数据的时候,B树的查询效率不固定,最好的情况是O(1)。可以认为在做单一数据查询的时候,使用B树平均性能更好。但是,由于B树中各节点之间没有指针相邻,因此B树不适合做一些数据遍历操作。
(2)B+树的数据只出现在叶子节点上,因此在查询单条数据的时候,查询速度非常稳定。因此,在做单一数据的查询上,其平均性能并不如B树。但是,B+树的叶子节点上有指针进行相连,因此在做数据遍历的时候,只需要对叶子节点进行遍历即可,这个特性使得B+树非常适合做范围查询。
因此,猜想关系型数据库Mysql中数据遍历操作比较多,所以用B+树作为索引结构。而非关系型数据库Mongodb是做单一查询比较多,数据遍历操作比较少,所以用B树作为索引结构。
3、关系型VS非关系型
假设,我们此时有两个逻辑实体:学生(Student)和班级(Class),这两个逻辑实体之间是一对多的关系。毕竟一个班级有多个学生,一个学生只能属于一个班级。
关系型数据库
我们在关系型数据库中,考虑的是用几张表来表示这二者之间的实体关系。常见的无外乎是,一对一关系,用一张表就行。一对多关系,用两张表。多对多关系,用三张表。
那这里,我们需要用两张表表示二者之间逻辑关系,如下所示
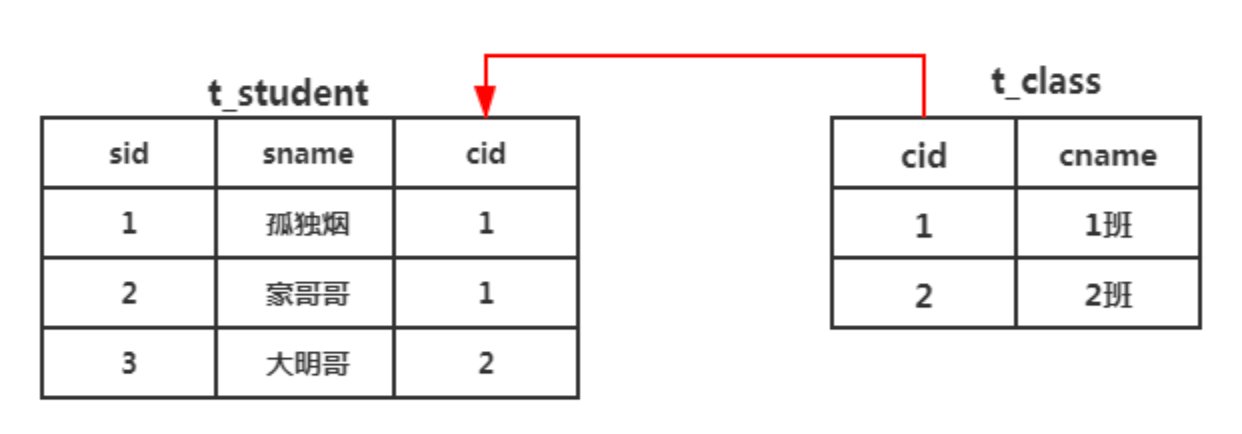
此时要查cname为1班的班级,有多少学生,假设cname这列,我们建了索引。
执行SQL,如下所示!
SELECT *
FROM t_student t1, (
SELECT cid
FROM t_class
WHERE cname = '1班'
) t2
WHERE t1.cid = t2.cid这就涉及到了数据遍历操作,因为但凡做这种关联查询,你躲不开join操作的!既然涉及到了join操作,无外乎从一个表中取一个数据,去另一个表中逐行匹配,如果索引结构是B+树,叶子节点上是有指针的,能够极大的提高这种一行一行的匹配速度!
非关系型数据库
可以设计两个集合,然后执行两次查询去获得结果!但是不符合非关系型数据库的设计初衷。
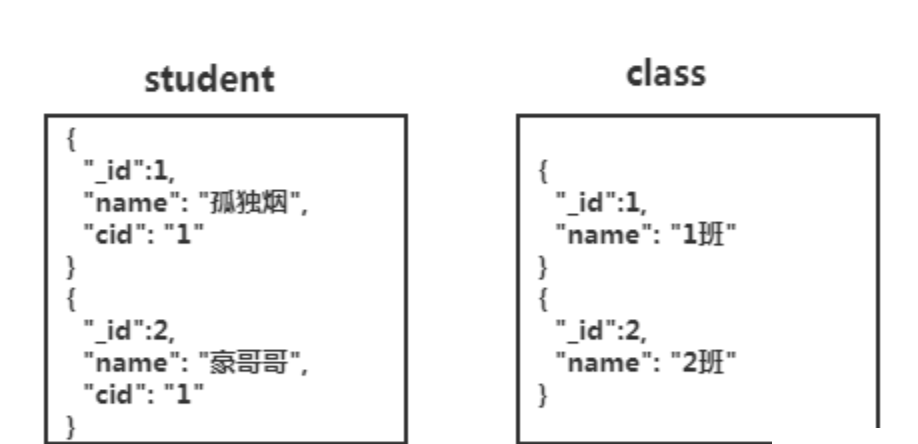
在MongoDB中,根本不推荐这么设计。虽然,Mongodb中有一个lookup操作,可以做join查询。这个lookup操作应该不会经常使用,如果需要经常使用它,那么其实就使用了错误的数据存储了(数据库):如果有相关联的数据,应该使用关系型数据库(SQL)。
因此,合理的设计应该如下
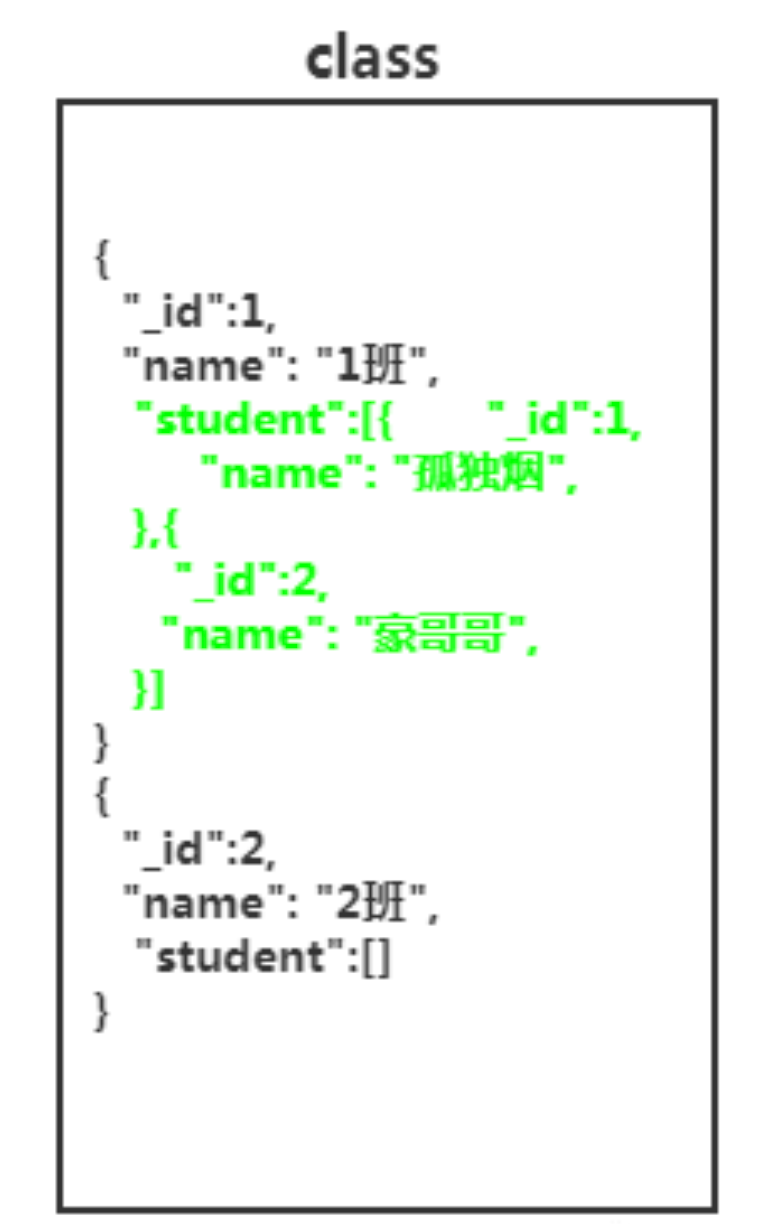
假设name这列建了索引,只需执行一次语句
db.class.find( { name: '1班' } )这就是一种单一数据查询!毕竟你不需要去逐行匹配,不涉及遍历操作,幸运的情况下,有可能一次IO就能够得到你想要的结果。
由于关系型数据库和非关系型数据的设计方式上的不同,导致在关系型数据中遍历操作比较常见,因此采用B+树作为索引比较合适。而在非关系型数据库中单一查询比较常见,因此采用B树作为索引比较合适。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号