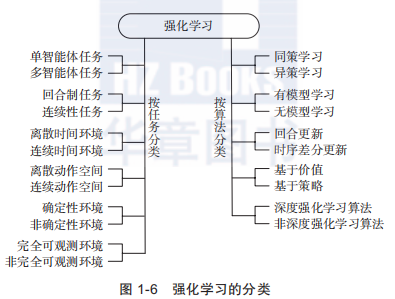
强化学习的分类
环境
- 单智能体任务(single agent task)和多智能体任务(multi-agent task)
- 回合制任务(episodic task)和连续性任务(sequential task):对于回合制任务,有明确的开始状态和结束状态。而对于连续性任务,没有明确的开始结束条件;
- 离散时间环境(discrete time environment)和连续时间环境(continuous time environment):如果智能体和环境的交互是分步进行的,那么就是离散时间环境。如果智能体和环境的交互是在连续的时间中进行的,那么就是连续时间环境。
- 离散动作空间(discrete action space)和连续动作空间(continuous action space)
- 确定性环境任务(deterministic environment)和非确定性环境(stochastic environ-ment)
- 完全可观测环境(fully observable environment)和非完全可观测环境(partially observable environment)
算法
- 同策学习(on policy)和异策学习(off policy):on policy学习是指边决策边学习,学习的策略和决策的策略相同;而off policy是指学习的策略和决策的策略并不一定是同一个策略;
- 有模型学习(model-based)和无模型学习(model free):model free方法是指不需要关于环境的任何信息,不需要搭建的环境模型,所有的信息都是通过与环境的交互得到;而model-based方法需要对环境的认识,可能在学习前环境模型已经明确,也可能是在学习的过程中通过与环境交互得到的经验对环境进行建模;
- 回合更新(Monte Carlo update)和时序差分更新(temporal difference update):回合制更新是在回合结束后利用整个回合的信息进行更新学习;而时序差分更新不需要等回合结束,可以综合利用现有的信息和现有的估计进行更新学习;
- 基于价值(value based)和基于策略(policy based):基于价值的强化学习定义了状态或动作的价值函数,来表示到达某种状态或执行某种动作后可以得到的回报。基于价值的强化学习倾向于选择价值最大的状态或动作;基于策略的强化学习算法不需要定义价值函数,它可以为动作分配概率分布,按照概率分布来执行动作;
posted @
2021-03-16 20:15
米么裤
阅读(
266)
评论()
收藏
举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号