TCP/IP 协议栈在Linux内核中的运行时序分析
调研要求
-
-
编译、部署、运行、测评、原理、源代码分析、跟踪调试等
-
应该包括时序图
1.TCP/IP协议栈
TCP/IP模型各个层次分别对应于不同的协议。TCP/IP协议栈是数据通信协议的集合 ,包含许多协议。其协议栈名字来源于其中最主要的两个协议TCP(传输控制协议)和IP(网际协议)。TCP/IP协议栈负责确保网络设备之间能够通信。TCP/IP通常被认为是一个四层协议系统,其分层模型如下:

每一层介绍:
链路层:
数据链路层实现了网卡接口的网络驱动程序,以处理数据在物理媒介(比如以太网、令牌环等)上的传输。
数据链路层两个常用的协议是ARP协议(Address Resolve Protocol,地址解析协议)和RARP协议(ReverseAddress Resolve Protocol,逆地址解析协议)。它们实现了IP地址和机器物理地址(通常是MAC地址,以太网、令牌环和802.11无线网络都使用MAC地址)之间的相互转换。
RARP协议仅用于网络上的某些无盘工作站。因为缺乏存储设备,无盘工作站无法记住自己的IP地址,但它们可以利用网卡上的物理地址来向网
络管理者(服务器或网络管理软件)查询自身的IP地址。运行RARP服务的网络管理者通常存有该网络上所有机器的物理地址到IP地址的映射。
网络层:
网络层实现数据包的选路和转发。
网络层最核心的协议是IP协议(Internet Protocol,因特网协议)。IP协议根据数据包的目的IP地址来决定如何投递它。如果数据包不能直接发送给目标主机,那么IP协议就为它寻找一个合适的下一跳(next hop)路由器,并将数据包交付给该路由器来转发。多次重复这一过程,数据包最终到达目标主机,或者由于发送失败而被丢弃。可见,IP协议使用逐跳(hop by hop)的方式确定通信路径。
网络层另外一个重要的协议是ICMP协议(Internet Control Message Protocol,因特网控制报文协议)。它是IP协议的重要补充,主要用于检测网络连接。
传输层:
传输层为两台主机上的应用程序提供端到端(end to end)的通信。与网络层使用的逐跳通信方式不同,传输层只关心通信的起始端和目的端,而不在乎数据包的中转过程。
传输层协议:TCP协议、UDP协议。TCP协议为应用层提供可靠的、面向连接的和基于流(stream)的服务。TCP协议使用超时重传、数据确认等方式来确保数据包被正确地发送至目的端,因此TCP协议通信的双方必须先建立TCP连接。UDP协议则与TCP协议完全相反,它为应用层提供不可靠、无连接和基于数据报的服务。
应用层:
应用层负责处理应用程序的逻辑。
应用层在用户空间实现,因为它负责处理众多逻辑,比如文件传输、名称查询和网络管理等。如果应用层也在内核中实现,则会使内核变得非常庞大。应用层协议(或程序)可能跳过传输层直接使用网络层提供的服务,比如ping程序和OSPF协议。应用层协议(或程序)通常既可以使用TCP服务,又可以使用UDP服务,比如DNS协议。我们可以通过/etc/services文件查看所有知名的应用层协议,以及它们都能使用哪些传输层服务。
2.Socket概述
2.1.Socket简介
在计算机通信领域,socket 被翻译为“套接字”,它是计算机之间进行通信的一种约定或一种方式。通过 socket 这种约定,一台计算机可以接收其他计算机的数据,也可以向其他计算机发送数据。
socket 的典型应用就是 Web 服务器和浏览器:浏览器获取用户输入的URL,向服务器发起请求,服务器分析接收到的URL,将对应的网页内容返回给浏览器,浏览器再经过解析和渲染,就将文字、图片、视频等元素呈现给用户。
2.2.Socket通信过程
服务器和客户端都建立socket套接字,通过socket彼此建立联系。数据传输过程如下:

客户端调用 socket() 函数创建套接字后,因为没有建立连接,所以套接字处于CLOSED状态;服务器端调用 listen() 函数后,套接字进入LISTEN状态,开始监听客户端请求。 当客户端调用connect服务器与客户端连接成功,并能够互相传输数据。
2.3.常见函数功能
-
int socket(int domain, int type, int protocol): -
int bind(int sock,struct sockaddr * my_addr,int addrlen):服务器端要用 bind() 函数将套接字与特定的IP地址和端口绑定起来,只有这样,流经该IP地址和端口的数据才能交给套接字处理 -
int listen(int sock,int input_queue_size):面向连接的服务器使用它将一个套接字置为被动模式,并准备接收传入连接。用于服务器,指明某个套接字连接是被动的 -
int accept(int sock, struct sockaddr *addr, int *addrlen):获取传入连接请求,返回新的连接的套接字描述符 -
int connect(int sock,struct sockaddr *server_addr,int sockaddr_len):同远程服务器建立主动连接,成功时返回0,若连接失败返回-1 -
int send(int sock, const void * data, int data_len, unsigned int flags):在TCP连接上发送数据,返回成功传送数据的长度 -
int recv(int sock, void *buf, int buf_len,unsigned int flags):从TCP接收数据,返回实际接收的数据长度 -
close(int sockfd):撤销套接字
2.4.Socket结构
struct socket {
socket_state state; //描述当前套接字的状态
typedef enum {
SS_FREE = 0,
SS_UNCONNECTED,
SS_CONNECTING,
SS_CONNECTED,
SS_DISCONNECTING
}socket_state;
sockaddr
struct sockaddr {
unsigned short sa_family; /* address family, AF_xxx */
char sa_data[14]; /* 14 bytes of protocol address */
};
数据结构用做bind、connect、recvfrom、sendto等函数的参数,指明地址信息。
sockaddr_in
struct sockaddr_in {
short int sin_family; /* Address family */
unsigned short int sin_port; /* Port number */
struct in_addr sin_addr; /* Internet address */
unsigned char sin_zero[8]; /* Same size as struct sockaddr */
};
编程中大多数是使用sockaddr_in这个结构来设置/获取地址信息。
sin_family指代协议族,在socket编程中只能是AF_INET
sin_port存储端口号(使用网络字节顺序)
sin_addr存储IP地址,使用in_addr这个数据结构
3.Linux内核体系结构
Linux内核只是Linux操作系统一部分。对下,它管理系统的所有硬件设备;对上,它通过系统调用,向Library Routine(例如C库)或者其它应用程序提供接口。
因此,其核心功能就是:管理硬件设备,供应用程序使用。而现代计算机(无论是PC还是嵌入式系统)的标准组成,就是CPU、Memory(内存和外存)、输入输出设备、网络设备和其它的外围设备。所以为了管理这些设备,Linux内核提出了如下的架构。

进程管理:主要负载CPU的访问控制,对CPU进行调度管理;这一部分包括具体创建创建进程(fork、exec),停止进程(kill、exit),并控制他们之间的通信(signal等)。还包括进程调度,控制活动进程如何共享CPU。这一部分是Linux已经做好的,在写驱动的时候,只需要调用对应的函数即可实现这些功能,例如创建进程、进程通信等等。
内存管理:内存管理的主要作用是控制多个进程安全的共享内存区域。
文件系统:隐藏各种文件系统的具体细节,为文件操作提供统一的接口。在Linux中“一切皆文件”,这些文件就是通过VFS来实现的。Linux提供了一个大的通用模型,使这个模型包含了所有文件系统功能的集合。
网络子系统:负责管理系统的网络设备,并实现多种多样的网络标准。
设备管理:Linux内核中有大量的代码在设备驱动程序部分,用于控制特定的硬件设备。
Linux驱动一般分为网络设备、块设备、字符设备、杂项设备,需要我们编写的只有字符设备,杂项设备是不容易归类的一种驱动,杂项设备和字符设备有很多重合的地方。
4.Send过程
4.1.总体流程
(1)应用层:
1.网络应用调用Socket API socket创建一个 socket,该调用最终会调用 Linux system call socket() ,并最终调用 sock_create() 方法。该方法返回被创建好了的那个 socket 的 描述符。
2.对于 TCP socket 来说,应用调用 connect()函数,使客户端和服务器端通过该 socket 建立一个连接。在此过程中,TCP 协议栈通过三次握手会建立 TCP 连接。在建立连接的过程中要确定双方使用的最大报文长度。
3.建立连接之后然后可以调用send函数发出一个 message 给接收端。sock_sendmsg 被调用,调用相应协议的发送函数。
(2)传输层:
1.最先调用tcp_sendmsg 函数,会把用户层的数据,填充到skb中。在tcp_sendmsg_locked中,将数据整理成发送队列,每个队列中的元素就是skb。
2.计算校验和和顺序号,保证数据的可靠传输。
3.数据创建之后调用tcp_push()来发送,tcp_push函数调用tcp_write_xmit()函数,其又将调用发送函数tcp_transmit_skb,所有的SKB都经过该函数进行发送。最后进入到ip_queue_xmit到网络层。
(3)网络层:
1.ip_queue_xmit(skb)会检查skb->dst路由信息。如果没有,比如套接字的第一个包,就使用ip_route_output()选择一个路由。
2.填充IP包的各个字段,比如版本、包头长度、TOS等。ip_fragment 函数进行分片,会检查 IP_DF 标志位,如果待分片IP数据包禁止分片,则调用 icmp_send()向发送方发不可达ICMP报文,并丢弃报文,即设置IP状态为分片失败,释放skb,返回消息过长错误码。
3.使用 ip_finish_ouput2 设置链路层报文头。如果链路层报头缓存存在,拷贝到skb里。如果没有,那么就调用neigh_resolve_output,使用 ARP 获取。
(4)链路层:
数据链路层在不可靠的物理介质上提供可靠的传输。该层的作用包括:物理地址寻址、数据的成帧、流量控制、数据的检错、重发等。从dev_queue_xmit函数开始,位于net/core/dev.c文件中。
4.2.gdb调试
传输层:

网络层:

链路层:

4.3.源代码分析
1)tcp_sendmsg
传输层的入口函数,实际上调用的是tcp_sendmsg_locked函数
1 int tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size)
2 {
3 int ret;
4
5 lock_sock(sk);
6 ret = tcp_sendmsg_locked(sk, msg, size);
7 release_sock(sk);
8
9 return ret;
10 }
11 EXPORT_SYMBOL(tcp_sendmsg);
1 int tcp_sendmsg_locked(struct sock *sk, struct msghdr *msg, size_t size)
2 {
3 struct tcp_sock *tp = tcp_sk(sk);
4 struct ubuf_info *uarg = NULL;
5 struct sk_buff *skb;
6 struct sockcm_cookie sockc;
7 int flags, err, copied = 0;
8 int mss_now = 0, size_goal, copied_syn = 0;
9 int process_backlog = 0;
10 bool zc = false;
11 long timeo;
12
13 flags = msg->msg_flags;
14
15 if (flags & MSG_ZEROCOPY && size && sock_flag(sk, SOCK_ZEROCOPY)) {
16 skb = tcp_write_queue_tail(sk);
17 uarg = sock_zerocopy_realloc(sk, size, skb_zcopy(skb));
18 if (!uarg) {
19 err = -ENOBUFS;
20 goto out_err;
21 }
22
23 zc = sk->sk_route_caps & NETIF_F_SG;
24 if (!zc)
25 uarg->zerocopy = 0;
26 }
27
28 if (unlikely(flags & MSG_FASTOPEN || inet_sk(sk)->defer_connect) &&
29 !tp->repair) {
30 err = tcp_sendmsg_fastopen(sk, msg, &copied_syn, size, uarg);
31 if (err == -EINPROGRESS && copied_syn > 0)
32 goto out;
33 else if (err)
34 goto out_err;
35 }
36
37 timeo = sock_sndtimeo(sk, flags & MSG_DONTWAIT);
38
39 tcp_rate_check_app_limited(sk); /* is sending application-limited? */
40
41 /* Wait for a connection to finish. One exception is TCP Fast Open
42 * (passive side) where data is allowed to be sent before a connection
43 * is fully established.
44 */
45 if (((1 << sk->sk_state) & ~(TCPF_ESTABLISHED | TCPF_CLOSE_WAIT)) &&
46 !tcp_passive_fastopen(sk)) {
47 err = sk_stream_wait_connect(sk, &timeo);
48 if (err != 0)
49 goto do_error;
50 }
51
52 if (unlikely(tp->repair)) {
53 if (tp->repair_queue == TCP_RECV_QUEUE) {
54 copied = tcp_send_rcvq(sk, msg, size);
55 goto out_nopush;
56 }
57
58 err = -EINVAL;
59 if (tp->repair_queue == TCP_NO_QUEUE)
60 goto out_err;
61
62 /* 'common' sending to sendq */
63 }
64
65 sockcm_init(&sockc, sk);
66 if (msg->msg_controllen) {
67 err = sock_cmsg_send(sk, msg, &sockc);
68 if (unlikely(err)) {
69 err = -EINVAL;
70 goto out_err;
71 }
72 }
73
74 /* This should be in poll */
75 sk_clear_bit(SOCKWQ_ASYNC_NOSPACE, sk);
76
77 /* Ok commence sending. */
78 copied = 0;
79
80 restart:
81 mss_now = tcp_send_mss(sk, &size_goal, flags);
82
83 err = -EPIPE;
84 if (sk->sk_err || (sk->sk_shutdown & SEND_SHUTDOWN))
85 goto do_error;
86
87 while (msg_data_left(msg)) {
88 int copy = 0;
89
90 skb = tcp_write_queue_tail(sk);
91 if (skb)
92 copy = size_goal - skb->len;
93
94 if (copy <= 0 || !tcp_skb_can_collapse_to(skb)) {
95 bool first_skb;
96
97 new_segment:
98 if (!sk_stream_memory_free(sk))
99 goto wait_for_sndbuf;
100
101 if (unlikely(process_backlog >= 16)) {
102 process_backlog = 0;
103 if (sk_flush_backlog(sk))
104 goto restart;
105 }
106 first_skb = tcp_rtx_and_write_queues_empty(sk);
107 skb = sk_stream_alloc_skb(sk, 0, sk->sk_allocation,
108 first_skb);
109 if (!skb)
110 goto wait_for_memory;
111
112 process_backlog++;
113 skb->ip_summed = CHECKSUM_PARTIAL;
114
115 skb_entail(sk, skb);
116 copy = size_goal;
117
118 /* All packets are restored as if they have
119 * already been sent. skb_mstamp_ns isn't set to
120 * avoid wrong rtt estimation.
121 */
122 if (tp->repair)
123 TCP_SKB_CB(skb)->sacked |= TCPCB_REPAIRED;
124 }
125
126 /* Try to append data to the end of skb. */
127 if (copy > msg_data_left(msg))
128 copy = msg_data_left(msg);
129
130 /* Where to copy to? */
131 if (skb_availroom(skb) > 0 && !zc) {
132 /* We have some space in skb head. Superb! */
133 copy = min_t(int, copy, skb_availroom(skb));
134 err = skb_add_data_nocache(sk, skb, &msg->msg_iter, copy);
135 if (err)
136 goto do_fault;
137 } else if (!zc) {
138 bool merge = true;
139 int i = skb_shinfo(skb)->nr_frags;
140 struct page_frag *pfrag = sk_page_frag(sk);
141
142 if (!sk_page_frag_refill(sk, pfrag))
143 goto wait_for_memory;
144
145 if (!skb_can_coalesce(skb, i, pfrag->page,
146 pfrag->offset)) {
147 if (i >= sysctl_max_skb_frags) {
148 tcp_mark_push(tp, skb);
149 goto new_segment;
150 }
151 merge = false;
152 }
153
154 copy = min_t(int, copy, pfrag->size - pfrag->offset);
155
156 if (!sk_wmem_schedule(sk, copy))
157 goto wait_for_memory;
158
159 err = skb_copy_to_page_nocache(sk, &msg->msg_iter, skb,
160 pfrag->page,
161 pfrag->offset,
162 copy);
163 if (err)
164 goto do_error;
165
166 /* Update the skb. */
167 if (merge) {
168 skb_frag_size_add(&skb_shinfo(skb)->frags[i - 1], copy);
169 } else {
170 skb_fill_page_desc(skb, i, pfrag->page,
171 pfrag->offset, copy);
172 page_ref_inc(pfrag->page);
173 }
174 pfrag->offset += copy;
175 } else {
176 err = skb_zerocopy_iter_stream(sk, skb, msg, copy, uarg);
177 if (err == -EMSGSIZE || err == -EEXIST) {
178 tcp_mark_push(tp, skb);
179 goto new_segment;
180 }
181 if (err < 0)
182 goto do_error;
183 copy = err;
184 }
185
186 if (!copied)
187 TCP_SKB_CB(skb)->tcp_flags &= ~TCPHDR_PSH;
188
189 WRITE_ONCE(tp->write_seq, tp->write_seq + copy);
190 TCP_SKB_CB(skb)->end_seq += copy;
191 tcp_skb_pcount_set(skb, 0);
192
193 copied += copy;
194 if (!msg_data_left(msg)) {
195 if (unlikely(flags & MSG_EOR))
196 TCP_SKB_CB(skb)->eor = 1;
197 goto out;
198 }
199
200 if (skb->len < size_goal || (flags & MSG_OOB) || unlikely(tp->repair))
201 continue;
202
203 if (forced_push(tp)) {
204 tcp_mark_push(tp, skb);
205 __tcp_push_pending_frames(sk, mss_now, TCP_NAGLE_PUSH);
206 } else if (skb == tcp_send_head(sk))
207 tcp_push_one(sk, mss_now);
208 continue;
209
210 wait_for_sndbuf:
211 set_bit(SOCK_NOSPACE, &sk->sk_socket->flags);
212 wait_for_memory:
213 if (copied)
214 tcp_push(sk, flags & ~MSG_MORE, mss_now,
215 TCP_NAGLE_PUSH, size_goal);
216
217 err = sk_stream_wait_memory(sk, &timeo);
218 if (err != 0)
219 goto do_error;
220
221 mss_now = tcp_send_mss(sk, &size_goal, flags);
222 }
223
224 out:
225 if (copied) {
226 tcp_tx_timestamp(sk, sockc.tsflags);
227 tcp_push(sk, flags, mss_now, tp->nonagle, size_goal);
228 }
229 out_nopush:
230 sock_zerocopy_put(uarg);
231 return copied + copied_syn;
232
233 do_error:
234 skb = tcp_write_queue_tail(sk);
235 do_fault:
236 tcp_remove_empty_skb(sk, skb);
237
238 if (copied + copied_syn)
239 goto out;
240 out_err:
241 sock_zerocopy_put_abort(uarg, true);
242 err = sk_stream_error(sk, flags, err);
243 /* make sure we wake any epoll edge trigger waiter */
244 if (unlikely(tcp_rtx_and_write_queues_empty(sk) && err == -EAGAIN)) {
245 sk->sk_write_space(sk);
246 tcp_chrono_stop(sk, TCP_CHRONO_SNDBUF_LIMITED);
247 }
248 return err;
249 }
250 EXPORT_SYMBOL_GPL(tcp_sendmsg_locked);
2)tcp_write_xmit
1 static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle,
2 int push_one, gfp_t gfp)
3 {
4 struct tcp_sock *tp = tcp_sk(sk);
5 struct sk_buff *skb;
6 unsigned int tso_segs, sent_pkts;
7 int cwnd_quota;
8 int result;
9 bool is_cwnd_limited = false, is_rwnd_limited = false;
10 u32 max_segs;
11
12 sent_pkts = 0;
13
14 tcp_mstamp_refresh(tp);
15 if (!push_one) {
16 /* Do MTU probing. */
17 result = tcp_mtu_probe(sk);
18 if (!result) {
19 return false;
20 } else if (result > 0) {
21 sent_pkts = 1;
22 }
23 }
24
25 max_segs = tcp_tso_segs(sk, mss_now);
26 while ((skb = tcp_send_head(sk))) {
27 unsigned int limit;
28
29 if (unlikely(tp->repair) && tp->repair_queue == TCP_SEND_QUEUE) {
30 /* "skb_mstamp_ns" is used as a start point for the retransmit timer */
31 skb->skb_mstamp_ns = tp->tcp_wstamp_ns = tp->tcp_clock_cache;
32 list_move_tail(&skb->tcp_tsorted_anchor, &tp->tsorted_sent_queue);
33 tcp_init_tso_segs(skb, mss_now);
34 goto repair; /* Skip network transmission */
35 }
36
37 if (tcp_pacing_check(sk))
38 break;
39
40 tso_segs = tcp_init_tso_segs(skb, mss_now);
41 BUG_ON(!tso_segs);
42
43 cwnd_quota = tcp_cwnd_test(tp, skb);
44 if (!cwnd_quota) {
45 if (push_one == 2)
46 /* Force out a loss probe pkt. */
47 cwnd_quota = 1;
48 else
49 break;
50 }
51
52 if (unlikely(!tcp_snd_wnd_test(tp, skb, mss_now))) {
53 is_rwnd_limited = true;
54 break;
55 }
56
57 if (tso_segs == 1) {
58 if (unlikely(!tcp_nagle_test(tp, skb, mss_now,
59 (tcp_skb_is_last(sk, skb) ?
60 nonagle : TCP_NAGLE_PUSH))))
61 break;
62 } else {
63 if (!push_one &&
64 tcp_tso_should_defer(sk, skb, &is_cwnd_limited,
65 &is_rwnd_limited, max_segs))
66 break;
67 }
68
69 limit = mss_now;
70 if (tso_segs > 1 && !tcp_urg_mode(tp))
71 limit = tcp_mss_split_point(sk, skb, mss_now,
72 min_t(unsigned int,
73 cwnd_quota,
74 max_segs),
75 nonagle);
76
77 if (skb->len > limit &&
78 unlikely(tso_fragment(sk, skb, limit, mss_now, gfp)))
79 break;
80
81 if (tcp_small_queue_check(sk, skb, 0))
82 break;
83
84 /* Argh, we hit an empty skb(), presumably a thread
85 * is sleeping in sendmsg()/sk_stream_wait_memory().
86 * We do not want to send a pure-ack packet and have
87 * a strange looking rtx queue with empty packet(s).
88 */
89 if (TCP_SKB_CB(skb)->end_seq == TCP_SKB_CB(skb)->seq)
90 break;
91
92 if (unlikely(tcp_transmit_skb(sk, skb, 1, gfp)))
93 break;
94
95 repair:
96 /* Advance the send_head. This one is sent out.
97 * This call will increment packets_out.
98 */
99 tcp_event_new_data_sent(sk, skb);
100
101 tcp_minshall_update(tp, mss_now, skb);
102 sent_pkts += tcp_skb_pcount(skb);
103
104 if (push_one)
105 break;
106 }
107
108 if (is_rwnd_limited)
109 tcp_chrono_start(sk, TCP_CHRONO_RWND_LIMITED);
110 else
111 tcp_chrono_stop(sk, TCP_CHRONO_RWND_LIMITED);
112
113 if (likely(sent_pkts)) {
114 if (tcp_in_cwnd_reduction(sk))
115 tp->prr_out += sent_pkts;
116
117 /* Send one loss probe per tail loss episode. */
118 if (push_one != 2)
119 tcp_schedule_loss_probe(sk, false);
120 is_cwnd_limited |= (tcp_packets_in_flight(tp) >= tp->snd_cwnd);
121 tcp_cwnd_validate(sk, is_cwnd_limited);
122 return false;
123 }
124 return !tp->packets_out && !tcp_write_queue_empty(sk);
125 }
调用了tcp_write_xmit来发送数据
3)ip_queue_xmit
1 //数据包发送函数
2 //sk:被发送数据包对应的套接字;dev:发送数据包的网络设备
3 //skb:被发送的数据包 ;flags:是否对数据包进行缓存以便于此后的超时重发
4 void ip_queue_xmit(struct sock *sk, struct device *dev,
5 struct sk_buff *skb, int free)
6 {
7 struct iphdr *iph;
8 unsigned char *ptr;
9
10 /* Sanity check */
11 //发送设备检查
12 if (dev == NULL)
13 {
14 printk("IP: ip_queue_xmit dev = NULL\n");
15 return;
16 }
17
18 IS_SKB(skb);//数据包合法性检查
19
20 /*
21 * Do some book-keeping in the packet for later
22 */
23
24
25 skb->dev = dev;
26 skb->when = jiffies;//重置数据包的发送时间,只有一个定时器,每次发数据包时,都要重新设置
27
28 /*
29 * Find the IP header and set the length. This is bad
30 * but once we get the skb data handling code in the
31 * hardware will push its header sensibly and we will
32 * set skb->ip_hdr to avoid this mess and the fixed
33 * header length problem
34 */
35 //skb->data指向的地址空间的布局: MAC首部 | IP首部 | TCP首部 | 有效负载
36 ptr = skb->data;//获取数据部分首地址
37 ptr += dev->hard_header_len;//后移硬件(MAC)首部长度个字节,定位到ip首部
38 iph = (struct iphdr *)ptr;//获取ip首部
39 skb->ip_hdr = iph;//skb对应字段建立关联
40 //ip数据报的总长度(ip首部+数据部分) = skb的总长度 - 硬件首部长度
41 iph->tot_len = ntohs(skb->len-dev->hard_header_len);
42
43 #ifdef CONFIG_IP_FIREWALL
44 //数据包过滤,用于防火墙安全性检查
45 if(ip_fw_chk(iph, dev, ip_fw_blk_chain, ip_fw_blk_policy, 0) != 1)
46 /* just don't send this packet */
47 return;
48 #endif
49
50 /*
51 * No reassigning numbers to fragments...
52 */
53 //如果不是分片数据包,就需要递增id字段
54 //free==2,表示这是个分片数据包,所有分片数据包必须具有相同的id字段,方便以后分片数据包重组
55 if(free!=2)
56 iph->id = htons(ip_id_count++);//ip数据报标识符
57 //ip_id_count是全局变量,用于下一个数据包中ip首部id字段的赋值
58 else
59 free=1;
60
61 /* All buffers without an owner socket get freed */
62 if (sk == NULL)//没有对应sock结构,则无法对数据包缓存
63 free = 1;
64
65 skb->free = free;//用于标识数据包发送之后是缓存还是立即释放,=1表示无缓存
66
67 /*
68 * Do we need to fragment. Again this is inefficient.
69 * We need to somehow lock the original buffer and use
70 * bits of it.
71 */
72 //数据包拆分
73 //如果ip层数据包的数据部分(各层首部+有效负载)长度大于网络设备的最大传输单元,就需要拆分发送
74 //实际是skb->len - dev->hard_header_len > dev->mtu
75 //因为MTU最大报文长度表示的仅仅是IP首部及其数据负载的长度,所以要考虑MAC首部长度
76 if(skb->len > dev->mtu + dev->hard_header_len)
77 {
78 //拆分成分片数据包传输
79 ip_fragment(sk,skb,dev,0);
80 IS_SKB(skb);//检查数据包skb相关字段
81 kfree_skb(skb,FREE_WRITE);
82 return;
83 }
84
85 /*
86 * Add an IP checksum
87 */
88 //ip首部校验和计算
89 ip_send_check(iph);
90
91 /*
92 * Print the frame when debugging
93 */
94
95 /*
96 * More debugging. You cannot queue a packet already on a list
97 * Spot this and moan loudly.
98 */
99 if (skb->next != NULL)
100 {
101 printk("ip_queue_xmit: next != NULL\n");
102 skb_unlink(skb);
103 }
104
105 /*
106 * If a sender wishes the packet to remain unfreed
107 * we add it to his send queue. This arguably belongs
108 * in the TCP level since nobody else uses it. BUT
109 * remember IPng might change all the rules.
110 */
111 //free=0,表示对数据包进行缓存,一旦发生丢弃的情况,进行数据包重传(可靠性数据传输协议)
112 if (!free)
113 {
114 unsigned long flags;
115 /* The socket now has more outstanding blocks */
116
117 sk->packets_out++;//本地发送出去但未得到应答的数据包数目
118
119 /* Protect the list for a moment */
120 save_flags(flags);
121 cli();
122
123 //数据包重发队列
124 if (skb->link3 != NULL)
125 {
126 printk("ip.c: link3 != NULL\n");
127 skb->link3 = NULL;
128 }
129 if (sk->send_head == NULL)
130 {
131 //数据包重传缓存队列则是由下列两个字段维护
132 sk->send_tail = skb;
133 sk->send_head = skb;
134 }
135 else
136 {
137 sk->send_tail->link3 = skb;
138 sk->send_tail = skb;
139 }
140 /* skb->link3 is NULL */
141
142 /* Interrupt restore */
143 restore_flags(flags);
144 }
145 else
146 /* Remember who owns the buffer */
147 skb->sk = sk;
148
149 /*
150 * If the indicated interface is up and running, send the packet.
151 */
152
153 ip_statistics.IpOutRequests++;
154 #ifdef CONFIG_IP_ACCT
155 //下面函数内部调用ip_fw_chk,也是数据包过滤
156 ip_acct_cnt(iph,dev, ip_acct_chain);
157 #endif
158
159 #ifdef CONFIG_IP_MULTICAST
160 //对于多播和广播数据包,其必须复制一份回送给本机
161 /*
162 * Multicasts are looped back for other local users
163 */
164 /*对多播和广播数据包进行处理*/
165 //检查目的地址是否为一个多播地址
166 if (MULTICAST(iph->daddr) && !(dev->flags&IFF_LOOPBACK))
167 {
168 //检查发送设备是否为一个回路设备
169 if(sk==NULL || sk->ip_mc_loop)
170 {
171 if(iph->daddr==IGMP_ALL_HOSTS)//如果是224.0.0.1(默认多播地址)
172 ip_loopback(dev,skb);//数据包回送给发送端
173 else
174 { //检查多播地址列表,对数据包进行匹配
175 struct ip_mc_list *imc=dev->ip_mc_list;
176 while(imc!=NULL)
177 {
178 if(imc->multiaddr==iph->daddr)//如果存在匹配项,则回送数据包
179 {
180 ip_loopback(dev,skb);
181 break;
182 }
183 imc=imc->next;
184 }
185 }
186 }
187 /* Multicasts with ttl 0 must not go beyond the host */
188 //检查ip首部ttl字段,如果为0,则不可进行数据包发送(转发)
189 if(skb->ip_hdr->ttl==0)
190 {
191 kfree_skb(skb, FREE_READ);
192 return;
193 }
194 }
195 #endif
196 //对广播数据包的判断
197 if((dev->flags&IFF_BROADCAST) && iph->daddr==dev->pa_brdaddr && !(dev->flags&IFF_LOOPBACK))
198 ip_loopback(dev,skb);
199
200 //对发送设备当前状态的检查,如果处于非工作状态,则无法发送数据包,此时进入else执行
201 if (dev->flags & IFF_UP)
202 {
203 /*
204 * If we have an owner use its priority setting,
205 * otherwise use NORMAL
206 */
207 //调用下层接口函数dev_queue_xmit,将数据包交由链路层处理
208 if (sk != NULL)
209 {
210 dev_queue_xmit(skb, dev, sk->priority);
211 }
212 else
213 {
214 dev_queue_xmit(skb, dev, SOPRI_NORMAL);
215 }
216 }
217 else
218 {
219 ip_statistics.IpOutDiscards++;
220 if (free)
221 kfree_skb(skb, FREE_WRITE);//丢弃数据包,对tcp可靠传输而言,将造成数据包超时重传
222 }
223 }
函数功能主要为:相关合法性检查、防火墙过滤、对数据包是否需要分片发送进行检查、进行可能的数据包缓存处理、调用下层接口函数 dev_queue_xmit 将数据包送往链路层进行处理。
当数据包大小大于最大传输单元时,需要将数据包分片传送,这里则是通过函数 ip_fragment 实现的。
4)dev_queue_xmit
链路层函数,负责将数据包传递给驱动程序,由驱动程序最终将数据发送到物理介质上。
skb:被发送的数据包;
dev:数据包发送网络接口设备;
pri:网络接口设备忙时,缓存该数据包时使用的优先级
1 void dev_queue_xmit(struct sk_buff *skb, struct device *dev, int pri)
2 {
3 unsigned long flags;
4 int nitcount;
5 struct packet_type *ptype;//用于网络层协议
6 int where = 0; /* used to say if the packet should go */
7 /* at the front or the back of the */
8 /* queue - front is a retransmit try */
9
10 if (dev == NULL)
11 {
12 printk("dev.c: dev_queue_xmit: dev = NULL\n");
13 return;
14 }
15
16 //加锁
17 if(pri>=0 && !skb_device_locked(skb))
18 skb_device_lock(skb); /* Shove a lock on the frame */
19 #ifdef CONFIG_SLAVE_BALANCING
20 save_flags(flags);//保存状态
21 cli();
22 //检查是否使用了主从设备的连接方式
23 //如果采用了这种方式,则发送数据包时,可在两个设备之间平均负载
24 if(dev->slave!=NULL && dev->slave->pkt_queue < dev->pkt_queue &&
25 (dev->slave->flags & IFF_UP))
26 dev=dev->slave;
27 restore_flags(flags);
28 #endif
29 #ifdef CONFIG_SKB_CHECK
30 IS_SKB(skb);//检查数据包的合法性
31 #endif
32 skb->dev = dev;//指向数据包发送设备对应结构
33
34 /*
35 * This just eliminates some race conditions, but not all...
36 */
37 //检查以免造成竞争条件,事实上skb->next == NULL的
38 if (skb->next != NULL)
39 {
40 /*
41 * Make sure we haven't missed an interrupt.
42 */
43 printk("dev_queue_xmit: worked around a missed interrupt\n");
44 start_bh_atomic();//原子操作,宏定义
45 dev->hard_start_xmit(NULL, dev);
46 end_bh_atomic();
47 return;
48 }
49
50 /*
51 * Negative priority is used to flag a frame that is being pulled from the
52 * queue front as a retransmit attempt. It therefore goes back on the queue
53 * start on a failure.
54 */
55 //优先级为负数,表示当前处理的数据包是从硬件队列中取下的,而非上层传递的新数据包
56 if (pri < 0)
57 {
58 pri = -pri-1;
59 where = 1;
60 }
61
62 if (pri >= DEV_NUMBUFFS)
63 {
64 printk("bad priority in dev_queue_xmit.\n");
65 pri = 1;
66 }
67
68 /*
69 * If the address has not been resolved. Call the device header rebuilder.
70 * This can cover all protocols and technically not just ARP either.
71 */
72 //arp标识是否完成链路层的硬件地址解析,如果没完成,则需要调用rebuild_header(eth_rebuild_header函数)
73 //完成链路层首部的创建工作
74 if (!skb->arp && dev->rebuild_header(skb->data, dev, skb->raddr, skb)) {
75 return;//这将启动arp地址解析过程,则数据包的发送则由arp协议模块负责,所以这里直接返回
76 }
77
78 save_flags(flags);
79 cli();
80 if (!where) {//where=1,表示这是从上层接受的新数据包
81 #ifdef CONFIG_SLAVE_BALANCING
82 skb->in_dev_queue=1;//标识该数据包缓存在设备队列中
83 #endif
84 skb_queue_tail(dev->buffs + pri,skb);//插入到设备缓存队列的尾部
85 skb_device_unlock(skb); /* Buffer is on the device queue and can be freed safely */
86 skb = skb_dequeue(dev->buffs + pri);//从设备缓存队列的首部读取数据包,这样取得的数据包可能不是我们之前插入的数据包
87 skb_device_lock(skb); /* New buffer needs locking down */
88 #ifdef CONFIG_SLAVE_BALANCING
89 skb->in_dev_queue=0;//该数据包当前不在缓存队列中
90 #endif
91 }
92 restore_flags(flags);//恢复状态
93
94 /* copy outgoing packets to any sniffer packet handlers */
95 //内核对混杂模式的支持。不明白...
96 if(!where)
97 {
98 for (nitcount= dev_nit, ptype = ptype_base; nitcount > 0 && ptype != NULL; ptype = ptype->next)
99 {
100 /* Never send packets back to the socket
101 * they originated from - MvS (miquels@drinkel.ow.org)
102 */
103 if (ptype->type == htons(ETH_P_ALL) &&
104 (ptype->dev == dev || !ptype->dev) &&
105 ((struct sock *)ptype->data != skb->sk))
106 {
107 struct sk_buff *skb2;
108 if ((skb2 = skb_clone(skb, GFP_ATOMIC)) == NULL)//复制一份数据包
109 break;
110 /*
111 * The protocol knows this has (for other paths) been taken off
112 * and adds it back.
113 */
114 skb2->len-=skb->dev->hard_header_len;//长度
115 ptype->func(skb2, skb->dev, ptype);//协议处理函数
116 nitcount--;
117 }
118 }
119 }
120 start_bh_atomic();
121 //下面调用hard_start_xmit函数,前面skb->next不为NULL时,也调用这个函数,不过参数数据包skb是NULL
122 //驱动层发送数据包,关联到了具体的网络设备处理函数,将进入真实的网卡驱动(物理层)
123 //高版本的内核协议栈,还有虚拟设备,这个版本就是直接进入真实设备
124 if (dev->hard_start_xmit(skb, dev) == 0) {
125 end_bh_atomic();
126 /*
127 * Packet is now solely the responsibility of the driver
128 */
129 return;
130 }
131 end_bh_atomic();
132
133 /*
134 * Transmission failed, put skb back into a list. Once on the list it's safe and
135 * no longer device locked (it can be freed safely from the device queue)
136 */
137 cli();
138 #ifdef CONFIG_SLAVE_BALANCING
139 skb->in_dev_queue=1;//如果使用主从设备,就缓存在队列中
140 dev->pkt_queue++;//该设备缓存的待发送数据包个数加1
141 #endif
142 skb_device_unlock(skb);
143 skb_queue_head(dev->buffs + pri,skb);//把数据包插入到数据包队列头中
144 restore_flags(flags);
145 }
5.recv过程
5.1.总体流程
(1)应用层:
1.应用调用 read 或者 recvfrom 时,该调用会被映射为/net/socket.c 中的 sys_recv 系统调用,并被转化为 sys_recvfrom 调用,然后调用 sock_recgmsg 函数。
2.对于 INET 类型的 socket,/net/ipv4/af_inet.c 中的 inet_recvmsg 方法会被调用,它会调用相关协议的数据接收方法。
3.TCP 调用 tcp_recvmsg。该函数从 socket buffer 中拷贝数据到 user buffer。
(2)传输层:
1.tcp_v4_rcv函数为TCP的总入口,数据包从IP层传递上来,进入该函数,其中handler即为IP层向TCP传递数据包的回调函数,设置为tcp_v4_rcv,tcp_v4_rcv函数只要做以下几个工作:(1) 设置TCP_CB (2) 查找控制块 (3)根据控制块状态做不同处理,包括TCP_TIME_WAIT状态处理,TCP_NEW_SYN_RECV状态处理,TCP_LISTEN状态处理 (4) 接收TCP段
2.调用的也就是__sys_recvfrom,整个函数的调用路径与send非常类似。整个函数实际调用的是sock->ops->recvmsg(sock,msg,msg_data_left(msg),flags),同样,根据tcp_port结构的初始化,调用的其实是tcp_rcvmsg
3.维护三个队列,prequeue、backlog、receive_queue,分别为预处理队列,后备队列和接收队列,在连接建立后,若没有数据到来,接收队列为空,进程会在sk_busy_loop函数内循环等待,知道接收队列不为空,并调用函数skb_copy_datagram_msg将接收到的数据拷贝到用户态,实际调用的是__skb_datagram_iter
(3)网络层:
1.IP层的入口函数在 ip_rcv 函数。该函数首先会做包括 package checksum 在内的各种检查,如果需要的话会做 IP defragment(将多个分片合并),然后 packet 调用已经注册的 Pre-routing netfilter hook ,完成后最终到达 ip_rcv_finish 函数。
2.ip_rcv_finish 函数会调用ip_route_input函数,进入路由处理环节。会调用 ip_route_input 来更新路由,然后查找 route,决定该会被发到本机还是会被转发还是丢弃。
3.如果是发到本机的话,调用 ip_local_deliver 函数,可能会做 de-fragment(合并多个 IP packet),然后调用 ip_local_deliver 函数。如果需要转发 (forward),则进入转发流程,调用 dst_input 函数。
(4)链路层:
1.机器的物理网络适配器接收到数据帧时,就会触发一个中断,并将通过 DMA 传送到位于 linux kernel 内存中的 rx_ring。
2.终端处理程序经过简单处理后,发出一个软中断(NET_RX_SOFTIRQ),通知内核接收到新的数据帧。进入软中断处理流程,调用 net_rx_action 函数。包从 rx_ring 中被删除,进入 netif _receive_skb 处理流程。
3.netif_receive_skb根据注册在全局数组 ptype_all 和 ptype_base 里的网络层数据报类型,把数据报递交给不同的网络层协议的接收函数(INET域中主要是ip_rcv和arp_rcv)。
5.2.gdb调试
传输层:

网络层:
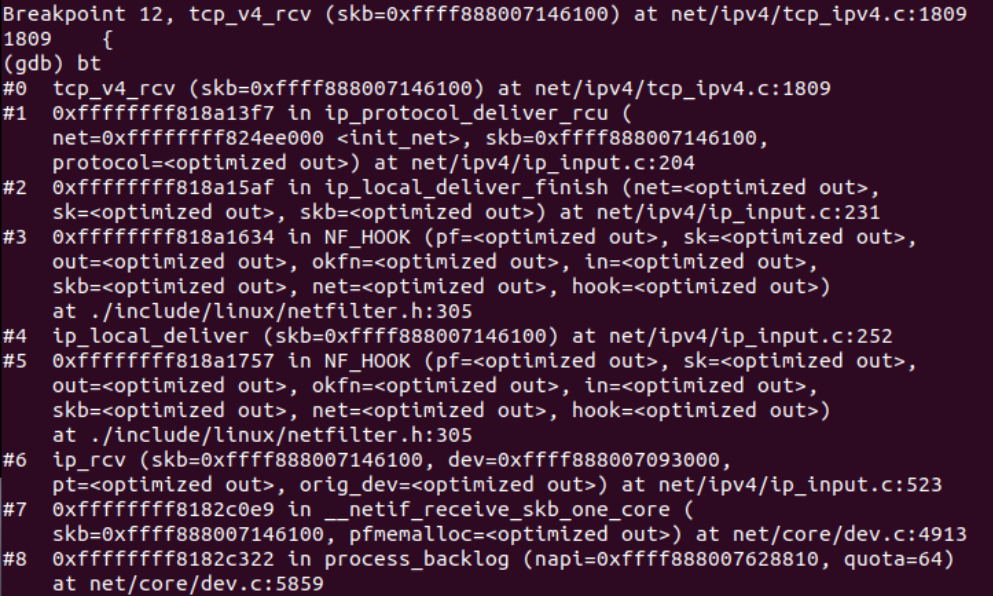
5.3.源代码分析
1)tcp_rcv
是tcp协议数据包处理的总中心,其内部涉及到tcp状态转换,主要功能:设置TCP_CB、查找控制块 、根据控制块状态做不同处理,包括TCP_TIME_WAIT状态处理,TCP_NEW_SYN_RECV状态处理,TCP_LISTEN状态处理、接收TCP段。
1 int tcp_rcv(struct sk_buff *skb, struct device *dev, struct options *opt,
2 unsigned long daddr, unsigned short len,
3 unsigned long saddr, int redo, struct inet_protocol * protocol)
4 {
5 struct tcphdr *th;
6 struct sock *sk;
7 int syn_ok=0;
8
9 //参数有效性检查
10 if (!skb)
11 {
12 printk("IMPOSSIBLE 1\n");
13 return(0);
14 }
15 //数据包必须通过网口设备才能被接收
16 if (!dev)
17 {
18 printk("IMPOSSIBLE 2\n");
19 return(0);
20 }
21
22 tcp_statistics.TcpInSegs++;
23 //如果不是发送给本地的数据包,在网络层就已经被处理,不会传送到传输层来
24 if(skb->pkt_type!=PACKET_HOST)
25 {
26 kfree_skb(skb,FREE_READ);
27 return(0);
28 }
29
30 th = skb->h.th;//获取数据包对应tcp首部
31
32 /*
33 * Find the socket.
34 */
35 //根据tcp首部找到对应的套接字,主要是根据首部里的tcp 四要素,这里是查找最佳匹配的套接字
36 //这个套接字既可以是客户端,也可以是服务器端,这个套接字是本地套接字,是该数据包目的接收的套接字,通过目的端口号定位的
37 sk = get_sock(&tcp_prot, th->dest, saddr, th->source, daddr);
38
39 /*
40 * If this socket has got a reset it's to all intents and purposes
41 * really dead. Count closed sockets as dead.
42 *
43 * Note: BSD appears to have a bug here. A 'closed' TCP in BSD
44 * simply drops data. This seems incorrect as a 'closed' TCP doesn't
45 * exist so should cause resets as if the port was unreachable.
46 */
47 //本地套接字已经被复位或者已经处于关闭状态,则不可接收该数据包
48 if (sk!=NULL && (sk->zapped || sk->state==TCP_CLOSE))
49 sk=NULL;//用作下面的if判断
50
51 if (!redo) //redo=0,表示这是一个新的数据包,所以需要进行检查其合法性
52 {
53 //计算tcp校验和
54 if (tcp_check(th, len, saddr, daddr ))
55 {
56 skb->sk = NULL;
57 kfree_skb(skb,FREE_READ);
58 /*
59 * We don't release the socket because it was
60 * never marked in use.
61 */
62 return(0);
63 }
64 th->seq = ntohl(th->seq);//序列号字节序转换
65
66 /* See if we know about the socket. */
67 //检查套接字是否有效,即是否存在,存在又是否已经被复位或关闭
68 if (sk == NULL)//如果上述某种情况是肯定的
69 {
70 /*
71 * No such TCB. If th->rst is 0 send a reset (checked in tcp_reset)
72 */
73 //本地不提供相关服务,此时回送一个RST数据包,复位对方请求
74 //防止其一再进行数据包的发送,浪费彼此资源
75 tcp_reset(daddr, saddr, th, &tcp_prot, opt,dev,skb->ip_hdr->tos,255);
76 skb->sk = NULL;
77 /*
78 * Discard frame
79 */
80 kfree_skb(skb, FREE_READ);
81 return(0);
82 }
83 //进入这里表示本地套接字可进行数据包接收
84 //数据包字段设置
85 skb->len = len;//数据部分长度
86 skb->acked = 0;
87 skb->used = 0;
88 skb->free = 0;
89 skb->saddr = daddr;//ip地址设置
90 skb->daddr = saddr;
91
92 /* We may need to add it to the backlog here. */
93 cli();
94 if (sk->inuse) //当前该套接字正在被使用,即当前套接字正忙,无暇处理这里的任务
95 {
96 skb_queue_tail(&sk->back_log, skb);//就将数据包暂存在back_log队列中,稍候由release_sock函数重新接收
97 sti();
98 return(0);
99 }
100 sk->inuse = 1;//否则,加锁,表示该套接字正在这里被使用
101 sti();
102 }
103 else//redo=1,表示该数据包来源于back_log缓存队列
104 {
105 if (sk==NULL) //同样进行检查判断
106 {//回送RST
107 tcp_reset(daddr, saddr, th, &tcp_prot, opt,dev,skb->ip_hdr->tos,255);
108 skb->sk = NULL;
109 kfree_skb(skb, FREE_READ);
110 return(0);
111 }
112 }
113
114 //prot字段是一个proto类型结构变量,表示所使用的传输层协议处理函数集合
115 //在创建套接字时,会根据所使用流类型进行该字段的相应初始化(见socket函数源码,以及UNP V1)
116 if (!sk->prot)
117 {
118 printk("IMPOSSIBLE 3\n");
119 return(0);
120 }
121
122
123 /*
124 * Charge the memory to the socket.
125 */
126 //检查接收缓冲区空余空间,查看剩余空间是否足够接收当前数据包
127 //sk->rcvbuf - sk->rmem_alloc =< skb->mem_len
128 //最大接收队列的大小 - 已经接收到的 = 还可以接收的大小
129
130 if (sk->rmem_alloc + skb->mem_len >= sk->rcvbuf)
131 {
132 //如果空间不够,则丢弃该数据包,将造成远端超时重发,这正是本地想要的
133 //到时或许就有足够空间接收了
134 kfree_skb(skb, FREE_READ);
135 release_sock(sk);//重新接收
136 return(0);
137 }
138 //如果接收缓冲区空间足够,那么更新已接收缓冲区值
139 skb->sk=sk;
140 sk->rmem_alloc += skb->mem_len;//缓冲区中已经存放的大小
141
142 /*
143 * This basically follows the flow suggested by RFC793, with the corrections in RFC1122. We
144 * don't implement precedence and we process URG incorrectly (deliberately so) for BSD bug
145 * compatibility. We also set up variables more thoroughly [Karn notes in the
146 * KA9Q code the RFC793 incoming segment rules don't initialise the variables for all paths].
147 */
148 //不是处于已连接状态,那么该数据包则不是数据传送数据包,是进行三次握手或四次挥手中的某个数据包
149 //下面的操作严格符合TCP三次握手状态转换,对照TCP状态转换图理解
150
151 if(sk->state!=TCP_ESTABLISHED) /* Skip this lot for normal flow */
152 {
153
154 /*
155 * Now deal with unusual cases.
156 */
157 //如果是处于监听状态,该套接字为服务器端,且等待的是请求连接数据包,而非数据传送数据包
158 if(sk->state==TCP_LISTEN)
159 {
160 //监听套接字只响应连接请求(SYN 数据包),对于其余类型数据包不做负责,
161 //处于TCP_LISTEN 状态的套接字只指示内核应接受指向该套接字的连接请求
162 //如果收到的是一个ACK应答数据包,表示这个数据包发错了地方,则回送RST数据包
163 if(th->ack) /* These use the socket TOS.. might want to be the received TOS */
164 tcp_reset(daddr,saddr,th,sk->prot,opt,dev,sk->ip_tos, sk->ip_ttl);
165
166 /*
167 * We don't care for RST, and non SYN are absorbed (old segments)
168 * Broadcast/multicast SYN isn't allowed. Note - bug if you change the
169 * netmask on a running connection it can go broadcast. Even Sun's have
170 * this problem so I'm ignoring it
171 */
172 //同样进行检查数据包类型,以及请求对象地址情况
173 if(th->rst || !th->syn || th->ack || ip_chk_addr(daddr)!=IS_MYADDR)
174 {
175 kfree_skb(skb, FREE_READ);
176 release_sock(sk);
177 return 0;
178 }
179
180 /*
181 * Guess we need to make a new socket up
182 */
183 //到了这一步,可认定这是一个SYN数据包,表示该数据包是客户端发过来的连接请求
184 //则调用tcp_conn_request 函数对连接请求做出响应
185
186 //该函数处理连接请求,主要完成新通信套接字的创建和初始化工作,并且这个请求数据包此后进行的所有工作将由这个新套接字负责
187 //具体看下一个函数剖析
188 tcp_conn_request(sk, skb, daddr, saddr, opt, dev, tcp_init_seq());
189
190 /*
191 * Now we have several options: In theory there is nothing else
192 * in the frame. KA9Q has an option to send data with the syn,
193 * BSD accepts data with the syn up to the [to be] advertised window
194 * and Solaris 2.1 gives you a protocol error. For now we just ignore
195 * it, that fits the spec precisely and avoids incompatibilities. It
196 * would be nice in future to drop through and process the data.
197 */
198 //处理back_log队列中先前被缓存的其他连接请求,并做出响应
199 release_sock(sk);
200 return 0;
201 }
202
203 /* retransmitted SYN? */
204 //重发的SYN数据包处理,直接丢弃
205 if (sk->state == TCP_SYN_RECV && th->syn && th->seq+1 == sk->acked_seq)
206 {
207 kfree_skb(skb, FREE_READ);
208 release_sock(sk);
209 return 0;
210 }
211
212 /*
213 * SYN sent means we have to look for a suitable ack and either reset
214 * for bad matches or go to connected
215 */
216 //如果状态是SYN_SENT,处于这种状态的一般是客户端,针对本函数,客户端下一个可能状态为RECV和ESTABLISHED
217 //什么情况下进入某种状态,参见TCP状态转换图
218 if(sk->state==TCP_SYN_SENT)
219 {
220 /* Crossed SYN or previous junk segment */
221 //如果ack置位(前提也要syn置位),那么正常情况下是进入ESTABLISHED状态
222 if(th->ack)//检查确认字段,第二个数据包(第二次握手),syn和ack确认字段都得置位
223 {
224 /* We got an ack, but it's not a good ack */
225 if(!tcp_ack(sk,th,saddr,len))//返回0,表示不正常,下面是非正常情况处理
226 {
227 /* Reset the ack - its an ack from a
228 different connection [ th->rst is checked in tcp_reset()] */
229 tcp_statistics.TcpAttemptFails++;
230 tcp_reset(daddr, saddr, th,
231 sk->prot, opt,dev,sk->ip_tos,sk->ip_ttl);//回送RST数据包
232 kfree_skb(skb, FREE_READ);
233 release_sock(sk);
234 return(0);
235 }
236 if(th->rst)//重置控制位rst置位
237 return tcp_std_reset(sk,skb);//释放一个传输连接
238 if(!th->syn)//syn没置位,肯定不行
239 {
240 /* A valid ack from a different connection
241 start. Shouldn't happen but cover it */
242 kfree_skb(skb, FREE_READ);
243 release_sock(sk);
244 return 0;
245 }
246 /*
247 * Ok.. it's good. Set up sequence numbers and
248 * move to established.
249 */
250 syn_ok=1;//不要重置(释放)这个连接 /* Don't reset this connection for the syn */
251
252 //客户端接收到服务器端的数据包(SYN+ACK),然后做出确认应答,回送确认数据包
253 //这里是三次握手的第二次握手阶段,客户端收到数据包,回送确认数据包让对端建立连接为第三次握手
254 //这里sk是套接字,th为数据包的tcp首部,数据包的序列号则是位于tcp首部中,tcp协议提供的是可靠协议
255 //其中之一就是序列号,接收是否正确,要看sk的对应序列号与th的序列号是否匹配
256 sk->acked_seq=th->seq+1;//套接字下一个要接收的数据包的序列号,置为该数据包最后一个序列号+1
257 //其实就是该数据包的下一个数据包数据的第一个字节
258 sk->fin_seq=th->seq;//应答序列号为接收到的该数据包的序列号
259 //发送确认数据包,帮助远端套接字完成连接,内部调用了_queue_xmit函数
260 //下面函数会创建一个确认数据包,且序列号对应
261 tcp_send_ack(sk->sent_seq,sk->acked_seq,sk,th,sk->daddr);
262 tcp_set_state(sk, TCP_ESTABLISHED);//然后客户端套接字进入ESTABLISHED状态
263 tcp_options(sk,th);//更新本地MSS值,告诉对方自己可接收的数据包最大长度
264 sk->dummy_th.dest=th->source;//获取对方的地址
265 sk->copied_seq = sk->acked_seq;//本地程序有待读取数据的第一个序列号
266 if(!sk->dead)
267 {
268 sk->state_change(sk);
269 sock_wake_async(sk->socket, 0);
270 }
271 if(sk->max_window==0)//重置最大窗口大小
272 {
273 sk->max_window = 32;
274 sk->mss = min(sk->max_window, sk->mtu);
275 }
276 }
277 else//ACK标志位没有被设置
278 //即只收到SYN,木有ACK,那就是第二种可能,进入RECV状态(省略了前面的SYN_)
279 {
280 //当客户端在发送 SYN 的同时也收到服务器端的 SYN请求,即两个同时发起连接请求
281 /* See if SYN's cross. Drop if boring */
282 //首先检查syn标志位
283 if(th->syn && !th->rst)
284 {
285 /* Crossed SYN's are fine - but talking to
286 yourself is right out... */
287 //检查是否是自己发送的,不允许自己与自己通信
288 if(sk->saddr==saddr && sk->daddr==daddr &&
289 sk->dummy_th.source==th->source &&
290 sk->dummy_th.dest==th->dest)
291 {
292 tcp_statistics.TcpAttemptFails++;
293 return tcp_std_reset(sk,skb);
294 }
295 //如果通过了以上检查,表明是合法的,那么客户端就会从 SYN_SENT 转换到 SYN_RECV 状态
296 tcp_set_state(sk,TCP_SYN_RECV);//这是两者同时打开连接的情况下
297
298 /*
299 * FIXME:
300 * Must send SYN|ACK here
301 应该在这里发送一个ACK+SYN数据包
302 */
303 }
304 /* Discard junk segment */
305 kfree_skb(skb, FREE_READ);
306 release_sock(sk);
307 return 0;
308 }
309 /*
310 * SYN_RECV with data maybe.. drop through
311 */
312 goto rfc_step6;
313 }
314
315 /*
316 * BSD has a funny hack with TIME_WAIT and fast reuse of a port. There is
317 * a more complex suggestion for fixing these reuse issues in RFC1644
318 * but not yet ready for general use. Also see RFC1379.
319 */
320
321 #define BSD_TIME_WAIT
322 #ifdef BSD_TIME_WAIT
323 //判断处于2MSL状态的套接字是否接收到一个连接请求,如果条件满足,表示接收到一个具有相同
324 //远端地址,远端端口号的连接请求,在处理上是将原来的这个通信套接字释放,而将请求转移给监听套接字
325
326 if (sk->state == TCP_TIME_WAIT && th->syn && sk->dead &&
327 after(th->seq, sk->acked_seq) && !th->rst)
328 {
329 long seq=sk->write_seq;//保存原套接字本地发送序列号最后值
330 if(sk->debug)
331 printk("Doing a BSD time wait\n");
332 tcp_statistics.TcpEstabResets++;
333 sk->rmem_alloc -= skb->mem_len;//接收缓冲区-数据包大小,要关闭连接了,回到解放前
334 skb->sk = NULL;
335 sk->err=ECONNRESET;//被对端释放连接,即对端发送关闭数据包
336 tcp_set_state(sk, TCP_CLOSE);//设置为CLOSE状态
337 sk->shutdown = SHUTDOWN_MASK;//本地关闭,但对端未关闭,所以连接处于半关闭状态
338 release_sock(sk);//如果sk->dead=1,那么该函数执行释放操作,这里是释放套接字
339 //经过上面的操作,原先的通信套接字已被搁浅,这里重新得到对应的套接字,
340 //由于原先的套接字被设置为CLOSE,所以在get_sock查找时会忽略该套接字,所以这里查找的为监听套接字
341 //PS:对于这部分操作不是很理解,就不强行误解了...
342
343 sk=get_sock(&tcp_prot, th->dest, saddr, th->source, daddr);
344 if (sk && sk->state==TCP_LISTEN)//如果是监听套接字
345 {
346 sk->inuse=1;
347 skb->sk = sk;
348 sk->rmem_alloc += skb->mem_len;
349 //调用conn_request函数创建一个新的通信套接字
350 tcp_conn_request(sk, skb, daddr, saddr,opt, dev,seq+128000);
351 release_sock(sk);
352 return 0;
353 }
354 kfree_skb(skb, FREE_READ);
355 return 0;
356 }
357 #endif
358 }
359 }
2)tcp_data_queue()
1 static void tcp_data_queue(struct sock *sk, struct sk_buff *skb)
2 {
3 struct tcp_sock *tp = tcp_sk(sk);
4 bool fragstolen = false;
5 int eaten = -1;
6
7 /* 无数据 */
8 if (TCP_SKB_CB(skb)->seq == TCP_SKB_CB(skb)->end_seq) {
9 __kfree_skb(skb);
10 return;
11 }
12
13 /* 删除路由缓存 */
14 skb_dst_drop(skb);
15
16 /* 去掉tcp首部 */
17 __skb_pull(skb, tcp_hdr(skb)->doff * 4);
18
19 tcp_ecn_accept_cwr(tp, skb);
20
21 tp->rx_opt.dsack = 0;
22
23 /* Queue data for delivery to the user.
24 * Packets in sequence go to the receive queue.
25 * Out of sequence packets to the out_of_order_queue.
26 */
27 /* 预期接收的数据段 */
28 if (TCP_SKB_CB(skb)->seq == tp->rcv_nxt) {
29 /* 窗口为0,不能接收数据 */
30 if (tcp_receive_window(tp) == 0)
31 goto out_of_window;
32
33 /* Ok. In sequence. In window. */
34 /* 进程上下文 */
35
36 /* 当前进程读取数据 */
37 if (tp->ucopy.task == current &&
38 /* 用户空间读取序号与接收序号一致&& 需要读取的数据不为0 */
39 tp->copied_seq == tp->rcv_nxt && tp->ucopy.len &&
40 /* 被用户空间锁定&& 无紧急数据 */
41 sock_owned_by_user(sk) && !tp->urg_data) {
42
43 /* 带读取长度和数据段长度的较小值 */
44 int chunk = min_t(unsigned int, skb->len,
45 tp->ucopy.len);
46 /* 设置running状态 */
47 __set_current_state(TASK_RUNNING);
48
49 /* 拷贝数据 */
50 if (!skb_copy_datagram_msg(skb, 0, tp->ucopy.msg, chunk)) {
51 tp->ucopy.len -= chunk;
52 tp->copied_seq += chunk;
53 /* 完整读取了该数据段 */
54 eaten = (chunk == skb->len);
55
56 /* 调整接收缓存和窗口 */
57 tcp_rcv_space_adjust(sk);
58 }
59 }
60
61 /* 未拷贝到用户空间或者未拷贝完整数据段 */
62 if (eaten <= 0) {
63 queue_and_out:
64 /* 没有拷贝到用户空间,对内存进行检查 */
65 if (eaten < 0) {
66 if (skb_queue_len(&sk->sk_receive_queue) == 0)
67 sk_forced_mem_schedule(sk, skb->truesize);
68 else if (tcp_try_rmem_schedule(sk, skb, skb->truesize))
69 goto drop;
70 }
71
72 /* 添加到接收队列 */
73 eaten = tcp_queue_rcv(sk, skb, 0, &fragstolen);
74 }
75
76 /* 更新下一个期望接收的序号*/
77 tcp_rcv_nxt_update(tp, TCP_SKB_CB(skb)->end_seq);
78 /* 有数据 */
79 if (skb->len)
80 tcp_event_data_recv(sk, skb);
81
82 /* 标记有fin,则处理 */
83 if (TCP_SKB_CB(skb)->tcp_flags & TCPHDR_FIN)
84 tcp_fin(sk);
85
86 /* 乱序队列有数据,则处理 */
87 if (!RB_EMPTY_ROOT(&tp->out_of_order_queue)) {
88
89 /* 将乱序队列中的数据段转移到接收队列 */
90 tcp_ofo_queue(sk);
91
92 /* RFC2581. 4.2. SHOULD send immediate ACK, when
93 * gap in queue is filled.
94 */
95 /* 乱序数据段处理完毕,需要立即发送ack */
96 if (RB_EMPTY_ROOT(&tp->out_of_order_queue))
97 inet_csk(sk)->icsk_ack.pingpong = 0;
98 }
99
100 if (tp->rx_opt.num_sacks)
101 tcp_sack_remove(tp);
102
103 /* 快路检查 */
104 tcp_fast_path_check(sk);
105
106 /* 向用户空间拷贝了数据,则释放skb */
107 if (eaten > 0)
108 kfree_skb_partial(skb, fragstolen);
109
110 /* 不在销毁状态,则唤醒进程读取数据 */
111 if (!sock_flag(sk, SOCK_DEAD))
112 sk->sk_data_ready(sk);
113 return;
114 }
115
116 /* 重传 */
117 if (!after(TCP_SKB_CB(skb)->end_seq, tp->rcv_nxt)) {
118 /* A retransmit, 2nd most common case. Force an immediate ack. */
119 NET_INC_STATS(sock_net(sk), LINUX_MIB_DELAYEDACKLOST);
120 tcp_dsack_set(sk, TCP_SKB_CB(skb)->seq, TCP_SKB_CB(skb)->end_seq);
121
122 out_of_window:
123 /* 进入快速ack模式 */
124 tcp_enter_quickack_mode(sk);
125
126 /* 调度ack */
127 inet_csk_schedule_ack(sk);
128 drop:
129 /* 释放skb */
130 tcp_drop(sk, skb);
131 return;
132 }
133
134 /* Out of window. F.e. zero window probe. */
135 /* 窗口以外的数据,比如零窗口探测报文段 */
136 if (!before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt + tcp_receive_window(tp)))
137 goto out_of_window;
138
139 /* 进入快速ack模式 */
140 tcp_enter_quickack_mode(sk);
141
142 /* 数据段重叠 */
143 if (before(TCP_SKB_CB(skb)->seq, tp->rcv_nxt)) {
144 /* Partial packet, seq < rcv_next < end_seq */
145 SOCK_DEBUG(sk, "partial packet: rcv_next %X seq %X - %X\n",
146 tp->rcv_nxt, TCP_SKB_CB(skb)->seq,
147 TCP_SKB_CB(skb)->end_seq);
148
149 tcp_dsack_set(sk, TCP_SKB_CB(skb)->seq, tp->rcv_nxt);
150
151 /* If window is closed, drop tail of packet. But after
152 * remembering D-SACK for its head made in previous line.
153 */
154 /* 窗口为0,不能接收 */
155 if (!tcp_receive_window(tp))
156 goto out_of_window;
157 goto queue_and_out;
158 }
159
160 /* 接收乱序数据段 */
161 tcp_data_queue_ofo(sk, skb);
162 }
tcp_data_queue作用为数据段的接收处理:
(1) 无数据,释放skb,返回;
(2) 预期接收的数据段,a. 进行0窗口判断;b. 进程上下文,复制数据到用户空间;c. 不满足b或者b未完整拷贝此skb的数据段,则加入到接收队列;d. 更新下一个期望接收的序号;e. 若有fin标记,则处理fin;f. 乱序队列不为空,则处理乱序;g. 快速路径的检查和设置;h. 唤醒用户空间进程读取数据;
(3) 重传的数据段,进入快速ack模式,释放该skb;
(4) 窗口以外的数据段,进入快速ack模式,释放该skb;
(5) 数据段重叠,在进行0窗口判断之后,进行(2)中的加入接收队列,以及>=d的流程;
(6) 乱序的数据段,调用tcp_data_queue_ofo进行乱序数据段的接收处理;
6 时序图


 浙公网安备 33010602011771号
浙公网安备 33010602011771号