机器学习库Scikit-Learn与应用
机器学习:pandas统计只能针对小部分数据,小维度,
从过去的大量的数据中总结出来泛化规律,用于新数据预测
给我一堆数据,我怎么根据数据总结规律呢?
监督学习:
给一堆数据,然后给出标准答案,训练建立新的模型,然后用新的数据使用该模型,做出预测
分类问题:不同类别的预测,离散的,是属于哪一类?是还是不是?
回归问题(对连续值进行预测):预测结果是哪一个值?
无监督学习:
不是所有的数据都有一个标准答案,对于某些数据,用户也不知道标准答案,只能根据现有数据,划分多个聚类,
物以类聚
数据降维
构建机器学习的一般流程
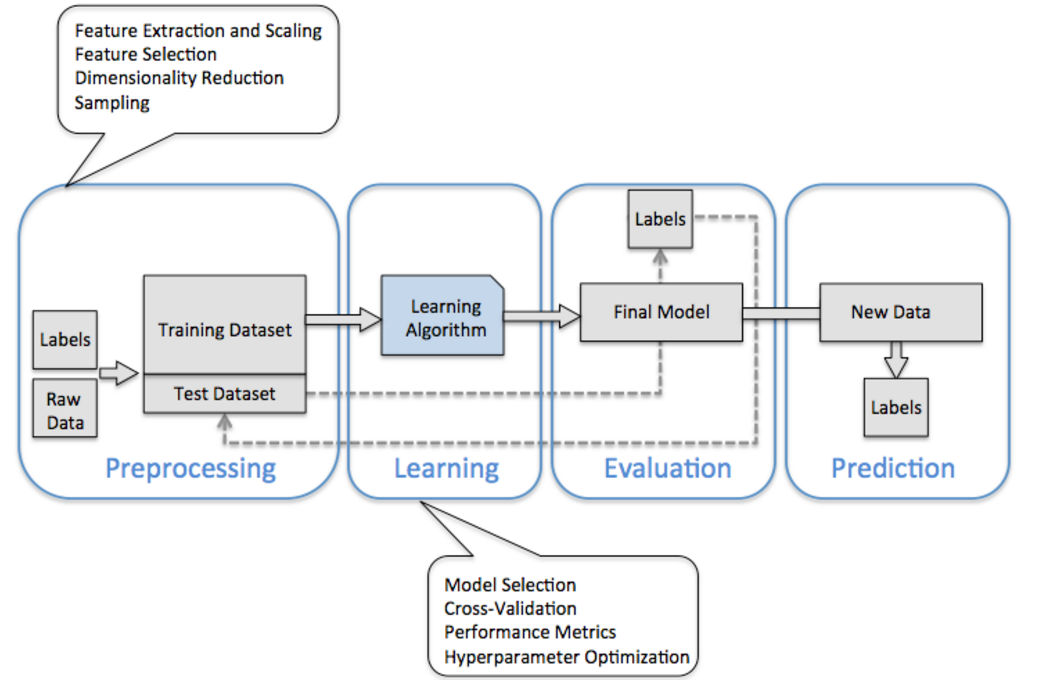
具体使用:


1 from sklearn import datasets,preprocessing,neighbors 2 from sklearn.metrics import accuracy_score 3 from sklearn.model_selection import train_test_split 4 5 iris=datasets.load_iris() 6 X=iris.data #数据 7 #print(iris.feature_names) #特征 8 y=iris.target #标准答案 9 X_train,X_test,y_train,y_test=(train_test_split(X,y,train_size=0.8,test_size=0.2)) #切分训练数据和测试数据,训练数据占80% 10 scaler = preprocessing.StandardScaler().fit(X_train) #拟合数据,缩放等 11 X_train=scaler.transform(X_train) #缩放数据 12 X_test=scaler.transform(X_test) 13 14 #初始化模型 15 knn = neighbors.KNeighborsClassifier(n_neighbors=5) #k邻近 16 knn.fit(X_train, y_train) #训练 17 y_pred = knn.predict(X_test) #预测 18 result=accuracy_score(y_test, y_pred) #评估 19 print(result) #1.0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号