VIT
AN IMAGE IS WORTH 16*16 WORDS: TRANSFORM FOR IMAGE RECOGNITION AT SCALE
1 . ABSTRACT:
在计算机视觉中,注意力和卷积神经网络一起使用,或者用来替代神经网络的某些组件,同时保持总的结构不会发生变化。
在分类任务中,将图像块作为序列作用于纯transfomer的效果是非常好的。
VIT实现了比最先进的卷积神经网络还要好的效果,同时需要非常少的计算机资源训练。
2. introduction
基于自注意力的结构,尤其是transforms,已经是NLP中模型的选择。主要的方法就是在大型的语料库进行预训练,在小或特殊的数据集进行微调。由于transformer的计算的有效性和可扩展性,它可以去训练史无前例的大小,超过100B参数。随着模型和数据集的发展,transformer性能饱和还未出现。
在视觉中,cnn仍然占主导。基于NIP的启发,尝试将cnn和自注意力结合起来(图片先进行卷积,传入特征图到transformer),有些完全代替的卷积。之后的模型,虽然理论上是有效的,但由于使用了专门的注意力模式,在现代硬件加速器上尚未有效地进行扩展。因此,在大型图像识别,典型的类似ResNet的结构仍然是最先进的。
基于transformer在NLP的成功,我们使用了标准的transformer结构直接应用于图像,尽可能做最少的改变。我们将一张图像分成很多小块,为这些patches做Linear embedding作为transformer的输入。patches 做类似于NLP中tokens的操作。分类训练为监督训练。
当训练在中等大小的数据集(ImageNet)并没有强正则化,这些模型的精度比同等规模的ResNet略低几个百分点。这个不太好的结果也在意料当中:transformer 缺少cnn固有的inductive biases,例如翻译等价性和位置,因此,当训练在不充足的数据时,通常表现不太好。
然而,如果模型在更大的数据集(14M-300M图像)上进行训练,则图片会发生变化。我们发现大规模训练胜过归纳偏置。我们的Vision Transformer (VIT)使用足够的规模进行预训练,应用到更少的数据点得到了很棒的结果。当在ImageNet-21K和JFT-300M数据集上,vit在多个图像识别基准上接近或打败了最先进的方法。特别是,最优模型在ImageNet上达到了88.55%的准确率,在ImageNet-REAL上达到了90.72%,在CIFAR-100上达到了94.55%,在包含19个任务的VTAB套件上达到了77.63%。
补充:
1、
transformer基于自注意力,如果使用每个像素点作为token,进行自注意力的规模会很大:例如,224*224图片,展开就是50176,每个像素再进行自注意力计算,规模特别大,所有不能取单个像素。
2、归纳偏置:先验知识,或者提前做好的假设。对于cnn常说有两个归纳偏置:locality:假设相邻的区域会有相邻的特征,translation equivalent 平移等变性:f(g(x)) = g(f(x))无论先做平移还是先做卷积,结果都是一样的,只要图片进来,遇到相同的卷积核,结果都是一样的
2:related work
transformer 由Vaswani(2017)年提出,现在已经在NLP任务领域成为了最先进的方法。基于Transformer的大型模型通常先在大型语料库预训练,在应用任务进行微调:BERT(2019):然而GPT一系列工作使用语言建模作为它的预训练任务。
自注意力的Naive application图片,需要每一个像素都要关注其他像素。使用像素数的二次方代价时,不会缩放到真实的输入大小。因此,在图像处理的上下文中应用transformer,在过去已经尝试了几种类似。Parmar(2018) :仅在Local neighborhoods 每个query进行自注意力,而不是全局。这种local 多头点积自注意力块可以完全代替卷积( (Hu et al., 2019; Ramachandran et al., 2019; Zhao et al., 2020))。在不同的工作中,Sparse transformer (Child et al 2019)使用全局自注意力的可缩放近似,以便应用于图像。另一种扩大注意力的方法是将其应用于不同大小的块(Weissenborn等人,2019年),在极端情况下只沿着单个轴(Hoet.,2019年;Wang等人,2020a)。很多这些特别的注意力架构证明在视觉任务是很有前景的,但是需要复杂的工程在硬件加速器上有效的实现。
和我们的模型最相关的是Cordonnier et al 2020,它从输入图像中提取2×2的patches并且在上一层使用全自注意力。这个模型非常像Vit,但是我们的工作进一步证明了大规模预训练使得vanilla transformer 能够和最先进的cnn进行对抗。此外,Cordonnier et al.(2020)使用2×2像素的小块大小,这使得该模型只适用于小分辨率的图像,而我们在中等分辨率上应用效果也很好。
也有很多将cnn和自注意力结合起来的形式,例如 (Bello et al., 2019) :增强特征图进行分类或者 使用自注意力对cnn的输出进行进一步处理;(Hu et al., 2018) :目标检测;视频处理(Wang et al 2019);图像分类(Wu et al,2020);unsupervised object discovery(Locatello et al),或者unified text-cision task(Chen et al 2020c);
另一个相关的模型为GPT(iGPT Chen et al 2020a),它在降低图像分辨率和颜色空间后将Transformer应用于图像像素。此模型使用无监督作为产生模型进行训练,然后生成的表示进行微调或线性探测probed linearly以提高分类性能,在Imagenet最高的准确率为72%。
我们的工作增加了很多的论文,这些论文比标准的ImageNet更大的规模探索图像识别。使用另外的数据源使我们在标准的基准中得到最先进的结果s (Mahajan et al., 2018; Touvron et al., 2019; Xie et al., 2020).。此外,Sun et al.(2017)研究CNN的性能如何随数据集的大小而扩展,Kolesnikovet等人。(2020);Djolonga等人。(2020)从ImageNet-21k和JFT-300m等大规模数据集对CNN迁移学习进行了实证探索。我们也关注后两个数据集,但是训练transformer而不是以前工作中使用的基于ResNet的模型。
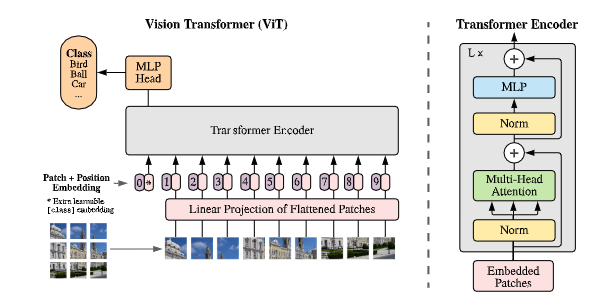
图一:模型概述:我们将一张图片分为固定大小的patches,linearly embed每个patches,position embeddings,将结果向量序列输入到标准的transformer encoder。为了进行分类,我们采用标准方法,向序列中添加额外的可学习的 “ classification token”。transfomrer编码器的插图灵感来自Vaswani等人。(2017)
vit只有encoder,并且利用cls判断所属分类
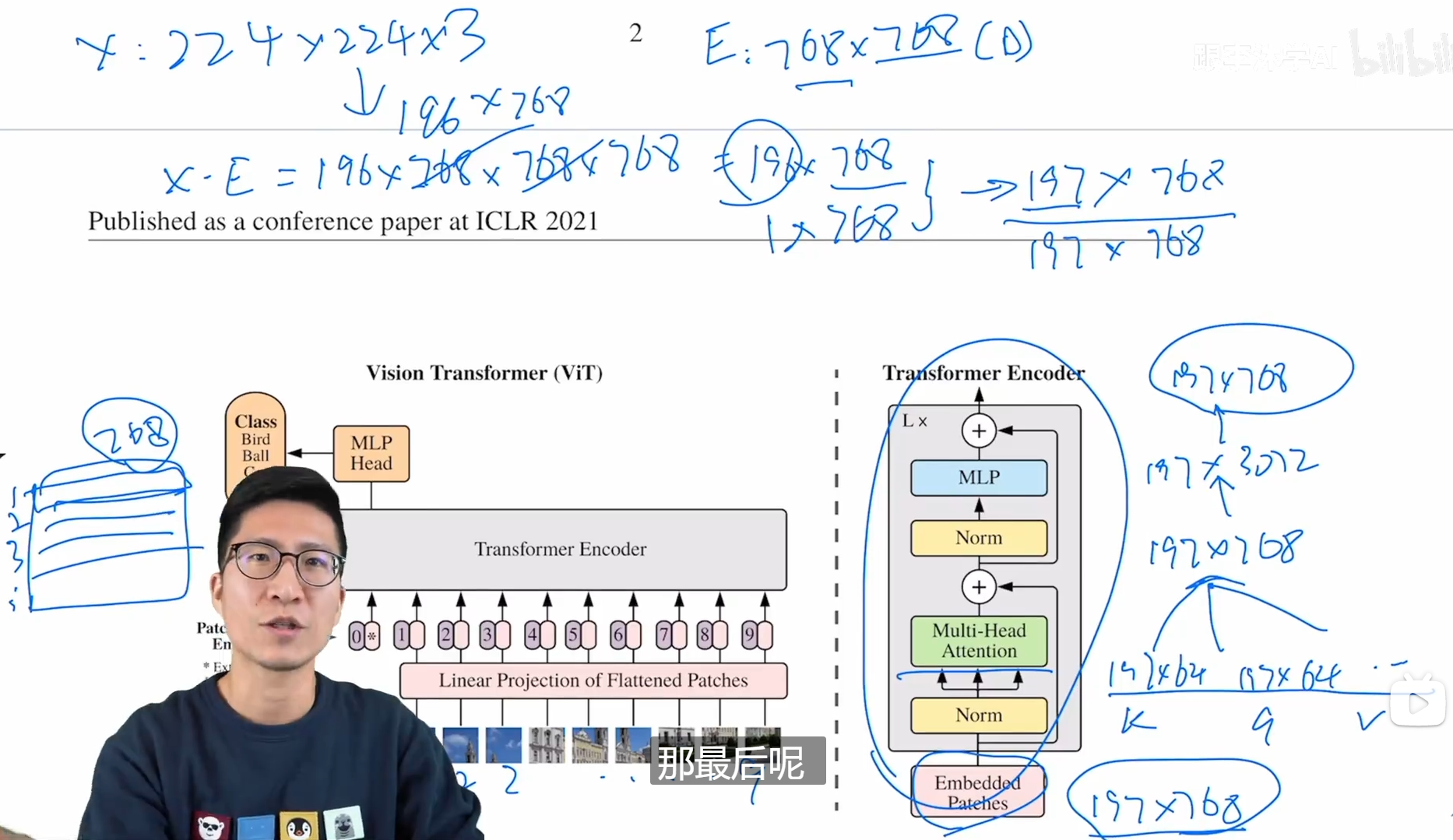
transformer输入197*768,输出197*768 ,所以可以叠加n个块
补充:
BETR: 类似于完型填空,挖掉一些词,然后再将这些词预测出来
GPT:language model 已经有个句子,然后要去预测下一个词
3 method
模型设计我们尽可能的和原始transformer相似。 这种特意简单的设置的一个优点是,可伸缩的NLP Transformer架构及其高效实现几乎可以开箱即用。
3.1 vision transformer (ViT)
模型描述在图1。标准transformer接收到一个1D的token embedding序列作为输入。为处理2D的图像,将(H,W,C)reshape为N×(P方×c),这里的(H,W)是图像最原始的分辨率,c为通道,(P,P)是每个图像patches的分辨率,N=HW/p方 为分成的patches数,它只作为transformer的有效输入序列长度。transformer在所有的层使用恒定的latent vector size D,因此我们flatten the patches 并且使用可训练的线性投影 map to D 维度 (等式1)。我们将投影的输出作为patches embedding。
和BERT的 [class ] token相似,在embedded patches(Z(0,0) = X class) 序列 前加入一个可学习的embedding。transformer encoder的输出state作为图像表示y(等式2)。在预训练和微调中,classification head 达到 z(0,L)。这个分类头通过MLP实现,MLP预训练时有一个隐藏层,在微调时由单个线形层实现。
position embedding 和 patch embedding相加 保留位置信息。我们使用标准可学习的1D position embedding,因为我们没有观测到使用更先进的2D-aware position embedding 而达到更好的效果。embedding 序列结果向量作为encoder的输入。
transformer encoder 由multiheaded self-attention(MSA)可替代层和MLP块组成。LayNorm(LN)应用在之前的每一个块,在块之后使用残差连接。
MLP包含两个GELU非线性层。
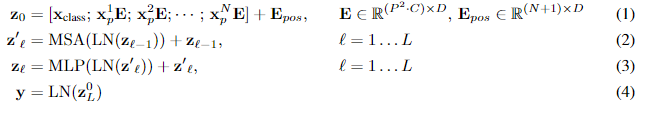
inductive bias: 我们注意到Vit transformer 比cnn有很小的image-specific inductive bias 。在CNN中,locality,wo-dimensional neighborhood structure, and translation equivariance 应用在整个模型的每一个层。在ViT中,只有MLP层是local and translationally equivariant,然而自注意层是全局的。这种two-dimensional neighborhood structure 结构使用的很少:在模型开始将图像裁剪成patches时,和在微调时面对不同的分辨率调整position embedding时。除此之外,position embedding 在初始化时没有携带任何关于patches 2D 信息,并且所有patches之间的空间关系要从scratch中学习。
Hybrid Architecture(混合式体系结构):作为对原始图像patches的替代方案,输入序列能够从cnn的特征图中获取。在这个混合的模型,patch embedding 映射 E应用于从cnn特征图中提取的patch。作为特例,patches可以是1×1空间大小,这意味着输入序列是通过简单的flatten特征图的空间维度并且投影到transformer的维度。
3.2 fine-tunning and higher resolution
通常,我们预训练ViT在大的数据集上,在小的下游任务做微调。为此,我们移除了预训练预测头,附上了一个zero-initialized D ×K feedforwardlayer,k是下游任务的类别。与预训练相比,在更高的分辨率下进行微调通常是有益的。当提供高分辨率图像时,我们保持patch大小相同,这产生了一个大而有效的序列长度。ViT能够处理任意的序列长度(达到内存限制)。然而,预训练的position embedding 就不再有意义了,因此我们展示了预训练position embedding的2D interpolation, 根据他们在原始图像中的位置。注意,分辨率的调整和patch提取唯一的点在于2D图像结构的inductive bias 是手动的注入到Vision transformer的。
4 experiments
我们对ResNe的表征学习能力进行了评估,ViT和混合式。去了解每一个模型对数据的需求,我们预训练在不同大小的数据集并且评估了很多基准任务。当考虑到预训练模型的计算成本时,ViT的表现很好,在大多数识别如任务基准达到了最先进的结果并且预训练代价更低。最后,我们展示了一个使用自监督的小实验,自监督ViT未来是充满希望的。
4.1 setup (安排)
数据集:为探索模型的可扩展性,我们使用ILSVRC-2012 ImageNet 数据集和1K classes和1.3M 图片(在下面我们统称为ImageNet),它的超集包含其中包含1k个类和13M个图像。我们对预训练的数据集w.r.t进行重复消除。以下是下游任务的测试集。我们将模型寻来你在这些数据集做几个基准任务:ImageNet 原始验证标签和清理后的Real 标签,CIFAR-10/100,Oxford-IIIT Pets,和Oxford Flowers-102.
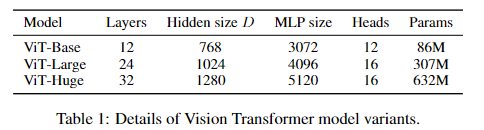
我们也在19-task VTAB 分类suite 进行了评估。VTAB 评估少数据作用于不同的任务,每个任务使用1000训练实例。任务被分为三个组:Natural:任务类似于上面的CIFAR.
5 结论:
我们已经将transform直接用于图像识别进行了探索。和之前在视觉任务中红使用自注意力不同,我们在结构中除了提取patch就再没有引进image-specific inductive biase。代替的是,我们将图片解释为patch序列通过一个标准的transformer encoder 处理。这一简单但可伸缩的策略在与大型数据集的预训练相结合时效果出奇地好。因此,vit 比肩或胜出最先进的方法,相对也需要更少的资源去预训练。
然而这些初步的结果是非常鼓舞人的,挑战仍然存在。一个就是将vit应用于其他视觉任务,目标检测和分割。另一个就是继续去探索自注意力预训练方法。我们的初步实验表明,自我监督的预训练有所改善,但与大规模监督的预训练相比,仍有较大差距。最后,VIT的进一步扩展可能会导致性能的提高。
6 补充:
1、使用cnn不好处理的使用vit很好处理:遮挡,偏移,对抗,排列组合


 浙公网安备 33010602011771号
浙公网安备 33010602011771号