AlexNet实现
- 端到端:神经网络可以直接基于图像的原始像素进行分类。这种称为端到端(end-to-end)的方法节省了很多中间步骤
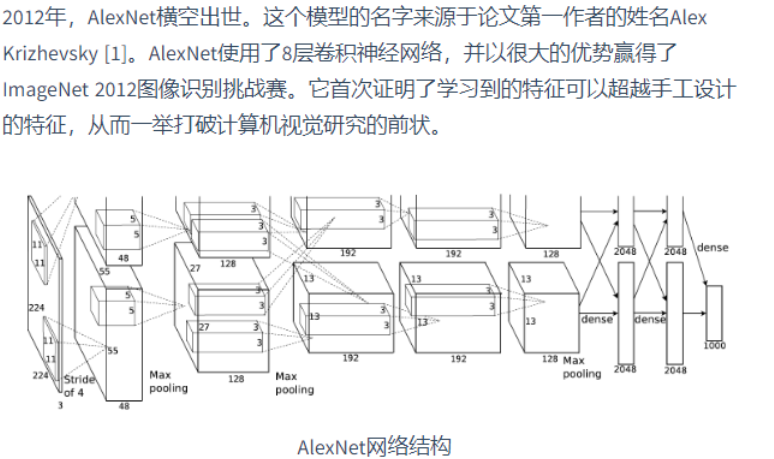
- 特征分级表示:多层神经网络中,图像的第一级的表示可以是在特定的位置和⻆度是否出现边缘;而第二级的表示说不定能够将这些边缘组合出有趣的模式,如花纹;在第三级的表示中,也许上一级的花纹能进一步汇合成对应物体特定部位的模式。这样逐级表示下去,最终,模型能够较容易根据最后一级的表示完成分类任务。需要强调的是,输入的逐级表示由多层模型中的参数决定,而这些参数都是学出来的。
缺乏要素:1、数据 2、硬件
Alex2012
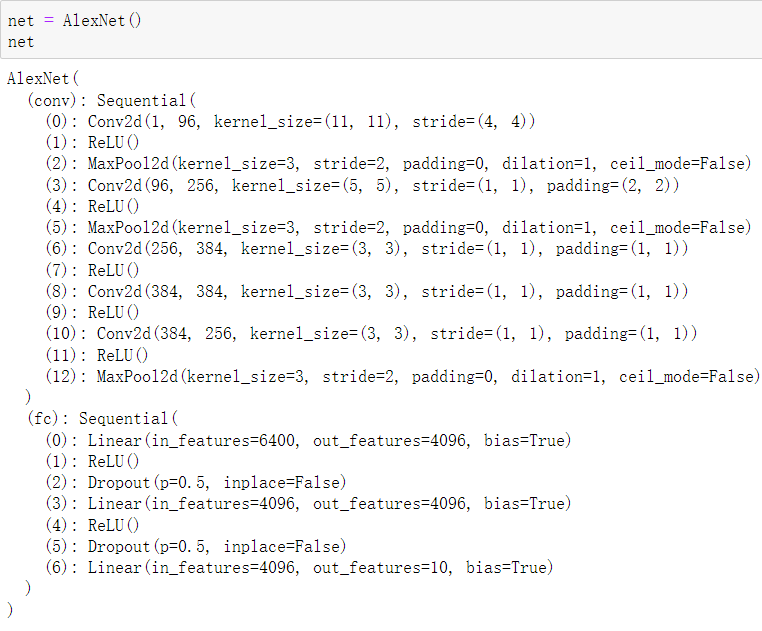
简化实现
import time import torch from torch import nn,optim import torchvision import sys sys.path.append('./Dive-into-DL-PyTorch-master/Dive-into-DL-PyTorch-master/code/') import d2lzh_pytorch as d2l device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') class AlexNet(nn.Module): def __init__(self): super(AlexNet,self).__init__() # in_channels, out_channels, kernel_size, stride, padding self.conv = nn.Sequential(nn.Conv2d(1,96,11,4), nn.ReLU(), # kernel_size,stride nn.MaxPool2d(3,2), # 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数 nn.Conv2d(96,256,5,1,2), nn.ReLU(), nn.MaxPool2d(3,2), # 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。 # 前两个卷积层后不使用池化层来减小输入的高和宽 nn.Conv2d(256,384,3,1,1), nn.ReLU(), nn.Conv2d(384,384,3,1,1), nn.ReLU(), nn.Conv2d(384,256,3,1,1), nn.ReLU(), nn.MaxPool2d(3,2) ) # 这里全连接层的输出个数比LeNet中的大数倍。使用丢弃层来缓解过拟合 self.fc = nn.Sequential(nn.Linear(256*5*5,4096), nn.ReLU(), nn.Dropout(0.5), nn.Linear(4096,4096), nn.ReLU(), nn.Dropout(0.5), # 输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000 nn.Linear(4096, 10), ) def forward(self,img): feature = self.conv(img) # 特征提取 output = self.fc(feature.view(img.shape[0],-1)) return output
# 本函数已保存在d2lzh_pytorch包中方便以后使用 def load_data_fashion_mnist(batch_size, resize=None, root='./data/FashionMNIST/'): """Download the fashion mnist dataset and then load into memory.""" trans = [] if resize: # 重新排列尺寸 trans.append(torchvision.transforms.Resize(size=resize)) trans.append(torchvision.transforms.ToTensor()) # compose 相当于pipple 把数据操作装入管道 transform = torchvision.transforms.Compose(trans) mnist_train = torchvision.datasets.FashionMNIST(root=root, train=True, download=True, transform=transform) mnist_test = torchvision.datasets.FashionMNIST(root=root, train=False, download=True, transform=transform) train_iter = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=4) test_iter = torch.utils.data.DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=4) return train_iter, test_iter batch_size = 128 # 如出现“out of memory”的报错信息,可减小batch_size或resize train_iter, test_iter = load_data_fashion_mnist(batch_size, resize=224)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号