一些工作记录 3.26
Mind-GPT 这篇文章,刚刚细读了一下:
https://arxiv.org/abs/2309.15729
其只用到图片经过 CLIP encoder 后的全局特征([CLS] token 对应的特征,1*768),然后用一个 transformer 去由 FMRI 预测CLIP全局特征,loss 是MSE。
同时用预测的特征加上一个交叉注意力层喂给GPT2(loss 是交叉熵损失)。
两个 loss 联合在一起训练,也取得了一定效果

其做了一个实验:
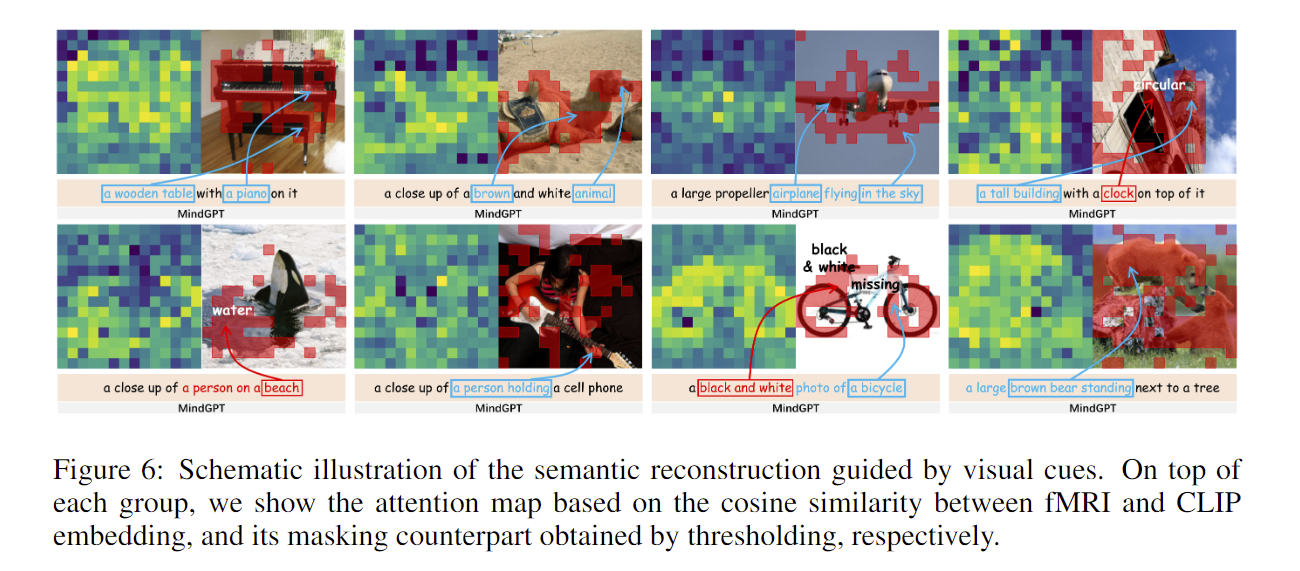
就是用 FMRI 预测的全局特征和每个patch的特征余弦相似度,相似度越大,亮度越高。
作者发现就是核心物体的周围区域亮度比较高,其它区域则暗淡
(我觉得这一部分原因是拟合的是全局特征,全局特征当然集中在重要语义物体上)
在思考一个问题:
之前的做法是岭回归预测所有的 patches 特征 + 全局特征,(然后由现有的方法去 decode 出 caption)
该方法只用全局特征,也能 decode 出 caption(但是没开源不太好比较效果)
从自然角度来看,一些无关紧要的 patch 能不能被大脑捕捉到信息是一个问题,一个 patch 太小大脑能捕捉多少信息也是问题。
当然 CLIP encoder 是能捕捉到的,而我们从 FMRI 去 还原出一些 patches 的特征是很难的,即有可能预测出来噪声,最后干扰了生成模型由特征生成文本。
全局特征
mse ridge 0.34308326
mse mlp 0.2492959476374768
cos ridge 0.2926877
cos mlp 0.6081855121466824
可以发现 mlp 的全局特征的预测还是 ridge 强很多的。
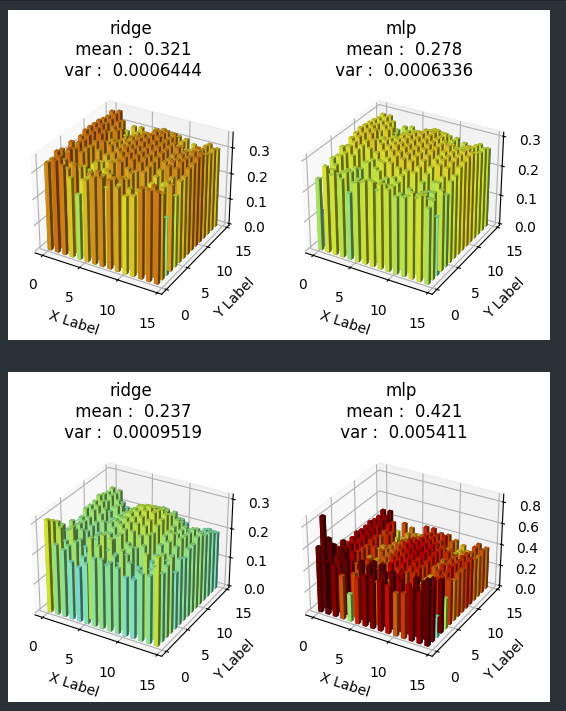
实验1:
对每个 patch,
比较 ridge 和 mlp 两个方法生成的特征 和 图片经过 CLIP encoder 得到的特征(即要预测的测试集的 Y)
左:ridge 右:mlp
上:MSE 下:cos
-
mlp 方法虽然均值优,但方差很大,可能给生成模型带来干扰。
-
mlp 中间的 patch 和 Ridge 差不多,但 mlp 的中间 patch 显著劣于四周的 patch
而 ridge 则平滑一点,特别在中间 patch 的表现不比四周的差(虽然 mlp 的中间 patch 的预测效果依然比 ridge 好)
语义信息来说,中间 patch 应该重要于四周 patch(当然中间 patch 肯定难预测),mlp 这样会带来干扰
实验2:
仿照论文中的对每个 patch 的特征求余弦相似度方法,
固定一张图片,对每个 patch 的特征与全局特征求 MSE loss,得到:
原,ridge,mlp,mlp_20(这个顺序代表用原特征的每个 patch,和按顺序的每个方法求 MSE)

ridge,原,mlp, mlp_20

mlp,原,ridge,mlp_20

mlp_20, 原,ridge,mlp

由第一行,可以发现 mlp 的方法,预测全局特征还是比较准的,而 ridge 预测的全局特征比较差。
但是,再看第二列(第二行以后),会发现 ridge 在 patch 的预测上分化的好一些(虽然也没有捕捉到飞机)。
需不需要只预测全局特征试试看?
关于模型:https://paperswithcode.com/sota/image-captioning-on-coco-captions
目前找到了一些模型只用全局特征 ClipCap,
但目前跑的好的算法我看了都是要用全部的特征:BLIP-2 mPLUG Oscar(这些方法都是做多任务的大模型)
CLIP-Caption-Reward:用全部特征。
CoCa :用 CLIP 的全部特征(主要用全局特征,patch 特征做了个交叉注意力喂给生成模型)
SimVLM 只做字幕,但是也是用所有 patch 的特征(用了一个预训练的 Resnet)
ExpansionNet v2 只做字幕,但是用了 swin transformer去提取全部特征,后面的训练也是利用全部特征
Xmodal-Ctx 这个同时利用 CLIP encode 的全局特征 还用了个目标检测,也不太行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号