

今日:爽
1.早上在宿舍改简历,做出来了一版还可以的。中午点了古丽花这次小吃给了很多,爽。
2.下午差点把上课忘了,带着电脑去上课。课上把VIST3A模型拼接看了,思路挺牛逼,宣怀的没填。
3.晚上回家,去姥姥家开会,跟哥哥聊。回家打守望连输到12点半,气笑了。
VIST3A: TEXT-TO-3D BY STITCHING A MULTI-VIEW RECONSTRUCTION NETWORK TO A VIDEO GENERATOR收获感悟
粗读:
1.Abstract:
①视频模型对文本-视觉潜编码很擅长(generator),3D模型对解码生成场景几何很擅长(decoder)。
②把它俩缝合到一起,组成text-to-3D生成模型。缝合模块操作只需要很少的数据集+零标签。
③直接奖励微调,一种流行的人类偏好对齐技术?
2.Introduction:
传统用Score Distillation Sampling(让2D扩散模型教3D生成模型,比较粗糙)和给出一组2D视图来生成3D模型。
引出端到端的潜空间扩散3D生成模型。有的用预训练2d image/video生成模型去整多视角,用先验合成3D模型。作者认为2d到3d的解码器是致命弱点,需要大量数据去训而且效果不好。作者还认为生成模型和VAE解码器对齐很费劲,2d和3d的损失难以对上联合训练,只有渲染损失能够链接,但还是不好。他们的框架保留了视频生成器和3D解码器处理长序列的能力
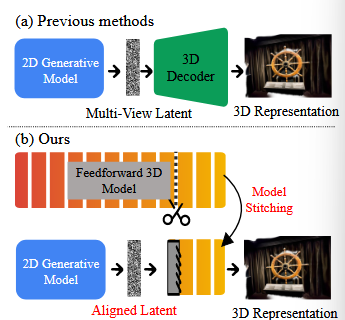
VIST3A: VIdeo VAE STitching and 3D Alignment.
两个技术:
①缝合视频生成模型和3D生成模型。
②直接奖励微调:让解码结果的视觉质量和3D一致性(即前面说的人类偏好)保持高。
精读:
1.相关工作:
①3D生成:经典点云\mesh\体素格\nerf\3dgs。分数蒸馏。
端到端生成架构:现有的基本都面向object-centric,对大场景复杂光照就寄了。引出很多今年的文章第三页,现有的方法生成一堆2d多视角图片,输入给3d重建模型得让它重新学习特征。
②3D重建:3d计算机视觉从多管道+迭代发展到了端到端+前馈。训练很贵,还要加上尺度。
③模型缝合:一些训练过的网络A的头部通常通过线性的、可训练的拼接层(stitching layer)连接到另一个网络B的尾部。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号