python基础
1.1 print() 输出函数

# 输出数字 print(520) print(98.5) # 输出字符串 print('helloworld') # 含有运算符的表达式 print(3 + 5 + 4) # 输出到文件 #注意 1指定盘存在 2使用file=fp 不然写不进去 fp = open('D:/text.txt', 'a+') # a+ 文件不存在就创建 ,存在就追加 print('helloworld', file=fp) fp.close() # 不进行换行输出 print('hello', 'word')
1.2 转义字符
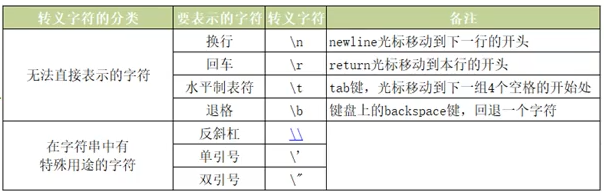
# 转义字符 print('hello\nhello') print('hello\thello') print('helloooo\thello') # 此处\t空格会多 print('world\rhello') # 只输出hello print('hello\bworld') # 退一个格 o没了 print('http:\\\\www.baidu.com') # \转义加 print('大家好:\'早上好\'') # 原字符 不希望转义字符起作用 在字符串之前加上r或R print(r'hello\nword') # 注意最后一个字符不能是\ 可以\\

1.3 保留字
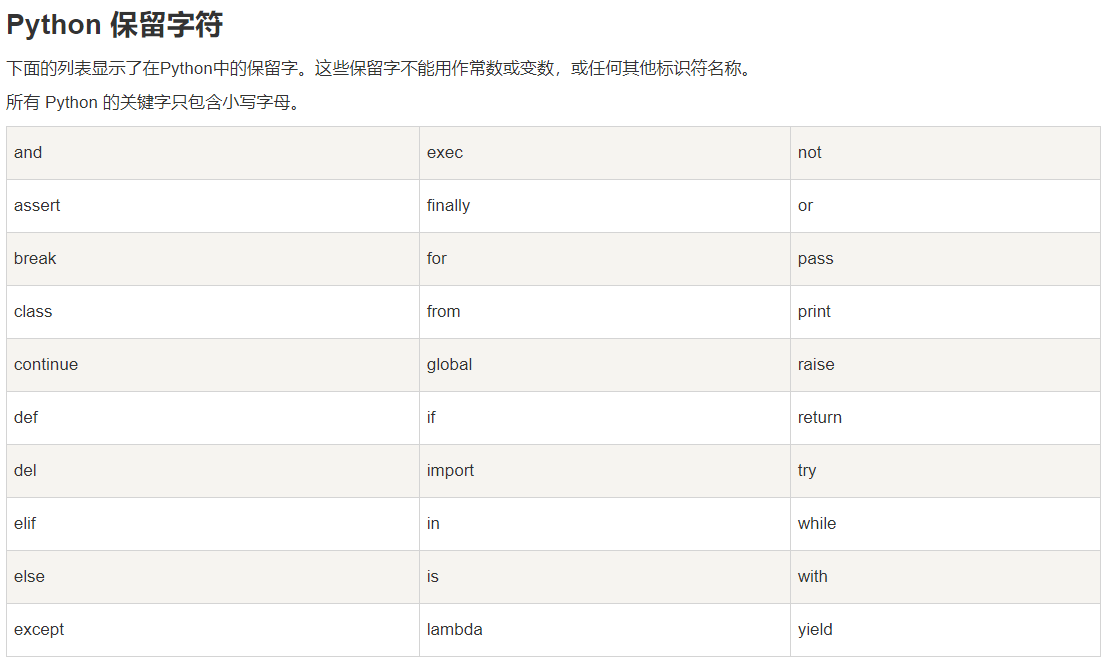
1.4 格式问题
if True: print('true') else: print('false')
上面的为正确,而下面的为错误,python格式严格
if True: print('true') else: print('false')
报错 IndentationError: expected an indented block
建议你在每个缩进层次使用 单个制表符 或 两个空格 或 四个空格 , 切记不能混用
1.5 多行注释
python 中多行注释使用三个单引号(''')或三个双引号(""")
''' 这里是多行注释 ''' """ 这里也是多行注释 """
1.6 同一行显示多条语句
Python可以在同一行中使用多条语句,语句之间使用分号(;)分割
print('第一条语句') ;print('第二条语句 要使用;分号断开')
1.7 不换行输出
# 换行输出 print(x) print(y) # 不换行输出 print(x, end=""), print(y)
2.1 赋值
name = 'coline' #name里存的是id 指向coline print('值', name) print('类型', type(name)) print('标识', id(name)) # 内存地址
2.2 数据类型

# 进制 可以为二进制,十进制,八进制,十六进制 默认十进制 print('十进制', 118) print('二进制', 0b1010101) print('八进制', 0o45712) print('十六进制', 0x152A1)
浮点类型
# 浮点类型 a = 3.1415 print(a, type(a)) n1 = 1.1 n2 = 2.2 print(n1+n2) # 结果 3.3000000000000003 有误差 不一定所以都会出现 # 解决方法 导入模块 from decimal import Decimal print(Decimal('1.1')+Decimal('2.2')) # 结果 3.3
布尔类型
# 布尔bool 可以直接和整数相加 print(True+1) # 2 print(False+1) # 1
字符串类型
# 字符串类型 统称字符串 str1 = '单引号' str2 = "单引号" str3 = """单引号 可以多行写""" # 会按照原样输出 print(str1, type(str1)) print(str2, type(str2)) print(str3, type(str3))
字符串截取
str = 'new.txt' index = str.rfind('.') # 3 查询.所在下标 # 字符串[起始下标(默认为0):结束下标(不包括):步长(默认为1)] print(str[:2]) # ne print(str[:index]) # new
字符串修改大小写
name = 'li lang' # title()以首字母大写的方式显示每个单词 # 你可能希望程序将值Ada、ADA和ada视为同一个名字, # 并将它们都显示为Ada print(name.title()) # Li Lang print(name.upper()) # LI LANG print(name.lower()) # li lang
字符串合并
# 合并字符串使用+号 first_name = "ada" last_name = "lovelace" full_name = first_name + " " + last_name print(full_name) print("Hello, " + full_name.title() + "!") # Hello, Ada Lovelace!
字符串去空白
# 去重字符串末尾空白rstrip() # 去除开头空白lstrip # 出去两边空白strip favorite_language = 'python ' print(favorite_language) # 去除后需要返回变量中 favorite_language = favorite_language.rstrip() print(favorite_language)
2.3 类型转换
a = 10 b = 198.2 c = False d = '123' print(type(a), type(b), type(c), type(d)) print(str(a), str(b), str(c), str(d)) # 转成字符串 print(int(b), int(d), int(c)) # 转成整形 float-int 会有数据精度丢失 print(float(a), float(c), float(d)) # 转成float 会自己补足精度 print(bool(a), bool(d), bool(b)) # 整形大于1 为 true 字符串为true 除了 ‘True’ 和'flase'
2.4 中文编码声明
# coding:gbk # 修改编码集
3.1 input函数
# 输入函数 present = input('你要什么礼物') print(present, type(present)) # 输入的类型为字符串 需要转换采用类型转换
# 输入函数 present = int(input('你要什么礼物')) # 修改类型 print(present, type(present))
3.2 算数运算符
print(1+1) # 2 print(1-1) # 0 print(1*3) # 3 print(1/3) # 0.333333333 print(1%3) # 1 print(2**3) # 8 2的3次方 # 整除 print(9//4) # 2 print(-9//-4) # 2 print(9//-4) # -3 一正一负 向下取整 print(-9//4) # -3 # %- 公式 余数=被除数-除数*商 print(9%-4) # -3 9-(-4)*(-3) 9-12 -3 print(-9%4) # 3 -9-4*(-3) -9+12 3
3.3 赋值运算符
# 链式赋值 a = b = c = 20 # 内存地址相同 20值的id都一样 都指向同一份地址 print(a, id(a)) print(b, id(b)) print(c, id(c)) # 参数赋值 a = 30 a += 20 print(a) a *= 10 print(a) a /= 2 print(a, type(a)) # float a -= 10 print(a) # 240.0 a //= 3 print(a) # 80.0 a %= 3 print(a) # 2.0 # 解包赋值 a, b, c = 20, 30, 40 print(a, b, c) # 交换两个变量的值 a, b = 20, 30 print('交换前', a, b) a, b = b, a print('交换后', a, b) # 交换后 30 20
3.4 比较运算符
大于 小于 等于 == !=
== 比较的是value值
而比较对象的标识 :is, is not
a,b=10,10 print(a==b) # 说明a与b的value值相等 print(a is b) # 说明a于b的id相等
3.5 布尔运算符
#布尔运算符 a,b=1,2 #and类似于 && print(a==1 and b==2) # true print(a==1 and b<2) #false #or类似于|| print(a==1 or b==2) #true print(a==1 or b!=2) #true print(a!=1 or b>2) #false #not类似取反 f=True print(not f) #false #in 在不在里面 not in 不在 s='hello' print('o' in s) #true o字符在不在s里面 print('o' not in s)#false o字符在s里面
3.6 位运算符
#位运算符 先将数据转为2进制 在进行运算 #& 按位与 print(4&8) #0 #|按位或 print(4|8) #12 #<<左移位 左移动几位 相当于2的多少次放 print(4<<2)#16 #>>右移位 相当于除以2的多少次方 print(4>>2) #1
3.7 运算符优先级
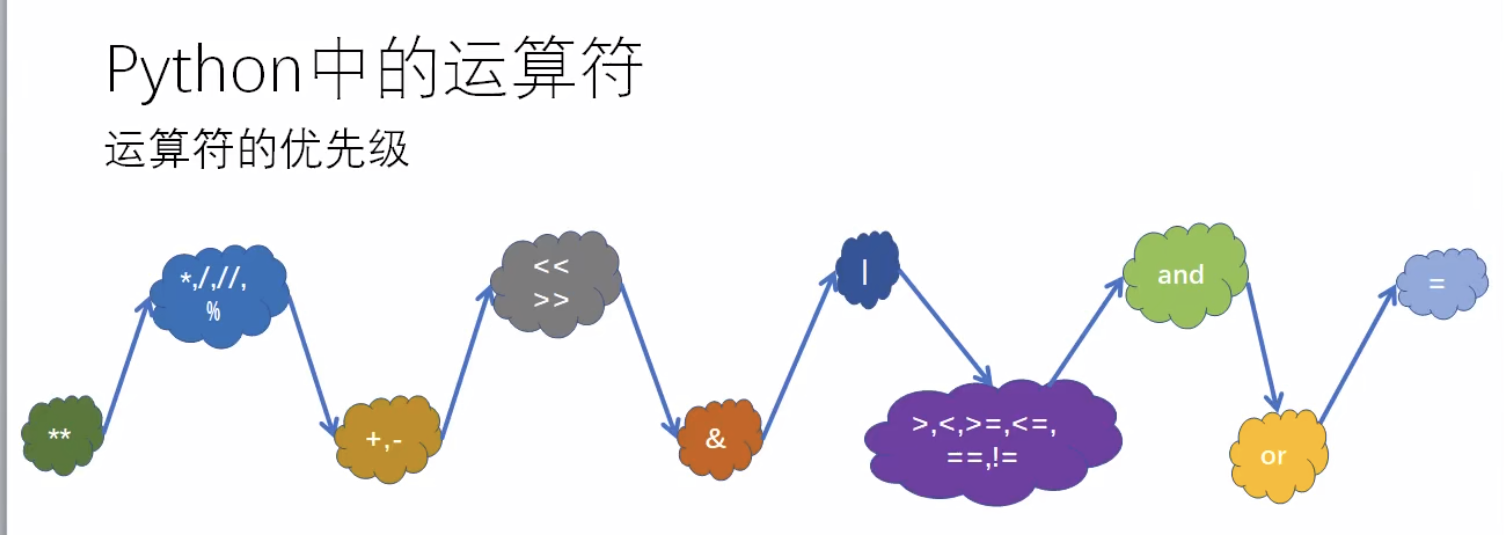
3.8 程序的组织结构
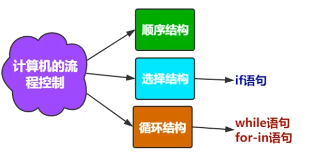
# 以下bool值为false # 测试对象的bool值 print(bool(False)) # False print(bool(0)) # False print(bool(0.0)) # False print(bool(None)) # False print(bool('')) # False print(bool("")) # False print(bool([])) # False 空列表 print(bool(list())) # False 空列表 print(bool(())) # 空元组 False print(bool(tuple())) # 空元组 False print(bool({})) # 空字典 False print(bool(dict())) # 空字典 False print(bool(set())) # 空集合 False
选择分支
# 选择结构 # 单分支 if # 多分支 if else money = 1000 # 余额 s = int(input('请输入取款金额')) # 判断余额是否充足 if s <= money: money -= s print('剩余余额', money) else: print('余额不足') # 多分支 if elif elif score = int(input('输入成绩')) if 90 <= score <= 100: print('A') elif 80 <= score <= 89: print('B') elif 70 <= score <= 79: print('C') elif 0 < score <= 69: print('D') else: print('输入有误')

条件表达式
# 条件表达式 # 判断两个数的大小 num1 = int(input('请输入第一个数')) num2 = int(input('请输入第二个数')) # 格式 True if 判断 else False print('最大的数为', num1 if num1 > num2 else num2)
3.9 pass语句
# pass语句 什么都不做,只是一个占位符,用到需要写语句的地方 # 占一个语句的位置 不会报错 适用于没有想好怎么写语句 answer = int(input('您是会员吗?y/n')) # 判断是不是会员 if answer == 'y': pass else: pass
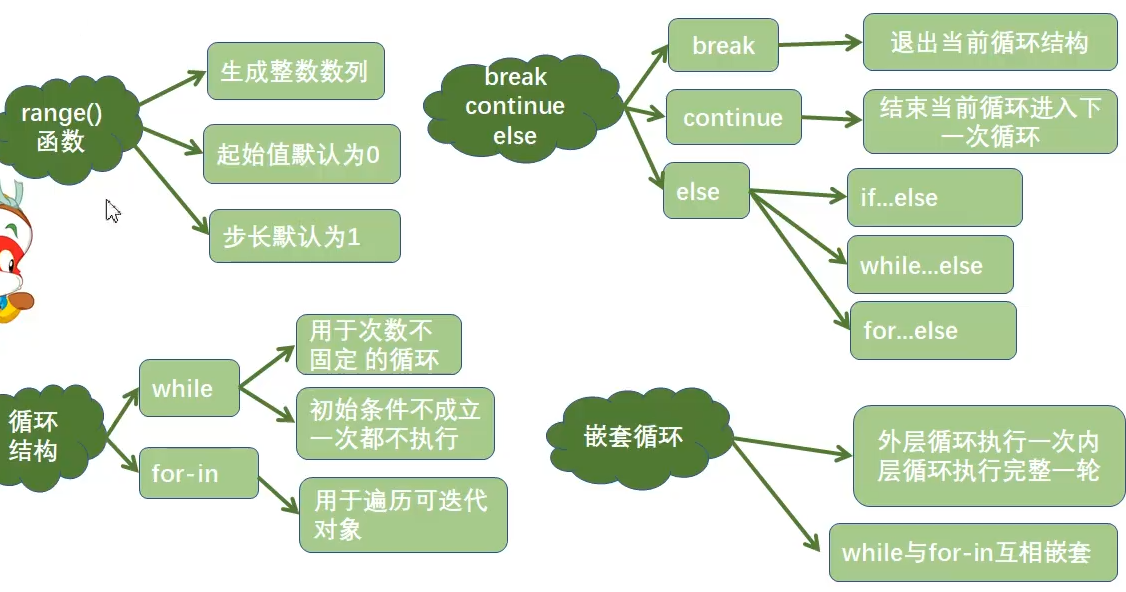
3.11 range()函数
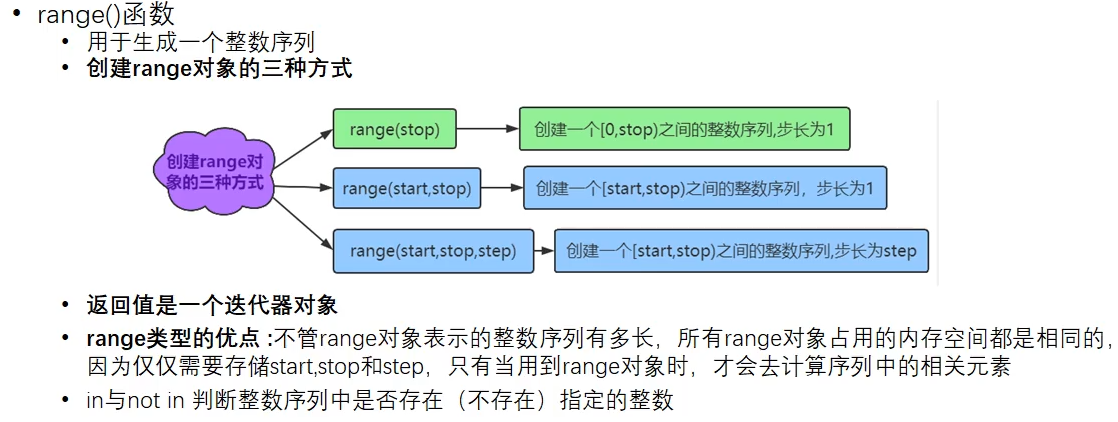
# range()的三种创建方式 # 第一种 r = range(10) # 默认从0开始 默认步长为1 print(r) # range(0, 10) print(list(r)) # 用于查看range对象中的整数序列 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 第二种 (start,stop) r = range(1, 10) # 指定从1开始10结束不包含10 print(list(r)) # [1, 2, 3, 4, 5, 6, 7, 8, 9] # 第三种 (start,stop,step) r = range(1, 10, 2) # 从1开始 到10结束不包含10 步长为2 print(list(r)) # [1, 3, 5, 7, 9] # 判断指定整数是否在序列r中存在 使用in 或者 not in print(10 in r) # False print(9 in r) # True print(10 not in r) # True # 只有当使用到的时候才会创建 一般用于for循环
3.12 循环结构

while True: pass # 语句 pass pass
# 计算1到100的偶数和 i = 1 num = 0 while i <= 100: if not(i % 2): num += i i += 1 # 此处不能使用i++ python 不支持 i++这个语法 要想累加的话 就用 i += 1这样的语句来完成 print(num)
使用标志
# 标志 prompt = "\nTell me something, and I will repeat it back to you:" prompt += "\nEnter 'quit' to end the program. " active = True while active: message = input(prompt) if message == 'quit': active = False else: print(message)
for 循环
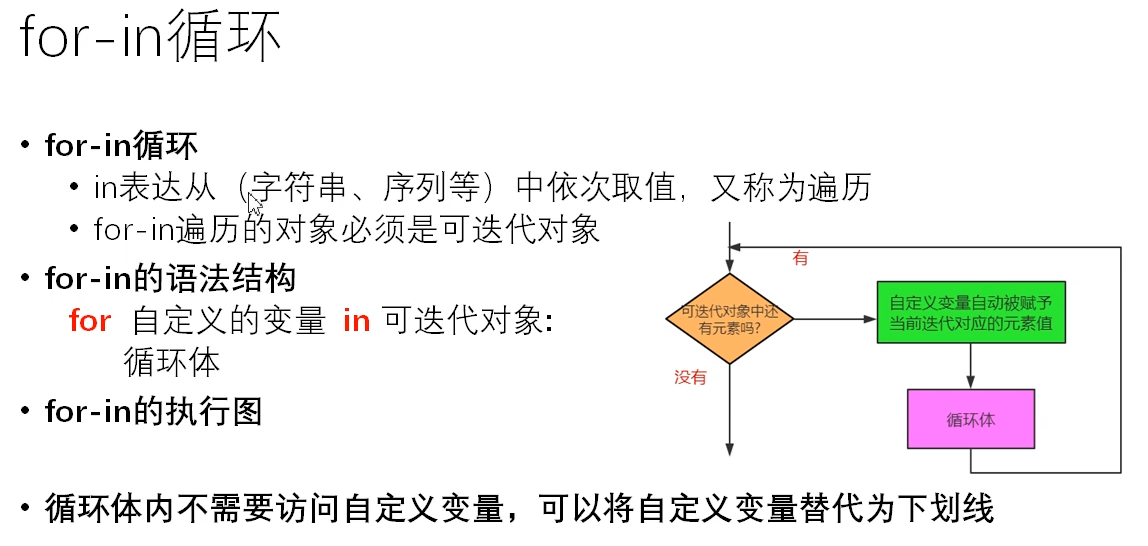
# for for item in 'python': print(item) # 一次把python中每一次字符赋给item 然后打印 # ranger() 产生一个整数序列 也可以是一个迭代对象 for i in range(10): print(i) # 0-9 执行10次 # 如果在循环中不需要使用自定义变量,可以用_代替 专注于循环次数 for _ in range(10): print('人生苦短') # 打印10次人生苦短 # 计算1-100的偶数和 for i in range(1, 101): if not(i % 2): num += i print(num)
判断水仙数
# 输出100到999之间的水仙花数 """ 水仙花数:153=3*3*3+5*5*5+1*1*1 """ for i in range(100, 1000): if int(i / 100)**3+int(i % 100 / 10)**3+(i % 100 % 10)**3 == i: print(i, '是水仙花数') # 个位 i%10 # 十位 i//10%10 # 百位 i//100
break 语句
# break语句 结束循环 # 从键盘输入密码 最多三次 输入正确就结束 # 初始密码为 888 for _ in range(3): pwd = int(input('输入密码')) if pwd == 888: print('输入正确') break else: print('输入有误')
continue
# 输出1-50所有5的倍数 for i in range(1, 51): if not(i % 5): print(i) # 输出不是5的倍数 for i in range(1, 51): if not(i % 5): continue print(i)
3.13 else 语句
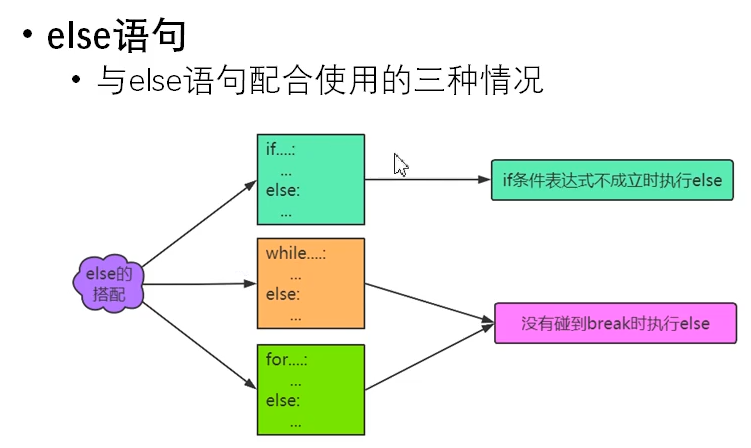
# else+for for _ in range(3): pwd = input("输入密码") if pwd == '666': print('密码正确') break else: print('密码错误') else: print("三次密码均输入错误") # else + while a = 0 while a < 3: pwd = input("输入密码") if pwd == '666': print('密码正确') break else: print('密码错误') a += 1 else: print("三次密码均输入错误")
3.14 嵌套循环
# 打印直角三角形5行 #* # ** # *** # **** # ***** for i in range(6): for j in range(i): print('*', end='') print()
# 打印乘法表 for i in range(1, 10): for j in range(1, i+1): print(i, '*', j, '=', i*j, '\t', end='') print()
4.1 列表

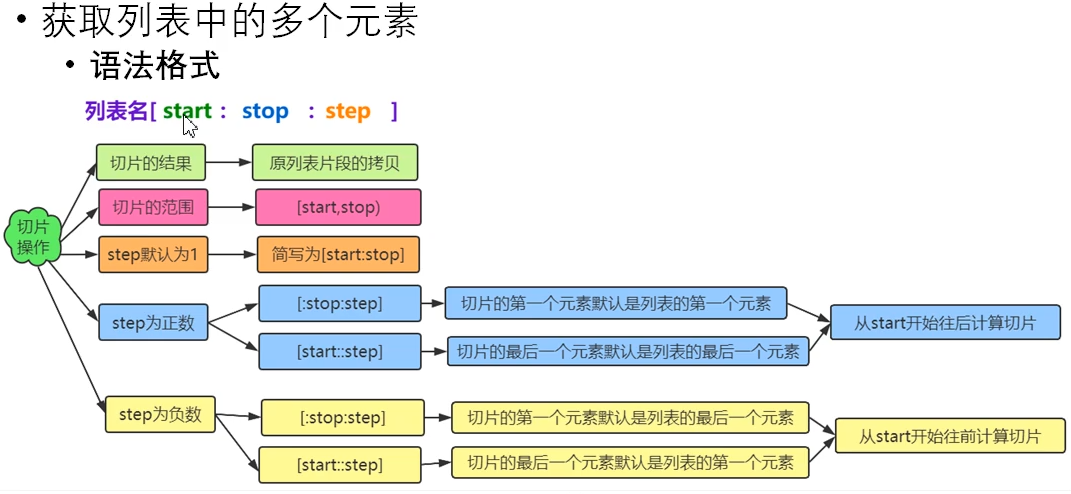
# 切片操作 lst = [10, 20, 30, 40, 80, 10, 5, 3] # start=1,stop=6,step=1 默认步长为1 print(lst[1:6:1]) # [20, 30, 40, 80, 10] 源列表的子集 新列表对象(通过拷贝源列表# ) print(lst[1:6:2]) # [20, 40, 10] print(lst[:6:2]) # [10, 30, 80] start默认为0 print(lst[1::1]) # [20, 30, 40, 80, 10, 5, 3] stop默认到最后 # 步长为负数 步长为负数类型逆序 print(lst[::-1]) # [3, 5, 10, 80, 40, 30, 20, 10] 逆序输出 print(lst[7::-1]) # [3, 5, 10, 80, 40, 30, 20, 10] print(lst[6:0:-2]) # [5, 80, 30] # 判断一个对象是否在列表中 print(10 in lst) # True print(10 not in lst) # False
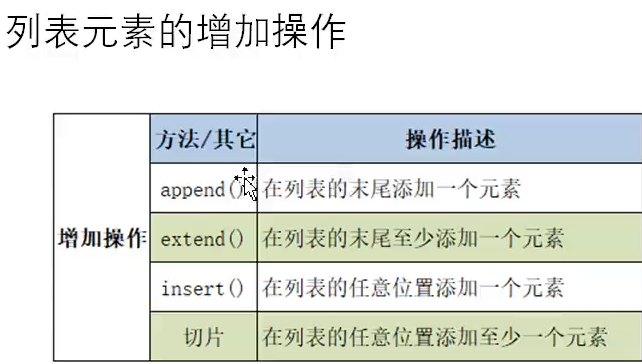
bicycles = ['trek', 'cannondale', 'redline', 'specialized'] # 。这种语法很有用,因为你经常需要在不知道列表长度的情况 # 下访问最后的元素。这种约定也适用于其他负数索引,例如,索引-2返回倒数第二个列表元素, # 索引-3返回倒数第三个列表元素,以此类推 print(bicycles[-1]) # specialized
# 遍历列表 for item in lst: print(item, end='') # 列表元素的增删改 # 向列表末尾增加一个元素 lst.append(100) # 还是在原来的列表中加入 id不会变 # 添加另一个列表 lst2 = ['hello', 'world'] lst.append(lst2) # 将lst2作为一个元素添加到列表尾部 print(lst) # [10, 20, 30, 40, 80, 10, 5, 3, 100, ['hello', 'world']] lst.extend(lst2) # 将列表的元素添加到另一个列表中 print(lst) # [10, 20, 30, 40, 80, 10, 5, 3, 100, 'hello', 'world'] # 在任意位置上添加元素 lst.insert(1, 90) # 在索引为1的位置添加90 print(lst) lst3 = [True, False, 'hello'] # 在任意位置上添加n多个元素 lst[1:] = lst3 # 索引为1后全覆盖 print(lst) # [10, True, False, 'hello']
Python中append和extend的区别

# 嵌套列表的append和extend number = ['1', '2', '3', '4', '5', '6', '7', '8'] str1 = [[], [], []] str1[1].extend(number) # [[], ['1', '2', '3', '4', '5', '6', '7', '8'], []] # str1[1].append(number) # [[], [['1', '2', '3', '4', '5', '6', '7', '8']], []] print(str1)
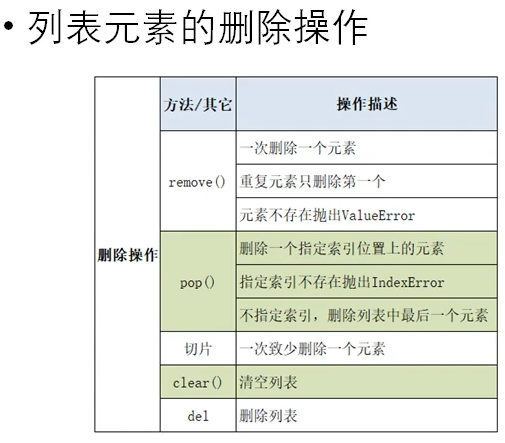
如果你要从列表 中删除一个元素,且不再以任何方式使用它,就使用del语句;如果你要在删除元素后还能继续 使用它,就使用方法pop()。
lst = [10, 20, 3, 45, 45, 41, 521] # 根据值删除元素 有时候,你不知道要从列表中删除的值所处的位置。如果你只知道要删除的元素的值,可使 用方法remove()。 lst.remove(20) # 如果有重复元素直移除第一个 print(lst) # [10, 3, 45, 45, 41, 521] # pop 根据索引移除元素 # 方法pop()可删除列表末尾的元素,并让你能够接着使用它。术语弹出(pop)源自这样的类 比:列表就像一个栈,而删除列表末尾的元素相当于弹出栈顶元素。 lst.pop(1) # 移除索引为1 print(lst) # [10, 45, 45, 41, 521] lst.pop() # 如果不指定参数 默认最后一个元素 print(lst) # [10, 45, 45, 41] # 切片删除 删除至少一个元素 ,将产生一个新的列表对象 new_list = lst[1:3] print('源列表', lst) print('切片后的列表', new_list) # 切片后的列表 [45, 45] # 不产生新的列表对象,而是删除原列表中的内容 lst[1:3] = [] # 只是用空列表进行覆盖 print(lst) # [10, 41] # 清空列表 lst.clear() print(lst) # [] # 删除列表 del lst
# del 删除必须知道索引 motorcycles = ['honda', 'yamaha', 'suzuki'] print(motorcycles) del motorcycles[1] print(motorcycles) # ['honda', 'suzuki']

lst = [10, 20, 30, 50] # 一次修改一个值 lst[2] = 100 # 改变 print(lst) # [10, 20, 100, 50] lst[1:3] = [300, 400, 500] # [10, 20, 100, 50] print(lst) # [10, 300, 400, 500, 50]
逆序输出
# 逆序 reverse() list1 = [1, 3, 2, 5, 4] list1.reverse() print(list1) # [4, 5, 2, 3, 1] # 法二 print(list1[::-1]) # [4, 5, 2, 3, 1]
永久性排序
# sort() 排序:升序降序 字母就是按照字母顺序 list1.sort() # 默认升序[1, 2, 3, 4, 5] 参数reverse=true 为降序 print(list1) list1.sort(reverse=True) print(list1) # [5, 4, 3, 2, 1] 降序
临时排序
# sorted()对列表进行临时排序 cars = ['bmw', 'audi', 'toyota', 'subaru'] print("Here is the original list:") print(cars) # ['bmw', 'audi', 'toyota', 'subaru'] print("\nHere is the sorted list:") print(sorted(cars)) # ['audi', 'bmw', 'subaru', 'toyota'] print("\nHere is the original list again:") print(cars) # ['bmw', 'audi', 'toyota', 'subaru']
列表反转
# 列表反转 cars = ['bmw', 'audi', 'toyota', 'subaru'] print(cars) cars.reverse() print(cars) # ['subaru', 'toyota', 'audi', 'bmw']
复制
# 列表复制 copy name_list = ['tom', 'Lily', 'Rose'] name_list2 = name_list.copy() print(name_list2) # ['tom', 'Lily', 'Rose']
列表的遍历
# 列表的遍历 name_list = ['tom', 'Lily', 'Rose'] # while i = 0 while i < len(name_list): print(name_list[i]) i += 1 # for 1 for i in name_list: print(i) # for 2 i = 0 for i in range(len(name_list)): print(name_list[i])
遍历部分列表
players = ['charles', 'martina', 'michael', 'florence', 'eli'] print("Here are the first three players on my team:") for player in players[:3]: print(player.title())
复制列表
# 复制列表 number = [0, 1, 5, 7, 8, 12, 2] number3 = number[:] print(number3) # [0, 1, 5, 7, 8, 12, 2] number.append(50) print(number3) # [0, 1, 5, 7, 8, 12, 2] # 此类复制列表 源列表一旦变化 复制后的列表也会变化 number2 = number # [0, 1, 5, 7, 8, 12, 2] print(number2) number.append(20) print(number2) # [0, 1, 5, 7, 8, 12, 2, 20]
分配办公室
# 综合运用 随机分办公室 三个办公室 8为老师 8位老师随机分配到3个办公室 teacher = ['tom', 'google', 'alex', 'sde', 'goad', 'colin', 'gila', 'pot'] classroom = [[], [], []] for i in teacher: classroom[random.randint(0, 2)].append(i) print(classroom) # [['alex'], ['google', 'sde', 'colin', 'pot'], ['tom', 'goad', 'gila']]
元组
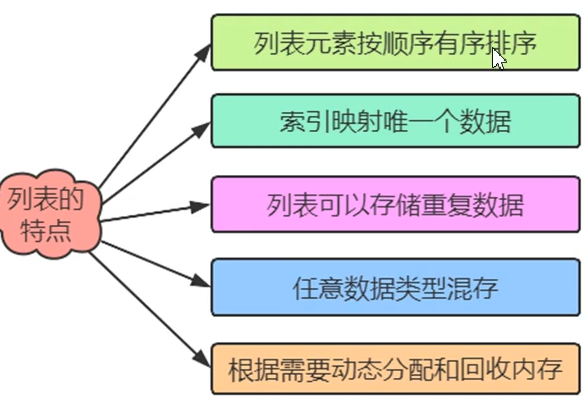
列表非常适合用于存储在程序运行期间可能变化的数据集。列表是可以修改的。
Python将不能修改的值称为不可变的,而不可变的列表被称为元组。
5 字典
# 字典 # 字典里的数据是以键值对形式出现和数据的顺序没有关系 # 无论后其数据如何变化,只要按照对应的键的名字查找数据 # 字典要求 1大括号 2键值对形式出现 3逗号隔开 # 创建有数据的字典 dict1 = {'name': 'Tom', 'age': 20, 'gander': '男'} print(dict1) # {'name': 'Tom', 'age': 20, 'gander': '男'} print(type(dict1)) # <class 'dict'> # 创建空字典 # 法一 dict2 = {} # 法二 dict3 = dict() print(type(dict3)) # <class 'dict'> # 字典常见操作 下标变为key值 # 新增id的值为110 dict1['id'] = 110 print(dict1) # {'name': 'Tom', 'age': 20, 'gander': '男', 'id': 110} # 再次覆盖已存在key的值就会覆盖原来的值 dict1['name'] = 'Rose' print(dict1) # {'name': 'Rose', 'age': 20, 'gander': '男', 'id': 110} # 删除数据 del() clear(): 清空字典 # del() del dict1['name'] # {'age': 20, 'gander': '男', 'id': 110} print(dict1) # clear() dict1.clear() print(dict1) # 修改数据 key存储可修改 不存在就新增 dict1['name'] = 'Lily' print(dict1) # {'age': 20, 'gander': '男', 'id': 110, 'name': 'Lily'} dict1['names'] = 's' print(dict1) # {'age': 20, 'gander': '男', 'id': 110, 'name': 'Lily', 'names': 's'} # 查找字典 # 法一 key值 print(dict1['name']) # Lily # 法二 get(key,默认值) key不存在则返回第二个参数(默认值),如果省略第二个参数,则返回None print(dict1.get('name')) # Lily print(dict1.get('id')) # None print(dict1.get('id', 110)) # 110 # 法三 keys() 返回可迭代对象 print(dict1) # {'name': 'Lily', 'names': 's'} print(dict1.keys()) # dict_keys(['name', 'names']) key值 for key in dict1.keys(): print(dict1[key]) # 法四 values() 返回可迭代对象 print(dict1.values()) # dict_values(['Lily', 's']) values值 for value in dict1.values(): print(value) # 法五 items() 返回可迭代对象 存储的是元组 元组数据1是字典里的key 元组数字据二是字典的值 print(dict1.items()) # dict_items([('name', 'Lily'), ('names', 's')]) for item in dict1.items(): print(item) # 遍历字典的键值对 元组数据1是字典里的key 元组数字据二是字典的值 for key, value in dict1.items(): # key value 可变其他词汇 print(f'{key}={value}') # name=Lily names=s
6 集合
# 创建集合 可变类型 # 1集合数据不允许重复 重复的数据只显示一次(去重) # 2并且没有顺序 # 3{}或set() 创建空集合只能用set() s1 = {10, 20, 20, 40, 50} print(s1) # {40, 10, 20, 50} s3 = set('abcdefg') # 集合没有顺序 print(s3) # {'c', 'd', 'f', 'g', 'a', 'e', 'b'} # 空集合 s4 = set() print(s4) # set() print(type(s4)) # <class 'set'> s5 = {} print(type(s5)) # <class 'dict'> # 增加单一数据 add() 如果已有则不会增加 有去重功能 s1.add(100) print(s1) # {100, 40, 10, 50, 20} s1.add(100) # {100, 40, 10, 50, 20} # 增加序列update() s1.update([50, 60]) print(s1) # {100, 40, 10, 50, 20, 60} # 集合删除数据 # remove 删除集合中的指定数据,如果属不存在会报错 s1.remove(100) print(s1) # {40, 10, 50, 20, 60} # s1.remove(100) # KeyError: 100 报错 # discard() 删除集合指定数据,数据不存在也不会报错 s1.discard(100) # {40, 10, 50, 20, 60} 不会报错 print(s1) # pop() 随机删除集合中某个数据,并返回这个数据 num = s1.pop() print(s1) # {10, 50, 20, 60} print(num) # 40 # 集合查找数据 in 和 not in print(50 in s1) # True print(50 not in s1) # False
7 公共操作
运算符公共操作
# 运算符 +合并 *复制 in元素是否存在 not in # 字符串 str1 = 'av' str2 = 'bdb' # 列表 list1 = [1, 2] list2 = [10, 20] # 元组 t1 = (1, 2) t2 = (10, 20) # 字典 dict1 = {'name': 'python'} dict2 = {'age': 30} # +: 合并 字典不支持合并 print(str1+str2) # avbdb print(list1+list2) # [1, 2, 10, 20] print(t1+t2) # (1, 2, 10, 20) # *:复制 字典不支持复制 print(str1 * 5) # aaaaaaaaaa # 打印5个-: print('-'*5) # ----- print(list1*5) # [1, 2, 1, 2, 1, 2, 1, 2, 1, 2] print(t1*5) # (1, 2, 1, 2, 1, 2, 1, 2, 1, 2) # in not in # 字符串 print('a' in str1) # True print('a' not in str1) # False # 列表 print(1 in list1) # True # 元组 print(1 in t1) # True # 字典 print('name' in dict1) # True print('name' in dict1.keys()) # True print('name' in dict1.values()) # False
公共方法
# 公共方法 # len 计算容器中元素的个数 print(len(str1)) # 2 print(len(list1)) # 2 print(len(t1)) # 2 print(len(dict1)) # 1 # max() 返回容器中元素最大值 print(max(list1)) # 2 print(max(str1)) # v # min() 返回容器中元素最小值 print(min(list1)) # 1 # range(start,end,step) 迭代 # range()的三种创建方式 # 第一种 r = range(10) # 默认从0开始 默认步长为1 print(r) # range(0, 10) print(list(r)) # 用于查看range对象中的整数序列 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 第二种 (start,stop) r = range(1, 10) # 指定从1开始10结束不包含10 print(list(r)) # [1, 2, 3, 4, 5, 6, 7, 8, 9] # 第三种 (start,stop,step) r = range(1, 10, 2) # 从1开始 到10结束不包含10 步长为2 print(list(r)) # [1, 3, 5, 7, 9] # 判断指定整数是否在序列r中存在 使用in 或者 not in print(10 in r) # False print(9 in r) # True print(10 not in r) # True # 只有当使用到的时候才会创建 一般用于for循环 # enumerate 将一个可遍历的数据对象组合为一个索引序列, # 同时列出数据和数据下标 一般用在for循环中 # enumerate(可遍历对象,start=0) start参数用来设置遍历数据的下标的起始值,默认为0 list3 = ['a', 'b', 'c', 'f', 'l'] for i in enumerate(list3): print(i) # (0, 'a') (1, 'b') (2, 'c') (3, 'f') (4, 'l') (小标,数据) for i in enumerate(list3, start=1): print(i) # (1, 'a')(2, 'b')(3, 'c')(4, 'f')(5, 'l') # del或del() 删除 del str1 # print(str1) # NameError: name 'str1' is not defined del list1[0] print(list1) # [2] del t1 del dict1['name'] print(dict1) # {}
容器类型转换
# 容器类型转换 # tuple() 将某个序列转换为元组 print(type(tuple(list1))) # <class 'tuple'> # list() 将某个序列转换为列表 print(type(list(t2))) # <class 'list'> # set() 将某个序列转换为集合 print(type(set(list1))) # <class 'set'> 集合带有去重功能 原来的数据会被去重 print(type(set(t2))) # <class 'set'>
8 推导式
# 推导式 列表 字典 集合
# 化简代码
列表推导式
# 列表推导式 # 用一个表达式创建一个有规律的列表或控制一个有规律列表 # 创建一个0-10的列表 # while实现 list1 = [] i = 0 while i<10: list1.append(i) i += 1 print(list1) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # for实现 list2 = [] for i in range(10): list2.append(i) print(list2) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] # 列表推导式实现 list3 = [i for i in range(10)] # 第一个i为循环返回值 print(list3) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
带if的推导式
# 带if的列表推导式 # 创建0-10的偶数列表 # 法一 range list4 = [i for i in range(0,10,2)] print(list4) # [0, 2, 4, 6, 8] # 法二 list5 = [i for i in range(10) if i % 2 == 0] print(list5) # [0, 2, 4, 6, 8]
带多个if的推导式
# 多个for循环实现推导式 # 建立[(1,0),(1,1),(1,2),(2,0),(2,1),(2,2)] list6 = [(i, j) for i in range(1, 3) for j in range(3)] print(list6) # [(1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]
字典推导式
# 字典推导式 # 快速合并列表为字典 或提取字典中的目标数据 # 创建key1-5,value是这个数的2次方 dict1 = {i: i**2 for i in range(1, 6)} print(dict1) # {1: 1, 2: 4, 3: 9, 4: 16, 5: 25} # 将两个列表合并为一个字典 list7 = ['name', 'age', 'gender'] list6 = ['tom', '20', 'man'] dict2 = {list7[i]: list6[i] for i in range(len(list6))} print(dict2) # {'name': 'tom', 'age': '20', 'gender': 'man'} # 提取字典的目标数据 counts = {'MBP': 28, 'HP': 250, 'DELL': 201, 'Lenovo': 199} # 提取电脑数量大于等于200的字典数据 print({key: value for key, value in counts.items() if value >= 200}) # {'HP': 250, 'DELL':
集合推导式
# 集合推导式 # 创建一个数据为下方列表的2次方 list8 = [1, 1, 2] set1 = {i ** 2 for i in list8} print(set1) # {1, 4} 集合有去重功能
9 函数
# 定义函数 先定义再调用 # 函数执行过程 当调用函数时,会执行函数内容 定义时不会执行函数 只会定义 def sel_func(): print('hello world') sel_func()
加法
# 完成加法运算 def add(a, b): print(a + b) def add2(a, b): return a + b # 调用函数 add(4, 6) # 10 print(add2(6, 5)) # 11
函数说明文档
# 函数说明文档 快速查看函数的作用 # help(len) help 查看函数的说明文档 # 位置 定义后第一行"""""" def sum(a, b): """求和函数""" return a + b help(sum) # 求和函数 print(sum(1, 5)) # 6 # 说明文档高级使用 “”“回车 def sum_num(a, b): """ 求和函数 :param a: 参数1 :param b: 参数2 :return: 返回值 """ return a + b
函数嵌套
# 函数嵌套调用 def multiply(a, b): return a * b def multiplyAdd(a, b): return multiply(a, b) + b print(multiplyAdd(4, 6)) # 30 # 打印一条横线 def line(): return '-' * 20 # 打印多条 for _ in range(4): print(line()) # 求两个数的平均值 def average(a, b): print(sum(a, b) / 3) average(4, 6) # 3.3333333333333335
修改全局变量
# 修改全局变量 global 关键字 a = 100 def testA(): print(a) def testB(): global a a = 200 print(a) testA() # 100 testB() # 200 此时a是局部变量 print(a) # 100 global 后为200 # 返回值作为参数传递 def one(): return 50 def two(num): print(num) two(one()) # 50 # 多个返回值 def return_num(): return 1, 2 # 返回的是一个元组 # return 后面可以返回 元组 列表 字典 print(return_num()) # (1, 2)
函数参数
# 函数参数 # 位置参数 def user_info(name, age, gender): print(f'名字为{name},年龄{age},性别{gender}') user_info('tom', 20, '男') # 名字为tom,年龄20,性别男 # 关键字参数 通过键=值的形式加以指定 指定参数名 就可以不按顺序写参数 def user_info2(name, age, gender): print(f'名字为{name},年龄{age},性别{gender}') user_info2('tom', age=20, gender='男') # 名字为tom,年龄20,性别男 user_info2('小明', gender='男', age=16) # 名字为小明,年龄16,性别男 # 缺省参数 默认参数 def user_info3(name, age, gender='女'): print(f'名字为{name},年龄{age},性别{gender}') user_info3('tom', 20) # 名字为tom,年龄20,性别女 # 不定长参数 可变参数 组包过程 # 包裹位置 def user_info4(*args): # args是元组类型 print(args) user_info4('Tom') # ('Tom',) user_info4('Tom', '18') # ('Tom', '18') # 包裹关键字 def user_info5(**kwargs): # kwargs是一个字典 print(kwargs) user_info5(name='Tom', age=18, id=110) # {'name': 'Tom', 'age': 18, 'id': 110}
让实参变成可选的
# 让参数变成可选 def get_formatted_name(first_name, last_name, middle_name=''): """返回整洁的姓名""" if middle_name: full_name = first_name + ' ' + middle_name + ' ' + last_name else: full_name = first_name + ' ' + last_name return full_name.title() musician = get_formatted_name('jimi', 'hendrix') print(musician) musician = get_formatted_name('john', 'hooker', 'lee') print(musician)
导入模块
def make_pizza(size, *toppings): # pizza.py 文件中
"""概述要制作的比萨"""
print("\nMaking a " + str(size) +
"-inch pizza with the following toppings:")
for topping in toppings:
print("- " + topping)
making_pizzas.py 文件中导入make_pizza模块
import pizza
pizza.make_pizza(16, 'pepperoni')
pizza.make_pizza(12, 'mushrooms', 'green peppers', 'extra cheese')
导入特定的函数
# 你还可以导入模块中的特定函数,这种导入方法的语法如下: from module_name import function_name # 通过用逗号分隔函数名,可根据需要从模块中导入任意数量的函数: from module_name import function_0, function_1, function_2 # 对于前面的making_pizzas.py示例,如果只想导入要使用的函数,代码将类似于下面这样: from pizza import make_pizza make_pizza(16, 'pepperoni') make_pizza(12, 'mushrooms', 'green peppers', 'extra cheese')
# 使用as给模块指定别名 import pizza as p p.make_pizza(16, 'pepperoni') p.make_pizza(12, 'mushrooms', 'green peppers', 'extra cheese') # 导入模块所以函数 from pizza import * make_pizza(16, 'pepperoni') make_pizza(12, 'mushrooms', 'green peppers', 'extra cheese')
拆包
# 拆包 # 元组 def return_num(): return 100, 200 num1, num2 = return_num() print(num1) # 100 print(num2) # 200 print(return_num()) # (100, 200) # 字典 dict1 = {'name': 'Tom', 'age': 18} a, b = dict1 # 对字典进行拆包,取出来的是字典的key print(a) # name print(b) # age print(dict1[a]) # Tom print(dict1[b]) # 18
交换变量的值
# 交换变量的值 a = 10 b = 20 # 常规 使用中间变量 c = 0 c = a a = b # 简便 a, b = 10, 20 a, b = b, a print(f'a={a},b={b}') # a=20,b=10
引用
# 引用 python中值都是靠引用来传递的 # 使用id() 来判断一个变量是否为同一个值的引用 # int a = 1 b = a print(b) # 1 print(id(a)) # 140703583966880 print(id(b)) # 140703583966880 # 修改a的值 a = 2 print(id(a)) # 140703583966912 print(id(b)) # 140703583966880 # 列表 aa = [10, 20] bb = aa # 数据传递时永远指向同一个id print(id(aa)) # 2829476104832 print(id(bb)) # 2829476104832 aa.append(30) print(bb) # [10, 20, 30] print(id(aa)) # 2829476104832 print(id(bb)) # 2829476104832
引用当实参
# 引用当实参传递 def test1(a): print(a) print(id(a)) a += a print(a) print(id(a)) # int: 计算前面id值不同 b = 100 test1(b) # 不可变类型 id 不一样 # 列表: 计算前后id相同 c = [11, 22] test1(c) # 可变类型 id 一样
可变类型和不可变类型
# 可变类型 不可变类型 # 可变 列表 字典 集合 # 不可变 整形 浮点型 字符串 元组
10 简易学员管理系统
# 函数加强 # 学院管理系统 info = [] # 添加学员 def add_student(): print("请输入该学员的信息") name = input("学员的姓名") age = input("学员的年龄") gender = input("学员的性别") student = {'name': name, 'age': age, 'gender': gender} info.append(student) print(info) # 删除学员 def delete_student(name): for item in info: if name == item['name']: info.remove(item) print(info) # 修改学员信息 def modify_student(name): for item in info: if name == item['name']: print(f'原始学员信息{item}') age = input("请输入修改后的年龄") gender = input("请输入修改后的性别") item['age'] == age item['gender'] = gender print(info) # 查询所以学员信息 def find_all(): print(info) # 显示界面 print("欢迎来到管理界面") while True: print("a: 添加学员") print("d: 删除学员") print("m: 修改学员") print("f: 查找所以学员") print("q: 推出系统") flag = input("请输入您要执行的操作") if flag == 'a': add_student() elif flag == 'd': name = input("请输入姓名") delete_student(name) elif flag == 'm': name = input("请输入姓名") modify_student(name) elif flag == 'f': find_all() elif flag == 'q': exit() else: print("输入有误,请重新输入")
11 lambda 表达式
# lambda 表达式 化简代码 形式:lambda 参数列表 : 表达式 # 一个函数只有一个返回值,并且只有一句代码,可以采用lambda # 参数可有可无 能接收任何数量的参数但是只能返回一个表达式的值 def fn1(): return 100 print(fn1) # <function fn1 at 0x0000018E8AEE6430> print(fn1()) # 100 # lambda fn2 = lambda: 100 print(fn2) # 内存地址 <function <lambda> at 0x000001939C7693A0> print(fn2()) # 100 # 计算a+b def add(a, b): return a + b print(add(1, 3)) # 4 # lambda add2 = lambda a, b: a + b print(add2(1, 3)) # 4 # 参数形式 # 无参数 fn2 = lambda: 100 print(fn2()) # 一个参数 fn3 = lambda a: a print(fn3('hello')) # hello # 默认参数 fn4 = lambda a, b, c=100: a + b + c print(fn4(10, 20)) # 130 # 可变参数 *args fn5 = lambda *args: args # 返回元组 print(fn5(10, 20, 50, 60)) # (10, 20, 50, 60) # 可变参数 **kwargs fn6 = lambda **kwargs: kwargs # 返回字典 print(fn6(name='python', age=20)) # {'name': 'python', 'age': 20} # lambda应用 # 带判断的lambda fn7 = lambda a, b: a if a > b else b print(fn7(100, 500)) # 500 # 列表数据按字典key的值排序 students = [ {'name': 'tom', 'age': 50}, {'name': 'Rose', 'age': 10}, {'name': 'Jack', 'age': 2} ] # 按name值升序排列 students.sort(key=lambda x: x['name']) print(students) # 按name值降序排列 students.sort(key=lambda x: x['name'], reverse=True) print(students)
12 高阶函数
import functools # 高阶函数 函数作为参数传入 # 内置函数 # abs() 绝对值 print(abs(-60)) # 60 # round() 绝对值 print(round(1.4)) # 1 # 需求:任意两个数字,按照指定要求整理数字后再进行求和计算 def add_abs(a, b): return abs(a) + abs(b) # 更加灵活 f 接收函数 def sum_num(a, b, f): return f(a) + f(b) print(add_abs(-10, 90)) # 100 print(sum_num(-10, -60, abs)) # 70 # 内置高阶函数 # map(func,lst) 将传入的函数变量func作用到lst变量中的每个元素中并将结果组成新的列表 # 计算list1序列中各个数字的2次方 list1 = [1, 2, 3, 4, 5] def func(x): return x ** 2 print(list(map(func, list1))) # [1, 4, 9, 16, 25] # reduce(func,lst),其中func必须有两个参数。每次func计算的结果继续和序列下一个元素做累加计算 # 计算list1序列中各个数字的累加积 需要用到functools def func2(a, b): return a + b result = functools.reduce(func2, list1) print(result) # 15 # filter(func, lst) # 用于过滤序列,过滤掉不符合条件的元素,返回一个filter对象。 # 如果要转换列表可以使用lst()来转换 lst = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] def fun(x): return x % 2 == 0 print(filter(fun, lst)) # <filter object at 0x000001FFFBE6B610> print(list(filter(fun, lst))) # [2, 4, 6, 8, 10]
13 类
创建类
# 首字母大写的名称指的是类,这个类定义中的括号是空的,因为我们要从空白创建这个类 class Dog(): """一次模拟小狗的简单尝试""" # 法__init__()是一个特殊的方法,每当你根据Dog类创建新实 # 例时,Python都会自动运行它 def __init__(self, name, age): """初始化属性name和age""" self.name = name self.age = age def sit(self): """模拟小狗被命令时蹲下""" print(self.name.title() + " is now sitting.") def roll_over(self): """模拟小狗被命令时打滚""" print(self.name.title() + " rolled over!") # 实例化 my_dog = Dog('willie', 6) print("My dog's name is " + my_dog.name.title() + ".") print("My dog is " + str(my_dog.age) + " years old.")
类的静态变量
class foo():
member1
member2
...
self.member1
foo.member2
其中的两个成员member1, member2有什么区别。。。这才知道python中也有自己的全局静态变量。
其实例的属性是实例的,如上class中的member1,对它进行+/-操作时,只会对一个相应对象实例产生影响,(其类和该类的其它实例的不受影响)。
如果类的属性是 mutable 对象的话,对此对象*本身*的修改会反映到其他所有实例。python 中定义的静态成员变量,就是类的变量, 只能通过 类.变量名的形式获取
可以用来查看此类实例了多少个实体
使用类
class Car(): """一次模拟汽车的简单尝试""" def __init__(self, make, model, year): """初始化描述汽车的属性""" self.make = make self.model = model self.year = year # 设置初始值 self.odometer_reading = 0 def get_descriptive_name(self): """返回整洁的描述性信息""" long_name = str(self.year) + ' ' + self.make + ' ' + self.model return long_name.title() def read_odometer(self): """打印汽车里程""" print('里程为'+str(self.odometer_reading)) def update_odometer(self,mileage): """方法里修改属性""" self.odometer_reading = mileage def increment_odometer(self,miles): """自增""" self.odometer_reading += miles my_new_car = Car('audi', 'a4', 2016) print(my_new_car.get_descriptive_name()) # 直接修改属性 my_new_car.odometer_reading = 30 my_new_car.read_odometer() # 里程为30 # 方法里修改属性 my_new_car.update_odometer(50) my_new_car.read_odometer() # 里程为50
继承
class Car(): """一次模拟汽车的简单尝试""" def __init__(self, make, model, year): """初始化描述汽车的属性""" self.make = make self.model = model self.year = year # 设置初始值 self.odometer_reading = 0 def get_descriptive_name(self): """返回整洁的描述性信息""" long_name = str(self.year) + ' ' + self.make + ' ' + self.model return long_name.title() def read_odometer(self): """打印汽车里程""" print('里程为' + str(self.odometer_reading)) def update_odometer(self, mileage): """方法里修改属性""" self.odometer_reading = mileage def increment_odometer(self, miles): """自增""" self.odometer_reading += miles def fill_gas_tank(self): print('油箱') my_new_car = Car('audi', 'a4', 2016) print(my_new_car.get_descriptive_name()) # 直接修改属性 my_new_car.odometer_reading = 30 my_new_car.read_odometer() # 里程为30 # 方法里修改属性 my_new_car.update_odometer(50) my_new_car.read_odometer() # 里程为50 # 创建子类的实例时,Python首先需要完成的任务是给父类的所有属性赋值。为此,子类的方 # 法__init__()需要父类施以援手 class ElectricCar(Car): """电动汽车的独特之处""" def __init__(self, make, model, year): """初始化父类的属性""" super().__init__(make, model, year) # 独有属性 self.battery_size = 70 def describe_battery(self): """独有方法""" print('电池量'+str(self.battery_size)) def fill_gas_tank(self): """重写父类方法""" print('电动车没有油箱') my_tesla = ElectricCar('tesla', 'model s', 2016) print(my_tesla.get_descriptive_name()) # 将实例可用作属性
导入类
# 要建立python package 而且 路径是根路径 # Restaurant类在此目录下 import 可以加多个类 * 表示所以 from pythonintomaster.nine.restaurant import Restaurant class IceCreamStand(Restaurant): def __init__(self, restaurant_name, cuisine_type, flavors, number_served=0): super().__init__(restaurant_name, cuisine_type, number_served) self.flavors = flavors def show_flavors(self): print(self.flavors) my_restaurant = IceCreamStand('ll', '川菜', '冰淇淋', 60) print(my_restaurant.flavors)
14 文件
文件操作
# 文件操作 # 打开文件 或者创建一个新文件 # open(file_name,mode) mode:只读r ,只写入w,追加 a f = open('test.txt', 'w') # 读写操作 write() read() f.write('aaa') # 关闭文件 f.close()
读取文件
# open 打开文件 返回文件对象 # 关键字with在不再需要访问文件后将其关闭 你也可以调用open()和close()来打开和关闭文件 with open('pi_digits.txt') as file_object: contents = file_object.read() # 该输出唯一不同的地方是末尾多了一个空行。为何会多出这个空行呢?因 # 为read()到达文件末尾时返回一个空字符串 print(contents.rstrip()) # 逐行读取 # 要以每次一行的方式检查文件,可对文件对象使用for循环 filename = 'pi_digits.txt' with open(filename) as file_object: # 每行的末尾都有一个看不见的换行符,而 # print语句也会加上一个换行符,因此每行末尾都有两个换行符 for line in file_object: print(line.rstrip()) # 创建一个包含文件各行内容的列表 # readlines读出每行放入到列表中 赋给lines 可以在with之外打印列表内容 filename = 'pi_digits.txt' with open(filename) as file_object: lines = file_object.readlines() for line in lines: print(line.rstrip()) # 若需要去掉两边的空白 采用strip
文件模式
# 文件模式 # 只读r 文件不存在读不了 文件指针将会放到文件的开头 f1 = open('test.txt', 'r') print(f1.read()) # aaa # 追加a 如果原文件不 # 访问模式省略时 文件不存在 不会新建 ,不能写只能读 f1 = open('test.txt') print(f1.read()) f1.close() # 读操作 # read(num) num表示从文件中读取数据的长度 不写参数就是所有数据 f2 = open('test.txt', 'r') print(f2.read(1)) # a 先读取了1个字节 在读取就从此从此操作之后的字节 print(f2.read()) # aa f2.close() # readlines() # 可以按照行的方式把整个文件中的内容进行一次性读取 # 并返回一个列表,其中每一行都数据为一个元素 f3 = open('test1.txt') print(f3.readlines()) # ['i love china\n', 'i really love china\n'] f3.close() # readline() 一次读取一行内容 f4 = open('test1.txt') print(f4.readline()) # i love china print(f4.readline()) # i really love china f4.close()
filename = 'programming.txt' # 读取模式('r')、写入模式('w')、 # 附加模式('a')或让你能够读取和写入文件的模式('r+') with open(filename, 'w') as file_object: file_object.write("I love programming.") # 函数write()不会在你写入的文本末尾添加换行符,因此如果你写入多行时指定换行符 with open(filename, 'w') as file_object: file_object.write("I love programming.\n") file_object.write("I love creating new games.\n")
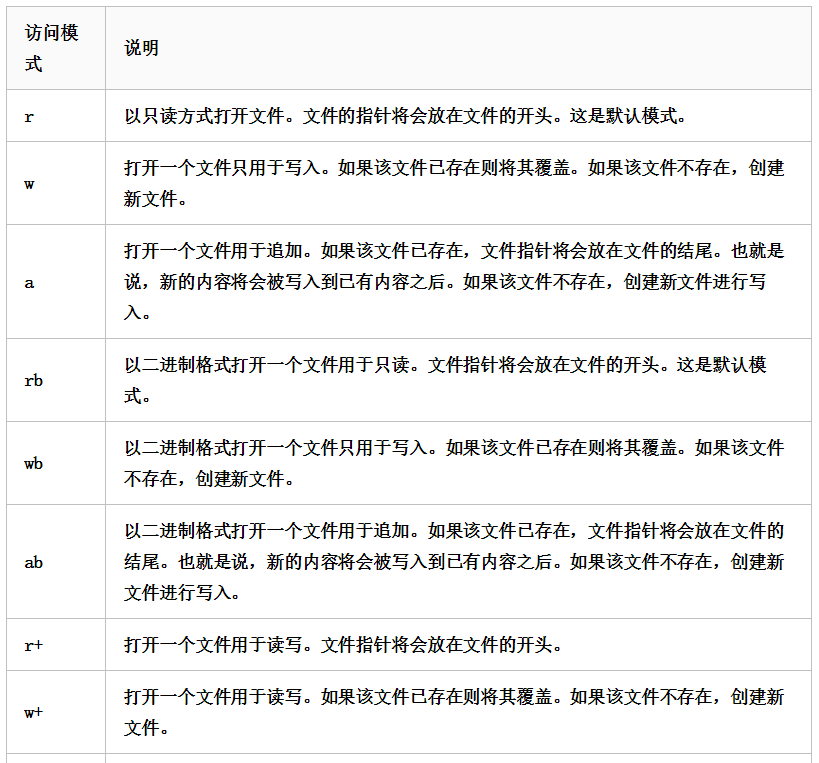

访问模式特点
# 访问模式的特点 # 模式带b的都是以二进制文件操作 # 带+的都是可读可写的 # 带r带w的文件指针都在开头位置 # 带a的文件指针都在结尾 # seek函数 移动文件指针 # 文件对象.seek(偏移量,起始位置) # 0:文件开头 1:当前位置 2:文件结尾
简单操作
# 简单操作 # r 改变指针位置 改变读取数据开始位置或把文件指针放到末尾(无法读取数据) f5 = open('test1.txt') f5.seek(10, 0) print(f5.read()) # na i really love china i exceedingly love china f5.seek(0, 2) print(f5.read()) f5.close() # a 改变文件指针位置,做到可以读取出来数据 f6 = open('test1.txt', 'a+') f6.seek(10, 0) print(f6.read()) # na i really love china i exceedingly love china f6.close()
文件备份
# 文件备份 # 需求:用户输入当前目录下任意文件名,程序完成对该文件的备份功能 # (备份文件名为xx[备份]后缀) 例如:test[备份].txt # me file_name = input('请输入您需要备份的文件名') old_file = open(file_name, 'r') new_file = open(f'{file_name}[备份].txt', 'w') new_file.write(old_file.read()) old_file.close() new_file.close() # teacher # 1 接收用户输入目标文件名 old_name = input('请输入您要备份的文件名:') # 2 规划备份文件名 # 获取文件后缀点的下标 index = old_name.rfind('.') if index > 0: # 不允许文件名为.txt postfix = old_name[index:] new_name = old_name[:index] + '[备份]' + postfix # 3 备份文件写入数据 old_f = open(old_name, 'rb') new_f = open(new_name, 'wb') # 将源数据写入备份文件 # 如果不确定目标文件大小,循环读取,当读取的数据没有了,就终止循环 while True: con = old_f.read(1024) if len(con) == 0: break new_f.write(con) old_f.close() new_f.close()
文件 和文件夹操作
import os # 文件和文件夹操作 # 需要导入os模块 import os 使用os.函数名() # 文件重命名 os.rename(目标文件,新文件名) os.rename('test.txt', 'text.txt') # 删除文件 os.remove(目标文件) os.remove('text.txt') # 创建文件夹 os.mkdir('file') # 文件夹重命名 os.rename('aa', 'bbbb') # 删除文件夹 os.rmdir('file') # 获取当前目录 print(os.getcwd()) # D:\python\python\pythonProject\file # 改变默认目录 os.mkdir('aa') os.chdir('aa') os.mkdir('bb') # 获取目录列表 获取某个文件夹所以文件 返回一个列表 print(os.listdir()) # ['aa', 'file', 'file.py', 'file2.py', 'test1.txt', 'test1.txt[备份].txt', 'text.txt'] print(os.listdir('aa')) # ['bb']
应用
import os # 需求:批量修改文件名,既可以添加指定字符串,又能删除指定字符串 # 当前文件重命名为python_xxxx file = os.listdir() print(file) for item in file: new_item = 'python_' + item os.rename(item, new_item)
异常
# 处理 ZeroDivisionError 异常 try: print(5 / 0) except ZeroDivisionError: print("You can't divide by zero!") # 包含一个else代码块;依赖于try代码块成功执行的代码都应放到else代码块中 print("Give me two numbers, and I'll divide them.") print("Enter 'q' to quit.") while True: first_number = input("\nFirst number: ") if first_number == 'q': break second_number = input("Second number: ") try: answer = int(first_number) / int(second_number) except ZeroDivisionError: print("You can't divide by 0!") else: print(answer) # 处理 FileNotFoundError 异常 filename = 'alice.txt' try: with open(filename) as f_obj: contents = f_obj.read() except FileNotFoundError: msg = "Sorry, the file " + filename + " does not exist." print(msg) else: # 处理如果文件存在之后的操作 pass # 当候你希望程序在发生异常时一声不吭,就像什么都没有发生一样继续运行 try: # 你的操作 pass except EOFError: # 此时出现异常不吭声 pass else: # 之后操作 pass
json格式
# 模块json让你能够将简单的Python数据结构转储到文件中 # ,并在程序再次运行时加载该文件中的数据,你还可以使用json在Python程序之间分享数据 # JSON数据格式并非Python专用的, # 这让你能够将以JSON格式存储的数据与使用其他编程语言的人分享。 import json # 写入json格式 json.dump numbers = [2, 3, 5, 7, 11, 13] filename = 'numbers.json' with open(filename, 'w') as f_obj: # 函数json.dump()接受两个实参:要存储的数据以及可用于存储数据的文件对象 json.dump(numbers, f_obj) # 读取json格式json.load filename = 'numbers.json' with open(filename) as f_obj: numbers = json.load(f_obj) print(numbers)
测试
方法
# 测试需要导入unittest import unittest # # 导入需要测试的方法 from pythonintomaster.ten.name_function import get_formatted_name class NamesTestCase(unittest.TestCase): """测试name_function.py""" def test_first_last_name(self): """能够正确地处理像Janis Joplin这样的姓名吗?""" formatted_name = get_formatted_name('janis', 'joplin') # 断言方法用来核实得到的结果是否与期望的结果一致。 self.assertEqual(formatted_name, 'Janis Joplin') unittest.main()
测试类

setup()方法
# 法setUp(),让我们只需创建这些对象一 次,并在每个测试方法中使用它们 import unittest from pythonintomaster.eleven.survey import AnonymousSurvey class TestAnonymousSurvey(unittest.TestCase): """针对AnonymousSurvey类的测试""" def setUp(self): """ 创建一个调查对象和一组答案,供使用的测试方法使用 """ question = "What language did you first learn to speak?" self.my_survey = AnonymousSurvey(question) self.responses = ['English', 'Spanish', 'Mandarin'] def test_store_single_response(self): """测试单个答案会被妥善地存储""" self.my_survey.store_response(self.responses[0]) self.assertIn(self.responses[0], self.my_survey.responses) def test_store_three_responses(self): """测试三个答案会被妥善地存储""" for response in self.responses: self.my_survey.store_response(response) for response in self.responses: self.assertIn(response, self.my_survey.responses) unittest.main()
global 关键字 全局变量
# python global 全局变量 x = 5 def fun_a(): print(x) def fun_b(): x = x+1 print(x) fun_a() fun_b() # 报错,

x = 5 def fun_a(): print(x) def fun_b(): global x # global x = x+1 print(x) fun_a() # 5 fun_b() # 6

 浙公网安备 33010602011771号
浙公网安备 33010602011771号