
随笔分类 - 爬虫
下载器中间件
摘要:Downloader Middlewares(下载器中间件) 下载器中间件是引擎和下载器之间通信的中间件。在这个中间件中我们可以设置代理、更换请求头等来达到反反爬虫的目的。要写下载器中间件,可以在下载器中实现两个方法。一个是 ,这个方法是在请求发送之前执行,还有一个是 ,这个方法是数据下载到引擎之前
阅读全文
下载文件和图片
摘要:下载文件和图片 Scrapy为下载item中包含的文件(比如在爬取到产品时,同时也想保存对应的图片)提供了一个可重用的 。这些 有些共同的方法和结构我们称之为 。一般来说你会使用 或者 。 为什么要选择使用 内置的下载文件的方法 1. 避免重新下载最近已经下载过的数据。 2. 可以方便的指定文件存储
阅读全文
Request和Response
摘要:Request对象: 对象在我们写爬虫,爬取一页的数据需要重新发送一个请求的时候调用。这个类需要传递一些参数,其中比较常用的参数有: 1. :这个request对象发送请求的url。 2. :在下载器下载完相应的数据后执行的回调函数。 3. :请求的方法。默认为 方法,可以设置为其他方法。 4. :
阅读全文
crawlspider
摘要:Scrapy中CrawSpider 回头看: 之前的代码中,我们有很大一部分时间在寻找下一页的url地址或者是内容的url地址或者是内容的url地址上面,这个过程能更简单一些么? 思路: 1. 从response中提取所有的a标签对应的url地址 2. 自动的构造自己requests请求,发送给引擎
阅读全文
scrapy模拟登录
摘要:对于scrapy来说,也是有两个方法模拟登陆: 1. 直接携带cookie 2. 找到发送post请求的url地址,带上信息,发送请求 scrapy模拟登陆之携带cookie 应用场景: 1. cookie过期时间很长,常见于一些不规范的网站 2. 能在cookie过期之前把搜有的数据数据拿到 3.
阅读全文
scrapy入门使用
摘要:scrapy入门 1. 创建一个scrapy项目 scrapy startporject mySpider 2. 生产一个爬虫 scrapy genspider itcast "itcast.cn" 3. 提取数据 完善spider,使用xpath等方法 4. 保存数据 pipeline中保存数据
阅读全文
scrapy流程
摘要: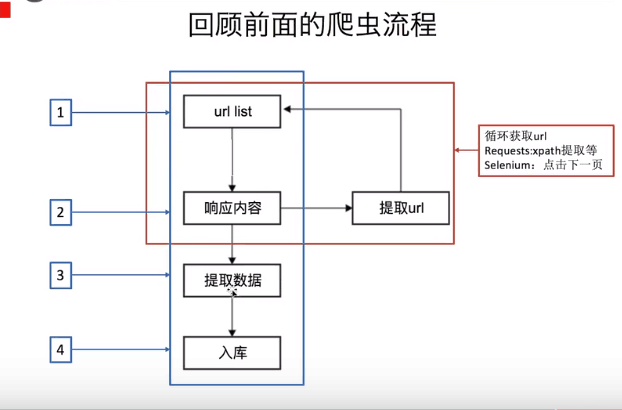 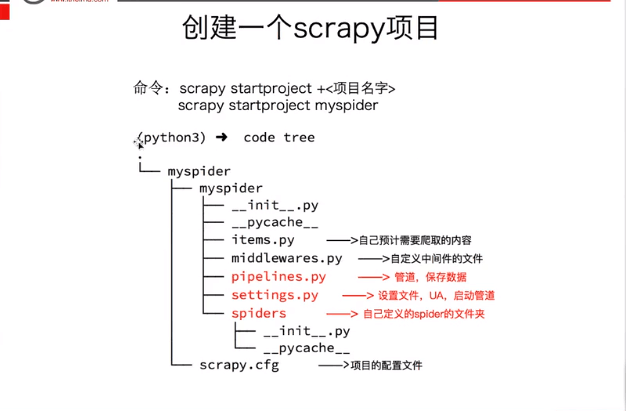  2. 安装 sudo apt get install tesseract ocr 3. 在python中调用Tesseract pip install pyte
阅读全文
动态HTMl处理
摘要:后续爬虫代码的建议 尽量减少请求次数 1. 能抓列表页就不抓详情页 2. 保存获取的html页面,供差错和重复请求使用 关注网站的所有类型的页面 1. wap页面,触屏版页面 2. H5页面 3. APP 多伪装 1. 动态的UA 2. 代理ip 3. 不使用cookie 利用多线程分布式 在不被b
阅读全文
寻求js
摘要:寻找登录的post地址 在form表单中寻找action对应的url地址 post的数据是input标签中的name值作为键,真正的用户名密码作为值得字典,post的url地址就是action对应的url地址 抓包,寻找登录的url地址 勾选presever log按钮,防止页面跳转不到url 寻找
阅读全文
requests模块
摘要:requests使用入门 问题:为什么要学习requests,而不是urllib? 1. requests的底层实现就是urllib 2. requests在python2和python3中通用,方法完全一样 3. requests简单易用 4. requests能够自动帮助我们解压(gzip压缩的
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号