工作记录 4.1
Mind-Eye(NIPS 2023 spotlight):
https://arxiv.org/abs/2305.18274
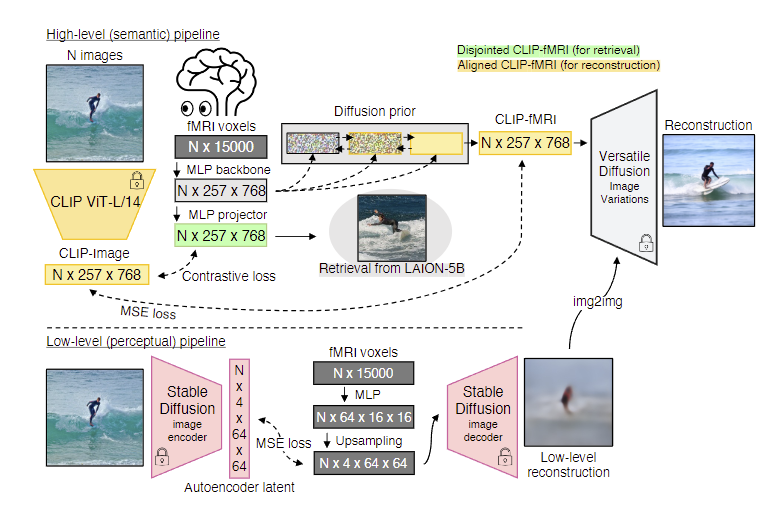
该方法,会预测图像经过 CLIP vision encoder 后的全部特征(用于),但不是用岭回归方法。
MLP backbone:4个残差块+线性投射层

其实总结一下,FMRI -> text or image 的几乎所有方法,都是变相的一种知识蒸馏。
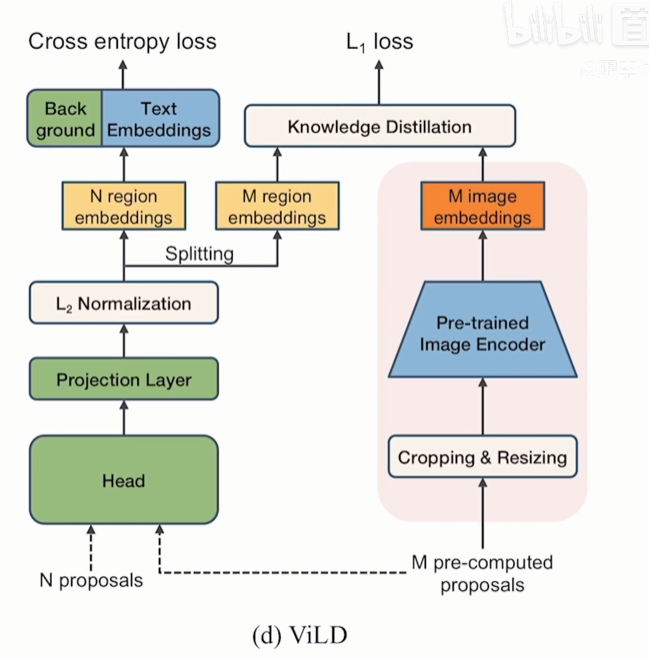
ViLD:
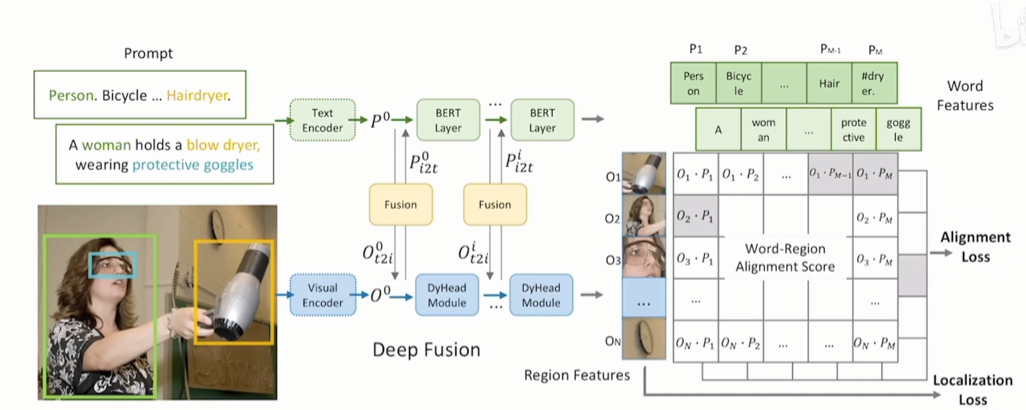
Glip(Vision grounding):
Faster-RCNN:

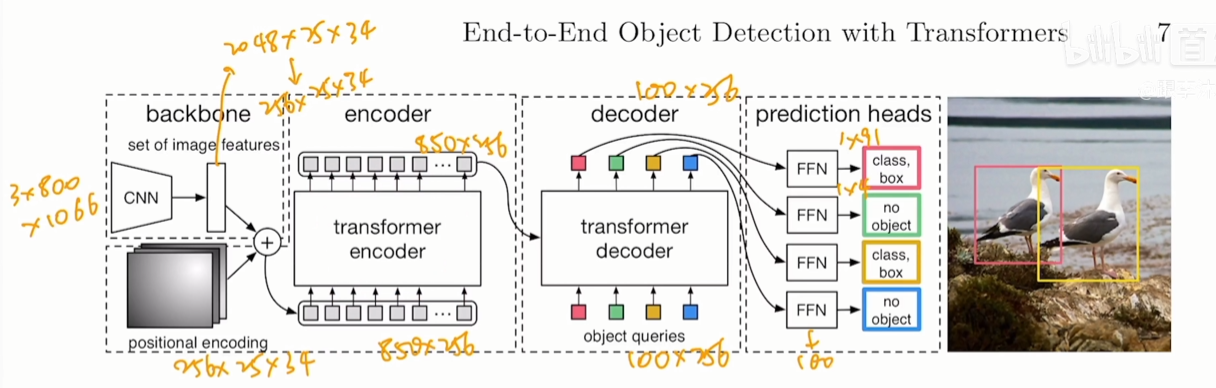
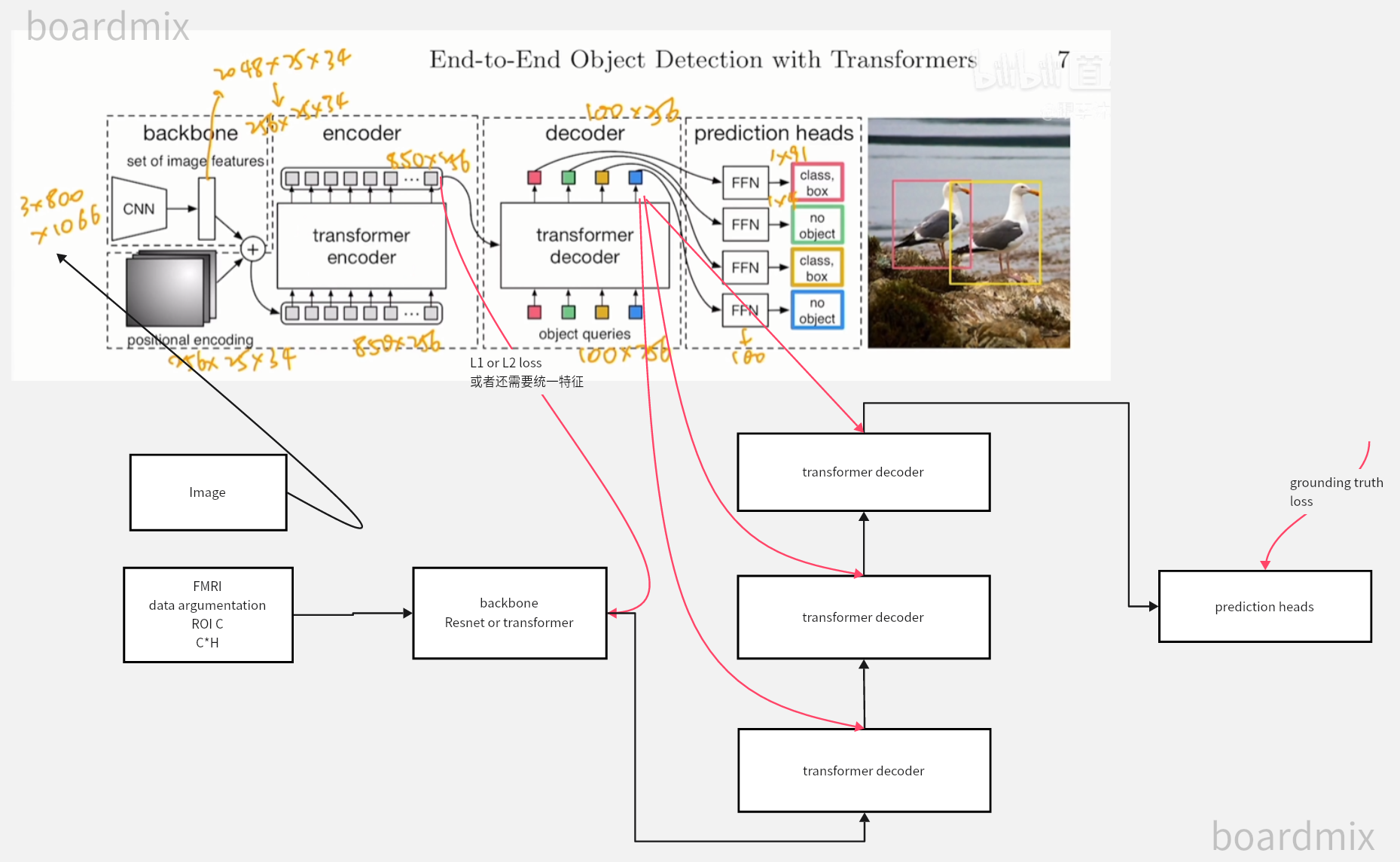
DETR:
BEVDistill:
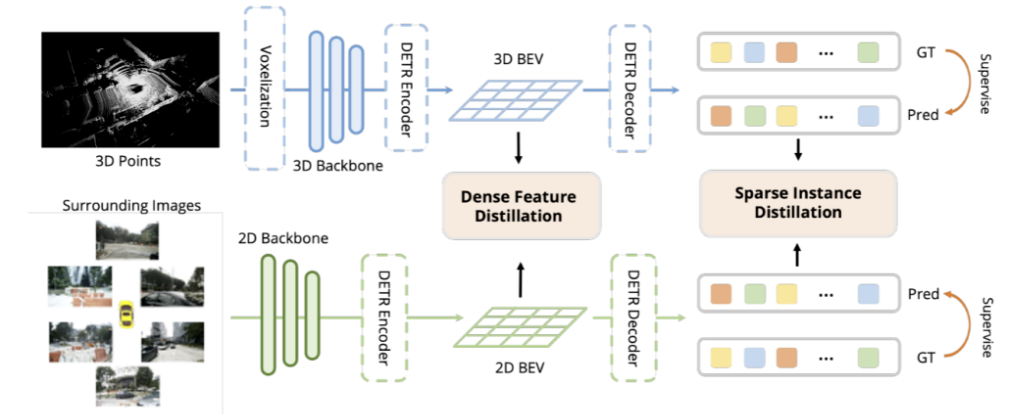
DistillBEV(更精细的蒸馏):
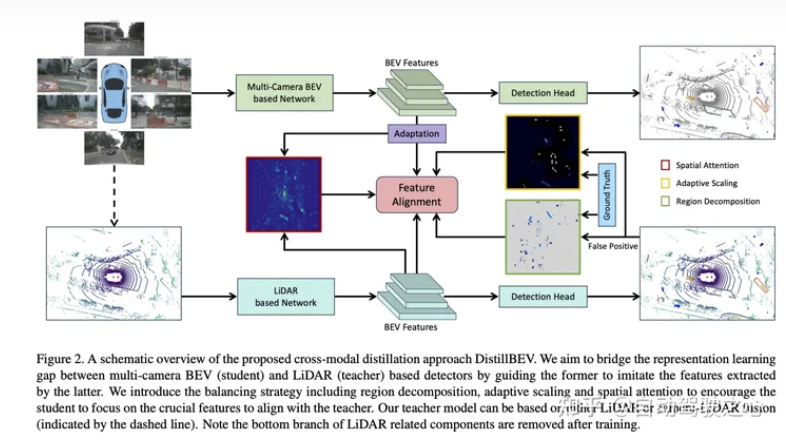
架构:
转载注意标注出处:
转自Cold_Chair的博客+原博客地址

 浙公网安备 33010602011771号
浙公网安备 33010602011771号