软工实践寒假作业(2/2)
寒假作业(2/2)
| 这个作业属于哪个课程 | 软件工程2021春软件工程W班(FZU) |
|---|---|
| 作业目标 | 1.阅读《构建之法》并提问;2.完成词频统计个人作业 |
| 作业要求 | 作业链接 |
| 参考文献 | csdn,java教程 |
任务一:阅读《构建之法》并提问
代码量是否等于树叶量?
看了该篇文章后,我对于文章中对于代码量问题老师给出的只要是能够解决问题就是一个好的课题持疑惑态度,我认为一个好的即使简略的项目要实现的功能也是需要较大的代码量来维护的,文章中所给的老师所讲的一个故事,说一颗树的树叶比作代码量,有一棵树上长满果实,一棵树上是长满果实树树叶的三倍。我认为这是不太现实的。到开发阶段,我认为一个好的编程人员都会有意识的去减少自己做重复的事件,也就是说代码的复用等。对于文章所说长满树叶的树我认为只能在新手阶段能够看到。我认为能够进行开发软件,设计课设的阶段的人不会犯这样的问题。因此直接将树叶必做代码量,我认为较为笼统,应说为树叶是无效代码量我认为更加合适。
普通的团队开发要如何做到高效的代码复审?
在阅读了第三点团队合作的几篇文章后,我认为结对项目中,每一行代码都由两个人思考过,且双方都十分熟悉代码,所以不必过多的介绍就可以开始进行细致的复审。但是在多人团队合作中,往往每个人都是负责一个模块,在个人编程习惯不同下,代码形式或者风格可能也较为不同,对于复审者来说,是一件非常复杂的事,如果是通过问问题方式来做,可能并不能够了解代码细节,很难发现逻辑上的错误及优化的空间等等,如果让复审者去深入了解,又是不太现实的一件事情。往往在校园团队合作上,时间统一更是一件较为复杂的事情,对于代码的复审效率提高是一件让我困惑的事情,照目前我得想法是只能够弱化复审者的要求,让自身模块的编程人员也参与其中。才能做到较为高效率的代码复审,但是往往bug不易让自身找到,是一把双刃剑。
如何去让用户能有更好的体验?
阅读了用户体验和用户界面后该文章后,我对于如何去让用户能够有更好的体验感有了更进一步的认识,从开发者即我得角度来看,首先在开发一个功能时,我们需要提前去对于用户会如何使用进行一个规划,如通过调查等方式或者自身和队友来考虑等,让用户使用时候不会觉得这个功能略显"幼稚",其次就是在于对界面的ui设计,不要为了不无目的的美观而美观,往往过度美化会适得其反,可以在测试阶段先让人员进行使用,看看体验感如何,ui让人觉得美观舒服才是最重要的。最后就是对于功能的测试,测试要尽量完善,勿让用户体验时遇到一些bug是我们应该去努力的方向。
团队有部分人不做事时候,我们应该怎么调动人员情绪来做事?
在阅读了其实还是人的问题这篇文章后,我对于老师在对于人的分类时把人分成了{做事的, 不做事的,不让别人做事的,P4=做假的事的,P5=假装做事的}大有所悟。在团队分配时,不可必要的并不是每个人都是团队角色中的"猪",对于所有事都是百分百的去努力完成,对于这五种分类,我们应该让自身成为做事的人。并且在一个团队中,如果有人是其余分类的人,我们应该如何去让他向我们看齐呢,这是我在阅读了后所提出的问题,对于这个问题我认为我在自身的经历上来说,我得解答是让他跟我一起办事,以我的积极去带动他的积极,这样来让其成为第一类人。我也会在后续更加的去认识和体会这一方面的解决方案。
一个团队在创造阶段才能产生一些有意义的东西么?
在团队合作阶段文章中提到的创造阶段才能产生有意义的东西,这一点思路我觉得有一些异议。一个团队从建立起来开始,就是一个创造的过程。萌芽阶段成员互相认识,适应环境,承担角色以及日常流程等,磨合阶段成员们开展讨论与构思,创造出更多想象和扩展的空间。规范阶段则是完善代码,完善能力。前三个阶段所做的每一步其实都是创造的过程,也没有人能够否认这些阶段是没有意义的。所以不仅仅是创造阶段成员们所做出的东西是有意义的,任何时候任何阶段,成员们辛苦的付出和努力都是在创造有意义的东西,只不过创造阶段显现出来的东西更多。意义对于我而言我认为有过程就存在着意义,并非区分过程中的每个阶段来看待有无意义。
附加题:
(来源于对bug词义的意思起了兴趣,很早的时候所查的一个故事)
美国的艾肯博士研制出了马克2号计算机,在研制过程中,诞生了一个新词“debug”来表示排除计算机故障,他的出现是这样的:在盛夏的时候,美国水上研究中心使用马克-Ⅱ计算机进行数据处理时,经常停止工作,其原因是,由于天气炎热加上机房无空调设备,致使大量飞蛾在机房中乱飞,这些飞蛾飞到正要闭合的继电器触点之间被继电器触电夹住,导致电路中断,造成工作故障。只需要将飞蛾找出拿掉,就可以正常工作,因为飞蛾的英文是bug,所以也使得bug成为了代名词。
任务二:设计一个程序,能够满足一些词频统计的需求
项目地址
Github解题思路描述
原先想用python做,能够用到更加便捷的方法去使用,后面以为只能java/c++选择了java,因为书没带上网查了一些技术的教程网站进行了学习和复习来完成课题。后续将所有功能设计成了一个工具类来进行调用。
首先拿到题目的时候,审了下题,将题目分成了几个部分:
1.统计文件的字符数
2.统计文件的单词总数
3.统计文件的有效行数
4.统计文件中各单词的出现次数
5.文件存取
代码规范
规范地址计算模块接口的设计与实现过程
将所有功能合成一个工具类Utils进行使用,后续设计api接口时候可以进行搬运调用,并且写了一个生成测试文本的程序用来测试。项目结构为:
核心功能部分代码
根据遍历来统计字符数
思路:一开始的想法是使用java中的正则表达式来匹配ASCII码,后续完成后在无意间发现通过readline会导致换行丢失且出现错误,后续经过验证后对自己的代码进行了修改,在该函数中进行了文件的read操作,并计数进行统计。
BufferedReader bufferedReader = null;
try{
String pre_path=new File("").getAbsolutePath();
bufferedReader = new BufferedReader(
new InputStreamReader(new FileInputStream( pre_path+ "\\" + filepath),"utf-8"));
while((bufferedReader.read())!=-1)
{
char_num+=1;
}
}
catch(...)
if(bufferedReader!=null){
bufferedReader.close();
}
return char_num;
}
统计文件的单词总数
思路:题意为获取为字母开头且长度大于4的单词数,使用正则表达式匹配。首先通过String类自带的split方法去拆开整篇文章使其形成一个数组,然后通过正则表达式去选择出正确的单词并作统计。
// 构造正则表达式,去根据空格拆分整篇文章
// temp字符串数组将保存所有的单词
//处理特殊字符,以免被误以为是单词的一部分
String[] temps = words.toString() .split("[^a-zA-Z0-9]");
// 构造题意:以字母开头且长度大于4的单词
String regexs = "^[a-zA-Z]{4,}.*";
// 循环遍历这个数组,利用正则表达式去匹配
for (int i = 0; i < temps.length; i++) {
if (temps[i].matches(regexs)) {
// 匹配成功,计数加1
word_num++;
//System.out.println(temps[i]);
}
}
return word_num;
统计文件的有效行数
思路:想通过获取文件中非空行的方式来进行统计,使用BufferdReader来读取文件,将要调用的文件放在src下.通过获取绝对路径的方式并与文件名拼接来查询文件,遍历行数累加。在构建文件对象的时候一开始使用了File直接来构建,发现其编码有误,不是UTF-8,且无法做修改,后续更换了InputStreamReader类型来让指定文件类型。
String pre_path=new File("").getAbsolutePath();
try {
bufferedReader = new BufferedReader(
new InputStreamReader(new FileInputStream( pre_path+ "\\" + path),"utf-8"));
String line;
// 通过循环不断整行读取文件
// 同时记录读取次数即可
while ((line = bufferedReader.readLine()) != null) {
//匹配任意非空白字符
if (line.length() != 0 && !line.matches("\\s+")) {
line_num++;
}
}
} catch (...)
return line_num;
}
统计文件中各单词的出现次数
思路:词频统计我用map来存储键值对,首先还是做相同的正则匹配来获取所有单词,然后进行遍历加数,以(单词名,出现次数)键值对存入map中。在排序时构造匿名内部类来重写compare方法,先比较值,如果值相同,则比较键序。并且为了判断字典序再写了一个方法来进行比较。
List<Map.Entry<String, Integer>> list = new ArrayList<>(map.entrySet());
// 构造匿名内部类
// 首先根据频率比较,如果频率相同,比较字典序
list.sort((Comparator<Map.Entry>) (o1, o2)
-> ((Integer) o1.getValue()).compareTo((Integer) o2.getValue()) != 0
? ((Integer) o2.getValue()).compareTo((Integer) o1.getValue()) : getCharNums((String)o1.getKey(),((String)o2.getKey())));
// 返回list 前十个 数据,也即出现的前十的高频词
return list.size() < 10 ? list.subList(0, list.size()) : list.subList(0, 10);
}
文件存取功能
思路:分别使用BufferedReader和BufferedWriter来进行文件的存取,增加了缓冲区对于性能有所提高,并且根据题意更换了File并使用InputStreamReader和OutputStreamWriter来替代,从而定义文件的默认编码。
String pre_path=new File("").getAbsolutePath();
try {
BufferedReader bufferedReader = new BufferedReader(
new InputStreamReader(new FileInputStream( pre_path+ "\\" + path),"utf-8"));
String temp;
while ((temp = bufferedReader.readLine()) != null) {
stringBuilder.append(temp).append("\n");
}
bufferedReader.close();
} catch(...)
return stringBuilder;
}
String pre_path=new File("").getAbsolutePath().toString();
try {
//生成的文件放在当前项目下
BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream( pre_path+ "\\" + path),"utf-8"));
bufferedWriter.write(message);
bufferedWriter.flush();
bufferedWriter.close();
} catch (...)
}
性能改进
1.IO处理上,使用了BufferedReader和BufferedWriter类,从性能来看比没有缓冲区的效率更好。
从全局的角度来考虑,在性能上我选择了能够避免使用正则表达式就避免,但不可全部舍去,可以节省代码开发时间,保持了较高的效率。
如在统计字符数上我分别使用了两个方法进行测试:
发现正则匹配性能较差,因此我只在统计单词和词频时候进行使用正则表达式。
单元测试
测试字符统计数据代码
对于统计字符进行了测试,包括ascii码的所有进行了一次统计。如无误则说明功能符合要求。
for(int i=0;i<128;i++){
stringBuilder.append((char)i);
}
message=stringBuilder.toString();
utils.writeTo("1.txt",message);
System.out.println("characters: "+utils.charNums("1.txt"));
测试单词统计数据代码
测试了一些可能出现的情况,并通过测试输出的值来比对进行判断功能是否符合。
//添加测试,包括基本可能出现的情况
stringBuilder.append("cold111").append("\n"); //是
stringBuilder.append("col111").append("\n"); //不是
stringBuilder.append("col]dl11").append("\n"); //不是
stringBuilder.append("col\nd111").append("\n"); //不是
stringBuilder.append("cola! sssb. aaaa, abbd\t dsds123").append("\n"); //5个都是
System.out.println("words: "+utils.wordNums(stringBuilder));
测试统计行数函数
测试了非空字符是否能够被算入有效行数中,如不能则功能符合需求。
/**
* 测试功能3,非空字符全部算行,
* 1.txt内容:
* ssss444 563ff 11d fase11 windows95 windows98 windows2000
*
* 1
* \n
* 2
* \t
*/
public void testLinenums() {
try {
Utils utils=new Utils();
System.out.println("lines:"+utils.lineNums("1.txt"));
}
catch(...)
}
测试统计词频数据代码
重点测试了词频的排序以及相同时是否能够以字典序进行排序。如可以则功能符合需求
for (int i = 0; i < 9; i++) {
for (int j = 2000; j < 2010; j++) {
stringBuilder.append("windows").append(j).append(",\n");
}
}
for (int i = 0; i < 10; i++) {
stringBuilder.append("windows2021,\n");
stringBuilder.append("WINDOWS2000.\n").append("windows98!\n").append("windows95?\n").append("windosa,\n");
stringBuilder.append("sjy%dsd*,\n");
}
对于上述的测试代码进行了测试,功能都是相符合的。
线性测试
分别测试了1000,10000,100000,1000000个单词的时间.
测试发现时间复杂度和单词量呈线性增长,且在使用了缓冲区后,运行时间分别为68ms,150ms,386ms,2464ms,耗时有了明显的缩短。
覆盖率
写代码前先进行规划,能够提升覆盖率
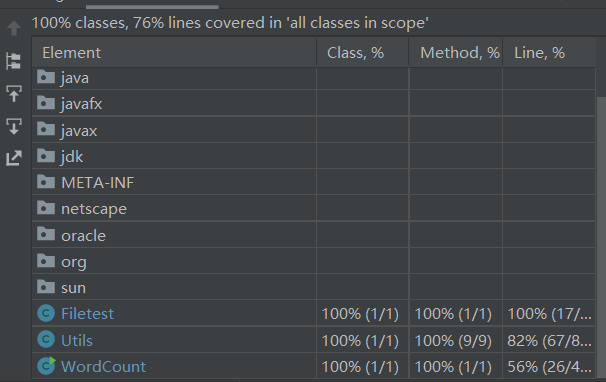
异常处理
只有简单的对于IO流的异常处理,如try,catch。因为项目较小,无自定义异常处理。在程序入口如果运行参数有误则会运行默认的测试方法。
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(h) | 实际耗时(h) |
|---|---|---|---|
| Planning | 计划 | 0.5 | 0.5 |
| Estimate | 估计这个任务需要多少时间 | 12 | |
| Development | 开发 | 2 | 3 |
| Analysis | 需求分析 (包括学习新技术) | 2 | 1 |
| Design Spec | 生成设计文档 | 0.5 | 0.5 |
| Design Review | 设计复审 | 1 | 0.5 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 1 | 0.5 |
| Design | 具体设计 | 2 | 2 |
| Coding | 具体编码 | 2 | 2 |
| Code Review | 代码复审 | 0.5 | 1 |
| Test | 测试(自我测试,修改代码,提交修改) | 2 | 2 |
| Reporting | 报告 | ||
| Test Repor | 测试报告 | 1 | 2 |
| Size Measurement | 计算工作量 | 0.5 | 0.5 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 1 | 1 |
| 合计 | 16 | 16.5 |
总结
1.温习了java所学的一些知识点,且了解到了一些新的特效会在后续的开发中学习和使用。
2.学会了使用psp表格来规划,对于后面大的项目更能够有所帮助。
3.测试要做到尽量完善,给用户更好的体验。
4.对于自身写代码时候的一些问题还需要订正,如没有比较简洁的代码风格,还需要更加努力学习。
5.更加熟练的使用git,以前是直接用git bash来提交项目,现在我用了编译器来调用git,更加的方便。且对于git如何使用有了更深的体会。
6.对于构建之法的学习,因为还没有发书因此去到了老师的博客学习,通过了几天的观看,学到了不少的知识,且老师的书籍幽默风趣让我深入其中,对于书中的故事所阐述的道理能够有更好的认识。也领悟了很多的道理如团队如何合作等,之后书籍下来后会继续去阅读和钻研书本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号