【GCC编译器】Swing Modulo Scheduling
1. SMS 在 GCC 中的实现
1.1. 一些基本概念
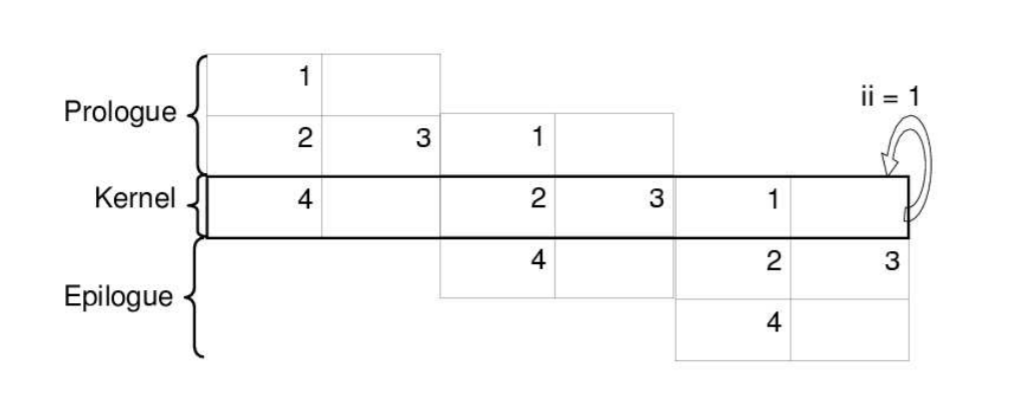
(1)软流水(Software pipelining )是一种通过重叠不同迭代的指令,使其并行执行,从而改进循环中指令调度的技术。关键思想是找到一种操作模式(称为内核代码),当反复迭代时,它会产生这样一种效果,即在前一个迭代完成之前启动下一个迭代。下图为包含4条指令的循环经过软流水调度后的结果
(2)模调度(Modulo scheduling)是一种实现软流水的方法,聚焦于最小化循环的平均周期计数,从而优化性能。
(3)在本文中,我们描述了SMS(Swing Modulo Scheduling)在GCC中的实现,这是一种模调度技术,它同时关注于降低调压器压力。
1.2. SMS 处理的循环需要满足如下约束:
(1)循环的迭代次数是已知的(或者生成运行时动态测试迭代次数的代码,并根据测试结果选择是否执行软流水)
(2)循环体是单个BB块
1.3. SMS 按如下步骤处理循环:
1.3.1. 构建数据依赖图(DDG),ddg的node表示RTL指令,ddg的edges表示循环内部和循环外部的依赖关系。
1.3.2. 模调度器按照如下步骤处理循环:
(1)计算最小启动间隔(MII)
(2)计算ddg中结点的调度顺序 (Swinging)
(3)调度 kernel
(4)执行模变量扩展
(5)生成填充部分(prologue)和排空部分(epilogue)
(6)生成循环迭代次数的预判断(可选)
2. 结合GCC代码,详细介绍 1.3.2. 的内容
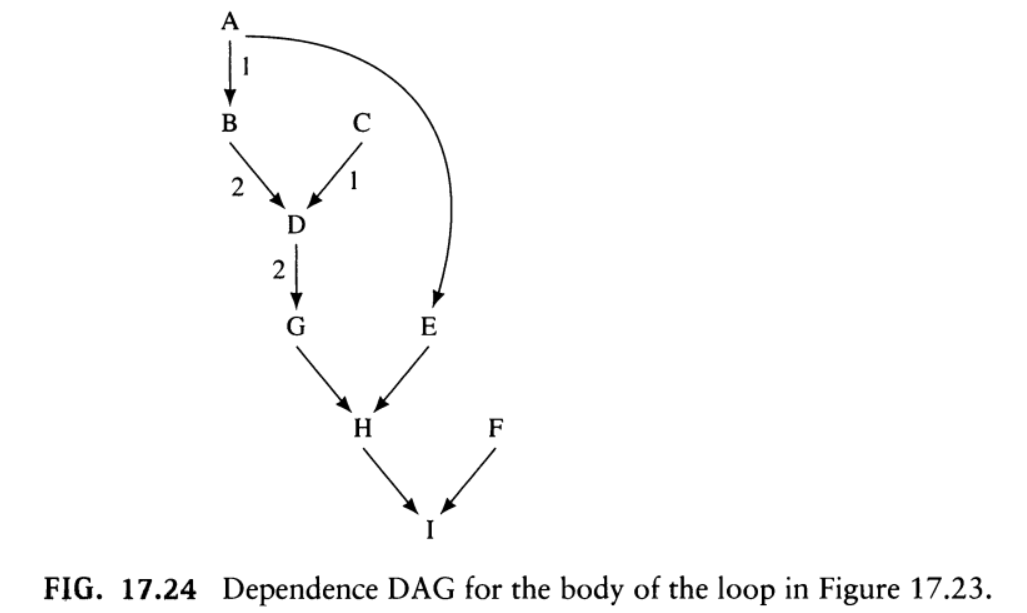
GCC 使用的是展开-压实软流水(unroll-and-compact software pipelining)的软流水方法。它将循环体展开若干次,然后在指令中选择每一步都要启动的重复模式。如果找到这种模式,它就用该模式构造流水的循环体,并用该模式之前和之后的指令构造prologue和epilogue。FIG. 17.23-17.25是鲸书中的举一个例子。这是一种无约束的贪婪调度,其中假设每个cycle上列出的指令都能并行执行,即不考虑寄存器个数和处理机的指令级并行。


2.1. 计算最小启动间隔(MII)
最小启动间隔(MII):通过任何可行的调度,执行循环kernel所需要的周期数下界(可以理解为 硬件资源充足 且 支持指令多发射 的前提下,处理器执行一次循环kernel的代码,所需要的最小cycle)
mii = 1; /* Need to pass some estimate of mii. */
rec_mii = sms_order_nodes (g, mii, node_order, &max_asap);
mii = MAX (res_MII (g), rec_mii);
maxii = MAX (max_asap, MAXII_FACTOR * mii);如果一次调度满足所有的指令间依赖约束及其相关latency,并且避免所有潜在的资源冲突,则调度是可行的。因此,我们计算两个独立的边界:
(1)数据依赖 recMII:基于循环依赖的周期数
(2)资源依赖 resMII:基于资源的可获取性和指令对硬件资源的需求
![]()
计算MII的目的是避免尝试太小的II,从而加快模调度的编译速度。MII作为下界(lower-bound),不会影响调度结果的正确性。
同样,计算MaxII作为上界(upper-bound)也是为了限制II的查找范围,减少编译时长。
所以,II 的尝试区间为 [ MII , MaxII )
2.2. 计算ddg中结点的调度顺序 (Swinging order)
“Swinging” order的目的是,在完成一条指令的调度后,立刻尝试调度DDG中它的前驱指令或后继指令,并使它们尽可能的接近,以缩短虚拟寄存器的活动范围,从而降低寄存器压力。
2.2.1 sms_order_nodes 源码分析
/* Order the nodes of G for scheduling and pass the result in
NODE_ORDER. Also set aux.count of each node to ASAP.
Put maximal ASAP to PMAX_ASAP. Return the recMII for the given DDG. */
static int
sms_order_nodes (ddg_ptr g, int mii, int * node_order, int *pmax_asap)
{
int i;
int rec_mii = 0;
ddg_all_sccs_ptr sccs = create_ddg_all_sccs (g);
nopa nops = calculate_order_params (g, mii, pmax_asap);
if (dump_file)
print_sccs (dump_file, sccs, g);
order_nodes_of_sccs (sccs, node_order);
if (sccs->num_sccs > 0)
/* First SCC has the largest recurrence_length. */
rec_mii = sccs->sccs[0]->recurrence_length;
/* Save ASAP before destroying node_order_params. */
for (i = 0; i < g->num_nodes; i++)
{
ddg_node_ptr v = &g->nodes[i];
v->aux.count = ASAP (v);
}
free (nops);
free_ddg_all_sccs (sccs);
check_nodes_order (node_order, g->num_nodes);
return rec_mii;
}
在计算 res_MII 时调用了函数 sms_order_nodes,该函数做了三件事情
(1)create_ddg_all_sccs :根据 DDG 的回边(backarcs)查找 SCC,并按照 recurrence_length 递减顺序对 SCCS 进行快排。并将 SCCS 中最大的 recurrence_length 作为 rec_mii(sccs->sccs[0]->recurrence_length)
(2)calculate_order_params : 计算 DDG 中每个节点的 ASAP(最早调度时间),ALAP(最晚调度时间),HEIGHT(指的是终止节点[没有succ的节点]到该节点的最大长度)。下面列举了与节点排序相关的5个宏定义,另外两个的含义分别是 MOB(该节点可调度空间),DEPTH(起始节点[没有pred的节点]到该节点的最大长度)
#define ORDER_PARAMS(x) ((struct node_order_params *) (x)->aux.info)
#define ASAP(x) (ORDER_PARAMS ((x))->asap)
#define ALAP(x) (ORDER_PARAMS ((x))->alap)
#define HEIGHT(x) (ORDER_PARAMS ((x))->height)
#define MOB(x) (ALAP ((x)) - ASAP ((x)))
#define DEPTH(x) (ASAP ((x)))(3)order_nodes_of_sccs :以强连通分量为切入点,根据(2)中计算得到的参数,对所有节点的调度顺序进行排序。详细的排序算法见 2.2.2
2.2.2 order_nodes_of_sccs 源码分析
static void
order_nodes_of_sccs (ddg_all_sccs_ptr all_sccs, int * node_order)
{
int i, pos = 0;
ddg_ptr g = all_sccs->ddg;
int num_nodes = g->num_nodes;
auto_sbitmap prev_sccs (num_nodes);
auto_sbitmap on_path (num_nodes);
auto_sbitmap tmp (num_nodes);
auto_sbitmap ones (num_nodes);
bitmap_clear (prev_sccs);
bitmap_ones (ones);
/* Perform the node ordering starting from the SCC with the highest recMII.
For each SCC order the nodes according to their ASAP/ALAP/HEIGHT etc. */
for (i = 0; i < all_sccs->num_sccs; i++)
{
ddg_scc_ptr scc = all_sccs->sccs[i];
/* 注意:find_nodes_on_paths API 搜索由 prev_sccs 到 scc->nodes 的有向路径,
结果 on_path 中除了保留有向路径中的节点,也会保留 prev_sccs 和
scc->nodes 的节点. */
/* Add nodes on paths from previous SCCs to the current SCC. */
find_nodes_on_paths (on_path, g, prev_sccs, scc->nodes);
bitmap_ior (tmp, scc->nodes, on_path);
/* Add nodes on paths from the current SCC to previous SCCs. */
find_nodes_on_paths (on_path, g, scc->nodes, prev_sccs);
bitmap_ior (tmp, tmp, on_path);
/* Remove nodes of previous SCCs from current extended SCC. */
bitmap_and_compl (tmp, tmp, prev_sccs);
pos = order_nodes_in_scc (g, prev_sccs, tmp, node_order, pos);
/* Above call to order_nodes_in_scc updated prev_sccs |= tmp. */
}
/* Handle the remaining nodes that do not belong to any scc. Each call
to order_nodes_in_scc handles a single connected component. */
while (pos < g->num_nodes)
{
bitmap_and_compl (tmp, ones, prev_sccs);
pos = order_nodes_in_scc (g, prev_sccs, tmp, node_order, pos);
}
}算法分为两步。First Step,我们按如下步骤,将DDG划分为子集 S2 来构造节点的局部顺序
(1)Find the SCC (Strongly Connected Component)/Recurrence of the data-dependence graph having the largest recMII—this is the first set of nodes S1.
(2)Find the SCC with the next largest recMII, put its nodes into the next set S2.
(3)Find all nodes that are on directed paths from any previous set (对应源码中变量 prev_sccs) to the next set S2 (对应源码中变量 tmp) and add them to the next set S2.
(4)If there are additional SCCs in the dependence graph goto step 2. If there are no additional SCCs, create a new (last) set of all the remaining nodes.
Second Step ,调用子函数 order_nodes_in_scc 处理子集 S2,这里分为两种排序模式
(1)BOTTOMUP:优先调度已排序节点中的前驱节点(predecessors)。顺序由 find_max_dv_min_mob 接口决定,第一优先级是 max DEPTH,第二优先级是 min MOB
(2)TOPDOWN:优先调度已排序节点中的后继节点(successors)。顺序由 find_max_hv_min_mob 接口决定,第一优先级是 max HEIGHT,第二优先级是 min MOB
每完成一个节点的排序,它的后驱或者前驱会加入到workset中,参与接下来的节点排序
/* Places the nodes of SCC into the NODE_ORDER array starting
at position POS, according to the SMS ordering algorithm.
NODES_ORDERED (in&out parameter) holds the bitset of all nodes in
the NODE_ORDER array, starting from position zero. */
static int
order_nodes_in_scc (ddg_ptr g, sbitmap nodes_ordered, sbitmap scc,
int * node_order, int pos)
{
enum sms_direction dir;
int num_nodes = g->num_nodes;
auto_sbitmap workset (num_nodes);
auto_sbitmap tmp (num_nodes);
sbitmap zero_bitmap = sbitmap_alloc (num_nodes);
auto_sbitmap predecessors (num_nodes);
auto_sbitmap successors (num_nodes);
bitmap_clear (predecessors);
find_predecessors (predecessors, g, nodes_ordered);
bitmap_clear (successors);
find_successors (successors, g, nodes_ordered);
bitmap_clear (tmp);
if (bitmap_and (tmp, predecessors, scc))
{
bitmap_copy (workset, tmp);
dir = BOTTOMUP;
}
else if (bitmap_and (tmp, successors, scc))
{
bitmap_copy (workset, tmp);
dir = TOPDOWN;
}
else
{
int u;
bitmap_clear (workset);
if ((u = find_max_asap (g, scc)) >= 0)
bitmap_set_bit (workset, u);
dir = BOTTOMUP;
}
bitmap_clear (zero_bitmap);
while (!bitmap_equal_p (workset, zero_bitmap))
{
int v;
ddg_node_ptr v_node;
sbitmap v_node_preds;
sbitmap v_node_succs;
if (dir == TOPDOWN)
{
while (!bitmap_equal_p (workset, zero_bitmap))
{
v = find_max_hv_min_mob (g, workset);
v_node = &g->nodes[v];
node_order[pos++] = v;
v_node_succs = NODE_SUCCESSORS (v_node);
bitmap_and (tmp, v_node_succs, scc);
/* Don't consider the already ordered successors again. */
bitmap_and_compl (tmp, tmp, nodes_ordered);
bitmap_ior (workset, workset, tmp);
bitmap_clear_bit (workset, v);
bitmap_set_bit (nodes_ordered, v);
}
dir = BOTTOMUP;
bitmap_clear (predecessors);
find_predecessors (predecessors, g, nodes_ordered);
bitmap_and (workset, predecessors, scc);
}
else
{
while (!bitmap_equal_p (workset, zero_bitmap))
{
v = find_max_dv_min_mob (g, workset);
v_node = &g->nodes[v];
node_order[pos++] = v;
v_node_preds = NODE_PREDECESSORS (v_node);
bitmap_and (tmp, v_node_preds, scc);
/* Don't consider the already ordered predecessors again. */
bitmap_and_compl (tmp, tmp, nodes_ordered);
bitmap_ior (workset, workset, tmp);
bitmap_clear_bit (workset, v);
bitmap_set_bit (nodes_ordered, v);
}
dir = TOPDOWN;
bitmap_clear (successors);
find_successors (successors, g, nodes_ordered);
bitmap_and (workset, successors, scc);
}
}
sbitmap_free (zero_bitmap);
return pos;
}2.3. 调度内核 kernel
经过 2.1 中 II 的计算,我们得到了 MII 和 MaxII ;经过 2.2 节点排序之后,我们得到了一个包含节点调度顺序的数组 node_order;在本节中,我们将前面得到的结果作为输入,调用 sms_schedule_by_order 接口, 根据预先计算的顺序为循环内核调度节点。
/* This function implements the scheduling algorithm for SMS according to the
above algorithm. */
static partial_schedule_ptr
sms_schedule_by_order (ddg_ptr g, int mii, int maxii, int *nodes_order)
{
int ii = mii;
int i, c, success, num_splits = 0;
int flush_and_start_over = true;
int num_nodes = g->num_nodes;
int start, end, step; /* Place together into one struct? */
auto_sbitmap sched_nodes (num_nodes);
auto_sbitmap tobe_scheduled (num_nodes);
partial_schedule_ptr ps = create_partial_schedule (ii, g, DFA_HISTORY);
bitmap_ones (tobe_scheduled);
bitmap_clear (sched_nodes);
while (flush_and_start_over && (ii < maxii))
{
if (dump_file)
fprintf (dump_file, "Starting with ii=%d\n", ii);
flush_and_start_over = false;
bitmap_clear (sched_nodes);
for (i = 0; i < num_nodes; i++)
{
int u = nodes_order[i];
ddg_node_ptr u_node = &ps->g->nodes[u];
rtx_insn *insn = u_node->insn;
......
if (bitmap_bit_p (sched_nodes, u))
continue;
/* Try to get non-empty scheduling window. */
success = 0;
if (get_sched_window (ps, u_node, sched_nodes, ii, &start,
&step, &end) == 0)
{
......
for (c = start; c != end; c += step)
{
/* 此处省略 precede和follow的处理 */
......
success =
try_scheduling_node_in_cycle (ps, u, c,
sched_nodes,
&num_splits, tmp_precede,
tmp_follow);
if (success)
break;
}
verify_partial_schedule (ps, sched_nodes);
}
if (!success)
{
if (ii++ == maxii)
break;
/* 此处省略compute_split_row的处理方式,仅保留reset_partial_schedule的处理方式. */
......
flush_and_start_over = true;
verify_partial_schedule (ps, sched_nodes);
reset_partial_schedule (ps, ii);
verify_partial_schedule (ps, sched_nodes);
break;
}
/* ??? If (success), check register pressure estimates. */
} /* Continue with next node. */
} /* While flush_and_start_over. */
if (ii >= maxii)
{
free_partial_schedule (ps);
ps = NULL;
}
else
gcc_assert (bitmap_equal_p (tobe_scheduled, sched_nodes));
return ps;
}(1)get_sched_window:对于 node_order 中的每个节点,我们计算一个调度窗口(scheduing windows)—— a range of cycles in which we can schedule the node according to already scheduled nodes. Previously scheduled predecessors (PSP) increase the lower bound of the scheduling window, while previously scheduled successors (PSS) decrease the upper bound of the scheduling window. The cycles within the scheduling window are not bounded a-priori, and can be positive or negative. The scheduling window itself contains a range of at-most II cycles
/* Given the partial schedule PS, this function calculates and returns the
cycles in which we can schedule the node with the given index I.
NOTE: Here we do the backtracking in SMS, in some special cases. We have
noticed that there are several cases in which we fail to SMS the loop
because the sched window of a node is empty due to tight data-deps. In
such cases we want to unschedule some of the predecessors/successors
until we get non-empty scheduling window. It returns -1 if the
scheduling window is empty and zero otherwise. */
static int
get_sched_window (partial_schedule_ptr ps, ddg_node_ptr u_node,
sbitmap sched_nodes, int ii, int *start_p, int *step_p,
int *end_p)
{
int start, step, end;
int early_start, late_start;
/* We first compute a forward range (start <= end), then decide whether
to reverse it. */
early_start = INT_MIN;
late_start = INT_MAX;
start = INT_MIN;
end = INT_MAX;
step = 1;
/* 此处省略PSP和PSS相关的处理代码 */
......
/* Get a target scheduling window no bigger than ii. */
early_start = NODE_ASAP (u_node);
late_start = MIN (late_start, early_start + (ii - 1));
/* Apply memory dependence limits. */
start = MAX (start, early_start);
end = MIN (end, late_start);
/* Now that we've finalized the window, make END an exclusive rather
than an inclusive bound. */
end += step;
*start_p = start;
*step_p = step;
*end_p = end;
if (start >= end && step == 1)
{
if (dump_file)
fprintf (dump_file, "\nEmpty window: start=%d, end=%d, step=%d\n",
start, end, step);
return -1;
}
return 0;
}(2)try_scheduling_node_in_cycle:在计算调度窗口后,我们尝试在scheduling windows的某个cycle调度节点,同时避免资源冲突。如果成功,则标记节点及其(绝对)调度时间;如果不能在调度窗口内调度给定的节点,我们将增加II,然后重新调用该接口。如果II达到MaxII,我们放弃当前循环的SMS调度。
/* Return 1 if U_NODE can be scheduled in CYCLE. Use the following
parameters to decide if that's possible:
PS - The partial schedule.
U - The serial number of U_NODE.
NUM_SPLITS - The number of row splits made so far.
MUST_PRECEDE - The nodes that must precede U_NODE. (only valid at
the first row of the scheduling window)
MUST_FOLLOW - The nodes that must follow U_NODE. (only valid at the
last row of the scheduling window) */
static bool
try_scheduling_node_in_cycle (partial_schedule_ptr ps,
int u, int cycle, sbitmap sched_nodes,
int *num_splits, sbitmap must_precede,
sbitmap must_follow)
{
ps_insn_ptr psi;
bool success = 0;
verify_partial_schedule (ps, sched_nodes);
psi = ps_add_node_check_conflicts (ps, u, cycle, must_precede, must_follow);
if (psi)
{
SCHED_TIME (u) = cycle;
bitmap_set_bit (sched_nodes, u);
success = 1;
*num_splits = 0;
if (dump_file)
fprintf (dump_file, "Scheduled w/o split in %d\n", cycle);
}
return success;
}
/* Checks if the given node causes resource conflicts when added to PS at
cycle C. If not the node is added to PS and returned; otherwise zero
is returned. Bit N is set in MUST_PRECEDE/MUST_FOLLOW if the node with
cuid N must be come before/after (respectively) the node pointed to by
PS_I when scheduled in the same cycle. */
ps_insn_ptr
ps_add_node_check_conflicts (partial_schedule_ptr ps, int n,
int c, sbitmap must_precede,
sbitmap must_follow)
{
int has_conflicts = 0;
ps_insn_ptr ps_i;
/* First add the node to the PS, if this succeeds check for
conflicts, trying different issue slots in the same row. */
if (! (ps_i = add_node_to_ps (ps, n, c, must_precede, must_follow)))
return NULL; /* Failed to insert the node at the given cycle. */
/* 此处省略 ps_has_conflicts 的相关处理. */
......
ps->min_cycle = MIN (ps->min_cycle, c);
ps->max_cycle = MAX (ps->max_cycle, c);
return ps_i;
}(3)add_node_to_ps:在调度内核的过程中,我们维护一个partial schedule(以下简写为 ps),它将调度的指令保存在II行中,如下所示:当一条指令调度到 cycle T 时(在其调度窗口内),它通过接口ps_insn_find_column 被插入到 ps 的某一行(row),row 的计算方式为:
row = T mod II
如果row的指令数量大于等于 issue_rate,表示指令级并发已达到上限,不能继续增加。一旦所有指令调度成功,ps 将提供内核中指令的顺序。
/* Inserts a DDG_NODE to the given partial schedule at the given cycle.
Returns 0 if this is not possible and a PS_INSN otherwise. Bit N is
set in MUST_PRECEDE/MUST_FOLLOW if the node with cuid N must be come
before/after (respectively) the node pointed to by PS_I when scheduled
in the same cycle. */
static ps_insn_ptr
add_node_to_ps (partial_schedule_ptr ps, int id, int cycle,
sbitmap must_precede, sbitmap must_follow)
{
ps_insn_ptr ps_i;
int row = SMODULO (cycle, ps->ii);
if (ps->rows_length[row] >= issue_rate)
return NULL;
ps_i = create_ps_insn (id, cycle);
/* Finds and inserts PS_I according to MUST_FOLLOW and
MUST_PRECEDE. */
if (! ps_insn_find_column (ps, ps_i, must_precede, must_follow))
{
free (ps_i);
return NULL;
}
ps->rows_length[row] += 1;
return ps_i;
}
/* Unlike what literature describes for modulo scheduling (which focuses
on VLIW machines) the order of the instructions inside a cycle is
important. Given the bitmaps MUST_FOLLOW and MUST_PRECEDE we know
where the current instruction should go relative to the already
scheduled instructions in the given cycle. Go over these
instructions and find the first possible column to put it in. */
static bool
ps_insn_find_column (partial_schedule_ptr ps, ps_insn_ptr ps_i,
sbitmap must_precede, sbitmap must_follow)
{
ps_insn_ptr next_ps_i;
ps_insn_ptr first_must_follow = NULL;
ps_insn_ptr last_must_precede = NULL;
ps_insn_ptr last_in_row = NULL;
int row;
if (! ps_i)
return false;
row = SMODULO (ps_i->cycle, ps->ii);
/* Find the first must follow and the last must precede
and insert the node immediately after the must precede
but make sure that it there is no must follow after it. */
for (next_ps_i = ps->rows[row];
next_ps_i;
next_ps_i = next_ps_i->next_in_row)
{
/* 此处省略precede和follow的处理. */
......
last_in_row = next_ps_i;
}
/* The closing branch is scheduled as well. Make sure there is no
dependent instruction after it as the branch should be the last
instruction in the row. */
if (JUMP_P (ps_rtl_insn (ps, ps_i->id)))
{
if (last_in_row)
{
/* Make the branch the last in the row. New instructions
will be inserted at the beginning of the row or after the
last must_precede instruction thus the branch is guaranteed
to remain the last instruction in the row. */
last_in_row->next_in_row = ps_i;
ps_i->prev_in_row = last_in_row;
ps_i->next_in_row = NULL;
}
else
ps->rows[row] = ps_i;
return true;
}
/* Now insert the node after INSERT_AFTER_PSI. */
ps_i->next_in_row = ps->rows[row];
ps_i->prev_in_row = NULL;
if (ps_i->next_in_row)
ps_i->next_in_row->prev_in_row = ps_i;
ps->rows[row] = ps_i;
return true;
}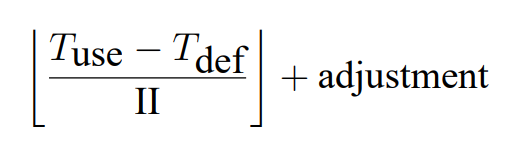
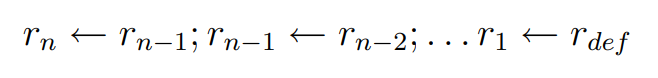
/*
Breaking intra-loop register anti-dependences:
Each intra-loop register anti-dependence implies a cross-iteration true
dependence of distance 1. Therefore, we can remove such false dependencies
and figure out if the partial schedule broke them by checking if (for a
true-dependence of distance 1): SCHED_TIME (def) < SCHED_TIME (use) and
if so generate a register move. The number of such moves is equal to:
SCHED_TIME (use) - SCHED_TIME (def) { 0 broken
nreg_moves = ----------------------------------- + 1 - { dependence.
ii { 1 if not.
*/
static bool
schedule_reg_moves (partial_schedule_ptr ps)
{
ddg_ptr g = ps->g;
int ii = ps->ii;
int i;
for (i = 0; i < g->num_nodes; i++)
{
ddg_node_ptr u = &g->nodes[i];
ddg_edge_ptr e;
int nreg_moves = 0, i_reg_move;
rtx prev_reg, old_reg;
int first_move;
int distances[2];
sbitmap distance1_uses;
rtx set = single_set (u->insn);
/* Skip instructions that do not set a register. */
if ((set && !REG_P (SET_DEST (set))))
continue;
/* Compute the number of reg_moves needed for u, by looking at life
ranges started at u (excluding self-loops). */
distances[0] = distances[1] = false;
for (e = u->out; e; e = e->next_out)
if (e->type == TRUE_DEP && e->dest != e->src)
{
int nreg_moves4e = (SCHED_TIME (e->dest->cuid)
- SCHED_TIME (e->src->cuid)) / ii;
if (e->distance == 1)
nreg_moves4e = (SCHED_TIME (e->dest->cuid)
- SCHED_TIME (e->src->cuid) + ii) / ii;
/* If dest precedes src in the schedule of the kernel, then dest
will read before src writes and we can save one reg_copy. */
if (SCHED_ROW (e->dest->cuid) == SCHED_ROW (e->src->cuid)
&& SCHED_COLUMN (e->dest->cuid) < SCHED_COLUMN (e->src->cuid))
nreg_moves4e--;
......
if (nreg_moves4e)
{
gcc_assert (e->distance < 2);
distances[e->distance] = true;
}
nreg_moves = MAX (nreg_moves, nreg_moves4e);
}
if (nreg_moves == 0)
continue;
/* Create NREG_MOVES register moves. */
first_move = ps->reg_moves.length ();
ps->reg_moves.safe_grow_cleared (first_move + nreg_moves);
extend_node_sched_params (ps);
/* Record the moves associated with this node. */
first_move += ps->g->num_nodes;
/* Generate each move. */
old_reg = prev_reg = SET_DEST (single_set (u->insn));
for (i_reg_move = 0; i_reg_move < nreg_moves; i_reg_move++)
{
ps_reg_move_info *move = ps_reg_move (ps, first_move + i_reg_move);
move->def = i_reg_move > 0 ? first_move + i_reg_move - 1 : i;
move->uses = sbitmap_alloc (first_move + nreg_moves);
move->old_reg = old_reg;
move->new_reg = gen_reg_rtx (GET_MODE (prev_reg));
move->num_consecutive_stages = distances[0] && distances[1] ? 2 : 1;
move->insn = gen_move_insn (move->new_reg, copy_rtx (prev_reg));
bitmap_clear (move->uses);
prev_reg = move->new_reg;
}
distance1_uses = distances[1] ? sbitmap_alloc (g->num_nodes) : NULL;
if (distance1_uses)
bitmap_clear (distance1_uses);
/* Every use of the register defined by node may require a different
copy of this register, depending on the time the use is scheduled.
Record which uses require which move results. */
for (e = u->out; e; e = e->next_out)
if (e->type == TRUE_DEP && e->dest != e->src)
{
int dest_copy = (SCHED_TIME (e->dest->cuid)
- SCHED_TIME (e->src->cuid)) / ii;
if (e->distance == 1)
dest_copy = (SCHED_TIME (e->dest->cuid)
- SCHED_TIME (e->src->cuid) + ii) / ii;
if (SCHED_ROW (e->dest->cuid) == SCHED_ROW (e->src->cuid)
&& SCHED_COLUMN (e->dest->cuid) < SCHED_COLUMN (e->src->cuid))
dest_copy--;
if (dest_copy)
{
ps_reg_move_info *move;
move = ps_reg_move (ps, first_move + dest_copy - 1);
bitmap_set_bit (move->uses, e->dest->cuid);
if (e->distance == 1)
bitmap_set_bit (distance1_uses, e->dest->cuid);
}
}
auto_sbitmap must_follow (first_move + nreg_moves);
for (i_reg_move = 0; i_reg_move < nreg_moves; i_reg_move++)
if (!schedule_reg_move (ps, first_move + i_reg_move,
distance1_uses, must_follow))
break;
if (distance1_uses)
sbitmap_free (distance1_uses);
if (i_reg_move < nreg_moves)
return false;
}
return true;
}模调度循环的内核包含来自不同迭代的指令实例。因此,需要一个prologue和一个epilogue(除非所有动作都是投机的)来保持代码的正确性。在生成prologue和epilogue时,如果循环边界未知,则应做特殊处理。一种方法是在prologue的每次迭代中添加一个exit分支,以不同的prologue为目标,这很复杂,并且增加了代码的大小;另一种方法是,如果循环计数太小而无法到达内核,则保留要执行的循环的原始副本,否则执行一个无分支的prologue,紧接着执行内核和 prologue。GCC 实现了后者,因为它更简单,对代码大小的影响更小。
/* Generate the instructions (including reg_moves) for prolog & epilog. */
static void
generate_prolog_epilog (partial_schedule_ptr ps, struct loop *loop,
rtx count_reg, rtx count_init)
{
int i;
int last_stage = PS_STAGE_COUNT (ps) - 1;
edge e;
/* Generate the prolog, inserting its insns on the loop-entry edge. */
start_sequence ();
if (!count_init)
{
/* Generate instructions at the beginning of the prolog to
adjust the loop count by STAGE_COUNT. If loop count is constant
(count_init), this constant is adjusted by STAGE_COUNT in
generate_prolog_epilog function. */
rtx sub_reg = NULL_RTX;
sub_reg = expand_simple_binop (GET_MODE (count_reg), MINUS, count_reg,
gen_int_mode (last_stage, GET_MODE (count_reg)),
count_reg, 1, OPTAB_DIRECT);
gcc_assert (REG_P (sub_reg));
if (REGNO (sub_reg) != REGNO (count_reg))
emit_move_insn (count_reg, sub_reg);
}
for (i = 0; i < last_stage; i++)
duplicate_insns_of_cycles (ps, 0, i, count_reg);
/* Put the prolog on the entry edge. */
e = loop_preheader_edge (loop);
split_edge_and_insert (e, get_insns ());
if (!flag_resched_modulo_sched)
e->dest->flags |= BB_DISABLE_SCHEDULE;
end_sequence ();
/* Generate the epilog, inserting its insns on the loop-exit edge. */
start_sequence ();
for (i = 0; i < last_stage; i++)
duplicate_insns_of_cycles (ps, i + 1, last_stage, count_reg);
/* Put the epilogue on the exit edge. */
gcc_assert (single_exit (loop));
e = single_exit (loop);
split_edge_and_insert (e, get_insns ());
if (!flag_resched_modulo_sched)
e->dest->flags |= BB_DISABLE_SCHEDULE;
end_sequence ();
}参考文献:
Swing Modulo Scheduling for GCC
posted on 2021-08-04 21:52 Save-Reset 阅读(1722) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号